渲染对比器怎么用?揪出爬虫和用户看到的页面不一样
本文目录
- 渲染对比器到底是什么?解决什么问题
- 它怎么拿到“爬虫看到的”和“用户看到的”?
- 为什么这种做法能查出问题,又有什么盲区?
- 什么是Cloaking?为什么搜索引擎严打它?
- 它从一个页面里提取哪些维度来对比?
- 评分是怎么扣出来的?从一百分开始扣
- 哪些差异是“严重”,哪些只是“警告”?
- 文本内容量的差异,为什么扣得最重?
- 标题、meta robots不一致,意味着什么?
- 文本相似度是怎么算的?
- JS渲染会让爬虫看不到内容吗?
- 既然查不出纯CSR,那它对JS站还有用吗?
- 动态渲染(Dynamic Rendering)是解药吗?
- 怎么用它做一次完整的渲染对比?
- SEO场景一:上线前的Cloaking自查
- SEO场景二:JS站的渲染丢内容排查
- SEO场景三:被怀疑作弊后的自证
- 它做不到的几件事,必须心里有数
- 实战案例:滑雪装备出海站的渲染丢内容
- 状态码两版不一致,为什么是头号红灯?
- 结构化数据两版不一致,要紧吗?
- 对比三件套:从文本到页面再到AI
- 常见问题解答
- 渲染对比器是真的用浏览器渲染页面吗?
- 它的一致性得分高,就说明我的页面没问题吗?
- Cloaking到底会有什么后果?
- 动态渲染还能用吗?Google怎么看?
- 这个工具和Google Search Console的网址检查,该用哪个?
- 权威参考资料
摘要:同一个网址,搜索引擎爬虫看到的内容,和真实用户看到的,是不是同一份?这个问题答错了,轻则JS渲染把正文丢了导致不收录,重则被判成隐藏作弊(Cloaking)直接掉排名。这篇用一个渲染对比器当例子,讲清它怎么用一招——给同一个网址发两次请求、分别冒充Googlebot和普通Chrome用户——抓回两份HTML来对比,又从标题、meta、正文字数、链接数、结构化数据等十一个维度逐项比对、从一百分往下扣分判风险。同时把这工具最关键的诚实边界说透:它不跑真正的浏览器,所以能查出服务器端的差别对待,却查不出纯客户端JS渲染的差异——明白这条,你才知道它能帮你什么、帮不了什么。
做技术SEO,有个问题始终绕不过去:你的页面,在搜索引擎爬虫眼里,和在真实访客眼里,长得一样吗?很多人想当然地以为“当然一样,都是同一个网址”,但现实里它们经常不一样——有的是无意的,比如页面靠JavaScript渲染,爬虫没等JS跑完就走了,看到的是一具空壳;有的是故意的,给搜索引擎喂一套讨好排名的内容,给用户看另一套,这就是搜索引擎严打的Cloaking(隐藏作弊)。
这两种情况,后果都很严重,但肉眼很难发现——你用浏览器打开看到的永远是“用户版”,爬虫看到的那一份你根本看不见。渲染对比器要解决的就是这个:把“爬虫看到的”和“用户看到的”两份内容都抓回来,摆在一起逐项对比,差在哪、差多少、严不严重,一目了然。这篇就用一个渲染对比器当例子,把它的原理、维度、评分和适用边界讲透。
渲染对比器到底是什么?解决什么问题
它的用法很简单:你给它一个网址,它返回一份对比报告——告诉你这个页面在爬虫视角和用户视角下,标题、描述、正文、链接、结构化数据等各方面有没有差异,给出一个0到100的一致性得分,并明确标出是否检测到了疑似Cloaking的严重差异。
它要解决的核心问题,是让“爬虫眼里的页面”这个平时看不见的东西变得可见、可比。正常情况下,一个页面给谁看都该是同一份内容,这是搜索引擎的基本要求。一旦两份内容出现明显差异,要么是技术故障(渲染问题),要么是政策风险(作弊嫌疑),都得尽快查清。这工具就是帮你把这种差异揪出来的探照灯。
它怎么拿到“爬虫看到的”和“用户看到的”?
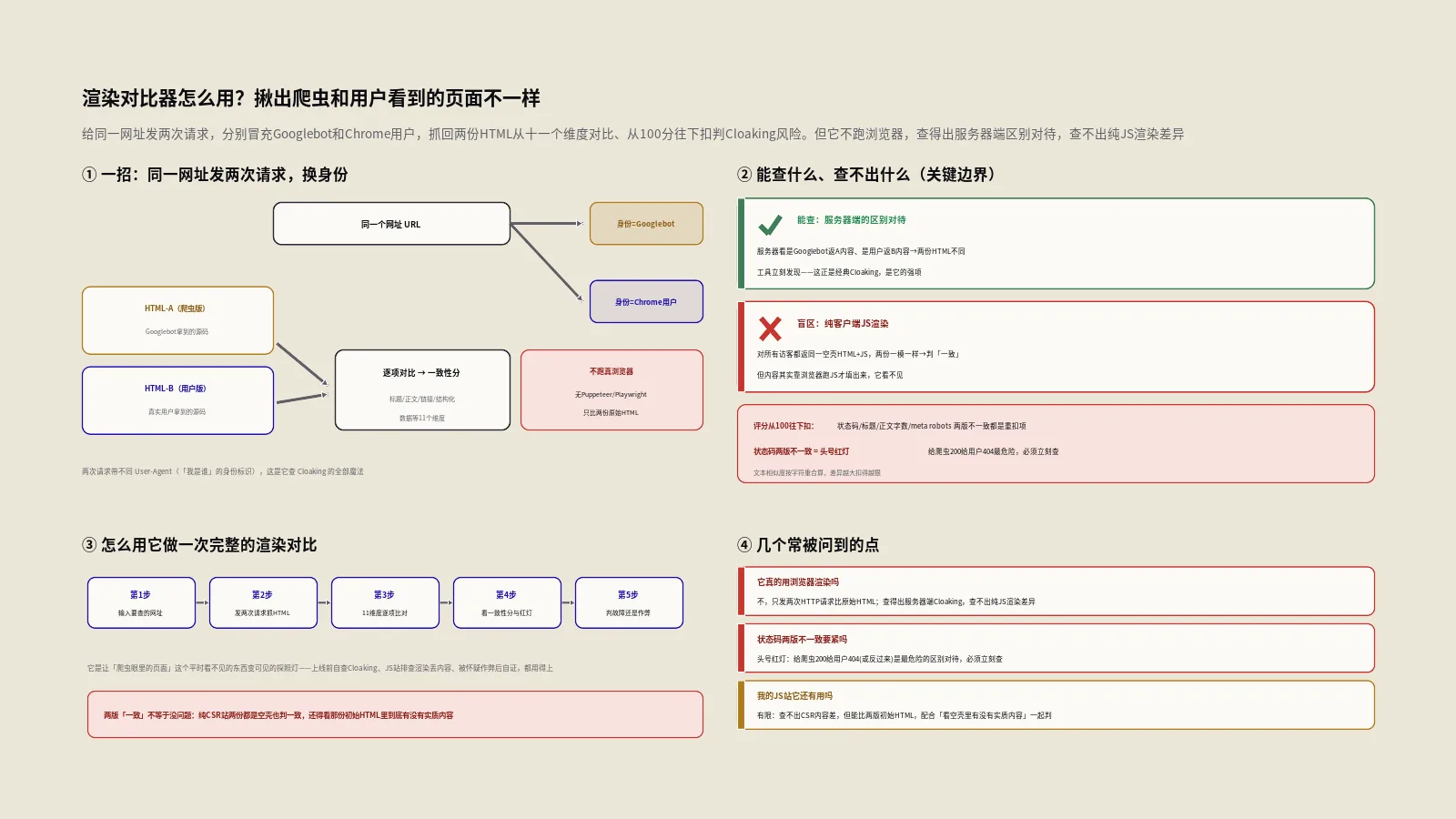
这是理解这个工具最关键的一点,必须讲得明明白白。它的做法是:给同一个网址发两次HTTP请求,两次请求带上不同的User-Agent(用户代理,也就是“我是谁”的身份标识)。
第一次,它把自己的身份标识设成Googlebot的样子,模拟搜索引擎爬虫来访;第二次,设成普通Chrome浏览器的样子,模拟真实用户来访。然后它拿回两次请求各自返回的HTML源码,逐项对比。这里有个必须诚实交代的核心事实:它不运行真正的浏览器,没有用Puppeteer、Playwright这类无头浏览器去真的把页面渲染一遍,它只是发了两次普通的HTTP请求、拿到两份原始HTML文本来比。这个设计让它很轻、很快,但也直接决定了它的能力边界。
为什么这种做法能查出问题,又有什么盲区?
明白了它“只发两次请求、不跑浏览器”,就能推出它能查什么、查不出什么,这点至关重要。
它能查出的,是服务器端的“区别对待”。如果你的服务器写了这样的逻辑——来访的是Googlebot就返回A内容、是普通用户就返回B内容——那两次带不同身份的请求拿回的HTML就会不一样,工具立刻能发现。这正是经典Cloaking的手法,也是它的强项。
它查不出的,是纯客户端JS渲染的差异。如果你的页面对所有访客(不管是Googlebot身份还是用户身份)都返回同一份“空壳HTML加一堆JS”,要靠浏览器执行JS才能填出内容,那两次请求拿回的HTML是一模一样的(都是空壳),工具会判它们“一致”——因为它不执行JS,看不到JS填进去的内容。
所以它对纯CSR(客户端渲染)应用存在盲区。知道这条,你用它时就不会误判:两版“一致”不一定代表没问题,还得看那份初始HTML里到底有没有实质内容,这点后面会专门讲。
什么是Cloaking?为什么搜索引擎严打它?
既然这工具的主战场是查Cloaking,得先讲清Cloaking是什么。Cloaking指的是“给搜索引擎和给用户呈现不同的内容”,目的是操纵排名、误导用户。
根据Google搜索中心的垃圾内容政策,Cloaking被明确列为违规行为——比如给搜索引擎展示一个关于旅游目的地的页面,却给用户看减肥药广告;或者只在检测到来访者是搜索引擎时才往页面里塞关键词。
这么干为什么遭严打?因为它从根上破坏了搜索的信任:用户点进来看到的,和搜索引擎承诺的不是一回事。Google会通过自动系统和人工审核来识别这类行为,一旦坐实,轻则排名下滑,重则整站从结果里消失。值得一提的是,被黑客入侵的网站也常被植入Cloaking,让站长更难察觉被黑——所以查出Cloaking差异,有时还能帮你发现网站被入侵了。
它从一个页面里提取哪些维度来对比?
工具会从抓回的每一份HTML里,提取一整套维度,再两两对比。维度大致分这么几类。头部元信息:标题(title)、meta描述、meta robots指令、规范标签(canonical)、字符编码、视口设置。标题结构:H1到H6各级标题的内容。
内容与链接:纯文本正文的字数和词数、链接总数(以及内部链接、外部链接、nofollow链接的数量)、图片数量(含有没有alt属性)。结构化数据:页面里的JSON-LD结构化数据有哪些类型。此外它还会提取Open Graph、Twitter卡片、hreflang多语言标签、以及页面用了什么JS框架的信号(这些用于辅助诊断)。一句话,它把一个页面里跟SEO相关的关键信号几乎都拎出来了,逐项看爬虫版和用户版对不对得上。
评分是怎么扣出来的?从一百分开始扣
它的评分逻辑很直观:起评100分,发现一处差异就按严重程度扣相应的分,扣到最后就是这个页面的一致性得分。
不同维度的差异,扣分轻重不同,这套权重是工具基于SEO审计经验定的工程化设定,不是什么官方标准。大致是:状态码不一致扣得最狠,标题、meta robots不一致也是重罚,正文内容量差异过大同样重扣,而描述、规范标签、H1的差异是中等扣分,链接数、图片数、结构化数据类型、HTML体积这些差异属于轻微警告、扣得少。最终得分卡在0到100之间。这套“从满分往下扣”的算法好处是直观:满分说明爬虫版和用户版高度一致,分数越低说明差异越大、风险越高。
哪些差异是“严重”,哪些只是“警告”?
工具把发现的差异按严重性分了三档,这个分级比单纯的分数更有指导意义。严重(critical):性质恶劣、最可能是Cloaking的差异,比如给爬虫和用户的状态码不同、标题完全不同、meta robots指令不同、正文内容量差太多。只要出现任何一项严重差异,工具就会直接判定为“检测到疑似Cloaking”。
错误(error):有问题但没到作弊嫌疑那么严重,比如规范标签不一致、H1不一致。警告(warning):轻微的、可能正常也可能需要留意的差异,比如链接数、图片数有些出入。这套分级的价值在于帮你分清主次:看到一片差异别慌,先看有没有“严重”级的——有,那是要命的问题,优先查;只有“警告”级的,往往是正常的动态内容波动,留意即可。
文本内容量的差异,为什么扣得最重?
在所有维度里,正文内容量的差异是工具盯得最紧的,判定也最讲究,值得单独说。它不是简单看字数差多少,而是用了“相对比例加绝对差额”的双重门槛。
具体是:先算两份正文的长度比例(短的除以长的),再看绝对字数差。如果比例低于一半、且绝对差超过两百字,判为严重差异、重扣;如果比例在一半到八成之间、且绝对差超过一百字,判为警告、轻扣;比例在八成以上,算通过。
为什么这么设计?因为正文是页面的核心,给爬虫看的正文和给用户看的差一大截,要么是Cloaking(喂给爬虫一堆用户看不到的关键词),要么是JS渲染把内容给丢了——两种都是大事。用双重门槛是为了避免误判:只看比例,短页面差几十字就报警太敏感;只看绝对数,长页面差几百字可能其实占比很小。两个条件都满足才判严重,更稳。
标题、meta robots不一致,意味着什么?
这两个维度的差异,工具都按重罚处理,因为它们的信号意义太强。标题不一致:给爬虫一个塞满关键词的标题、给用户一个正常标题,是典型的Cloaking手法,所以标题完全不同会被判严重。
meta robots不一致更敏感。meta robots是告诉搜索引擎“这页能不能收录、能不能跟踪链接”的指令。如果给用户版写的是正常可收录,给爬虫版偷偷加了noindex(不收录),或者反过来,这都是在玩两面派——要么想藏着掖着,要么逻辑出了严重bug。这种差异对收录的影响是直接而致命的,所以工具把它列为严重级。看到meta robots两版不一致,几乎一定是要立刻排查的问题。
文本相似度是怎么算的?
报告里会给一个文本相似度的百分比,它的算法是个简单的工程化公式:两份正文里,较短那份的长度,除以较长那份的长度,得到一个比例,再换算成百分比。
这个算法很朴素,它衡量的是“两份正文长度上的接近程度”,而不是逐字逐句的内容相似。也就是说,它假设“长度差不多”大体能反映“内容差不多”——这在多数情况下成立,但要知道它的局限:两段长度一样但内容完全不同的文本,按这个公式也会算出很高的相似度。所以它是个快速的、粗粒度的参考,用来配合内容量的双重门槛判断,不是精确的内容比对。要做精确的字面差异比对,那是文本差异对比器的活儿。
JS渲染会让爬虫看不到内容吗?
这是JS站最关心的问题,也是渲染对比的另一大用途背景。答案是:可能会,取决于你怎么渲染。
根据Google搜索中心关于JavaScript SEO基础的文档,Google处理JS网页分三个阶段:抓取、渲染、索引。抓取时Googlebot先拿到原始HTML;之后在资源允许时,用一个无头版的Chromium把页面渲染一遍、执行JS;最后用渲染后的HTML来索引。
问题在于“渲染”这一步不是即时的,它要排队、要等Google有空闲资源——如果你的页面初始HTML是空壳、全靠JS填内容,那在渲染发生之前,爬虫看到的就是没内容的壳。文档也明确建议:服务端渲染或预渲染依然是好主意,因为它让页面对用户和爬虫都更快,而且不是所有爬虫都能执行JS。
既然查不出纯CSR,那它对JS站还有用吗?
前面说了,这工具不执行JS,查不出纯客户端渲染的差异,那它对JS站是不是就没用了?不是,它换个角度依然有用。
它能告诉你一件重要的事:你的页面的“初始HTML”(也就是不执行任何JS、服务器直接吐出来的那份)里,到底有没有实质内容。怎么用?你拿工具一抓,如果爬虫版和用户版的正文都很空、字数都极少,那即便两版“一致”(都空),也说明一个危险信号——你的初始HTML没内容,全指望JS渲染。结合前面说的“渲染要排队、不是所有爬虫能跑JS”,这就是个隐患。所以对JS站,别只看它报的“一致性得分”,更要看它抓到的“初始HTML正文字数”——这个数太小,就是该上服务端渲染的警报。
动态渲染(Dynamic Rendering)是解药吗?
聊到JS渲染问题,很多人会想到一个老方案:动态渲染——服务器检测来访者,如果是爬虫就给一份预先渲染好的静态HTML,如果是用户就给正常的JS版本。听起来正好解决问题,但这里要泼盆冷水。
根据Google搜索中心关于动态渲染的文档,Google已经把动态渲染定位成一个“权宜之计(workaround)”而非长期推荐方案,并建议改用服务端渲染、静态生成或同构(hydration)等方案。
原因有几个:动态渲染要维护两套输出,复杂且易出错;而且它的机制——“给爬虫和用户返回不同内容”——天然踩在Cloaking的边界上,一旦两套内容偏差大了,就可能被误判成作弊。这也正好呼应了这个对比工具:动态渲染做得不干净,恰恰会被它检测成爬虫版和用户版不一致。所以与其用动态渲染再提心吊胆,不如直接上服务端渲染。
怎么用它做一次完整的渲染对比?
把它用规范,按这套流程走,结论最可靠。
- 选对页面。优先挑那些对SEO最重要、又最可能出问题的页面——比如靠JS渲染的产品页、分类页,或者最近排名异常波动的页面。
- 输入网址、跑对比。把页面的完整网址贴进去,让工具发两次不同身份的请求、抓回两份HTML。
- 先看有没有“严重”级差异。报告出来,第一眼别看总分,先看差异列表里有没有标红的严重项——有,那是Cloaking或重大故障的信号,优先处理。
- 再看正文字数这个关键指标。不管两版一致不一致,都看一眼抓到的初始HTML正文字数。太空,说明内容靠JS填,对爬虫不友好,要考虑服务端渲染。
- 逐项核对可疑维度。对标题、meta robots、规范标签这些重权重维度逐个确认,是不是符合你的预期,有没有不该有的差异。
这套流程的关键是“先严重后警告、一致也要看正文空不空”——既抓作弊和故障的大问题,也不放过JS渲染这个隐性隐患。
SEO场景一:上线前的Cloaking自查
最常见的用法,是当网站功能复杂、用了各种针对不同访客的逻辑时,上线前自查有没有无意中构成Cloaking。有时候你的服务器为了优化体验,给不同来源做了不同处理,自己都没意识到这在搜索引擎看来就是“区别对待”。
上线前用它把核心页面跑一遍,确认爬虫版和用户版没有严重差异,相当于过一道安检。尤其是那些做了地域跳转、设备适配、A/B测试的页面,最容易在不经意间给爬虫和用户喂了不同内容。提前自查,比上线后被搜索引擎判罚再补救,代价小得多。
SEO场景二:JS站的渲染丢内容排查
第二个高频场景,是排查JS站“内容明明在页面上、搜索引擎却好像没收录到”的怪事。这往往就是渲染丢内容——内容靠JS填,爬虫在渲染前看到的初始HTML是空的。
用工具抓一下,看初始HTML的正文字数。如果用浏览器看页面内容很丰富、但工具抓到的初始HTML正文却空空如也,那就坐实了:你的内容是JS渲染出来的,初始HTML里没有。这时候结合搜索引擎的收录情况,基本能判断问题就出在渲染上,解决方向是服务端渲染或预渲染,让内容直接出现在初始HTML里。关于JS渲染对AI爬虫和收录的更深影响,可以看我们拆过的JS渲染与AI爬虫引用率的分析。
SEO场景三:被怀疑作弊后的自证
还有个不太常见但很关键的场景:你的网站排名异常下滑,怀疑是不是被误判成Cloaking,或者想排除这个可能。这时候工具能帮你自证清白,或者揪出真问题。
把可疑页面跑一遍,如果一致性得分很高、没有严重差异,说明你给爬虫和用户的内容确实一致,Cloaking这个嫌疑可以排除,问题出在别处。如果跑出了严重差异,那恭喜你找到了病根——可能是某段历史遗留的“优化”代码在偷偷给爬虫开小灶,也可能是网站被黑植入了Cloaking。不管哪种,定位到了就能对症下药。
它做不到的几件事,必须心里有数
用好它,得清楚边界,否则会误判。第一,也是最重要的——它不执行JS。它查的是服务器返回的原始HTML,所以能发现服务器端的区别对待,但发现不了纯客户端渲染的差异。要看JS执行后的真实效果,得用能跑浏览器的工具(比如Google Search Console的网址检查、或本地的无头浏览器方案)。
第二,它只模拟User-Agent这个身份标识,而真实的Googlebot除了身份标识,还会执行JS、有特定的IP段——工具的模拟是简化的,跟真实爬虫存在差距。第三,所有的扣分权重、阈值(比如正文差异的两百字、一半比例这些数)都是基于经验的工程化设定,是相对刻度,不是搜索引擎的官方判罚标准——它给的是“风险参考”,不是“会不会被罚的判决”。第四,它有抓取上限(一般单页最多抓两兆字节),超大页面可能抓不全。把这四条记牢:它是个轻量、快速的“服务器端内容差异探测器”,JS执行层面的事不归它管。
实战案例:滑雪装备出海站的渲染丢内容
我们团队去年帮一个做滑雪装备的出海站排查过一个典型问题,正好用上了这套思路。这站卖滑雪板、雪服、护具、雪镜,产品页做得很漂亮,前端用了个比较重的JS框架,交互体验确实好。但客户的痛点是:产品页在Google上的收录和排名一直起不来,明明内容写得不少。
我们先用渲染对比器抓了几个核心产品页。结果很说明问题:一致性得分挺高,爬虫版和用户版“一致”——但关键在于,两版抓到的初始HTML正文字数都极少,产品描述、参数、评价这些内容在初始HTML里几乎是空的。这就对上了:内容全是JS渲染出来的,初始HTML是个壳。两版“一致”只是因为它俩都空,不代表没问题,反而暴露了内容根本没进初始HTML这个大隐患。
诊断清楚后,方向就明确了:上服务端渲染,让产品的核心内容(描述、参数、结构化数据)直接出现在服务器返回的HTML里,不再等JS。改造后再抓,初始HTML的正文字数从几十字涨到了正常水平,过了一段时间,产品页的收录和排名明显改善。这个案例的要点是:渲染对比器虽然不执行JS,但它抓到的“初始HTML正文字数”这个指标,恰恰是诊断JS站渲染问题最直接的证据——别被“一致性得分高”迷惑,要看内容到底进没进初始HTML。
状态码两版不一致,为什么是头号红灯?
在所有维度里,HTTP状态码的差异是工具扣分最狠的一项,这背后有很硬的道理。状态码是服务器对每次请求给出的“身份回执”——200表示正常返回页面、404表示页面不存在、301表示永久跳转、403表示禁止访问。
如果同一个网址,给Googlebot身份返回的是200(正常)、给用户身份返回的却是404或别的,或者反过来,那意味着服务器在“让不让你看这个页面”这件最根本的事上,就对爬虫和用户区别对待了。这比内容上的差异性质更恶劣:内容差异还可能是渲染或动态内容造成的,状态码差异几乎只能是服务器被刻意配置成两面派。常见的坑是有人给爬虫单独开了通道、或者某些反爬规则误伤了Googlebot身份的请求。所以看到状态码两版不一致,别犹豫,这是优先级最高的排查项——它直接决定了爬虫到底能不能正常拿到你的页面。
结构化数据两版不一致,要紧吗?
工具也会对比两版页面里的结构化数据(JSON-LD)类型有没有差异,虽然它的扣分权重不高(属于警告级),但这个维度值得单独留意,因为它牵涉一条SEO红线。
结构化数据是你给搜索引擎的“机器可读说明书”,告诉它这页是篇文章、是个产品、有什么价格评分。搜索引擎有条明确要求:结构化数据描述的内容,必须和页面上用户能看到的内容一致。如果你只给爬虫身份的请求返回了带评分、带价格的结构化数据,用户版里却没有对应的可见内容,这就构成了“结构化数据与可见内容不符”,是会被处罚的违规。
所以两版结构化数据不一致,虽然工具只标警告,但你得认真查:是不是无意中只给爬虫喂了用户看不到的标记?把这条当成一个提醒——结构化数据可以加,但描述的东西必须在页面上真实可见、对谁都一样。
对比三件套:从文本到页面再到AI
把渲染对比放进更大的图景,它是“对比”这件事里的第二层——比的是同一个页面在爬虫和用户两种视角下的差异。这套“对比”思路有三层,层层递进。
第一层是文本级:两段纯文字之间的字面差异,比如改版前后、原稿与洗稿,可以看我们拆过的文本差异对比器的方法。第二层就是本文这个页面渲染级,比的是机器视角和人视角看到的同一页面差在哪。第三层是AI引用级:你的页面内容,和AI概览给出的回答之间缺了什么,这是GEO时代的新课题,可以看AI概览对比器的方法。文本、页面、AI回答——对比的对象一层层放大,从一段文字到一个页面再到AI眼中的你,串起来就是一套完整的差异诊断框架。
常见问题解答
渲染对比器是真的用浏览器渲染页面吗?
不是,这是理解它最关键的一点。它不运行真正的浏览器,没有用无头浏览器去执行JS渲染。它的做法是给同一个网址发两次HTTP请求,两次分别冒充Googlebot和普通Chrome用户的身份标识,然后对比两次返回的原始HTML。这个设计让它轻量又快,但也带来明确的边界:它能查出服务器端的区别对待(典型Cloaking),却查不出纯客户端JS渲染的差异——因为它不执行JS,看不到JS填进去的内容。所以用它时要清楚,它比的是服务器吐出来的初始HTML,不是浏览器渲染后的最终页面。
它的一致性得分高,就说明我的页面没问题吗?
不一定,要分情况看。一致性得分高,只说明爬虫版和用户版的初始HTML高度一致,能排除服务器端Cloaking的嫌疑。但如果你是JS站,两版“一致”很可能只是因为它俩都是空壳(内容都靠JS渲染、初始HTML里都没有),这种“一致”反而暴露了内容没进初始HTML的隐患。所以看报告不能只看总分,更要看它抓到的初始HTML正文字数——字数太少,哪怕得分满分,也说明你的内容对爬虫不友好,该考虑服务端渲染了。得分高排除的是作弊嫌疑,排除不了渲染隐患。
Cloaking到底会有什么后果?
后果很严重。Cloaking是给搜索引擎和用户呈现不同内容来操纵排名,被Google明确列为垃圾内容政策的违规行为。Google通过自动系统和人工审核识别这类行为,一旦坐实,网站可能排名大幅下滑,严重的会从搜索结果里彻底消失。而且要注意,Cloaking不一定是你故意的——服务器为不同来访做的某些优化处理、被黑客入侵后植入的恶意代码,都可能在搜索引擎看来构成Cloaking。所以即便你没主观作弊,也值得用工具自查,确认没有无意中触线,这是保护网站的必要一步。
动态渲染还能用吗?Google怎么看?
能用,但Google已经不推荐把它当长期方案了。Google搜索中心的文档把动态渲染定位成一个权宜之计,建议改用服务端渲染、静态生成或同构这些方案。原因是动态渲染要维护爬虫版和用户版两套输出,复杂易错;而且它“给爬虫和用户返回不同内容”的机制天然贴着Cloaking的边界,两套内容一旦偏差大,就可能被误判成作弊。如果你正在用动态渲染,建议逐步迁移到服务端渲染——既更省心,也避开了被渲染对比这类工具检测出差异的风险。
这个工具和Google Search Console的网址检查,该用哪个?
两个互补,各有所长,建议都用。这个渲染对比器的强项是“对比”——它一次抓两份(爬虫版和用户版)放一起比,专门查两者的差异,适合排查Cloaking、查初始HTML空不空,而且快、能批量。Google Search Console的网址检查的强项是“真实渲染”——它能展示Googlebot执行JS渲染之后看到的最终HTML,这是渲染对比器做不到的(它不执行JS)。
所以排查思路是:先用渲染对比器快速扫一遍、看有没有服务器端差异和初始HTML是否空;要进一步确认JS渲染后的真实效果,再用Search Console的网址检查看渲染结果。一个快筛,一个深查。
权威参考资料
本文标题:《渲染对比器怎么用?揪出爬虫和用户看到的页面不一样》
本文链接:https://zhangwenbao.com/render-compare-bot-user-cloaking-detection-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0