AI概览对比器怎么用?把你的内容和AI概览的回答比出差距
本文目录
- AI概览对比器到底是什么?解决什么问题
- 它怎么用?你要喂给它哪两样东西
- 它是纯规则引擎,还是真的调用了AI?
- 综合匹配度是怎么算出来的?四个维度加权
- 主题覆盖率:为什么权重最高?
- 数据覆盖率:AI为什么爱引用带数字的内容
- 实体覆盖率:品牌、产品、机构这些专名
- 语义相似度用的是什么算法?
- 它还会分析AI回答的格式吗?
- 已覆盖、缺失、独有,这三类话题怎么用?
- 它怎么识别你的查询意图?
- 不同意图,AI偏好什么格式的回答?
- 评分多少算好?那些基准值靠谱吗?
- AI概览到底是什么?它从哪取内容?
- 优化能上AI概览吗?Google官方怎么说?
- GEO研究怎么看“让内容更易被引用”?
- 它怎么从一堆文字里抽出“话题”的?
- 主题都覆盖了,分却不高,可能是哪出了问题?
- 怎么用它做一次完整的差距诊断?
- SEO场景一:定位你和AI回答的内容缺口
- SEO场景二:竞品凭什么被引用,你为什么没有
- 它做不到的几件事,必须心里有数
- 实战案例:无人机出海站的AI概览缺口补全
- 对比三件套:AI引用级是最高一层
- 常见问题解答
- AI概览对比器是真的调用AI来打分的吗?
- 综合匹配度的那套权重是Google官方的吗?
- 做了优化就能上AI概览吗?
- 它的“语义相似度”是真的理解意思吗?
- AI概览每次都不一样,那比对还有意义吗?
- 权威参考资料
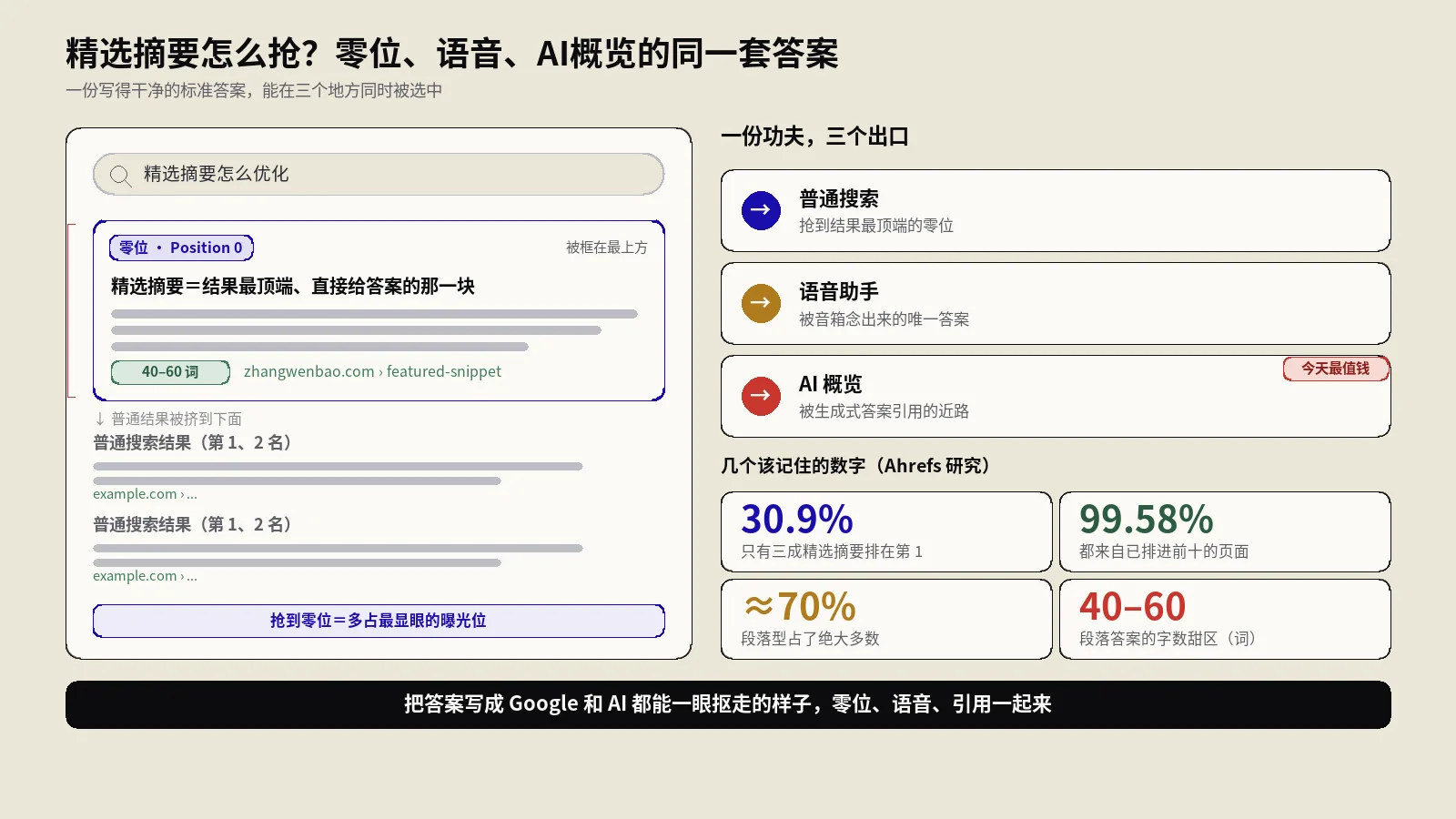
摘要:你搜一个词,Google顶部那段AI概览(AI Overviews)引用了别人的内容,却没引你的——你的页面到底差在哪?这篇用一个AI概览对比器当例子,讲清它怎么把“你的页面内容”和“AI概览给出的回答”摆在一起,从主题、数据、实体、语义四个维度算出一个综合匹配度,再把话题拆成“你已覆盖的、你缺失的、你独有的”三类,精准告诉你缺口在哪。同时把最关键的诚实边界讲透:它是个纯规则引擎,不调用任何AI或Google的接口,所有打分都是本地的正则匹配和文本计算,那些权重和基准分都是工程化设定而非官方标准——它给的是可量化、可重复的差距诊断,不是能不能被AI引用的概率预测。再结合Google官方对AI概览的说法和GEO研究,帮你把这工具用在刀刃上。
做SEO的这两年,都被同一件事搅得睡不好觉:你搜一个本该属于你的关键词,Google结果顶部弹出一段AI概览,洋洋洒洒把答案总结好了,下面挂着几个来源链接——偏偏没有你。明明你那篇文章写得不差,凭什么被引用的是别人?你的内容到底缺了哪一块,让AI觉得它“不够格”被拿来当答案?
光靠瞎猜没用。比较靠谱的办法,是把“AI概览实际给出的那段回答”和“你自己页面的内容”摆到一起,一项一项地比:AI提到的话题你覆盖了吗?AI引用的数据你有吗?AI点名的那些品牌、概念你写到了吗?这正是AI概览对比器要干的活儿。这篇就用一个AI概览对比器当例子,把它怎么比、按什么算分、又有哪些必须警惕的边界,掰开揉碎讲清楚。
AI概览对比器到底是什么?解决什么问题
它的定位很明确:一个帮你找出“自己内容”和“AI概览回答”之间差距的诊断工具。你把两样东西喂给它——你的页面内容、以及Google针对同一个查询给出的AI概览回答——它就帮你逐维度比对,输出一个综合匹配度,外加详细的缺口清单。
它要解决的核心问题,是把“为什么没被AI引用”这个模糊的焦虑,变成一份具体、可操作的差距报告。在AI概览成为越来越多搜索的“第一屏答案”之后,能不能被它引用,直接关系到你的内容还能不能被人看见。而要被引用,前提是你的内容得“接得住”AI想要的那些信息点。这工具就是帮你照出“你接住了哪些、漏了哪些”的镜子。
它怎么用?你要喂给它哪两样东西
用法上,它需要你提供两份核心输入,外加一个可选项。第一份是你的页面内容:可以是HTML源码,也可以是纯文本,就是你想去争取AI引用的那篇内容。第二份是AI概览的回答:你针对目标查询,在Google上实际看到的那段AI概览总结文字,复制下来贴进去。
可选的第三项是查询词本身——你填上它,工具能顺带帮你判断这个查询是什么意图类型,给出更贴合的格式建议。喂进去之后,它就开始干活:从两份文本里分别抽取话题、数据、实体,做语义比对,最后算出各项指标和缺口。整个过程你不用懂算法,但懂了算法你才知道它给的数字该怎么读——这正是下面要讲的。
它是纯规则引擎,还是真的调用了AI?
这是用这工具前必须搞清的头等大事,关系到你该怎么看待它给的每一个数字。答案是:它是个纯规则引擎,不调用任何AI模型,也不调用Google的任何接口。
它做的所有事——从文本里抽话题、识别数据、认出品牌实体、算语义相似度——全部是在本地用正则表达式匹配和文本计算完成的,零外部接口依赖。这意味着两件事。好的一面:它快、稳、可重复,同样的输入永远给同样的结果,不受网络和接口波动影响,也不花接口费用。要警惕的一面:它不是真的“问了AI”,它给的匹配度不是“AI会不会引用你的概率”,而是“按一套预设规则,你的内容和这段AI回答在字面上的重合程度”。把这条记牢,你就不会把它的分数误当成命运判决。
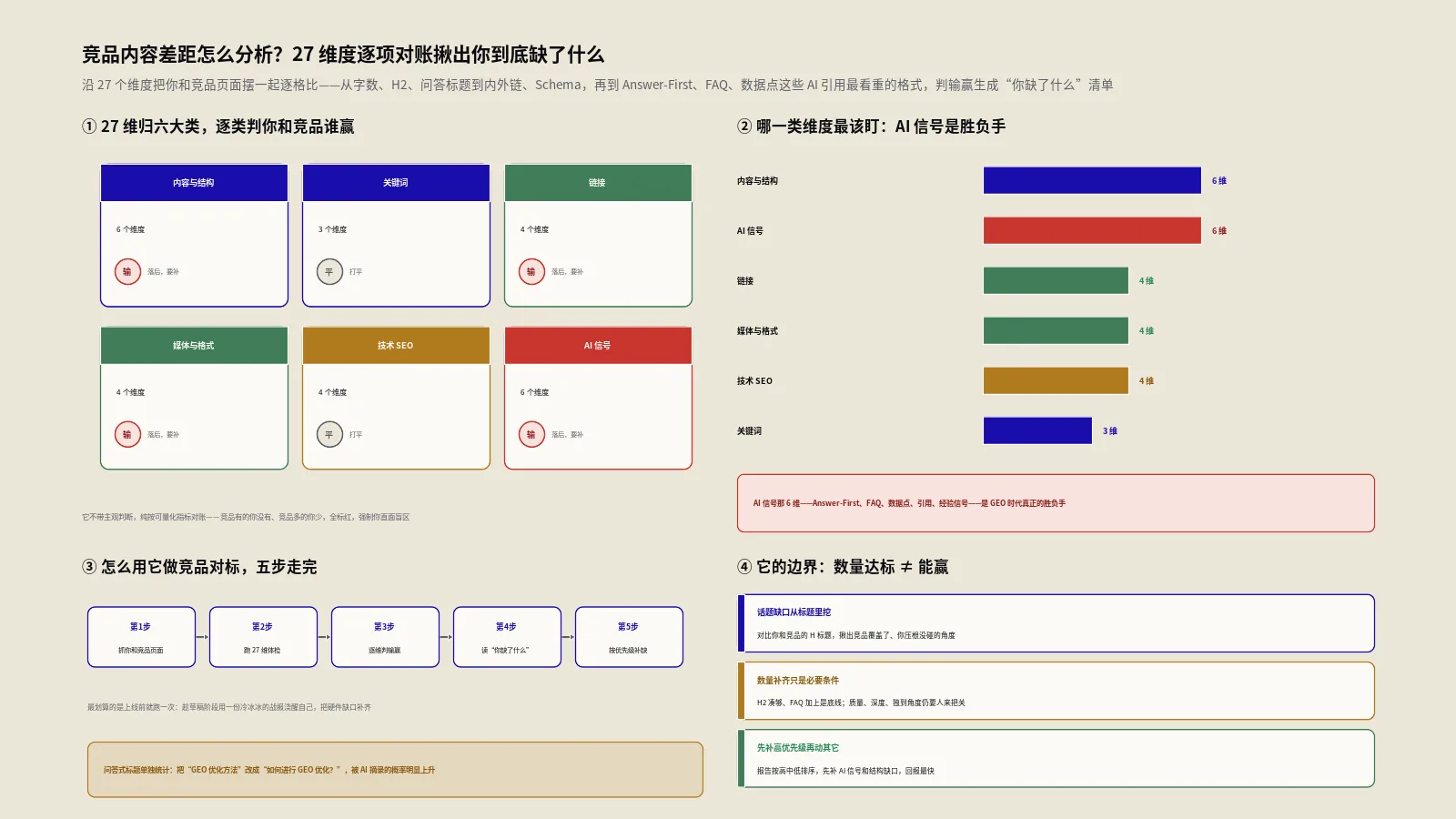
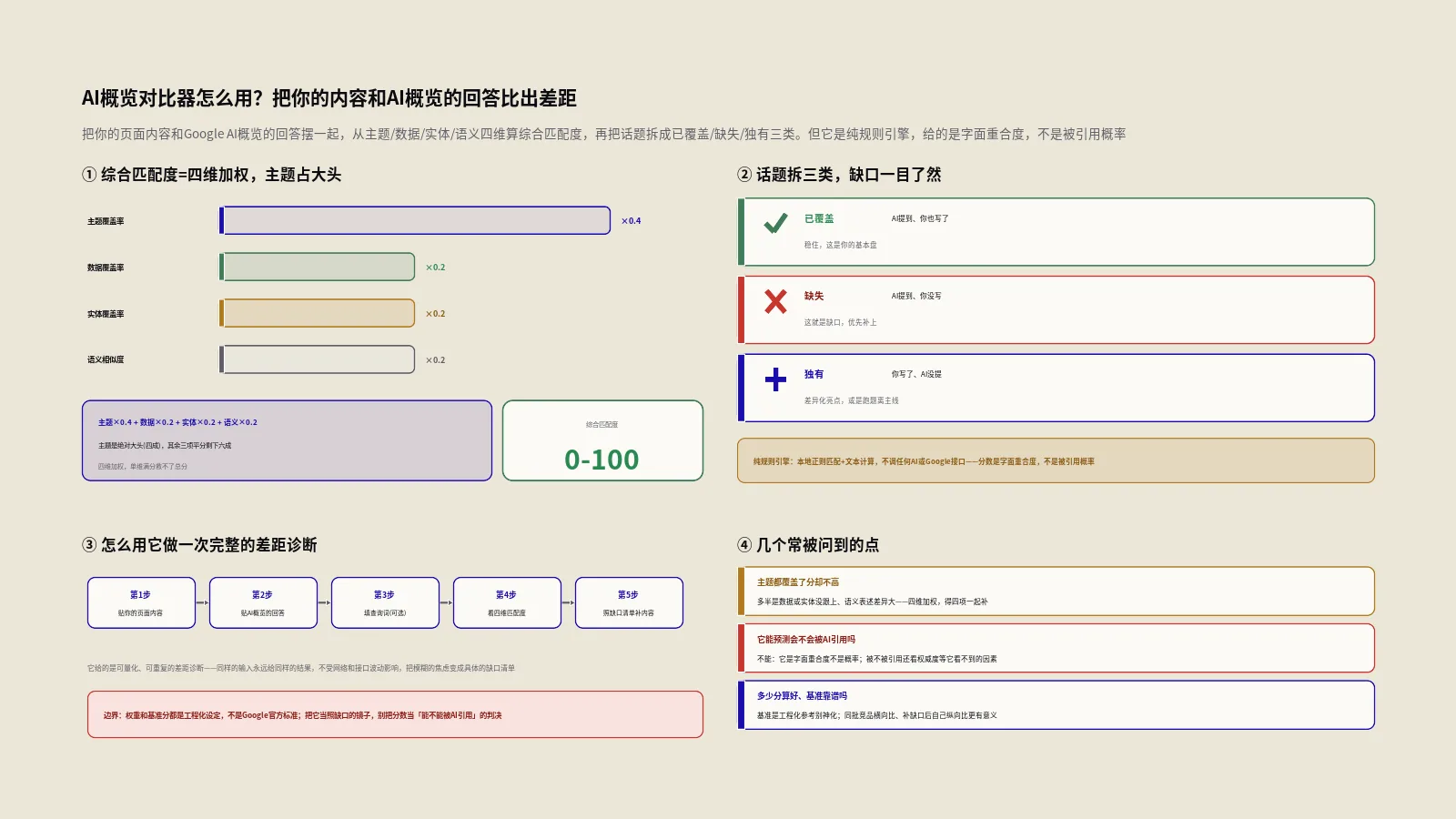
综合匹配度是怎么算出来的?四个维度加权
报告里最显眼的数字是综合匹配度(0到100分)。它不是拍脑袋给的,而是四个维度按权重加起来的,这套公式值得记住。综合匹配度等于:主题覆盖率乘以0.4,加数据覆盖率乘以0.2,加实体覆盖率乘以0.2,加语义相似度乘以0.2。
翻译成人话:主题覆盖占四成、数据覆盖占两成、实体覆盖占两成、语义相似占两成。主题是绝对的大头,其余三项平分剩下的六成。这里要诚实说明:这套0.4加0.2加0.2加0.2的权重,是工具基于GEO优化经验定的工程化设定,不是Google公布的官方权重——Google从没说过“主题占四成”这种话。它体现的是一个合理假设:在“能不能被引用”这件事上,你有没有覆盖到AI回答的核心话题,比其他因素更重要。把它当成一个有道理的相对刻度,而不是物理定律。
主题覆盖率:为什么权重最高?
主题覆盖率是四维里权重最高的,算法是:AI回答里提到的核心话题,你的内容覆盖了多少个,除以AI提到的话题总数。比如AI回答里提炼出20个关键话题,你的内容覆盖了17个,主题覆盖率就是85%。
这里有个聪明的细节——它判断“你有没有覆盖某个话题”不是要求一字不差,而是设了个部分匹配的门槛:一个话题短语,只要它里面的词有六成在你内容里出现,就算覆盖。比如一个五个词的短语,你写到了其中三个(三除以五等于零点六),就算你覆盖了这个话题。这个六成的阈值同样是工程化设定,目的是更贴近真实——表达同一个意思,用词不会完全一样,卡得太死会把本来覆盖了的判成没覆盖。
主题权重最高的逻辑也好理解:AI概览本质是在“总结某个话题”,你要被它引用,首先你得真的在谈这个话题、谈全了它的几个核心面,这是入场券。
数据覆盖率:AI为什么爱引用带数字的内容
第二个维度是数据覆盖率,权重两成。它专门盯一类东西:统计数据、百分比、金额、数量、年份这些“硬信息”。算法是看AI回答里出现的这些数据,你的内容里包含了多少。
它靠正则识别各种数据形态——带百分号的比例、带万亿千百倍这类单位的数量、带货币符号的金额、四位数的年份等等,中英文都认。为什么单独把数据拎出来当一个维度?因为带具体数字的内容,天然更“可信、可引用”。AI在生成回答时,倾向于引用那些有据可查的事实性陈述,而数字正是事实性的最强信号。一句“转化率显著提升”和一句“转化率提升了32%”,后者被引用的分量明显更重。所以如果对比下来你的数据覆盖率低,往往意味着你的内容偏空泛、缺乏具体数字支撑——这是个很实用的优化提示。
实体覆盖率:品牌、产品、机构这些专名
第三个维度是实体覆盖率,权重也是两成。“实体”指的是有名有姓的具体对象:品牌、产品、机构、人物、模型名称等。算法是比对AI回答里点到的实体,你的内容覆盖了多少。
工具内置了一份几十个常见实体的识别清单(涵盖主流的科技公司、AI模型、平台、学术机构等),同时还能用正则识别中文机构名(带“公司、大学、学院、集团、平台、系统、模型”等后缀的)和版本号、型号这类模式。为什么实体重要?因为AI回答一个话题时,常会提到这个领域里的关键参与者和具体对象——你要在这个话题上显得权威、信息完整,就得把相关的关键实体也覆盖到。如果AI回答里反复出现某几个品牌或概念,你的内容里却只字未提,那在“信息完整度”上你就输了一截,被引用的可能自然就低。
语义相似度用的是什么算法?
第四个维度是语义相似度,权重两成,用的算法是Jaccard相似度。它把两份文本都拆成词的集合,算“两个集合的交集,除以它们的并集”,得到一个比例。交集越大、并集里独有的越少,相似度越高。
计算前它会做点预处理——统一转小写、过滤掉“的、了、是、the、and”这类没有实义的停用词,中英文都支持。这里要厘清一个容易误会的点:它叫“语义相似度”,但本质是词集合的重合度,并不是真正理解了“意思”的那种深层语义。两段用词高度重叠的文本,它算出来相似度高;用词不同但意思一样(比如“番茄”和“西红柿”)的,它认不出来。所以这个维度反映的是“你和AI回答在用词层面有多接近”,是个有用的粗粒度参考,别把它当成真正的语义理解。这也是为什么它只占两成权重而非更高。
它还会分析AI回答的格式吗?
会,而且这是个常被忽略但很有用的功能。除了比内容,它还会识别AI那段回答用的是什么格式结构,因为格式本身就是被引用的一个信号。它能认出几类典型格式。
编号列表:一二三这样带序号的。要点列表:用项目符号罗列的。定义型:“某某是指、是一种”这样下定义的。步骤型:“首先、其次、然后”这样讲流程的。对比型:“相比、区别、优劣”这样做比较的。它识别出AI回答用了哪种格式后,会顺带检查你的内容里有没有对应的结构化标签(列表、表格等)。
这个分析的价值在于:如果AI回答是用列表组织的,而你的内容是一大段没有任何结构的文字,那即便你内容都覆盖了,组织形式上也“不投AI所好”——AI更容易从结构清晰的内容里提取答案。这给了你一个超越“写什么”的优化方向:还要注意“怎么排版”。
已覆盖、缺失、独有,这三类话题怎么用?
这工具最实用的产出,不是那个综合分,而是它把话题分成的三类清单。已覆盖:AI提到了,你的内容也有——这是你的基本盘,守住。缺失:AI提到了,你却没有——这是你最该补的缺口,是优化的第一优先级。
独有:你有,但AI这次回答没提——这类要分两面看。一方面,它可能是你的差异化优势、你比AI回答更深入的地方,值得保留甚至强化;另一方面,如果某些“独有”内容跟用户查询的核心关系不大,那它们可能在稀释你内容的焦点,让AI更难判断你在精准回答这个问题。所以拿到三类清单,最高效的动作是:照着“缺失”清单一条条补齐你漏掉的核心信息,同时审视“独有”清单里哪些是真优势、哪些是该删的噪声。这比盯着那个综合分纠结有用得多——分数是结果,清单才是抓手。
它怎么识别你的查询意图?
如果你填了查询词,工具会顺带判断这个查询属于什么意图类型,靠的是正则匹配查询里的关键词。它分了几类。定义型:带“什么、是什么、定义”这类词的,用户想知道“某东西是什么”。
教程型:带“如何、怎么、方法、步骤”的,用户想知道“怎么做”。对比型:带“对比、区别、哪个好、vs”的,用户想做比较。推荐型:带“最好、推荐、排名、top”的,用户想要选择建议。其余归为通用信息型。识别意图不是为了好看,而是为了给出更对路的格式建议——这就引出下一节。
不同意图,AI偏好什么格式的回答?
识别出意图后,工具会据此建议你的内容该用什么结构来组织,因为不同意图的查询,AI概览偏爱的回答形态确实不同。定义型查询:最适合“答案前置”——开头第一句话就把定义讲清楚,别绕弯子,AI最爱直接摘第一句。
教程型查询:适合清晰的操作步骤列表,一二三四列出来。对比型查询:适合结构化的对比表格,把几个对象的各维度并排列清。推荐型查询:适合带评价依据的排名列表,不光给排名还说为什么。通用信息型:适合全面覆盖加权威引用。这套建议背后的逻辑是:AI从你内容里“抠答案”时,结构越贴合查询意图,它越容易抠得准、抠得全。所以优化不只是补内容,还要按查询意图调整内容的组织形式——查询问“怎么做”,你就别用一大段散文,改成步骤列表。
评分多少算好?那些基准值靠谱吗?
工具会给一些参考基准,比如“综合匹配度80分以上算优秀”“被AI频繁引用的内容平均匹配度约72分、主题覆盖率约85%”。这些数字看着很权威,但必须诚实地给它们“祛魅”。
这些基准全部是工程化经验值,来自工具团队对内容样本的观察分析,不是Google官方数据,更不存在“到了72分就会被引用”这种因果关系。Google从未公布过任何“被引用的内容匹配度多少”的指标——事实上以Google对AI概览机制的一贯说法,根本不存在这样一个可量化的官方门槛。所以正确的用法是:把这些基准当成“相对参照”,用来横向比较——比如对比你的几个页面、或对比你和竞品,看谁的缺口更小。别把它当成绝对的及格线,更别因为“差几分到80”就焦虑。这工具的价值在“找差距”,不在“算概率”。
AI概览到底是什么?它从哪取内容?
要用好这工具,得先搞清它要对标的那个东西——AI概览——本身是怎么回事。根据Google搜索中心关于AI功能与你的网站的文档,AI概览是Google在搜索结果里给出的摘要式回答,帮用户快速抓住一个复杂话题的要点,同时提供链接让用户深入了解。
关键的一点是它怎么取内容。文档提到,AI概览和AI模式可能使用一种叫“查询扇出(query fan-out)”的技术——针对你的一个搜索,它在背后拆成多个相关的子搜索、跨多个子话题和数据源去找信息,再综合成一段回答。这意味着AI概览引用的,往往不是单一某篇文章,而是从多个来源里各取所需拼出来的。对你的启示是:你不需要一篇文章覆盖所有,但你那篇得在它的某个子话题上足够强、足够完整,才能成为那个“被取用”的来源之一。这也正是对比器帮你做的事——看你在这个话题上够不够完整。
优化能上AI概览吗?Google官方怎么说?
这是所有人最关心的问题,得听听Google官方的明确表态,别被各种“AI概览秘籍”带偏。根据Google搜索中心的生成式AI功能优化指南,Google说得很直白:想出现在AI概览或AI模式里,没有额外的特殊要求,也不需要什么专门的优化。
因为Google搜索里的生成式AI功能,根植于它核心的搜索排名和质量系统——一句话,“AI搜索本质上还是搜索”。你为普通搜索做的那些基础功夫照样管用:满足技术要求、遵守政策、专注于创作对人有用、可靠、以人为本的内容。这话对理解这个对比工具非常重要:它不是一套“钻AI空子”的特殊技巧,它本质上是在帮你把内容做得更完整、更有数据、更结构化——而这些恰恰是“好内容”的通用标准。换句话说,用对比器补齐缺口,方向上跟Google的官方建议是一致的,不是投机取巧。
GEO研究怎么看“让内容更易被引用”?
学术界对“怎么让内容更容易被生成式引擎引用”也有系统研究,给这工具的思路提供了理论背书。最有代表性的是普林斯顿等机构提出的GEO(生成式引擎优化)框架,论文《GEO: Generative Engine Optimization》系统研究了这个问题。
这篇发表在KDD 2024的论文,把“优化内容在生成式引擎里的可见度”当成一个可研究的新课题,测试了多种内容调整手法对“被引用”的影响——比如增加引用来源、加入统计数据、引述权威观点等,发现这些手法确实能明显提高内容被生成式引擎采纳的概率。
这正好和对比器盯的几个维度对上了:数据覆盖(加数字)、实体覆盖(点名权威)、主题完整——这些不是工具拍脑袋选的维度,而是有研究支撑的、真正影响“可引用性”的因素。理解了这层,你就明白对比器为什么盯这几样:它把GEO研究里被验证有效的方向,做成了一把可量化的尺子。
它怎么从一堆文字里抽出“话题”的?
主题覆盖率是核心维度,那它怎么从AI回答和你的内容里识别出一个个“话题”的?这背后是一套朴素但有效的关键短语提取逻辑,了解它能帮你理解为什么有时候识别得准、有时候会有偏差。
对中文,它提取的是连续的、长度适中(大致两到八个字)的字段;对英文,它倾向于抓那些首字母大写的多词短语(这类往往是专有概念或关键术语)。抽出一堆候选后,它按出现频率排序,取最高频的那一批(一般是前三十个左右)当作这段文本的核心话题。
这套方法的好处是快、不依赖任何外部词库;局限是它认的是“字面上的高频片段”,不是真正理解了语义的主题——所以偶尔会把一些高频但不那么核心的词组也算进来。理解这点你就明白:它给的话题清单是个很好的起点,但你最终还得用自己的判断,去甄别哪些“缺失话题”是真该补的核心、哪些只是噪声。
主题都覆盖了,分却不高,可能是哪出了问题?
实际用的时候,常会遇到一个让人困惑的情况:明明三类话题清单显示你“缺失”的不多、主题覆盖率不低,综合匹配度却还是上不去。这往往是其余三个维度在拖后腿,正好提醒你别只盯主题这一项。
最常见的拖累是数据覆盖率低。你把话题都谈到了,但谈得空泛、没有具体数字,而AI回答里全是实打实的数据——这种“话说到了但没数据撑”的内容,匹配度自然高不了。其次是实体覆盖不足:AI回答反复点到的某几个关键品牌、概念、规格名词,你一个没提,信息完整度上就丢分。还有语义相似度低,可能是你和AI回答虽然谈的是同一话题,但用词体系差得远。
遇到分数上不去,正确的排查顺序是:先确认缺失话题补没补,再依次看数据够不够具体、关键实体全不全、用词贴不贴近。把四个维度当成一套体检指标,哪项弱补哪项,比死磕总分高效得多。
怎么用它做一次完整的差距诊断?
把它用出效果,按这套流程走最稳。
- 选定目标查询、拿到AI概览原文。挑一个对你重要、且确实会触发AI概览的查询,在Google上搜一下,把顶部AI概览那段回答完整复制下来。
- 准备你的对标内容。把你想去争取这个查询引用的那篇页面内容(纯文本或HTML)准备好,连同查询词一起喂给工具。
- 先看三类话题清单,别先看分。重点看“缺失”清单——这是AI提到、你却没覆盖的核心话题,是你优化的第一优先级。
- 对照四个维度找薄弱项。看是主题没覆盖全、还是数据太少、还是关键实体没提、还是格式不对路,定位你最该补的那一两块。
- 按意图建议调整结构,补齐后复测。照着工具给的格式建议(定义型就答案前置、教程型就用步骤列表)重组内容,补齐缺失话题和数据,改完再跑一次看缺口缩小了没。
这套流程的核心是“以缺口清单为纲、以维度诊断为目”——清单告诉你补什么,维度告诉你怎么补,复测告诉你补得对不对。
SEO场景一:定位你和AI回答的内容缺口
最直接的用法,就是给一篇没能被AI概览引用的内容做体检,找出它和“标准答案”的差距。你心里大概知道这篇该被引用,但就是没有,又说不清差在哪——对比一跑,缺口清单一摆,立马清楚。
常见的诊断结果有几类:主题覆盖低,说明AI回答涉及的几个核心面你没谈全,得补;数据覆盖低,说明你内容偏空泛、缺具体数字,得加数据;某个反复出现的关键实体你没提,得补上。把这些缺口一条条补齐,你的内容在“完整度”上就追上了AI想要的标准。这比闷头重写整篇高效得多——你只补真正缺的那几块。
SEO场景二:竞品凭什么被引用,你为什么没有
第二个进阶用法,是借它做竞品逆向分析。AI概览下面通常挂着它引用的来源链接,那些就是“被选中”的内容。你可以把竞品被引用的那篇内容找来,和AI回答比一遍,看它的匹配度、它的缺口;再把你自己的内容也比一遍。两份报告一对照,竞品强在哪、你弱在哪,清清楚楚。
这种对照常能给你意外的发现:可能竞品的内容并不比你写得好,但它的数据更具体、关键实体更全、结构更贴合查询意图——这些“可引用性”上的细节,正是它被选中而你被忽略的原因。找到这些差距,你的优化就有了明确靶子,不再是凭感觉。需要说明,这工具比的是“内容对AI回答”的差距,如果你想更进一步模拟“多个AI引擎分别会不会引用你”,那是另一类工具的活儿,可以看我们拆过的AI搜索问答模拟器的方法。
它做不到的几件事,必须心里有数
用好它,边界得拎得清,否则容易被数字误导。第一,也是最根本的——它不调用真实的AI或Google接口。它给的匹配度不是“AI会不会引用你的概率”,而是“按预设规则,你的内容和这段AI回答的字面重合度”。它预测不了真实的引用结果,只能量化“内容差距”。
第二,它的权重(主题四成等)和基准分(72分、85%)都是工程化设定,是相对刻度,不是Google官方标准——别把它们当绝对门槛。第三,它的“语义相似度”是词集合重合度,不是真正的语义理解,认不出同义改写。
第四,AI概览本身是动态的、个性化的——同一个查询不同时间、不同用户看到的回答都可能不同,你比对的只是你这次抓到的那一份快照。第五,它只比你给的这两份文本,不会自动去抓AI概览、也不会自动找竞品内容,这些得你手动准备。把这五条记牢:它是个把“内容差距”量化的诊断尺,不是预测AI行为的水晶球。
实战案例:无人机出海站的AI概览缺口补全
我们团队去年帮一个做消费级无人机的出海站做过一轮AI概览优化,很能说明这工具怎么落地。这站卖航拍无人机、配件、电池,做了不少“怎么选无人机”“无人机航拍入门”这类知识内容,想去争取相关查询的AI概览引用。客户的困惑很典型:内容写了一堆,AI概览就是不引他们的,引的全是几个老牌科技媒体。
我们挑了几个核心查询,把Google的AI概览回答和他们的对应文章逐一用对比器比。结果缺口很清晰:主题覆盖上还行,但数据覆盖率普遍偏低——他们的内容大量是“续航久、画质清晰、操作简单”这种定性描述,而AI回答里全是“续航35分钟、4K录制、有效遥控距离10公里”这种具体数字。实体覆盖也有缺口,AI回答里会提到几个关键的技术规格名词和认证标准,他们没怎么写。格式上,AI对“怎么选”这类查询给的是要点列表,他们却是大段散文。
诊断清楚后,优化方向就明确了:把定性描述全部换成具体参数(每个卖点都配上确切数字)、补上缺失的技术规格和认证名词、把选购类内容改成清晰的要点列表加对比表格。改完再用对比器复测,缺口明显缩小,综合匹配度上去了。过了一段时间,他们有几篇内容开始出现在相关查询的AI概览来源里了。
这个案例的要点是:对比器的价值不在它给的那个分数,而在它精准指出了“数据太空、实体不全、格式不对”这三个具体缺口——顺着缺口补,比闷头重写有效得多。这也呼应了GEO研究的发现:加数据、点权威、对结构,确实是提升可引用性的实在功夫。
对比三件套:AI引用级是最高一层
把AI概览对比放进更大的图景,它是“对比”这件事里最高的一层——比的是你的内容和AI眼中“标准答案”的差距。这套对比思路一共三层,由浅入深。
第一层是文本级:两段纯文字之间的字面差异,比如改版前后、原稿与洗稿,可以看我们拆过的文本差异对比器的方法。第二层是页面渲染级:搜索引擎爬虫看到的页面,和真实用户看到的差在哪,关系到JS渲染丢内容和隐藏作弊,可以看渲染对比器的方法。第三层就是本文这个AI引用级,比的是AI概览的回答和你内容之间的缺口。
文本、页面、AI回答——对比的对象一层层抬升,从一段文字,到一个页面在机器眼里的样子,再到AI总结出的标准答案与你的差距。三层串起来,正好是一套从字面、到机器视角、再到AI视角的完整差异诊断框架,覆盖了SEO进入GEO时代你需要的三把对比尺。
常见问题解答
AI概览对比器是真的调用AI来打分的吗?
不是,它是个纯规则引擎,不调用任何AI模型,也不调用Google接口。它抽话题、识别数据、认实体、算语义相似度,全部是本地用正则匹配和文本计算完成的。所以它给的综合匹配度,不是“AI会不会引用你的概率”,而是“按一套预设规则,你的内容和这段AI回答在字面上的重合程度”。好处是快、稳、可重复、不花接口费;要警惕的是别把它的分数当成命运判决。它的真实价值在于用一套可量化、可重复的维度,帮你照出内容和AI回答的差距在哪,而不是预测AI的真实行为。理解这条,才能正确使用它给的每一个数字。
综合匹配度的那套权重是Google官方的吗?
不是。综合匹配度是主题覆盖乘0.4、数据覆盖乘0.2、实体覆盖乘0.2、语义相似乘0.2加起来的,这套权重是工具基于GEO优化经验定的工程化设定,Google从没公布过任何这类官方权重。它体现的是一个合理假设——在能不能被引用上,覆盖到AI回答的核心话题比其他因素更重要,所以主题占大头。
同样,那些“80分优秀”“被引用内容平均72分”的基准也都是工程团队的经验值,不是官方门槛,更不存在“到72分就会被引用”的因果。正确用法是把它们当相对参照,用来横向比较你的几个页面或你和竞品,别当绝对及格线。
做了优化就能上AI概览吗?
没有“做了就一定上”这回事,但方向对了能提高机会。Google官方明确说过,想出现在AI概览里没有特殊要求、不需要专门优化,因为AI功能根植于核心搜索的排名和质量系统——AI搜索本质还是搜索。这意味着用对比器补齐缺口(补全话题、加具体数据、补关键实体、调整结构),方向上跟Google建议的“创作有用、可靠、以人为本的内容”是一致的,不是钻空子。所以别把这工具当成上AI概览的保证或秘籍,它是帮你把内容做得更完整、更扎实的诊断手段,而内容扎实本来就是被引用的根本前提。
它的“语义相似度”是真的理解意思吗?
不是真正的语义理解。它的语义相似度用的是Jaccard算法,把两份文本拆成词的集合,算交集除以并集,本质是词集合的重合度。计算前会转小写、过滤停用词。所以它衡量的是“你和AI回答在用词上有多接近”,而不是“意思有多接近”——用词高度重叠它算相似度高,用词不同但意思一样(比如番茄和西红柿)它认不出来。这也是它只占两成权重的原因。理解这点你就不会误读:这个维度是个粗粒度的用词重合参考,别拿它当深层语义判断。要看内容是否真正覆盖了某个意思,还得结合主题覆盖率和你自己的人工判断。
AI概览每次都不一样,那比对还有意义吗?
有意义,但要理解你比的是“快照”。AI概览确实是动态、个性化的——同一个查询,不同时间、不同用户、不同地区看到的回答都可能不同。你用对比器比的,是你这次抓到的那一份AI回答快照。但这不影响它的诊断价值:因为不同版本的AI回答,覆盖的核心话题、引用的数据类型、点到的关键实体往往是相对稳定的,你针对一份有代表性的快照补齐缺口,补的是这个话题下普遍需要的信息,对争取后续各版本的引用都有帮助。
实践中建议:挑一份信息比较完整的AI回答做对标,或者隔段时间多抓几份对比,找出反复出现的核心缺口重点补,比纠结单次差异更实在。
权威参考资料
本文标题:《AI概览对比器怎么用?把你的内容和AI概览的回答比出差距》
本文链接:https://zhangwenbao.com/ai-overview-compare-content-gap-geo-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0