爬虫识别器怎么用?120种UA分类与真假Googlebot验证全拆解
本文目录
- 谁在抓你的站,你真的清楚吗?
- 这个爬虫识别器到底做什么?
- 它内置的爬虫库里到底有多少种?
- 搜索引擎爬虫这一类都有谁?
- AI爬虫这一类为什么最值得单独拎出来?
- Google-Extended和Googlebot是一回事吗?
- SEO工具爬虫该不该放进来?
- 社交媒体爬虫拦了会怎样?
- 它靠什么识别一个爬虫——正则还是别的?
- 光看User-Agent能不能信?
- 真假Googlebot到底怎么验?
- 工具给每个爬虫标的“SEO友好度”是什么意思?
- “建议屏蔽”的三档怎么理解?
- 它能一键生成robots.txt屏蔽规则吗?
- 拦AI爬虫到底会不会影响搜索排名?
- 从access日志里能识别出爬虫占比吗?
- 怎么用它做一次爬虫流量盘点?
- 哪些数字和事实是官方的,哪些是工具的判断?
- 这个工具的能力边界在哪?
- 实战案例:茶叶茶具出海站的爬虫流量体检
- 识别爬虫只是第一步,下一步管什么?
- 常见问题解答
- 这个识别器能验证一个Googlebot是真是假吗?
- 拦掉GPTBot、ClaudeBot这些AI爬虫,会影响我的Google排名吗?
- Google-Extended和Googlebot有什么区别,能分开拦吗?
- 它靠正则表达式匹配UA吗,准不准?
- 我拦了机器人后,链接分享到社交平台没预览图了,怎么回事?
- 权威参考资料
摘要:你的服务器日志里趴着一堆机器人——有来收录你、给你带流量的,有来扒内容拿去训练大模型的,还有伪装成Googlebot的假货。分不清谁是谁,就谈不上该放谁、拦谁。这篇用一个爬虫识别器当线索,把它内置的120多种爬虫库、9大分类、靠User-Agent子串匹配的识别逻辑、一键生成robots.txt屏蔽规则的方式,还有真假Googlebot到底该怎么验证(以及这个工具做到了哪一步、没做哪一步),全都拆开,讲清怎么用它把爬虫流量盘清楚,又不被一串可伪造的UA字符串骗了。
每个网站背后都有一群你看不见的访客:爬虫。打开服务器日志,人类访问之外,是密密麻麻的各种机器人——Googlebot、Bingbot来给你做收录,GPTBot、ClaudeBot来扒内容喂大模型,AhrefsBot、SemrushBot来做SEO分析,还有一堆叫不上名字的脚本和采集器。它们消耗你的服务器资源、影响你的抓取预算,有的还把你的内容拿去做了别的用途。
问题是,这些爬虫的身份全藏在一串叫User-Agent的字符串里,又长又乱,肉眼根本分不清谁是该欢迎的、谁是该提防的。我们团队常用的一个爬虫识别器,能把你粘进去的UA字符串或一段日志解析开,告诉你这是哪家的什么爬虫、属于哪一类、对SEO是友好还是不友好、建不建议屏蔽,还能直接帮你生成一份robots.txt屏蔽规则。这篇就用它当解剖刀,把爬虫识别这件事讲透。
谁在抓你的站,你真的清楚吗?
大多数站长对自己站点的爬虫流量是糊涂的。他们知道有Googlebot,但说不清除了它还有几十种机器人天天来访;知道AI爬虫这个词,但分不清GPTBot和ChatGPT-User有什么区别、Google-Extended和正经的Googlebot是不是一回事。
这种糊涂是有代价的。该放行的搜索引擎爬虫,你可能因为一刀切的WAF规则误拦了,结果收录掉了;该考虑拦的AI训练爬虫,你可能压根不知道它来过,内容被悄悄扒走训练;冒充Googlebot的恶意采集,你当成真Googlebot放行了,反而被薅了羊毛。想做对这些决策,前提是先把“谁在抓我”这件事搞清楚——爬虫识别器就是干这个的第一道工序。
这个爬虫识别器到底做什么?
它的用法很灵活:你可以粘一个完整的User-Agent字符串、粘多行UA列表、甚至直接粘一段服务器访问日志(它会自己从里头提取UA),也支持上传txt或log文件。它解析完,给你几样东西。
核心是一张识别结果卡片:每识别出一个爬虫,列出它的名称、所属公司、分类、用途说明、对SEO的友好度、是否建议屏蔽、以及一个官方文档链接。然后是一组统计:这次一共识别出几个爬虫、其中搜索引擎几个、AI爬虫几个、SEO友好的几个、不友好的几个。最后,它还能根据识别结果,自动生成一段robots.txt屏蔽规则,把那些它判断该拦的爬虫写成Disallow条目,你复制就能用。
它的定位是“身份识别加屏蔽建议”。它帮你把一串看不懂的UA翻译成“这是谁、该不该理它”,但要不要真的照它的建议屏蔽,是你的决定。后面会讲它判断的依据,以及哪些该信、哪些得自己拿主意。
它内置的爬虫库里到底有多少种?
这个工具的家底是一个内置的爬虫数据库,收了120多种爬虫。每一条记录都带着完整的信息结构:UA匹配模式、显示名称、所属公司、分类类型、用途描述、SEO友好度、屏蔽建议、官方文档链接。这是它能给出有据可查的识别结果的基础。
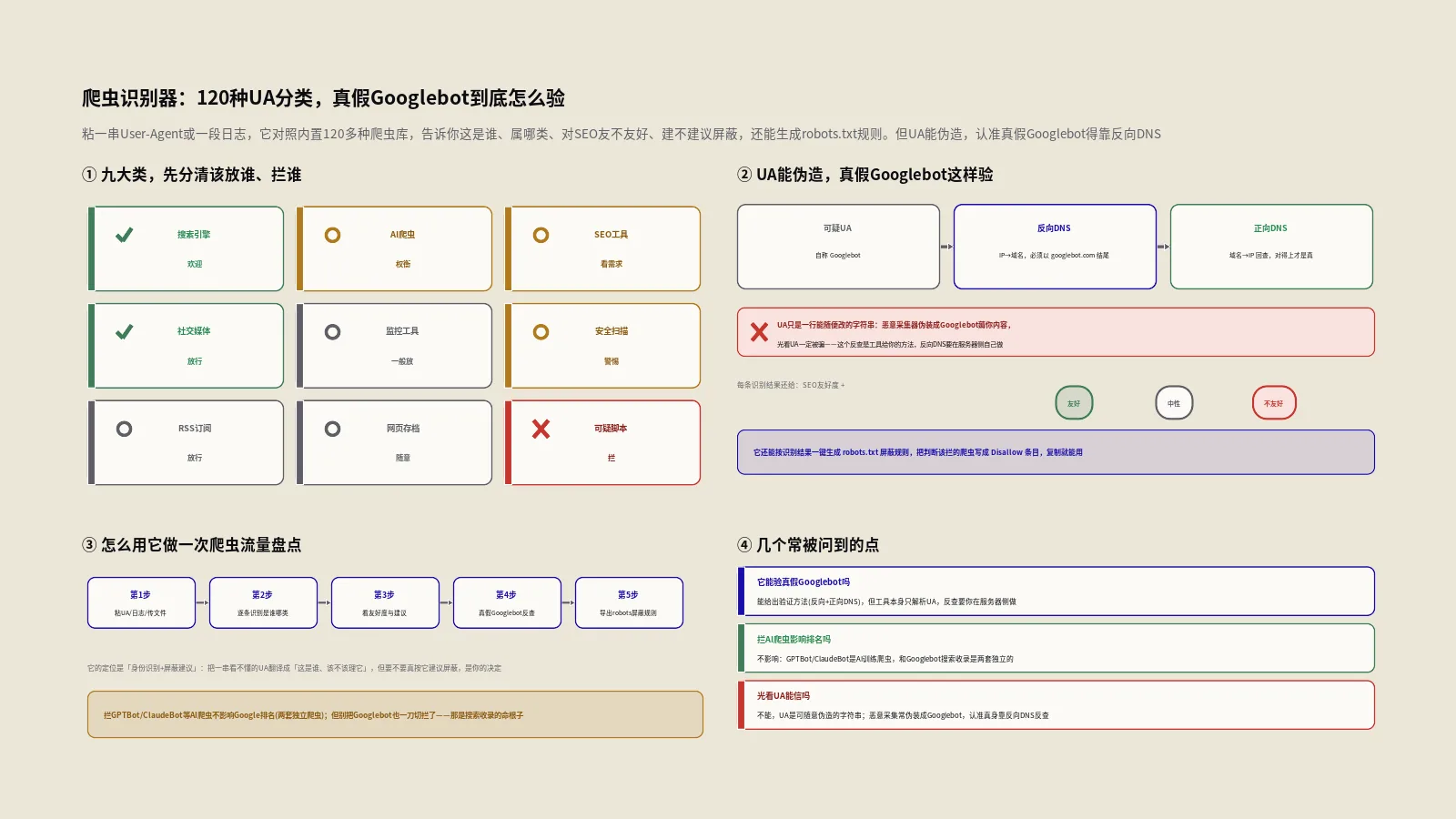
这120多种被归成9大类:搜索引擎爬虫、AI爬虫、SEO工具爬虫、社交媒体爬虫、监控工具、安全扫描、RSS订阅、网页存档、通用工具脚本。这个分类不是随便分的,它直接对应“这个爬虫来干嘛、我该怎么对它”——搜索引擎爬虫你欢迎还来不及,AI训练爬虫你得权衡,恶意采集脚本你直接拦。下面挑几个最关键的类别细说。
搜索引擎爬虫这一类都有谁?
这是你最该认全、也最不该误伤的一类。光Google一家就有一大串:主爬虫Googlebot之外,还有Googlebot-Image、Googlebot-Video、Googlebot-News、Googlebot-Mobile这些按内容类型分工的子爬虫。
除此之外还有一堆功能性的子爬虫——Google-InspectionTool(你在搜索控制台点“测试实际URL”时来的)、AdsBot-Google(检查广告落地页质量)、Mediapartners-Google(AdSense)、Storebot-Google(购物)等等,它们都是Google官方的正经爬虫。
除了Google,还有微软的bingbot、BingPreview,百度的Baiduspider系列,以及Yandex、Sogou、DuckDuckBot、Applebot等国际搜索引擎。工具给这一类几乎都标了“SEO友好”、屏蔽建议“不要屏蔽”。道理很简单:这些是给你做收录、带自然流量的爬虫,拦了它们等于自断搜索流量。
识别器在这一类上的价值,是帮你认清这些功能各异的Google子爬虫——很多人看到Google-InspectionTool、Storebot-Google这种不常见的UA会慌,以为是假货,其实都是Google官方的正经爬虫,该放行的别误拦。
AI爬虫这一类为什么最值得单独拎出来?
AI爬虫是这几年冒出来、也是最该搞清楚的一类,工具收了20多种。它们又能分成两拨:一拨是来扒内容做大模型训练的,比如OpenAI的GPTBot、Anthropic的ClaudeBot、Common Crawl的CCBot(很多大模型的训练数据来自它)、还有Google-Extended;另一拨是给AI产品做实时检索的,比如用户在ChatGPT里点开链接时来的ChatGPT-User、OpenAI的搜索爬虫OAI-SearchBot、Perplexity的爬虫。
这里有个细节值得留意:同一家公司的爬虫也不是铁板一块。根据OpenAI的爬虫与User-Agent官方文档,光OpenAI一家就有GPTBot、ChatGPT-User、OAI-SearchBot三种用途不同的爬虫,各有各的UA和robots.txt控制方式,把它们当成一个东西就会做出错误的放拦决策——比如你想拦训练、却连实时检索也一起拦了,白白丢掉AI回答里的曝光机会。
这两拨的SEO含义完全不同,工具也区别对待。训练类爬虫(GPTBot、ClaudeBot、CCBot)多被标为“SEO不友好”、屏蔽建议“可选”——它们扒走你内容用于训练,但对你的搜索排名没有直接帮助,拦不拦看你愿不愿意让内容被拿去训练。检索类爬虫(ChatGPT-User、OAI-SearchBot)则偏中性——它们关系到你的内容能不能在AI回答里被引用、带来AI时代的新流量,拦了可能丢掉这部分曝光。能把“训练”和“检索”这两拨AI爬虫分清楚,是这个工具特别实用的地方。
Google-Extended和Googlebot是一回事吗?
这是个特别容易搞混、也特别重要的点,值得单独说。Google-Extended不是一个真正会来抓取页面的爬虫,它是Google给你的一个“开关”:用来控制你的内容要不要被用于训练Gemini等Google的AI模型。它和负责搜索收录的Googlebot是两套独立的东西。
这个设计的意义在于:你可以在robots.txt里单独屏蔽Google-Extended、拒绝内容被拿去训练AI,同时完全不影响Googlebot继续来收录你、不影响你的搜索排名。很多人不知道这俩能分开控制,要么因为怕影响排名而不敢拦AI训练,要么一拦就把Googlebot也连带拦了导致收录出问题。识别器把Google-Extended单独列出来、标清它的用途,就是帮你避开这个最常见的误区——拦AI训练和保搜索收录,是可以兼得的。
SEO工具爬虫该不该放进来?
第三类是SEO工具的爬虫,工具收了20多种:Ahrefs的AhrefsBot、Semrush的SemrushBot、Moz的DotBot、Majestic的MJ12bot,以及各种SEO平台和审计工具的爬虫。它们来你站上爬,是为了给它们的用户(包括你的竞品)提供外链分析、关键词排名、站点审计这些数据。
工具给这一类大多标“中性”、屏蔽建议“可选”。逻辑是:拦不拦它们都不影响你自己的搜索排名(它们不是搜索引擎),但有个微妙的权衡——你拦了它们,你自己用Ahrefs、Semrush分析自己站点时数据会不全;可你不拦,你的竞品也能用这些工具把你的外链、关键词扒得一清二楚。所以这一类是典型的“看需求决定”:你重视竞品情报保密就拦,你自己重度依赖这些工具分析就放。识别器帮你把它们认出来、点明这个权衡,决定权留给你。
社交媒体爬虫拦了会怎样?
第四类是社交媒体爬虫,比如facebookexternalhit、Twitterbot、LinkedInBot、Pinterest、Slackbot、Discordbot等等。它们的用途很专一:当你的链接被分享到对应平台时,它们来抓取页面的Open Graph标签,生成那张分享预览卡片。
工具给这一类标“SEO友好”、屏蔽建议“不要屏蔽”,而且这个“不要屏蔽”比搜索引擎那个还硬。因为一旦你拦了facebookexternalhit,你的链接被分享到Facebook时就抓不到OG标签,卡片直接变成一片空白的丑陋链接,社交流量全废。很多站长在配WAF规则狂拦机器人时,会顺手把社交爬虫也拦了,结果纳闷为什么自己的链接分享出去没有预览图。识别器把这一类明确标成“绝对别拦”,就是帮你避开这种自伤社交流量的低级错误。
它靠什么识别一个爬虫——正则还是别的?
这里得讲清楚它的识别原理,因为这直接关系到它的可靠性边界。它的识别逻辑出乎意料地简单:不用复杂的正则表达式,而是拿数据库里每个爬虫的UA匹配模式(比如Googlebot这个词),去你输入的文本里做不区分大小写的子串匹配——只要你的UA里包含这个词,就判定为这个爬虫,并统计出现了几次。
这种子串匹配的好处是快、简单、覆盖广,对99%的真实场景够用了——绝大多数正经爬虫的UA里就是老老实实写着自己的名字。但它的软肋也正在这里:它只看UA字符串里有没有那个词,至于这个UA是真的还是伪造的,它判断不了。这就引出了一个关键问题:光看UA到底能不能信。
光看User-Agent能不能信?
答案是:不能完全信,因为User-Agent是可以任意伪造的。UA只是HTTP请求头里的一个字段,任何人写个脚本,都能把自己的UA设成“Googlebot”“ClaudeBot”或任何想冒充的名字。所以一个UA里写着Googlebot的请求,可能是真Googlebot,也可能是个伪装成Googlebot来抓你内容、绕过你防护的采集器。
这是所有基于UA识别的工具(包括这个识别器)的共同天花板:它能告诉你“这个UA自称是Googlebot”,但不能告诉你“它真的是Googlebot”。对于善意的、正经的爬虫,UA识别完全够用——它们没必要伪装。但对于你想严防死守的场景(比如有人冒充Googlebot来薅你的高价值内容),光靠UA就不够了,得上更硬的验证手段。
真假Googlebot到底怎么验?
验证真假Googlebot有一套官方推荐的硬方法,叫正向确认的反向DNS(FCrDNS)。它分两步,缺一不可。根据Google验证Googlebot的官方文档,第一步是拿访问你的那个IP做反向DNS查询(查PTR记录),看它解析出来的主机名是不是以googlebot.com或google.com结尾;第二步是把这个解析出来的主机名再做一次正向DNS查询,看它是不是又解析回了原来那个IP。两次都对上,才能确认这是真Googlebot。
为什么要两步?因为单做反向DNS能被伪造——攻击者可以把自己IP的反向解析设成一个假的googlebot.com名字;但第二步的正向解析必须解析回同一个IP,攻击者控制不了Google的正向DNS记录,所以伪造不了。Google正是因为这个原因推荐用DNS验证、而不是维护一个公开IP清单(不过后来Google也额外公开了爬虫的IP段,让你能直接比对IP)。
关键来了:这个爬虫识别器做到了哪一步?它只做UA字符串匹配,不做反向DNS、不做IP段比对。也就是说,它能帮你快速认出“这串UA对应哪个爬虫”,但它验证不了真假Googlebot——那需要在你服务器上对IP做DNS查询,不是一个解析UA文本的网页工具能完成的。用它的时候得心里有数:它是身份识别工具,不是真伪验证工具,真要防伪造,得在服务器端配FCrDNS校验。
工具给每个爬虫标的“SEO友好度”是什么意思?
识别结果里,每个爬虫都带一个SEO友好度标签,分三档:友好、中性、不友好。这是工具帮你快速判断“该怎么对它”的一个浓缩指标。友好(绿色)指的是支持你被索引、给你带流量的爬虫,主要是搜索引擎和社交媒体,建议放行。
中性(橙色)指的是不影响你排名、拦不拦都行的爬虫,比如SEO工具爬虫、监控工具、部分AI检索爬虫。不友好(红色)指的是扒你内容做训练、或纯粹消耗资源没回报的爬虫,比如AI训练爬虫、采集框架,建议考虑屏蔽。要明确的是,这套三档评分是工具的工程化判断,是它基于“对网站SEO有没有好处”这个角度给的归类,不是某个官方的权威定级。它是帮你快速排序的参考,不是非黑即白的命令。
“建议屏蔽”的三档怎么理解?
除了SEO友好度,每个爬虫还带一个屏蔽建议,也是三档:建议屏蔽(yes)、可选屏蔽(optional)、不要屏蔽(no)。这跟SEO友好度是两个维度,合起来用更准。
建议屏蔽(yes)给的是那些几乎没有正当理由该放行的,比如开源采集框架Scrapy、批量图片采集工具img2dataset——它们来你站上基本就是为了批量扒数据。可选屏蔽(optional)是最大的一档,给AI训练爬虫、SEO工具爬虫、通用HTTP工具这些“看需求”的,拦不拦取决于你的取舍。不要屏蔽(no)给搜索引擎和社交媒体这些“拦了就自伤”的。这两个维度一组合,工具就能比较聪明地帮你筛出“到底该把谁写进robots.txt”——这正是它自动生成屏蔽规则的依据。
它能一键生成robots.txt屏蔽规则吗?
能,这是工具一个挺省事的功能。它会根据这次识别出的爬虫,自动挑出该屏蔽的,生成一段现成的robots.txt规则,每个被屏蔽的爬虫配上注释(说明它是谁、干嘛的)加上User-agent和Disallow行,你直接复制贴到自己的robots.txt里就行。
它挑选屏蔽对象的逻辑是两条:一是屏蔽建议为yes的(强制采集类,比如Scrapy);二是屏蔽建议为optional且SEO友好度为不友好的(主要就是GPTBot、ClaudeBot、CCBot、Google-Extended这些AI训练爬虫)。而搜索引擎、社交媒体、以及中性的SEO工具爬虫,它不会自动放进屏蔽名单。
这个默认逻辑挺合理——它帮你拦掉最该拦的AI训练爬虫和恶意采集,同时绝不误伤给你带流量的爬虫。但生成出来的规则是个起点不是终点,你得照着自己的需求再微调,比如你其实想保留内容被AI训练(换曝光),就把对应行删掉。
拦AI爬虫到底会不会影响搜索排名?
这是站长们拦AI爬虫时最大的顾虑,也最值得说清。结论是:拦AI训练爬虫,不影响你的Google搜索排名。原因前面提到过——负责搜索收录的Googlebot,和负责AI训练的Google-Extended,是两套独立的爬虫和控制开关。
根据Google爬虫与UA字符串总览文档,Google-Extended是专门用来控制内容是否用于Gemini等生成式AI训练的,它独立于Googlebot;你在robots.txt里Disallow了Google-Extended,Googlebot照样来收录你,搜索排名不受任何影响。同理,拦GPTBot不影响你在Bing、Google的排名,拦ClaudeBot也一样。所以“拦AI训练爬虫会掉排名”是个普遍的误解。
真正要权衡的不是排名,而是另一件事:你拦了AI训练,你的内容就更难出现在ChatGPT、Gemini的回答里被引用——这才是拦AI爬虫真正的机会成本,是“保护内容”和“换取AI曝光”之间的取舍。想清楚你更看重哪个,再决定拦不拦,而不是因为怕掉排名这个根本不存在的顾虑而纠结。
从access日志里能识别出爬虫占比吗?
能,而且这是它比单条UA识别更有价值的用法。你把一段服务器访问日志整个粘进去,它会从每行里提取UA、逐个识别、然后统计:这段日志里出现了哪些爬虫、各自来了多少次、搜索引擎和AI爬虫各占多少。
这个统计能回答几个很实际的问题:我的抓取预算主要被谁消耗了?是Googlebot这种该来的爬虫占大头(健康),还是一堆AI训练爬虫、采集脚本在疯狂消耗(该治理了)?有没有哪个我没听说过的爬虫访问量异常高(可疑,值得追查)?把爬虫流量从“一团乱麻的日志”变成“谁占多少的清晰占比”,你才能判断要不要对某些爬虫动手。想做更深入的抓取预算和日志分析,可以结合我们拆过的日志分析器的方法一起用。
怎么用它做一次爬虫流量盘点?
把工具用出价值,靠一套固定动作。我们团队给一个站做爬虫流量盘点时,标准流程是这样的。
- 从服务器拉一段有代表性的访问日志(比如最近七天的),整段粘进识别器,让它跑出这段时间里所有爬虫的清单和访问次数统计。
- 先看搜索引擎爬虫的健康度。确认Googlebot、Bingbot这些该来的爬虫访问正常、没被异常拦截,它们是你搜索流量的命根子,优先保证畅通。
- 再看AI爬虫的占比和构成。分清哪些是训练类(GPTBot、ClaudeBot、CCBot)、哪些是检索类(ChatGPT-User、OAI-SearchBot),按你“保护内容还是换AI曝光”的策略决定拦谁放谁。
- 揪出可疑爬虫。看有没有访问量异常高、或者叫不上名字、或者自称Googlebot却来得蹊跷的,这些标记出来,到服务器端用反向DNS验证真伪。
- 用它生成的robots.txt规则做底稿。复制出来后按自己的策略微调——删掉你想放行的、补上工具没收录但你想拦的,再更新到线上robots.txt。
- 定期复盘。爬虫生态变化很快,新的AI爬虫不断冒出来,隔一段时间重新拉日志跑一遍,保持你的屏蔽规则跟得上。
这套流程的核心是“先看清、再决策、定期复盘”。识别器负责把爬虫流量从看不懂的UA翻译成看得懂的身份和占比,你负责按自己的SEO策略和内容保护需求做放拦决策,可疑的真伪验证则交给服务器端的DNS校验。
哪些数字和事实是官方的,哪些是工具的判断?
用这个工具得分清两类信息。属于官方、可核实的事实:各大爬虫的UA字符串(Googlebot的UA含Googlebot、GPTBot的UA是GPTBot、Google-Extended用于控制AI训练,这些都有对应公司的官方文档背书);真假Googlebot用FCrDNS验证的方法(Google官方推荐);拦Google-Extended不影响Googlebot收录(Google官方说明)。这些可以当事实依据。
属于工具工程化判断的:SEO友好度的三档评分(友好/中性/不友好,是工具按“对SEO有没有好处”这个角度的归类);屏蔽建议的三档(yes/optional/no,是工具的建议而非强制);自动生成robots.txt时的挑选逻辑(屏蔽yes的加上optional且不友好的,是工具的设计决策)。这些是帮你快速决策的参考,不是必须照办的命令。用工具的正确姿势是:把UA对应哪个爬虫当事实信,把该不该拦的建议当参考、结合自己的需求拿主意。
这个工具的能力边界在哪?
用好它,得清楚它做不到什么。最大的边界前面反复强调了:它只做UA字符串匹配,不验证真伪。它能告诉你“这个UA自称是Googlebot”,但验证不了它是不是真的——真伪验证得在服务器端做反向DNS和IP段比对,不是网页工具能完成的。
第二个边界是它依赖内置的爬虫库。库里有120多种主流爬虫,覆盖很广,但爬虫生态天天在变,新冒出来的爬虫如果还没被收进库,它就只能标成“未知”。所以遇到识别不出的UA,不代表它不是爬虫,可能只是太新。第三,它是个静态的识别工具,不联网去查实时的爬虫IP段、不主动更新库。把这些边界记清楚,它就是个好用的“爬虫身份翻译器”——快速把UA翻译成身份和建议,但真伪核验、最新爬虫、实时IP这些,得靠别的手段补上。
实战案例:茶叶茶具出海站的爬虫流量体检
我们团队去年给一个做茶叶茶具的出海站做技术SEO体检,这站卖各类茶叶、紫砂壶、茶具套装,内容做得挺用心,有不少泡茶教程和茶文化的长文。客户的困惑是两个:一是服务器负载莫名其妙地高,二是听说内容被AI扒走训练,想知道是不是真的、能不能拦。
我们拉了它最近一周的访问日志,整段丢进爬虫识别器。结果挺说明问题:爬虫流量里,正经的Googlebot、Bingbot访问其实不算多、很健康;占大头的是两拨——一拨是CCBot(Common Crawl)和GPTBot,访问量加起来比Googlebot还高,这俩都是AI训练爬虫,难怪客户感觉内容被扒;另一拨是几个SEO工具爬虫和一个叫不上名字、UA很简陋的脚本,后者访问频率高得异常,是服务器负载高的一个隐形来源。
我们还注意到日志里有几条自称Googlebot但来源IP很可疑的请求。在服务器端做了反向DNS验证,果然——它们的IP反向解析根本不是googlebot.com,是冒充的采集器,正顺着茶具产品页批量薅图片和价格。
按识别和验证的结果,我们给客户的处理分三类:那些教程长文是花了大力气写的核心资产,客户决定保护,于是用工具生成的robots.txt底稿,拦掉GPTBot、ClaudeBot、CCBot、Google-Extended这些训练爬虫(同时确认完全不影响Googlebot收录和搜索排名);那个简陋脚本和验证为假的伪Googlebot,在服务器端直接按UA和IP封禁;社交和搜索爬虫一个没动。
处理完,服务器负载降了一截,核心内容也挡住了大部分训练扒取。这个案例的要点是:识别器帮我们把“谁在抓、抓得凶不凶”从看不见变成了看得见,但真伪验证靠的是服务器端DNS,拦谁放谁靠的是客户对自己内容的取舍。
识别爬虫只是第一步,下一步管什么?
识别爬虫,放在“网站可抓取性”这个大图景里,是中间一环。一个站能不能被搜索引擎顺畅地抓取收录,要过三关,对应三类诊断。
第一关是抓取入口:你递给搜索引擎的URL清单干不干净,决定抓取资源投向哪里,这能用我们拆过的sitemap提取器的方法去摸底。第二关就是这篇讲的——搞清楚到底是谁在抓你的站、真假怎么分、AI爬虫该放该拦。第三关是抓取落地:单个页面别太重,别超过Googlebot的抓取体积上限导致内容被截断,这能用抓取体积检查器的方法去测。识别爬虫管的是“谁来抓、给谁开门”,它上承抓取入口、下接抓取落地,三件套合起来才算把一个站的抓取健康度查全了。
常见问题解答
这个识别器能验证一个Googlebot是真是假吗?
不能,它只做UA字符串识别。它能告诉你这串UA对应Googlebot,但User-Agent是可以伪造的,它判断不了这个请求是真Googlebot还是冒充的。验证真假得用Google官方推荐的正向确认反向DNS(FCrDNS):拿请求IP做反向DNS查看是否解析到googlebot.com,再把这个域名正向解析回去看是否还是原IP。这个验证必须在服务器端对IP做,不是一个解析UA文本的网页工具能完成的。
拦掉GPTBot、ClaudeBot这些AI爬虫,会影响我的Google排名吗?
不会。负责Google搜索收录的是Googlebot,负责AI训练的GPTBot、ClaudeBot、Google-Extended是另一套独立爬虫,拦前者才影响排名,拦后者只影响内容会不会被拿去训练AI。你在robots.txt里Disallow这些AI训练爬虫,Googlebot照常来收录,排名不受影响。真正要权衡的不是排名,而是拦了之后内容更难出现在ChatGPT、Gemini的回答里被引用,这是保护内容与换取AI曝光之间的取舍。
Google-Extended和Googlebot有什么区别,能分开拦吗?
能分开,而且这正是关键。Googlebot负责搜索收录,Google-Extended是个独立开关,专门控制你的内容要不要被用于训练Gemini等Google的AI模型。你可以在robots.txt里单独Disallow Google-Extended、拒绝内容被拿去训练,同时完全不影响Googlebot继续收录你、不影响搜索排名。很多人不知道这俩能分开,结果要么不敢拦AI训练,要么一拦把搜索收录也连累了。识别器把它俩分开列出,就是帮你避开这个误区。
它靠正则表达式匹配UA吗,准不准?
不用正则,用的是不区分大小写的子串匹配——拿库里每个爬虫的名字去你的UA文本里找,找到就判定为这个爬虫。对正经爬虫很准,因为它们的UA里老老实实写着自己的名字。但它的准只限于“这个UA自称是谁”,没法判断UA是不是伪造的。对善意爬虫够用,对想严防的冒充场景就不够,得另上DNS和IP验证。
我拦了机器人后,链接分享到社交平台没预览图了,怎么回事?
八成是误拦了社交媒体爬虫。facebookexternalhit、Twitterbot、LinkedInBot这些爬虫,是在你链接被分享时来抓Open Graph标签、生成预览卡片的,拦了它们卡片就变空白。很多人配WAF或robots规则狂拦机器人时会顺手把社交爬虫也拦了。识别器明确把这一类标成“不要屏蔽”,就是防这种自伤社交流量的错误。检查你的屏蔽规则,把社交爬虫放行就能恢复预览。
权威参考资料
本文标题:《爬虫识别器怎么用?120种UA分类与真假Googlebot验证全拆解》
本文链接:https://zhangwenbao.com/crawler-identifier-user-agent-bot-verification-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0