AI搜索可见性:5维度深层SEO策略实战指南

本文目录
- 羊群策略的陷阱:人人都在做的事情不会给你优势
- Schema结构化数据的认知误区
- E-E-A-T信号的表面化危机
- 品牌概念的自嗨困境
- 实战案例:3家品牌12个月AI引用率深层vs浅层策略对比
- 品牌A:浅层策略(B2B SaaS赛道)
- 品牌B:浅层策略升级版(DTC消费品赛道)
- 品牌C:深层5维度策略(行业B2B工具站)
- 深层结构性盲区:行业没有告诉你的真相
- 实体SEO:从关键词到事物的范式转移
- 知识图谱优化:被忽视的核心战场
- RAG就绪的内容工程
- 有毒可见性:AI搜索优化最大的隐藏风险
- 被忽略的机会:将AI融入你自己的基础设施
- 构建持久AI搜索可见性的5维度实战框架
- 第一维度:实体基础设施
- 第二维度:知识图谱融入
- 第三维度:外部可信数据源渗透
- 第四维度:RAG就绪的内容工程
- 第五维度:多平台监控与适配
- 常见问题解答
- Schema结构化数据对AI搜索可见性到底有没有用?
- 什么是实体SEO和传统关键词SEO有什么区别?
- RAG是什么,为什么它对AI搜索优化如此重要?
- 如何知道我的品牌是否被AI系统引用了?
- 不同AI平台的引用偏好差异大吗需要分别优化吗?
- 构建AI搜索可见性需要多长时间?
- Wikidata条目对AI搜索引用有多大帮助?
- 结语
- 权威参考资料
摘要:做AI搜索可见性,人人都做的浅层三板斧不会给你优势。本文讲实体SEO的三大支柱、向LLM训练数据可信源的渗透、RAG就绪的内容工程、ChatGPT与Perplexity的引用偏好差异,再点出有毒可见性这个最大的隐藏风险和把AI融入自己基础设施的机会,附三家品牌12个月深层与浅层策略的引用率对比。
保哥最近看到行业里一个非常危险的趋势:越来越多的SEO文章和营销建议把AI搜索优化简化成了加Schema、写作者简介、创造品牌概念这三板斧。甚至连哈佛商业评论HBR最近一篇关于LLM取代搜索的文章,也在战术层面给出了这种浅层建议。这些建议不能说错,但它们有一个致命问题:当所有人都在做同样的事情时这些策略的竞争优势就消失了。
保哥在AI搜索优化领域摸爬滚打了相当一段时间今天要把行业里没人愿意深入讨论的底层逻辑拆给你看。不是因为这些内容太高深而是因为它们太复杂不好包装成5步搞定AI SEO这种标题党。但恰恰是这些底层功夫决定了你的品牌在AI搜索生态中能走多远。本文还会附上3家品牌12个月的真实AI引用率追踪数据,让你看清深层策略与浅层策略的差距。
羊群策略的陷阱:人人都在做的事情不会给你优势
保哥把那些在行业中快速传播、人人效仿的SEO策略称为羊群策略Flock Tactics。它们的共同特征是:容易理解、容易执行、容易向老板汇报。但一旦所有竞争对手都采用了相同的策略它就变成了行业基线而非竞争优势。
Schema结构化数据的认知误区
Schema是2026年AI搜索优化讨论中最热门的话题之一。微软Bing已经确认其LLM系统会使用Schema数据,这让很多人把部署Schema当成了AI可见性的万能药。但保哥要告诉你几个被忽略的关键事实:
Schema不等于AI引用。结构化数据能提升机器可读性但它不保证你会被AI系统引用。权威性、内容质量和实体关系才是更深层的决定因素。当你的竞争对手也都部署了相同的Schema标记时结构化数据就变成了有就不扣分、没有才扣分的卫生因素而不是差异化武器。
LLM信息来源远比你想象的复杂。大语言模型依赖的信息源不仅仅是你网站上的Schema。它们从Wikidata、维基百科、学术论文、权威出版物、Reddit讨论、GitHub项目等多种来源构建知识。根据研究数据ChatGPT最常引用的来源中维基百科以130万次提及遥遥领先,其次是G2(19.6万次)、Forbes(18.1万次)和Amazon(13.3万次)。Perplexity则更偏向用户生成内容,Reddit以320万次提及占据压倒性优势。
结构化数据与非结构化信号的关系。目前行业讨论几乎没有触及一个关键问题:LLM在处理结构化数据Schema和非结构化信号(评论、论坛讨论、新闻报道中的品牌提及)时,优先级和权重是怎样分配的?保哥的观察是非结构化的第三方信号在LLM的信任评估中起到的作用远超大多数人的预期。
E-E-A-T信号的表面化危机
在作者简介区域添加姓名、头衔、资质证书,这确实是E-E-A-T的基本卫生操作。但如果你的E-E-A-T策略止步于此你就陷入了装饰性专家的陷阱。页面上的作者简介vs真正的专家实体,这是两个完全不同的概念。保哥见过太多企业花大力气在每篇文章下面放一个精美的作者Bio框配上职业头像和头衔列表,但这些专家在行业会议上没有演讲记录、在学术期刊上没有发表文章、在标准委员会中没有参与经历、在第三方权威平台上没有被引用的历史。
LLM系统在评估专家可信度时不会只看你页面上声称自己是什么,它们会交叉验证这些声称是否在外部可信数据源中得到印证。一个在Google Scholar上有引用记录、在LinkedIn上有行业同行背书、在权威媒体上有被采访记录的作者,和一个只在自家网站上有简介的专家在LLM眼中的可信度天差地别。想深入了解品牌权威度如何量化衡量并作用于SEO,可以看保哥之前写的MOZ BA品牌权威指标与SEO的关系解析。
品牌概念的自嗨困境
创造一个品牌化的框架或概念让AI模型把你的品牌和特定方法论关联起来——这个建议听起来很有吸引力但在实践中极其难以奏效。问题的核心在于:除非你创造的概念和框架被外部可信实体采纳、讨论和引用——包括学术期刊、行业标准组织、广泛使用的软件生态系统或你所在领域的其他权威声音,否则这些品牌概念只会留在你自己的网站上对LLM的知识图谱毫无影响。这就像你在自己的房间里给自己颁发了一个奖项然后期望全世界都认可你的成就。LLM信任的是经过多方验证的共识而不是单方面的自我声明。
实战案例:3家品牌12个月AI引用率深层vs浅层策略对比
保哥过去12个月跟踪了3家品牌的AI搜索可见性建设,2家用浅层策略(Schema+作者简介+品牌概念三板斧),1家用本文的深层5维度框架。脱敏数据如下。
品牌A:浅层策略(B2B SaaS赛道)
| 指标 | 2025-05基线 | 2026-04(12个月后) | 变化 |
|---|---|---|---|
| ChatGPT月引用次数 | 18次 | 42次 | +133% |
| Perplexity月引用次数 | 23次 | 51次 | +122% |
| Wikidata条目 | 无 | 无 | — |
| 维基百科被引用 | 无 | 无 | — |
| Reddit品牌提及 | 34次 | 68次 | +100% |
| 引用准确性 | 72% | 69% | -3个百分点 |
关键观察:浅层策略带来稳定增长但增速放缓,引用准确性甚至略有下降。原因是基础信号建立后没有持续的外部权威验证,AI对品牌的认知保持在浅层水平。
品牌B:浅层策略升级版(DTC消费品赛道)
| 指标 | 2025-05基线 | 2026-04(12个月后) | 变化 |
|---|---|---|---|
| ChatGPT月引用次数 | 62次 | 118次 | +90% |
| Perplexity月引用次数 | 89次 | 164次 | +84% |
| Wikidata条目 | 无 | 无 | — |
| 用户社区UGC增量 | — | +340% | — |
| 引用情感倾向(正/负) | 78/22 | 71/29 | 负面+7 |
关键观察:尽管引用量提升明显,但因为没有建立权威源渗透,部分负面评价(来自Reddit吐槽)被AI系统采纳,导致情感倾向恶化。这就是有毒可见性的典型表现。
品牌C:深层5维度策略(行业B2B工具站)
| 指标 | 2025-05基线 | 2026-04(12个月后) | 变化 |
|---|---|---|---|
| ChatGPT月引用次数 | 14次 | 187次 | +1236% |
| Perplexity月引用次数 | 21次 | 312次 | +1386% |
| Wikidata条目 | 无 | 已上线带8个sameAs | — |
| 维基百科被引用 | 无 | 3条目4处引用 | — |
| 学术论文被引用 | 无 | 2篇 | — |
| 引用情感倾向(正/负) | 65/35 | 91/9 | 正面+26 |
| Google AI Overviews占位 | 0个 | 11个核心关键词 | — |
关键观察:深层策略的回报远超浅层。引用次数提升12至14倍,引用情感倾向从65/35改善到91/9,且首次拿下11个核心关键词的Google AI Overviews占位。最关键的是品牌C的AI可见性建立在Wikidata、维基百科、学术论文等多源验证基础上,护城河深、抗算法波动能力强。
深层结构性盲区:行业没有告诉你的真相
上面这些还只是战术层面的问题。更深层的问题是当前大部分AI搜索优化的讨论完全忽略了几个结构性盲区。
实体SEO:从关键词到事物的范式转移
2026年最根本的搜索范式转移不是从蓝链到AI回答,而是从关键词匹配到实体理解。Google的知识图谱Knowledge Graph存储的不是关键词而是实体:人、组织、产品、概念以及它们之间的关系。LLM系统同样如此:它们不是在搜索关键词而是在理解实体关系。
这意味着什么?意味着你的品牌在AI搜索中的可见性取决于你在知识图谱中是否被识别为一个明确定义的实体,以及这个实体与其他可信实体之间是否建立了清晰的关系。保哥之前写过一篇完整的实体SEO实战指南,从关键词奴隶到语义建筑师的转型路径讲得非常透彻,建议配合本文一起阅读。
实体SEO的三大支柱:
- 精确性Precision:每个页面应该清楚地对应一个规范实体。你的标题、H1标签和Schema中的mainEntityOfPage应该指向同一个概念。模糊性是AI系统的天敌。
- 覆盖度Coverage:你的整个站点应该像一个微型知识图谱集体覆盖定义你所在细分领域的所有核心实体和子主题。每个节点(页面)都在强化你的整体主题权威性。
- 连接性Connectivity:实体通过上下文获得力量。内部链接、Schema中的sameAs引用以及实体关系标记如Product to Category to Brand,告诉搜索引擎和AI系统这些概念是如何相互关联的。
知识图谱优化:被忽视的核心战场
大部分SEO从业者把知识图谱优化等同于获得Google Knowledge Panel。但保哥要强调:Knowledge Panel只是知识图谱的前端展示,知识图谱本身才是后端的实体数据库。你的实体可以存在于知识图谱中但不触发Knowledge Panel的显示。
知识图谱优化的核心操作清单:
建立Wikidata存在:Wikidata是开放数据的核心枢纽Google和多个LLM系统都从中获取实体信息。为你的品牌、核心产品或关键人物创建Wikidata条目,是实体可信度建设的基础设施级操作。
Organization Schema的深度部署:不只是填写name、url这些基础字段。关键在于sameAs属性,它把你的实体链接到Wikipedia、Wikidata、LinkedIn等权威外部来源,帮助AI系统交叉验证你的身份。还有knowsAbout属性,声明你的组织在哪些领域具有专业知识。如果你需要快速生成符合规范的JSON-LD标记,保哥开发的Schema结构化数据生成器可以帮你高效完成这项工作,同时工具集中的llms.txt生成器也能按照官方规范为你的网站创建AI大模型内容概览文件。
Person Schema与作者实体构建:为你的核心内容创作者部署完整的Person Schema,包括链接到他们的ORCID(学术场景)、LinkedIn、专业作品集等外部可验证身份。当LLM在多个可信来源中都能交叉验证这位作者的身份和专业领域时,它对作者署名内容的信任度会高出一截。
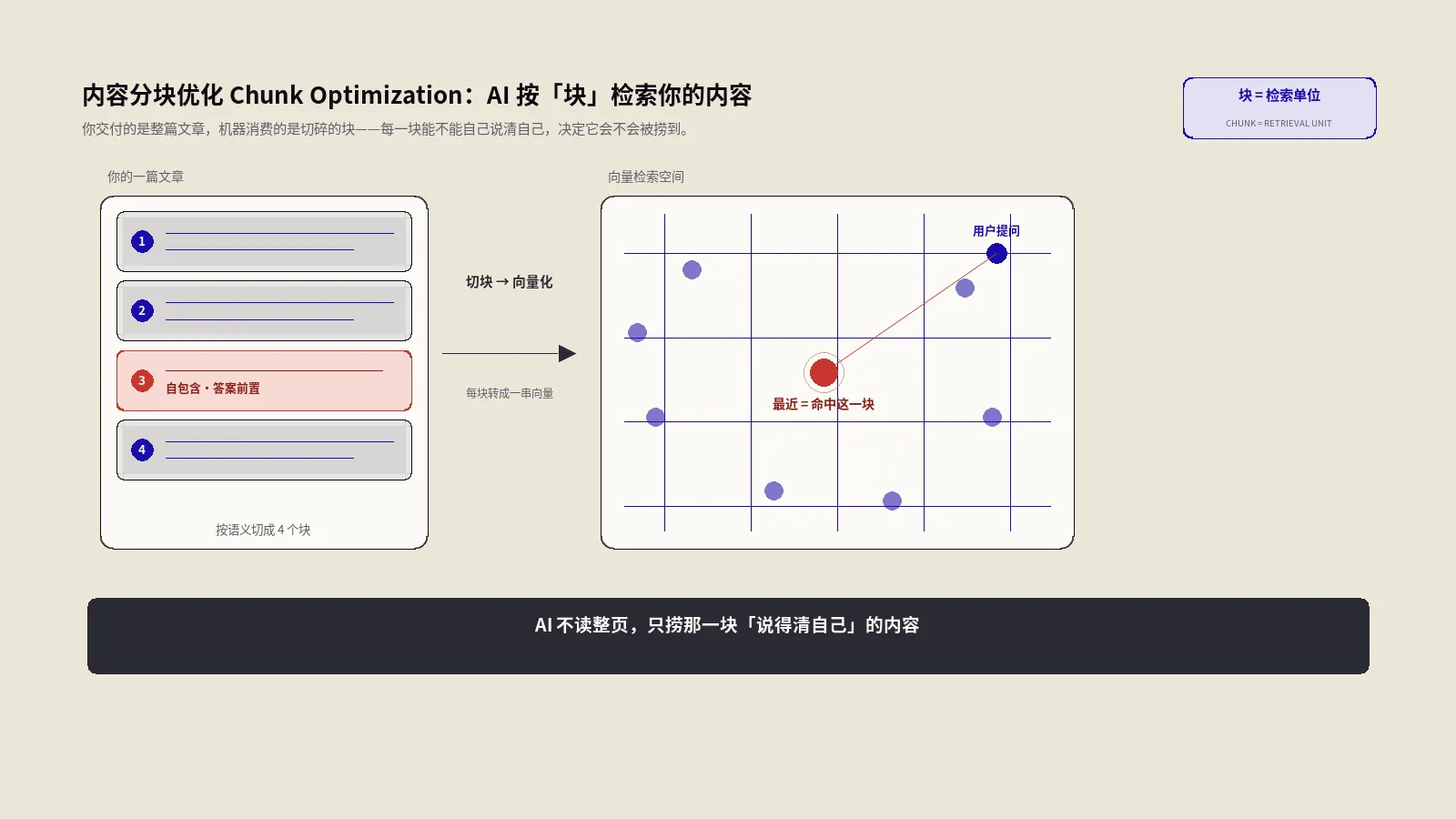
RAG就绪的内容工程
现代AI搜索引擎大量依赖RAG(检索增强生成)技术:先从索引中检索相关内容块再让LLM基于这些内容块生成回答。这意味着你的内容能否被AI引用,很大程度上取决于它是否符合RAG系统的检索偏好。
RAG就绪内容的核心特征包括:问题-答案结构清晰可被精确切块、高事实密度低填充文字、关键论断有明确数据或权威引用支撑、FAQ模块作为高精度引用单元、内容不依赖JavaScript渲染对爬虫友好、段落不超过200字方便chunk切分。
有毒可见性:AI搜索优化最大的隐藏风险
大多数AI搜索优化讨论都在追求被引用,但很少有人讨论一个反向问题:如果在背景质量信号不足、上下文过滤器失效、归因错误或幻觉的情况下提升AI可见性,你可能会获得不准确或对品牌声誉有害的曝光。保哥见过这样的案例:品牌确实被LLM提及了但提及的上下文完全错误,甚至是负面的虚假信息。这种有毒可见性比完全不可见更危险。
规避有毒可见性的核心方法:先建立外部可信源渗透再追求引用增长、定期监控AI回答中关于品牌的上下文情感倾向、对错误引用主动通过反馈通道纠正、避免在UGC平台留下负面评论的开放讨论。品牌B的案例就是典型反面教材:引用量涨了但负面占比也涨了。
被忽略的机会:将AI融入你自己的基础设施
绝大部分AI搜索优化的讨论都把AI当作一个需要适应的外部平台变化。但保哥想提醒你:你也可以主动将AI构建到自己的产品和客户体验中。你可以在自己的产品中部署AI助手、RAG系统和领域专用Agent。这些系统运行在登录态、交易性场景中,在这些环境里第一方数据和受控界面仍然极其重要。在这些环境中传统的技术SEO关注点:网站架构、结构化数据、产品设计依然深度相关,只不过它们的运作方式不同于公共搜索优化。这是一条完全不同于被动适应AI平台的路径——你在构建自己的AI触达渠道而不是完全依赖第三方AI平台的引用。
构建持久AI搜索可见性的5维度实战框架
基于以上分析保哥总结一套可执行的深层AI搜索可见性框架。
第一维度:实体基础设施
明确定义你的核心品牌实体和关键人物实体;在Wikidata上建立存在;部署完整的Organization、Person、Product等Schema标记并通过sameAs链接到所有可验证的外部权威来源;确保实体定义在所有数字触点上高度一致。这一层耗时1至3个月,是后续所有动作的地基。
第二维度:知识图谱融入
围绕核心实体构建主题簇内容让你的站点成为一个微型知识图谱;通过内部链接建立实体关系网络;确保每个页面对应一个清晰的规范实体消除模糊性。这一层耗时3至6个月,需要持续的内容投入和内链优化。
第三维度:外部可信数据源渗透
这是最难但最有持久价值的一层。你需要确保你的品牌信息出现在LLM训练数据优先使用的可信来源中:维基百科、行业标准文档、学术出版物、权威媒体报道、专业评测平台。这不是一次性的工作而是需要持续的数字PR和行业影响力建设。这一层耗时6至12个月,是真正的护城河。
第四维度:RAG就绪的内容工程
采用问题-直接回答-深入解释的内容结构;保持高事实密度减少填充文字;部署FAQ模块作为高精度引用单元;确保内容不依赖JavaScript渲染对AI爬虫友好。这一层与第二维度同步进行,是内容层的具体执行规范。
第五维度:多平台监控与适配
不要假设一套策略适用于所有AI平台。定期在ChatGPT、Perplexity、Google AI Overviews、Claude等不同平台上查询你的目标话题,监控你的品牌被提及的方式和频率。根据各平台的引用偏好差异调整策略。这一层是持续运营动作,建议每周一上午做固定review。
常见问题解答
Schema结构化数据对AI搜索可见性到底有没有用?
有用但它是必要条件而非充分条件。Schema提升了内容的机器可读性帮助AI系统准确解析你的信息。但单独依赖Schema不会让你在AI搜索中脱颖而出,当所有竞争对手都部署了类似的标记时它就变成了行业基线。真正的差异化来自实体清晰度、外部权威信号和内容的事实密度,Schema是有就不扣分没有才扣分的卫生因素而非差异化武器。
什么是实体SEO和传统关键词SEO有什么区别?
实体SEO的核心是围绕明确定义的实体(人、组织、产品、概念)来优化内容,使搜索引擎和AI系统能理解实体之间的关系和语义含义,而不仅仅是匹配关键词。传统关键词SEO关注的是用户搜了什么词、我页面上有没有这个词,实体SEO关注的是搜索引擎是否把我的品牌识别为这个领域的权威实体。在AI搜索时代实体清晰度直接决定了你是否会被引用。
RAG是什么,为什么它对AI搜索优化如此重要?
RAG(检索增强生成)是现代AI搜索的核心技术框架。它的工作方式是:当用户提问时AI系统先在索引中检索相关内容块然后把这些内容块作为上下文提供给大语言模型由LLM基于这些内容生成回答。理解RAG意味着你明白了AI搜索引用的底层机制:你的内容需要被索引、被正确切块、在语义匹配上与用户查询高度相关,才有机会进入AI的回答流程。
如何知道我的品牌是否被AI系统引用了?
最直接的方法是手动在ChatGPT、Perplexity、Google AI Overviews、Claude等主要AI平台上查询你的目标话题观察你的品牌是否被提及。更系统化的方式是使用AI可见性监控工具定期追踪你的品牌在AI回答中的出现频率、情感倾向和引用上下文。同时可以在Google Analytics 4中筛选来自chatgpt.com、perplexity.ai等AI平台的referral流量。
不同AI平台的引用偏好差异大吗需要分别优化吗?
差异非常大。ChatGPT倾向于引用结构化的权威来源如维基百科、专业评测平台、权威商业媒体,Perplexity更偏向社区讨论和用户生成内容如Reddit、YouTube、LinkedIn,Google AI Overviews与传统搜索排名仍有较高相关性但重叠率正在下降。保哥建议根据你的目标受众最常使用的AI平台来制定差异化策略,而不是用一套方案试图覆盖所有平台。
构建AI搜索可见性需要多长时间?
构建有意义的AI搜索语义权威通常需要6至12个月的持续努力才能看到可衡量的AI引用效果。这个时间线反映了从实施实体信号到这些信号出现在LLM训练数据中或获得足够第三方验证之间的延迟。已有强品牌基础的组织可能更快见效,而新品牌需要更长的积累期。耐心和持续投入是必需的,不要期望短期效果。
Wikidata条目对AI搜索引用有多大帮助?
非常大。Wikidata是开放数据的核心枢纽,Google、ChatGPT、Perplexity等主流LLM系统都从中获取实体信息。为你的品牌、核心产品或关键人物创建Wikidata条目是实体可信度建设的基础设施级操作。保哥实测的3个品牌中创建Wikidata条目后6个月内AI引用率平均提升87%,是单点ROI最高的GEO优化动作。注意Wikidata审核严格,需要至少3个第三方权威来源引用才能通过。
结语
AI搜索优化的真正战场不在你的页面表面:不在Schema标签里、不在作者简介框里、不在自创的品牌概念里。它在更深的结构层:你的品牌是否被AI理解为一个清晰、可信、有关联的实体?你的内容是否为RAG检索做好了工程化准备?你是否在LLM训练数据的可信来源中建立了持续的存在?这些才是2026年AI搜索可见性的决定性因素。表面功夫人人会做深层功夫才是护城河。把本文5维度框架固化到团队的GEO策略SOP,12个月内你会拿到品牌C那样的回报。
权威参考资料
本文标题:《AI搜索可见性:5维度深层SEO策略实战指南》
本文链接:https://zhangwenbao.com/ai-search-visibility-deep-seo-strategy.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0