文本差异对比器怎么用?逐行逐词揪出两版内容改了哪里
本文目录
- 文本差异对比器到底是什么?解决什么问题
- 它的核心是什么算法?最长公共子序列
- 为什么是LCS,而不是简单逐字比对?
- 行级和词级,两层diff怎么配合?
- 动态规划矩阵,是怎么把差异算出来的?
- 它和Myers diff是什么关系?
- 四种操作:相同、删除、插入、替换怎么判定?
- 忽略空白、忽略大小写,这些选项怎么用?
- 相似度百分比,是怎么算出来的?
- 这个相似度,和Jaccard、编辑距离有什么不同?
- 并排视图和合并视图,该看哪个?
- 怎么用它做一次完整的内容对比?
- SEO场景一:网站改版前后的内容对比
- SEO场景二:洗稿、AI改写前后的比对
- SEO场景三:重复内容与原创度自查
- 它做不到的几件事,必须心里有数
- 实战案例:红酒葡萄酒出海站的描述改版审阅
- 词级diff里,为什么要把空白也当成一个词?
- 它能用来比对代码和配置文件吗?
- 对比三件套:文本级只是第一层
- 常见问题解答
- 文本差异对比器用的是什么算法?
- 它给的相似度百分比准吗?该怎么理解?
- 忽略空白和忽略大小写,会改我的原文吗?
- 它能用来查文章是不是抄袭的吗?
- 对比超长的文本会有问题吗?
- 权威参考资料
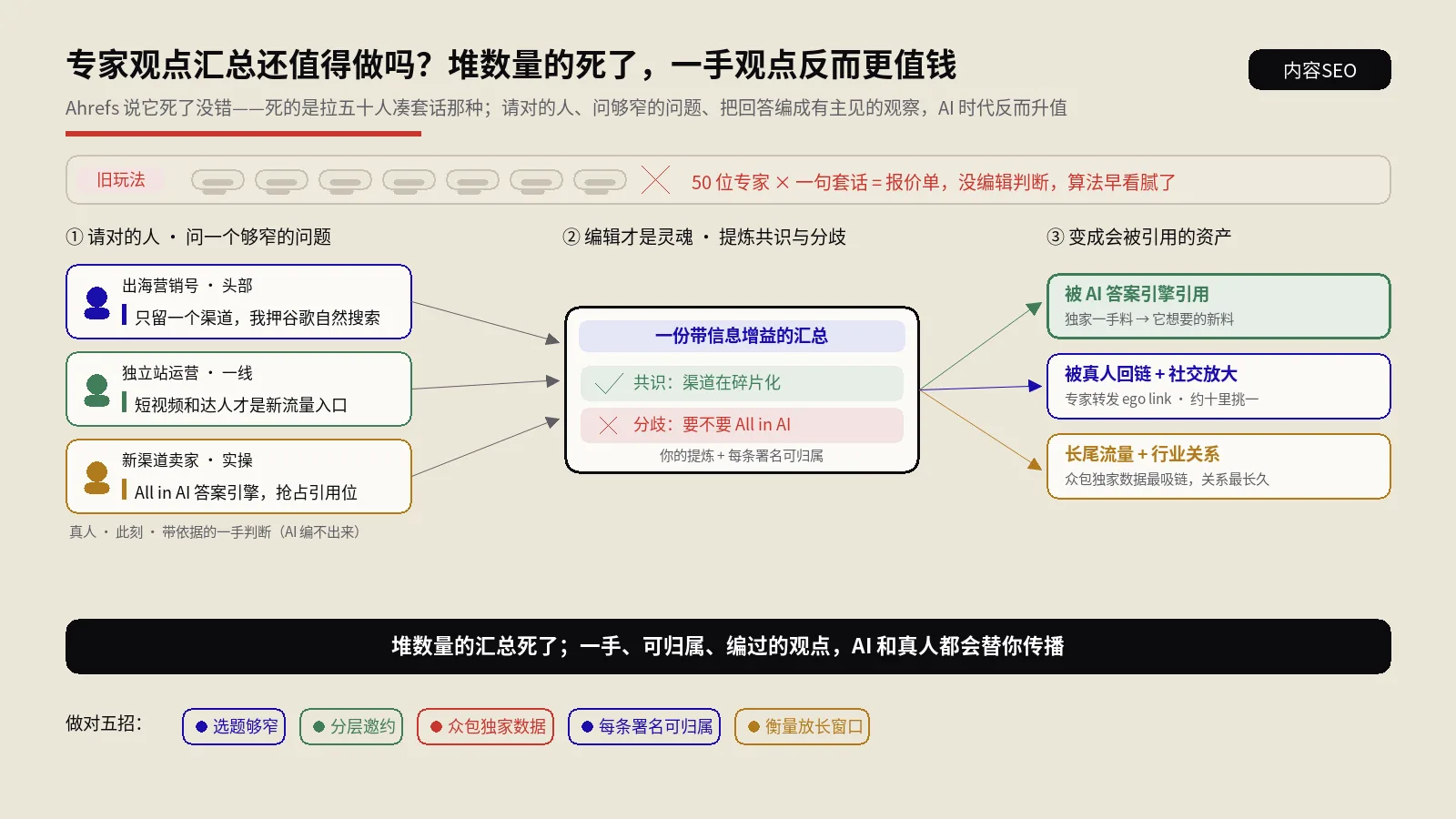
摘要:两个版本的文案摆在面前,到底改了哪几句、动了哪几个词,靠肉眼一行行对,又慢又容易漏。这篇用一个文本差异对比器当例子,把它背后那套经典算法讲透——它用的是LCS(最长公共子序列)加动态规划,先在行级别判断每一行是新增、删除还是修改,再对修改的行做词级别的精细比对,把改动的词高亮出来。顺带讲清几件容易混的事:它和大名鼎鼎的Myers diff算法是什么关系、它给的那个相似度百分比是怎么算的、跟Jaccard和编辑距离有什么不同,以及在SEO里它能帮你做改版审阅、洗稿前后对比、重复内容自查,又有哪几件事它根本做不到。
做内容这行,总会遇到这样的场景:同一篇产品描述,运营改了一版发回来,你想知道他到底动了哪里;或者一篇文章用AI洗了一遍稿,你想确认改动幅度够不够、有没有把关键信息改丢。两份文本摆在一起,一行行用眼睛扫,三五百字还行,上千字就开始头晕,改动小的地方一不留神就漏过去了。
这种活儿,交给文本差异对比器最省事。你把旧版贴左边、新版贴右边,它一比,哪行删了、哪行加了、哪行改了,改的又是改了哪几个词,全给你标得清清楚楚。这篇就用一个文本差异对比器当例子,把它怎么工作、背后是什么算法、在SEO里怎么用、又有哪些边界,掰开揉碎讲一遍。
文本差异对比器到底是什么?解决什么问题
它的用法很直接:输入两段文本(一段是原始版本,一段是修改后的版本),它就帮你逐行、逐词比对,输出一份高亮过的差异报告——删掉的内容标红、加上的内容标绿,没动的保持原样。同时给你一组统计数字:新增了几行、删除了几行、修改了几行、两份文本的相似度是多少。
它要解决的核心问题,是把“找不同”这件费眼又易错的活儿自动化。人对着两大段文字找差异,注意力撑不了多久,越往后越容易看花眼。机器不会累,它会把每一处改动都精确定位到行、定位到词,一个标点的变化都不放过。对要反复审稿、对版本的内容工作者来说,这是个能省下大量眼力的工具。
它的核心是什么算法?最长公共子序列
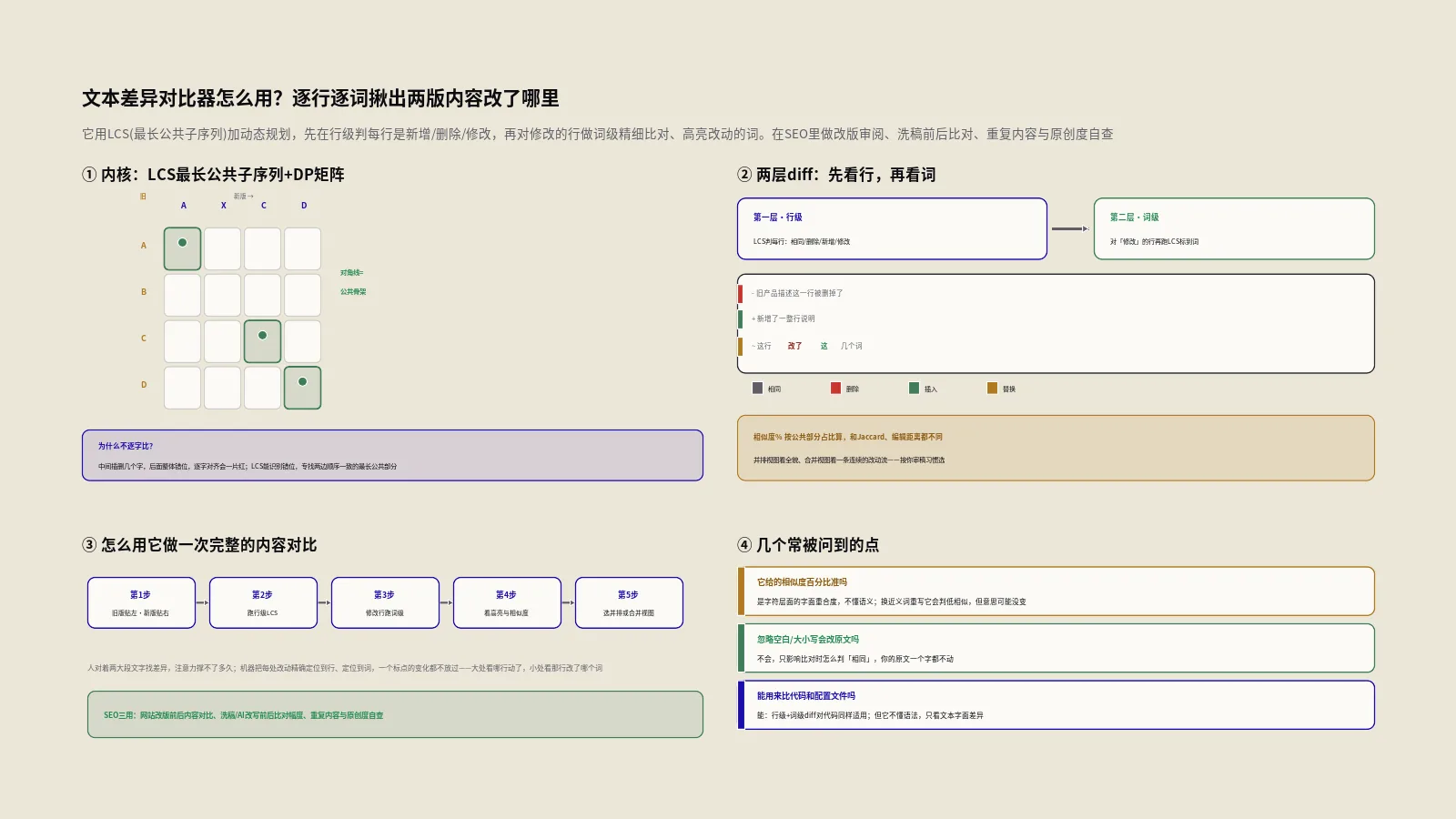
这工具的灵魂,是一个叫LCS(Longest Common Subsequence,最长公共子序列)的经典算法。理解了它,你就理解了几乎所有diff工具的底层逻辑。
所谓最长公共子序列,是指在两个序列里,按原有顺序都出现、且长度最长的那个公共部分(不要求连续)。举个例子,两段文本拆成行的序列,LCS就是“两边都有、且顺序一致的那些行”里最长的一组。找到了这个最长公共部分,剩下的事就顺理成章了:公共部分就是“没变的内容”,左边有、公共部分没有的就是“被删的”,右边有、公共部分没有的就是“新增的”。关于这个概念的严格定义,可以参考维基百科最长公共子序列问题词条,它把LCS的数学定义和动态规划解法讲得很完整。
为什么是LCS,而不是简单逐字比对?
你可能会想:找不同,从头到尾一个字一个字比不就行了?问题在于,一旦中间插入或删除了几个字,后面的内容整体就错位了,逐字对齐会把后面全判成“不同”,结果一片红,完全没法看。
LCS的高明之处,就是它能识别出这种“错位”。它不是死板地按位置对齐,而是去找两边顺序一致的最长公共骨架,把插入和删除当成骨架之外的增减来处理。这样哪怕你在文章开头加了一段话,后面没动的内容依然会被正确识别成“未改动”,而不是因为整体下移就全被误判。这正是LCS比朴素逐字比对聪明的地方,也是它成为diff工具标配的原因。
行级和词级,两层diff怎么配合?
这个工具的diff是分两层做的,这设计很值得说道。第一层是行级:它先把两段文本按换行拆成一行行,用LCS判断每一行的命运——是两边都有的“相同”,是只在左边的“删除”,是只在右边的“新增”,还是位置对应但内容不一样的“修改”。
光到行级还不够。如果一行被判成“修改”,你只知道这行变了,却不知道变在哪。所以有了第二层——词级:对每一个“修改”的行,工具再跑一次LCS,这次比对的不是行,而是这行里的一个个词,精确标出是哪几个词被删、哪几个词被加。两层一配合,效果就是:大处看哪行动了,小处看那行里具体改了哪个词。这种“先粗后细”的两级结构,让报告既有全局又有细节。
动态规划矩阵,是怎么把差异算出来的?
LCS的标准解法,是动态规划。工具内部会构建一个二维矩阵:行对应左边序列、列对应右边序列,每个格子记录“到这一步为止,最长公共子序列有多长”。
填表规则很简洁:如果当前两个元素相等,这个格子的值就等于左上角格子加一;如果不等,就取上方格子和左方格子里较大的那个。整张表填完,右下角那个数就是最长公共子序列的长度。然后从右下角往回“回溯”走一遍,就能还原出完整的操作序列——哪些是相同、哪些是增删改。这套填表加回溯的方法是教科书级的标准实现,时间和空间复杂度都是序列长度的乘积(也就是常说的O(m乘n)),对一般的文本对比足够快。
它和Myers diff是什么关系?
提到diff算法,绕不开一个名字:Myers diff。Git、Unix的diff命令、GitHub上看到的代码改动高亮,背后大多用的是它。这里要诚实说清楚:本文这个工具用的是教科书版的LCS动态规划,并不是Myers那套优化算法。
两者解决的是同一个问题,但路子不同。Myers在1986年的经典论文《An O(ND) Difference Algorithm and Its Variations》里提出了一种更省资源的解法,它的耗时只跟两段文本的“差异量”相关——差异越小跑得越快,所以特别适合代码这种通常只改几行的场景。
而标准LCS动态规划的开销跟两段文本的“总长度乘积”相关,差异大小不影响。对日常那种几百到几千行的文本对比,标准LCS完全够用;只有在超大文件、且改动很小的极端场景,Myers的优势才明显。知道这个区别,你就明白这工具的能力定位在哪——它不是为“几万行只改一处”的极端场景设计的,而是为日常的文章、文案、配置对比服务的。
四种操作:相同、删除、插入、替换怎么判定?
回溯矩阵时,工具会给每一步打上一个标签,一共四种。相同(equal):两边内容一致,原样保留。删除(delete):这行只在左边有,右边没有,判为被删。插入(insert):这行只在右边有,左边没有,判为新增。
第四种最微妙——替换(replace):当左右位置对应、但内容不一样时,工具不是简单粗暴地判成“删一行再加一行”,而是判成“这一行被改了”,并触发前面说的词级diff去看具体改了哪几个词。判定用的是回溯时的一个启发式:当“往上走”和“往左走”的代价相等时,就认为是替换而非分开的增删。这个选择直接影响最终统计里“修改行数”这个数——它让报告更符合人的直觉:你改了一行里的几个字,它就告诉你“这行改了”,而不是冷冰冰地说“删了一行、加了一行”。
忽略空白、忽略大小写,这些选项怎么用?
实际对比时,有些差异你并不关心。比如有人把段落重新缩进了、把多个空格敲成了一个,内容其实没变,但严格比对会把这些都标成差异。工具给了几个开关来应对。
忽略空白:把连续的多个空白统一当成一个,这样缩进、多余空格的变化就不算差异(但换行不会被忽略,它定义了行的边界)。忽略大小写:比对时把字母统一转小写,这样大小写的改动不再算差异。忽略行首尾空格:去掉每行两端的空白再比。这里有个聪明的设计——这些“忽略”只作用在比对判断的环节,输出展示时给你看的仍然是原始内容,工具不会偷偷改写你的文本。你勾上忽略大小写,它只是判定时不计较,屏幕上的字还是你原来的字。
相似度百分比,是怎么算出来的?
报告里有个很直观的数字:相似度百分比。它怎么来的,值得说清楚,因为这是个工程化的简化公式,不是什么学术标准定义。
它的算法是:未改动的行数乘以二,除以“左边总行数加右边总行数”,再换成百分比。为什么未改动行要乘二?因为一行“没变”,意味着它在左右两边各算一次,所以用乘二来对应分母里左右行数的总和。这个公式有个好性质——对称:你把左右两段对调,算出来的相似度一模一样。两段完全相同时是100%,毫无共同之处时是0%。理解它的算法,你就知道这个相似度反映的是“行级别的重合程度”,而不是字符级别的精细相似。
这个相似度,和Jaccard、编辑距离有什么不同?
很多人会把各种“相似度”混为一谈,这里区分一下。这个工具用的是行级重合度,分母是行数总和,只看行有没有对齐,不看一行里改了几个字——所以哪怕你把每一行都改动一个字,行级上全是“修改”,相似度可能掉得很低,但实际内容大部分没变。
Jaccard相似度是另一套:算两个集合的交集除以并集,常用在词级或字符级的集合比较,不在乎顺序和重复。编辑距离(也叫Levenshtein距离)又是一套:算从一段文本变成另一段,最少要做几次插入、删除、替换的字符操作,它精细到单个字符。三者各有各的口径,没有谁对谁错,关键是知道你看的那个数字代表什么。这个工具的相似度,定位就是“行级别改动幅度的快速参考”,别拿它当字符级精确度量用。
并排视图和合并视图,该看哪个?
工具一般给两种看差异的视图。并排视图:左右两栏对照,左边标删除、右边标新增,还能同步滚动,适合逐行细看、做审阅时用,一眼能看出对应关系。
合并视图(也叫统一视图):把差异合成一栏,删除的行前面加减号、新增的行前面加加号,这就是你在Git和代码评审里最常见的那种格式,适合快速浏览改了哪些、或者把差异复制下来贴到别处。两种视图看的是同一份diff结果,只是排版不同。审稿、要看左右对应关系时用并排;快速扫一遍、或要复制差异时用合并。按场景切换就行。
怎么用它做一次完整的内容对比?
把它用顺手,其实就几步,这里给一套可照搬的流程。
- 准备两个版本。把原始版本(旧稿)整理成纯文本贴到左边,把修改后的版本(新稿)贴到右边。注意去掉无关的格式干扰,纯文本对比最干净。
- 按需勾选忽略选项。如果你只关心实质内容、不在乎排版调整,就勾上忽略空白和忽略行首尾空格;如果大小写的变化对你不重要,再勾忽略大小写。
- 跑对比、看统计。先看顶部的统计数字——新增、删除、修改各几行,相似度多少,对改动规模有个整体判断。
- 切到并排视图细看。逐行扫红绿标记,重点看“修改”的行里那些高亮的词,确认每一处改动是不是你预期的,有没有把不该动的内容改了。
- 导出或记录结论。确认无误后,把差异结论记下来或截图存档,作为这次改版的审阅留痕。
这套流程的核心是“先看整体规模、再看局部细节”——统计数字给你大局观,并排视图给你显微镜,两步走,又快又不漏。
SEO场景一:网站改版前后的内容对比
网站改版是SEO的高危动作。页面文案重写、模板调整,稍不留神就把原本有排名的关键内容改没了,或者把重要的内链、说明文字误删,等排名掉了才发现,已经晚了。
文本差异对比器在这里就是个保险。改版前,把关键页面的正文内容存一份;改版后,把新版内容拿来逐页对比。哪些段落动了、哪些关键句被删了、核心关键词还在不在,一比就清楚。尤其是那种“设计师只说改了样式、没动文字”的改版,用它一比,常常能发现文字其实被悄悄动过——这种隐性改动正是排名波动的隐患。把对比当成改版上线前的一道检查关,能拦下不少事故。
SEO场景二:洗稿、AI改写前后的比对
现在用AI改写、洗稿是常态,但改完得验收:改动幅度够不够?有没有把准确的事实、数据、专有名词给改错改丢?光读一遍很难发现这些细节问题。
把原稿和改写稿丢进对比器,改动一目了然。你能直观看到AI到底动了多少——相似度太高说明改得太保守、跟原文太像;改动太碎又可能伤了原文的准确性。更重要的是,那些被改动的词会被高亮,你能逐个检查:这个数字改对了吗?这个产品型号改没改错?这个专业术语换的同义词合不合适?AI改写最容易在这些细节上翻车,而对比器让你能精准盯住每一处改动去核对,比通读两遍可靠得多。
SEO场景三:重复内容与原创度自查
站内重复内容是个老问题。两个产品页文案高度雷同、几篇文章大段重复,搜索引擎要在这些近乎一样的页面里选一个当代表,剩下的可能就不被收录,白白浪费抓取资源。
对比器可以帮你做自查:把怀疑重复的两个页面内容拿来比,相似度一算、重合的行一标,到底重不重、重在哪,立马有数。发现高度重复后,正确的做法不只是改文案,还要在技术层面处理——给重复页面设好规范标签,告诉搜索引擎哪个是“正主”。关于怎么用规范标签整合重复URL,可以参考Google搜索中心关于整合重复网址的官方文档,它把规范标签、重定向等几种整合手段讲得很清楚。对比器帮你定位重复,规范标签帮你处理重复,两手一起上才彻底。
它做不到的几件事,必须心里有数
用好它,得清楚它的边界。第一,它不做语义理解。它比的是字面,“番茄”和“西红柿”在它眼里是两个完全不同的词,会被标成改动——它不懂这俩是一回事。同义改写在它看来就是大改动,别指望它判断“意思变没变”。
第二,它有规模上限。因为标准LCS的开销跟文本长度乘积相关,文本太大(一般建议单边不超过五千行)时会明显变慢,超大文件更适合用本地的专业diff工具。第三,它不查抄袭来源——它只对比你给的这两段文本,不会去全网搜你的内容有没有被抄、或你有没有抄别人,那是查重工具的活儿。第四,它不处理图片、表格的视觉差异,只认纯文本。把这四条记清楚:它是个精准、快速的“文本字面差异定位器”,语义、查重、超大文件、富媒体,都不在它的射程里。
实战案例:红酒葡萄酒出海站的描述改版审阅
我们团队去年帮一个做红酒、葡萄酒的出海站做产品描述改版,这事很能说明对比器的价值。这站卖进口红酒、起泡酒、酒具配件,有几百个产品页,原来的描述写得干巴巴,运营想统一重写一版,让文案更有质感、也更利于SEO。
问题来了:几百页交给好几个人改,怎么保证改得对、没把关键信息(年份、产区、酒精度、容量这些硬参数)在润色时改错?我们的做法是,每改完一页,就把改版前后用对比器跑一遍。先看相似度,太高的说明只是换了几个字、没真正重写,打回去重改;改动正常的,就切并排视图逐个检查高亮的词,重点盯那些硬参数——结果还真揪出好几处,有的把2018年份手滑改成了2019、有的把750毫升写成了500毫升,这种错肉眼通读极难发现,混进去就是客诉甚至退货。
靠这套“每页必比、重点盯参数”的流程,几百页的改版上线后零参数错误,文案质量也整体提了一档。这个案例的要点是:对比器的价值不在“找文字差异”这个动作本身,而在它能让你把审校精力精准投到“改动的地方”,尤其是那些一旦错了代价很大的关键数据上。
词级diff里,为什么要把空白也当成一个词?
有个藏在实现里的小巧思值得说:做词级比对时,工具的分词不是只取“实词”,而是把连续的非空白字符当一个词、把连续的空白也当一个词,两类交替着切。也就是说,词和词之间的空格,本身也是一个被记录下来的单元。
为什么要这么干?因为要保证输出时能原样还原文本的格式。如果分词时把空白都丢了,比对完再拼回去,词和词之间该有几个空格、是空格还是制表符,就全乱了。把空白也当词保留下来,工具在标红标绿、还原原文时,每个词的位置、每处空白都丝毫不差。这是个不起眼但很关键的工程选择——它让差异报告既精确标出了改动,又完整保留了原文的模样,你看到的高亮结果就是你原文该有的样子,不会因为比对而走形。
它能用来比对代码和配置文件吗?
能,而且这是它很顺手的场景之一。代码、配置文件、数据片段这类“逐行有意义”的文本,正是行级加词级diff最擅长的——它们改动往往集中在某几行,行级diff能快速定位改了哪行,词级diff能精确到改了哪个参数、哪个值。
实际用的时候,对代码和配置有个小建议:善用忽略选项。代码里经常有纯粹的缩进调整、空格规范化,这些不是逻辑改动,勾上忽略空白能把它们过滤掉,让你只盯真正的逻辑变更。比如对比两版配置文件,你关心的是某个参数的值变了没、某个开关开了还是关了,而不是有人把缩进从两个空格改成了四个——忽略空白一开,噪声就清干净了。需要提醒的是,它做的是“文本层面”的对比,不理解代码语义(比如它不知道两个变量名其实指同一个东西),所以它适合做“看改了哪些字面”的快速审阅,不能替代代码评审里对逻辑正确性的判断。
对比三件套:文本级只是第一层
把文本差异对比放进更大的图景,它其实是“对比”这件事里最基础的一层——比的是两段文字的字面差异。在SEO和GEO的审计里,“对比”还有更高的两层。
第二层是页面渲染级的对比:搜索引擎爬虫看到的页面,和真实用户看到的,是不是同一份内容?这关系到JS渲染丢内容、甚至隐藏作弊(Cloaking)的问题,可以看我们拆过的渲染对比器的方法。第三层是AI引用级的对比:你的页面内容,和AI概览实际给出的回答之间差在哪、缺了什么,这是GEO时代的新课题,可以看AI概览对比器的方法。文本级、渲染级、AI引用级,对比的对象从一段文字,扩展到一个页面、再到AI眼中的你——三层串起来,正好是一套从字面到机器视角的差异诊断思路。
常见问题解答
文本差异对比器用的是什么算法?
用的是LCS(最长公共子序列)加动态规划,这是diff类工具的经典做法。它先找出两段文本里顺序一致、长度最长的公共部分,公共部分就是“没变的”,左边独有的是“被删的”,右边独有的是“新增的”。具体实现上分两层:先在行级别判断每行是相同、删除、插入还是修改,再对修改的行做一次词级别的LCS,标出具体改了哪几个词。要注意,它用的是教科书版标准LCS,不是Git那种Myers优化算法,两者解决同一问题但实现路子不同,标准LCS对日常几百到几千行的文本对比足够用。
它给的相似度百分比准吗?该怎么理解?
这个相似度是个工程化的简化指标,算法是“未改动行数乘以二,除以左右行数之和”。它反映的是行级别的重合程度,不是字符级的精细相似度,也不是Jaccard或编辑距离那种学术定义。所以理解它要有分寸:如果你把每行都只改一个字,行级上全算“修改”,相似度会显得很低,但其实内容大部分没变。把它当成“改动规模的快速参考”就好——相似度高说明动得少,低说明动得多,至于具体细节,还得切到并排视图逐行看高亮才准。
忽略空白和忽略大小写,会改我的原文吗?
不会。这些忽略选项只作用在“比对判断”这个环节——勾上忽略大小写,工具在判断两行是否相同时不计较大小写差异;勾上忽略空白,多个连续空格被当成一个来比。但展示给你看的,始终是原始内容,工具不会偷偷把你的文本改写或格式化。这个设计很重要:它让你能在不破坏原文的前提下,过滤掉那些你不关心的差异(比如纯粹的缩进调整),只盯实质改动。换行符永远不会被忽略,因为它定义了行的边界。
它能用来查文章是不是抄袭的吗?
不能,这是常见的误解。它只对比你手动贴进去的这两段文本,告诉你它们之间有什么差异,它不会、也没法去全网搜索你的内容有没有被别人抄、或你有没有抄别人。查抄袭、查全网重复是查重工具(比如各类原创度检测)的活儿,它们背后是庞大的网页索引和比对系统。文本差异对比器是个“两段文本之间”的工具,不是“一段文本对全网”的工具。它能帮你做的,是站内两个页面之间的重复自查——把你怀疑重复的两页拿来比,看重合多少,这它在行。
对比超长的文本会有问题吗?
会变慢。因为标准LCS动态规划的计算量跟两段文本的长度乘积相关,文本越长,要填的矩阵越大,耗时和内存涨得很快。一般建议单边不超过五千行,在这个范围内体验是流畅的。如果你要比对的是超大文件(比如几万行的日志、整个数据库导出),更适合用本地安装的专业diff工具(很多用的是Myers这类对大文件更友好的算法)。日常对比文章、产品描述、配置片段这类几百到几千行的内容,这个在线工具完全胜任,不用担心。
权威参考资料
本文标题:《文本差异对比器怎么用?逐行逐词揪出两版内容改了哪里》
本文链接:https://zhangwenbao.com/text-diff-lcs-line-word-comparison-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0