语义化HTML到底影响AI抓取吗?拿样本页跑一遍就知道

本文目录
- 为什么“内容写得好”和“能被机器抽出来”是两件事?
- 机器到底是怎么“读”你的页面的?
- 它看的是DOM,不是渲染后的样子
- 标题树就是它理解的文章大纲
- 段落级排名和AI抽取,抽的为什么是“块”不是“页”?
- 让内容可被抽取的几条结构原则是什么?
- 答案先行,每个块的第一句能独立成立
- 一个块只回答一个问题,别把三个意思塞一段
- 用语义标签表达角色,而不是靠样式
- 标题是内容的语义延伸,不是视觉装饰
- 用列表、表格、定义把隐含结构显性化
- 哪些常见写法正在悄悄毁掉可提取性?
- 靠视觉假装层级:跳级标题与“伪标题”
- 答案依赖上下文:代词、“前面说过”、“如下图”
- 关键内容藏在交互后面:折叠、标签页、懒加载
- 关键信息只活在图片或纯排版表格里
- 结构化数据和语义HTML是一回事吗?
- 一个文档站是怎么把可提取性做上去的?
- AI时代,可提取性为什么从加分项变成了入场券?
- 可提取性和可访问性、性能是不是一回事?
- 可提取性怎么自查和纳入流程?
- 常见问题解答
- 权威参考资料
摘要:页面排版好看,和内容“能被机器干净抽出来”,是两件完全不同的事。搜索引擎的段落级排名和AI答案引擎,抽取的从来不是“你这一页”,而是页面里那一段最能回答问题的内容块。决定它能不能被抽出来的,不是你写得多深,而是你的HTML有没有把“哪一段是答案、哪一段是论据、哪一段是题外话”这件事用结构表达清楚。一个靠div套div、靠视觉而非语义传达层级的页面,人读着顺,机器抽出来是一团糊。可提取性是能被工程化的,而且它同时喂搜索段落排名和AI引用——这是当下投入产出比最高的on-page动作之一,可惜大多数人还没把它当回事。
有个现象,做内容的人多半遇到过:你写了一篇明显比对手详尽、专业的长文,对手那篇又短又浅,结果精选摘要、AI答案里被引用的,偏偏是它不是你。你反复检查内容质量、关键词、外链,找不出原因,最后归结为“算法玄学”。
它不是玄学。大概率的原因是:你的内容很好,但机器抽不干净。它想从你这篇里揪出那段能直接回答用户问题的话,结果你的答案埋在第六段中间、依赖前文才说得通、被一张图劈成两半、外面套了五层没有任何语义的div。对手那篇虽然浅,但答案就摆在小标题下面第一句,独立成立,结构清清楚楚。机器做的是“抽取”,不是“阅读理解”——在抽取这件事上,结构清晰打败内容深厚,是常态。
这篇保哥想把“内容可提取性”这件被严重低估的事讲透:机器到底怎么读你的页面、为什么它抽的是“块”不是“页”、让内容可被抽取的几条结构原则、哪些常见写法正在悄悄毁掉可提取性、语义HTML和结构化数据到底什么关系、它和可访问性性能又是什么关系,以及怎么把可提取性做成流程而不是靠某个人灵光一现。这件事不需要你写得更多,只需要你把已经写好的东西,组织成机器能看懂的结构。
先把这件事的定位说清楚:可提取性不是“锦上添花的优化项”,它是一个和内容质量正交、但同样决定生死的独立维度。你可以内容很好、可提取性很差,也可以内容一般、可提取性极好——在“被搜索段落排名选中”和“被AI答案引用”这两件事上,后者经常赢。把它当成和写好内容同等重要的事,是这篇唯一想让你接受的前提;接受了,剩下的全是可操作的工程动作。
为什么“内容写得好”和“能被机器抽出来”是两件事?
根源在于:人读页面和机器读页面,用的是两套完全不同的东西。人读的是渲染之后的视觉结果——字号大的你知道是标题,加粗的你知道是重点,空一行你知道是换了个意思,图文并排你自动把它们关联起来。这些理解,靠的是视觉呈现,跟底层用什么标签写的几乎无关。
机器不看渲染结果,它看的是结构本身。你用视觉手段表达出来的那些层级和关系——这是标题、这是重点、这一段和上一段是并列还是递进——如果没有同时用结构表达出来,机器就拿不到。一个用大号粗体文字假装的“标题”,人一眼看出是标题,机器只看到一段被加粗的普通文字,它不知道这是一个章节的开始。视觉和语义在你这边是统一的,因为你的大脑自动补全了;在机器那边它们是分开的,你没用结构说出来的,等于没说。
所以“内容写得好”保证的是“人读了有收获”,它完全不保证“机器能定位并抽出其中能回答问题的那一块”。后者是一个独立的、可以单独做好或做砸的维度。很多专业内容在搜索和AI里吃亏,不是输在内容,是输在这个维度——它们默认“写好了机器自然懂”,而机器从来不是这么工作的。
举个具体到能想象的画面。同一个问题,你写了一篇两千字深度长文,正确答案在第六段的第三句,前面五段是行业背景、历史沿革、概念辨析,那一句答案还带着“基于上面的分析”这种前缀。对手写了三百字,小标题就是那个问题,标题下第一句话直接给结论,干净利落。机器要为这个问题找一段话用,它扫到对手那篇,答案就在标题正下方、独立、完整,零成本拎走;扫到你这篇,它得先穿过五段无关内容,找到那句还残缺、还依赖前文的答案。它会选谁,几乎不用想。你输的不是这一仗的内容,是这一仗的“可被取用程度”——而这两件事,是可以分开训练的。
机器到底是怎么“读”你的页面的?
要做对可提取性,先得知道机器这一侧实际拿到的是什么。它不是拿到你屏幕上看到的那个漂亮页面,它拿到的是一棵结构树。
它看的是DOM,不是渲染后的样子
机器解析的是文档的结构树,也就是DOM——标签和它们的嵌套关系。它从这棵树里推断语义:遇到表示章节标题的标签,它知道这里开启了一个新主题;遇到表示列表的标签,它知道这是一组并列项;遇到表示主要内容区的标签,它知道这才是正文,侧栏和页脚不是。你的CSS让页面长什么样,它基本不关心;它关心的是这棵树有没有把内容的角色和层级表达出来。
这里有一步很多人不知道的前置动作:机器在抽内容之前,要先把“正文”和“模板噪声”分开。导航、侧栏、页脚、广告位、相关推荐、版权声明——这些每页都有、和本页主题无关的东西,叫样板内容,机器会尽量把它们剥掉,只在它判定为正文主体的那部分里去找答案。它靠什么判定哪块是正文?很大程度上靠语义结构。如果你用了明确表示“主内容区”的语义容器把正文圈起来,机器剥样板、定位正文又快又准;如果整页从头到尾都是无差别的div,它只能靠启发式去猜哪块是正文,猜错的代价是——你真正的答案可能被当成噪声剥掉了,或者一堆导航文字被当成正文混进了它的理解里。把正文用语义结构清晰地圈出来,是在帮机器第一步就别走错。
这里还有一个前置的、更致命的问题:机器得先拿得到这棵有内容的树。如果你的关键内容是页面加载后靠脚本才注入的,而抓取它的程序没有执行脚本、或执行得不充分,那它拿到的就是一棵空树——内容根本不在里面,后面谈再多结构都是空中楼阁。不同渲染方式对“机器能不能拿到内容”的影响,本身就是一道入场关:AI搜索为什么会跳过你的站、不同渲染方式怎么决定段落级竞争,是这一切的前提,结构做得再好,内容不在初始树里也白搭。
标题树就是它理解的文章大纲
在这棵树里,标题层级是机器理解文章结构最重要的一条线索。它会把所有标题按层级抽出来,拼成一份大纲——这就是它眼里你这篇文章的骨架。一级讲什么、下面分几个二级、每个二级又拆几个三级,文章在讲什么、各部分什么关系,它主要靠这份大纲来判断。
这意味着标题不是排版装饰,是你交给机器的目录。如果你的标题层级是按“这里想要个大字”随手选的——该是下级却跳了级,或者纯粹为了好看用了个标题标签包了句不是标题的话——你交给机器的就是一份错乱的目录。它据此理解的文章结构,和你真实想表达的结构就对不上,后面所有的内容定位都建立在这个错的骨架上。把标题写对,是可提取性里性价比最高、却最常被敷衍的一步。
段落级排名和AI抽取,抽的为什么是“块”不是“页”?
传统认知里,搜索是“给页面排名”。但现在很大一部分场景,无论是搜索的段落级排名、精选摘要,还是AI答案引擎,工作单位都已经不是“整页”,而是“页面里的一个内容块”。它要解决的是“用户这个具体问题,由哪一段话来回答最好”,然后把那一段拎出来——可能给你一个精选摘要,可能合进AI答案并标注引用来源。
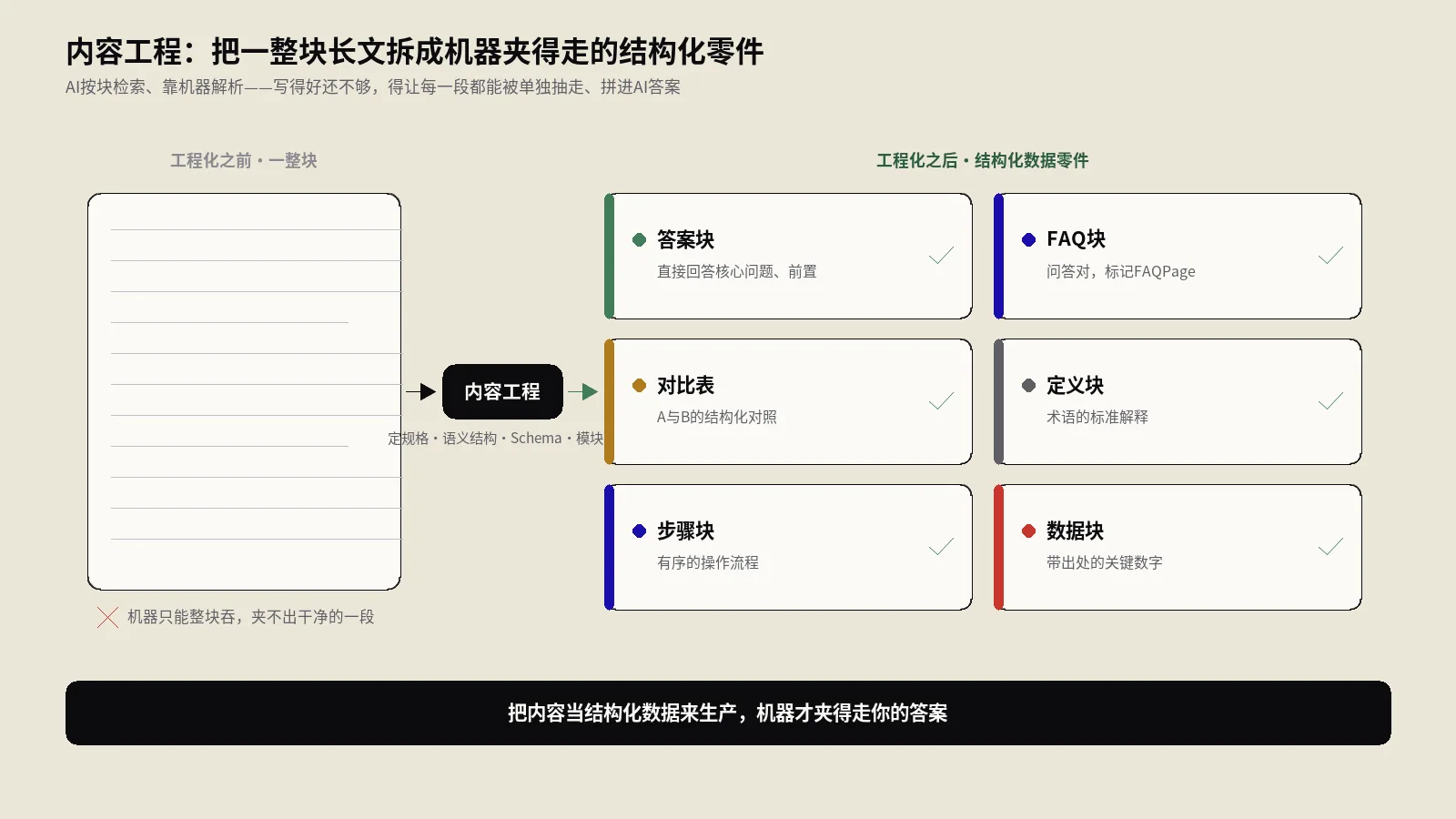
这件事的底层,是检索系统先把海量内容切成一个个块、按块去匹配和召回。切块不是按你的意愿切的,是按它的规则切的——通常顺着结构边界(标题、段落、列表项)来分。这意味着块的边界,实际上是你用结构画出来的:结构清晰,块就切得干净,一块就是一个完整意思;结构含糊,它只能按长度硬切,一刀下去经常把一个完整答案拦腰斩断,或者把两个无关的意思塞进同一块。现代搜索甚至能把用户直接定位、高亮到页面里那个具体段落,这种段落级深链的前提,同样是那一段在结构上是可被精确指向的一个单元,怎么写才不会让这种深链失效,本身就有讲究:Google段落深链的最佳实践、前端怎么悄悄弄坏它,是“块要能被精确指向”这条原则的一个具体侧面。
一个观点如果埋在长段落正中间、必须读完前面三句铺垫才说得通,它被切出来之后是残缺的,匹配不上、也没法直接用;一个观点如果就是某个块的开头一句、不依赖上下文也成立,它被切出来就是一个干净、可用、可引用的答案。同样的信息,前一种写法在“块”这个单位上几乎没有竞争力,后一种写法天然占优。这背后是整条排名流水线的运作方式决定的,召回和段落定位发生在哪一层、为什么“能不能被干净切块”直接影响你进不进得了候选,可以顺着这条线理解:搜索排名的召回到重排四层流水线是怎么运转的。理解了“单位是块”,下面的结构原则就全都有了出发点:你不是在排版一篇文章,你是在制造一个个能独立成立、能被干净抽取的块。
让内容可被抽取的几条结构原则是什么?
把“制造可被抽取的块”落成可执行的原则,核心就这么几条。它们不要求你改内容,只要求你改组织方式。
答案先行,每个块的第一句能独立成立
每一个小节,开头第一句话就应该是这一节核心问题的直接答案,能脱离上下文单独读懂。先给结论,再展开论据、条件、例外。这不仅是给人省时间,更是把“最该被抽取的那句”放在机器最容易定位、且切出来后最完整的位置。把答案藏在层层铺垫之后、最后才揭晓,是阅读体验上的悬念,是可提取性上的灾难——机器很可能切到的是你的铺垫,不是你的答案。
一个块只回答一个问题,别把三个意思塞一段
一个段落、一个小节,理想状态是只服务一个明确的问题。当你把“是什么、为什么、怎么做”三件事揉进同一大段,机器切块时无论怎么切都切不干净——切出来要么混着三个半截意思,要么为了完整不得不带上一大坨无关内容。一节一意,块的边界才清晰,抽出来才是一个完整且单一的答案。判断标准很简单:这一段能不能用一句话概括它在回答的那个问题?如果概括不出来,或者要用“以及”“还有”,它就该被拆开。
用语义标签表达角色,而不是靠样式
内容在页面里扮演什么角色——这是正文主体、这是一段引用、这是补充说明、这是一组并列项、这是一个定义——要用对应语义的标签表达出来,而不是用一个无语义的容器加一身CSS去“看起来像”。下面这个对比能说明问题:
<!-- 机器看不出角色:一堆无语义容器 -->
<div class="big">什么是可提取性</div>
<div class="text">它指内容能被机器干净抽取的程度。</div>
<!-- 机器一眼看懂角色:语义标签 -->
<h2>什么是可提取性</h2>
<p>它指内容能被机器干净抽取的程度。</p>两段渲染出来可以长得一模一样,人看没区别。但上面那段,机器只看到两个不知道是什么的盒子;下面那段,机器明确知道这是一个章节标题加它的正文。语义标签是你跟机器之间的共同语言,放弃它去用纯样式表达角色,等于你说的话机器一句都接收不到。
标题是内容的语义延伸,不是视觉装饰
承接前面说的标题树:每一个标题都应该是它统辖那块内容的真实概括,层级反映真实的从属关系,而不是“这里需要一个醒目的字”就放一个。一个写得对的标题树,光读标题就能复述全文脉络;一个写错的,标题之间逻辑断裂、层级混乱,机器拼出来的大纲就是错的。检验方法很朴素:把全文标题单独抽出来列成一串,它读起来是不是一份通顺、完整、不重不漏的提纲。是,结构就立住了;不是,先别管正文,回去修标题。
用列表、表格、定义把隐含结构显性化
很多内容里其实藏着强结构,只是被写成了散文。“做这件事分三步,第一……第二……第三……”塞在一个大段落里,人能看懂,但对机器,它就是一段连续文字,三个步骤的边界、顺序、并列关系全是隐含的。同样的内容如果用有序列表写出来,机器立刻拿到“这是一个有先后的三步流程”这个结构事实,不用猜。并列项用无序列表,对比维度用表格,术语和解释用语义上表示“定义”的结构——这些不是排版偏好,是把你脑子里的结构关系,从“藏在文字里要靠理解才能还原”变成“写在结构里机器直接读到”。
有个朴素的判断法:你写一段话时,如果心里在用“第一第二第三”“一方面另一方面”“A的话怎样、B的话怎样”这种结构在组织,那它本来就该是列表或表格,把它压成散文是在亲手把结构信息抹掉。该结构化的内容结构化,比任何标签技巧都直接地提升可提取性,因为你是在把隐含关系变成显式事实。
哪些常见写法正在悄悄毁掉可提取性?
反过来,有几类极其普遍的写法,几乎是在系统性地破坏可提取性,而且写的人毫无察觉,因为它们在视觉上完全没问题。
靠视觉假装层级:跳级标题与“伪标题”
两种最常见。一种是标题跳级——为了视觉效果,该用下一级的地方直接跳过,导致机器拼出来的大纲层级断裂,它无法判断这一块到底从属于谁。另一种是“伪标题”——明明是个小节标题,却用加粗大字的普通段落来做,没有用标题标签。人看着是标题,机器看着是一段恰好很显眼的正文,它根本不知道这里开了一个新主题。这两种都是典型的“视觉上成立、结构上不存在”,杀伤力极大且极隐蔽。
答案依赖上下文:代词、“前面说过”、“如下图”
这是专业作者最容易犯的。“如上所述”“下面会讲到”“这个问题”“如下图”——这些表达让文章读起来连贯,但每一个都是在给这个块打上“我离不开上下文”的标记。机器把这一块单独切出来,“这个问题”指什么没了,“如下图”那张图没跟过来,整块答案残缺。专业内容在AI引用里吃亏,这一条占了很大比例:它们写得太“连贯”了,连贯到每一块都无法独立。解法不是写得割裂,是在每个块内部把关键指代补全,让它即使被单独拎出来也信息完整。
关键内容藏在交互后面:折叠、标签页、懒加载
把关键答案放进默认折叠的手风琴、藏在需要点击的标签页里、或者靠滚动到才加载的无限滚动后段——这些交互设计对人没问题,点一下就出来。但对抓取程序,这些内容可能根本不在它拿到的初始结构里,或者被判定为“非默认可见、权重存疑”。你最该被抽取的那段答案,恰恰是机器最不容易拿到的那段。涉及核心内容时别赌机器会去点开它:重要的答案,别藏在任何需要交互才出现的地方。
关键信息只活在图片或纯排版表格里
还有一类很隐蔽。把一份关键数据、一个流程、一段重要结论做成图片放上去,好看、整齐,但图片里的文字对机器基本是不可读的——那段信息在它眼里等于不存在,你以为发布了,其实没发布给机器。同源的问题是“拿表格当排版工具”:用表格的行列去摆布局,里面塞的根本不是结构化数据,机器按表格去解析,得到的是一堆错乱的伪数据。原则很简单:凡是你希望被搜索和AI用到的信息,它的文本必须真实地、以可解析的结构存在于DOM里,图片、画布、纯排版表格都不算数。图片可以用来辅助,但承载关键信息的那份文本,必须另有一份机器读得到的。
结构化数据和语义HTML是一回事吗?
很多人一听“让机器读懂”,第一反应是“那我加结构化数据(schema/JSON-LD)不就行了”。这是个需要掰清楚的混淆。它俩是互补的两层,不能互相替代。
结构化数据是显式地、在正文之外,用约定格式告诉机器“这一页是一篇文章/一个产品/一组问答,它的标题是X、作者是Y”。它贴的是元信息标签。语义HTML是让正文主体本身的结构就能被解析——哪是标题、哪是答案、哪是论据、块的边界在哪。它治的是内容本体的可读性。结构化数据告诉机器“这页是什么”,语义HTML决定机器“能不能从这页的正文里干净抽出它要的那段”。
打个比方更直观:结构化数据像是给一本书贴上规范的图书馆分类卡——书名、作者、类别一目了然,方便检索系统快速归类;语义HTML则是这本书内部有没有清晰的目录、章节、段落划分。分类卡贴得再标准,如果书里面是一整团没有分段、没有章节、没有标点的文字,读者(机器)想从中精确找到并摘出某一段话回答某个问题,依然无从下手。两者解决的是不同环节的问题,缺了任何一个,机器要么不知道这是什么书,要么知道了也翻不到那一页。把精力全押在分类卡上、不管书的内部结构,是投入产出严重失衡的常见错配。
最常见的错误,是做了一身漂亮的结构化数据,正文却还是div套div的一团糊,然后困惑“标记都加了为什么还是不被引用”。因为结构化数据帮你拿到的是“这页有资格被理解成某类内容”的入场资格,真正决定那段答案能不能被精准揪出来用的,还是正文本体的语义结构。这也是为什么精选摘要这类“抽一段出来直接展示”的形态,对正文结构如此敏感——它选取和丢失的机制,本质就是在考验你的内容能不能被干净抽取:精选摘要为什么会丢、它的选取机制和AI时代价值重估,可以和本文对照着看,一个讲机制,一个讲你这边该怎么把结构做对。两层都做,机器才既知道这页是什么、又抽得动里面的内容。
一个文档站是怎么把可提取性做上去的?
讲一个保哥经手的真实例子,一个出海开发者工具的官方文档站。它的内容客观说相当扎实,工程师写的,准确、详尽。但它有个长期想不通的问题:很多概念和用法的查询,被引用、进精选摘要、被AI答案采纳的,是几个内容明显不如它的第三方博客,它自己的官方文档反而不在。
拆开看结构,问题很集中。第一,几乎全站靠div加样式排版,章节标题是带样式的div不是标题标签,机器拼不出文档大纲。第二,典型的一节是“先两三段背景铺垫,再上一大段代码,答案性的结论藏在代码之后”——机器切块切到的要么是铺垫要么是代码,最该被抽的那句结论位置最差。第三,大量“如前所述”“参见上一节”“见下方示例”,每一块都严重依赖上下文,单独拎出来全是残的。内容没问题,结构把内容的可抽取性几乎清零了。
重构没有改一个字的技术内容,只动结构:每一节开头补一句不依赖上下文、直接回答“这个概念是什么/这个用法怎么用”的结论句,代码和铺垫挪到结论之后作为支撑;所有章节标题改回真正的标题标签并理顺层级,让标题树本身就是一份可读的文档目录;把概念定义改用语义上表示“术语—解释”的结构组织;逐块排查并补全指代,让每一节单独拿出来都信息完整。机制上的变化是确定的:原本切出来残缺、匹配不上的块,变成了一个个能独立成立、能被直接引用的答案单元,它在“块”这个竞争单位上重新有了竞争力。这里没有任何内容升级,纯粹是把已有的好内容,组织成了机器能抽的形状。
这个文档站的例子里,有一个细节特别值得单拎出来:它的工程师团队第一反应是“那我们补一套完整的结构化数据标记”。这恰恰是前面说的那个经典误区——元信息标记加得再全,正文还是div套div、答案还埋在代码后面,机器依然抽不出那段结论。真正起作用的是改正文本体的结构,结构化数据是在这之后才补的、用来锦上添花,顺序反了就会先白忙一场还困惑“为什么没用”。
再补一个更短的对照。一个健康科普内容站,文章的医学内容由专业人士审过,质量没问题,但AI引用率长期偏低。根因几乎全在“答案依赖上下文”这一条:作者习惯写“如上文提到的这种情况”“这类人群(指前一段描述的人群)应当……”,专业、严谨、连贯,但每一条建议单独被抽出来都不知道在说谁。后来的调整很轻:每条结论性建议内部,把适用人群、前提条件就地说清,不靠前文。内容一个字没变深,可被引用的块却一下子立住了。两个案例是同一个道理:可提取性的瓶颈,极少在内容本身,几乎总在组织方式——这也是个好消息,因为组织方式是你完全能控制、且改起来不伤内容的东西。
AI时代,可提取性为什么从加分项变成了入场券?
过去,结构差一点,影响的是精选摘要这类锦上添花的位置,丢了可惜但不致命,自然排名还在。现在不一样了。当用户的问题越来越多地在AI答案里被直接解决,“能不能成为那个被合成、被引用的来源”,正在变成你能不能被看见的主线,而不是支线。
而能不能被AI引用,前置条件就是能不能在块这个粒度上被干净检索、被干净抽取。一个无法被切成清晰、自足的块的页面,在AI这条链路上,约等于不存在——不是排得靠后,是压根进不了那个被参考的候选集。这就是性质的变化:可提取性从“做了更好”的加分项,变成了“没有就出局”的入场券。它和写得好不好是两个正交的维度,但在AI时代,后者的天花板被前者锁死——内容再好,抽不出来,等于没有。把可提取性当成和内容质量同等优先级的事来投入,不是超前,是已经有点晚了。
可提取性和可访问性、性能是不是一回事?
不是一回事,但它们高度同源,理解这层关系能帮你少做重复功、还能把这件事在团队里讲通。
可访问性,是让屏幕阅读器等辅助技术能正确地把页面读给视障用户。它依赖的恰恰也是语义结构——屏幕阅读器靠标题层级让用户跳读、靠语义标签播报“这是导航、这是主内容、这是一组列表”。你为机器抽取做的那些结构工作,几乎原样地也在改善可访问性,反之亦然。一个对屏幕阅读器友好的页面,对搜索和AI的抽取大概率也友好,因为它们读的是同一棵语义树。这给了你一个特别有用的代理检验:用纯键盘和读屏的方式过一遍你的页面,哪里逻辑断裂、哪里读出来一团乱,那里大概率也是机器抽取会出问题的地方。
和性能的关系则在前面那道“机器拿不拿得到内容”的关上。一个为性能做了正确渲染处理、首屏内容稳定可得的页面,机器拿到完整结构树的概率高得多;一个把正文全压在脚本执行之后、首屏空荡荡的页面,性能差、可访问性差、可提取性也差,是同一个病根的三种症状。所以别把可提取性当成一件孤立的新活儿去额外立项——它和你本来就该做的语义化、可访问性、性能优化是同一套地基。把它们当成一件事来推进,阻力小,回报还叠加。这也是为什么保哥一直说,语义结构是那种“做对一次,搜索、AI、无障碍、性能一起受益”的少数高杠杆动作。
可提取性怎么自查和纳入流程?
最后落到怎么做。可提取性的好处是它高度可自查,几个朴素的测试就能暴露大部分问题。
- 大纲测试:把全文标题单独抽成一串读,是不是一份通顺、完整、层级正确、不重不漏的提纲。不是,就先修标题树。
- 独立成块测试:随机抽几个小节,假装它被单独拎出来,问“脱离全文,这段话还说得明白、还是一个完整答案吗”。不是,补指代、提前结论。
- 去样式测试:想象把所有CSS去掉,只剩裸结构。如果去掉样式后层级和角色就全乱了,说明你的结构本来就靠样式假装,机器看到的就是那个乱的版本。
- 首句测试:逐节看开头第一句,它是不是这一节问题的直接答案、能不能独立读懂。是铺垫就重排。
这四个测试里,“去样式测试”值得多说一句,因为它最能一眼照出真问题。方法是真的去做,不是想象:在浏览器里临时禁用页面所有CSS,看裸结构。一个可提取性好的页面,去掉样式后依然是一份逻辑通顺的文档——标题是标题、列表是列表、正文是正文,层级一眼可辨。一个靠样式撑着的页面,去掉CSS后会原形毕露:所谓的标题变回普通段落、精心排布的“表格”塌成一堆乱码、层级荡然无存。机器看到的,基本就是这个去掉样式后的版本。这个测试残酷但诚实,做一次胜过看十遍源码。
但靠人每篇手动自查,是扛不住量也留不住的。真正的解法是把它结构化进流程:把这几条做成内容质检清单里的硬项,写完不过这几关不算完成;把语义结构固化进内容模板和CMS——编辑能用的就是正确的标题层级、正确的语义块,想写错都不容易;新人入职就按这套结构训练,让“答案先行、一块一意、语义表达角色”变成默认动作而不是额外要求。还可以把部分检查自动化:标题层级有没有跳级、有没有空标题、有没有用错容器假装结构,这些都能写成规则在发布前自动拦截,不靠人肉记得。可提取性一旦变成模板、流程和自动校验的一部分,它就不再依赖某个人记不记得,而是结构性地、稳定地发生在每一篇上——这才是它真正的杠杆所在。
最后回到开头那个场景:你写得更深,却被更浅的对手抢走了引用。现在你知道,那多半不是内容输了,是内容没被组织成机器抽得动的形状。好消息是,这件事不需要你重写内容,也不需要更高的写作天赋,它需要的只是把“答案先行、一块一意、用结构而不是样式说话、别让任何一块离了上下文就残”这几条,变成你和团队的肌肉记忆。它朴素、不性感、容易被更花哨的优化盖过,但在搜索段落排名和AI引用同时成为主战场的今天,它可能是你手上回报最确定的那一块。
常见问题解答
问:内容写得好,机器自然就能读懂,不需要专门做结构吗?
答:不对。人靠渲染后的视觉理解内容,机器只读底层结构。你没用结构表达出来的层级和角色,机器拿不到。内容好只保证人读有收获,完全不保证机器能定位并抽出能回答问题的那一块,这是独立的一个维度。
问:为什么说机器抽的是“块”不是“整页”?
答:搜索的段落级排名、精选摘要、AI答案,工作单位都是页面里的内容块,不是整页。检索系统先把内容切块再按块匹配。答案埋在长段中间、依赖上下文,切出来就残缺;答案是块的开头、独立成立,切出来就干净可用。
问:加了结构化数据(schema),还需要做语义HTML吗?
答:需要,两者不能互替。结构化数据在正文外显式说明“这页是什么”,语义HTML让正文本体本身可被解析、能定位答案块。只做schema正文却是div一团糊,照样抽不出内容,这是最常见的错误。
问:可提取性差,最典型的症状是什么?
答:你的内容明显比对手详尽专业,但精选摘要和AI答案引用的是更浅的对手。多半因为你的答案埋在铺垫之后、依赖上下文、被图或代码劈开、外面套满无语义容器,机器抽不干净,而对手答案就在小标题下第一句。
问:把关键内容放进折叠面板或标签页,影响大吗?
答:影响大。藏在折叠、标签页、需滚动才加载的内容,可能不在抓取程序拿到的初始结构里,或被判为非默认可见、权重存疑。你最该被抽取的答案恰恰最难被拿到。核心答案别藏在任何需要交互才出现的地方。
问:专业作者写得很连贯,为什么反而不利于被引用?
答:连贯往往靠“如上所述”“这个问题”“如下图”这类上下文依赖。读着顺,但每一块被单独切出来就残缺:指代没了、图没跟来。解法不是写得割裂,是在每个块内部补全关键指代,让它单独拎出来也信息完整。
问:标题层级随便选,只要视觉醒目可以吗?
答:不行。机器把标题按层级拼成文章大纲,这是它理解结构的主线。跳级或用大字假装标题,会让它拼出错乱的骨架,后续内容定位全建立在错的结构上。标题是交给机器的目录,不是排版装饰。
问:AI时代可提取性到底有多重要?
答:它已从加分项变成入场券。能不能被AI引用,前提是能不能在块粒度被干净检索抽取。无法被切成清晰自足块的页面,在AI链路上约等于不存在——不是排得靠后,是进不了被参考的候选集。内容再好也被它锁死天花板。
权威参考资料
本文标题:《语义化HTML到底影响AI抓取吗?拿样本页跑一遍就知道》
本文链接:https://zhangwenbao.com/semantic-html-content-extractability-engineering.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0