文章写得又全又长却还是不行?谷歌现在看的是信息增益
本文目录
- 信息增益到底指什么,又不该被理解成什么?
- 为什么“写得更全更长”会越来越不灵?
- 覆盖度是有上限的公共品
- 去重与有用内容机制在主动压制复述
- AI摘要时代把这件事放大到极致
- 搜索引擎和AI是怎么“看见”雷同与增量的?
- 真正的增量信息,能从哪几个维度产生?
- 第一手数据与实测
- 反常识结论与失败案例
- 新的综合与判断
- 被系统性忽略的边界与例外
- 可落地性的跃升
- 时效性的真实跟进
- 特定人群或场景的纵深
- 动笔之前,怎么判断这篇到底有没有增量?
- 篇幅和增量,到底是什么关系?
- 增量会随时间被抹平吗,怎么维护?
- 在AI和GEO的格局下,这件事被放大成了什么?
- 怎么系统性地生产增量,而不是靠碰运气?
- 信息增益,怎么和几个长得像的概念区分开?
- 为什么“伪增量”比没有增量更危险?
- 一个真实的盘整过程长什么样?
- 哪些是最容易踩、又听起来很合理的坑?
- 不靠流量,怎么判断一篇的增量到底立没立住?
- 怎么把增量这件事变成可执行的工序?
- 常见问题解答
- 信息增益是不是Google某个可以优化的具体排名分数?
- 那是不是文章越短越好,长内容已经没意义了?
- 我没有第一手数据,是不是就没法做出增量?
- 动笔前怎么快速判断一个选题有没有增量?
- 用AI辅助写作,会不会天然没有信息增益?
- 为了和别人不一样,故意写个反常识结论行不行?
- 权威参考资料
摘要:看到对手某个词排第一,就写一篇更长更全的同题文章去盖它,这套打法早就不灵了,原因是搜索引擎和AI评估一个页面时,越来越不看你覆盖了多少,而看你相对于它已经见过的所有内容,多贡献了什么别处没有的东西。覆盖度是有上限的公共品,前十名加起来早把常识讲完了,你再讲一遍只是第N份拷贝,边际价值接近零。真正能让一个页面被排上、被AI引用并署名的,是它提供了结果集里别人没有的那一块——第一手数据、反常识结论、更强的可落地性、被系统性忽略的边界。这篇把信息增益的机制讲清楚,告诉你增量从哪几个真实维度产生、动笔前怎么盘、怎么别把它做成又一个能刷的指标。
有个动作几乎每个做内容的人都干过:盯上一个有价值的关键词,把当前排在前面的几篇挨个看一遍,然后写一篇“集大成”的——他们讲了的我都讲,再多加几个小标题、补一段常见问答、配一张目录,争取在篇幅和全面性上压过所有人。发出去,等。结果常常是石沉大海,或者短暂动一下又掉回去。这不是执行不到位,是这套以“更全更长”取胜的逻辑,本身已经和现在搜索引擎、AI的评估方式对不上了。要把这件事讲明白,得先搞清楚一个被很多人挂在嘴边、却很少有人讲透的机制:信息增益。
信息增益到底指什么,又不该被理解成什么?
先去掉神秘感。信息增益不是某个藏在算法里、有个具体数值、你优化几下就能拉高的“分数”。把它当成一个可以单独去刷的指标,方向从一开始就错了。它更准确的样子,是搜索引擎和AI在判断一个页面值不值得排上去、值不值得被引用时,背后那一组机制的统称——这组机制做的事情,是衡量你这个页面相对于系统已经索引过、已经见过的海量内容,多带来了什么。
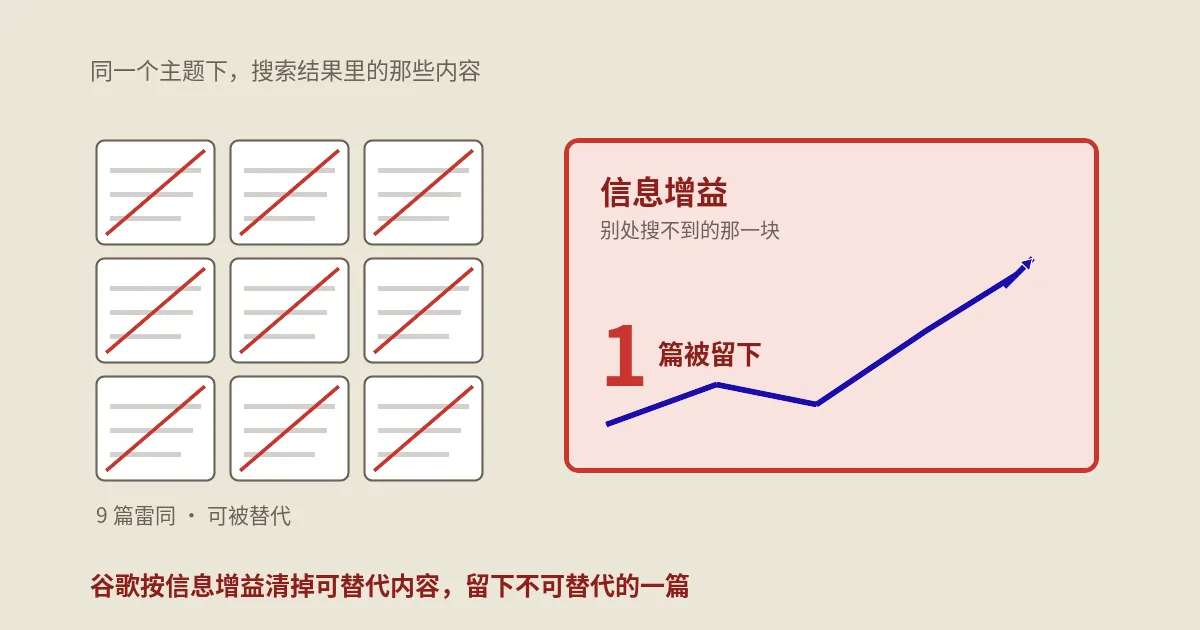
换个角度说,系统看你的页面,不是孤立地看它写得好不好,而是把它放进“关于这个查询,我已经知道的一切”这个背景里看:你说的这些,是已经被前面十篇讲烂了的,还是有它们都没有的东西?一个把前十名观点重新组织、换种说法复述一遍、没有任何新增的页面,写得再流畅、结构再漂亮,对系统而言的边际价值也接近于零,因为它没有让“关于这个问题人类已有的答案”变得更完整一点。理解这一点,是理解后面所有结论的地基。
为什么“写得更全更长”会越来越不灵?
这套打法曾经管用,是因为早期搜索更看重覆盖度和篇幅的代理信号。但它有个根本的天花板,现在被几股力量同时压下来了。
覆盖度是有上限的公共品
对任何一个成熟话题,排在前面的那些页面合起来,已经把常识性的内容覆盖得差不多了。覆盖度这种东西像公共品——第一个把它讲全的人贡献很大,第十个再讲一遍贡献几乎为零,因为那些信息已经在结果集里了。你以为自己写了一篇“最全的”,系统看到的是“第十一份大同小异的全”。它要的从来不是十一份雷同的完整,而是这个查询的结果集里,观点、事实、视角的多样性。
去重与有用内容机制在主动压制复述
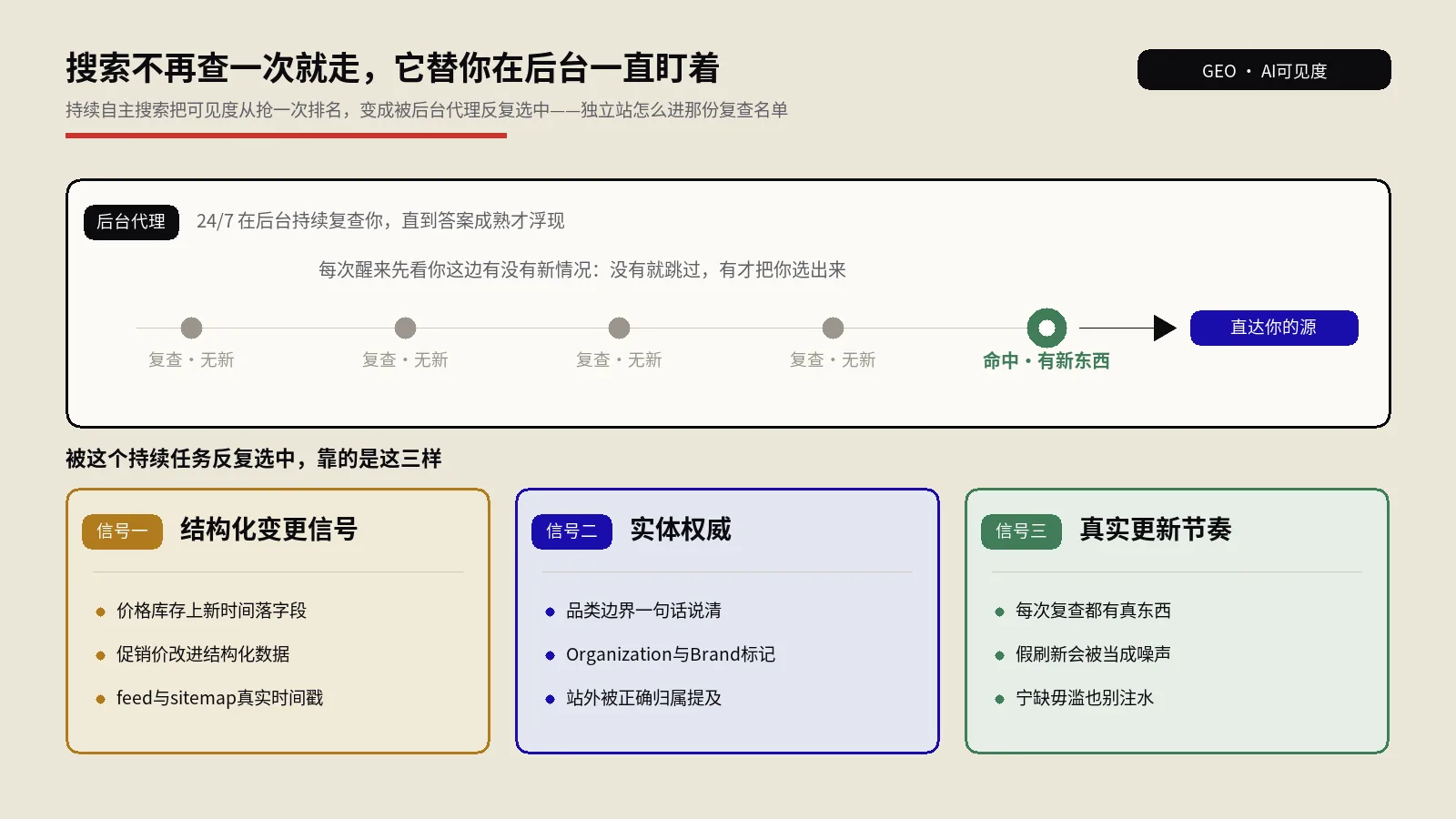
这些年搜索方对“把别人说过的话重新包装一遍”的内容越来越不客气。系统性地复述、缺乏第一手经验、为覆盖而覆盖的页面,本来就是有用内容这类评估要打压的典型。你那篇“更全的”如果实质是高质量的复述,恰好命中的就是被压制的特征,篇幅越长,反而越像在堆。
AI摘要时代把这件事放大到极致
这是最关键的一股力量。当用户的问题被AI一句话答完,雷同的来源之间是互相抵消的——十篇内容讲的是同一套,AI综合完只需要其中能讲清楚的一两篇,剩下八九篇连被点开的机会都没有,更别说被署名引用。在这种格局下,一个页面能不能被单独拎出来引用,几乎完全取决于它有没有提供别处答不出来的那一块。没有增量的内容,在纯搜索时代还能靠覆盖度蹭点流量,在AI答案时代是直接出局。
这也解释了开头那个常见现象——发出去石沉大海,或者短暂动一下又掉回去。短暂上去,常常是新内容有过一段被试探性给量的窗口;掉回去,是系统在那段时间里比对了它和已有结果集,发现它没贡献新东西,于是把临时给的位置收了回去。很多人把这解读成“可能是没做外链”“可能是更新频率不够”,反复在这些末端信号上加码,却始终没回答那个根上的问题:相对结果集,这一篇到底多了什么。绕开这个问题做的所有努力,都是在给一篇注定被追平的复述续命。
搜索引擎和AI是怎么“看见”雷同与增量的?
不必把内部算法说得神乎其神,但机制层面的大致样子值得讲清楚,因为它能解释为什么有些操作根本没用。现代搜索和AI处理内容,很大程度上是在一个语义空间里看的——意思相近的内容,在这个空间里会挤在一起。十篇讲同一套观点的文章,哪怕用词不同、排版各异,在这个空间里也彼此高度靠近,系统能很轻松地认出它们说的是一回事,于是其中大部分对“回答这个问题”的边际贡献趋近于零。这就是为什么换个说法复述、调整段落顺序、把同义词替换一遍这类操作完全没用:它们在表面上变了,在语义空间里还是原地踏步。
反过来,一篇内容如果带着别处没有的事实或判断,它在这个空间里就会落在一个相对孤立、别人覆盖不到的位置。系统在组织结果集、或者在拼一个AI答案时,是有意要覆盖到不同位置以保证答案完整和多样的,于是那个占据独特位置的内容,会因为不可替代而被选中、被引用。专利文档里描述的那种对“信息增益”的评分,更多是在已经召回的一批内容里做的一种排序后处理——先有候选,再看谁带来了别人没有的增量——这进一步印证了一件事:你得先有那块别人没有的东西,机制才有东西可识别,没有的话,再怎么优化排序信号也轮不到你。
真正的增量信息,能从哪几个维度产生?
关键问题来了:不靠注水、不靠生造,实质的增量到底从哪来。这里不是玄学,是有具体维度的,每一个都对应一种系统确实看重、别人确实难复制的东西。下面七个维度逐个说清机制,以及怎么判断自己这篇到底有没有摸到它。
第一手数据与实测
你自己跑出来的数字、亲手测过的结果、真实环境里观察到的现象,是最硬的一种增量,因为在你做这件事之前,这些数据在全网根本不存在,谁也复述不走、AI也合成不出来。它的稀缺性是结构性的——别人想要,只能自己再去做一遍。自查的方法很简单:把文章里的关键数字逐个圈出来,问每一个是不是来自你自己的测量或观察,如果全是从别处搬来的二手数字,这一维度你就是空的。
反常识结论与失败案例
绝大多数内容只敢讲“应该怎么做”,极少有人老实写“我们就这么做了,结果翻车了,根因是什么”。失败的细节、踩坑的代价、和主流说法相反却被验证过的结论,是结果集里最稀缺的视角,因为它有讲出来的成本,多数人不愿付。自查方法:通篇找一下,有没有至少一处是和排在前面那几篇的主流结论相左、且你能拿出依据的;一处都没有,说明你只是在和声,没有提供新的判断。
新的综合与判断
单点信息往往别处都有,但把分散在很多地方的碎片,第一次组织成一个能拿来做决定的判断框架,这个连接和取舍是你的增量。系统看重的不只是信息本身,还有“把它们串成可用判断”这层加工,这恰恰是纯复述给不出来的。自查方法:问自己这篇有没有一个别人没提出过的框架或判断主线,还是只是把已有观点按目录摆了一遍。
被系统性忽略的边界与例外
所有人都在讲主线场景顺利时怎么做,几乎没人讲边界条件、例外情况、这套方法什么时候会失效、什么前提下结论会反转。补上这块,等于补上了整个结果集的盲区,而盲区往往正是用户真正卡住、最想找答案的地方。自查方法:看文章里有没有明确的“什么情况下这条不成立”,只有正面结论、没有边界,说明你停在了所有人都停的地方。
可落地性的跃升
别人停在“是什么、为什么”,你给出能照着一步步复现的“具体怎么做、中途会遇到什么、怎么验证对没对”。从知道到能做之间那段,绝大多数内容是空的,把它填实就是实打实的增量,而且这种增量很难被泛泛复述抄走,因为它要求作者真做过完整一遍。自查方法:把你的步骤交给一个没做过的人,他能不能照着走通,走不通说明你写的还是概念不是做法。
时效性的真实跟进
别人的内容停在某个旧版本、旧规则、旧数据上,而你跟进了真实发生的变化,并讲清楚这个变化对原来结论的影响。这是一种会随时间不断再生的增量——只要世界在变,旧内容就在持续过期,谁先认真跟进谁就有新东西。自查方法:确认你写的是“截至现在的真实情况和它和过去的差异”,而不是把一篇旧文换个日期。
特定人群或场景的纵深
通用内容满天飞,但“在某个非常具体的处境下,这件事到底该怎么办”往往没人愿意挖到底,因为受众窄、写起来费劲。把范围主动收窄、在窄场景里挖到别人没到的深度,对那批人来说,你这篇的价值高到无可替代,这本身就是强增量。自查方法:问这篇是不是真的为某个具体人群解决到底了,还是又一篇谁看都行、谁看都不解渴的通用稿。
这七个维度有个共同点:它们要么来自你真做过、真测过、真踩过,要么来自别人偷懒没做的深挖,没有一个是靠把文章拉长、把小标题加多能变出来的。这恰恰说明,增量是个生产问题,不是排版问题——这也决定了它没法靠收尾时的优化补救,只能在选题和素材阶段就解决。
动笔之前,怎么判断这篇到底有没有增量?
最省事也最该做的一步,是在写之前就把这件事问清楚,而不是写完发出去靠运气。方法很笨但很有效,可以叫它增量盘点。
把当前排在前面的那几篇认真读完,不是扫一眼,是把它们的核心论点、给出的事实、用的视角逐条列出来,拼成一张“关于这个查询,结果集里已经有的东西”的清单。然后问自己一个很硬的问题:我这篇能往这张清单上添加,而它们都没有的,具体是哪几条?把它逐条写下来。如果你能清清楚楚写出三条以上、属于前面那些真实增量维度的东西,这篇值得写;如果憋了半天只能写出“我会讲得更清楚”“我会更全面”这种话,那说明你没有增量,这时候正确的动作不是硬写,是要么换一个能产生增量的角度,要么干脆别写——硬写出来的,就是那篇会石沉大海的“第十一份全”。
这个判断和站内话题撞车时该合并还是另写是一脉相承的,区别在于那是站内层面的重复问题,而增量盘点针对的是你这一篇相对整个结果集的边际价值,是单页机制层的判断,动笔前就该过这一关。
篇幅和增量,到底是什么关系?
这里要把一个被绑了很多年的东西彻底解开:内容长度和内容价值,没有必然关系。
长本身不是问题,没有增量的长才是问题。一篇两千字、但通篇是别处没有的第一手实测和反常识结论的内容,可以稳稳赢过一篇一万字、却全是常识复述加目录加问答堆出来的“大全”。反过来也成立:如果一个话题确实需要很长才能讲透,而每一段都在贡献别处没有的东西,那它就该那么长。问题从来不是字数,是单位篇幅里的增量密度。用字数、小标题数量、目录深度这些去当全面性的KPI,是把代理指标当成了目标本身,最后写出来的是“看起来很全、读完什么新东西都没记住”的内容——这种内容现在不只是没用,是被用户和AI同时惩罚的,因为它浪费了所有人的时间。
增量会随时间被抹平吗,怎么维护?
这里有个很多人没意识到的性质:增量是相对的,不是绝对的。你今天写出一篇带着独有第一手结论的内容,它的增量是相对当下结果集而言的;一旦别人跟进、把你那块也讲了,甚至AI把它学进了通用回答里,你这篇相对结果集的增量就被慢慢抹平了,哪怕你一个字没改。这解释了一个常见困惑——为什么有些内容明明没动,排名和被引用却慢慢往下走。这不是单纯的流量自然衰退,那是另一套机制;这里是你的差异化优势被结果集追平了,是增量层面的衰减。
所以有增量的内容也需要维护,但维护的正确含义不是“定期加点字”,而是定期重新做一次增量盘点:现在再看这个查询的结果集,我这篇当初独有的那几条,还独有吗?哪几条已经被人追上、变成常识了,哪些新的空白又出现了。维护动作应该是补上新的增量、替换掉已经变common的部分,而不是机械地把篇幅再撑大。把这件事和内容资产的盘点、衰退分级放在一起做效率最高,但要清楚你盯的指标不一样——那套盯的是流量和价值衰退,这里盯的是“我相对结果集还剩多少别人没有的东西”。两条线一起看,才知道一篇内容到底是该补增量、该合并、还是该退役。
在AI和GEO的格局下,这件事被放大成了什么?
前面提过AI摘要会让雷同来源互相抵消,这里把这条机制讲到底,因为它正在重新定义“被看见”意味着什么。
检索增强式的回答,本质是把多篇内容里的信息抽出来、压成一个答案。在这个过程里,提供同一套信息的来源是高度可替换的——系统从十个说同样话的来源里挑一两个就够了,其余的贡献为零。唯一不可替换的,是那个提供了别人都没有的那一块的来源:当答案里某个关键事实、某个反常识结论只有你讲过,系统要给出这部分,就绕不开你,引用和署名自然落到你头上。所以在GEO语境下,“被引用”这件事可以被翻译成一句很朴素的话——你贡献了这个答案里别处没有的一块。这和单纯把主题权威做到位还不一样:权威做到位却仍然不被选,很多时候恰恰是因为你权威归权威,但这一篇没有提供增量,关于这个具体问题,别人已经把能说的说完了。主题权威是入场资格,单页增量才是被这一次答案选中的理由。
怎么系统性地生产增量,而不是靠碰运气?
如果增量是个生产问题,那它就不能靠某个作者灵光一现,得有让增量稳定流出来的机制。否则就是好的时候撞上一篇有增量,差的时候一连串复述,全凭运气。
第一件事是把选题的判断方向倒过来。常见做法是先看哪个词搜索量大、然后想办法写一篇,这套路天然导向复述,因为搜索量大的词早被覆盖透了。正确的方向是反过来从“我们手里有什么别人没有的”出发:哪些数据只有我们有、哪些复盘只有我们经历过、客户反复问而公开内容答不好的是什么——从这些地方倒推选题,增量是天生就带着的,不是事后硬挤的。第二件事是把第一手素材当成一条要专门运营的管线。实测结果、项目复盘、销售和客服对话、内部踩坑记录,这些是增量的原矿,但它们默认是散落、会蒸发的,得有人定期把它们收集、结构化、变成可写的素材,而不是等要写了才临时去翻。第三件事是改激励。如果团队考核的是发了多少篇,产出必然滑向高产量的复述;要让被引用、被独立提及、那几条独有结论的可见度,进到评价里,作者才有动力去做更难但有增量的内容。第四件事是把增量写进内容简报:每篇动工前,简报里就该有一栏明确写清这篇的增量是什么、来自哪个维度,写不出就别立项。这件事和内容简报、生产规范是同一套工程里的,区别是简报解决“怎么把要求传达清楚不返工”,这里强调的是简报里必须有“增量”这一必填项,否则规范做得再细,产出的也只是规范化的复述。
信息增益,怎么和几个长得像的概念区分开?
这个概念特别容易和另外几个混,混了就会拿错方法去解决问题。逐个划清楚。
| 概念 | 它说的是什么 | 和信息增益的关键区别 |
|---|---|---|
| 信息增益 | 单页相对整个结果集贡献了多少别处没有的东西 | 这是基准 |
| 关键词自相残杀 | 站内多个页面争同一意图,互相内耗 | 站内重复问题,靠合并诊断解决,不是新颖度问题 |
| 可提取性 | 机器能不能干净地把你的内容抽出来 | 结构问题,内容再有增量抽不到也白搭,但抽得到不代表有增量 |
| 主题权威 | 站点在某领域累积的实体级权威 | 是入场资格,单页没增量照样不被这次选中 |
| 重复内容 | 技术层面近乎一字不差的副本 | 技术去重问题,和有没有提供新观点是两回事 |
用一句话串起来:可提取性保证你“能被读到”,重复内容处理保证你“不被当副本丢掉”,主题权威保证你“有资格进候选”,而信息增益决定的是“这一次到底选不选你、引不引用你”。前面几样都做好了却还是不行,问题往往就出在最后这一项——这一篇没有给出别人没有的东西。站内多页内耗那种情况,要走自相残杀的诊断与合并思路,可以参考关键词自相残杀那篇,那是另一类问题;机器抽不抽得到,是可提取性工程那篇的范畴;权威做到位仍不被选的更深原因,主题权威极限那篇讲得更透,本篇只补单页增量这一层。
认错的代价是实打实的,举个常见的误诊:一篇内容排不上,团队第一反应是“结构不够清晰、机器抽不干净”,于是花大力气改HTML语义、加标记、调层级,做完发现还是不动——因为它本来就抽得到,问题是抽出来的东西和别人一模一样,是增量缺失被误当成了可提取性问题。另一种误诊是把它当站内自相残杀,去做页面合并,合并完两篇变一篇,那一篇相对结果集还是没有增量,内耗解决了,没被选的根因一点没动。判断的口诀很简单:先确认抽得到、不是副本、站内不互相打架,这些都没问题却仍然不被选,几乎可以锁定是这一篇没有提供别人没有的东西——这时候唯一有效的动作是回到选题和素材去补增量,在结构和技术上再使劲都是南辕北辙。
为什么“伪增量”比没有增量更危险?
看懂了增量这么重要,有人会动一个危险的念头:那我编一个和大家不一样的结论不就行了。这是这套思路里最该被警告的歧路。没有增量,最坏不过是这篇被埋掉,是机会成本;伪增量是主动失实,代价完全不是一个量级。
机制上它会连环出事。一旦那个为了不一样而硬造的结论被读者或同行识破,受损的不只是这一页——你这个作者、这个站点的整体可信度会被连带怀疑,读者会回头重新打量你别的内容是不是也在编,这种信任崩塌是很难修回来的。更隐蔽的一层是,如果这种失实内容真的被AI当作增量学了进去并对外引用,等于你借系统的嘴在传播一个错的东西,等它被发现并被纠偏,反噬会更重,因为你不再只是“没价值”,而是“被标记为不可信来源”。还有一种常见的软性伪增量也要警惕:把别人也讲过的东西,包装成“只有我发现了的独家洞察”,本质是复述穿了件差异化的外衣,这种自欺会让团队以为自己有增量,从而停止真正的深挖。真增量必须来自你真做过、真测过、真想清楚的东西,它的对立面不是“平庸”,是“失实”,而失实是这门手艺里唯一不能碰的红线。
一个真实的盘整过程长什么样?
有家做出海工业设备的公司,自建了内容站,主打各类设备的选型和应用指南。负责内容的人很拼,每篇选型指南都写得比同行长、参数列得比谁都全,可大半年下来核心词排名一直卡在第二三页上不去,团队的判断是“写得还不够全”,于是又往里加参数、加品牌、加目录。
把那批文章和排在前面的对手内容并排读一遍,问题一下就清楚了:他们那些“最全”的指南,本质是把各家厂商官网的参数和说明重新组织了一遍,逻辑通顺、排版整齐,但里面没有一句是“我们实际把这台设备用在某种工况下,结果如何、哪里和参数表对不上、什么情况下会出问题”。也就是说,相对于结果集,这些页面的增量接近于零——它们覆盖的东西,前面那几篇早覆盖完了。改的方向不是再加内容,是换内容的来源:基于真实工况的实测表现、按使用环境给出的选型取舍、明确写出某些设备在什么条件下会翻车的失败教训,把那些厂商参数表里永远不会写、用户却最想知道的东西补上。结构没大动,篇幅甚至比原来还短了一些,但每一段都在贡献别处没有的判断。
这个诊断本身就是前面那套方法的现场演示。当时做的第一件事不是改稿,是把他们那篇和排在前面的几篇并排,做了一次减法测试——把所有重合内容划掉,结果他们那篇几乎不剩什么能独立成立的东西,而对手那几篇划完还各自留着一块自己的判断。这一下就定了性:问题不在写得不够全,恰恰在于全部都是别人也有的全,增量留存比接近零。后续的重写,本质就是按那七个维度里他们真正能拿出来的两三个(第一手实测、失败工况、按环境的选型判断)去重建,而不是再往那张已经满了的覆盖度清单上加东西。方法不是事后总结出来好看的,是当时就这么一步步走的。
变化是逐步发生的:那批被重写的页面先是停止下滑,随后核心词开始往第一页爬,再往后团队注意到,有人在AI工具里问相关设备怎么选时,答案开始引用他们写的那些工况结论——因为那部分内容,AI在别处确实找不到。这里不报具体名次和涨幅,因为同期站点也在做别的事,把单一数字归因到这一项不诚实;但机制是确定的:内容从复述变成增量,系统才有理由选你。客户型上这是个出海B2B工业设备站,换个完全不同的型机制也一样——一个做户外装备测评的内容媒体,靠的是把装备真带去恶劣环境用到坏的实测数据建立增量;一个在线教育平台的知识内容,靠的是把大量学习者真实卡点和走过的弯路系统化,这些都是别人复述不走的东西,型不同,逻辑完全一致。
哪些是最容易踩、又听起来很合理的坑?
- 照搬摩天大楼打法——“比第一名更长更全”这套,在覆盖度已饱和、AI会去重的今天,产出的基本就是会石沉大海的复述。
- 拿字数和小标题数当全面性KPI——把代理指标当目标,写出“看着很全、读完没记住任何新东西”的内容,被用户和AI同时惩罚。
- 用AI大批量生成同题内容——规模化生成的同题内容增量天然趋零,还集中命中低质判定,是在反方向用力。
- 以为加目录加问答就叫增量——这些是结构和可读性改善,不是新信息,结果集里没多出任何别处没有的东西。
- 只盯单页不看结果集——评估自己内容时不去读前面那几篇,等于闭着眼判断有没有增量,多半是自我感觉良好。
- 为了差异化生造结论——这是最危险的一种。没有真实增量就编一个反常识结论出来,伪增量比没有增量更糟,因为它失实,一旦被识破,连带整页和品牌的可信度。
不靠流量,怎么判断一篇的增量到底立没立住?
用总流量判断一篇内容的增量行不行,会严重误导,因为流量受太多别的因素影响,且反馈很慢,等流量给出信号,黄花菜都凉了。要换一组更直接、更早的信号。
第一个是被引用与被署名:拿这篇覆盖的那几个核心问题去问主流AI,看答案里会不会引用到你,尤其是那几条只有你讲过的结论有没有被原样采纳。如果AI在讲到那块时绕不开你,说明你的增量是实打实立住了的。第二个是被他人主动引用和提及:有没有别的内容在讨论这个话题时,把你那篇当作某个结论的出处来引,这是结果集里其他人对你增量的投票。第三个是独有结论的可见度:你那几条独有判断里的特征说法,在搜索里是不是能定位回你,能,说明这块在结果集里仍是你的。第四个是减法测试的留存比:定期把这篇和当下排在前面的几篇重新比对,划掉所有重合内容后还剩多少独立成立的东西,这个比例如果在下降,说明你的增量正在被结果集追平,该补新的了。这四个信号合起来,能让你在流量给出反馈之前,就判断这篇到底有没有真正贡献别处没有的东西,以及它还能撑多久。
怎么把增量这件事变成可执行的工序?
光懂机制没用,得能落到每一篇的流程里。三个动作,前中后各一个。
动笔前,做增量盘点:读完结果集前几名,列出已有清单,写下自己能新增的三条以上实质增量,写不出就换角度或不写。写作中,每写完一个核心段落,停一下问一句:这段讲的东西,前面那几篇里有没有?有,就要么删掉,要么改写成你独有的视角,别让复述占据篇幅。评审时,做一个减法测试:假设把这篇里所有和前十名重复的内容都划掉,剩下的还能不能独立成立、还有没有价值。剩得下扎实的一块,这篇就有底气;划完几乎不剩,说明它本质是复述,再改结构也救不回来。把这三个动作固定进流程,比记住一百条写作技巧都管用,因为它直接卡在价值的源头,而不是末端的修饰。
最后收束成一句话:在覆盖度早已饱和、AI会把雷同来源互相抵消的今天,决定一篇内容命运的不再是它讲得多全,而是它相对于这个世界已有的答案,多贡献了哪一块别处没有、又站得住的东西。把这件事想清楚、并且把它前置到选题和素材环节,比在文末做任何优化都重要——因为增量是没法在收尾时补出来的,它要么在你动笔之前就有,要么这篇从一开始就注定是结果集里第N份多余的拷贝。这不是又一条技巧,是这门手艺现在的地基。
常见问题解答
信息增益是不是Google某个可以优化的具体排名分数?
不该这么理解。它不是一个能单独去刷的数值,而是搜索引擎和AI评估页面相对已有内容贡献了多少新东西的一组机制统称。把它当可调指标,方向就错了,正确做法是真的去产生别处没有的内容。
那是不是文章越短越好,长内容已经没意义了?
不是。长短和价值没必然关系,没增量的长才是问题。话题确实需要很长才能讲透、且每段都在贡献新东西,它就该那么长。要盯的是单位篇幅里的增量密度,不是字数本身。
我没有第一手数据,是不是就没法做出增量?
第一手数据是最硬的一种,但不是唯一。反常识结论、失败案例、新的判断框架、被忽略的边界、可落地性跃升、时效跟进、特定场景纵深,都是真实增量来源。没数据就从这些没人愿意深挖的方向切。
动笔前怎么快速判断一个选题有没有增量?
把排在前面的几篇读完,逐条列出他们已有的论点和事实,再写下你能新增、他们都没有的具体几条。能写出三条以上扎实增量就值得做,只能写出“我会更全更清楚”就说明没有,该换角度或放弃。
用AI辅助写作,会不会天然没有信息增益?
用AI复述公开内容,几乎必然零增量还容易踩低质判定。但AI用来帮你整理自己的第一手数据、梳理失败复盘、组织独有判断是另一回事,关键不在用不用AI,在最终内容里有没有别处不存在的那一块。
为了和别人不一样,故意写个反常识结论行不行?
不行,这是最危险的做法。没有真实依据硬造的反常识结论是伪增量,比没有增量更糟,因为它失实。一旦被识破,整页和品牌的可信度一起赔进去。增量必须来自真实的东西,不能是为差异化生造的。
权威参考资料
本文标题:《文章写得又全又长却还是不行?谷歌现在看的是信息增益》
本文链接:https://zhangwenbao.com/information-gain-content-differentiation-mechanism.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0