Google Read more折叠看前面到底是怎么弄出的:5步实战指南
本文目录
- 搜索结果里多出来的那个Read more链接,到底把人带到哪?
- 它背后是同一套技术:Scroll-to-Text-Fragment怎么工作?
- 为什么这其实是段落级检索的延续,而不是孤立新功能?
- 和精选摘要、自家跳转目录有什么区别?
- 为什么内容必须对人立即可见,不能藏在tab和折叠里?
- 为什么页面加载时不能用JS抢滚动位置?
- 为什么不能在加载时改URL把片段指令抹掉?
- 既然每段都可能是第一眼,正文该怎么写?
- 前端框架里最容易踩的几个隐形杀手
- SSR、预渲染、hydration和深链的时序坑在哪?
- 不支持的浏览器会怎样?要不要担心降级?
- 怎么自己测出来页面有没有挂掉这个能力?
- 怎么把这个检测做成CI回归,而不是每次手测?
- 它对点击率和数据口径意味着什么?
- 一个B2B SaaS文档站被自己前端坑掉的复盘
- 常见问题解答
- Read more深链和精选摘要是一回事吗?
- 这个深链能力需要我给段落加id或做什么标记吗?
- 为什么我的SPA一进页面深链就失效了?
- 把内容放在选项卡或折叠面板里,深链会失效吗?
- 怎么自己测试页面有没有支持这个深链?
- 虚拟列表和懒加载会不会影响深链?
- 修这个对流量到底有多大帮助?
- 用了SSR或预渲染就稳了吗?
- 浏览器不支持会出问题吗?
- 权威参考资料
摘要:Google在搜索摘要里新增的“Read more / 阅读更多”链接,不是把人带到页面顶部,而是用Scroll-to-Text-Fragment技术把人精准滚动并高亮到页面里某一段——这个能力默认就有,但你自己的前端很可能正在亲手把它弄坏。官方给的三条最佳实践本质只解决一件事:别让前端干扰浏览器对这段文字的定位。具体就是三个机制:内容必须在加载时就真实渲染、对人可见,不能藏在tab、折叠、虚拟列表里;页面加载时不要用JS抢滚动位置把用户拽回顶部;加载时改URL(history API、改hash)不要把
#:~:text=这段片段指令抹掉。本文把这条深链的底层原理、和精选摘要的区别、三条实践各自的失效机制、前端框架里最容易踩的隐形杀手,以及一套你自己就能跑的检测方法讲透,最后用一个B2B SaaS文档站被自家前端坑掉的复盘收尾。读完你能当场判断自己的站有没有挂掉这个能力、错在前端哪一层。
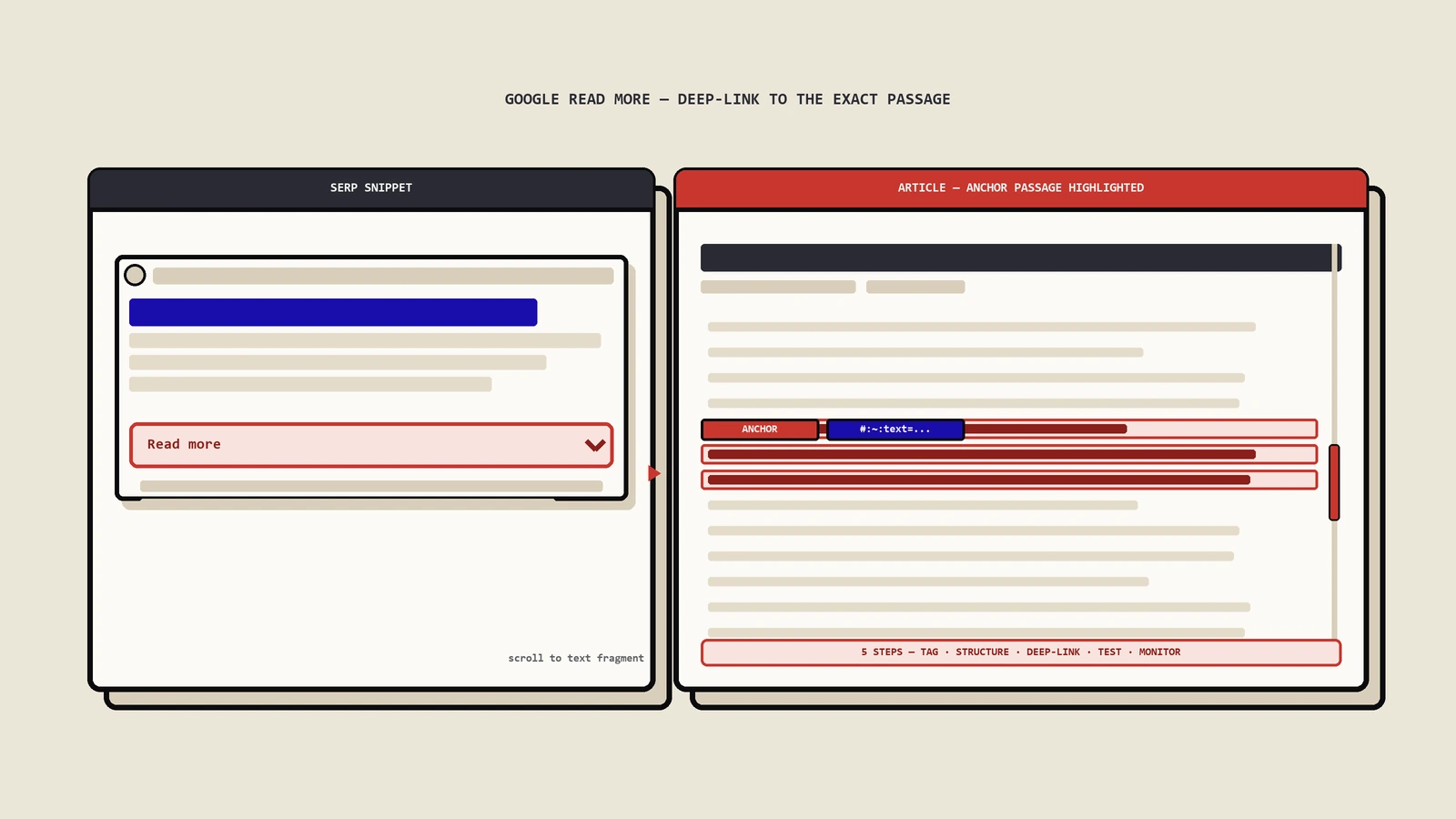
搜索结果里多出来的那个Read more链接,到底把人带到哪?
先说清楚它是什么,因为绝大多数人对它的理解是错的。它不是一个普通的“点进去到文章页”的链接——那种链接搜索结果里早就有了。它是一个会把用户直接滚动到页面正文某一具体段落、并把那段文字高亮起来的链接。用户搜了一个问题,Google判断答案在你这篇长文的第三屏某一段,于是给摘要补一个“阅读更多”链接,点进去浏览器不是停在页面顶部,而是唰地滚到那一段、黄底高亮,用户一眼看到他要的答案。
这件事的意义比“多一个链接”大得多。它意味着你页面里的每一个段落,都可能成为一个独立的落地点。过去一个URL就是一个入口,用户从顶部进、自己往下找。现在Google可以替用户跳过前面所有铺垫,直接把他空投到最相关的那一段。这对长内容、文档、指南类页面是巨大的机会,但前提是——浏览器那一下“滚动并高亮”能成功落地。它落不了地,这个链接Google要么不给你,要么给了用户点了却体验崩坏。三条最佳实践,全是在保证这一下能落地。
它背后是同一套技术:Scroll-to-Text-Fragment怎么工作?
这个“滚动到指定文字并高亮”不是Google的私有黑魔法,是一个公开的浏览器标准,叫Scroll-to-Text-Fragment(滚动到文本片段,常简称STTF),Chrome从80版开始支持。它的载体是URL末尾一段特殊的片段指令:
https://example.com/long-guide.html#:~:text=这里是要定位的一段原文关键是 #:~: 这个序列,叫片段指令(fragment directive)。:~: 之后的 text= 参数告诉浏览器:在页面里找到这段文字,滚过去,高亮它。它还支持更精确的定位语法,用来消除歧义:
#:~:text=prefix-,startText,endText,-suffix其中 startText,endText 表示“从这句开始到那句结束”这一整段,prefix- 和 -suffix 是前后文锚点,用来在页面里有多处相同文字时锁定唯一那一处。Google生成“Read more”链接时,就是自动算出能唯一命中目标段落的这串参数。
这里有一个极少有人讲、但直接决定你SPA会不会踩雷的机制:出于隐私设计,:~: 这段片段指令对页面里的JavaScript是不可见的。也就是说,你用 location.hash 去读,是读不到 :~:text=... 的——浏览器故意把它从暴露给脚本的hash里剥掉了(防止页面探测用户是从哪段搜索结果点进来的)。但它依然真实存在于地址栏、存在于浏览器拿到的原始URL里,浏览器自己会处理它。这个“脚本看不见、浏览器看得见”的不对称,正是后面第三条最佳实践会出大事的根源——你的SPA代码以为hash是空的就放心去重写URL,结果把浏览器还没来得及处理的指令冲掉了。
还要分清它和普通锚点的区别:普通锚点是 #section-id,需要页面里有对应 id 的元素,是你自己埋的跳转点;STTF是 #:~:text=原文,不需要你埋任何 id,浏览器靠匹配可见文本定位。Google的“Read more”用的是后者,所以你没给段落加id也能被深链——但也因此,它对“这段文字到底有没有真的渲染出来”这件事极度敏感。
为什么这其实是段落级检索的延续,而不是孤立新功能?
很多人把Read more当成又一个突然冒出来要应付的新花样,这个认知会让你低估它。把时间线拉开看,它是一条已经走了好几年的技术主线的显性化。
2020年起,Google给精选摘要做的就是STTF式的锚定加高亮——你点精选摘要的来源,落地不是页顶而是被抽出来那段,且高亮。2021年Google上线段落索引(passage indexing / passage ranking),核心思想是:一个页面整体没有为某个查询优化,但其中某一段恰好是最佳答案时,Google可以单独把那一段拎出来参与排名。检索的颗粒度从“页面”下沉到了“段落”。现在的Read more链接,是把这条主线第一次明明白白摆到用户眼前——既然Google早就在按段落理解和排序,那它当然也能按段落把用户送进来。
想通这条脉络,战略含义就出来了:你该按“这个页面里每一段都可能是某个用户的第一个落地点”来组织长内容,而不是按“用户都从顶部线性读下来”。这不是某个孤立功能的应对,是整个检索范式从页面级走向段落级之后,内容组织方式必须跟上的一次结构性调整。后面那条“正文该怎么写”,就是这个战略推论的具体落地。
和精选摘要、自家跳转目录有什么区别?
很容易把它和几个相似的东西混为一谈,但机制完全不同,搞混就会优化错方向。
| 形态 | 谁决定 | 定位方式 | 你能控制什么 |
|---|---|---|---|
| 精选摘要(零位置) | Google选取整段直接展示在SERP | 抽取你的内容显示在搜索页上 | 内容结构、可被抽取性 |
| Read more深链 | Google自动生成STTF链接 | 把用户滚到你页面内某段并高亮 | 前端别破坏定位(本文重点) |
| 站内目录 / 跳转锚 | 你自己埋的 #id | 跳到你预设的锚点 | 完全自己控制 |
| HTML id锚点 | 你写的 id 属性 | 跳到该元素,无高亮 | 完全自己控制 |
站内已经写过精选摘要怎么被选取、丢了怎么诊断,那是关于精选摘要选取与抢占机制的另一个话题——那篇解决的是“怎么让Google选中你的内容放到搜索页上”;本篇解决的是一个完全不同的问题:Google已经决定把用户深链到你页面里某段了,怎么保证你的前端别把这一下接砸。一个是“被不被选中”,一个是“选中之后接不接得住”,别混。同样,它和SPA在AI搜索里被跳过那条线也不同,AI搜索为什么跳过你的SPA站讲的是渲染导致内容根本进不了候选池,这里讲的是内容进得去、但深链落地被前端干扰,两者是抓取渲染链条上前后两段不同的病。
为什么内容必须对人立即可见,不能藏在tab和折叠里?
第一条最佳实践:确保内容在页面上对人立即可见,不要藏在可展开区块或选项卡式界面后面。它的机制是这样的:
STTF要定位一段文字,前提是这段文字在页面加载完成时,真实存在于渲染树里、且不是被 display:none 隐藏的状态。浏览器匹配的是“可见文本”。常见的几种把内容藏起来的写法,恰恰都让目标文字处于浏览器认为“不可定位”的状态:
- 选项卡(tab):非激活的标签内容通常用
display:none,那段文字在DOM里但不可见,STTF滚过去找不到,深链落空; - 折叠面板 / 手风琴(accordion)/
<details>未展开:内容默认收起,同理定位不到; hidden属性、visibility:hidden、content-visibility:hidden:都让文本不可被STTF命中;- 点击/滚动才异步注入的内容:加载时DOM里根本没有这段文字,更无从定位。
所以最常见的翻车现场是:把核心答案塞进“产品详情”标签页、把FAQ全做成默认收起的手风琴、把正文用“点击展开全文”折叠。这些做法在视觉设计上很常见,但它们等于亲手告诉Google:这段内容我不保证点进来能直接看到——于是Google要么干脆不给你这个深链,要么给了用户点进来滚到一片空白,体验比没有还差。正确做法是:希望被深链命中的核心内容,加载即渲染、默认可见,把折叠和tab留给次要信息。这条其实和无障碍访问、以及长期以来“重要内容别藏在交互后面”的SEO共识是同一个方向,现在多了一个非常具体的第三方理由。
为什么页面加载时不能用JS抢滚动位置?
第二条最佳实践:不要用JavaScript在页面加载时控制用户的滚动位置,比如别强制把滚动位置拉回页面顶部。机制在于一个时序竞争。
用户点Read more链接,浏览器拿到带 #:~:text= 的URL,会在页面加载过程中自行执行“找到那段文字、滚过去、高亮”。这个原生滚动发生在加载阶段。如果你的页面同时有这类JS在加载时也要动滚动条,两者就会打架,而且通常是你的JS后执行、把浏览器刚做好的定位覆盖掉。典型的肇事代码:
// 页面初始化时无条件回到顶部——会把STTF定位冲掉
window.scrollTo(0, 0);
// 或者关掉浏览器的滚动恢复后自己接管
history.scrollRestoration = 'manual';
window.addEventListener('load', () => window.scrollTo(0, 0));用户的真实体验是:点进来,画面先唰地滚到了正确那一段(浏览器干的),零点几秒后又被弹回了页面顶部(你的JS干的)。用户一脸懵,以为这链接是坏的。其他等价肇事场景还包括:吸顶导航栏用JS在load时做锚点偏移补偿、轮播或动画库在初始化时设定初始滚动、单页应用路由组件挂载时统一 scrollTo(0,0)。判断原则很简单:页面加载时,把滚动位置的最终决定权交给浏览器,你的JS不要在load阶段无条件抢滚动。需要回到顶部的逻辑,限定在“用户主动触发的导航”而不是“每次页面加载”。
为什么不能在加载时改URL把片段指令抹掉?
第三条最佳实践最隐蔽,杀伤力也最大,单页应用几乎人均踩雷:如果你在页面加载时调用History API或修改 window.location.hash,不要把URL里的hash片段删掉,否则深链行为会被破坏。
回到前面那个关键机制::~:text=... 这段片段指令对你的JS不可见,但真实存在于URL里,浏览器需要它来定位。大量SPA和分析脚本有一个习惯动作——加载时“清理”地址栏,把它们认为多余的部分去掉,让URL看起来干净。最常见的肇事写法:
// SPA启动时“规范化”URL——把片段指令一起抹了
history.replaceState({}, '', location.pathname + location.search);
// 或清空hash
location.hash = '';
// 路由库初始化时重写当前地址,同样会丢掉 :~: 指令这些代码的作者通常以为hash是空的(因为脚本读 location.hash 确实读不到 :~:,被浏览器藏起来了),于是放心地 replaceState 到一个“干净”地址。结果是:浏览器还没来得及完成STTF定位,URL里的指令就被你的代码删了,深链彻底失效。这就是“脚本看不见、浏览器看得见”那个不对称机制在真实项目里咬人的地方。正确做法是:页面加载阶段的任何URL重写、规范化、清理逻辑,必须原样保留URL的片段部分,绝不能因为 location.hash 读起来是空的就认为可以安全清掉。分析脚本里那种“去掉UTM和hash让上报URL干净”的常规操作,也要把片段指令排除在清理范围外。
既然每段都可能是第一眼,正文该怎么写?
前面三条最佳实践解决的是“别让前端弄坏定位”,是技术侧的减法。但还有一个内容侧的增量,原文完全没提,价值却很大:既然任何一段都可能成为用户进入你页面的第一眼,每个核心段落都得做到脱离上下文也能独立看懂。
具体到写作上有几条可直接执行的规范。第一,关键结论段不要依赖前文铺垫——用户被深链空投到这一段时,他没读过上面,如果这段的第一句是“因此,上述三种情况都应该这样处理”,他完全不知道“上述”是什么。把它改成自带主语的完整陈述。第二,少用悬空指代:如上所述、前面提到、综上、该方法、这种情况——这些词在段落级检索里是有毒的,因为“上”和“前面”对深链进来的用户不存在。第三,每个能独立回答一个具体问题的段落,前面给一个能被搜索查询直接命中的小标题或首句,相当于主动给Google提供“这段是回答什么的”信号。第四,定义和缩写别只在全文首次出现处展开,核心段落里第一次用到时给个一句话的就近解释,因为深链用户的“首次出现”可能就是这一段。
这套写法的副作用是全是正向的:它同时让内容对AI抽取更友好、对无障碍读屏更友好、对没耐心线性阅读的移动端用户更友好。段落自洽不是为深链单独做的妥协,是段落级检索时代内容的基本功。
前端框架里最容易踩的几个隐形杀手
上面三条原理清楚了,但真正咬人的往往是框架默认行为,团队自己都没意识到写了抢滚动或清URL的代码。几个高频隐形杀手:
- 路由库的滚动恢复:主流前端路由(如React Router的滚动恢复组件、Next、Nuxt的
scrollRestoration配置、Vue Router的scrollBehavior)默认或常见配置会在导航时统一把滚动归位,没人单独为“带片段指令进入”开口子,于是深链被路由的滚动逻辑直接吃掉。 - 虚拟列表 / 懒渲染:用react-window、虚拟滚动、列表分页懒加载的页面,目标段落在用户滚到之前根本没挂载进DOM。STTF加载时找不到这段文字,深链落空——这是文档站、长列表站最隐蔽的杀手,因为内容“看起来都在”,只是没在加载那一刻在。
- 图片懒加载引发的位移:目标段落上方有大量懒加载图片,浏览器先按无图高度算好位置滚过去,图片随后加载撑开布局,用户最终停的位置偏了一大截。这是布局偏移和锚定滚动叠加出来的细节bug,可参考Core Web Vitals的真实影响里关于布局稳定性的部分一并治理。
- 同意弹窗 / 插屏覆盖层:Cookie同意条、订阅弹窗、年龄确认这类加载时弹出的覆盖层,常带滚动锁定(
overflow:hidden锁body),浏览器的STTF滚动被锁死,用户关掉弹窗时定位窗口早过了。 - 骨架屏占位:先渲染骨架占位、真实内容延迟替换的页面,加载那一刻DOM里是骨架不是真文字,STTF同样命中不到。
- 即时翻译层:站点用JS自动翻译、或用户开了浏览器翻译时,目标段落的原文被替换成了译文。Google生成的深链锚的是原文,页面里已经没有那段原文,匹配失败——这是出海多语言站极易忽略的一类,尤其是那种检测到非目标语言就自动整页替换文案的实现。
这些没有一个是“写错了代码”,全是行业标配的工程实践,只是没人把它们和这个新出现的深链能力放在一起想过。这正是这件事的含金量所在:它不是要你做什么新东西,而是要你回头检查一批你早就觉得理所当然、其实正在悄悄破坏深链的默认行为。
SSR、预渲染、hydration和深链的时序坑在哪?
有人会想:那我上服务端渲染(SSR)或静态预渲染(SSG),内容首屏就在DOM里,不就稳了?方向对,但有一个更深的时序坑藏在水合(hydration)阶段,比单纯的抢滚动隐蔽得多。
SSR/SSG确实让目标文字在加载第一刻就真实存在,这对STTF是利好。问题出在前端框架接管这段静态HTML的过程:水合时,框架要把事件和状态绑回这棵已经存在的DOM树。如果水合实现得不干净——比如组件在水合时整体卸载重挂、用客户端结果替换了一片DOM、或者发生水合不一致(hydration mismatch)导致React抛弃服务端HTML整段重渲染——那么在水合那一小段时间里,目标文字可能短暂地从DOM里消失或位置剧烈变动。而浏览器的STTF定位恰好就在加载这个窗口里执行,正好撞上,结果就是定位到错误位置、或定位后内容被重挂导致高亮丢失。
这类bug的特征是“偶发、难复现”:网快、水合快的时候没事,网慢或设备弱、水合慢的时候才翻车,所以特别容易被开发在自己的好机器上测不出来。排查思路是用条件限速(DevTools的CPU/网络节流)放大水合窗口,再用深链进入观察定位是否在水合前后发生跳变。治理方向是让首屏关键内容的DOM在水合前后保持稳定、避免对包含深链目标的区域做卸载重挂式水合。这一层和渲染架构是连着的,JS SEO与SSR架构决策那篇的取舍框架可以一起用。
不支持的浏览器会怎样?要不要担心降级?
STTF不是所有浏览器都完整支持——Chrome系(含Edge)支持得最好,其他浏览器历史上支持程度不一。这会不会让这件事变得不值得做?两个澄清,结论是反而更该做。
第一,降级是安全的。在不支持片段指令的浏览器里,带 #:~:text= 的链接会被当成普通URL处理——用户照样进到正确页面,只是停在页顶而不是精准段落,体验退回到没有这个功能之前,不会报错、不会白屏。也就是说,把前端三条修对,对支持的浏览器是净收益,对不支持的浏览器零负作用,没有需要权衡的下行风险。
第二,要破除一个常见误解:这是纯客户端问题,服务端和CDN帮不上忙也碍不着事。片段在URL的 # 之后,按规范根本不会被发送到服务器,所以你的CDN边缘缓存、服务端路由、反向代理都看不到也处理不到这段指令——别在服务端或CDN配置上浪费时间找解法,问题100% 在浏览器加载时跑的那段前端代码里。想清楚这两点,就不会因为“反正不是所有浏览器都支持”而把一个低成本高确定性的修复无限期搁置。
怎么自己测出来页面有没有挂掉这个能力?
不用等Google给不给你Read more链接,这个能力你自己十分钟就能测,因为它用的就是公开的STTF。一套可照做的检测流程:
- 手搓一个深链:拿你某个长页面,复制正文靠下位置的一句原文,拼成
你的URL#:~:text=那句原文(文字记得做URL编码),在新开的Chrome标签页打开。正常应该唰地滚过去并黄底高亮。 - 测折叠场景:把目标文字换成藏在tab或手风琴里的内容,再用同样的深链打开。如果定位不到或滚到空白,说明你的折叠设计正在挡深链。
- 测加载抢滚动:用深链打开后盯着看——如果先滚对了又被弹回顶部,说明有load阶段的抢滚动JS,去查
scrollTo和scrollRestoration。 - 测SPA清URL:用深链进入SPA后立刻看地址栏,
#:~:text=还在不在。打开几百毫秒后被你的代码抹掉,就是第三条的雷,去查路由初始化和replaceState。 - 查加载时DOM:DevTools里在加载完成那一刻搜目标文字,看它是否已在DOM、是否带
display:none。虚拟列表和异步注入会在这一步现原形。
这套测试不依赖任何Google工具,因为深链落地是浏览器行为不是搜索行为。这也是它和很多SEO玄学的区别——它是可复现、可二分定位、能精确到哪一行前端代码的工程问题。把它纳入和抓取、渲染、索引同一套技术体检清单,按这五步逐页过一遍即可。
怎么把这个检测做成CI回归,而不是每次手测?
手工测一次能定位问题,但前端是天天在改的,今天修好下次重构又踩回去,没有回归就守不住。这件事完全可以自动化进CI,因为它的判定是确定性的、不依赖搜索引擎。
思路是用无头浏览器(Puppeteer或Playwright,底层就是Chrome,原生支持STTF)跑一组关键长页面的回归断言。每个用例的骨架是固定的:
// 伪代码:对一批关键URL做深链回归
for (const { url, probeText } of cases) {
const page = await browser.newPage();
await page.goto(url + '#:~:text=' + encodeURIComponent(probeText));
await page.waitForLoadState(); // 等到加载稳定
assert(page.url().includes(':~:text=')); // 断言1:片段没被前端抹掉
const y = await page.evaluate(() => window.scrollY);
assert(y > 0); // 断言2:没有被弹回页顶
const hit = await page.evaluate(() =>
!!document.querySelector('::target-text, mark, [data-sttf-hit]'));
assert(hit); // 断言3:目标文本命中并高亮
}三条断言正好一一对应三条最佳实践:地址栏片段还在不在(对应清URL那条)、滚动位置有没有被拽回顶部(对应抢滚动那条)、目标文字有没有真的被定位高亮(对应内容可见那条)。probeText选每个页面靠下、藏在风险结构里的真实句子,最能压出问题。把这套挂进CI,前端任何一次提交只要把深链能力改坏,流水线立刻红,根本不用等到线上Google不给你深链了才后知后觉。这类把一次性排查固化成持续防回归的工程纪律,比单次修复值钱得多——单次修复管一次,回归守护管长期。
它对点击率和数据口径意味着什么?
把技术机制说完,回到生意层面:这件事值不值得花工程时间修?两个角度。
第一,它在搜索结果里给你的摘要多挂了一个醒目的蓝色链接,等于多占了一点SERP版面、多给了用户一个点进来的钩子,方向上是争取更多点击而不是更少。对内容长、信息密度高的页面,这个增量不该被放过——尤其当你的竞品页面把内容藏在tab里、深链拿不到,而你的不藏,这就是一个结构性的展现优势。
第二个角度更微妙,是数据口径会变。用户从Read more进来,落地的不再是页面顶部,而是正文中段。这会让你的分析数据出现一批“从中部进入”的会话:滚动深度起点不是0、首屏停留行为异常、跳出判断口径都受影响。如果你不知道有这回事,可能会把这些“反常”数据误读成页面体验出了问题,做出错误优化。正确的认知是:深链带来的中段落地是结构性的新常态,衡量长内容时要把“从摘要深链进入”当成一类独立的入口来理解,而不是和顶部进入混在一起算平均。把这条纳入对页面互动数据的解读框架,比纠结单个跳出率数字有用得多。
一个B2B SaaS文档站被自己前端坑掉的复盘
保哥手上一个做B2B SaaS的客户,产品帮助中心是个典型的现代文档站:单页应用框架、左侧目录、长文档页、FAQ用手风琴折叠。它恰恰是最该吃到深链红利的形态——文档页又长又全,用户搜的多是“怎么配置某功能”这种能精确命中某一段的问题。但接手时它几乎把三条最佳实践反着踩了个遍。
排查过程本身就是上面那套检测流程的实战。手搓深链测试,第一现象就是点进文档页先滚到了正确小节、半秒后被弹回页面顶部——定位到框架路由组件在挂载时无条件 scrollTo(0,0),命中第二条。继续测发现地址栏里的 #:~:text= 进来后很快消失——文档站启动时有一段“规范化URL”的逻辑,作者以为hash是空的就 replaceState 清掉了,命中第三条。最后那批折叠的FAQ,深链根本定位不到收起的答案,命中第一条。三条全中,难怪它的文档页几乎拿不到Read more深链。
修复动作完全对应机制,没有一处是玄学:路由的加载时抢滚动改成只在用户主动导航时执行、对带片段指令进入的情况让行;URL规范化逻辑显式保留片段部分;最该被搜到的核心配置说明从手风琴里拿出来改成加载即可见,把折叠只留给边角信息。这里不写“流量涨了百分之多少”那种数字——深链带来的增量高度依赖页面长度和查询结构,给个精确百分比反而是误导。真正可靠的结论是结构性的:一个长内容站如果前端把这三条踩反了,等于主动放弃了Google愿意免费送的一个额外入口,而修复它靠的不是写新功能,是回头把几个习以为常的默认行为关掉——成本极低,却很少有人去查。
常见问题解答
Read more深链和精选摘要是一回事吗?
不是。精选摘要是Google把你的内容抽出来直接显示在搜索结果页上,解决的是“被不被选中展示”;Read more深链是Google用Scroll-to-Text-Fragment把用户滚动并高亮到你页面内某一段,解决的是“选中之后你的前端接不接得住”。一个在搜索页上,一个在你自己页面里,优化方向完全不同,别混。
这个深链能力需要我给段落加id或做什么标记吗?
不需要。它基于Scroll-to-Text-Fragment,靠匹配页面可见文本定位,不依赖你埋的 #id 锚点。你要做的不是加标记,而是别破坏它:内容加载即渲染可见、加载时别用JS抢滚动、别在加载时把URL里的 #:~:text= 片段指令清掉。是做减法不是做加法。
为什么我的SPA一进页面深链就失效了?
大概率是启动时清理了URL。片段指令 :~:text= 出于隐私设计对JavaScript不可见,location.hash 读起来是空的,很多路由或规范化代码据此 replaceState 到“干净”地址,把浏览器还没处理完的指令删了。修复方法是页面加载阶段任何URL重写都显式保留片段部分,不要因为hash读着是空就清。
把内容放在选项卡或折叠面板里,深链会失效吗?
会。Scroll-to-Text-Fragment只能定位加载时真实渲染、未被 display:none 等方式隐藏的可见文本。tab非激活页、未展开的手风琴、hidden 属性、点击才注入的内容,都让目标文字处于不可定位状态。希望被深链命中的核心内容应加载即可见,折叠只留给次要信息。
怎么自己测试页面有没有支持这个深链?
不用等Google。复制页面靠下的一句原文,拼成 你的URL#:~:text=那句话(文字做URL编码)在Chrome打开,正常会滚过去并高亮。再分别测折叠内容、看是否被弹回顶部、看地址栏片段是否被抹、DevTools查加载时目标文字在不在DOM,就能二分定位到是三条里的哪一条出问题。
虚拟列表和懒加载会不会影响深链?
会,而且很隐蔽。虚拟滚动、react-window这类懒渲染,目标段落在用户滚到前根本没挂载进DOM,加载时STTF找不到就落空,内容“看着都在”其实没在加载那一刻在。上方图片懒加载还会因布局偏移让定位停错位置。长文档站尤其要排查这两类。
修这个对流量到底有多大帮助?
它在搜索摘要里多给你一个醒目链接,多占SERP版面、多一个点击钩子,方向上利于争取更多点击,长内容页收益更明显。但具体增量高度依赖页面长度和查询结构,给精确百分比是误导。更可靠的认知是:修复成本极低(多是关掉几个默认行为),而不修等于主动放弃一个Google免费给的额外入口。
用了SSR或预渲染就稳了吗?
方向对,但有个更深的坑在水合阶段。SSR让内容首屏就在DOM里利于定位;但水合时如果组件卸载重挂、或发生不一致导致整段重渲染,目标文字会在浏览器执行定位那一刻短暂消失或位移,造成偶发、难复现的定位失败,往往网慢、设备弱时才暴露。治理方向是让首屏关键内容的DOM在水合前后保持稳定。
浏览器不支持会出问题吗?
不会,降级是安全的。不支持片段指令的浏览器会把它当普通链接,用户照样进正确页面,只是停在页顶,不报错不白屏。把三条修对,对支持的浏览器是净收益、对不支持的零负作用,没有下行风险。另外这是纯客户端问题,片段不发往服务器,CDN和服务端看不到也帮不上忙,别在那儿找解法。
权威参考资料
本文标题:《Google Read more折叠看前面到底是怎么弄出的:5步实战指南》
本文链接:https://zhangwenbao.com/google-read-more-deep-link-passage-anchor-best-practices.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0