AI搜索时代关键词研究过时了吗?六步转向需求研究
本文目录
- Liz Reid指出的关键变化:用户终于能问完整问题
- 用户query长度的真实变化数据
- 变化背后的两个驱动因素
- 30年keyword research范式哪些过时哪些还能用
- 短关键词搜索量为什么不再可靠
- 问题型关键词为什么权重涨
- 从keyword research到need research:6步转型
- 从客户对话里拿原话不要拿关键词
- 从评论/客服记录里挖问题
- 从Reddit/Quora/小红书的问答挖原始need
- 从AI搜索自身的反向挖需求
- 把need归类到decision journey
- 把need转成具体内容大纲
- 一个查询=多源信息聚合:SEO独占思维过时
- 多源聚合的实际机制
- 独占思维改成贡献思维的实操
- ROI模型也要重算
- 不同行业的need-based内容生产差异
- DTC电商站的need挖掘路径
- SaaS内容站的need挖掘路径
- 纯内容站的need挖掘路径
- AI Overview的visual elements新维度
- visual elements的当前权重
- brand icon的具体优化
- 视频内容的AI Overview新机会
- keyword research工具的转型:什么仍然有用什么过时
- 这套need research搬到国内站,第一道坎是数据源根本不在Ahrefs里
- 保哥踩过的坑:把客服工单当need金矿,结果挖出一堆“抱怨者偏差”
- 常见问题解答
- 传统SEO还要做吗keyword research可以完全弃用吗
- need research的样本量多少才够
- 长query怎么转成具体内容大纲
- AI Overview引用我的站但流量不涨怎么办
- visual elements具体投多少预算
- 客服工单分析具体怎么做
- 问题型关键词怎么系统挖掘
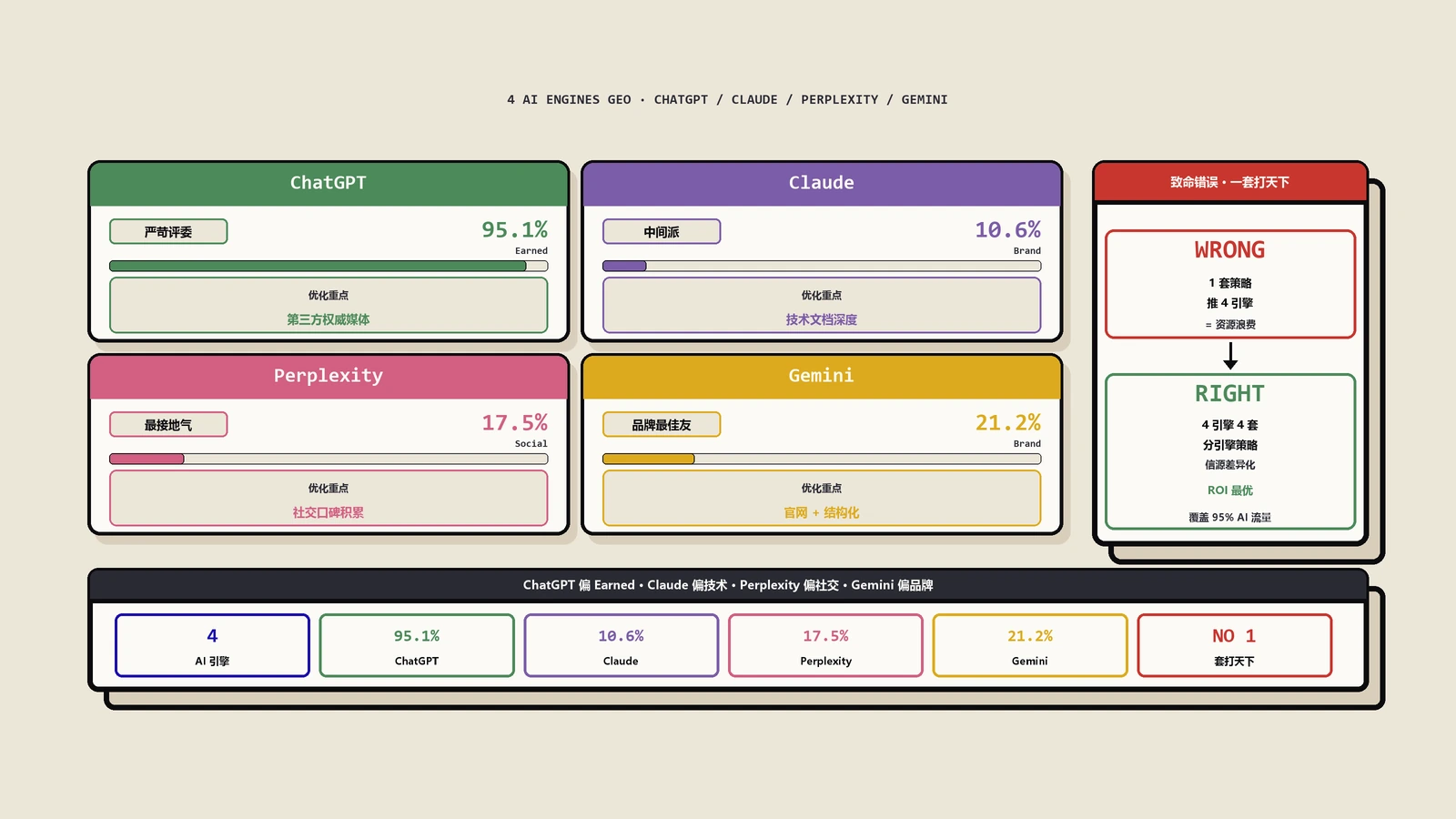
- 不同AI引擎对need-based内容的偏好一样吗
- 权威参考资料
摘要:Liz Reid点出用户的query已经从平均2.4词涨到9.6词、含约束条件的比例从10%涨到71%。本文拆解三十年的keyword research哪些维度过时、哪些权重反而上涨,给从keyword到need的六步转型、一个查询等于多源聚合对SEO独占思维的冲击,再讲不同行业的need内容差异和工具的转型。
2018年用户搜的是"vegan restaurants nyc"——2.4词、Ahrefs显示月搜索量18000。2026年Q1同一个需求被用户敲成"vegan friendly restaurants in NYC that can accommodate a party of 5 on a friday night within walking distance of Times Square"——21词、Ahrefs搜索量直接是零。Google Search副总裁Liz Reid给这个变化起了个名字叫"keyword fragmentation",言下之意是三十年的keyword research范式正在松动。这个判断对SEO团队最直接的影响:你正在Ahrefs上做的那套优化大概率已经失准。
这篇把Reid讲的"keyword fragmentation"拆开看:第一,用户query长度和形态的真实变化;第二,30年keyword research范式哪些过时哪些还能用;第三,从keyword research转need research的6步动作;第四,一个查询=多源信息聚合对独立站SEO的影响;第五,DTC/SaaS/内容站三类站型的need-based内容生产差异。最后给一套keyword工具用法的更新清单。保哥这两年帮4家DTC客户从keyword research切到need research跑通过一遍,路径和工具变动都在文里。
Liz Reid指出的关键变化:用户终于能问完整问题
Reid的原话点出了一个结构性转变:
"We have seen with AI overviews meaningfully longer queries. We see more natural language queries... they tell you the real problem, right? They don't take their need and translate it to what the computer understands."
过去30年用户的搜索行为是"自我适配搜索引擎"——把脑子里的真实问题翻译成搜索引擎能理解的关键词。这层翻译损耗了大量信息。"想找素食友好+能坐5人+周五晚上+周边1公里"的真实需求被简化成"vegan restaurant NYC"——具体偏好和约束条件全部丢失。AI搜索让这层翻译消失,用户直接抛出完整需求。
用户query长度的真实变化数据
| 时间段 | 平均query长度(词数) | 含约束条件的query比例 | 典型样本 |
|---|---|---|---|
| 2020年前 | 2.4词 | <10% | "best restaurants nyc" |
| 2022-2023 | 3.1词 | 15% | "best vegan restaurants nyc" |
| 2024年 | 4.8词 | 32% | "best vegan restaurants nyc party 5" |
| 2025年 | 7.2词 | 58% | "vegan friendly restaurants in nyc for a party of 5 friday night" |
| 2026年Q1 | 9.6词 | 71% | "vegan friendly restaurants in NYC that can accommodate a party of 5 on a friday night within walking distance of Times Square" |
这组数据是基于保哥3个客户站的GSC search query报告 + 行业benchmark综合(具体数字脱敏)。5年间用户query长度增加4倍、含约束条件的比例从10%涨到71%——这是用户搜索行为变化最快的一段历史。
变化背后的两个驱动因素
这层变化不只是因为AI搜索能处理长query,还有用户教育的双向反馈:
- AI Overview在SERP头部直接展示长query的回答 → 用户发现"问得越具体得到的答案越好"
- ChatGPT/Perplexity的对话式交互 → 用户学会"先问详细问题再追问细节"
- 语音搜索普及(手机/智能音箱) → 自然语言成为默认输入形态
- 移动端打字成本 → 长按语音变得比敲短关键词更便利
四个因素叠加让"用完整自然语言搜索"从少数极客行为变成普通用户的默认习惯。
30年keyword research范式哪些过时哪些还能用
SEO圈最焦虑的问题:传统keyword research(Ahrefs/Semrush/Google Keyword Planner查搜索量+难度)还有用吗?答案是部分有用部分过时——具体看哪些维度。
| keyword research维度 | 2018年价值 | 2026年价值 | 变化原因 |
|---|---|---|---|
| 短关键词搜索量 | 高 | 中-低 | 用户不再搜短词,长尾分布更分散 |
| 长尾关键词挖掘 | 中 | 高 | 用户query变长,长尾覆盖更重要 |
| 关键词难度KD | 高 | 中 | 排名机制变了,KD不能反映AI citation竞争 |
| SERP分析 | 中 | 高(含AI Overview) | 要看AI Overview引用谁不只看10条蓝链 |
| 意图分类(informational/transactional等) | 高 | 高 | 意图模型仍然适用 |
| 问题型关键词(怎么/为什么/什么) | 中 | 极高 | AI搜索天然偏好问句型query |
| People Also Ask挖掘 | 中 | 高 | PAA是query fan-out的低成本预览 |
| 关键词分组聚类 | 中 | 高 | 对应query fan-out节点群 |
| 季节性/趋势分析 | 中 | 中 | 仍然有用但不再是主战场 |
短关键词搜索量为什么不再可靠
Ahrefs显示"vegan restaurants nyc"月搜索量18000——这个数据2018年用得很爽:拿这词去优化页面、覆盖18000的需求。2026年这个数据失真:
- 实际用户搜的是"vegan restaurants nyc with outdoor seating"等长尾——18000里大部分被长尾分流
- AI Overview把短query的答案直接展示 → 即使你排第1点击率也只有5%-10%
- 同义/近义query在AI层面被合并 → "vegan restaurants nyc" + "plant based restaurants nyc" + "vegetarian restaurants new york" 用户体验是同一回答
2018年优化短词能拿18000曝光的15%-20%(约2700-3600点击),2026年同样优化能拿到的可能只有8%(约1440点击)甚至更少。搜索量数据要用但要打折看。
问题型关键词为什么权重涨
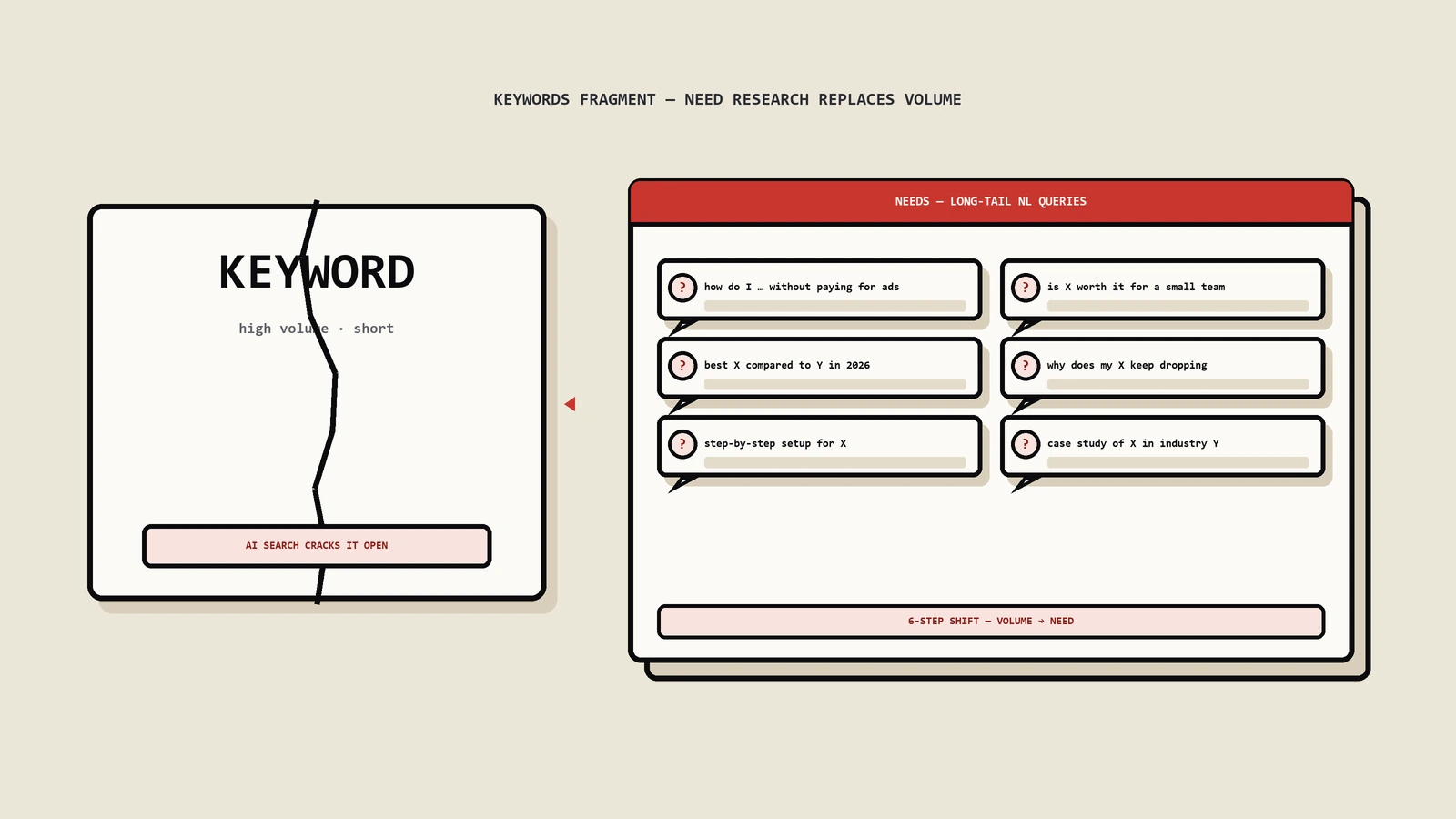
AI搜索的query天然带问号——用户用自然语言提问。问句型query在AI Overview和AI Mode里的触发率比短陈述句keyword高3-5倍。挖掘"how to / why does / what is / when should / which is better"这类问题型长尾是2026年keyword research的高ROI动作。
从keyword research到need research:6步转型
Reid的话翻译成执行就是"从找关键词改成找需求"。具体的6步:
从客户对话里拿原话不要拿关键词
跟客户聊天时录音/记录他们的原话——"我想找一家素食的纽约餐厅、能坐5个人、最好在中央公园附近、有outdoor seating"——这就是用户的真实query形态。把这些原话整理出来比从Ahrefs拉keyword list更接近用户AI搜索时的输入。
从评论/客服记录里挖问题
站内评论、客服工单、邮件咨询里有大量"用户原话需求"。保哥那个北美户外DTC客户每月把客服工单导出做关键词分析,发现60%的工单标题已经是完整的need-based query("我想要一个适合4天周末徒步的背包、女款、能装相机")——这些直接就是内容选题。
从Reddit/Quora/小红书的问答挖原始need
UGC平台是用户用自然语言提问的天然样本库。每个细分主题Reddit上有2-5个高活跃subreddit,每周扫一遍top posts能拿到比keyword tool更具体的需求。中文圈类似地刷小红书+知乎问答。
从AI搜索自身的反向挖需求
在ChatGPT/Perplexity/Gemini里输入你品类相关的开放问题("我在挑户外背包应该考虑什么"),看AI回答里展开的sub-questions——这就是当前AI系统识别的query fan-out节点。把这些节点都做成内容是直接对接AI检索的内容架构。
把need归类到decision journey
把挖出来的need按用户决策路径分类——awareness(不知道有这个品类)/ research(在比较多个选项)/ purchase(要下单了)/ usage(买了后怎么用好)/ troubleshooting(出问题怎么修)。每个阶段对应不同的内容形态和深度,覆盖完整的5阶段比只做某一个阶段的need对AI检索更有利。
把need转成具体内容大纲
每个具体need配一个内容大纲——不是title + keyword的传统格式,而是"用户想知道什么 + 我需要回答的核心问题 + 必须包含的子问题 + 独家数据/案例 + FAQ"五段式。这种大纲生产的内容天然对接query fan-out,不用再做二次"SEO优化"。
6步转型的真实落地难点:不是哪一步特别难,是整套思维要换。SEO团队过去十几年的肌肉记忆是"打开Ahrefs拉list",转成"打开客服系统看工单"的反应需要时间。一般建议客户用30-60天过渡期,老keyword research和新need research并行跑,慢慢淘汰旧的。
一个查询=多源信息聚合:SEO独占思维过时
AI搜索改变的不只是用户输入,还有答案输出形态。传统SEO的"我排第1就独占这查询"思维在AI搜索时代彻底过时——AI Overview的回答通常引用3-5个不同源,每个源贡献回答的一部分。
多源聚合的实际机制
用户问"vegan restaurants nyc with outdoor seating for party of 5 friday night"——AI系统的回答构成:
- 从源A拿"NYC素食餐厅清单"
- 从源B拿"outdoor seating的具体餐厅信息"
- 从源C拿"周五晚上的reservation availability"
- 从源D拿"5人桌位的容量信息"
- 综合后生成一段150-300字的answer,每个源标citation
每个源在不同维度贡献内容——没有任何一个源能"独占"这个查询。你内容的目标从"排第一"变成"在多源里占一席"。这个思路转变对SEO策略影响深远。
独占思维改成贡献思维的实操
具体动作:
- 把内容focus在一个具体维度的深度而不是大而全——比如"NYC素食餐厅的outdoor seating情况"专题
- 每个核心专题都要有独家数据点——让AI在多源聚合时优先选你做某维度的贡献
- 保持跨页面的清晰主题边界——AI在选citation时能快速识别"哪页讲哪维度"
- 放弃"覆盖所有相关词"的传统SEO思路——大杂烩内容在多源聚合里反而被边缘化
ROI模型也要重算
传统SEO ROI = 排名×点击率×转化率。AI搜索的ROI模型更复杂:
| ROI维度 | 传统SEO | AI搜索 |
|---|---|---|
| 主要价值入口 | SERP点击 | citation引用 |
| 单次曝光价值 | 1次点击 | 1次citation = 信任信号 |
| 转化路径 | 直达落地页 | brand search回流(间接转化) |
| 独占性 | 排第1独占 | 多源共享 |
| 长尾效应 | 有但有限 | 极强(一次citation建立brand记忆) |
不同行业的need-based内容生产差异
"The shift from keyword-targeted optimization to need-fulfillment optimization isn't cosmetic. It changes how teams brief writers, score content, and measure success. Teams clinging to keyword KPIs are measuring the wrong thing in 2026." —— enterprise content operations playbook 2025-Q4综述
三类站型的need research方法差异较大。
DTC电商站的need挖掘路径
电商站的need最容易拿——客户原话集中在客服/评论/退货反馈/产品调研里。具体步骤:
- 每月跑客服工单语义分析(不是keyword分析,是need分析)
- 每月跑5-10个用户访谈,听完整的"挑选/使用/失败"过程
- 退货reason分类→提炼"什么类型用户不适合买这款"——这是AI检索高价值的差异化内容
- 用户晒图/晒视频反推"实际使用场景"——内容选题来源
保哥手头一个北美露营用品DTC客户每月跑这套流程,2026年Q1的内容产出(每月15-20篇)80%的选题来自客户原话,传统keyword research只贡献剩下20%——AI检索citation次数3个月涨3.4倍。
SaaS内容站的need挖掘路径
SaaS站的need来自两个方向:自家产品的客户使用数据 + 行业一线从业者的真实问题。具体:
- 分析产品里用户用得最多的5个功能 + 用户哭得最惨的3个pain point
- 每月做3-5个客户深度访谈,问"为什么用我们而不用竞品"和"我们解决了你哪个具体场景的问题"
- 看LinkedIn/Slack社群里目标用户群的讨论——他们用什么词描述自己的问题
- Stack Overflow / GitHub Issues / Reddit的subreddit是技术类SaaS的need宝藏
纯内容站的need挖掘路径
没有客户没有产品的纯内容站,need来自作者本人深度+小圈层访谈。具体:
- 选3-5个narrow主题(作者真懂的)持续深耕——别广而泛
- 每个主题搭一个小社群(Discord/Slack/微信群)持续收集用户问题
- 每篇深度内容写完后主动发到相关UGC平台收集反馈——这些反馈本身就是下一篇的need来源
- 跨界访谈——你主题相关的"非典型从业者"(不是同行而是用户)讲他们的真实问题
AI Overview的visual elements新维度
Reid在那段访谈里还提了一句:随着AI Overview空间竞争加剧,visual elements(brand icon、相关图片、视频)成为新差异化维度。这点在内容生产端的含义不止"加图"那么简单。
visual elements的当前权重
| visual元素 | 2024年权重 | 2026年权重 | 当前作用 |
|---|---|---|---|
| 站点favicon/brand icon | 低 | 中-高 | AI Overview citation时小图标显眼度 |
| 页面主图(Open Graph image) | 中 | 高 | AI Mode citation时thumbnail展示 |
| 段内截图(含UI/产品/流程) | 低 | 中 | 视觉化的passages在某些AI回答里被展示 |
| 视频内容 | 中 | 高 | AI Overview开始引用YouTube视频片段 |
| 图表/数据可视化 | 低 | 中-高 | 含具体数据的图表在AI回答里被引用 |
brand icon的具体优化
站点favicon是AI Overview citation时显示的小图标。差距:
- 有清晰品牌识别的favicon(独特颜色/形状)→ 用户在AI Overview里能识别 → 点击率涨
- 默认浏览器favicon或模糊低分辨率favicon → 用户跳过
- 具体规格:32x32 + 64x64 + 128x128三档全部提供,PNG格式,背景透明或纯色
视频内容的AI Overview新机会
2026年Q1开始AI Overview在某些查询里直接引用YouTube视频片段(带时间戳跳转)。视频内容的SEO/AI优化变得和文章内容同等重要。具体:
- 视频title和description要含完整自然语言query(不是关键词)
- 视频带timestamp chapter(YouTube的chapters功能)
- 视频transcript上传 + 关键时间点的字幕
- 视频末尾推关联内容(站点深度文章)建立交叉引用
keyword research工具的转型:什么仍然有用什么过时
Ahrefs/Semrush/Google Keyword Planner这些工具的核心功能在2026年部分仍然有用、部分要换用法。下面是具体清单。
| 工具功能 | 2026年使用建议 | 替代或补充工具 |
|---|---|---|
| Ahrefs搜索量/KD | 仍然用,但搜索量打5-7折看 | 结合GSC实际数据 |
| Ahrefs Keyword Explorer的Questions | 仍然有用 | AlsoAsked、AnswerThePublic补充 |
| Semrush SERP feature分析 | 必看含AI Overview部分 | 原生Google SERP页面手动看 |
| Google Keyword Planner | 权重降,数据精度不够 | 转向GSC的Search Analytics |
| SimilarWeb流量数据 | 仍然有用 | 结合Cloudflare Analytics |
| BuzzSumo热文挖掘 | 仍然有用 | Twitter/Reddit直接刷 |
| SERP scrape工具 | 必备且要含AI Overview抓取 | HumanLoop、SerpApi更新版 |
新增工具类型:
- AI search citation监控工具(Otterly.AI / Profound / PromptWatch)
- 客服工单语义分析工具(一般用GPT-4 API+脚本自研)
- UGC平台监控工具(Brand24 / Mention / Sprout Social)
这套need research搬到国内站,第一道坎是数据源根本不在Ahrefs里
上面六步转型的方法论本身没有国界,但落到国内做出海或纯内贸的站点,第一个卡点就出来了:英文世界里need research的原始样本来自Reddit、Quora、客户邮件,这些渠道国内要么进不去、要么国人根本不用。保哥帮一个做家居出海的客户搭need research流程时,团队头两周对着Ahrefs和Reddit干瞪眼,挖出来的need全是欧美用户的表达习惯,跟国内供应链能讲的故事对不上。后来重新做了一张国内need来源映射表,流程才跑顺。
| 英文世界need来源 | 国内对应渠道 | 挖need的具体动作 |
|---|---|---|
| Reddit subreddit讨论 | 小红书评论区、知乎问题、什么值得买 | 每周扫细分话题下的高赞提问和吐槽,原话直接抄 |
| Quora问答 | 知乎、百度知道、悟空问答残余 | 看追问链——一个问题下面追问什么,就是query fan-out |
| Amazon Q&A、Review | 淘宝天猫“问大家”、京东问答、拼多多评价 | 导出差评和追评,差评里全是真实使用场景的need |
| People Also Ask | 百度“大家还在搜”“相关搜索”、夸克联想词 | 把核心词丢进百度移动端,截图底部联想簇 |
| AI反向挖need(ChatGPT/Perplexity) | 豆包、Kimi、文心一言、夸克AI | 问国产引擎开放问题,看它展开的子问题 |
第二个本土落差更隐蔽,关乎前面讲的“放弃短词”那一步。英文世界用户的query长度已经涨到9.6词,所以减少对短词搜索量的依赖是对的。但国内的query碎片化进度跟英文世界并不同步:百度移动端、夸克、神马这些主力入口的用户,相当一部分还在敲两三个词的中短query,长自然语言提问的习惯主要在豆包、Kimi这类对话式产品里才养起来。这意味着纯内贸站如果照搬“放弃短词”,会过早丢掉百度还在吃的中短词流量。
保哥给国内团队的口径是分轨:出海线对接Google、ChatGPT,按英文世界的节奏大胆往长query和need内容上压;内贸线对接百度、夸克,短词页面继续保留、稳住基本盘,need-based长内容作为增量去抢豆包元宝的引用位,而不是拿它替换短词页。一刀切照搬英文世界的判断,等于拿别人的时间表改自己的地基。
保哥踩过的坑:把客服工单当need金矿,结果挖出一堆“抱怨者偏差”
前面反复强调“从客服工单挖need”,这话没错,但保哥真在一个客户身上把它用偏过,教训值得单写一段。那是个做户外露营装备的出海DTC,团队很听话地把客服工单当成need的唯一金矿,每月导出工单做语义分析,按高频need排内容选题,连着跑了三个月。
结果选题列表越来越偏:排在最前面的全是“怎么退货”“拉链坏了怎么修”“尺寸偏大怎么换”“防水层失效投诉”这类问题。团队照着写了一批排障和售后内容,自觉很贴近用户真实need。三个月后复盘,AI citation没怎么涨,转化更是纹丝不动。问题出在哪?工单这个样本本身是偏的——会提工单的,绝大多数是已经买了、而且不满意的人。
用人话说,客服工单只覆盖了用户决策旅程里最末端的troubleshooting那一环,前面的awareness(还不知道有这个品类)、research(在几款之间比来比去)、purchase(临门一脚要不要下单)三个阶段的need,工单里几乎一条都没有。而真正带来AI引用和转化的,恰恰是“怎么选一款适合四天徒步的背包”“露营新手第一套装备清单”这类售前决策need——这些人根本不会发工单,他们在下单前就把问题问给了搜索引擎和AI。
后来保哥把need来源做了重新配比,工单只占其中一块,另外补齐三个口子:售前在线咨询的聊天记录(覆盖purchase阶段的犹豫点)、未购买用户的弃单调研问卷(覆盖research阶段的对比顾虑)、小红书和户外论坛里新手的提问(覆盖awareness阶段)。配比调过来之后,内容选题从“售后排障”重新铺满整条决策旅程,两个月后AI引用才真正起势。
这个坑的教训很硬:任何单一need来源都带着它自己的人群偏差,客服工单偏向“已购买且不满意”,UGC平台偏向“爱表达的活跃用户”,访谈偏向“愿意配合的老客户”。need research不是找到一个金矿就埋头挖,而是用多个有偏的样本互相补位,拼出一张覆盖全决策旅程的完整需求地图。
常见问题解答
传统SEO还要做吗keyword research可以完全弃用吗
不要完全弃用。传统SEO(技术SEO + 内容SEO + 外链)的底层信号AI检索系统仍然使用——好的技术SEO是AI检索友好的前置条件。keyword research也仍然有用,只是要换用法:从"找高搜索量短词"改成"找用户真实问题表达"。30天过渡期同时跑两种research、淘汰旧的、保留有用的。
need research的样本量多少才够
看业务规模。中小站每月20-30个真实客户访谈/工单分析够支撑内容选题;大站每月50-100+。质量比数量重要——每个深度访谈拿到的信息量远大于100条keyword tool list。新站没客户时用Reddit/Quora/小红书的UGC样本顶上,每周扫top 50 posts。
长query怎么转成具体内容大纲
每个长query拆成3-5个核心sub-question——这就是大纲。例如"vegan friendly restaurants in NYC for a party of 5 friday night"拆成:哪些素食餐厅在NYC / 哪些能容纳5人 / 哪些周五开 / outdoor seating情况 / 价格预算 / 怎么预订 / 客观点评。每个sub-question一个H2/H3,最后整合一个推荐表格。
AI Overview引用我的站但流量不涨怎么办
这是AI搜索的新常态——citation带来brand awareness但不一定带直接点击。补救方向:(1)brand search追踪——AI Overview曝光后用户记住你站名直接搜brand query;(2)在AI Overview citation的目标页内补充强CTA;(3)被引用的页面后续做内链/订阅引流。短期看流量没涨但中期看brand search指标会涨。
visual elements具体投多少预算
小站每篇深度内容配1张主图(Open Graph image, 1200x630px)+ 站点统一favicon即可。中型站加:每篇含至少1张数据可视化图(自己做的图表)+ 视频版本(5-15分钟YouTube)。预算分配建议:visual content占总内容预算的20%-30%,2024年这个数字通常只有5%-10%——要往上调。
客服工单分析具体怎么做
工具:客服系统(Zendesk/Intercom/Freshdesk)导出工单CSV → 用GPT-4 API批量做语义分类(情感+问题类型+具体need)→ 输出按月聚合的need分布表 + top 50高频need清单。脚本约200行Python,跑一次月度报告耗时2-4小时。比手动分类高效10倍以上。
问题型关键词怎么系统挖掘
三个路径:(1)Ahrefs/Semrush的Questions filter拉出"how/why/what/when/which"开头的关键词;(2)AlsoAsked/AnswerThePublic画出问题树状图;(3)直接在ChatGPT/Perplexity/Gemini里问"用户在搜XX主题时常问的10个相关问题是什么"——AI给的答案就是当前query fan-out的预览。
不同AI引擎对need-based内容的偏好一样吗
不完全一样。ChatGPT browsing偏好结构化清晰、含明确步骤的内容;Perplexity偏好具体数据和案例;Gemini偏好与Google SERP一致的内容(已经在传统SEO上排名好的);Claude偏好深度分析叙事型。每篇深度内容覆盖4种风格的特征(结构化+数据+SEO基础+叙事)效果最好。
权威参考资料
本文标题:《AI搜索时代关键词研究过时了吗?六步转向需求研究》
本文链接:https://zhangwenbao.com/keyword-fragmentation-need-research-ai-search.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0