SPA站AI爬不到的真相:四种渲染模式对比与段落级被引用诊断
本文目录
- 为什么AI搜索看不到你的SPA站
- SPA站在4家AI引擎里的真实状态
- SPA加SSR是不是就解决了问题
- 段落级竞争:AI怎么把你3000字长文切成20个独立候选
- chunk边界的实际划分规则
- passage级竞争的实操含义
- chunk优化的具体改写动作
- query fan-out:一个查询如何变成20个sub-query并行检索
- query fan-out的实际工作机制
- fan-out偏好的内容架构
- retrieval vs citation:被索引≠被引用
- 两层结构的实际差异
- 怎么判断你处在哪一层失败
- retrieval失败的常见根因
- citation失败的常见根因
- 决定段落被选中的两个核心信号:information gain和topic depth
- information gain的定义和落地
- topic depth的两个层面
- AI检索失败诊断:retrieval问题还是quality问题
- retrieval问题的快速诊断动作
- quality问题的快速诊断动作
- 修复优先级:技术修复先于内容投入
- retrieval修复阶段——预计耗时2到4周
- quality迭代阶段——持续3到6个月
- retrieval vs quality的投入回报对比
- 常见问题解答
- SPA站非要SSR迁移吗用prerendering插件够吗
- tab和accordion完全不能用吗
- AI检索的chunk size有具体上限吗
- FAQPage结构化数据能提升AI citation吗
- Perplexity不索引我的站点是不是没救了
- information gain怎么持续产生不是一次性资产
- cluster架构具体怎么设计
- AI citation的数据怎么追踪没专门工具
- 权威参考资料
摘要:AI检索是在passage段落级别召回与引用,而不是页面级。SPA站靠CSR渲染导致首屏HTML是空的,Perplexity和Gemini完全看不到内容。本文讲清AI怎么把长文切成独立候选、查询扇出机制、被索引不等于被引用,给信息增益与主题深度两个核心信号和retrieval与quality二维诊断框架。
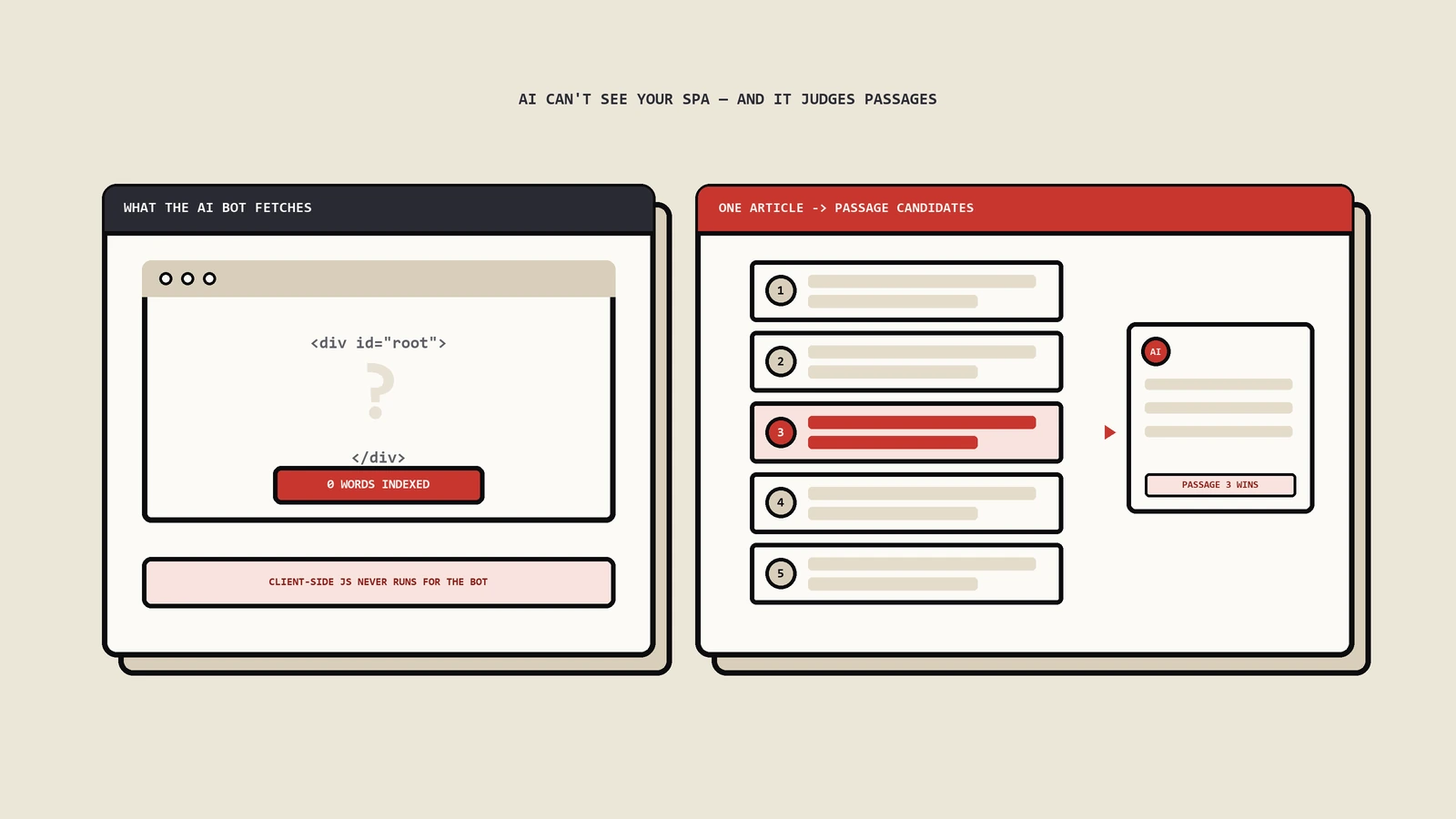
用 curl -A "PerplexityBot/1.0" 抓一个React SPA站的产品页——返回HTML里只有一个空 <div id="app"> 和一坨JS引用,product名称、规格、评论全部不存在。这就是Perplexity看你站的样子。Gemini URL grounding拿到的也是同一份空白页。然后再去Perplexity搜你产品的相关查询——零次citation。这不是内容问题,是技术可见性问题。但还有一种更隐蔽的失败:内容能到AI候选池,每次都输给竞品。这两种失败的修复路径完全不同。
更关键的是另一种隐藏失败模式——内容能到候选池但每次都输给竞品。这不是技术问题,是段落级的内容质量竞争。这篇把"AI跳过你内容"拆成两类失败:retrieval失败(系统看不到)和quality失败(系统看到了但选了别人),各给诊断清单和修复路径。SPA框架部分单独拆一节,把React/Vue/Next.js/Nuxt/SvelteKit 4种典型组合对AI检索的实际表现讲透。保哥过去半年帮3家SaaS客户做过这两类失败的诊断,文里的检查清单都是从实测里整理出来的。
为什么AI搜索看不到你的SPA站
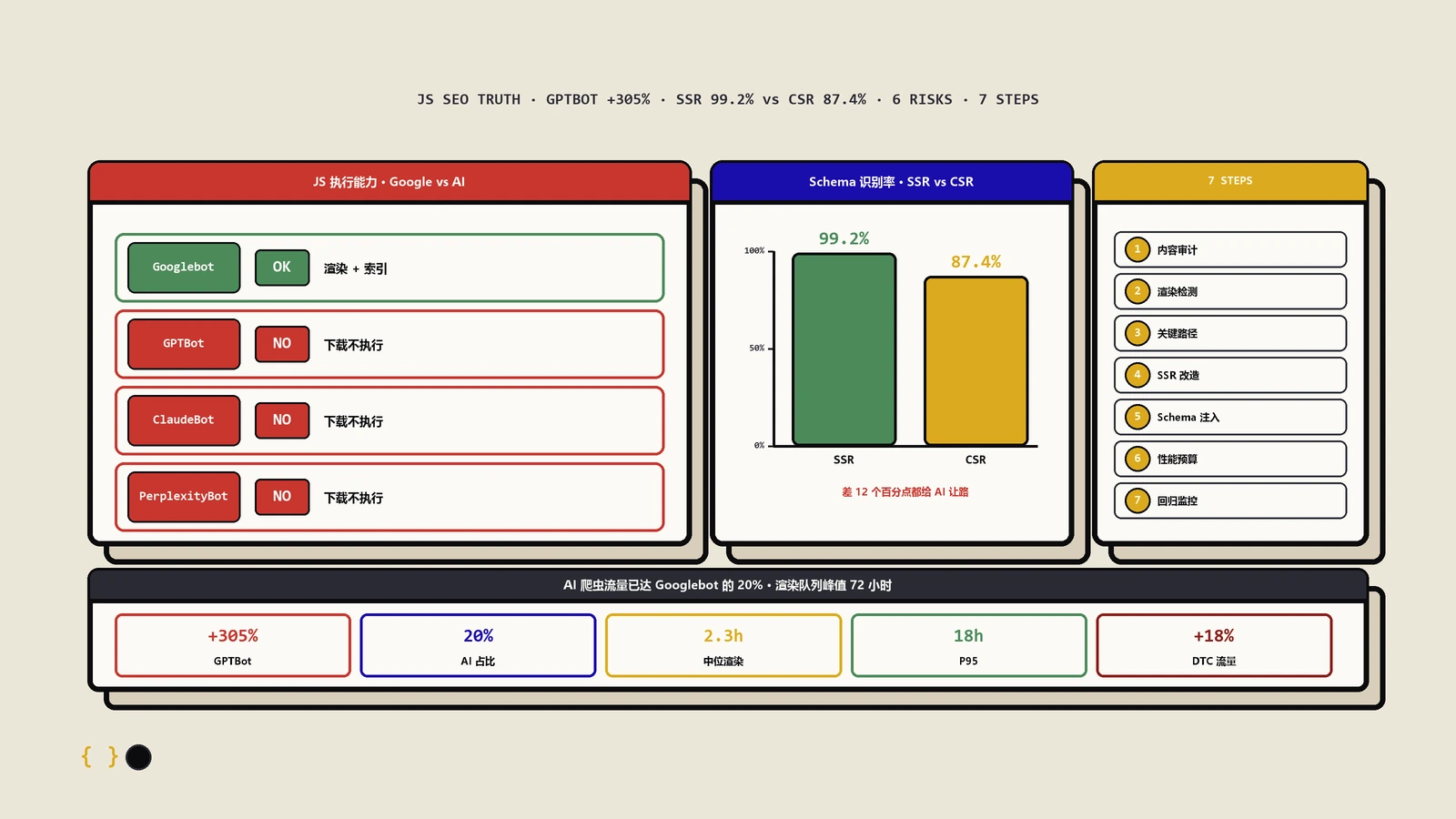
传统SEO圈对SPA的诟病停留在"Googlebot能爬但慢"的认知——这个判断在AI检索时代失效了。AI检索系统(ChatGPT browsing、Perplexity、Gemini grounding、Claude computer use)对JavaScript的执行策略各家不一样,整体偏严格。
| AI引擎 | JavaScript执行 | 等待时间 | 对SPA的友好度 |
|---|---|---|---|
| Googlebot(间接影响AI Overview) | 执行 | 5秒左右 | 中 |
| ChatGPT browsing | 大部分情况执行(Bingbot通道) | 3-5秒 | 中 |
| Perplexity crawler | 不执行JS | 0秒(只抓HTML) | 极低 |
| Gemini URL context grounding | 不执行JS(直接fetch HTML) | 0秒 | 极低 |
| Claude computer use | 执行(实时浏览器自动化) | 看页面加载 | 中-高 |
| Bingbot | 选择性执行 | 不稳定 | 低-中 |
SPA站在4家AI引擎里的真实状态
保哥手头一个北美SaaS客户站(Vue 3 + Vite + CSR渲染、无SSR),2025年Q4整理citation监控数据:
- ChatGPT browsing:3个月citation次数6次(同体量SSR对照站47次)
- Perplexity:3个月citation次数0次(同对照站31次)
- Gemini:3个月citation次数2次(同对照站28次)
- Claude:3个月citation次数4次(同对照站11次)
SPA站的AI citation总数只有同体量SSR站的8%-14%——这不是质量差距,是技术可见性差距。Perplexity和Gemini基本看不到SPA内容,因为它们的crawler不执行JS、只抓首屏HTML。
SPA加SSR是不是就解决了问题
不完全是。SSR/SSG/ISR/CSR四种渲染模式对AI检索的表现差异很大:
| 渲染模式 | 首屏内容来源 | AI检索友好度 | 典型技术栈 |
|---|---|---|---|
| SSG(静态生成) | 构建时预渲染成HTML | 极高(与传统站等价) | Next.js getStaticProps / Nuxt generate / Astro / Hugo |
| SSR(服务端渲染) | 请求时服务端渲染HTML | 高 | Next.js getServerSideProps / Nuxt server / Remix |
| ISR(增量静态再生) | 首次SSR后缓存、定期重生 | 高(与SSG接近) | Next.js revalidate / Nuxt ISR |
| CSR(客户端渲染) | JS执行后才有内容 | 极低 | Vite + Vue/React + 无SSR / Angular无prerender |
| Hybrid(部分静态+部分动态) | 路由级混合 | 看具体路由配置 | Next.js App Router / Nuxt 3 |
SSG是AI检索最友好的——构建时生成纯HTML、首屏完整。SSR需要服务器实时渲染、稍慢但同样友好。CSR是最差选择。新站建议直接用SSG或Next.js App Router这类Hybrid框架,旧的CSR站要做SSR迁移。
常见误判:很多团队以为"用了React/Vue就是SPA、就对SEO/AI不友好"——这是错的。React/Vue本身可以SSR可以SSG可以CSR,取决于你怎么用。真正的问题是CSR模式(首屏HTML空,内容靠客户端JS渲染)。用React但走Next.js SSR的站完全没有AI检索可见性问题。
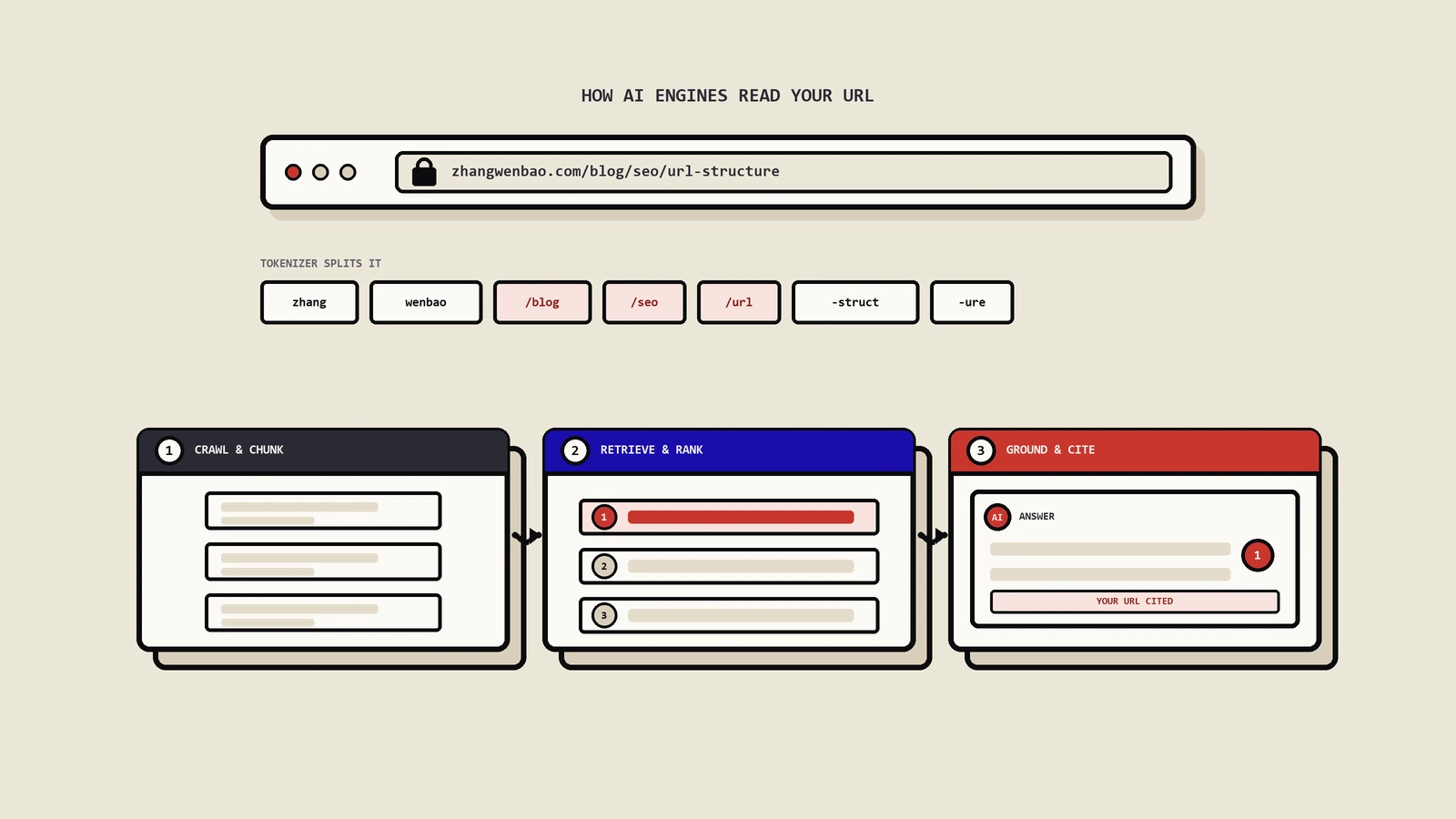
段落级竞争:AI怎么把你3000字长文切成20个独立候选
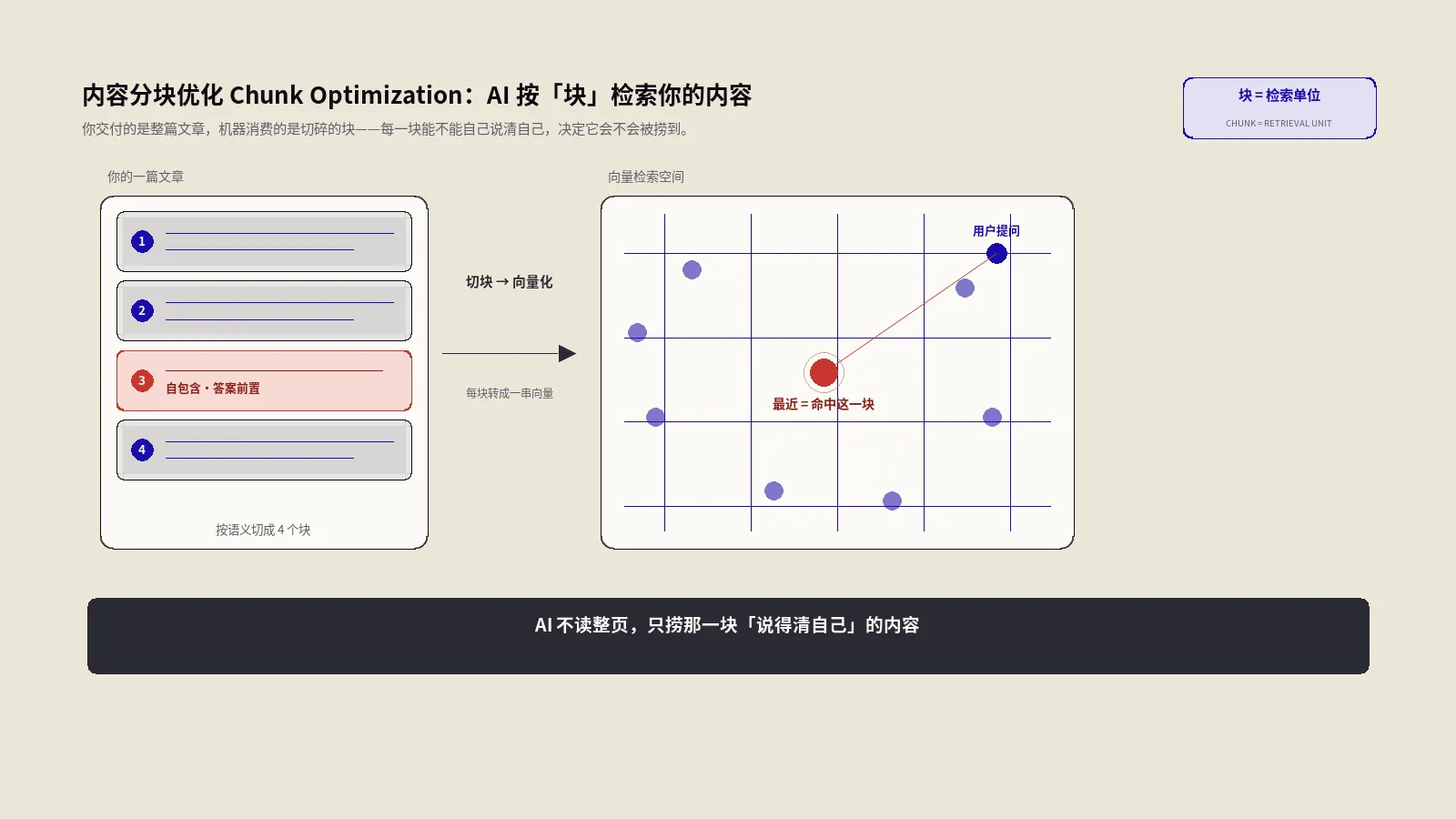
传统SEO思维是"页面级竞争"——一个URL作为一个整体参与排名。AI检索系统不是这样工作的。AI系统在索引时把页面切成多个独立的passages(段落),每个passage独立参与召回和评分。
chunk边界的实际划分规则
主流AI检索系统的chunk策略大致这样:
- 边界优先用H标签——H2/H3之间的段落自然成为chunk单位
- 无H标签时按段落和句子边界——双换行、句号是次级边界
- chunk大小通常300-800字符——超长段落会被切成多个chunk
- 列表项和表格行通常独立成chunk——这是为什么列表/表格在AI检索里特别有效
一篇3000字的文章被切成15-25个chunks是常态。每个chunk独立打分、独立召回,意味着你的页面在AI检索里"被引用的可能性"等于"任意一个chunk被选中的概率累加"。这就是为什么"内容好"不等于"每段都好"。
passage级竞争的实操含义
每段内容写完后做一个自检:
- 这段单独抽出来读得通吗(不依赖上下文)
- 这段能用一句话总结它回答的query吗
- 这段开头是答案还是铺垫(铺垫段大概率被chunk降权)
三个问题全部"是"才算"retrieval ready"的段落。过渡段、铺垫段、纯转折段在AI检索里全是浪费的passage——它们占了chunk数但不产生召回价值。
chunk优化的具体改写动作
保哥那个北美SaaS客户站做内容chunk优化时用的5个动作:
- 每个H2/H3下第一句直接给答案而不是过渡
- 每个表格上方加一句"这张表说明X"的总结句(被独立chunk时仍可读)
- 每个列表上方加一句"以下是X的Y种情况"开头
- 砍掉所有"接下来我们看看"、"让我们深入探讨"类过渡句
- 把超过400字的段落拆成两段(每段一个核心点)
5个动作做完60天后,那个站的AI Overview citation次数涨了2.8倍。没有写新内容、只是把现有内容chunk化优化——这是性价比最高的AI检索优化动作之一。
query fan-out:一个查询如何变成20个sub-query并行检索
传统SEO的"keyword targeting"思维在AI检索时代必须升级——AI系统拿到一个用户查询后不会按字面去检索,会先做query fan-out把查询扩展成网状的相关子查询。
query fan-out的实际工作机制
用户问"hreflang配置对Shopify多语种站有哪些坑"——AI系统的fan-out大致:
- 主query:hreflang Shopify多语种配置
- fan-out 1:Shopify默认hreflang实现的局限
- fan-out 2:3+语种vs 2语种的实施差异
- fan-out 3:subdirectory vs subdomain vs ccTLD在Shopify的取舍
- fan-out 4:Shopify Plus vs普通Shopify hreflang能力差异
- fan-out 5:常见hreflang错误诊断
- fan-out 6:hreflang与canonical的交互
- fan-out 7:Google对Shopify hreflang的索引行为
- ...还有10-15个
系统对每个sub-query独立检索召回top-K passages,然后整体重排选择最终citation。你的内容能在多少个fan-out节点上被召回,决定了最终citation机会。
fan-out偏好的内容架构
fan-out对内容架构的要求和传统SEO的"长尾关键词"思路有相似但更精细:
- topic cluster——一个pillar page + 多个subtopic page,每个subtopic独立深入
- each subtopic独立站点路径——不要全塞pillar page里
- 每个subtopic page里覆盖至少3-5个常见sub-question(FAQ段是好载体)
- 跨页面相互内链——让AI系统能从一个passage跳到相关页拿更多上下文
一个pillar+8个subtopic的cluster结构在AI检索里通常能命中fan-out里的60%-80%节点。单独一个3000字大杂烩pillar能命中的fan-out节点数普遍在20%-30%。
"Query fan-out fundamentally rebalances the competitive landscape. A focused 1,500-word page that exhaustively covers one specific sub-question can systematically outperform a 4,000-word generalist guide in AI retrieval, because retrieval happens at the passage level and selection happens against the specific fan-out node." —— RAG实施手册综述2025-Q4
retrieval vs citation:被索引≠被引用
"The distinction between retrieval presence and citation selection is the single most underused diagnostic axis in AI search optimization. Teams that conflate the two end up rewriting content when the actual fix is technical, or rebuilding infrastructure when the actual fix is editorial." —— enterprise AI search benchmarks 2025-Q4综述
大部分团队混淆了retrieval(被检索到)和citation(被引用)的区别——这是2026年AI搜索可见性诊断里最常见的错误。
两层结构的实际差异
| 维度 | retrieval(候选池) | citation(最终引用) |
|---|---|---|
| 判定标准 | 系统能否从你的页面拿到passage作为候选 | 系统是否在生成回答时选择了你的passage |
| 瓶颈类型 | 技术(crawl/render/chunk) | 内容(specificity/depth/uniqueness) |
| 修复成本 | 低(技术修复一次到位) | 高(要持续生产高质量内容) |
| 典型失败信号 | 站完全不出现在AI回答里 | 同主题查询里出现但被选中率低 |
| 诊断工具 | GSC + 第三方crawler模拟器 | 逐查询手动对照 |
怎么判断你处在哪一层失败
简单的判断流程:
- 用Perplexity/ChatGPT browsing搜你主题相关的10个核心查询
- 看AI回答里是否出现你的站点citation——任意一个就算retrieval OK
- 如果10个都没出现 → retrieval失败(修技术)
- 如果出现1-3个 → citation竞争失败(改内容)
- 如果出现4个以上 → retrieval和citation都OK,看怎么扩到更多queries
retrieval失败的常见根因
- CSR渲染(无SSR)——首屏HTML空,Perplexity/Gemini看不到
- 内容塞在tab/accordion里默认不展开——chunk时被跳过
- 内容塞在iframe里——AI爬虫普遍不跨iframe抓取
- robots.txt误屏蔽——/api/ /search/ /user/这类路径误屏
- JS执行依赖第三方加载——CDN挂了或加载慢导致chunk失败
citation失败的常见根因
- passage级具体度不够——每段都是泛泛而谈
- topic depth不足——只有pillar没有subtopic
- information gain低——内容和竞品同质化
- 过渡句太多、信号密度低——chunk被切出来后单独读不通
- 缺少作者署名/E-E-A-T信号——AI在选citation时降权
决定段落被选中的两个核心信号:information gain和topic depth
过了retrieval关、进入citation竞争后,AI系统选择passage时主要看两个信号:information gain(信息增益)和topic depth(主题深度)。
information gain的定义和落地
information gain是"这段内容能否提供候选池里其他passages无法提供的信息"。独家数据、第一手案例、专有调研、自创框架都是高information gain的来源。同质化内容information gain为0——AI系统拿你的passage还是拿竞品的passage都一样。
识别和强化information gain的具体动作:
- review同主题top 10竞品页面——找出反复出现的claims/definitions/examples
- 标记你的内容里"竞品没说过的"点——可能是数据、案例、框架、踩坑
- 把独家点上移到H2开头位置或独立H3
- 用具体数字/客户名/时间戳支撑独家点("2025-Q3某北美家居DTC客户在测试hreflang配置时发现……")
topic depth的两个层面
topic depth在站内分两层:
| 层面 | 定义 | 实操标准 |
|---|---|---|
| 跨页面深度 | 一个主题在站内有多少独立subtopic页 | 每个核心主题至少1 pillar+5-8 subtopic |
| 页面内深度 | 单页面覆盖basics+edge cases+practitioner tradeoffs三层 | 每个核心H2下要有"基础-边界-取舍"三段 |
一个大domain authority但单主题只有一个pillar的站在AI检索里会输给一个小站但有完整cluster的对手。AI系统在主题级评估authority,不只在domain级——这是2026年AI检索的核心结构变化。
AI检索失败诊断:retrieval问题还是quality问题
实操诊断的两栏表是最简单有效的工具:
| 诊断维度 | retrieval问题信号 | quality问题信号 |
|---|---|---|
| AI citation次数 | 0或接近0 | 有但远低于竞品 |
| GSC impressions | 正常(传统SEO可见) | 正常但AI流量不增 |
| Crawl状态 | 异常或部分被屏 | 正常 |
| 首屏HTML | 空或加载延迟 | 完整 |
| 段落chunk质量 | 每段独立读不通 | 每段通但太泛泛 |
| 修复优先级 | P0(不修后面全是空谈) | P1-P2(持续迭代) |
retrieval问题的快速诊断动作
- 用
curl -A "PerplexityBot/1.0" https://yourdomain.com/page模拟Perplexity爬取——看返回HTML是否有首屏内容 - 用
curl -A "Googlebot" https://yourdomain.com/page模拟Googlebot——对照Perplexity看差异 - 用Chrome DevTools的"Disable JavaScript"模式看页面——这是Perplexity/Gemini看到的版本
- 查GSC的Crawl Stats——看Googlebot抓取频率是否正常
- 查robots.txt和meta robots——确认无误屏
quality问题的快速诊断动作
- 挑3-5个核心查询在Perplexity/ChatGPT/Gemini跑一遍
- 看哪些竞品被引用——下载competitor citation list
- 把竞品被引用的具体passage和你站对应段落对照看——找specificity/depth/uniqueness差异
- 不要全文重写——改competitor赢的具体段落
- 跑完改进后等30-60天看citation数据变化
修复顺序硬规则:先修retrieval再修quality。没有retrieval时改内容0意义——AI系统根本看不到。先用2-4周修技术(SSR迁移、清tab/accordion、修robots、补schema),再用3-6个月迭代内容质量。倒着做的团队最终都返工。
修复优先级:技术修复先于内容投入
把AI检索修复拆成具体的两阶段路径:
retrieval修复阶段——预计耗时2到4周
| 动作 | 难度 | 预期改善 |
|---|---|---|
| CSR迁到SSR/SSG | 高(架构改造) | Perplexity/Gemini citation率从0涨到基线 |
| tab/accordion改default expand | 中 | chunk数据涨30-50% |
| 修robots.txt误屏 | 低 | 立即生效 |
| 补Person/Organization schema | 低-中 | citation时被识别为权威源 |
| H层级规范化 | 低 | chunk边界清晰度涨 |
| 砍过渡句和铺垫段 | 中(要逐段改) | passage-level质量基线涨 |
quality迭代阶段——持续3到6个月
| 动作 | 每月投入 | 预期改善 |
|---|---|---|
| 挑10个near-miss query改对应passage | 10-20小时 | citation命中率涨 |
| 每月加3-5个subtopic新页扩cluster | 30-40小时 | topic depth提升、fan-out命中节点增加 |
| 补独家数据和案例 | 变动(看素材) | information gain增加 |
| 更新60天以上的高价值页面 | 5-10小时 | freshness信号 |
retrieval vs quality的投入回报对比
从保哥3个客户站的实测来看:
- retrieval修复一次性投入20-80小时(看SPA迁移复杂度),3个月内AI citation次数涨5-15倍
- quality迭代持续投入每月30-50小时,6个月citation涨2-4倍(叠加在retrieval基础上)
- retrieval和quality都不做的对照站——citation次数月环比持续小幅下降(因为竞品在做)
结论简单粗暴:没做retrieval修复就投quality内容生产是浪费钱。优先级永远是技术先行。
常见问题解答
SPA站非要SSR迁移吗用prerendering插件够吗
prerendering(如prerender.io、puppeteer-prerender)能解决Googlebot/Bingbot抓取问题,但Perplexity和Gemini不一定走prerender路径——它们的crawler识别策略可能跳过prerender代理。最稳的方案还是SSR/SSG迁移。中等站点用Next.js或Nuxt 3的Hybrid模式渐进迁移,旧React站可以套Astro shell逐页迁移。
tab和accordion完全不能用吗
能用但要做两件事:(1)首屏HTML里完整渲染所有tab/accordion内容——可以用CSS hide但DOM里要有;(2)每个tab有独立URL锚点和H层级——让chunk边界清晰。绝对不要用JS动态加载tab内容、点击时才fetch——这种结构对AI检索完全不可见。
AI检索的chunk size有具体上限吗
没有公开标准。实测主流系统的chunk大小在200-1200 token之间(约150-900中文字符)。单段超过500中文字符的内容大概率被切成多个chunks——切分点不一定理想。最佳实践是每段控制在200-400字符、自然形成单独的chunk单位。
FAQPage结构化数据能提升AI citation吗
能。FAQPage JSON-LD把Q&A结构化标注后AI系统能直接抽取——AI Overview尤其偏好这种结构。每篇深度内容里加5-8个FAQ + FAQPage schema是低成本高回报的动作。注意Google在2026-05下线了FAQ富结果展示但schema本身依然被AI系统使用。
Perplexity不索引我的站点是不是没救了
大部分是技术问题。检查清单:(1)Perplexity-Bot User-Agent是否被你站robots.txt允许(默认通常允许);(2)首屏HTML是否完整(用 curl -A "PerplexityBot" 验证);(3)是否有anti-bot措施(Cloudflare bot fight mode经常误伤Perplexity)。修完技术后等2-4周Perplexity会自然重新爬取。
information gain怎么持续产生不是一次性资产
把information gain做成持续运营机制而不是单次产出:每月做客户访谈3-5个、每季度跑一次产品长期测试、每半年发布行业报告、每年公开一次站点运营数据复盘。这套节奏跑起来后information gain变成机器学习量级的内容资产,比单篇精品文长尾价值更高。
cluster架构具体怎么设计
常见结构:1个pillar page(主题overview,2000-3000字)+ 6-10个subtopic page(每个具体sub-question,1500-2500字)+ pillar和subtopic之间双向内链 + 每个subtopic间相关性强的也内链。关键是subtopic要narrow到具体场景——"hreflang for Shopify with 3+ languages"比"hreflang配置指南"更narrow。
AI citation的数据怎么追踪没专门工具
手动跟踪可行但费时间——准备一个spreadsheet:列出20-50个核心查询,每月在Perplexity/ChatGPT/Gemini各跑一遍,记录citation情况。第三方工具有Otterly.AI/Profound/PromptWatch等,价格不一价值看具体业务规模。对中小站手动跟踪+spreadsheet完全够用。
权威参考资料
本文标题:《SPA站AI爬不到的真相:四种渲染模式对比与段落级被引用诊断》
本文链接:https://zhangwenbao.com/ai-search-skips-spa-rendering-passage-level.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0