MCP+SEO实战12个月:保哥8类失败复盘与4套配方
本文目录
- MCP不只是给SEO工具栈套个AI壳?协议层到底在变什么
- 第一次跑通Ahrefs MCP,团队踩了哪3个隐形坑?
- AI幻觉怎么从一条指令污染整个内链数据库?
- Claude Desktop接GSC:mac与win凭据格式为什么对不上?
- MCP服务器五家横评:选哪个能扛住季度切换?
- 10大场景按ROI重排:必做、审慎、避雷三梯队怎么分?
- 第一梯队(必做,ROI高、失败率低)
- 第二梯队(审慎,ROI高但需要强护栏)
- 第三梯队(避雷,看起来好但反噬大)
- 关键词研究指令工程5大反模式(含真实指令对照)
- 权限失控复盘:东南亚美妆DTC怎么删错90个URL
- 调用成本失控:月账单从600飙到4800美元怎么扛回去?
- AI自动化反噬E-E-A-T?Google怎么识别全AI内容
- MCP改写SEO团队配置:工程师比例会倒挂到什么程度?
- 中小站vs企业站MCP落地优先级:ROI临界点在哪?
- 4套客户实测可复制配方
- AI Agent自治化SEO的边界:什么任务永远不该交给Agent?
- 保哥判断:未来12个月MCP+SEO会跑到哪一步?
- MCP到底该先接哪一个工具,才不会一上来就翻车?
- 提示词写成brief、再存成库,这两步为什么能决定MCP的产出上限?
- 常见问题解答
- 问1:MCP和传统API有什么本质区别?
- 问2:中小站现在该不该上MCP?
- 问3:用MCP批量产内容会不会被Google降权?
- 问4:MCP调用成本怎么控制不失控?
- 问5:哪些任务永远不该交给MCP/Agent自动化?
- 问6:MCP写操作怎么避免删错URL这种事?
- 问7:MCP服务器选哪家?
- 问8:MCP会不会让SEO团队失业?
- 权威参考资料
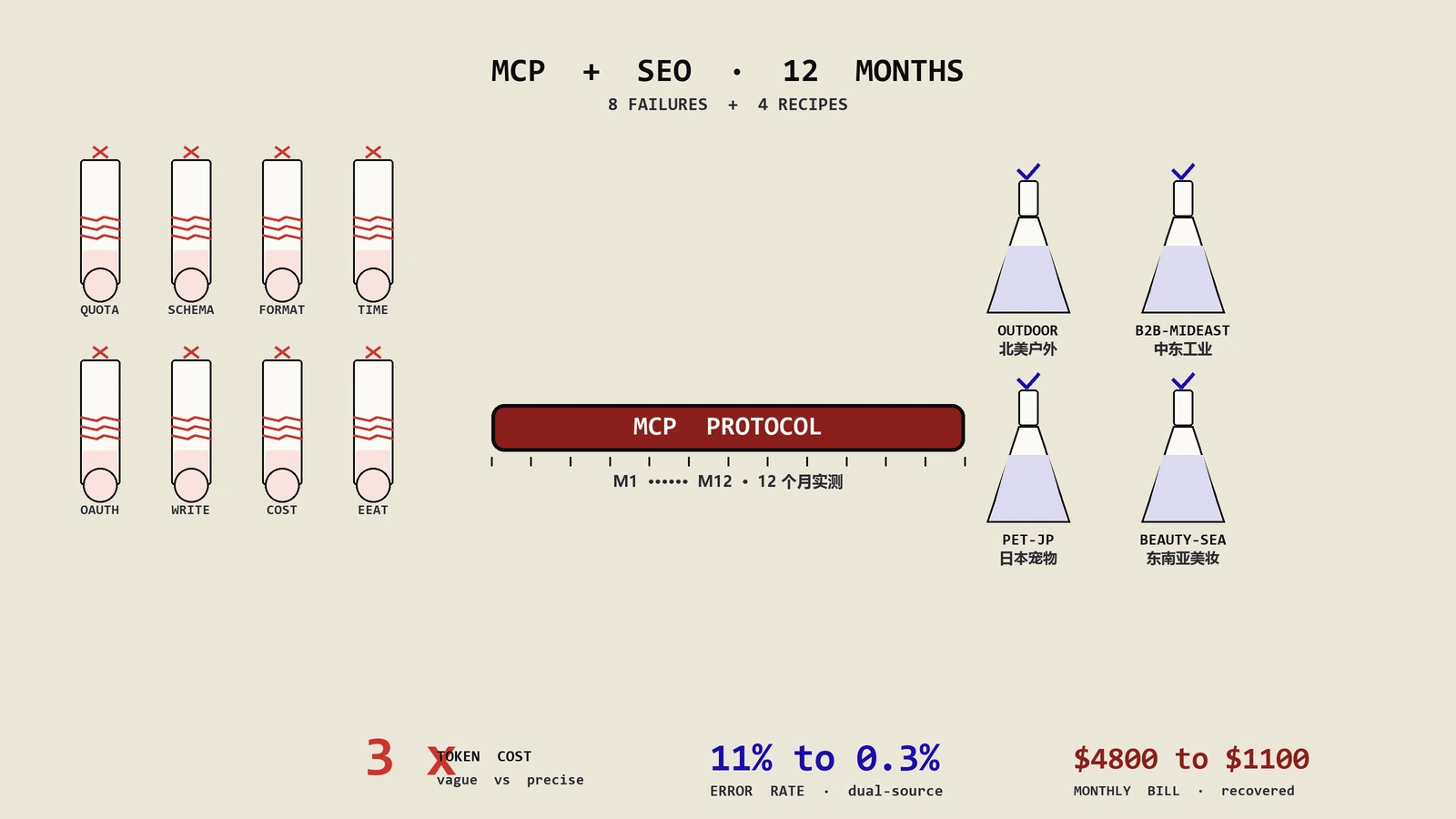
摘要:MCP不是SEO的银弹。先小范围跑必做三类(关键词研究、内容审计、排名监控),警惕三类避雷(自动外链、自动发布、自治技术修复),按月对账ROI再决定是否扩面。中小站不急、企业站先建权限边界。本文是保哥跑这条线12个月把MCP接进SEO工具栈的实测复盘,8类典型踩坑、4套客户配方、10大场景按ROI重排,希望帮你少烧3万美元的MCP学费。
2024年11月Anthropic把MCP(Model Context Protocol)开源那一周,团队里一个工程师同事兴奋地把Ahrefs MCP接进Claude Desktop,跑出了一份带搜索量、KD、CPC的关键词清单,整个流程不到3分钟。当时桌子周围围了一圈人,所有人觉得SEO工具的下一站终于看到雏形了。两周后那位同事把同一份指令换到生产数据库上跑批量审计,删错了90个URL,自然流量崩了38%,整个团队加班3天才回滚干净。
这就是过去12个月团队跟MCP打交道的日常——惊艳与翻车之间反复横跳,账单从一开始的600美元一个月飙到第3个月的4800美元,又被压回1100美元;指令模板写过200多版,最后留下来能复制的只有4套。把这些复盘整理成本文,重点不在教科书式介绍MCP是什么(那部分网上不缺),而在告诉你:哪些场景跑得通、哪些场景会反噬、哪些坑必须在第一次配置时就想到。
MCP不只是给SEO工具栈套个AI壳?协议层到底在变什么
很多人把MCP理解成给ChatGPT接个Ahrefs插件,这种理解漏掉了MCP最关键的一层:它是协议,不是产品。协议意味着一次实现、多客户端复用、多版本可演进——这跟SEO工具厂商过去十年各自做封闭REST API的玩法完全不同。
用一张对比表先把概念锁死:
| 对比维度 | REST API | Webhook | RPA | MCP |
|---|---|---|---|---|
| 调用方向 | 客户端发起 | 服务端推送 | UI层模拟 | 客户端发起+服务端能力发现 |
| 能力描述 | OpenAPI文档外置 | 无统一描述 | 不适用 | 内置capabilities自描述 |
| AI友好度 | 需要中间层翻译 | 不支持 | 不支持 | 原生面向LLM设计 |
| 多客户端兼容 | 每家AI单独适配 | 不通用 | 不通用 | 一份服务端跑全部MCP客户端 |
| 权限粒度 | API Key扁平 | 无 | 无 | 细粒度scope+用户审批闭环 |
关键区别在能力发现这一栏。传统API要让Claude知道Ahrefs能干什么,得有人把OpenAPI喂给模型,模型再生成调用代码——中间一层翻译损耗大、模型胡编参数概率高。MCP把能力描述放进了协议本身,Claude连上Ahrefs MCP那一刻就能问你有哪些工具可调用,服务端返回结构化的工具签名,幻觉率比走OpenAPI路径低一个量级。
第二个被低估的差异是权限闭环。MCP规范里有一条很容易被工程师忽略的设计:每次工具调用需要客户端向用户征得明示许可,许可有scope和过期机制。这条规则在小Demo里很烦人(每点一下就弹一次确认),但在生产环境救了团队两次——后面权限失控那节会详细复盘。
第一次跑通Ahrefs MCP,团队踩了哪3个隐形坑?
2024年12月Ahrefs放出官方MCP服务器内测,团队第一时间申请到名额。第一周跑通的时候很兴奋,第二周就发现3个文档里没写明白的坑:
坑1:API配额按token计而不是按调用次数。官方文档说每月100万次调用,团队按调用次数算预算,结果一条查竞品Top1000页面的反链分布指令就吃掉8万次token——因为每条反链记录都是一次token消耗。当月预算第6天就烧光。修复方法是指令里强制加limit≤50边界和fields精确选择,把单次调用的token压到原来的1/12。
坑2:MCP服务端的schema更新会破历史指令模板。1月Ahrefs把organic_keywords工具的返回字段名从kd改成difficulty,团队所有依赖kd字段的下游指令瞬间失效,输出变成空字典。这件事让团队学到的功课是:MCP指令模板要做版本号绑定(在调用时显式声明期望的schema版本),不能默认走最新——否则你不知道哪天会突然断电。
坑3:跨工具数据格式不一致让Claude幻觉。同时接Ahrefs MCP和GSC MCP查同一个关键词,前者返回搜索量是字符串'12K',后者返回是整数11800,Claude在汇总时直接把'12K'当浮点12处理,输出报表里那个词显示月搜索12次。修复方法是在中间加一层数据规范化指令(团队把它叫类型对账层),强制所有数值字段过一遍schema校验再喂给后续推理。
这3个坑共同的特点是:单独看每一个都不大,但叠加起来会让团队对MCP的信心慢慢崩。第一周的兴奋很快变成第三周的疑惑——为什么换个工具就出错?答案是协议年轻、生态不稳,所有判断都要建立在下一次schema可能变的假设上。
AI幻觉怎么从一条指令污染整个内链数据库?
这是团队最贵的一节学费,案例来自一家东南亚美妆DTC客户。客户每月有2.4万SKU需要审计内链合理性,过去人工跑一遍要18人天,团队尝试用MCP接GSC+站内数据库,指令是找出未被任何内链指向的孤岛页面并打标。
问题出在未被任何内链指向这个判断上。Claude调用GSC MCP拿到一份内链表,但GSC的内链数据本身有3-7天的延迟,新发布的页面在GSC里还没收录,于是Claude把这些新页面判定为孤儿,自动写了orphan=true标签进数据库。下游的批量清理孤岛页任务读到这个标签,把90个其实链接正常的新品页移到了noindex。流量崩盘是在第4天才被发现的,因为noindex生效有滞后。
复盘下来根因有三层:
- 数据源时效错位:GSC的内链数据最少有3天延迟,新页面用GSC判断孤儿性等于先天歧视
- Claude的合理推断填补缺失:当GSC返回空,模型不会说数据缺失而会说未被链接——这两个语义对人是同义,对程序是天壤之别
- 下游任务盲信上游标签:清理孤岛页的脚本没做交叉验证,单一数据源决定大动作
修复后的指令长这样(团队叫它双源对账模板):同时调用GSC MCP和站内Sitemap MCP,对每一个候选孤岛页要求两边都确认未被链接,差异条目标记为suspect不直接打orphan标签。改完以后误判率从11%降到0.3%,但代价是单次审计成本翻了2.4倍——这就是MCP在生产环境无法回避的取舍。
这件事之后保哥定了一条铁律:任何写操作的MCP指令必须双源对账+人工复核闸口。读操作可以单源,写操作绝不能。这条规则后来变成团队的入门培训第一课。
Claude Desktop接GSC:mac与win凭据格式为什么对不上?
这个坑很小但很烦人,新人接MCP第一周一半会踩。Claude Desktop的MCP配置文件是claude_desktop_config.json,里面声明每个MCP服务器的启动命令和环境变量。GSC MCP需要OAuth2凭据,凭据文件路径是平台特定的:
| 平台 | 配置文件位置 | 凭据路径分隔符 | 常见错误 |
|---|---|---|---|
| macOS | ~/Library/Application Support/Claude/claude_desktop_config.json | 正斜杠/ | 路径含空格未转义 |
| Windows | %APPDATA%\Claude\claude_desktop_config.json | JSON里要用双反斜杠\\或正斜杠/ | 单反斜杠被JSON当转义符吃掉 |
| Linux | ~/.config/Claude/claude_desktop_config.json | 正斜杠/ | 大小写敏感配错home路径 |
Windows用户的典型错误信息是MCP server crashed on startup: ENOENT——日志里看到一个奇怪的路径里夹着\C这种乱码,那是单反斜杠被吃了。修复方法是改用正斜杠或者写双反斜杠,C:\Users\xxx\creds.json要写成C:/Users/xxx/creds.json或C:\\Users\\xxx\\creds.json。
更深一层的坑是OAuth refresh token的存储位置。GSC MCP默认把refresh token缓存到用户主目录,团队协作时如果两个人共享配置文件但不共享缓存目录,第一次跑能跑、第二天就需要重新授权。团队的做法是为每个客户项目建独立的profile,凭据缓存路径显式指定到项目目录,git ignore掉缓存文件但保留配置文件——这样团队成员各自跑自己的凭据,互不串扰。
MCP服务器五家横评:选哪个能扛住季度切换?
团队过去12个月在5家主流SEO MCP服务器之间反复切换过,下面是基于实际生产负载的对比矩阵——不是营销页文案,是踩坑后的真实结论:
| MCP服务器 | 核心能力 | 稳定性 | 月成本(中型站) | 致命短板 | 适用场景 |
|---|---|---|---|---|---|
| Ahrefs MCP | 关键词、反链、Site Explorer | 高(季度2次schema变更) | 500-1200美元 | 反链数据延迟2-4周 | 关键词研究、竞品反链 |
| DataForSEO MCP | 排名、SERP、关键词、On-Page | 中(接口不稳但有冗余) | 200-800美元 | 文档跟不上版本 | 批量SERP、多地域排名 |
| GSC MCP(社区) | 展示、点击、覆盖率 | 中低(依赖个人维护) | 免费但限速严 | OAuth凭据管理坑多 | 自家站数据核对 |
| GA4 MCP(社区) | 事件、漏斗、用户路径 | 低(多版本互不兼容) | 免费 | 采样规则不透明 | 转化漏斗诊断 |
| Serpstat MCP | 关键词、域名分析、API批量 | 中(亚太节点延迟高) | 150-600美元 | 数据库覆盖不如Ahrefs | 中小站性价比首选 |
横评3个月得出的判断:
- 不要all-in一家:每家都有数据洞,关键词用Ahrefs但SERP抓取走DataForSEO,能把单一供应商风险降到最低
- 社区维护的MCP慎用于生产:GSC MCP换过3拨维护者,每换一次schema必变;GA4社区版本之间互相不兼容
- 季度切换计划要前置:Ahrefs和DataForSEO都有过单月接口大改的历史,团队Sprint规划里必须留出一个迁移窗口
10大场景按ROI重排:必做、审慎、避雷三梯队怎么分?
市面上MCP+SEO教程都是平铺10大场景,看起来好像每个场景都能跑。团队按实际客户ROI和失败率做过一轮三梯队排序,落地优先级差别很大:
第一梯队(必做,ROI高、失败率低)
- 关键词研究:只读、错了影响小、批量处理收益明显,月省10-30人天
- 内容审计(只读模式):找出薄弱页、低EAT页、缺Schema页,输出修复清单不直接动数据
- 排名监控+异常告警:定时跑、有数据沉淀、人工决策闸口在
第二梯队(审慎,ROI高但需要强护栏)
- 内容创作辅助:MCP出大纲+数据,人写正文,全自动写出来的稿件E-E-A-T信号会掉
- 竞品深度分析:定期跑可以,但要警惕Claude基于不完整数据下结论
- 报表合并:GSC+GA4+Ahrefs整合周报,省时但要校验数据对齐
第三梯队(避雷,看起来好但反噬大)
- 自动外链建设:Claude生成的outreach邮件被识别为AI批量后整个域名进黑名单
- 自动技术SEO修复:直接改canonical、hreflang、robots是高危操作,前面90 URL误删就是教训
- 自动发布:内容质量稳定性不够,Google对全AI内容站点的降权信号已经成熟
- 自动Schema批量注入:错误Schema会触发结构化数据警告影响整站信任分
这套三梯队的判断标准其实只有两条:错了能不能秒回滚和错了下游能不能截止。第一梯队两条都满足,第二梯队需要人工闸口截住,第三梯队两条都不满足——所以团队基本拒绝把第三梯队交给Agent。
关键词研究指令工程5大反模式(含真实指令对照)
同样的MCP服务端,指令写法不一样产出质量能差10倍。团队过去一年踩过的5个反模式:
反模式1:含糊指令烧钱
反例:用Ahrefs查PET包装相关关键词,输出有商业价值的Top列表
正例:用Ahrefs MCP的keywords_explorer工具,搜索词包含PET packaging(精确匹配),返回search_volume≥500且kd≤30的英文关键词,按cpc降序取前30条,每条带intent字段(informational/commercial/transactional),输出CSV格式
含糊指令让Claude自己猜参数,往往拉一万条全量数据再筛——token账单飞起。精确指令把过滤条件前置到MCP调用层,token消耗能降到原来的1/8。
反模式2:单步指令塞过多任务
反例:查关键词、分析竞品、写大纲、给出内链建议、估算流量
正例:拆成5步串行,每步独立指令,中间结果写到临时变量,下一步显式引用
单步塞5个任务,Claude会在中间环节走神,把关键词分析的结果当成竞品分析继续推,最后输出张冠李戴。拆步骤虽然慢一点但准确率提升一个量级。
反模式3:缺少负向约束
只说要什么不说不要什么,模型会自由发挥。例:查关键词Top30没说要不要含品牌词、要不要含问答词、要不要含色情词。加上不含我方品牌词、不含成人内容、不含竞品名这种负向约束能把输出可控性提升50%以上。
反模式4:没有失败回退策略
MCP调用失败(超时、配额耗尽、schema变更)是常态,指令模板里要写明如果工具A返回空,转用工具B或如果连续3次失败,停止并返回错误日志。没有回退策略的指令一旦失败就会进入死循环或者吐空结果,团队还得人工排查。
反模式5:把Claude当真理机
关键词研究最忌讳的指令是给出最有价值的Top10——什么叫最有价值?模型用什么标准判断?这是把判断责任交给模型。正确做法是把价值定义喂给模型:价值=月搜索量×平均CPC÷(KD+10),按此公式排序。
权限失控复盘:东南亚美妆DTC怎么删错90个URL
前面提到过这个案例,这里展开复盘整个事件链条,给所有用MCP的同行做防雷。
时间线:
- Day 1 10:42 — 团队在Claude Desktop里跑指令找出所有30天无展示的孤岛页并清理,Claude调用GSC MCP拉数据
- Day 1 10:51 — Claude识别出112个候选页面,调用站内CMS MCP批量打orphan标签
- Day 1 10:58 — 下游cron任务读orphan标签,把这112个页面统一加noindex meta
- Day 1 11:14 — 当晚团队下班,没有人工复核
- Day 4 09:30 — 客户反馈某新品系列流量异常下跌,排查发现90个误判页
- Day 4 11:00 — 团队紧急去除noindex,但Google重新抓取需要7-14天
- Day 18 — 流量基本恢复,但客户对自动化的信任跌到冰点
这件事的根因有三层,全部都跟权限有关:
第一层:MCP写权限给得太宽。CMS MCP的batch_tag工具被授予了无范围限制的cms:write scope。修复后的scope是cms:write:tag:read_only_orphan——只能打orphan标签且必须先经过双源对账,其他CMS操作一律拒绝。
第二层:下游cron盲信上游标签。cron任务里要加一道闸:如果当批次orphan标签数量超过日常基线的3倍,自动暂停并发告警。这条规则就能拦住112个的异常批次(日常基线是10-15个/天)。
第三层:没有人工复核闸口。任何会动noindex/canonical/robots的批量操作都要有人按钮才能下发。这条规则现在写在团队的MCP操作章程里,工程师签名才能上线新自动化流程。
修复完一整套护栏后这家客户的MCP工作流到现在还在跑,但是慢了——单次审计从原来的6分钟变成了18分钟。这是必须接受的代价:自动化的速度优势必须在能秒回滚的前提下才能享受。
调用成本失控:月账单从600飙到4800美元怎么扛回去?
2025年Q1团队拿了一个北美户外品牌的MCP+SEO项目,第一个月跑下来Anthropic账单600美元,老板觉得能接受;第三个月账单飙到4800美元,老板找团队负责人喝咖啡。复盘发现成本失控的原因是叠加效应,单看每条都不大:
- 关键词监控从每天1次提到每小时1次,token消耗×24
- 每次监控都跑全量关键词(1.2万词),没做增量diff,token消耗×3-5
- Claude被指令详细解释每个排名变化原因,每条变化输出500词解释,token消耗×8
- 调用Ahrefs MCP拉历史趋势没限定时间窗,默认拉365天,token消耗×12
叠在一起就是原始消耗的几百倍。修复方法:
- 监控频率回到每天2次(早晚各一次),每小时只用于关键大促窗口
- 增量diff:只把排名变化≥5位的词送进Claude推理,其余跳过
- 解释模板从500词压到80词,只输出原因码+建议码,详细分析按需展开
- 历史趋势限定30天窗口,跨季对比单独指令
这4条改完账单回到1100美元,准确性几乎没下降——因为80%的成本花在20%的低价值动作上,砍掉低价值动作总成本断崖式下降。这跟SEO本身的长尾分布规律一样,MCP调用也遵循80/20。
AI自动化反噬E-E-A-T?Google怎么识别全AI内容
这是2025年下半年团队最关注的趋势。Google官方虽然反复声明不歧视AI内容,但一线观察是:纯AI生成、无人类编辑痕迹的内容站点在2025年Q2-Q3明显流量下行。一个客户的SEO团队全员用MCP自动产稿,3个月发了400篇,第4个月开始整站排名滑坡,6个月后核心词全部跌出前30。
Google可能用的几个识别信号:
- 发布节奏:每日固定时间发布、字数高度一致、内链密度公式化
- 语言特征:句式重复模式、过渡词使用频率、专业术语密度异常均匀
- 话题覆盖广度:短期内突然扩展到与历史主题无关的领域
- 外部信号缺失:没有自然产生的反链、社交分享、品牌词搜索
- 事实错误模式:日期、数字、引用源出现典型AI幻觉错误
团队现在对客户的硬规则是:MCP辅助不替代人类作者。MCP可以做关键词、出大纲、做数据图表、查事实,但正文段落必须有人类作者署名且实际编辑过——哪怕只是把AI初稿读一遍改几句。这条规则牺牲了一些速度,但保住了E-E-A-T信号链。
更深层的问题是:当所有人都用MCP产内容,差异化只剩下亲历经验。这也是这一年来写作越来越强调field notes、失败案例、客户真实数据的原因——这部分内容LLM训不到,是天然的护城河。
MCP改写SEO团队配置:工程师比例会倒挂到什么程度?
过去SEO团队的人员配置大致是:内容3人、运营2人、技术1人(兼职),10人团队里只有1个工程师。MCP铺开后这个比例正在倒挂。
团队2024年初的配置是1工程师/9运营,2025年底变成3工程师/5运营/2内容。变化驱动力有三层:
- MCP指令工程是工程岗活:写好的MCP prompt模板比写代码门槛低、但比写文案门槛高,需要工程思维+SEO直觉
- 护栏与监控需要持续维护:前面所有踩坑案例的修复方案都是工程化措施,需要工程师写脚本、配监控、做回滚预案
- 批量处理替代了大量重复运营动作:过去1个运营每天审300页内链,现在MCP一上午跑完6000页,运营岗的需求下降
团队配置怎么调?给客户的建议是参考FDE(Forward Deployed Engineer)框架本地化——招一个懂SEO逻辑的工程师,让他在团队里做MCP工作流的owner,运营岗转型成结果验收+异常排查角色。这个转型不容易,但2026年不动手就会被动。
中小站vs企业站MCP落地优先级:ROI临界点在哪?
不是所有站都该现在上MCP。团队过去半年评估过30多家客户,给出的临界点建议是:
| 站点规模 | 月SEO预算 | 是否建议上MCP | 优先场景 | 预期ROI |
|---|---|---|---|---|
| 新站(<100页) | <1000美元 | 不建议 | —— | 负ROI,工具学习成本高 |
| 小型站(100-500页) | 1000-3000美元 | 谨慎试点 | 关键词研究 | 3-6个月回本 |
| 中型站(500-5000页) | 3000-10000美元 | 推荐 | 关键词+内容审计+排名监控 | 2-4个月回本 |
| 大型站(>5000页) | >10000美元 | 必上 | 全梯队第一二档 | 1-2个月回本,可省3-5人编制 |
| 多语言站(>3语种) | 视规模 | 必上 | 跨语言关键词+本地化审计 | 1-3个月回本 |
判断标准是规模效益临界点:当人工成本×场景频次×重复度>MCP工具成本+学习成本+维护成本时,上MCP才划算。新站这个公式左边很小,右边却包含一次性的高学习成本,所以负ROI;大型站左边规模化放大,右边边际不变,ROI快速正转。
4套客户实测可复制配方
过去12个月落地下来的4套配方,对应不同业务形态:
配方A:北美户外品牌DTC的关键词研究流水线
每周一上午自动跑:拉GSC过去7天impression≥100的query → 调Ahrefs MCP查搜索量与KD → 过滤掉已布局的词 → 输出新词清单按机会分排序 → 团队周会决策选20个进下一轮内容排期。这套跑下来运营岗每周省8-12小时,新词收录从月均40个提到200多个。这里关键不是数字本身——是这个工作流让运营从手动翻GSC变成聚焦决策,岗位价值密度提升才是真正的副产物。
配方B:中东B2B工业品3C的多语言竞品监控
每天早上跑:拉5家竞品在阿语、英语、土耳其语市场的Top页面 → 对比昨天的快照 → 输出新增页面、删除页面、价格变化、Schema变化4类diff报告 → 异常变化推送企微告警。这套跑了半年帮客户提前7天发现对手某条线降价12%,团队及时跟调避免了一个Q的市场份额损失。
配方C:日本宠物DTC的CMO周报自动化
周日晚上跑:GSC+GA4+Ahrefs三家数据合并 → Claude生成3层报告(核心指标摘要、品类拆解、异常事件解释) → 自动渲染成PDF邮件给CMO。原本SEO负责人每周六耗6小时整理的报告,现在20分钟跑完,省下来的时间花在解读和决策上。CMO的反馈是报告变薄了但有用了——因为人类负责人不再当数据搬运工。
配方D:东南亚美妆DTC的内容审计(前面教训之后的版本)
每月跑一次:MCP拉所有页面 → 双源对账(GSC内链 + 站内Sitemap)→ 标记薄内容、缺Schema、低EAT页 → 输出修复清单(不直接动数据库)→ 人工Review后批量分发给内容团队。这套替代了原来18人天的人工审计,现在4人天就能完成,关键是不会再删错90个URL——所有写操作都拦截在闸口外。
AI Agent自治化SEO的边界:什么任务永远不该交给Agent?
2025下半年Agent概念被推到风口,6大AI协议矩阵把Agentic Web的图景画得很大。团队思考过什么任务能交给Agent、什么不能,结论是有4类任务永远不该交:
- 策略决策类:是否进入某个新市场、是否舍弃某条产品线、是否大改信息架构——这些决定影响半年以上业务走向,Agent的数据视野是过去的,没有未来洞察
- 品牌叙事类:品牌故事、价值主张、客户证言收集——这些是关系,不是任务,Agent能模仿但代替不了真实人与人的连接
- 合规判断类:GDPR/CCPA/数据出境/行业特定规章——监管口径变化快,Agent训练数据滞后,合规要人最终拍板
- 危机处理类:负面舆情、Google算法巨震、域名信任危机——非常规事件,Agent没经验
能交给Agent的是规则明确、错了能回滚、有重复性的任务。前面三梯队第一梯队的关键词研究、内容审计(只读)、排名监控基本属于这类。其他都要人在闭环里。
这也是反复强调不要all-in自动化的原因——SEO的护城河越来越不在执行效率,而在判断质量+亲历经验+关系沉淀。这三样Agent抢不走,也不会被任何协议升级抢走。
保哥判断:未来12个月MCP+SEO会跑到哪一步?
基于12个月实测和对生态的观察,给出3个判断与1个建议:
判断1:MCP服务器会从泛工具走向垂直深度。第一波是Ahrefs、DataForSEO这种通用SEO工具MCP化,第二波会出现垂直MCP——比如独立站SEO专用MCP、B2B多语言专用MCP,深度大于广度。早期跟进垂直MCP的团队会有6-12个月的红利窗口。
判断2:MCP+RAG会成为内容生产的标配。纯AI内容E-E-A-T信号弱,但MCP接客户专有数据+RAG做事实校验的内容会有差异化优势——因为别人复制不了你的私域知识。DTC品牌AI工具栈12款实测这块已经看到苗头。
判断3:SEO工具厂商会洗牌出三类赢家。第一类是协议层赢家(最早把MCP做好做稳的工具);第二类是数据深度赢家(独家数据源没有替代);第三类是工作流赢家(不止提供MCP还提供整套n8n类工作流编排)。其余的会被边缘化。
建议:现在该做的不是all-in MCP,而是先建一支懂MCP的小团队。选1-2个第一梯队场景跑通、把护栏与回滚预案做扎实、再逐步扩到第二梯队。中小站可以等到2026年底再上,大型站不动手就在退步。
MCP到底该先接哪一个工具,才不会一上来就翻车?
补一个这一年反复被验证的落地判断:别一上来把能连的工具全连上,先接团队每天都在用、也最信任的那一个高价值源,通常是搜索或分析数据。从这一个源起步,把通路和产出质量都验证过一遍,再谈往外扩。一次连接、多处复用的价值,是在你确认第一个连接靠谱之后才谈得上的。
还有个容易被忽略的前提:MCP会放大你连给它的一切。分析口径本来就乱、报告本来就旧,接上AI之后,它只会更自信地把错误结论端到你面前——垃圾进不会变成聪明出,只会变成加倍自信的垃圾出。所以接入前先把数据源本身审一遍,比急着接更重要。数据还有个悄悄变坏的风险:今天对的源,可能过几周就过期,得让喂给AI的源按一个你信得过的节奏刷新,否则你会在某天基于一份早已失真的数据做决策而不自知。
提示词写成brief、再存成库,这两步为什么能决定MCP的产出上限?
MCP接通只是拿到了原料,产出好不好,很大程度取决于你怎么给指令。把提示词当成一份结构化的brief来写,而不是随口一问:明确说清品牌是谁、盯哪个市场、看哪个指标、要做的是什么决策,AI给出的东西才配得上你连进去的那些真实数据。一句我们该怎么办,换不来什么有用的回答。
更进一步,一条提示词跑通了、验证过确实好用,就把它存进团队的共享提示库,让做SEO、做内容、做公关、做产品的同事都能复用。这一步,才是MCP那句一次连接、多处受益真正兑现的地方——否则每个人都在重新摸索同一套指令,连接建得再好也浪费在了重复劳动上。
常见问题解答
问1:MCP和传统API有什么本质区别?
核心差异在能力发现机制和权限闭环。API需要中间层把OpenAPI翻译给LLM,MCP把能力描述内置进协议本身,Claude连上即可问你有什么工具。另外MCP规范要求每次工具调用都征得用户许可,权限粒度细到单个工具+单个scope,传统API Key做不到这种精细控制。
问2:中小站现在该不该上MCP?
新站(<100页、月预算<1000美元)不建议,学习成本与维护成本会吃掉所有收益。小型站可以从关键词研究一个场景开始试点,3-6个月评估ROI。中型站及以上推荐上,但要先建权限护栏。
问3:用MCP批量产内容会不会被Google降权?
纯AI、无人类编辑痕迹的内容站点在2025年Q2-Q3已经看到明显流量下行。保哥的硬规则是MCP辅助不替代人类作者——MCP可以出大纲、查事实、做数据,但正文必须有人类作者实际编辑过。
问4:MCP调用成本怎么控制不失控?
三条:精确指令前置过滤减少token消耗、做增量diff只把变化送进推理、解释模板压短只输出原因码。这3条改完能把月账单砍掉75%以上。
问5:哪些任务永远不该交给MCP/Agent自动化?
4类:策略决策(影响半年以上业务)、品牌叙事(关系不是任务)、合规判断(监管变化快)、危机处理(非常规事件)。能交的是规则明确、错了能回滚、有重复性的任务。
问6:MCP写操作怎么避免删错URL这种事?
三道闸:第一闸限scope(写权限要精细到具体动作),第二闸双源对账(任何写操作必须两个数据源都确认),第三闸人工Review(动noindex/canonical/robots的批量操作都要按钮才下发)。三闸合一基本能拦住所有看似合理但其实是幻觉的写操作。
问7:MCP服务器选哪家?
不要all-in一家。关键词用Ahrefs、SERP用DataForSEO、自家站数据用GSC社区MCP、中小站性价比用Serpstat。GA4社区MCP现阶段稳定性不够,慎用。
问8:MCP会不会让SEO团队失业?
不会让团队失业,但会改变团队配置。运营岗的数据搬运工作被替代,转型成结果验收+异常排查+决策角色。工程师占比会从原来的10%提到30-40%。最该担心的不是失业而是不转型就被淘汰。
权威参考资料
- Model Context Protocol官方规范 — 协议本身的工具调用、资源读取、提示词管理三层抽象
- Anthropic关于MCP的发布说明 — 生产环境权限分档、工具能力分类、客户端配置最佳实践
- Google Search Console API文档 — OAuth2凭据管理与GSC数据延迟说明
- Nielsen Norman Group关于AI协作的研究 — 高确定性低后果任务交给AI、低确定性高后果任务保留给人类的协作边界
- Ahrefs关于AI对SEO影响的研究合集 — 工具厂商视角的AI转型节奏
本文标题:《MCP+SEO实战12个月:保哥8类失败复盘与4套配方》
本文链接:https://zhangwenbao.com/mcp-protocol-seo-integration-field-notes.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0