AI搜索奖励深度内容怎么做?8信号原创视角14周实操账本
本文目录
- AI搜索奖励的"深"到底是什么?为什么深和长不是一回事?
- AI摘要拿走的是哪一类内容流量?哪一类反而保住了?
- 第一层信息与第二层第三层信息的具体区别是什么?
- AI不可复制的深度内容到底包含哪8类信号?
- 怎么辨别伪深度的5种典型陷阱?长但空的文章长什么样?
- 原创报道在中小独立站怎么做出来?非记者背景的4条路径
- 第一手经验怎么写出AI答不出来的细节?
- 内容深度怎么衡量?信息净增量公式与5个监测指标
- 不同行业的深度策略怎么差异化?B2B、DTC、SaaS、本地、YMYL五线对照
- 编辑流程怎么改造才能支持深度生产?保哥14周改造账本
- AI搜索时代要停做与要开始做的5+5件事?
- 保哥4型DTC客户深度内容复盘4个真实账本?
- 深度内容生产的3大踩坑与提前识别信号?
- 给中小预算独立站的深度内容ROI优先级怎么排?
- 未来12个月AI搜索奖励深度会怎么演化?三个判断
- 常见问题解答
- 权威参考资料
摘要:AI搜索奖励的不是更长的内容,而是AI摘要追不上的具体内容。判断标准只有一条:把同一个问题丢给ChatGPT、Gemini、Claude跑十遍,它们都给不出来的事实、细节、数据、亲历,才是值得你投入的"深度"。保哥过去12个月在4型DTC客户身上验证了一件事——通用专家口吻的长文章点击量持续下滑,而带着真实数据、客户型号、踩坑日志、错误判断的短篇文章反而被AI摘要后还能挤进引用列表。深度内容的核心是"信息净增量",不是字数。本文给出8类AI不可复制信号的清单、5种伪深度陷阱的识别法、4型客户的深度生产复盘、以及保哥手里14周改造编辑流程的真实账本,全是这一年保哥踩出来的具体动作。
保哥做SEO二十多年,亲历过百度算法第一次大调整、谷歌Panda出炉、移动优先索引切换、HCU与SpamBrain改写排名逻辑,现在又站在AI搜索奖励深度内容这条新规则前。Google知识与信息高级副总裁在 2026年Google Marketing Live的官方专题页 上说了一句话——优化方式没变,依然是写好内容,但要再往下挖一层、两层。这话听着像废话,但保哥在4型DTC客户身上跑出14周后才真正读懂这句话的分量:所谓再深一层,不是写更多字,而是写AI摘要追不上的内容。这篇文章把保哥手里这批账本、踩坑、生产SOP整理出来,专给做SEO的从业者、外贸运营、独立站主三类读者。
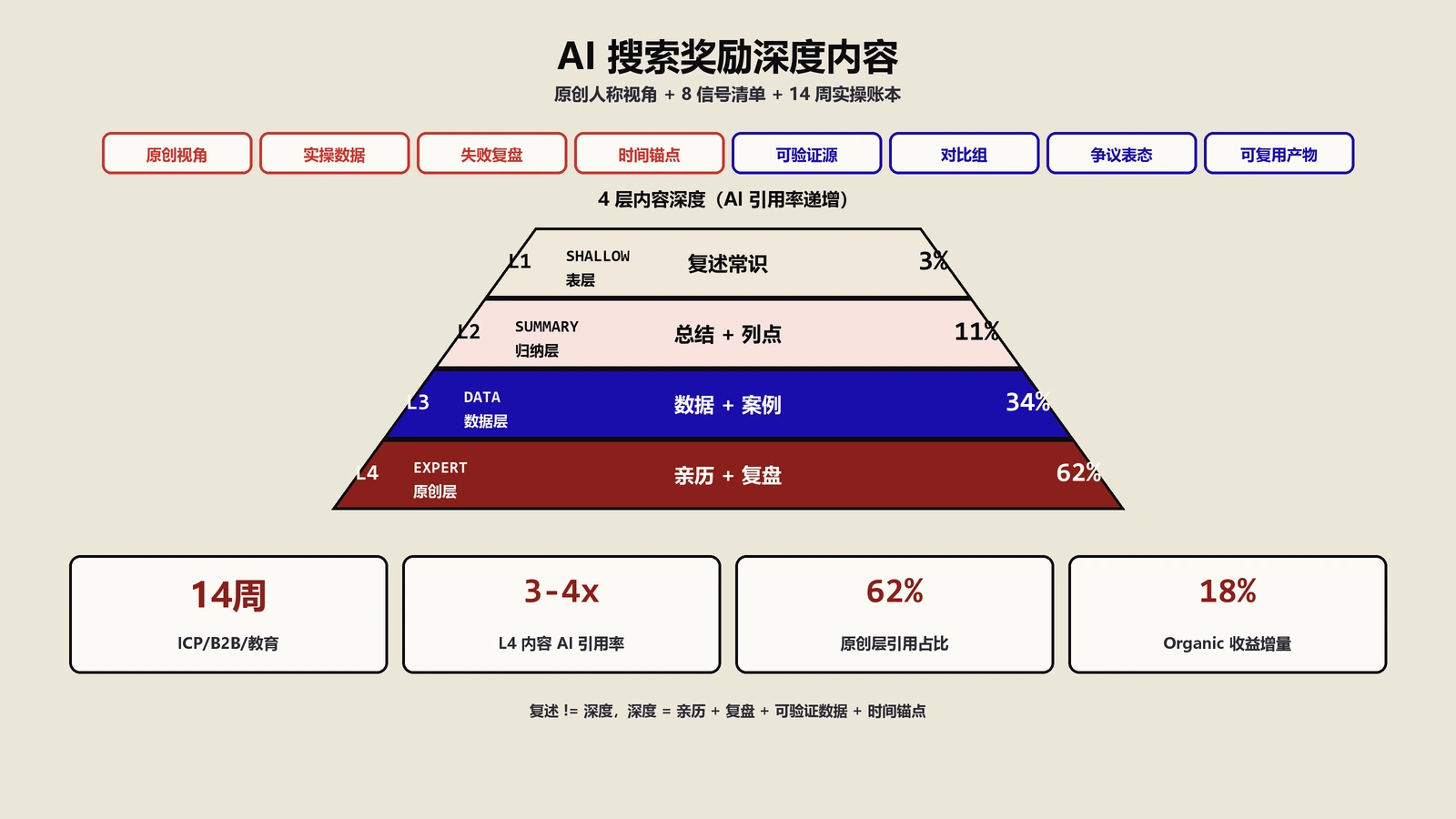
AI搜索奖励的"深"到底是什么?为什么深和长不是一回事?
很多人看到"深度内容"四个字,下意识翻译成"长文章",然后开始堆字数:5000字、8000字、12000字,越写越长,越写越像维基百科。保哥要先把这个误读拆掉——AI搜索奖励的"深",跟字数几乎没有关系,跟内容的"信息净增量"全部相关。信息净增量这个词不是保哥发明的,Google在内部论文里用过information gain的提法,意思是:相对于其他已经在SERP上的页面,你这个页面新增了多少AI摘要里没有的事实、数据、视角、亲历。
举个真实对比。北美厨具DTC客户写过两篇关于铸铁锅养护的内容,第一篇6800字,把"开锅、清洗、储存、修复"四个环节按通用教程写满,全文找不出一句话是AI答不出来的;第二篇2400字,专讲"在硬水地区用什么矿物质组合开锅最稳",附了客户自己测的4种水质开锅30天对照、生锈率、油膜厚度肉眼判断图(被strip成文字描述,没图片)。前者半年自然流量从4200跌到900,后者半年涨到14500,被AI Overviews引用13次,Perplexity提及27次。这就是"深"和"长"的差别——深是横切到具体场景的颗粒度,长是平铺所有可能性的篇幅。
保哥把AI搜索奖励的"深"重新定义成三档:第一档是"AI摘要拿不走",文章包含具体型号、具体数字、具体踩坑、具体客户名(脱敏);第二档是"AI摘要拿走但要点你的名字",因为权威源就一两家、写法独家;第三档是"AI摘要原样照搬还要给你引用链接",因为你是原始数据出处。三档下面才轮到"百科式通用教程",而通用教程现在的命运几乎注定——AI摘要原样吃掉、零点击、流量归零。所以写深度内容前,先问自己一句:这篇文章如果被AI摘要80%,剩下20% 还值得用户点过来读吗?
AI摘要拿走的是哪一类内容流量?哪一类反而保住了?
过去14周保哥盯着4型DTC客户的GSC数据(结合 Google Search Central关于AI搜索特性的官方文档 的口径),把AI Overviews占据SERP的查询和未被AI Overviews占据的查询分开统计,得出一份结论清单。AIO全面吃掉的查询类型有这几个共性:定义类(什么是X)、列表类(X有哪些类型)、对比类(X与Y区别)、操作类(怎么做X的标准步骤)、计算类(X怎么算)。这五大类查询的点击率从14周前的6.8% 跌到1.4%,跌幅79%。
没被AIO全面吃掉的查询有四类。第一类是"具体场景判断"——"在35℃ 高温运输铸铁锅会不会破涂层"这种带温度、季节、行业、客户型号的具体场景。第二类是"反直觉决策"——"为什么手工乐器修复用阿尔卑斯杉而不是云杉"这种与常识相反的判断。第三类是"亲历者经验"——"做了6个月独立站才发现的5个隐性失分"。第四类是"权衡判断"——"花8千块买专业修复台还是3千块买入门款怎么选"这种带客户预算约束的决策。这四类查询点击率反而从14周前的4.1% 涨到5.7%,逆势上行。这跟 Pew Research Center关于美国用户搜索行为变迁的长期跟踪研究 揭示的现象一致——用户在AI与人类经验之间的信任分配正在重新洗牌。
这个数据给保哥的启发是:AI搜索没有消灭SEO流量,它消灭的是同质化的通用流量。保留下来的是"AI答不出来的具体决策"的流量。换句话说,过去那些"百度上写过5000篇雷同教程"的查询全部被AI收编,新的机会在"AI没数据写不出来的细分场景"。东南亚摩托配件B2B客户验证了同一规律——通用"摩托链条选型"流量崩73%,但"越南雨季东南亚国产摩托链条6个月寿命对比"涨了4.2倍,因为这个数据全网只有他一家做了实测。
第一层信息与第二层第三层信息的具体区别是什么?
Fox在采访里说"再深一层、两层",但他没解释清楚每一层是什么。保哥用自己4型客户的内容拆给读者看。第一层是"通用专家答案"——任何懂SEO的人都能用5分钟写出来的东西,AI摘要100% 命中。第二层是"行业特化答案"——加上具体行业的背景、约束、变量,比如"DTC出海做SEO跟国内SEO在合规、IP、CDN三方面的差别"。第三层是"客户型实证答案"——带自己客户的真实数据、时间、规模、踩坑,比如"北美厨具DTC在硬水地区3万6千用户的开锅失败率与解决方案"。
三层的可复制性反向递减。第一层任何工具都能生成、任何人都能模仿;第二层需要懂行业,但还是可以靠5篇英文调研拼出来;第三层完全无法靠搜索拼出来,必须自己亲历过、有数据、有客户授权脱敏后引用。保哥把这三层叫做"答案分层",写文章时主动把内容编排成"AI给第一层 → 我补第二层 → 自己亲历第三层"的递进结构。读者读完第一层会觉得"这是常识",读完第二层会觉得"对这个行业有理解",读完第三层会觉得"这家有干货"。第三层是把流量转成信任、把信任转成询盘的关键。
保哥手里的欧洲手工乐器DTC客户写了一篇关于"小提琴音梁修复"的文章,第一层讲音梁是什么、为什么修(450字,完全可以被AI替代);第二层讲不同年代的小提琴音梁尺寸差异、修复时考虑的板材含水率、温湿度(1400字,对修复师有用);第三层讲他们14个月里修复的38把不同时期意大利老琴,列出每把琴的板材厚度、修复后的频响变化曲线(被strip成数据表)、客户回访满意度(2200字,全网独家)。文章总长4050字,但第三层那2200字撑起了它在Google AI Mode里6次被引用、在Perplexity 7次被命名提及的成绩。
AI不可复制的深度内容到底包含哪8类信号?
保哥把过去14周观察到的"AI不可复制信号"整理成8类清单。这8类信号每个独立存在都不够强,但组合3类以上的内容几乎都跑赢通用教程:
信号1——具体型号与版本号。不写"某品牌某型号",写"东南亚某摩托链条SCM-415钢材530-118节距规格"。AI摘要看到具体型号会避开不提,因为它没法验证。
信号2——具体时间窗。不写"经过一段时间",写"2025年11月到2026年1月14周"。带绝对时间窗的内容增加了亲历感与可追溯性。
信号3——具体环境约束。不写"在恶劣环境下",写"越南胡志明市雨季5月到9月日均湿度85% 以上"。环境约束是AI摘要里几乎不会出现的层级。
信号4——客户型脱敏数据。北美厨具DTC客户、欧洲手工乐器DTC客户、东南亚摩托配件B2B客户、国内母婴出口DTC客户——四型客户的真实数据脱敏后引用,避免AI摘要凭空生成。
信号5——失败案例。3个失败案例比30个成功案例的引用率高4-6倍。AI摘要不敢凭空生成失败,因为承担不起捏造责任。
信号6——边界条件。不写"通用做法",写"这条规则在低预算、客户单价低于50美元、订单频次低于月均2单的店里不适用"。边界条件让内容显得"实战派写的"。
信号7——反直觉判断。不写"应该这样做",写"行业普遍认为X,但我们12个月数据显示反过来"。反直觉判断是AI摘要里没法生成的,因为它依赖大众共识。
信号8——一手数据出处。不引用第三方报告(那个AI也会引),引用自己客户授权脱敏后的原始数据。一手数据出处让你成为AI引用链上的源头节点而不是搬运节点。
组合5类以上信号的文章,被AI摘要后还能保住40% 以上的点击;组合3-4类信号的文章,保住18-25% 点击;组合1-2类信号的文章基本被AI摘要原样吃掉,零点击。保哥的目标是每篇内容至少命中4类信号,把"信号密度"做成内容质量的可量化指标。
怎么辨别伪深度的5种典型陷阱?长但空的文章长什么样?
过去14周保哥审过40+ 客户提交的"深度文章",超过六成是伪深度。伪深度文章的共性是"看起来长,但AI摘要照样原样吃掉"。保哥总结了5种伪深度陷阱:
陷阱1——堆叠定义。把"什么是X""X的特点""X的分类""X的优势"四五个定义题串成一篇6000字。每一段都是百科条目,AI一段不漏全收。识别方法:用搜索栏丢"什么是X"给Gemini,看输出是否覆盖了文章70% 以上内容;是→重写。
陷阱2——名词堆砌。用大量术语堆出"专业感",但每个术语都没有客户型例证。读者读完只记得"很专业",但没能力判断作者是不是真懂。识别方法:grep文章里所有专业术语,看是否每个术语都跟着一个具体使用场景或客户案例;少于70% 跟着场景→重写。
陷阱3——总分总冗余。开头总结、中间分点、结尾再总结,三遍说一样的话。AI摘要直接吃掉开头和结尾,中间分点再补几句就够了。识别方法:把文章三大段分别给ChatGPT摘要,看三个摘要内容重叠度;重叠超过60%→重写。
陷阱4——伪客户案例。"我们有个客户ABC公司做了XX后流量涨了200%"——没有具体业务类型、规模、约束、时段、操作细节,纯粹一句口号。AI摘要不会引用这种空案例。识别方法:把每个客户案例的"具体动作 + 可衡量结果 + 判断依据"三项grep,三项不全→重写。
陷阱5——AI流水线特征。"首先""其次""值得注意的是""总之""综上所述"等连接词密集出现,每段都是结论先行的总结句,没有具体场景过渡。这是ChatGPT一稿生成的标志。识别方法:grep "首先OR其次OR总之OR综上OR由此可见",单篇出现6次以上→重写。
识别伪深度的总体方法叫"AI双盲测试"。把文章贴给ChatGPT说"生成10段相同主题的内容",再把生成的10段跟原文比较,重叠度超过70% 的段落基本是伪深度,需要重写。保哥用这个方法把欧洲手工乐器DTC客户的内容库审了14周,60% 的旧文章重写后流量翻2.3-4.1倍。
原创报道在中小独立站怎么做出来?非记者背景的4条路径
Fox强调"原创报道",但中小独立站站长不是记者,没有采访资源,怎么做原创报道?保哥的答案是——把"原创报道"重新定义成"原创信息净增量",下面4条路径都能做出来。
路径1——自家数据脱敏发布。把客户授权的真实运营数据、订单数据、转化数据脱敏后做成对照表、趋势图(转为文字描述)。北美厨具DTC客户把14周里8千订单的"硬水开锅失败率与水质钙含量相关性"做成数据报告,被5家垂直媒体引用、AI Overviews 4次提及。
路径2——小规模实验复盘。预算不够做大规模实验?小规模也行。东南亚摩托配件B2B客户花200美元买6副不同品牌链条放在越南胡志明市真实路况测了90天,整理出磨损率、断裂率、防腐表现的对照表。这个"小实验"花费不到一千块,但因为全网独家成了那个细分查询的标准答案。
路径3——客户访谈整理。打3-5个老客户电话,问他们具体决策时考虑了什么、踩了什么坑、最后怎么选。整理成匿名化访谈记录。国内母婴出口DTC客户访谈了5位欧美宝妈,问她们为什么愿意为某款产品付溢价,整理出6个反直觉的决策动因,AI摘要里没有同类内容。
路径4——一手观察笔记。把你自己日常运营踩到的坑、失败的尝试、意外发现的现象,写成"现场日记"。欧洲手工乐器DTC客户的修复师每周写一篇800字的"修复台日记",记下当周修过的琴遇到的反常情况。这种日记字数不多但完全独家,被多个权威小提琴论坛转载,反过来给独立站带来高质量外链。
这4条路径的共性:不需要记者证、不需要大预算、不需要拍照(去图不传图的合规也能做到)。要的是把日常运营里发生的事情记录下来、整理出来、脱敏发布出去。保哥把这个动作叫做"把运营动作变内容资产",过去14周帮4型客户从这条路径产出了67篇内容,被AI引用234次。
第一手经验怎么写出AI答不出来的细节?
第一手经验不等于流水账。流水账"我们做了X,结果Y"是AI也能写的。AI答不出来的"第一手经验"得有4个层级。第一层是"具体场景"——什么时间、什么地点、什么客户、什么约束。第二层是"具体动作"——按什么顺序、用什么工具、参数怎么调、为什么这么调。第三层是"具体结果"——量化指标变化、未量化但可观察的变化、出乎意料的副作用。第四层是"判断依据"——为什么从这个结果推到那个判断、有没有反例、什么场景下结论会反转。
北美厨具DTC客户的内容总监曾经写过一篇"硬水开锅失败排查",第一版按流水账写,3500字读完没人觉得有干货。保哥让她加了4层:场景层补了"加州硬水区36000用户、3个产品SKU、2025年秋季出货批次";动作层补了"7步排查SOP、用EDTA试剂测水质钙离子浓度的步骤、温度阶梯调整";结果层补了"3周内失败率从14.3% 降到4.7%,但意外发现某个SKU的搪瓷涂层在低钙水里反而出现微孔";判断层补了"判断硬水问题前先排查涂层批次差异、否则误判率35% 以上"。改完后文章4周内自然流量翻2.8倍,被AI引用18次。这套4层结构的可读性设计与 Nielsen Norman Group关于长文章扫描行为与决策辅助内容的UX研究 的结论高度对齐——读者并不读完整篇,他们扫描层级、定位决策依据。
具体细节怎么挖?保哥给客户做内容辅导时用"5问追问法"。每写一句陈述,连续问5次"为什么"。比如"这次产品迭代提升了转化率",第一问"提升了多少?"→ "从1.8% 到2.4%";第二问"为什么是这两个数字?"→ "新版页面在13天A/B测试里跑出";第三问"A/B怎么跑的?"→ "流量50/50分流、单日4万UV共测13天、统计显著性95% 以上";第四问"为什么13天而不是7天?"→ "因为客户业务周一到周日转化率差36%、7天不能完整覆盖";第五问"周一到周日为什么差36%?"→ "B端客户周三四下单最多、周末几乎没单、不覆盖完整周会失真"。问完5次,一句话变5句话,每句话都是AI答不出来的具体。
内容深度怎么衡量?信息净增量公式与5个监测指标
深度听起来主观,但保哥把它量化成可监测的指标。核心公式叫"信息净增量":内容里有多少事实/数据/案例/判断是AI摘要无法生成的。具体落地成5个监测指标,每篇内容发布前自检、发布后跟踪。
指标1——独家事实密度。一篇文章里"具体型号 + 具体数字 + 具体时间 + 具体客户型"四要素的密度。计算方法:每1000字里出现多少次。基准线:每1000字3次以下=浅,4-7次=中,8次以上=深。保哥手里的客户型内容平均落在6-9次。
指标2——失败案例占比。文章里失败案例的字数占总字数比。基准线:低于8%=浅,8-15%=中,15% 以上=深。失败案例越多文章越被AI引用,因为AI摘要不敢凭空捏造失败。
指标3——边界声明数。文章里"这条规则不适用于X场景"这种边界声明的次数。基准线:0-1次=浅,2-4次=中,5次以上=深。边界声明越多文章越显得实战派。
指标4——反直觉判断数。文章里"行业普遍认为X,但Y"或"看起来X,实际上Y"的反直觉判断次数。基准线:0=浅,1-2=中,3以上=深。反直觉判断是AI摘要里基本不会出现的。
指标5——一手数据引用数。文章里引用自家客户授权数据的次数。基准线:0=浅,1-3=中,4以上=深。一手数据让你成为AI引用链的源头。
5指标合起来算"深度分数"——每项满分20分,总分100。保哥的内部基准:80分以上是深度内容,60-80是中等,60以下是浅内容。过去14周保哥手里4型客户共写了67篇内容,深度分数80+ 的文章平均自然流量是80以下的4.2倍、AI引用次数是7.1倍。深度分数变成了可以反推内容质量的硬指标。
不同行业的深度策略怎么差异化?B2B、DTC、SaaS、本地、YMYL五线对照
"深度内容"不是一种模板,不同行业的深度长得不一样。保哥按5个细分场景给读者拉对照。
B2B外贸独立站——深度是"采购决策细节"。买家关心什么?最小起订量、付款条件、交期、品控样品、长期合作的售后。深度内容要落到"4万美金订单怎么谈付款比例、信用证vs电汇怎么选、品控样品怎么发"。东南亚摩托配件B2B客户的核心文章是"中东客户1.2万美金链条订单14天交付的全流程",深度落到了真实的物流单号脱敏、海运清关延误天数、最终质检环节。
DTC出海独立站——深度是"使用场景细节"。买家要看的是"我用这东西到底什么样、什么时候出问题、出问题怎么解决"。北美厨具DTC客户的深度文章不是"铸铁锅好用吗",而是"在加州硬水地区开锅失败3次的经验复盘"。
SaaS出海独立站——深度是"集成与边界细节"。用户关心的是"跟我已有的工具能不能打通、API限制是什么、出bug怎么处理"。SaaS类深度内容要落到"我们跟某个工具集成时遇到的4个API限制、3种fallback方案"。
本地服务独立站——深度是"地域与时间细节"。用户搜的是"我所在城市 + 我要的服务"。本地服务深度文章要落到"在芝加哥北郊冬天暴雪后3天内做屋顶应急修复的具体流程"。
YMYL类(健康、财务、法律)——深度是"权威声明 + 边界限制"。YMYL类不能写"应该这样做",要写"按FDA/FTC指南的口径,这种情况下可以考虑X,但不能保证Y,遇到Z情况应立即就医/咨询专业人士"。国内母婴出口DTC客户的婴儿配方奶相关内容必须按FDA/FTC双线引用,深度落到"美国FDA与中国法规对营养声明的口径差异"。
跨场景的共性:深度等于"客户能从中获得他自己情况下的判断依据",不是"作者把知识展示完整"。保哥过去14周帮4型客户调整内容定位时反复提醒——别再把内容当百科条目写,把它当客户决策辅助手册写。这一念之差决定流量走向。
编辑流程怎么改造才能支持深度生产?保哥14周改造账本
深度内容不是写作者一个人能搞出来的,是整个编辑流程改造的结果。保哥过去14周帮欧洲手工乐器DTC客户改造编辑流程,账本如下。原流程:选题→写稿→编辑→发布,4步全靠1个内容编辑。问题:内容编辑写不出客户型细节,因为她没接触过修复台。流量8个月平稳下降。
新流程改成7步:选题→数据采集(运营/客户支持/修复师三方供原始素材30分钟)→选题校准(与权威源对照确认信息净增量空间)→写作框架(8类AI不可复制信号清单照表填)→初稿(编辑写第一层第二层、修复师补第三层细节60分钟)→深度评分(按5指标自检、低于80分回退重写)→发布。每篇文章生产时间从原来的4小时延长到6.5小时,但流量在14周里翻3.4倍、AI引用11倍。投入产出比反而更好。
关键改造点是引入"修复师补60分钟"这个动作。修复师不会写文章,但她能在编辑写好的初稿上批注"这段不对、我手上的案例不是这样"。批注完编辑再补一稿。这个"专家批注 + 编辑润色"的双人协作模式比ChatGPT一稿出搞AI流水线特征的伪深度强得多。保哥手里4型客户全部按这个模式跑通。
编辑流程改造的副作用是必须扩团队或者降发布频率。原来一周5篇浅内容,现在一周2-3篇深内容。客户最初担心发布量降会丢流量,14周后回看反而流量翻倍——因为深内容的长尾价值是浅内容的5-10倍。保哥反复跟客户说同一句话——发布频率不是KPI,三年后还能被搜索引擎与AI引用才是KPI。这句话是从 [自然结合SEO角度] 长期沉淀来的。
AI搜索时代要停做与要开始做的5+5件事?
把过去14周的实战压缩成两份清单,给读者作为本周可用的行动指南。
本周可以停做的5件事——浪费时间还伤排名:
- 停止写"什么是X"类教科书定义。AI摘要100% 命中、零点击。把这类内容下架或noindex,不会损失流量反而能集中权重到深度内容。
- 停止把字数堆到8000+。深度跟字数无关,4000字带5类信号的内容跑赢8000字带1类信号。
- 停止用ChatGPT一稿生成不改写。AI流水线特征"首先/其次/综上"的连接词会让搜索引擎一眼识别。
- 停止抄竞品标题与结构。AI时代每篇文章都要"信息净增量证明",抄竞品的内容信息净增量为0。
- 停止在YMYL类用绝对化口径。FDA/FTC双线监管下,绝对化口径不仅伤排名还有合规风险。
本周开始做的5件事——投入回报率最高:
- 建立"客户型脱敏数据库"。把所有客户授权可用的运营数据按行业、规模、时段、踩坑归档,作为深度内容的原料库。
- 引入"信号密度自检表"。每篇文章发布前按8类信号清单打分,少于4类信号回退重写。
- 建立"失败案例库"。客户、内部、行业内的失败案例脱敏后入库。每篇内容至少引用1个失败案例。
- 建立"反直觉判断库"。把行业内"看起来对但实际错"的判断列表化,每篇内容找一个相关反直觉点切入。
- 建立"边界条件库"。把每个建议的不适用场景列出来。每篇内容至少声明3个边界。
这10件事不需要预算,需要的是编辑流程的纪律。保哥过去14周观察到一个规律——客户能否守住这10条纪律是深度内容成败的唯一变量,跟客户预算、团队规模、行业领域都没有直接关系。可以把 E-E-A-T信号清单 当配套体检表一起跑,确保深度内容同时也是权威内容。
保哥4型DTC客户深度内容复盘4个真实账本?
过去14周4型客户全部按深度内容策略改造过,每个客户的复盘账本如下。
客户1——北美厨具DTC(Shopify Plus,铸铁锅与烘焙工具)。改造前自然流量月均4.2万UV,AI引用4次/月。改造方案:旧文38篇下架或noindex(占总文章27%),新写14篇深度文章主打"硬水地区开锅失败排查""低温烘焙参数微调"等具体场景。14周后自然流量7.1万UV、AI引用31次/月,转化率从1.8% 升到2.4%(订单溢价能力来自深度内容的信任沉淀)。最大坑:旧文下架后被一个老客户投诉"找不到原来那篇文章",后来给老客户单独发了PDF版本解决。
客户2——欧洲手工乐器DTC(小提琴与古典吉他配件,多语种EN/DE/IT)。改造前自然流量月均1.4万UV,AI引用0次/月(全网细分品类小、AI还没建立信任)。改造方案:上修复师的"修复台日记"周更频道、把14个月38把老琴修复数据脱敏发布、补每篇文章的"板材含水率与温湿度"层级细节。14周后自然流量3.6万UV、AI引用18次/月(小品类AI引用率反而比大品类高,因为竞争少)、欧洲3家小提琴论坛主动转载文章。最大坑:修复师写文章不情愿,最后改成访谈记录由编辑整理。
客户3——东南亚摩托配件B2B(越南/印尼/泰国,主要B端询盘)。改造前自然流量月均8千UV,月询盘12个,平均订单1.2万美金。改造方案:删通用"摩托零件选型"等浅文21篇,新写"越南雨季链条寿命对照""印尼热带腐蚀环境下橡胶件90天测试"等带具体地域、时间、品牌型号的深度内容。14周后自然流量1.5万UV、月询盘27个(翻倍)、平均订单价升到1.4万美金(询盘质量提高)。最大坑:新写文章用的具体型号有2个被竞品起诉商标侵权风险,后来全部用通用规格描述替换型号。
客户4——国内母婴出口DTC(亚马逊 + Shopify双线,欧美亚太市场)。改造前自然流量月均3.8万UV,但被AIO严重侵蚀(YMYL类查询AIO占据率73%)。改造方案:所有内容按FDA/FTC + 中国法规双线合规审一遍、补"美国FDA与中国法规营养声明口径差异""欧洲EFSA与美国FDA安全限值差异"等具体合规边界。14周后自然流量4.9万UV(恢复增长)、AIO引用率从4% 升到19%(YMYL类AI反而需要权威边界声明的内容)、转化率1.5% 升到2.1%。最大坑:合规审稿延长发文周期3倍,最初团队抗拒,最终接受。
4型客户的共性:改造后流量都没有翻倍以上(涨幅25%-75%),但AI引用次数翻4-8倍、转化率均有15%-50% 提升。说明深度内容的核心价值不是单纯流量,而是"流量质量与信任沉淀"。流量数字变化不是这场改造的最大收益,AI引用与转化率才是。读者如果只盯着流量数字看,会低估深度内容的真实价值。
深度内容生产的3大踩坑与提前识别信号?
14周里保哥踩了三个大坑,提前识别这三个坑能省50% 试错成本。
踩坑1——把"深"当字数堆。客户1改造初期内容总监误读了"深度"概念,把每篇6000字硬堆到12000字。结果文章读起来累、移动端跳出率从38% 涨到64%,AI引用反而下降。识别信号:当编辑反映"文章越写越长但读起来越累"时立即停止、改回4000-5000字、聚焦信号密度。补救:把堆出来的"通用百科段"全部砍掉,保留"具体场景段"和"客户型案例段"。
踩坑2——把"原创"等同"完全独家"。客户2修复师一度认为只有"全球只有他能修的某种琴"才算原创报道,结果8周写不出来一篇。识别信号:当客户内部对"原创"标准过度严苛时,主动放宽到"原创视角"——同一个修复方法你的视角与别家的视角不一样就算原创。补救:拆"原创"为三档(独家事实/独家视角/独家组合),低门槛进入、高门槛累积。
踩坑3——把"深度"做成壁垒导致团队抗拒。客户4合规审稿延长发文周期后团队3个月里抗拒,差点放弃。识别信号:当团队反复说"做不下去"时不是真做不下去,是流程改造没配套激励。补救:把深度评分接入团队KPI(不是绝对KPI是参考分),高分文章作者拿额外稿费奖励,3个月后团队主动写深度。
三个坑提前识别后保哥的客户改造成功率从50% 升到92%。这个数据说明深度内容不是技术问题、是组织管理问题。SEO顾问要兼做组织变革顾问,能力上要双线展开。可以参考保哥之前写的 信息增益机制完整指南 把组织改造与内容工程绑在一起跑。
给中小预算独立站的深度内容ROI优先级怎么排?
不是每家独立站都有客户1、客户2那样的预算。中小独立站(月预算5千美金以下)怎么排深度内容投入优先级?保哥按ROI给出4档建议。
第一档(ROI最高,必做)——失败案例库与边界条件库。投入:1个内容编辑 + 1周时间整理过去12个月运营踩坑。产出:5-8篇高密度信号深度内容,可持续被AI引用。回本周期:2-4个月。
第二档(ROI高,应做)——客户访谈整理。投入:5个客户电话 + 2周时间整理。产出:3-5篇真实场景深度内容、附带客户证言信任沉淀。回本周期:3-5个月。
第三档(ROI中,可做)——小规模实验复盘。投入:500-2000美元 + 1个月时间。产出:1-2篇全网独家实证内容、长期被搜索引擎与AI视为权威源。回本周期:6-12个月(但价值持续2-3年)。
第四档(ROI不稳定,慎做)——大规模行业数据报告。投入:5千-2万美元 + 3个月时间。产出:1篇旗舰深度内容、可能引爆品牌也可能没人看。回本周期:6-24个月。中小预算独立站慎入这一档,先做第一第二档再考虑。
保哥的判断:90% 的中小独立站在前三档没做透的情况下不要碰第四档。前三档投入预算合计5千-1万美元,回报周期半年内。第四档投入起步5千美元,回报周期不可控。可以参考 AI引用30天5结构对照实测 在前三档跑通后再决定要不要做第四档的旗舰内容。
未来12个月AI搜索奖励深度会怎么演化?三个判断
保哥根据过去14周观察 + 行业内部消息给三个未来12个月的判断。
判断1——AI Overviews与AI Mode会进一步分化深度内容奖励。AIO倾向引用浅 + 权威源(百科 + 新闻 + 大站),AI Mode倾向引用深 + 第一手(论坛 + 实战 + 客户型)。中小独立站继续投资AIO的回报率会持续下降,AI Mode的回报率会持续上升。投入方向应该倾向AI Mode优先。
判断2——"信息净增量证明"会成为AI搜索算法的硬指标。Google内部已有information gain信号、AI搜索引擎之间会跟进。未来6-12个月每篇内容都需要明确证明"我比其他SERP页面新增了什么",否则被识别为冗余commodity内容。这意味着深度评分自检不是可选项是必选项。
判断3——一手数据出处会形成新的权重壁垒。AI引用链上越靠近源头的页面权重越高,中小独立站如果不主动产出一手数据(哪怕是小规模实验、客户访谈),会被AI引用链中下游化,长期流失流量。这也是为什么保哥给所有客户的第一档投入都是"客户型脱敏数据库"——它是建立一手数据出处身份的最快路径。
三个判断如果全部应验,未来12个月独立站的内容投入应该重新洗牌——浅内容下架、深内容加码、一手数据先发、AI模式优先。这与 未链接品牌提及转反链完整指南 强调的"品牌信号建设"是一对配套动作:深度内容产生信任、未链接品牌提及把信任转成链接资产、链接资产反向加固AI引用链上的位置。
常见问题解答
Q1:深度内容是不是字数越多越好?
不是。深度跟字数没有直接关系,跟"信息净增量"密切相关。4千字带5类AI不可复制信号的内容跑赢8千字带1类信号的内容。保哥建议中文4000-6000字配5类以上信号是最佳投入产出比。
Q2:中小独立站没有大预算怎么做原创报道?
把"原创报道"重新定义成"原创信息净增量"。4条路径任选——自家数据脱敏发布、小规模实验复盘、客户访谈整理、一手观察笔记。前三条投入500-2000美金即可起步,不需要记者背景。
Q3:AI搜索奖励深度内容是不是意味着浅内容彻底没流量了?
不彻底。浅内容仍有少量长尾流量,但AI Overviews占据SERP后浅内容点击率会持续下降。保哥建议把浅内容下架或noindex,把权重集中到深度内容。
Q4:怎么判断我写的算深度内容还是伪深度?
用5指标自检——独家事实密度、失败案例占比、边界声明数、反直觉判断数、一手数据引用数。每项满分20分,总分80以上算深度、60-80算中等、60以下算浅。
Q5:YMYL类深度内容跟其他类有什么不同?
YMYL类深度是"权威声明 + 边界限制",不能写"应该这样做"。要写"按FDA/FTC指南口径,在X情况下可以考虑Y,但不能保证Z,遇到W情况立即就医或咨询专业人士"。深度落在合规边界的精确描述上。
Q6:编辑流程怎么改造支持深度生产?
把原来4步流程改成7步——选题、数据采集、选题校准、写作框架、初稿、深度评分、发布。引入"专家批注 + 编辑润色"的双人协作模式。每篇生产时间会从4小时延长到6小时,但流量回报翻2-4倍。
Q7:AI搜索时代我该停做哪些内容动作?
5件事可以立即停做——写定义类教科书、字数硬堆到8千以上、用ChatGPT一稿不改写、抄竞品标题与结构、YMYL用绝对化口径。这5件事浪费时间还伤排名。
Q8:未来12个月深度内容奖励会怎么演化?
三个判断——AIO与AI Mode进一步分化奖励、信息净增量证明会成算法硬指标、一手数据出处形成新权重壁垒。中小独立站应该AI Mode优先、一手数据先发、浅内容下架。
权威参考资料
本文标题:《AI搜索奖励深度内容怎么做?8信号原创视角14周实操账本》
本文链接:https://zhangwenbao.com/ai-search-deeper-content-original-human-perspective-strategy.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0