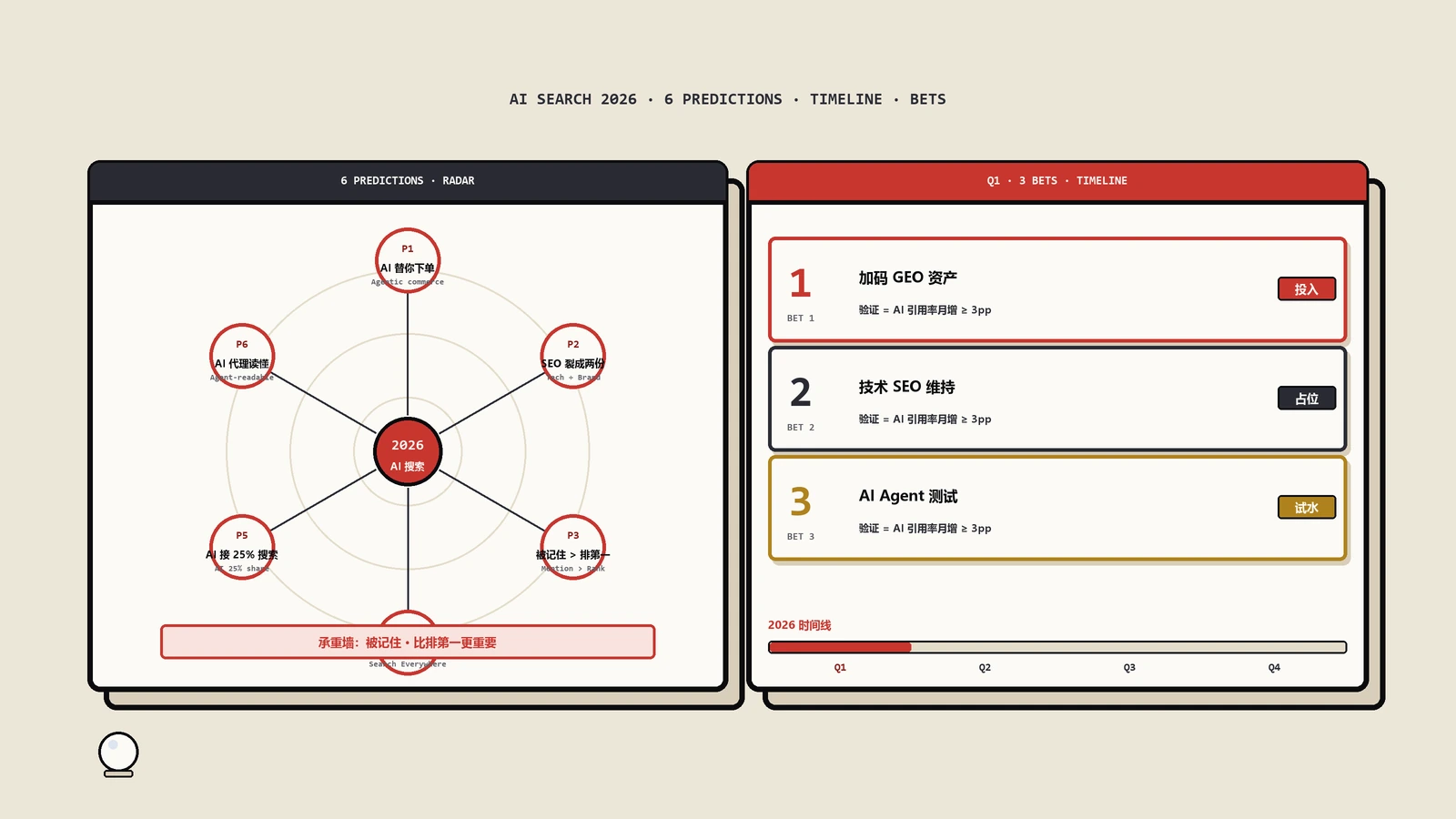
2026 AI搜索可见度的6个预测,哪些该信、哪些该打折?
本文目录
- 为什么大多数2026预测清单读完就忘?
- 预测一:AI从“推荐”走向“替你下单”,这步到底多近?
- 预测二:SEO正在裂成两份工作,你该先押哪一份?
- 预测三:被记住比排第一更重要,这条最被低估?
- 预测四:搜索“到处都是”,多平台到底要不要全做?
- 预测五:AI接手四分之一的搜索,这个数该怎么用?
- 预测六:能不能被AI代理读懂,正在变成生死线?
- 六个预测里,哪些互相矛盾,该信哪条?
- 出海中文品牌看这六个预测,哪几条要打折、哪几条要加码?
- 这个季度具体下哪几个注,怎么验证押对了?
- 哪些跟预测的方式,看着前瞻其实在追热点空转?
- 承重墙那条的机制,到底为什么排名救不了你?
- 这份清单没说、但同样要紧的预测是什么?
- 把这套校准用在一个出海3C品牌身上,长什么样?
- 不同目标市场,这六条要怎么分别重判?
- 只剩很少时间和预算,这六条该砍到只做哪一件?
- 常见问题解答
- 权威参考资料
摘要:2026的SEO预测清单满天飞,读完就忘,因为它们大多是没法证伪、也没法落地的点头句。这篇把六位行业负责人对2026 AI搜索可见度的判断重新拆过一遍,每一条只问三件事——背后的机制成不成立、被高估的是哪部分时间线对不对、这个季度具体该下什么注以及怎么验证它对你成立。最该当真的不是“AI会替你下单”,是“被AI记住比排第一更重要”,这条最被低估,也最难补。
每年年底到年初,行业里都会刷出一批2026预测。问题不是这些预测错——它们大多方向都对——问题是读完你什么也做不了。“AI会改变搜索”“品牌越来越重要”“要重视结构化数据”,这类话没法证伪,也没法落地,点个头就翻篇了。预测清单的价值从来不在那张清单本身,在校准:六条里哪条是承重墙、哪条被严重高估、哪条机制对但时间线被说早了、以及对着每一条到底该下什么具体的注。
这篇就干这件事。来源是六位行业负责人对2026 AI搜索可见度的判断——包括Writesonic的Samanyou Garg、Wix的Crystal Carter、NP Digital的Neil Patel、BrightEdge的Jim Yu、AI教育者Britney Muller等人各自的预测。保哥不打算复述他们说了什么,那种综述网上一抓一把;这篇把六条预测逐条拆机制、做校准、落到“这个季度做什么、怎么知道押对了”,并且专门挑出哪几条互相矛盾、出海中文品牌该怎么重新加权。
先划边界,免得和站内文章重复。“AI到底会不会消灭SEO、从业者怎么转型”这个问题,站内有一篇AI会不会消灭SEO与四季度转型时间表讲得很完整,那篇是职业生存视角;“被记住取代排名”这一条本身,站内有一篇识别度取代排名这件事的单独拆解讲透了,那篇是把这一个主题做深;AI搜索可见性具体怎么做的深层方法——实体、知识图谱、RAG——站内还有一篇AI搜索可见性的五维深层方法。这篇不重复那三件事,它的独特位置是:把2026这六个预测放在一起做相对权重和时间线的校准,再翻译成可下注、可验证的动作。
为什么大多数2026预测清单读完就忘?
一条预测要能用,得同时具备三样东西,缺一样就只是情绪:一个站得住的机制(为什么会这样,不是“感觉会这样”),一个可校准的时间线(2026全年、还是某个季度、还是其实还要两三年),一个能验证的动作(你做了它,怎么知道有没有用)。绝大多数预测清单只给了第一样的一半——给了结论没给机制,更别说时间线和验证。
这一节定个规矩,后面六条都按这套读:先讲机制成不成立,再校准它被高估还是被说早,最后给这个季度的动作和验证口径。一条预测如果机制不成立,再热也不跟;机制成立但时间线被说早了,就准备别冲;机制成立时间线也对,那就真下注,并且想好怎么验证它在你身上成立——不是验证这个行业,是验证你这门生意。这套读法本身比任何一条预测都值钱,因为明年还会有新的预测清单,方法不过期。
预测一:AI从“推荐”走向“替你下单”,这步到底多近?
这条说的是:AI不再只是告诉你哪双跑鞋好,它会直接帮你找到尺码、套上优惠券、完成结账——答案引擎在变成你的执行助理。支撑论据很硬:相关的代理商务协议已经被开源,Shopify商家据称一行代码就能开启对话内结账,技术管道确实在被铺平。
机制成立。一旦交易能在对话里闭环,用户没有理由再跳出去逛官网,这对“点击之后才发生转化”的整套打法是结构性冲击。但时间线被说早了一截,要分开看“技术就绪”和“行为就绪”。协议开源、一行代码能接,是技术就绪;用户愿意把支付和决策权交给AI代理、平台愿意放开这个口子、信任和退换货责任怎么界定,是行为和制度就绪——后者明显慢于前者,而且按品类、按市场差异极大。高客单、需要对比体验、退换敏感的品类,2026大概率还不会真的在对话里闭环;低客单、标准化、复购型的才是先发地带。
这个季度该下的注,不是赌它哪天来,是把“被代理读得懂”这件事补上——这件事无论它早来晚来都不亏。具体说:库存、价格、规格、可用性必须是机器能实时解析的结构化数据和接口,而不是埋在图片和JS里。验证口径很简单:拿你的产品页让一个AI代理去“尝试理解并比价”,它能不能不靠人就抽出准确的价格、库存、关键规格——抽不出,你已经在交易层之外了,这跟它哪年普及没关系。
预测二:SEO正在裂成两份工作,你该先押哪一份?
这条说的是:2026的SEO变成两件事——给人争点击,和给可能永远不访问你网站的AI代理供给干净、可信的输入。两件事的优化对象、衡量方式、甚至该归谁管,都不一样。
机制成立,而且是这六条里最该当成组织问题而不是技术问题来对待的一条。难点不在“知道有两份工作”,在大多数团队的人、KPI、汇报线都是按“给人争点击”那一份搭的,没人对“喂AI”那份负责,于是它长期没人做。但“先押哪一份”不该一刀切五五开,要按你的生意结构判:你的购买决策有多少发生在AI对话里、有多少还在传统点击里。决策前端越靠AI(高调研、长链路、B2B、复杂品类),越要往“喂AI”那份加码;冲动型、品牌词驱动、即时需求的,传统点击那份还得是基本盘。
动作:先做一次归属盘点——“喂AI代理”这份工作,现在谁的KPI里有它?大概率没人。在没有重组团队之前,至少先指定一个人对“AI能不能拿到我们干净可信的输入”这件事的端到端结果负责。验证口径:去几个主流AI引擎问你所在品类的典型决策问题,看AI引用和组织信息时,用的是不是你希望它用的那批事实和表述——不是,说明那份工作确实没人在做。
预测三:被记住比排第一更重要,这条最被低估?
这条说的是:大模型不像传统搜索那样去爬SERP、从前几名里挑,它是从训练数据和被引用的模式里建立对一个品类的理解。结果就是——一个页面排名再高,如果品牌没有在它的“认知”里建立起识别度和偏好,它在AI答案里依然不存在。
这条是六条里的承重墙,也是最被低估的一条。被低估的原因很现实:它最反直觉(做了二十年“怎么排上去”的人,很难接受排名不再是胜负手),见效最慢(识别度是攒出来的,不像技术修复立竿见影),也最难量化(没有一个像排名那样干净的数字)。越是这种又重要又难又慢的事,越容易被排在“以后再说”,然后就一直没做。
机制讲透一层:AI对一个品类的理解,来自这个品类被反复怎么谈论、谁和这个品类被一起提及、哪些来源被它当可信。所以可见度的战场从“你的页面在结果里第几”前移到了“你的品牌在它读过的那些地方,是不是作为这个品类的默认答案被反复念到”。这件事一旦建起来,比排名抗造得多,也更难被一次算法更新清零——代价是它不能临时抱佛脚。这一整条的深拆站内已有专文,这里不展开,只强调它在2026六个预测里的相对位置:如果只能动一件事,动这个。动作不是再优化排名,是排查你的品牌在AI读得到的地方有没有被作为品类答案反复、一致地提及;验证口径是直接问AI“这个品类有哪些靠谱品牌”,连续问、换措辞问,你的名字稳定出现还是飘忽或缺席。
预测四:搜索“到处都是”,多平台到底要不要全做?
这条说的是:用户的调研行为正在碎到多个平台、多种格式、多个AI界面上,碎片化成了常态,单押一个入口越来越危险。
机制成立,但这条最容易被误读成“所有平台都要做”——那是另一种死法。“到处都是”描述的是用户行为的事实,不是给你的待办清单。资源有限的团队如果听成“全都要”,结果是每个平台都浅尝辄止、每个都做不透,比专注一个还糟。正确的读法是:用户在哪几个地方真正做你这门生意的决策调研,把那几个做透,其余的知道存在、不投入。
动作:做一次“决策发生地”盘点,而不是“平台覆盖”盘点。问你的真实客户(不是凭想象):你决定买我们这类东西之前,会在哪查、问谁、看什么。把答案按出现频率排序,资源压在前两三个,剩下的明确放弃。验证口径不是“我们覆盖了几个平台”,是“在客户真正调研的那两三个地方,我们是不是被找得到、且呈现得对”。覆盖数是虚荣指标,决策地命中率才是。
预测五:AI接手四分之一的搜索,这个数该怎么用?
这条说的是:AI助手预计将处理大约四分之一的搜索查询。这个数被引用得很多,也最容易被用错。
机制方向成立,但“四分之一”这个总量数字本身几乎没有决策价值,会用的人看的是分布不是总量。关键不是“整体25%”,是这25% 落在哪类查询上——信息型、答案型、可被一句话回答的查询被AI接走的比例远高于平均,而交易型、需要个性化判断、强本地性的查询被接走的比例远低于平均。如果你拿整体25% 去拍所有内容的策略,你会在“其实没怎么被接走”的交易型上过度恐慌,又在“早就被接走大半”的信息型上反应不足。
动作:别用行业平均数,算你自己的查询结构被接走的比例。把你带业务的查询按类型分档,逐档去看在主流AI入口里它是被直接答掉、还是仍然导向点击。验证口径是这张“你自己的分档接管率表”,它会告诉你哪些内容该认命转去做“被AI引用”、哪些点击还在值得继续争。拿别人的总量数当自己的决策依据,是这条预测最大的坑。
预测六:能不能被AI代理读懂,正在变成生死线?
这条说的是:未来的代理如果没法实时解析你的库存、价格、可用性,你就不存在于交易层——机器可读性和接口兼容性从加分项变成了入场券。
机制成立,且这是六条里最不该犹豫、性价比最高的一条,因为它几乎没有押注风险——把数据做成机器可读,无论代理普及快慢、无论用户行为怎么变,都不会亏,最差也只是提前做了迟早要做的基础工。它和预测一是一体两面:预测一讲交易闭环这个“果”,预测六讲机器可读这个“因”,因不具备,果一定轮不到你。
动作很具体:产品和服务的核心事实——价格、库存、规格、可用性、适用条件——必须以结构化数据、数据馈送、或接口的形式,让机器不靠渲染页面、不靠人就能准确拿到,并且保证它和页面展示实时一致(不一致比没有更糟,会喂错AI)。验证口径:用程序化方式(不经过浏览器渲染)去抓你的关键事实,抓到的和页面上人眼看到的是否一字不差、是否实时同步——这一步今天就能测,不用等任何预测兑现。
六个预测里,哪些互相矛盾,该信哪条?
把六条摆在一起,会看到它们不是平行的六件事,而是有主有次、甚至局部张力的一张图。理清这张图,比记住六条本身重要。
| 预测 | 机制 | 时间线校准 | 2026优先级 |
|---|---|---|---|
| 三·被记住胜过排名 | 承重墙 | 现在就慢慢攒,越晚越亏 | 最高 |
| 六·机器可读是入场券 | 成立·零押注风险 | 本季度就能做 | 高 |
| 二·SEO裂成两份工作 | 组织问题 | 本季度先定责任人 | 高 |
| 五·AI接手约四分之一 | 看分布不看总量 | 用自己的分档表 | 中 |
| 四·搜索到处都是 | 是事实不是清单 | 聚焦决策发生地 | 中 |
| 一·AI替你下单 | 成立但时间线被说早 | 别冲,先备好可读性 | 偏低(除低客单复购品类) |
张力在哪:预测四(到处都是)和资源现实天然矛盾——它描述的是用户行为的发散,你的应对却必须收敛,听话照做“全都要”就是被它带沟里。预测一(替你下单)和预测三(被记住)则有先后——很多人兴奋于前者那个性感的画面,急着去接结账协议,却跳过了后者那个不性感但承重的地基;可现实是,如果AI在“该推荐谁”这一步就没把你算进去,后面那个一行代码的结账接得再顺,也没有它替你下单的份。所以这张图真正的主线只有一句:可见度的胜负手正在同时向两个方向移动——向点击之前移(被不被AI记住),和向SERP之外移(在不在AI的认知和交易管道里)。六条预测都是这条主线的不同侧面,认准主线,单条预测兑现早晚就没那么重要了。
出海中文品牌看这六个预测,哪几条要打折、哪几条要加码?
这六条预测的默认语境是英文、是欧美市场。出海中文品牌照搬会踩两类偏差,得重新加权。
要加码的:预测三(被记住)对出海品牌权重还要再调高。原因是结构性的——中文品牌在英文训练数据和被引用模式里的存在感,普遍远低于本土品牌,AI对“这个品类有哪些靠谱品牌”的默认认知里,你大概率一开始就不在名单上。本土品牌是巩固识别度,出海品牌是从零进入它的认知,难度和紧迫性都更高,这一条对你不是最高优先级,是生死线。
要打折和重判的:预测一(替你下单)和预测四(到处都是)都要按目标市场重新校。代理结账的制度和信任就绪程度、用户把决策权交给AI的意愿,按国家差异巨大,用一个全球时间线拍你的目标市场会错得离谱;“搜索到处都是”里的“到处”,在不同市场是不同的几个地方,照搬欧美的平台清单等于没盘点。这两条对出海品牌都要落到“具体哪个市场、哪个品类”再判,不存在全球统一答案。预测六(机器可读)则对所有市场一致成立,没有打折空间——它是基础工,哪个市场都躲不掉。
这个季度具体下哪几个注,怎么验证押对了?
把校准结果压成一张可执行的下注表,按优先级排,每个注都带它自己的验证口径——验证的是“在你身上成立”,不是“这个行业是不是这样”:
- 注一·补机器可读(预测六,本季度就做):核心事实结构化、可程序化获取、与页面实时一致。验证:不经浏览器渲染抓关键事实,与页面一字不差且实时同步。
- 注二·定“喂AI”责任人(预测二,本季度就定):指定一个人对“AI拿到的是不是我们希望它用的输入”端到端负责。验证:去主流AI引擎问品类决策问题,看引用的事实和表述是不是你想要的那批。
- 注三·开始攒识别度(预测三,本季度起持续):排查并补齐品牌在AI读得到的地方、作为品类答案被一致提及的程度。验证:连续、换措辞地问AI“这个品类有哪些靠谱品牌”,你的名字是否稳定出现。
- 注四·算自己的接管率分档表(预测五,本季度一次):带业务的查询按类型分档,逐档看被AI接走还是仍导向点击,据此重配内容投入。验证:这张表本身就是产出,按它调过一轮后下季度复跑看分布变化。
- 不下的注:不为“AI替你下单”抢着接结账协议(除非你是低客单复购标准化品类),不为“搜索到处都是”铺全平台。这两个“不做”同样是决策。
这套下注表的共同点:每一个注,无论对应的预测今年兑不兑现,做了都不亏——这是把预测转成行动时最该守的纪律,叫“押不会后悔的注”。任何一个注,如果它只有在某条预测正好兑现时才有意义、不兑现就纯亏,那它就是赌不是下注,别下。
哪些跟预测的方式,看着前瞻其实在追热点空转?
- 把预测清单当成路线图照着做。清单是别人对趋势的判断,不是你的执行计划,逐条照做必然顾此失彼、资源摊薄。
- 挑最性感的那条冲(通常是“AI替你下单”),跳过最承重那条(“被记住”)。性感的见效画面诱人,但地基没打,性感的那步根本轮不到你。
- 用行业平均数当自己的决策依据。“AI接手25%”“某某要全平台”,不算自己的分布就拍策略,错得理直气壮。
- 为没法验证的目标做优化。定了一个连自己都说不清怎么算赢的方向(“提升AI可见度”),半年后既证明不了有用也证明不了没用,等于没做。
- 每出一份新预测清单就调一次大方向。预测年年有、各家口径还打架,跟着每份清单转向,一年下来哪条都没做透。认主线、用固定方法校准,比追清单稳得多。
说到底,预测本身不创造价值,对预测的校准和按校准结果下注才创造价值。明年这个时候还会有新的2026之后的预测清单刷出来,那时候真正有用的,不是你记住了今年这六条,是你有没有把“拆机制、校时间线、押不后悔的注、定可验证口径”这套读法变成肌肉记忆。预测会过期,这套读法不会。
承重墙那条的机制,到底为什么排名救不了你?
预测三被列为承重墙,但“大模型不爬SERP”这句话太笼统,得把机制再拆一层,否则你不知道该往哪使劲。
大模型对一个品类的“认知”,来自两个不同的层,作用方式完全不一样。第一层是参数化记忆——训练阶段,这个品类被怎么反复谈论、谁和它一起被提及、哪些来源被当成可信,沉淀进了模型权重。这一层决定了你问“这个品类有哪些靠谱品牌”时,它脑子里默认浮现的那张名单。这张名单不看你今天排第几,它是过去很长一段时间里“品类讨论”的沉淀结果,排名再高也进不去,因为排名根本不是这一层的输入。第二层是检索增强——回答时,系统去外部抓一批当下内容补充。这一层看起来给了排名一点空间,但有两个反直觉点:它抓的不一定是传统排名前几,更可能是结构清晰、能被直接抽出干净论断的页面;而且抓回来之后,模型还是用第一层那套已经形成的认知去筛选和组织这些片段——如果你不在它的认知里,它抓到你的内容也倾向于不采信、或不把你和品类的“好答案”关联起来。
这就解释了那个让做了二十年排名的人难受的事实:排名是“在用户搜某个词时,让你的页面出现在结果靠前”,而AI可见度是“在模型对这个品类的认知里,你作为答案被反复、一致地记住”。前者是页面级、查询级、即时的;后者是品牌级、品类级、累积的。优化前者完全不喂养后者——你可以霸占某词第一名整年,而模型对你这个品类的认知里依然没有你,因为它从没把“某词排第一”当过输入。明白这层机制,才知道“攒识别度”具体是攒什么:是让你的品牌在它训练会读到的地方、作为这个品类的可信答案,被足够多、足够一致地一起提及,直到这件事沉进它的参数化记忆,而不是反复优化那个它根本不看的排名数字。这一整套具体怎么落地、攒哪些信号,站内那篇识别度专文讲得细,这里只把“为什么排名救不了”这层机制讲透——因为不讲透,大多数人会继续把预算投在他熟悉但无效的那个动作上。
这份清单没说、但同样要紧的预测是什么?
一份预测清单的价值,一半在它说了什么,另一半在它系统性回避了什么。这六条整体偏“机会侧”,几个同样会决定2026可见度的判断没进清单,补在这里。
第一个没说的:可信来源会加速收敛。当模型越来越依赖“被哪些来源一起提及”来判断可信,结果不是百花齐放,是马太效应——少数已经被反复引用的来源会被进一步加权,新进入者越来越难挤进那个被信任的集合。这条对出海新品牌是坏消息,意味着“攒识别度”的窗口正在变窄,越晚动越贵,它其实是预测三的紧迫性注脚,但清单回避了这个不那么乐观的推论。
第二个没说的:度量会长期处于半盲。六条都在讲该做什么,没有一条诚实面对“你怎么知道做了有没有用”。现实是AI可见度的度量工具远不成熟,且AI答案高度不稳定、个性化、难复现,这意味着2026你很可能要在“看不太清效果”的状态下持续投入。承认这一点很重要,否则你会因为短期量不出效果而误判策略失败、半途砍掉那条最该坚持的承重墙投入。
第三个没说的:押错时间线的代价是不对称的。预测把“会发生”说得很确定,但很少讲“早押和晚押分别亏多少”。这件事的不对称性是关键决策依据:像机器可读、攒识别度这类,早做最差只是提前做了基础工,亏的是一点时间;像抢接结账协议这类,押早了是真金白银打水漂还占用本该投向地基的资源。看不见这个不对称,就会被“都很重要”这句话拖去平均用力,而正确做法是把资源压在“早做不亏”的那几条上,对“押早了会真亏”的那几条保持克制。这恰恰是一份预测清单天然不会告诉你的——它负责让你兴奋,不负责帮你控制下注风险。
把这套校准用在一个出海3C品牌身上,长什么样?
方法讲再多,不走一遍还是抽象。拿一个典型场景过一遍:一个做消费电子配件、主攻欧美和东南亚的出海品牌,看完这六条预测,按本文的读法该得出什么。
先排优先级。预测三(被记住)对它是生死线而非最高优先级那么轻描淡写——它是中国品牌,在英文训练数据里几乎不存在,AI回答“平价某配件有哪些靠谱牌子”时默认名单里没有它,这是它当前最大的隐形失血点,且按上面补的“可信来源收敛”机制,越晚越难。预测六(机器可读)当本季度必做的零风险基础工,它是卖货的,库存价格规格能不能被代理实时读懂,直接决定它在不在未来交易层,且这事做了无论代理快慢都不亏。预测一(替你下单)对它要分市场看:它的配件品类客单低、标准化、复购高,恰恰是代理结账最可能先落地的地带,所以它比大多数品类更该认真准备——但准备的方式不是抢着接协议,是先把预测六做扎实,因为没有机器可读这个因,结账闭环这个果轮不到它。
再看该放弃什么。预测四(搜索到处都是)对它最大的价值是提醒它别全平台铺。它资源有限,正确动作是去问真实买家“你买这类配件前会在哪查、问谁”,大概率答案高度集中在一两个地方,把那一两个做透,其余明确不投。预测五(四分之一)对它的用法是算自己的分布:它的查询里“某配件兼容某机型吗”这类信息型占比很高,这部分被AI直接答掉的比例远超平均,意味着它该尽早把这类内容的目标从“争点击”转成“被AI准确引用”,而不是继续按旧打法死磕这批词的排名。
最后落成本季度的下注:补机器可读(注一)、定一个人对“AI拿到的输入对不对”负责(注二)、开始系统攒英文世界的品类识别度(注三)、算出自己的查询接管率分档表据此重配内容(注四)、明确不抢结账协议也不铺全平台(两个不做)。每一个注,无论这六条今年兑现几条,做了都不亏——这就是把一份让人兴奋的预测清单,真正榨出决策价值的样子。
不同目标市场,这六条要怎么分别重判?
“出海”不是一个市场,是好几个差异极大的市场,用一套全球判断拍所有目标市场,错得会很具体。按市场把最受影响的几条重判一下。
| 市场 | 预测一·替你下单 | 预测三·被记住 | 预测四·决策发生地 |
|---|---|---|---|
| 北美 | 最快落地,低客单品类要认真备 | 训练数据竞争最激烈,最难挤进 | 分散在多个AI入口与垂直平台 |
| 欧洲 | 慢于北美,受合规与信任拖累 | 多语种,每种语言要单独攒 | 本地平台权重高于北美 |
| 东南亚 | 整体偏慢,移动与社交电商先行 | 英文与本地语混杂,门槛相对低 | 高度集中在社交与即时通讯 |
| 中东 | 最慢,制度与支付习惯差异大 | 阿拉伯语内容稀缺,先发红利大 | 平台与语言都需本地化重判 |
这张表的用法不是记结论,是建立一个习惯:拿到任何一条全球口径的预测,先问“它默认的是哪个市场,我的目标市场和这个默认差在哪三件事上”。比如“AI接手四分之一搜索”这个数,几乎肯定是基于成熟英文市场算的,照搬到东南亚或中东会高估;“代理结账今年起飞”默认的是北美生态,照搬到合规更重的欧洲或支付习惯不同的中东会押早。预测六(机器可读)是少数所有市场一致成立、没有打折空间的——它是基础工,哪个市场都躲不掉,这也是它该被无脑优先做的又一个理由。把“按市场重判”变成读每条预测的固定动作,比记住任何一张表都管用,因为市场会变,这个追问的习惯不会过期。
只剩很少时间和预算,这六条该砍到只做哪一件?
预测清单默认你有资源把该做的都做了,但很多团队的真实处境是:人就这么几个,钱就这么点,六条全做是奢望。这时候需要一个清单天然不会给的东西——分诊优先级,砍到只剩一件该做哪件。
答案是预测六(机器可读),不是预测三(被记住)。这看起来和前面“承重墙是预测三”矛盾,其实不矛盾,是两个不同问题的答案:要问“长期最重要”,是预测三;要问“资源极限下只够做一件且不能赌”,是预测六。原因有三个,全是约束条件下的硬道理。其一,预测六见效路径最短、最不依赖长期累积,识别度要攒很久才看得到,机器可读做完当下就生效。其二,预测六几乎零押注风险,做了无论别的预测兑不兑现都不亏,而资源极限时最承受不起的就是押错。其三,预测六是预测一和预测二的共同前提——数据不可读,替你下单和喂AI代理都无从谈起,做它等于同时给另外两条留了门。
所以分诊逻辑是这样分层的:只够做一件,做预测六,因为它短、稳、还是别条的地基;能再多做半件,挤出时间指定一个人对预测二那件“喂AI的输入对不对”负责,这件事不要钱只要责任归属;资源再松一点,才开始动预测三那场必须长期投入的硬仗。把这个分层记住,比记住六条预测本身更适合资源紧张的团队——它回答的不是“理想情况下做什么”,是“现实约束下先保什么”,而后者才是大多数人真正要做的决策。
常见问题解答
问:这么多2026预测,到底该信哪一条?答:别按“信哪条”想,按“哪条机制成立、时间线没被说早、且做了不后悔”筛。这六条里被记住胜过排名是承重墙,机器可读是零风险基础工,这两条最该当真,AI替你下单则要按品类和市场打折。
问:“AI替你下单”是不是2026就要全力准备结账协议了?答:技术就绪不等于行为和制度就绪。高客单、强体验、退换敏感品类2026大概率还闭不了环。该准备的不是抢接协议,是把库存价格规格做成机器可实时读取——这件事它早来晚来都不亏。
问:六条预测里只能先做一件,做哪件?答:做“被AI记住”。它最反直觉、见效最慢、最难量化,所以最容易被拖,但它是承重墙——排名再高,AI认知里没有你的品牌作为品类答案,你在AI答案里就不存在,且这事不能临时抱佛脚。
问:出海中文品牌看这些预测要做什么不同处理?答:被记住这条权重再调高,因为中文品牌在英文训练数据和被引模式里存在感普遍偏低,是从零进入AI认知;AI替你下单和搜索到处都是要按具体目标市场重判;机器可读对所有市场一致成立,没有打折空间。
问:“AI接手四分之一搜索”这个数怎么用?答:别用这个总量数。要把你带业务的查询分类型,逐档算被AI接走还是仍导向点击。被接走多的信息型认命转去争被引用,仍导向点击的交易型继续争点击。用行业平均拍全局是最大的坑。
问:怎么验证我跟着预测做的事到底有没有用?答:每个动作都要带它自己的验证口径,验证的是在你身上成立而非行业成立。比如识别度就连续换措辞问AI品类靠谱品牌看你是否稳定出现,机器可读就不经渲染抓关键事实看是否与页面一致。说不清怎么算赢的方向不要做。
权威参考资料
本文标题:《2026 AI搜索可见度的6个预测,哪些该信、哪些该打折?》
本文链接:https://zhangwenbao.com/ai-search-visibility-predictions-2026.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0