内容溯源与C2PA:AI内容泛滥后,可验证出处正成为新的信任货币
本文目录
- 先把话说白:执行门槛塌了,下一道坎是“这内容能信吗”
- 什么是内容溯源与内容凭证:给数字内容贴的“营养标签”
- 为什么是现在:三件事在2026年同时发生
- 为什么大厂突然都上车了:一场信任的军备竞赛
- 机制拆解:一条内容的出处链是怎么签出来的
- 从相机到读者:出处链上到底谁在参与
- C2PA不等于水印:三种真实性技术的分工
- 和SEO/GEO到底什么关系:先按可验证性排序,再按质量排序
- 内容凭证怎么核验:读者和引擎实际看到什么
- 出处会成为明确的排名因子吗:别把“没明说”当“不影响”
- 内容凭证的软肋:为什么它经常“上传就没了”
- 独立站主现在能做的7件事(不等标准普及)
- 一个真实的踩坑复盘:保哥团队的内容凭证乌龙
- 别做的三件事:把溯源做歪的三种姿势
- 未来12到18个月:溯源从合规走向信任货币
- 常见问题解答
- C2PA和内容凭证是一回事吗?
- 我不做欧盟市场,还需要关心内容溯源吗?
- 内容凭证会直接提升我的搜索排名吗?
- 给内容签了凭证,为什么发出去就没了?
- 普通独立站主现在最该做的一件事是什么?
- 内容凭证能防住深度伪造吗?
- 权威参考资料
摘要:AI把内容生产的门槛按到了地板,下一道坎不是“能不能写出来”,而是“这内容还能不能信”。可验证出处(内容凭证,也就是C2PA标准这一套)正在从一个合规话题,悄悄变成排序信号和新的信任货币。2026年三件事同时发生:AI内容占比飙升、欧盟8月2日起强制机器可读标注、Google和OpenAI把内容凭证与水印验证搬进了搜索和聊天界面。这篇讲清楚内容溯源到底是什么、机制怎么跑、和SEO/GEO有什么真实关系,以及独立站主现在——不是等标准普及之后——能落地的7件事。文末也把一次真实的内容凭证乌龙摊出来复盘。
先把话说白:执行门槛塌了,下一道坎是“这内容能信吗”
过去两年,写内容这件事的成本几乎归零。一个人配上几个模型,一天能产出过去一个小团队一周的量。保哥在之前聊Vibe营销那篇里泼过一次冷水:执行不再稀缺,稀缺的是判断力。这话今天要接着往下说一层。
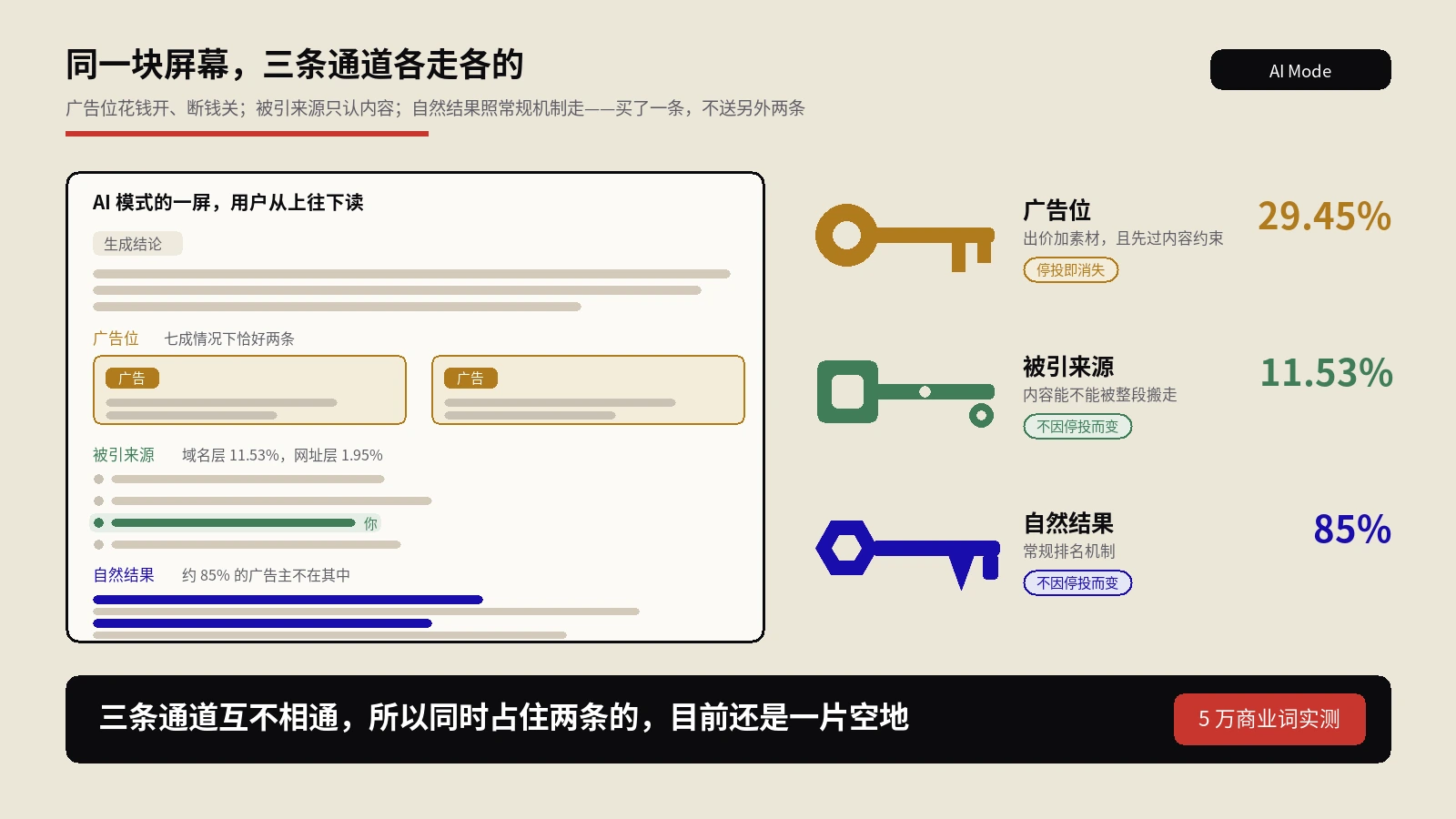
当所有人都能无成本地量产内容,读者和搜索引擎面对的第一个问题就变了。不再是“这篇写得好不好”,而是更底层的一句:这玩意儿是谁做的、是不是机器编的、能不能信。信任,正在从一个默认前提,变成一件需要被证明的事。
你可以把它想成餐厅后厨。以前食客默认厨房是干净的,没人会盯着看。等到出过几次食品安全事故,大家开始要求明厨亮灶——不是因为菜变难吃了,而是因为“看不见”本身成了风险。内容行业现在就走到这一步。可验证出处,就是内容世界的那面玻璃墙。
什么是内容溯源与内容凭证:给数字内容贴的“营养标签”
先把名词理顺,别被缩写吓退。内容溯源(content provenance)指的是:一条数字内容从哪来、中间被谁改过、是不是AI参与生成,这条完整的“身世链”能被记录下来、被任何人核验。承载这套记录的技术标准,主流的就是C2PA——内容来源与真实性联盟推的一套开放标准。它落到具体内容上,对外的名字叫内容凭证(Content Credentials)。
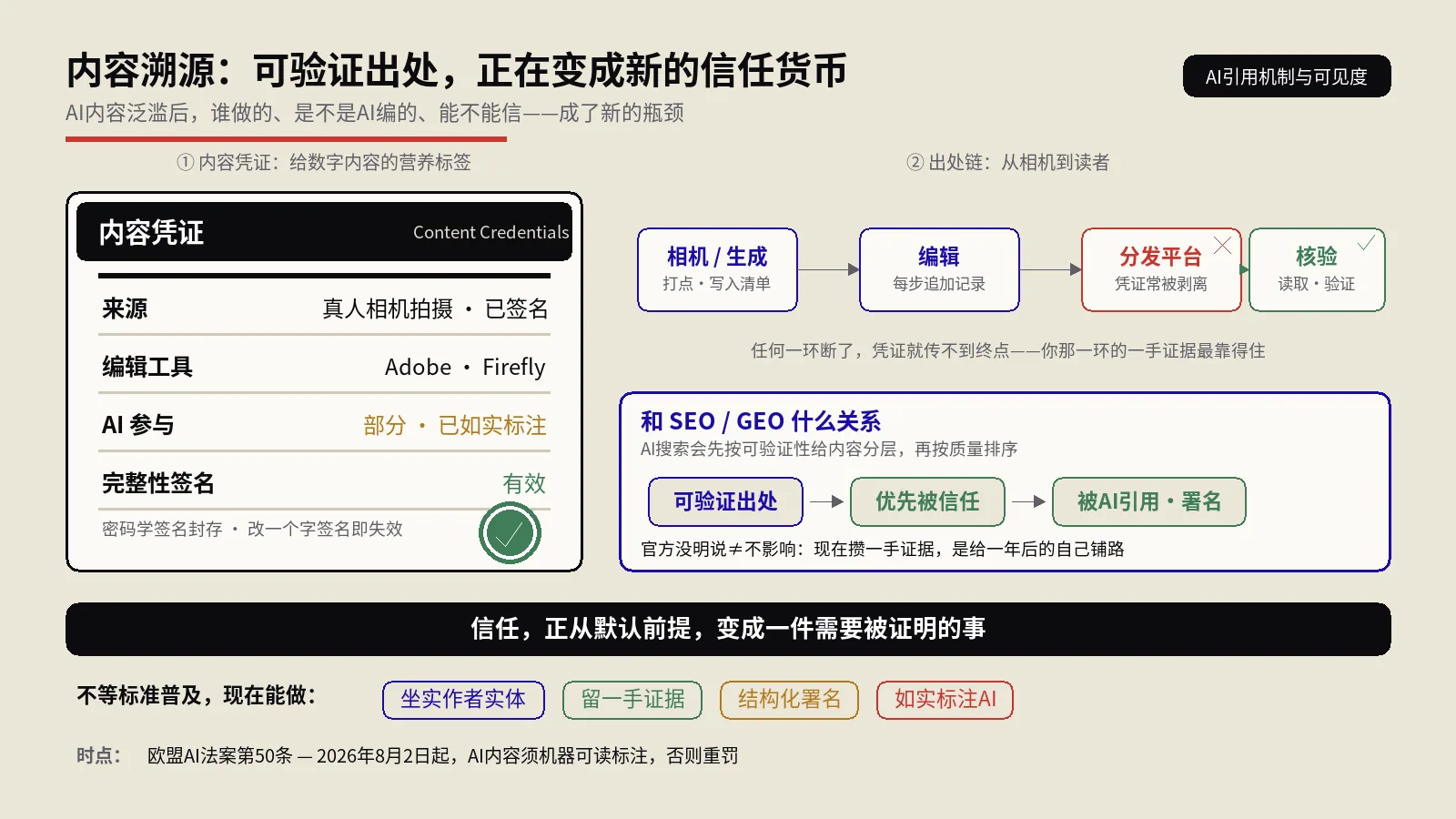
C2PA官方对这套标准的说明里用了一个特别接地气的比喻:内容凭证就像数字内容的“营养标签”。你买包薯片,背面印着热量、成分、产地、保质期;一张带内容凭证的图片,附带的就是“谁拍的、用什么设备、后期用没用AI、被谁编辑过、什么时候改的”。这份清单任何时候、任何人都能查。
关键在于,这不是一句可以随手涂改的水印文字,而是用密码学签名封起来的一份清单(manifest)。改动内容或改动清单本身,签名就会失效,核验方一眼就能看出“这份出处被动过手脚”。这一点,是它和普通EXIF元数据、和图片角落那行小字水印的本质区别。
为什么是现在:三件事在2026年同时发生
内容溯源这个概念不新,C2PA联盟2019年就有了。但它一直停在“标准党在讨论”的阶段。真正让它在2026年从会议室走进生产环境的,是三件事凑到了一起。
第一,供给侧崩了。AI内容占比在各个渠道飙升,真假内容混在一起,谁也没法靠肉眼分辨。当造假的边际成本比核验还低,市场自然会长出一套“证明真实”的基础设施——这是需求逼出来的,不是标准党喊出来的。
第二,监管上了硬指标。欧盟《人工智能法案》第50条的透明度义务,2026年8月2日起在27个成员国正式可强制执行。生成式AI的输出——文本、图像、音频、视频——必须以机器可读的格式标注为人工生成或经过篡改,深度伪造还要显著标注。不合规最高罚1500万欧元或全球营收的3%,取高者。这一下,“要不要做标注”从选择题变成了必答题。而机器可读的标注格式,C2PA就是现成的答案之一。
第三,平台把验证搬到了台前。2026年5月,OpenAI和Google宣布对齐——用C2PA元数据加SynthID水印的双层溯源方案。通过ChatGPT、OpenAI API生成的图像,会同时带上SynthID水印和C2PA清单。Google更进一步,把C2PA验证和SynthID检测搬进了搜索和Chrome:用户在Google图片、Lens、“圈图搜”里看到一张图,用“关于此图片”功能就能查它是不是AI做的、有没有内容凭证。
三件事叠在一起,意味着一个信号:可验证出处不再是加分项,正在变成基础设施。你不主动配,它也会在别处被拿来评判你的内容。
为什么大厂突然都上车了:一场信任的军备竞赛
有个细节值得琢磨:内容溯源这套东西,平时互相抢地盘抢得头破血流的几家公司,这回却站到了一条船上。C2PA联盟的指导委员会里,坐着Adobe、亚马逊、BBC、Google、英特尔、Meta、微软、OpenAI、索尼、Truepic一长串名字,成员和关联方到2026年初已经超过6000家。这种“竞争对手集体结盟”的场面,本身就说明问题——它们赌的是同一个未来。
为什么?因为对这些平台来说,AI内容泛滥是一把双刃剑。它们既是AI内容的生产方(模型都是自家的),又是内容的分发方(搜索、社交、浏览器都是自家的)。如果用户开始默认“网上的东西都可能是假的、是机器编的”,那整个信息生态的信任地基就塌了,受伤最重的恰恰是这些靠信任吃饭的平台。给内容建一套可核验的出处体系,本质上是在给自己的商业模式买保险。
各家的落地进度并不齐。Adobe走在最前,创意云全家桶——包括它的AI图像工具Firefly——都默认写入内容凭证;微软从2026年2月起给Microsoft 365的内容加AI水印和C2PA元数据,Bing和Designer也自动给AI生成内容打标;Google把凭证验证铺进搜索和Chrome;OpenAI则给ChatGPT出图统一挂上水印加清单。你会发现,生产端、编辑端、分发端、核验端,正被这几家一格一格地补齐。对独立站主来说,这意味着你迟早会站在一个默认要求“亮出身世”的环境里,早点熟悉规则,总比被规则推着走要从容。
机制拆解:一条内容的出处链是怎么签出来的
不用怕,机制其实不复杂,讲人话就三步。
第一步,生成或拍摄时打点。支持C2PA的相机(索尼、尼康、徕卡都有型号)、支持的软件(Adobe全家桶、Firefly、微软Designer)在你产出内容的那一刻,把“谁、什么设备、什么时间、是不是AI生成”写进一份清单。
第二步,每次编辑追加记录。你把图拉进Photoshop调个色、裁个边,这一步动作会作为新的一条追加进出处链。链条是累积的——原始来源、每一次修改、每一个经手工具,串成一条可回溯的历史。
第三步,密码学签名封存。整份清单用签发方的证书做数字签名。任何人拿到这个文件,都能验证签名是否完整、内容有没有在签名之后被动过。C2PA 2.1版本还专门加强了对篡改攻击的抵抗,对验证出处历史的技术要求收得更紧。
这套东西的妙处在于:它不判断内容“好不好”,只负责如实记录“从哪来、被谁动过”。判断权交还给看内容的人和引擎。这跟我们一贯的观点一致——真实性不是靠喊,是靠可核验的证据链。想深入理解AI时代“如何被认成可信实体”这件事,可以顺带看看我们拆过的 Google那份教AI认识你是谁的实体专利,逻辑是一脉相承的。
从相机到读者:出处链上到底谁在参与
光讲签名和清单还是有点抽象,我们把一条内容的出处链,从头到尾走一遍,看每一环上谁在干活。
源头,是采集设备。索尼、尼康、徕卡都已经有支持内容凭证的相机型号,快门一按,拍摄设备、时间、真实性签名就直接写进照片。这是最硬的一环——从物理世界进入数字世界的那一刻就打上戳,后面想伪造源头就难了。Google的Pixel手机也把C2PA支持塞进了相机。
中间,是编辑与生成工具。你把图拉进Photoshop、用Firefly生成一张、在微软Designer里改一版,每个动作都会作为一条记录追加进出处链。工具越是主流、越是原生支持,这条链就越完整。反过来,只要中间有一环用了不支持的工具,链条就可能在那里断掉。
末端,是分发与核验平台。内容发到Google、Bing、社交平台之后,核验能力决定了读者最终能不能看到这份身世。Google在搜索、Lens、Chrome里铺验证,Bing给AI图打标,读者理论上一点就能查。问题在于,这一端目前最不齐整——有的平台读得懂凭证,有的直接把凭证连同元数据一起清掉。
把这条链看完你就明白一件事:内容溯源不是某一家的产品,而是一整套需要全行业接力的基础设施。任何一棒掉链子,凭证都传不到终点。这也解释了为什么现阶段它还不完美——不是技术不行,是接力还没跑顺。对内容人的启示是:别指望这条链现在就替你把可信这件事全办了,你自己那一环的一手证据,仍然是最靠得住的。
C2PA不等于水印:三种真实性技术的分工
很多人把“内容凭证”“水印”“AI检测”混成一锅粥,其实是三样不同的东西,各管一段,缺一不可。
| 技术 | 它是什么 | 强在哪 | 弱在哪 |
|---|---|---|---|
| 内容凭证(C2PA元数据) | 附在文件上的签名清单 | 信息全、可回溯、密码学防篡改 | 一旦被剥离元数据就没了 |
| 数字水印(如SynthID) | 嵌进像素/音频里的隐形标记 | 压缩、截图、转存都不容易掉 | 信息量小,只标“是不是AI” |
| 数字指纹(fingerprinting) | 给内容算一个哈希去比库 | 不改原文件,事后能追溯 | 要有对照库,覆盖有限 |
看明白就懂了:为什么OpenAI和Google要搞“双层”。元数据信息全但脆,一上传到某些平台就被清掉;水印信息少但顽固,截图转存都还在。两个叠着用,才能既保留完整出处,又在元数据丢失时还剩一道“这是AI生成”的底线证据。指望单一技术解决全部问题,是外行才会有的期待。
和SEO/GEO到底什么关系:先按可验证性排序,再按质量排序
讲了半天技术,独立站主最关心的还是那句:这跟我排名、跟我被AI引用有半毛钱关系吗?有,而且关系正在变大。
逻辑是这样的。当AI内容把每个渠道都灌满,模型在决定“引用谁、把谁的话搬进答案”时,会越来越倾向于可验证来源的内容。Google不需要公开宣布“这个站用了AI”,它完全可以在AI概览的引用排序里,把出处可验证性当成一个隐性权重。换句话说:溯源信号会先按“可不可信”给内容分层,再在同一层里按质量排。你内容再好,落在“来源存疑”那一层,起跑线就低了一截。
这跟GEO的一条老规律严丝合缝:原创的一手内容更容易被AI搜索引用。为什么?因为一手、可溯源、有明确出处的内容,恰恰是模型在“真假难辨的海洋里”最想抓住的浮木。可验证出处,本质上是把“我是原创一手”这件事,从口头声明变成了机器能核验的证据。
举个具体的。同一个问题,两个站都写了答案,质量五五开。A站是匿名发布、图片来路不明、数据没标出处;B站作者是可查的真人、图带完整凭证、数据附了原始来源。当AI要从这两篇里挑一篇塞进答案、还要署上来源时,它更敢引哪个?答案不用猜。可验证性在这里起的作用,不是让B站“排得更前”,而是让B站“更值得被引用、被署名”——这在AI搜索时代,是比传统排名更值钱的位置。这也是我们一直强调的,别只盯着排名那个旧指标,被AI引用、被当成可信来源,才是下一轮真正的战场。
保哥的判断是:短期内,内容凭证不会是一个像标题标签那样立竿见影的排名杠杆;但中期,“按可验证性排序”会成为AI搜索的底层习惯。现在开始攒可验证的一手证据,是在给一年后的自己铺路。
内容凭证怎么核验:读者和引擎实际看到什么
说了半天出处能被核验,那核验的那一下,到底看到啥?举两个眼下就能摸到的场景。
第一个,是Google的“关于此图片”。你在Google图片、Lens或“圈图搜”里看到一张图,点开这个功能,如果这张图带着内容凭证,你就能看到它是不是被AI工具创建或编辑过。对普通用户,这是一次“背景核查”;对内容人,这是一面照妖镜——你的图在核验端被识别成什么样,直接影响别人对它的信任。
第二个,是专门的内容凭证查看器。把一张带凭证的图拖进去,它会像剥洋葱一样把出处链一层层展开:原始来源、用了哪些工具、有没有AI参与、每一次编辑发生在什么时候。这就是那份“数字营养标签”被读出来的样子。
对搜索引擎和AI模型来说,读的是同一份机器可读的清单,只不过它们不需要人点一下——抓取的时候顺手就把出处信息一起收了。这里藏着一个关键推论:你的出处信息,是同时说给“人”和“机器”两个读者听的。人看的是那面照妖镜给不给你背书,机器读的是那份清单能不能交叉验证得上。两个读者都满意,你的内容才算真正“经得起查”。
反过来想,如果你的内容在核验端“查无此人”——没有可读的出处、没有清晰的署名、没有一手证据——在一个越来越习惯“先查身世再决定信不信”的环境里,你就是在裸奔。裸奔在人少的时候没事,人一多,就尴尬了。
出处会成为明确的排名因子吗:别把“没明说”当“不影响”
这是最容易被带偏的地方,得掰开说。
截至目前,Google没有把内容溯源列为一个官方公布的正式排名因子。于是很多人松一口气:既然不是排名因子,那就不用管。这个推理,坑得离谱。
Google历史上大量真正起作用的信号,从来没被写进官方的排名因子清单——用户行为、品牌信号、实体权威,哪个是明着说的?“没有公开承认”和“不影响结果”是两码事。尤其在AI搜索这一侧,引用哪个来源、怎么描述你,本来就发生在一个不透明的黑箱里。指望Google发个公告告诉你“从今天起我按出处排序”,属于对平台运作方式的天真想象。
我们的原则一直是:官方沉默的地方,恰恰是要提前卡位的地方。等它写进官方文档,红利期早就过了。这条逻辑在AI可见性这件事上尤其成立——顺带一提,那些想把溯源信号反过来当黑帽玩、搞接地投毒的路子,我们在 < href="https://zhangwenbao.com/grounding-wars-ai-visibility-black-hat-playbook.html">AI推荐时代的黑帽正在成形那篇里已经拆过边界,这里不重复,只提醒一句:溯源这东西天生反造假,想拿它作弊是逆着风向跑。
内容凭证的软肋:为什么它经常“上传就没了”
吹了半天,该泼冷水了——不然你真去all in就该踩坑了。
内容凭证最大的软肋,是它作为附加元数据,非常容易在传播过程中被剥离。你辛辛苦苦签好一张图,往某些社交平台一传,平台后台为了压缩、为了隐私、为了省流量,可能顺手把EXIF和C2PA清单一起清掉。到了对方手里,那张图跟没签过一模一样。这也是为什么“双层方案”里非要塞一个像素级水印当兜底。
第二个软肋,是覆盖不均。相机端只有部分高端型号支持,手机端刚起步;软件端Adobe生态最完整,但你要是用别的工具链,很可能根本没有这一环。核验端也一样,Google在铺、但不是所有平台都读得懂内容凭证。整条链上任何一环断了,凭证就传不到终点。
第三个软肋更现实:它证明的是“出处”,不是“质量”。一份签得漂漂亮亮的内容凭证,只能告诉你这是真人用真相机拍的,不能保证内容本身有价值、没在胡说。别把“可验证”当成“可信任”的同义词——它俩是两回事。溯源解决的是“这是谁做的”,内容好不好,还得靠你自己的真本事。
还有个容易被忽略的对照:很多人指望用“AI内容检测器”来判断真假,但那类工具误判率高得离谱,把人写的判成AI、把AI写的放过去,是家常便饭。内容溯源走的是完全相反的路——它不靠“猜”这段文字像不像机器写的,而是靠“证”,用一份签好名的清单如实记录事实。从“概率性地猜”转向“确定性地证”,这才是溯源真正的价值所在。检测器是事后抓贼,溯源是事前发身份证,后者显然更靠谱。
所以态度很明确:了解它、提前布局、但别为一个还没成熟的标准过度投入技术改造。把精力放在那些无论标准普及与否都成立的一手证据上,才是稳的。
独立站主现在能做的7件事(不等标准普及)
好,落地。这7件事的共同点是:不依赖C2PA完全普及,现在做就有用,标准普及后收益还会翻倍。
- 把作者做成可核验的实体。真实姓名、真实简介、可考的履历、跨平台一致的身份。让Google和AI都能把内容归到一个“查得到的人”头上,而不是一个匿名内容农场。这是最不依赖技术、收益最确定的一件。
- 给原创内容留一手证据。原始数据表、访谈录音、实测截图、草稿演进记录——这些是你“一手原创”最硬的凭据。哪怕C2PA没铺开,这些证据也能在人工核验、在申诉、在建立权威时救你的命。
- 图片带上你能带的元数据。版权信息、作者、拍摄信息,能写就写全。支持 Content Credentials 的工具(比如Adobe系)产出的图,尽量保留凭证再发布。就算平台会剥,源头做全没坏处。
- 用结构化数据把署名和来源说清楚。作者、发布方、发布与修改时间、引用来源,用schema标记清楚。这是当下就能被引擎读懂的“半结构化溯源”,成本低、见效快。
- 建立引用与来源的透明习惯。你引了谁、数据出自哪、图哪来的,明明白白标出来。透明本身就是一种可验证性——它让核验方少费劲,也让你的内容更像“一手”而非“搬运”。
- 盯住核验端的动向。Google的“关于此图片”、各家的内容凭证读取能力在快速变。定期用这些工具查查自己的内容被识别成什么样,别等到出问题才发现自己在核验端“查无此人”。
- 把AI参与度如实标注。无论是不是为了合规,主动、诚实地标注哪些内容有AI参与,长期看是在攒信任,不是在减分。遮遮掩掩被识破,那才是真减分。
这7件事如果排个优先级,第1件(作者实体)和第2件(一手证据)是地基,投入产出比最高、最不看技术脸色,任何站现在就该做;第4、5件(结构化署名、来源透明)是当下引擎就读得懂的中层,成本低见效快;第3、6、7件(图片凭证、盯核验端、如实标注)偏工具与习惯层,跟着标准成熟度慢慢补即可。一句话概括这套打法:先把人和证据坐实,再谈技术和标签。把顺序搞反、一上来就折腾C2PA签发流程,很容易花大力气办小事。
一个真实的踩坑复盘:保哥团队的内容凭证乌龙
说个自己人的糗事,比讲道理管用。
2026年初,团队接了个出海储能品牌的内容项目,甲方特别在意“原创可信”,我们就动了心思:产品图全部用支持内容凭证的工具链产出、签好凭证,想着这下“真实性”这块稳了,还能当卖点。结果发出去一圈,问题来了——图往主流社交平台一发,凭证被平台压缩流程清得干干净净;AI搜索那边当时还读不到我们的凭证,等于我们对着空气签了一堆名。花的功夫,终端一点没感知到。
复盘出来两条,一直用到现在。第一,别指望元数据自动救你——它太脆,传播链上随时会断,把宝全押在凭证上是想当然。第二,真正起作用的是“人能核验、引擎能交叉验证”的一手证据:我们后来把原始产品实测数据、工厂实拍、第三方检测报告这些“硬料”补进内容里,配上清楚的作者署名和结构化标记,这套组合拳在建立信任和被引用上的效果,比那一堆被剥掉的凭证实在得多。
结论朴素得有点扎心:内容凭证是未来的好基础设施,但今天,能救你的还是那些最笨、最一手、最经得起核验的真东西。这也呼应我们反复讲的一件事——AI内容想不被反垃圾机制误伤,关键从来是流水线里那几个人工核查节点,而不是某个自动化的技术标签。
别做的三件事:把溯源做歪的三种姿势
新东西一出来,总有人第一反应是“怎么钻空子”。这三种姿势,劝你别有。
第一,别把溯源做成新的黑帽。伪造出处、给搬运内容套一层假凭证、或者反过来给对手内容投毒——这些路子在一个“天生为反造假而生”的体系里,是逆风局。短期或许有缝可钻,长期一定被反噬,因为整个系统的进化方向就是识别造假。
第二,别为合规而合规地过度投入。如果你的主要市场不在欧盟,8月2日那个deadline对你的直接约束有限,没必要连夜上一整套C2PA签发流程。抓住“可验证一手证据”这个不变的内核就够了,工具层等它成熟再跟不迟。
第三,别把AI参与藏着掖着。在一个正在铺开水印和凭证核验的环境里,“假装全人工”的谎言越来越容易被戳穿。与其赌运气,不如大方标注——这跟真实性验证在其他渠道的逻辑是一致的,我们在聊 < href="https://zhangwenbao.com/social-secondary-search-ai-authenticity-verification.html">社交平台正在变成AI二级搜索的真实性验证层那篇里也是这个判断:藏不如亮。
未来12到18个月:溯源从合规走向信任货币
把时间线拉长一点,保哥的预判分三步。
近期(半年内),它是合规话题。驱动力主要来自欧盟这类监管硬指标,大厂忙着把机器可读标注铺到位。对多数独立站主,这一阶段主要是“了解、观望、做无悔的一手证据”。
中期(一年左右),它变成信任信号。随着核验端在搜索、浏览器、聊天界面全面铺开,“有没有可验证出处”会开始悄悄影响内容在AI答案里的被引用概率。这时候,早就攒好一手证据的站,会吃到一波结构性红利。
远期(一年半以后),它可能成为信任货币。当可验证性成为内容的默认底座,“能不能证明你是真的”会像今天的HTTPS一样,从加分项变成不做就掉队的基础项。到那时,今天这篇里讲的布局,就成了别人眼里的“怎么当初就想到了”。
说到底,内容溯源不是一个新的SEO技巧,而是内容行业在AI洪水里重建信任的一次基础设施升级。技巧会过时,信任不会。前几年大家拼的是谁的内容更多、更快,接下来这几年,拼的会是谁的内容更经得起查、更值得被信。这不是唱高调,而是当造假成本趋近于零之后,市场必然会给“可验证”这件事重新定价。谁先把“可验证”当回事,谁就先站到了下一轮竞争的高地上。
常见问题解答
C2PA和内容凭证是一回事吗?
可以理解成标准和产品的关系。C2PA是内容来源与真实性联盟推的一套开放技术标准,规定了出处信息怎么记录、怎么签名、怎么核验。内容凭证(Content Credentials)是这套标准落到具体内容上、对外呈现的名字,就像文件上那份可查的“数字营养标签”。日常沟通里两者常被混用,不算大错。
我不做欧盟市场,还需要关心内容溯源吗?
欧盟《人工智能法案》第50条对你的直接法律约束有限,但内容溯源的影响不止于合规。Google、OpenAI这些平台把凭证与水印验证铺进搜索和聊天界面,是全球性的。只要你的内容想被AI搜索引用、想在真假难辨的环境里被信任,可验证出处的逻辑就跟你有关,跟你在哪个市场关系不大。
内容凭证会直接提升我的搜索排名吗?
短期内不会有立竿见影的排名效果,Google也没把它列为官方排名因子。但真正起作用的信号历来很多不在官方清单上。中期看,“按可验证性给内容分层、再按质量排序”很可能成为AI搜索的底层习惯。所以更准确的说法是:它不是一个即时杠杆,而是一项值得提前布局的长期资产。
给内容签了凭证,为什么发出去就没了?
因为内容凭证是附加在文件上的元数据,很多社交平台在上传时会为了压缩、隐私或省流量把它连同EXIF一起清掉。这是当前最大的软肋,也是OpenAI和Google要用“元数据加像素水印”双层方案兜底的原因——元数据丢了,还剩一道水印证明“这是AI生成”。
普通独立站主现在最该做的一件事是什么?
如果只能做一件,就是把作者做成可核验的真实实体:真名、真简介、可考履历、跨平台一致的身份,让内容能归到一个“查得到的人”名下。这件事不依赖任何技术标准普及,现在做就有用,还是溯源体系里最难被伪造的一环。做完这件,再往图片元数据、结构化署名、一手证据上叠。
内容凭证能防住深度伪造吗?
能帮上忙,但不是万能药。它的作用是“证明真的东西是真的”——给正规来源的内容盖上可核验的出处章。它没法阻止别人生成一段没有凭证的伪造内容,只能让“有凭证的正品”和“来路不明的东西”在核验时区分开来。所以它是防伪思路(证明正品),不是纯粹的验伪思路(抓出赝品),两者要配合水印、指纹等手段一起用。
权威参考资料
- C2PA官方“关于”页——内容来源与真实性联盟对内容凭证、出处链与“数字营养标签”框架的权威定义。
- Google官方博客:借C2PA提升生成式AI内容透明度——Google在搜索、Chrome、“关于此图片”中落地内容凭证验证的官方说明。
- OpenAI:推进内容溯源——OpenAI与Google对齐的C2PA加SynthID双层溯源方案官方公告。
- Content Credentials官方核验站——查看与验证媒体真实性、体验内容凭证如何呈现的官方入口。
- 欧盟《人工智能法案》第50条:透明度义务——2026年8月2日生效的AI生成内容机器可读标注与深度伪造披露条款原文。
- Semrush:AI搜索优化指南——为什么原创一手、可溯源的内容在AI搜索里更容易被引用的实战拆解。
本文标题:《内容溯源与C2PA:AI内容泛滥后,可验证出处正成为新的信任货币》
本文链接:https://zhangwenbao.com/content-provenance-c2pa-trust-currency-geo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0