AI浏览器之战打响:搜索入口正在碎裂,出海独立站的流量该往哪接

本文目录
- 先看清战场:一年之内,浏览器成了AI的新主场
- 这场仗跟你的独立站有什么关系
- 三种“新浏览”方式,分别怎么截走你的流量
- 数据说话:流量到底在往哪走
- 四方势力各自的算盘:为什么它们的打法不一样
- 可见性的新排序:被引用 > 被排名 > 被访问
- 智能体会代替用户来你的站,这是新的技术SEO
- 你的站在智能体眼里长什么样
- 别再只盯google.com:把流量入口重新盘一遍
- 品牌实体一致性:让每个引擎都认得你是同一个你
- 内容要同时喂人、也喂机器
- 监测新流量来源:从referrer和UA里揪出AI浏览器
- 智能体购物:对电商独立站是威胁,也是机会
- 隐私与数据:AI浏览器读走用户看的一切
- 要不要拦AI浏览器的机器人?一个需要想清楚的取舍
- 内容变现的新逻辑:付费墙、分成与向机器收费
- 出海独立站的现实清单:现在就该做的几件事
- 五个常见误区,别踩
- 常见问题解答
- AI浏览器会让谷歌SEO彻底没用吗?
- 独立站现在就要为AI浏览器专门做优化吗?
- 怎么知道AI浏览器有没有给我带来流量?
- 智能体会来我的站上直接下单吗?我该准备什么?
- 要不要用robots.txt把AI爬虫都拦了?
- 入口这么多,中小独立站根本顾不过来怎么办?
- 权威参考资料
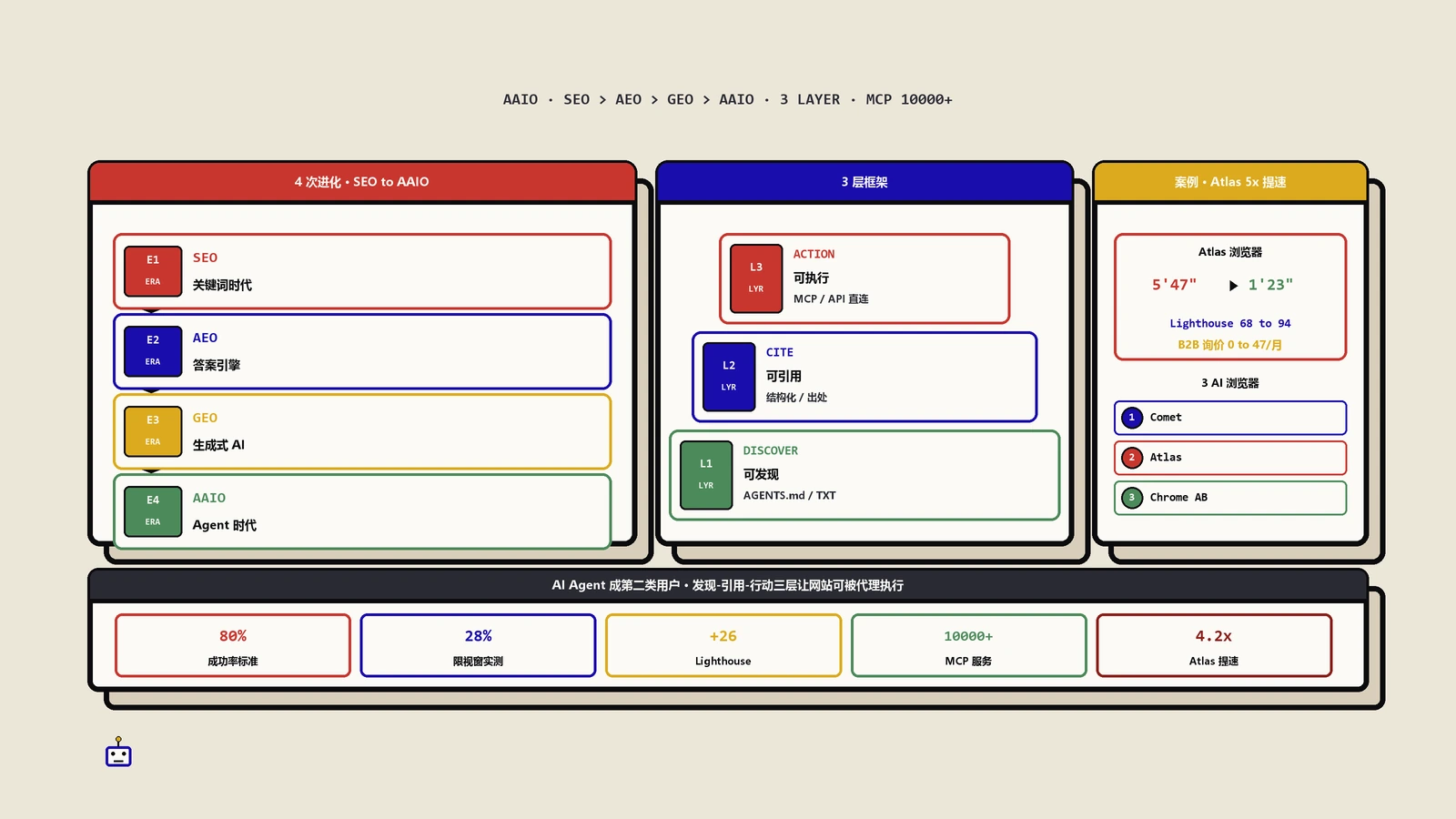
摘要:过去二十年,搜索几乎只发生在一个地方——谷歌那个搜索框。2025年下半年开始,这件事变了:OpenAI出了内置ChatGPT的Atlas浏览器,Perplexity的Comet全球免费开放,谷歌把Gemini直接焊进Chrome,微软给Edge装上Copilot智能体模式。搜索入口正在从“一个框”碎裂成“每个浏览器自带的一层AI答案”。对独立站来说,这不是又一个要优化的渠道,而是流量入口本身在重新洗牌。这篇把这场浏览器之战讲清楚,更重要的是告诉你:作为出海独立站主,现在该在哪几件事上动手,才能在答案被前置、用户被智能体代办的新格局里,还能被发现、被引用、被访问。
先看清战场:一年之内,浏览器成了AI的新主场
把时间线拉一下你就明白节奏有多快。2025年7月,Perplexity先给Max订阅用户放出了 Comet浏览器;10月2日,它宣布Comet面向全球所有人免费,把原本每月200美元的门槛直接抹掉。紧接着10月21日,OpenAI发布了ChatGPT Atlas,一款把ChatGPT当成默认浏览层的macOS浏览器。进入2026年,谷歌在1月底宣布把Gemini更深地整合进Chrome,还上线了能替你多步操作的auto browse;微软则把Edge的Copilot模式重做成一个能读多标签页、能填表、能下单的智能体浏览器。
这些产品名字各异,但打的是同一个位置:你每天睁眼就用、却从来没觉得它有多重要的浏览器。为什么都盯上它?因为浏览器是离用户意图最近的一层。你在哪个页面、看了什么、正在纠结买哪个,浏览器全知道。谁把AI塞进这一层,谁就能在你还没打开谷歌之前,先把答案递到你面前。这也是为什么连Chrome自己都要“自我革命”——它比谁都清楚,一旦用户习惯了在浏览器里直接要答案,传统的十条蓝色链接就不再是唯一的出口。
这场仗跟你的独立站有什么关系
你可能会想:浏览器巨头打架,关我一个卖储能、卖宠物用品的独立站什么事?关系大了。因为这场仗的核心战利品,正是你赖以生存的东西——用户找信息、找产品、做决定的那个入口。
过去的路径很简单:用户有需求 → 打开谷歌 → 搜关键词 → 看到十条结果 → 点进你的站。你做SEO,就是想办法在那十条里往上爬。现在这条链路被从中间截断了。用户有需求 → 在浏览器侧边栏问一句 → AI直接给一段答案 → 用户可能压根不再点任何链接。搜索没有消失,但“搜索的地点”从谷歌那一个框,碎成了Chrome的侧边栏、Atlas的问答、Comet的助手、Edge的Copilot每一处。入口碎了,你要接的流量也就跟着碎了。
更麻烦的是,这几个入口各有各的脾气:它们引用谁、相信谁、把哪家的内容拿来生成答案,逻辑并不一样。这意味着你不能再用“优化一个谷歌”的思路去应付,而要面对一张越来越分散的分发网。这跟站内之前拆过的SEO与GEO流量分裂的定量证据是同一件事的两面:可见性正在从“排名”迁移到“被各类AI界面选中”。
三种“新浏览”方式,分别怎么截走你的流量
要接住流量,先得看清它是怎么被拦下的。当下这几款AI浏览器,截流量的方式大致分三层,一层比一层狠。
第一层是侧边栏助手。你正常打开网页,浏览器侧边挂着一个AI,随时能总结当前页、回答关于这页的问题。Comet的“sidecar”助手、Gemini在Chrome侧栏、Edge的Copilot都是这个路子。这一层还算温和——用户毕竟到了你的页面。但它会把“读完整页”变成“读AI的三行总结”,你精心写的长文、你埋在下半页的转化钩子,可能根本没被人眼看到。
第二层是AI答案模式。用户在地址栏或搜索里提问,浏览器直接生成一段综合答案,底下给几个来源角标。Atlas有个“Auto”模式,会根据问题在ChatGPT生成的答案和谷歌搜索结果之间来回切换。到了这一层,用户很可能看完答案就走,你连被点进来的机会都没有——除非你是那几个被引用的来源之一。这就是浏览器层面的零点击,比搜索页里的AI概览更靠前、更彻底。关于零点击带来的后台数据空白,站内之前在零点击时代的归因怎么补里专门拆过,这里不展开。
第三层是智能体代办。这是最新也最颠覆的一层。Atlas的agent模式会给AI一个光标、把浏览器界面高亮成蓝色,让它替你订酒店、建文档;Chrome里的Gemini与auto browse 能替你完成多步任务;Edge的Copilot智能体模式在你同意后能填表、下单。到了这一层,来你站上的可能根本不是人,而是一个替用户跑腿的智能体。它会不会选中你、能不能在你的站上把事办成,直接决定了这单生意落不落到你头上。
数据说话:流量到底在往哪走
趋势叙事容易让人焦虑,我们看点硬数据,把恐慌和现实分开。
路透新闻研究院2026年的媒体趋势与预测报告里,受访的出版商预期未来三年搜索引擎带来的流量会下滑超过40%,其中约五分之一的人认为会损失75%以上,只有少数乐观派觉得冲击会小于20%。这不是空口预测——Chartbeat的聚合数据显示,2024年11月到2025年11月这一年里,谷歌自然搜索流量全球已经掉了33%,美国跌了38%;同期社交引荐也在缩水,Facebook掉43%、X掉46%。入口不只是被AI抢,是整个“别人把流量分给你”的旧模式在退潮。
但另一面同样要看清:AI浏览器现在带来的直接引荐量,还很小。按Similarweb的口径,AI平台贡献的流量大约只占自然流量的0.5%到1%,2026年一季度甚至略有回落。路透的报告也提到一个反差——ChatGPT每周活跃用户已经到了约8亿,但光从搜索算,谷歌带来的引荐量仍是ChatGPT的500倍。
这两组看似矛盾的数据合起来说明什么?旧入口在快速缩水,新入口还没接住等量的流量,中间是一段真空期。谁能在这段真空期里提前把“被AI选中”的能力建起来,谁就能在新入口长大时吃到红利;反过来,只守着谷歌排名的站,会先感受到失血、后错过接盘。
再看 Cloudflare关于智能体互联网的流量报告,它把非人类的AI流量拆成三类:训练爬虫约占89%,搜索爬虫约8%,而智能体机器人只有2%出头——但这2%正是增长最快的一类。也就是说,替用户跑腿的浏览器智能体,今天量还小,却是曲线最陡的那条。你现在感觉不到痛,不代表两年后不痛。
四方势力各自的算盘:为什么它们的打法不一样
要判断该往哪几个入口押注,得先看懂这四家为什么下场、各揣着什么心思。动机不同,产品的持久性和它对你的价值也不同。
OpenAI是从聊天往外扩,抢的是入口。它手里有几亿周活的对话用户,但对话框是个孤岛,用户查完就走。做浏览器,是把ChatGPT从一个你要专门打开的应用,变成你上网时一直在旁边的默认层。它要的是让你所有的上网行为都经过它这一层,越早养成习惯越好。所以Atlas会激进地把AI答案顶到最前面,哪怕被批评是在替代网页。
Perplexity是答案引擎起家,浏览器是它的延伸。它从第一天就在做“直接给答案”这件事,浏览器只是把这个能力铺到你的整个上网过程里。它把Comet全球免费,赌的是用规模换未来的变现空间——先让足够多的人用起来,再谈怎么赚钱。对独立站来说,Perplexity生态里买前决策类的问题密度很高,值得留意。
谷歌是防守,被迫自我革命。Chrome有三十多亿用户,是谷歌最深的护城河之一,但也正因为体量大,它最怕的就是用户习惯被别人改掉。所以谷歌宁可自己把Gemini塞进Chrome、上线auto browse,也不愿意等着被Atlas和Comet一点点蚕食。它的打法是稳中带攻:既保住原有的搜索广告盘子,又不能在智能体浪潮里掉队。对你而言,Chrome生态用户基数最大、又在猛推AI,是最不该忽视的一块。
微软走的是企业和差异化路线。Edge在消费端拼不过Chrome,但它把Copilot模式和企业场景、Office生态绑在一起,主攻“公司里的智能体浏览”。这块用户的商业价值高、但和多数出海独立站的目标客户重合度未必高,所以优先级可以往后放,看你的品类而定。
把四家的算盘摊开你就明白:这不是一个会很快分出胜负的战场,更可能是长期多强并存。正因为如此,押注单一入口很危险,而把自己的站做成“谁来都能读懂、能引用、能操作”的样子,才是穿越这场混战最稳的姿势。
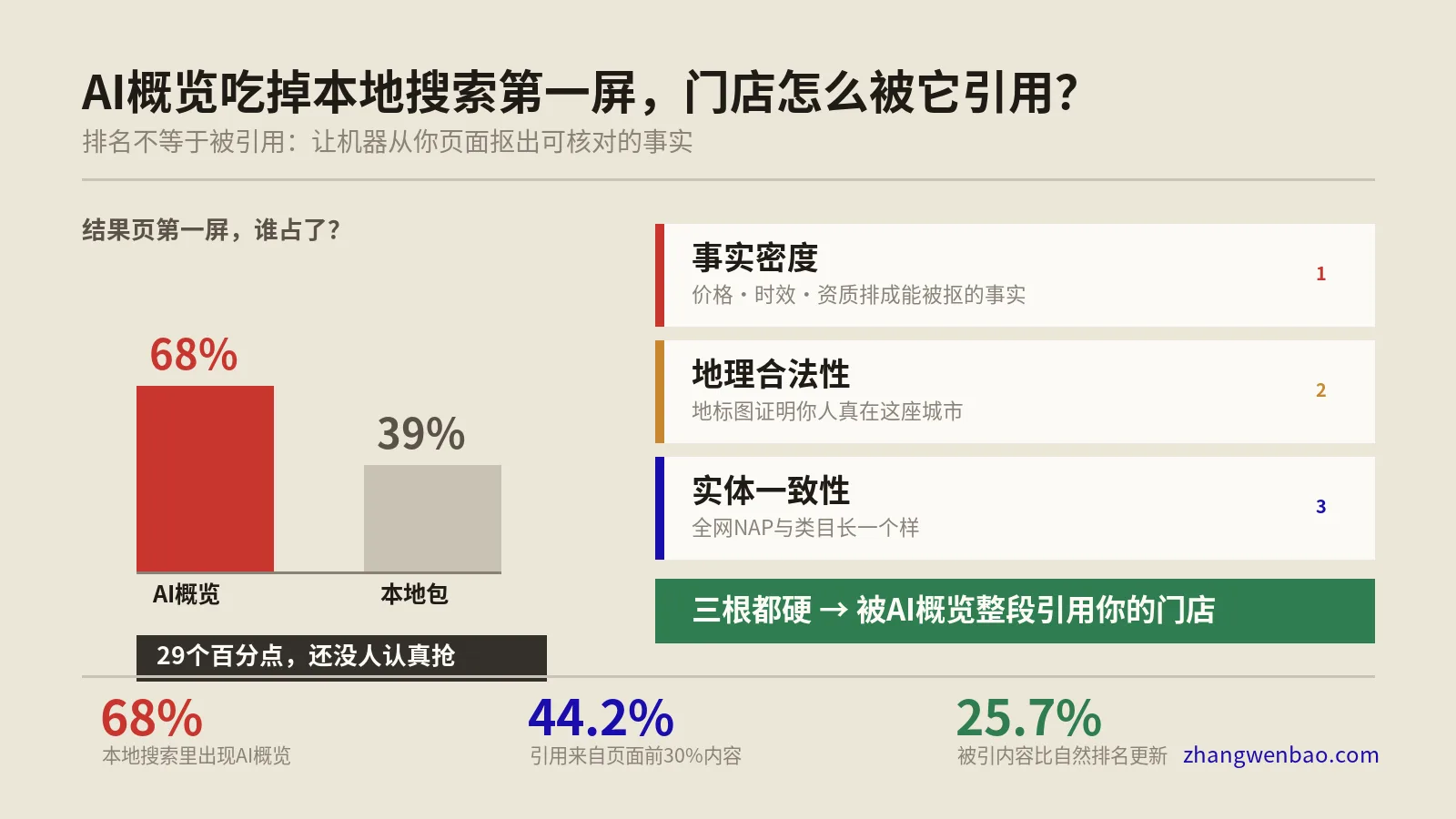
可见性的新排序:被引用 > 被排名 > 被访问
在这套新格局里,衡量你“混得好不好”的指标,顺序变了。
过去是“被访问”至上:一切优化都是为了把人弄到站上来。现在,在AI浏览器主导的场景里,优先级悄悄倒过来了。第一位是被引用——你的内容有没有被AI拿去生成答案、有没有出现在那几个来源角标里。被引用,你的品牌名和观点就进入了用户的决策,哪怕他没点进来。第二位才是被排名——传统的搜索名次仍然有用,因为很多AI答案的来源池,就是从搜索前排里捞的。第三位是被访问——真人点进来当然还是最值钱,但它越来越像是前两位做好之后的自然结果,而不是你唯一能追的目标。
这个排序的实操含义是:你要同时经营“被引用的内容”和“被访问后能转化的内容”,而且要分清哪篇内容承担哪个任务。站内在分清“被检索”和“被引用”的两套打法里把这层机制拆得很细,浏览器时代只是把它的重要性又抬高了一档:因为在浏览器里,“被引用”往往是用户看到你的唯一一次机会。
智能体会代替用户来你的站,这是新的技术SEO
如果说前面几层还是“内容能不能被选中”,那智能体代办这一层,考的是“你的站能不能被机器顺利用起来”。这是一个很多做内容的人还没反应过来的新战场。
想象一个真实场景:用户对Atlas说“帮我买一台适合露营的便携储能电源,预算三千以内,要能给无人机充电”。agent模式启动,它会去几个站上比参数、看评价、加购物车。这时候决定你能不能进它购物车的,不再是你的文案写得多动人,而是一连串很技术的东西:你的产品参数是不是结构化、机器能不能读;关键操作要不要先注册登录;有没有弹窗、cookie横幅、反爬机制把它挡在门外;页面是不是纯JS渲染、内容要等脚本跑完才出来。任何一处卡住,智能体就转身去了下一家。
换句话说,“让智能体能读懂、能操作”正在成为技术SEO的新科目。过去我们优化爬虫抓取,是为了被索引;现在要额外优化智能体的可操作性,是为了被“办成事”。站内之前写过AI代理如何感知你的网站,那套适配思路,现在有了非常具体的落地场景。
你的站在智能体眼里长什么样
把自己想象成那个替用户跑腿的智能体,走一遍你的站,很多问题会立刻暴露。这里给一张自查清单,按“最容易劝退智能体”的顺序排:
- 关键动作前的登录墙。要看价格得先注册、要看规格得先留邮箱——人类会犹豫,智能体直接放弃。把核心信息放在登录墙之外。
- 拦路的弹窗和横幅。满屏的订阅弹窗、cookie同意框、地区选择层,人类点一下关掉,智能体可能识别不了、点不对,卡在那里。
- 只在脚本里的内容。产品参数、价格、库存如果要等前端JS渲染才出现,很多抓取层根本读不到。关键数据尽量落到服务端渲染的HTML里。
- 没有结构化的数据。价格、评分、库存、规格如果只是散落的文字,机器得猜;用上Schema结构化标记,等于把这些字段直接摆到机器面前。
- 模糊的行动路径。加购、下单、咨询的按钮语义不清、藏得深,智能体找不到“下一步”该点哪。让主路径清晰、可预测。
这张清单的底层逻辑很朴素:对智能体友好的站,往往对真人也更友好。你不是在为机器牺牲体验,而是在借这个机会把那些一直拖后腿的障碍清掉。
别再只盯google.com:把流量入口重新盘一遍
浏览器之战最该改变的,是你脑子里那张“流量地图”。如果它上面还只有一个谷歌,那就太旧了。
现在值得盘进去的入口至少有这么几类:Chrome里的Gemini与AI Mode、Atlas的问答与agent、Comet的助手、Edge的Copilot,还有独立的ChatGPT、Perplexity这些不绑浏览器的助手。它们各自的来源偏好不一样——有的偏爱社区和百科,有的偏爱视频,有的偏爱机构和新闻源。你要做的不是把每一个都当成独立渠道去猛攻(你也没这个资源),而是想清楚:哪几个入口的用户,跟我的目标客户重合度最高,就重点保证在那几个里被引用、被读懂。
对出海独立站来说,一个务实的判断是:先盯Chrome生态(因为它用户基数最大、AI功能又在猛推)和ChatGPT/Atlas生态(因为购买决策类问题很多人已经在这问),把这两块的被引用和agent就绪做扎实,再看数据决定要不要往Comet、Edge上加码。多渠道不等于平均用力,而是有优先级地布点。
品牌实体一致性:让每个引擎都认得你是同一个你
入口越碎,“你是谁”这件事就越要说得清楚、说得统一。因为每个引擎都在用自己的方式,试图把你识别成一个可信的实体。如果你在官网叫一个名、在社媒叫另一个名、在目录里信息又对不上,机器就会犹豫——它拿不准这几处说的是不是同一家,干脆谁都不选。
实体一致性要抓的,是那些机器用来交叉验证你身份的信号:统一的品牌名与拼写、清晰的关于我们页、一致的联系方式和地址、结构化的组织信息、以及在多个可信平台上口径统一的品牌描述。这些做好了,不管用户是在Chrome、Atlas还是Perplexity里问到你所在的领域,几个引擎都能把你拼成同一个清晰的实体,被选中的概率自然高。这也是AI时代品牌为什么越来越像护城河——你越是一个机器认得清的实体,越难被替换掉。
内容要同时喂人、也喂机器
浏览器时代的内容,有一个双重身份:它既要打动屏幕前的真人,又要能被AI干净利落地抽取成答案。这两件事不矛盾,但需要你在写法上多想一层。
喂机器的关键,是让内容“块状可抽取”:一个问题对应一段清晰的直接回答,把结论前置,别让机器在一大段铺垫里捞重点;用小标题、列表、表格把信息切成边界清楚的块;关键事实旁边带上出处和数字,提升可信度密度。喂人的关键,则是别把文章写成冷冰冰的问答机器——真实的经验、具体的案例、一点温度和判断,才是让人愿意读下去、愿意信你的东西。
把这两者拧在一起的诀窍是分层:开头给一段机器和急性子的人都能直接拿走的浓缩答案,后面再给愿意深读的人展开细节、讲故事、摆案例。这样一篇内容,在侧边栏被总结时不吃亏,被真人细读时也有料。
监测新流量来源:从referrer和UA里揪出AI浏览器
你没法优化你看不见的东西。AI浏览器带来的流量和访问,很多藏在你还没留意的地方,得主动去挖。
两个方向可以下手。一是看引荐来源:在分析后台留意来自AI助手和浏览器域名的访问,虽然量还小,但趋势比绝对值重要——它在涨还是在跌,涨得快的就是你要重点接的入口。二是看服务器日志里的User-Agent:越来越多的抓取和访问来自各类AI智能体。但这里有个坑要提醒——按Cloudflare的观察,约80%的AI智能体访问网站时并不老实表明身份,靠的是很容易伪造的UA字符串。所以日志能看个大概趋势,别把它当成精确账本。
把这些新来源和你熟悉的自然搜索、直接访问放在一张表里对照着看,你才能判断:旧入口失血的速度,和新入口长起来的速度,谁快谁慢,自己的站处在这条曲线的哪一段。
智能体购物:对电商独立站是威胁,也是机会
agent代办里最值钱的一块,是购物。当越来越多的人开始让智能体去比价、去下单,电商独立站面对的是一个全新的货架——一个由机器来逛、来挑、来结账的货架。
威胁的一面很直白:如果智能体读不懂你的产品、进不了你的结账流程,你就被排除在它的候选之外,连被比较的资格都没有。但机会的一面同样真实:过去中小独立站很难和大平台拼流量、拼广告位;而在智能体面前,大家某种程度上被拉回同一起跑线——它不看你广告砸得多凶,只看你的产品数据是否清晰、参数是否匹配需求、页面是否能被顺利操作。谁把产品做成机器最容易理解和处理的样子,谁就能在这个新货架上被更多地选中。
具体到动作:把产品的关键属性结构化、把价格库存放在机器能稳定读到的位置、把加购到结账的路径做得干净可预测、减少非必要的登录和弹窗阻拦。这些既是为智能体铺路,也顺带优化了真人的购买体验,一举两得。
隐私与数据:AI浏览器读走用户看的一切
有一层影响容易被SEO视角忽略,但它会反过来改变游戏规则,那就是数据和隐私。
这些AI浏览器为了给出个性化的帮助,需要比传统浏览器记住更多东西。以Atlas的“浏览记忆”为例,它会保留从访问过的网页里提取的信息——OpenAI官方对ChatGPT Atlas的介绍里说,摘要会在七天内删除、原始网页内容在总结后立即删除,但这套机制本身就意味着,用户在你页面上看了什么、纠结了什么,都可能被浏览器层的AI记下、拿去优化对这个用户的下一次回答。有安全研究者甚至把这类浏览器称作“反网页浏览器”,因为它倾向于用自己生成的内容,替代掉用户本该看到的原始网页。
对你的现实含义有两点:一,你和用户之间多了一个“中间层”,它在替你和用户对话,你的信息可能被它转述、被它加工,口径未必是你想要的——这更逼着你把品牌事实说清楚、说一致,减少被误传的空间。二,恶意网页对这类浏览器的提示注入攻击是新的安全隐患,虽然主要是浏览器厂商的责任,但作为站点方,保持内容干净、不给可疑第三方脚本留口子,也是在保护你自己的声誉。
要不要拦AI浏览器的机器人?一个需要想清楚的取舍
随着智能体流量上来,一个现实问题摆到桌上:这些AI机器人来抓你的内容,你是欢迎还是拦截?这不是个能一刀切的问题,得分清来意。
Cloudflare现在把AI流量按用途分成了训练、搜索、智能体几类,并且对新接入的域名,默认在展示广告的页面上拦截训练和智能体类爬虫,而保留搜索类的通行——甚至开始探索直接向这些爬虫收费。背后的逻辑是:拿你内容去训练模型的爬虫,对你几乎没回报;而帮用户找到你、可能带来引荐的搜索类爬虫,拦了反而伤自己。数据上也能看到分歧,据观察约79%的大型新闻出版商已经在用robots.txt拦训练爬虫,约71%连检索爬虫也一起拦。
对独立站的建议是:别盲目跟风全拦,先分清哪类爬虫对你有价值。你要的是被AI引用、被智能体选中带来生意,那就别把负责“找到你”的那类爬虫也误伤了。拦截更适合那些内容本身就是核心资产、且不指望AI引荐的站;对多数靠被发现吃饭的出海独立站,思路应该是“让该进来的进得来、把纯薅羊毛的挡在外面”,而不是一堵墙全封死。
内容变现的新逻辑:付费墙、分成与向机器收费
浏览器之战还悄悄改写了一件事——内容到底靠什么赚钱。这条线索容易被忽略,但它可能比流量本身更影响你的长期活法。
一个信号是Perplexity在Comet之外推出了Comet Plus订阅,让付费用户能读到来自“可信出版商和记者”的内容。说白了就是:AI浏览器开始尝试把优质内容源纳入一套新的付费和分成体系,谁被认定为可信来源,谁就有机会分到这块钱。另一个信号是Cloudflare那套按用途给爬虫分类、并探索直接向爬虫收费的做法——它背后是一个更大的命题:当机器成了内容的主要消费者,内容的价值该怎么重新计价、这笔钱该由谁来付。
这两件事合起来,勾勒出一个正在成形的新逻辑:过去内容靠“人来看广告”变现,未来可能越来越多靠“被可信地引用、被机器付费调用”变现。对绝大多数出海独立站来说,现在还谈不上直接从AI那边收到钱,但方向值得记在心里:把自己做成一个内容可信、实体清晰、机器愿意反复引用的源,是在为下一轮的变现规则提前占位。今天你争的是被引用的曝光,明天争的可能就是被引用带来的实际分成或授权价值。
务实的做法不是现在就去研究怎么收费,而是别做那些会让你在新体系里掉队的事:别靠洗别人的内容凑数(可信来源的门槛只会越来越高),别把内容全锁死(该被引用的部分要让机器进得来),把原创的、有第一手价值的东西做扎实。这些既是今天被引用的资本,也是明天分蛋糕的入场券。
出海独立站的现实清单:现在就该做的几件事
讲了这么多格局,落到手上,你这季度真正该做的其实不多,但每件都值。保哥手头有个做户外储能的客户,去年下半年就是靠这几件事,在自然流量整体走平的情况下,AI助手和浏览器带来的被引用明显涨了一截:
- 把核心产品和主打内容改成“块状可抽取”。问题前置、结论先行、参数结构化,让侧边栏总结和答案生成都能干净地拿走你的信息。
- 做一遍“智能体走查”。假装自己是agent,从搜索到加购走一遍,把登录墙、弹窗、JS障碍逐个清掉。那个储能客户光是把规格表从图片改成结构化文字,就让好几处AI答案开始正确引用它的参数。
- 统一品牌实体信息。官网、关于我们、社媒、目录,把品牌名、描述、联系方式的口径对齐,让每个引擎都认得你。
- 建一张新的流量监测表。把AI助手引荐、浏览器来源、智能体UA和传统渠道放在一起看趋势,别等失血了才发现。
- 想清楚爬虫策略。按用途区别对待,别把带来引荐的搜索类爬虫也一起拦了。
这五件事的共同点是:它们不赌某一个浏览器赢,而是不管最后谁赢,你都更容易被读懂、被引用、被办成事。在一个入口高度不确定的时期,这种“押注确定性”的做法,比追着每个新产品跑要稳得多。
五个常见误区,别踩
误区一:AI浏览器还没起量,等它成熟了再说。直接引荐量确实还小,但被引用能力是需要时间养的——等入口长大了再动手,你已经错过了对手在真空期建立的领先。
误区二:把AI浏览器当成又一个要单独运营的社媒渠道。它不是让你去开号发内容,而是要你把自己的站改造成“机器能读懂、能操作”的样子,是底层能力,不是又一个内容分发口。
误区三:只要SEO排名好,AI那边自然就好。有相关性但不是等号。很多AI答案的来源逻辑和搜索排名并不一致,被引用需要额外的、面向抽取的优化。
误区四:把所有AI爬虫一律拦掉最安全。拦掉训练爬虫可以理解,但连帮你被找到、被引用的搜索类爬虫也拦,等于自断新入口。
误区五:这是大站和媒体的事,我一个小独立站够不着。恰恰相反,智能体不看广告预算只看数据清晰度,某种意义上把中小站和大平台拉回了同一条起跑线,这是小站难得的机会窗口。
常见问题解答
AI浏览器会让谷歌SEO彻底没用吗?
不会,但会改变它的角色。传统搜索排名短期内仍是很多AI答案的来源池,排在前面依然有用。变化在于:排名不再是终点,而是“被AI选中”的一个前置条件。你需要在做好排名的基础上,再补上面向抽取和引用的优化,两条腿走路。
独立站现在就要为AI浏览器专门做优化吗?
要,但方式不是“专门”。你该做的事——内容块状化、数据结构化、清掉登录墙和弹窗、统一品牌实体——每一件同时利好真人体验、搜索、AI引用和智能体操作。所以不是新增一摊工作,而是把这些本就该做好的基本功,按新格局重新排个优先级。
怎么知道AI浏览器有没有给我带来流量?
看两个地方:分析后台里来自AI助手和浏览器域名的引荐来源,以及服务器日志里的智能体User-Agent。注意量还很小,看趋势比看绝对值重要;也要留意约八成智能体不老实表明身份,日志只能反映大概趋势,不是精确账本。
智能体会来我的站上直接下单吗?我该准备什么?
已经开始了,Atlas、Chrome、Edge的智能体都能在用户授权下完成加购甚至下单。你要准备的是让它办得成事:产品属性结构化、价格库存机器可读、加购到结账路径清晰、减少登录和弹窗阻拦。谁的站对智能体最友好,谁就更容易被选中。
要不要用robots.txt把AI爬虫都拦了?
别一律拦。按用途区分:拿内容去训练模型的爬虫回报低,可以拦;帮用户找到你、可能带来引荐的搜索类爬虫,拦了是自伤。多数靠被发现吃饭的出海独立站,思路应是有选择地放行,而不是一堵墙封死。
入口这么多,中小独立站根本顾不过来怎么办?
不用平均用力。先判断哪几个入口的用户和你的目标客户重合度最高——对多数出海站是Chrome生态和ChatGPT/Atlas生态——把这两块的被引用和智能体就绪做扎实,其余看数据再决定加不加码。有优先级地布点,比追着每个新产品跑要现实得多。
权威参考资料
本文标题:《AI浏览器之战打响:搜索入口正在碎裂,出海独立站的流量该往哪接》
本文链接:https://zhangwenbao.com/ai-browser-wars-search-distribution-fragmentation-traffic.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0