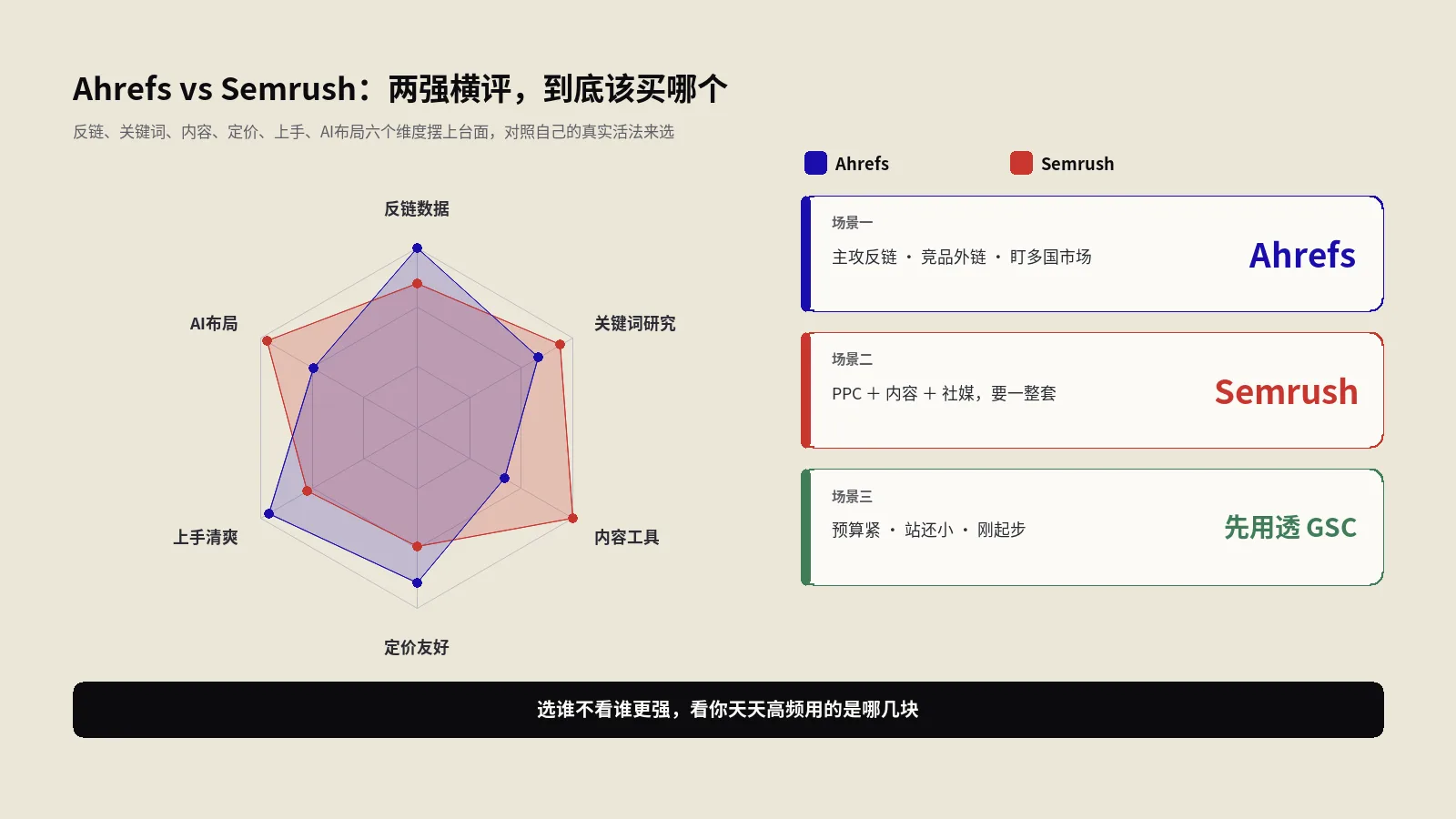
抓取体积检查器怎么用?Googlebot 2MB抓取上限实测全拆解

本文目录
- Googlebot抓你的页面,居然有个体积上限?
- 这个抓取体积检查器到底做什么?
- 2MB这个限制是真的,而且刚刚收紧
- 为什么大部分页面根本碰不到这条线?
- 它把页面体积拆成哪几块?
- 为什么外部资源不算进这2MB?
- 超过2MB会发生什么?
- 哪些内容最容易被2MB截断掉?
- 内联CSS和JS的警告阈值是哪来的?
- 怎么用它给一个页面做体积体检?
- PDF为什么是64MB这个完全不同的数?
- 哪些数字是官方的,哪些是工具的经验值?
- 这个工具的能力边界在哪?
- 服务端渲染的页面为什么是2MB超标的重灾区?
- 实战案例:骑行装备出海站的SSR臃肿页面
- 抓取体积只是抓取三件套的最后一关
- 常见问题解答
- Googlebot的抓取体积上限到底是2MB还是15MB?
- 页面超过2MB,Google会不收录这一页吗?
- 给HTML文档减重,最有效的一招是什么?
- JSON-LD结构化数据放在页面哪里比较安全?
- 这个工具能测页面的加载速度和Core Web Vitals吗?
- 权威参考资料
摘要:很多人不知道Googlebot抓一个页面是有体积上限的——超过这个数,后面的内容它直接不要了,正文、结构化数据、页脚链接都可能在截断点之后凭空消失。而这个上限在2026年刚从15MB大幅收紧到2MB,比以前相关得多。这篇用一个抓取体积检查器当线索,把它测量HTML文档体积的方式、把页面拆成HTML与内联CSS与内联JS与注释与JSON-LD五块的逻辑、为什么外部资源不算进这2MB(这是最大的优化杠杆),还有2MB与64MB这些数字的官方依据,全都拆开,讲清怎么用它在内容被悄悄截断之前就发现问题。
聊页面体积,大家第一反应都是“加载速度”“Core Web Vitals”。但有一件事容易被忽略:Googlebot抓取你的页面时,并不是把整个HTML文档无限量地读下来,它有一个明确的字节上限,读到那个点就停。超出的部分,等于对Google不存在——它没读到,自然也不会索引。
更要命的是,这个上限在2026年发生了一次大调整,从沿用多年的15MB一下收紧到了2MB。这意味着以前觉得“我页面才几百KB,离15MB远着呢”的安全感,现在得重新算账了。我们团队常用的一个抓取体积检查器,能把一个页面的HTML文档体积量出来,告诉你过没过这条2MB的线,还把体积拆成几块让你看清谁在占地方。这篇就用它当解剖刀,把抓取体积这件容易被忽略的事讲清楚。
Googlebot抓你的页面,居然有个体积上限?
是的,而且这是Google官方明确的机制,不是传说。Googlebot抓取一个URL时,只会下载这个资源的前一段字节,到达上限就停止下载——注意,它不是拒绝整个页面,而是“截断”,把已经下载的那部分当成完整文件交给后续的索引和渲染系统去处理。
这个机制的后果很直接:如果你页面真正重要的内容排在字节上限之后,Google根本读不到它。你以为整页都提交给Google了,实际上可能只有前面一截被读取、被索引,后面的部分石沉大海。而且这个截断是悄无声息的——页面在浏览器里显示得好好的,你不会有任何报错提示,只有用工具去量、或者发现某些内容死活不被收录时,才会意识到撞了这条线。
这个抓取体积检查器到底做什么?
它的用法很简单:你给它一个URL(它去抓取这个页面,自动跟随重定向),或者直接粘贴HTML源码。它算完,告诉你这个页面的HTML文档总共多大、过没过2MB这条线(通过显示绿色、超标显示红色,还告诉你超出了多少),然后把体积拆成几块画出来,再根据各块的占用给你优化建议。
有个技术细节值得一提:它抓取时会主动告诉服务器“别压缩,给我未压缩的原始内容”(用Accept-Encoding: identity这个请求头)。这是因为Googlebot的2MB上限算的是未压缩的字节数,所以工具要量的也得是未压缩体积,跟Google的口径对齐,量出来的数才有参考意义。
它的定位是“体积读数加成分拆解”。它精准地告诉你页面多重、重在哪里,但怎么减重是你的活。理解这个定位,后面讲它的能力边界时会更清楚。
2MB这个限制是真的,而且刚刚收紧
先把这个核心数字的来历讲清楚,因为它直接关系到这个工具值不值得用。Googlebot对HTML文档的抓取上限,历史上长期是15MB——这个数字Google在2022年公开过。但根据Google搜索中心2026年3月关于Googlebot抓取机制的官方博客,这个上限被下调到了2MB,而且这2MB包含了HTTP响应头在内。
从15MB到2MB,是个数量级的收紧。以前15MB这条线,普通页面基本不可能碰到,所以大家都不当回事;现在2MB,对于那些塞了大量内联脚本、把整个页面数据都注入进HTML的现代站点(尤其是服务端渲染的电商和资讯站),就突然变得真实可触了。这也是为什么这个检查器在2026年比以前任何时候都更值得用——以前是杞人忧天,现在是真有不少页面在悄悄撞线。工具把2MB这条线设成判定标准,量出来直接告诉你过没过,省得你自己换算。
为什么大部分页面根本碰不到这条线?
话说回来,也别一听2MB就恐慌,以为自己的页面都危险了。事实是,绝大多数页面离2MB还很远。Google在同一篇官方说明里提到,一个HTML文件的体积中位数大约只有30KB——也就是说,典型页面比2MB这个上限小了大约500倍。
这个对比很重要,它告诉你:抓取体积不是一个该天天焦虑的指标,而是一个该针对特定页面去排查的指标。普通的文章页、产品页,HTML文档几十到几百KB,离2MB远得很,根本不用操心。真正可能撞线的是少数“特殊体质”的页面:把成百上千条数据一次性渲染进HTML的大列表页、塞了巨量内联脚本和样式的页面、或者把整个应用状态都注入到HTML里的服务端渲染页。用工具的姿势应该是:日常不用查,但对那些“感觉特别重、或者死活有内容不被收录”的页面,单独拎出来量一下。
它把页面体积拆成哪几块?
光知道“这页2.3MB超标了”还不够,你得知道这2.3MB是被什么撑起来的,才知道从哪减。这正是工具最实用的功能——它把HTML文档的总体积拆成五块。
第一块是纯HTML内容(标签和文本本身)。第二块是内联CSS,也就是写在style标签里的样式(不含外部CSS文件)。第三块是内联JavaScript,写在script标签里的脚本(不含外部JS文件)。第四块是HTML注释,那些写在注释标记里的内容。第五块是JSON-LD结构化数据,也就是那段用于标记的脚本。
它通过正则去匹配提取这几块各自的字节数,再画成一个横向的堆叠条形图,每块一个颜色,配上各自的字节数和百分比。这么一拆,超标的元凶通常一目了然——大多数超标页面,问题都出在内联CSS或内联JS某一块异常臃肿上,把它揪出来,减重就有了明确目标。
为什么外部资源不算进这2MB?
这是整篇里最关键的一个认知,也是最大的优化杠杆。Googlebot的2MB上限,算的只是HTML文档本身的字节——那些通过link标签引入的外部CSS文件、通过script的src引入的外部JS文件、通过img引入的图片,全都不算在这2MB里面。
根据Google关于抓取体积限制的官方博客,这个限制只针对HTML文档主体,页面引用的图片、CSS、JS等外部资源是被单独请求、单独抓取的,不计入HTML的体积上限。这条规则直接决定了减重的方向。
它的意义在于:同样是100KB的CSS,你写成内联的style标签,它就实打实占掉HTML文档里的100KB、计入2MB;但你把它挪到一个外部的.css文件、用link引入,它对HTML文档体积的贡献就是零。所以把内联的CSS和JS挪到外部文件,是给HTML文档减重最立竿见影的一招——内容一个字没删,纯靠搬家就把体积降下来了。这也是为什么工具要专门把内联CSS、内联JS单独拆出来量:它们是最容易膨胀、又最容易通过外置来解决的两块。
超过2MB会发生什么?
得把超标的后果说准确,避免误解。超过2MB,Google不会拒绝或惩罚你的页面——它不会因为你超标就不收录这一页。它做的是“截断”:在2MB那个字节位置把页面切断,只拿前面这2MB的内容去做索引和渲染,后面的部分丢弃。
所以超标的真正危害不是“页面被拒”,而是“内容被悄悄吞掉”。你页面的前2MB照常被处理,但凡是排在2MB之后的东西——可能是正文的后半段、可能是页脚的导航链接、可能是放在底部的JSON-LD结构化数据——对Google来说就像不存在。这种损失是隐蔽的:页面还在、还能被收录,只是它“缺了一块”,而你很难察觉到底缺了哪块。工具的价值,就是在这种隐蔽损失发生前,先帮你把体积量出来、把超标的部分标红预警。
哪些内容最容易被2MB截断掉?
顺着上面的逻辑,得具体说说哪些东西最怕被截断,因为它们的损失最伤。第一是正文内容。如果你页面头部塞了大量内联CSS和JS,把字节预算占掉一大半,真正的正文又排在后面,那正文很可能有一部分落在2MB之外没被读到,直接影响这页的内容相关性和排名。
第二是JSON-LD结构化数据。很多人习惯把结构化数据的脚本放在页面底部(body快结束的地方),一旦页面超标,这段标记就被截掉了,富结果、知识面板这些依赖结构化数据的功能全部失效。所以最佳实践是把JSON-LD放在head里、靠前的位置,确保它在2MB预算的前面被优先读到。
第三是页脚的内链。页脚通常有大量导航链接,搜索引擎靠它们发现站内其他页面,如果页脚落在截断点之外,这些链接就没被发现,影响站内的链接权重传递和新页发现。这三类内容都有一个共同点:它们往往排在页面靠后的位置,正好是截断最先牺牲的区域。
内联CSS和JS的警告阈值是哪来的?
工具除了判定整体过没过2MB,还会在某一块内联资源过大时单独给警告:内联CSS超过100KB、内联JS超过100KB、HTML注释超过10KB,它都会提示你该处理了。这几个数字得说清楚来历——它们不是Google的官方规定,而是工具基于SEO最佳实践设定的工程化经验值。
这跟2MB那个数字的性质完全不同。2MB是Google官方的硬性截断线,过了就真的被截;而这100KB、10KB是工具自己设的“该优化了”的提醒线,过了不会有什么硬性后果,只是说明这块内联资源胖到了值得你把它挪去外部文件的程度。所以读这两类提示要分清:整体超2MB的红色是“真出事了,必须处理”,单块内联超100KB的提醒是“有优化空间,建议处理”。前者是底线,后者是建议。
怎么用它给一个页面做体积体检?
把工具用出价值,靠一套固定动作。我们团队怀疑某个页面有抓取体积问题时,标准的排查流程是这样的。
- 先锁定可疑页面。不用全站都查,挑那些“感觉特别重”或者“死活有内容不被收录”的页面——大列表页、服务端渲染的复杂页、塞了大量数据的页,这些是最可能撞线的。
- 把URL或HTML贴进检查器,看整体判定。第一眼看过没过2MB:绿色就基本放心,红色就重点处理,记下超出了多少。
- 看成分拆解图,揪出元凶。看那五块里哪块占地方最大,超标页面通常是内联CSS或内联JS某一块异常臃肿,锁定它就锁定了减重目标。
- 优先把内联CSS和JS挪到外部文件。这是最立竿见影的一招——内容不动,把内联样式和脚本搬到外部.css、.js文件用link和src引入,它们就不再计入这2MB。
- 检查JSON-LD的位置。确认结构化数据放在head靠前,而不是页面底部,避免它在超标时被截断导致富结果失效。
- 清理冗余。移除生产环境用不着的HTML注释、精简服务端注入的数据(只注入首屏必需的,其余异步加载)、把超长列表分页,改完再量一次确认降到了安全线下。
这套流程的核心是“先定位重页、再拆解减重”。检查器负责把体积和成分准确量出来,你负责按“内联外置、JSON-LD前置、冗余清理”这几招去减——而其中外置内联资源往往一招就能解决大部分超标问题。
PDF为什么是64MB这个完全不同的数?
工具除了HTML的2MB,还处理另一种情况:如果你抓取的是PDF文件,它用的上限是64MB,而不是2MB。这俩数字差这么多,是因为Google对不同类型的文件确实设了不同的抓取上限。
这对那些靠PDF做内容的站有意义——比如发布产品手册、技术白皮书、研究报告的站,这些PDF往往体积不小,但只要在64MB以内,Google就能完整抓取。根据Google关于Googlebot的官方文档,Googlebot会按文件类型采取不同的抓取行为,HTML和PDF这类文档各有各的处理方式和上限。工具能自动识别你抓的是HTML还是PDF,套用对应的上限来判定,不会拿2MB去误判一个本该按64MB算的PDF。知道这个区别,你在用工具量PDF资源时就不会被那个小得多的HTML上限吓到。
哪些数字是官方的,哪些是工具的经验值?
用这个工具,得拎清两类数字。有官方依据、可以当硬指标的:HTML文档2MB抓取上限(Google官方,2026年从15MB下调而来)、PDF的64MB上限(Google官方)、外部资源(图片/CSS/JS)单独抓取不计入HTML体积(Google官方)、HTML文件中位数约30KB(Google官方提到的数据)。这些是确凿的事实,可以放心依据。
属于工具工程化设定的:内联CSS超100KB、内联JS超100KB、HTML注释超10KB这几个警告阈值(是工具基于最佳实践设的提醒线,不是Google规定);以及它把页面拆成那五块的具体划分方式。所以用工具的正确姿势是:把“过没过2MB”当成铁的底线(过了内容真会被截),把那几个内联资源的警告当成有用的优化建议(过了是该优化的信号,但不是硬性出事)。两者都有用,但分量不同。
这个工具的能力边界在哪?
用好它,得清楚它做不到什么。它测的是HTML文档的字节体积,专注于“过没过Googlebot的抓取上限”这一件事,所以它不是一个综合的性能工具。它不测页面的加载速度、不测Core Web Vitals那几个体验指标、不分析渲染性能、不告诉你图片该怎么压缩——这些是性能优化工具的活,跟抓取体积是两码事。
它也只算内联的代码,外部资源它只是不计入、但也不会去逐个请求测量那些外部文件多大。还有,它做的是“绝对上限检测”(过没过2MB这条硬线),不做“相对优化程度”的精细打分——它不会给你的页面体积打个0到100的健康分,就是简单的通过或超标。把这些边界记清楚,它就是个很专一的工具:精准回答“这个HTML文档会不会被Googlebot截断”,至于页面快不快、体验好不好,得另找性能工具。
服务端渲染的页面为什么是2MB超标的重灾区?
前面反复提到服务端渲染的页面最容易撞2MB线,这里值得专门说清原因,因为现代站点用这类框架的越来越多。服务端渲染(SSR)为了让页面首屏不白屏、也为了对搜索引擎友好,会在服务器上先把页面内容生成好、连同数据一起塞进HTML直接返回。这本是好事,但它埋了个体积的雷。
雷就在“连同数据一起塞进HTML”这句上。很多框架为了让前端交互时不用再请求一遍数据,会把渲染这个页面用到的全部数据——甚至包括很多首屏根本用不到的字段——序列化成一大段JSON,作为内联脚本注入到HTML里。一个聚合了几百条商品的列表页,这段内联数据动辄上MB,单这一块就能把2MB预算吃光。结果就是页面在浏览器里跑得好好的,HTML源码却早已超标,底部的真实内容被Google截断在外。
所以SSR站点是这个检查器最该常驻的客户。它们的页面有两副面孔:浏览器里看一切正常,HTML源码里却塞满了用户看不见的内联数据。不主动去量,你根本不知道这些页正在被悄悄截断。识别出问题后,解法也清晰——只注入首屏必需的数据,其余的改成异步加载,就能把HTML体积压回安全区。
实战案例:骑行装备出海站的SSR臃肿页面
我们团队去年帮一个做骑行装备的出海站排查收录问题,这站卖公路车、山地车配件、骑行服、码表这些,用的是服务端渲染的现代框架。客户的困惑很具体:几个主力分类页(比如“公路车配件”这种聚合了大量产品的页)明明内容丰富,但页面底部的一些产品和介绍文字,在Google搜索里死活搜不到,像是没被收录。
我们怀疑是抓取体积的问题,把这几个分类页贴进检查器一量,果然——这些页的HTML文档普遍在3MB上下,全都超过了2MB的线,标红。看成分拆解图,元凶很清楚:内联JavaScript那一块占了惊人的比例,接近2MB。一查源码,是框架在服务端渲染时,把整个页面所有产品的完整数据(包括很多首屏根本用不到的字段)一股脑序列化成一大段内联脚本注入进了HTML,把字节预算撑爆了。结果就是页面底部的产品列表和介绍文字,正好落在2MB截断点之外,Google压根没读到,自然搜不到。
按流程,我们给客户的处理是两条:一是精简服务端注入的数据,只在HTML里注入首屏渲染必需的那部分,其余产品数据改成滚动时异步加载;二是把一部分本可外置的内联脚本挪到外部JS文件。改完这几个分类页的HTML文档从3MB降到了几百KB,远在2MB安全线下。一段时间后,之前搜不到的底部产品和文字陆续被收录了。这个案例的要点是:检查器帮我们把“内容为什么凭空消失”这个谜团,定位到了“HTML超2MB被截断”这个具体原因上,但怎么改框架的渲染逻辑,是开发的活。
抓取体积只是抓取三件套的最后一关
抓取体积这件事,放在“网站可抓取性”的大图景里,是最后一关。一个页面要被搜索引擎完整地抓取收录,得连过三关,对应三类诊断。
第一关是抓取入口:你递给搜索引擎的sitemap清单干不干净,决定抓取资源投向哪里,这能用我们拆过的sitemap提取器的方法去摸底。第二关是抓取身份:搞清楚到底是谁在抓你的站、真假Googlebot怎么分、AI爬虫该放该拦,这能用爬虫识别器的方法。第三关就是这篇讲的抓取落地——搜索引擎来抓了,但你的页面别太重,别超过2MB把内容截断在外。前两关解决“来不来抓、抓不抓得对”,这第三关解决“抓了能不能完整读下来”,三件套合起来,才算把一个站从入口到落地的抓取健康度查了个遍。
常见问题解答
Googlebot的抓取体积上限到底是2MB还是15MB?
现在是2MB。这个上限历史上长期是15MB(Google在2022年公开过),但根据Google搜索中心2026年的官方说明,已经下调到2MB,且这2MB包含HTTP响应头在内。从15MB到2MB是数量级的收紧,以前普通页面碰不到,现在那些塞满内联脚本的服务端渲染页就真有可能撞线了。这也是这个工具现在比以前更值得用的原因。注意PDF文件用的是另一个上限64MB。
页面超过2MB,Google会不收录这一页吗?
不会不收录,但会截断。Google不会因为超标就拒绝或惩罚整个页面,它做的是在2MB那个字节位置把页面切断,只拿前面这2MB去做索引和渲染,后面的部分丢弃。所以危害不是页面被拒,而是排在2MB之后的内容(正文后段、页脚链接、底部的JSON-LD)被悄悄吞掉,对Google就像不存在。页面照常被收录,只是缺了一块,而且这种损失很隐蔽,不量根本发现不了。
给HTML文档减重,最有效的一招是什么?
把内联的CSS和JavaScript挪到外部文件。因为2MB上限只算HTML文档本身的字节,外部的.css、.js文件、图片都不计入。同样100KB的样式,写成内联style标签就占掉HTML里的100KB、计入2MB,挪到外部用link引入就对HTML体积贡献为零。所以内联资源外置是减重最立竿见影的招——内容一个字不删,纯靠搬家就把体积降下来。工具专门把内联CSS、JS拆出来量,就是因为它们最容易膨胀又最容易靠外置解决。
JSON-LD结构化数据放在页面哪里比较安全?
放在head里、靠前的位置。很多人习惯把JSON-LD脚本放在页面底部,一旦页面超过2MB被截断,这段标记就落在截断点之外、被丢弃了,富结果和知识面板这些依赖结构化数据的功能全部失效。放在head靠前,能确保它在2MB字节预算的前面被优先读到,即便页面整体偏大也不容易被截掉。这是个低成本的保险动作。
这个工具能测页面的加载速度和Core Web Vitals吗?
不能,它只测HTML文档的抓取体积。它专注回答“这个HTML文档会不会超过Googlebot的2MB上限被截断”这一件事,不测加载速度、不测Core Web Vitals、不分析渲染性能、不评图片压缩。抓取体积和加载性能是两码事——一个关乎Google能不能完整读到你的内容,一个关乎用户和体验指标。要测速度和体验,得另找专门的性能工具,这个检查器只管抓取体积这一关。
权威参考资料
本文标题:《抓取体积检查器怎么用?Googlebot 2MB抓取上限实测全拆解》
本文链接:https://zhangwenbao.com/crawl-size-checker-2mb-googlebot-fetch-limit-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0