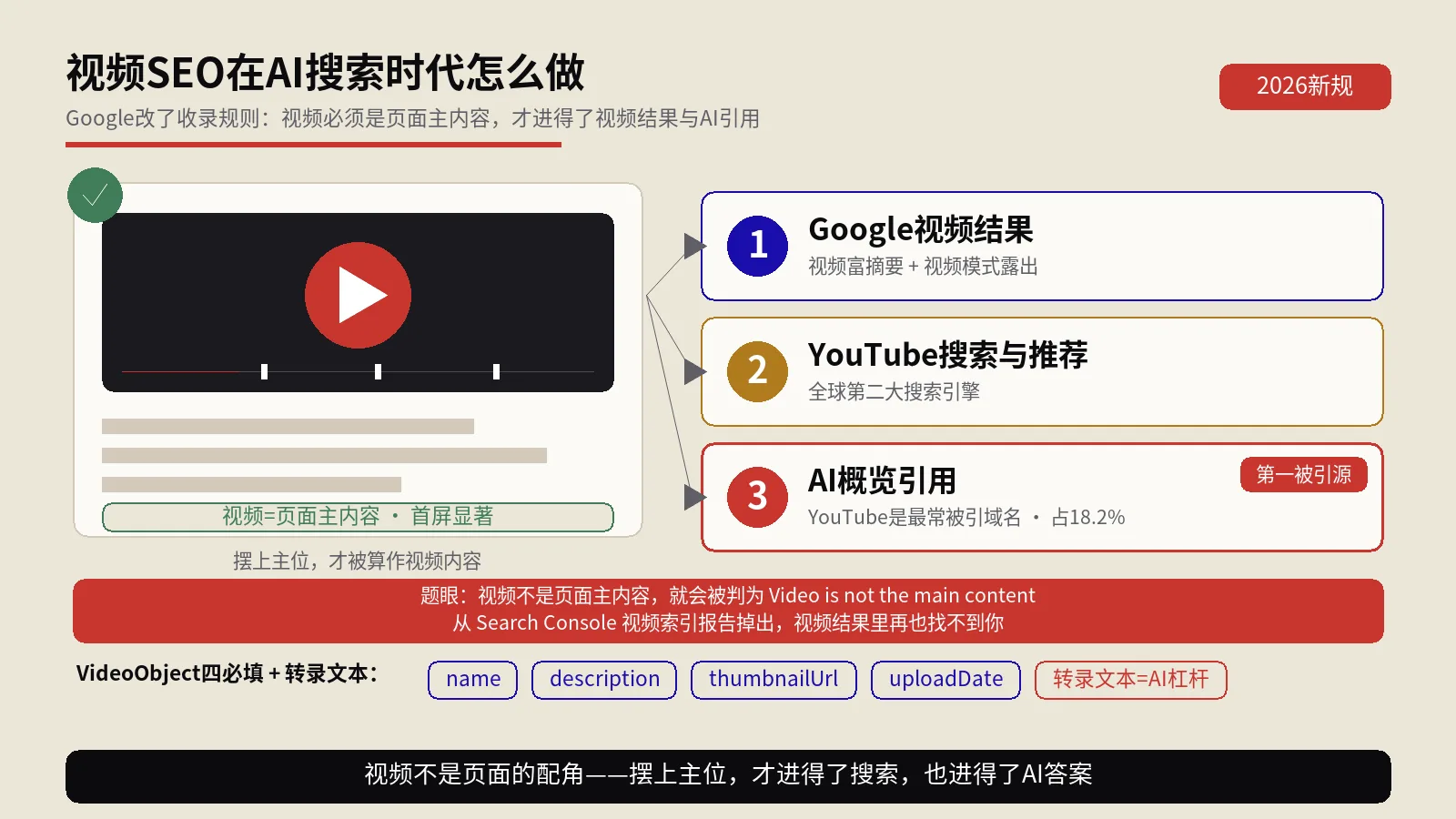
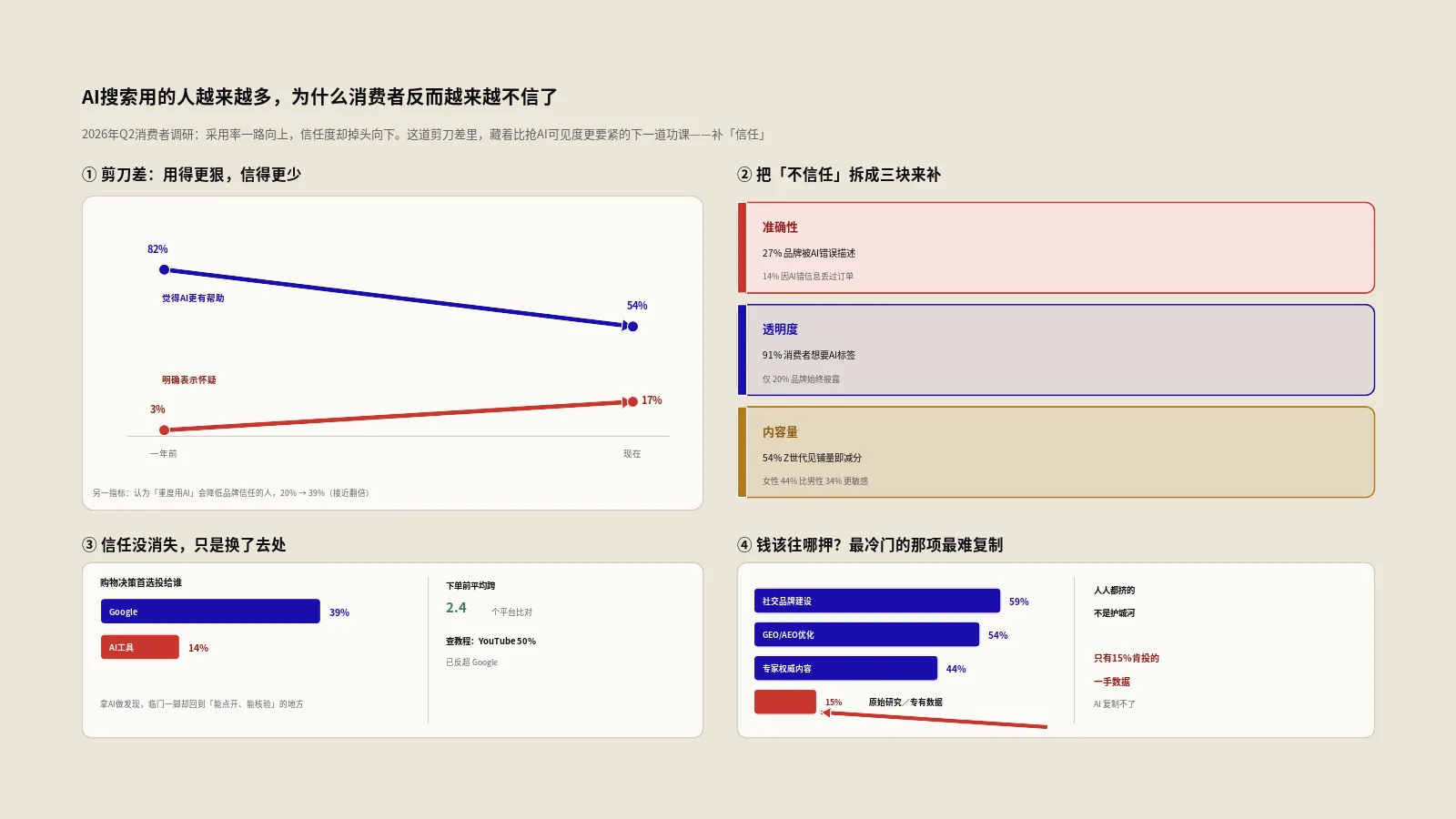
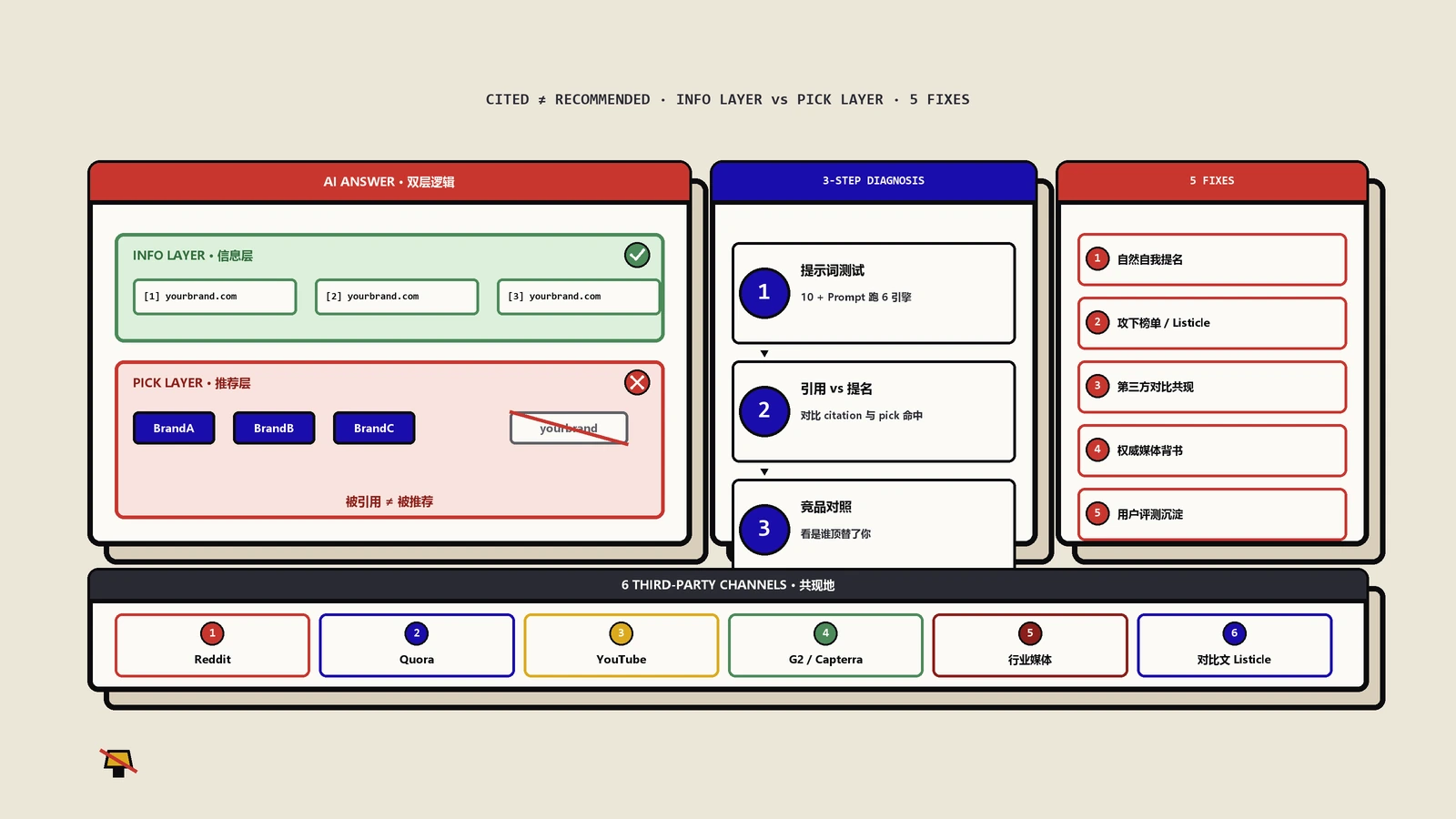
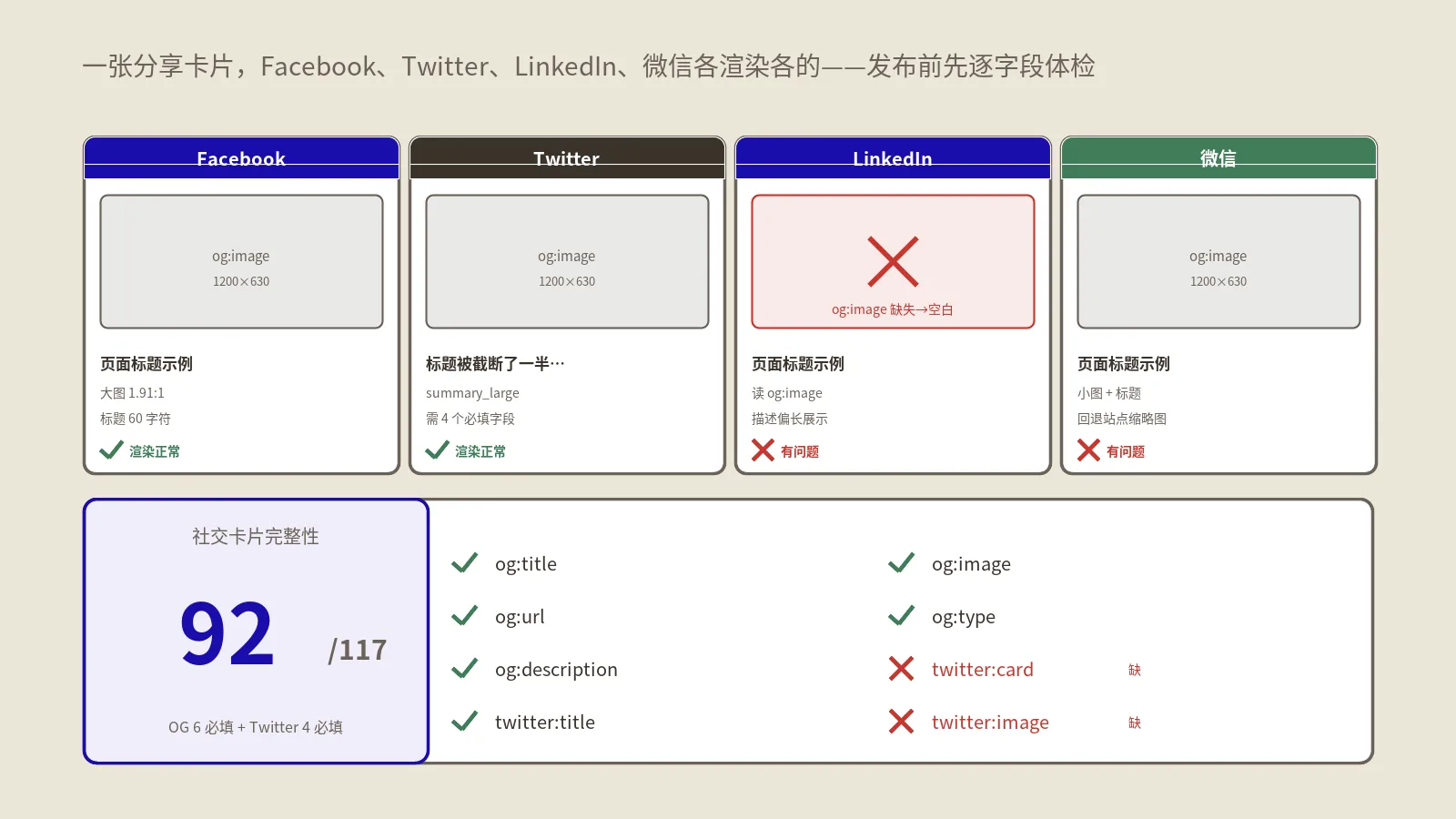
AI搜索问答模拟器怎么用?一份内容跑五引擎体检看清谁愿意引用你

本文目录
- 为什么同一篇内容,五个AI引擎引用你的概率天差地别?
- 这个AI搜索模拟器到底在算什么?
- ChatGPT偏好什么样的内容?
- Perplexity为什么是个“时效控”?
- Google AI Overview最看重的是结构化数据?
- Claude的打分逻辑为什么显得最“挑”?
- Grok吃哪一套?
- 五大引擎的“人格”一张表能看明白吗?
- 工具靠什么判断你的内容命中了哪些信号?
- 数据点是怎么数出来的?
- 它怎么挑出“最可能被引用”的5个句子?
- 关键词密度0.5%到3%是什么讲究?
- 一份内容怎么用这个模拟器做一次完整体检?
- 跑出低分,先改哪里最划算?
- 这些分数和数字,是论文还是工程设定?
- 为什么不该追求五个引擎都满分?
- 模拟器的边界到底在哪?
- 实战案例:珠宝首饰出海站的五引擎体检
- 怎么用五引擎差异反推内容策略?
- 模拟分和真实引用差多少才该担心?
- 常见问题解答
- 这个模拟器的引用概率分准吗,能信几分?
- 五个引擎的分数,我该先盯哪一个?
- 为什么我内容质量很高,某个引擎分却很低?
- 关键词密度一定要卡进0.5%到3%吗?
- 这个工具和真正的GEO效果评测有什么区别?
- 补Schema对哪个引擎帮助最大?
- 权威参考资料
摘要:同一篇内容,被ChatGPT频繁引用,到了Perplexity、Google AI概览却没声音——这不是玄学,而是5个AI引擎各有各的脾气。这篇用一个AI搜索问答模拟器做线索,把ChatGPT、Perplexity、Google AI Overview、Claude、Grok各自的引用偏好拆成可量化的打分项,告诉你每个引擎吃哪一套、工具靠哪些信号判断你命中了没有、哪些数字是工程化刻度、以及怎么用一份内容跑五引擎体检后对症补强,把内容从“只讨好一个引擎”改成“五个引擎都愿意引用”。
做GEO久了会撞上一件怪事:你精心打磨的一篇内容,在ChatGPT里被反复当成答案来源,可换到Perplexity或Google的AI概览里搜同一个问题,回答里压根没有你的影子。第一反应通常是“是不是这篇质量不够”,于是继续加字、加引用、加案例——结果越改越乱,因为病根不在质量,而在于:你把某一个引擎的偏好,默认成了所有AI引擎的通用标准。
AI搜索引擎在生成回答时,并不是平等地对待所有检索到的内容,而是各自挑“最对自己胃口”的片段来引用。胃口由模型本身、训练方式、产品定位共同决定,彼此差得很远。看不清这条边界,多引擎优化就会变成“东补补西补补、哪个引擎都讨好不全”的瞎忙。这篇文章用我们团队常用的一个AI搜索问答模拟器当解剖刀,把五大引擎的引用偏好彻底讲透。
为什么同一篇内容,五个AI引擎引用你的概率天差地别?
先建立一个底层认知:AI搜索的“引用”不是检索排名的简单延续。传统搜索给你排前十条链接,用户自己点;而AI搜索是把检索到的若干篇内容揉碎,挑出它认为最值得复述的句子,组装成一段回答,再标注来源。能不能进那段回答、能不能拿到来源标注,取决于你的内容是否命中了这个引擎的“可引用偏好”。
这套偏好为什么分引擎?举几个直观的例子。ChatGPT背后是偏好长篇、权威、数据扎实内容的模型,它愿意引用一篇结构完整、有作者有日期、数据点充足的深度文;Perplexity定位是“实时答案引擎”,对时效性、Answer-First(开头直接给答案)、多来源验证极其敏感;Google AI Overview长在搜索引擎的地基上,天然吃结构化数据(Schema)和传统排名信号;Claude偏好平衡、严谨、有限定条件的论述,对夸张营销词反而会降权;Grok则盯着时效和热点,喜欢直给的、问答式的回答。
同一篇按ChatGPT脾气写的内容——长、权威、数据多但没标日期、没上Schema——它在ChatGPT里如鱼得水,到了看重时效的Perplexity、看重Schema的Google AI Overview那里,就明显吃亏。这就是为什么“一套内容打天下”在AI搜索时代越来越不灵。
普林斯顿团队那篇GEO(Generative Engine Optimization,arXiv 2311.09735)奠基论文早就用上万条查询验证过:针对生成式引擎做内容优化,被引用的可见度最高能提升约40%,而能拉动这个提升的策略(引用来源、统计数据、Answer-First等)本身就有明确的、可量化的偏好结构。换句话说,引擎偏好不是玄学,是可以拆解、可以量化、可以逐项优化的工程对象。
这个AI搜索模拟器到底在算什么?
把工具的定位说清楚:你给它一个URL或一段内容,再给一个目标搜索关键词,它会输出这篇内容被ChatGPT、Perplexity、Google AI Overview、Claude、Grok这5个引擎引用的概率评分,每个引擎一个0到100分,并给出对应的优化建议。
它的核心不是给你一个笼统的“GEO总分”,而是五个引擎各算各的。每个引擎有一套独立的打分项和权重,工具先按这套权重把你内容命中的信号逐条累加成原始分,再乘以一个引擎专属的放大系数,最后用上限100封顶。公式很朴素:
最终评分 = min(100,round(原始分 × 引擎倍数系数))
五个引擎的倍数系数各不相同:ChatGPT是1.1,Perplexity和Claude是1.15,Google AI Overview和Grok是1.2。系数的作用是把不同引擎的原始分拉到同一个可比的量级上——倍数越高,意味着工具认为这个引擎对“命中信号”的回报更敏感。需要先说清:这些系数是工具作者基于对各引擎公开行为的观察设定的工程化刻度,不是任何官方公布的算法参数。把它当成“相对量级的校准旋钮”即可。
理解了这个框架,你就明白为什么同一篇内容在工具里会跑出五个高低错落的分数:不是工具在瞎给分,而是它在用五套不同的尺子量同一块布。哪把尺子量出来短,就是那个引擎最不待见你的地方。
ChatGPT偏好什么样的内容?
ChatGPT的打分逻辑可以概括成一句话:偏好权威长篇加数据支撑。工具里它的主要加分项是这样分布的。
- 内容充足:正文超过2000字加12分,介于800到2000字之间给6分的部分分。
- 数据支撑:命中3个及以上数据点加10分,至少1个给4分。
- 有引用来源:正文里出现“据……研究/报告”“according to”这类引证表述,加10分。
- 标题含关键词加8分;含清晰定义或解释加8分。
- 有作者信息加5分、有日期标记加5分、含列表结构加5分。
- 结构化数据上,Article Schema加4分、FAQ Schema加5分;外部链接达到2条加4分。
看清这套权重,你就知道怎么“喂”ChatGPT:它不怕长,2000字是它给满内容分的门槛;它特别在意你说话有没有出处和数据;它认作者和日期这类E-E-A-T信号。如果你的内容在ChatGPT这栏分低,八成是字数不够、数据点太少、或者通篇没有一句“根据某某报告”。
Perplexity为什么是个“时效控”?
Perplexity的权重表里,最显眼的一项是日期:有明确的发布或更新日期标记,直接加12分,是它给分最高的单项。这跟它“实时答案引擎”的产品定位完全吻合——它要给用户当下最新的答案,一篇没标时间的内容,在它眼里就是“不知道是不是过期了”的可疑货。
除了时效,Perplexity还重三件事:Answer-First格式(开头直接给定义或答案)加10分、有引用来源加10分、多源验证(外部链接达到3条)加6分。它的逻辑是“答案要新、要有出处、要能被别的来源印证”。Title和H1同时含关键词加8分,只有Title含、H1缺则降到5分——它对标题层级的一致性也很在意。
所以如果你的内容在Perplexity栏分低,先别急着加字,去检查三件事:有没有显眼的更新日期、第一段是不是绕了半天才说到答案、有没有足够的外链做交叉印证。把这三件事补上,Perplexity分往往蹭一下就上去了。
Google AI Overview最看重的是结构化数据?
Google AI Overview长在Google搜索的地基上,所以它的打分项里同时混着“AI偏好”和“传统SEO信号”。结构化数据是它的命门:页面上有Schema加10分、FAQ Schema再加8分、HowTo Schema加6分。这是五个引擎里对Schema最敏感的一个。
除此之外,它还看:标题含关键词加10分、单一H1(H1只有一个)加5分、标题层级完整(至少3个标题)加5分、列表结构加5分、Meta Description完整(至少50字符)加4分。还有一个别处少见的项——关键词密度落在0.5%到3%这个区间加5分,太低显得不相关、太高像堆砌。它对Schema.org定义的FAQPage这类结构化标记尤其友好,因为这是它从传统Google搜索继承下来的、最熟悉的“机器可读”语言。
Google AI Overview这一栏,本质上是在考你的“技术SEO底子”。如果你过去把页面SEO做扎实了——Schema齐全、H标签规范、Meta写全——这一栏天然不会差。反过来,一篇正文写得再好但裸奔(没有任何结构化标记)的内容,在它这里会吃大亏。关于结构化数据怎么校验和补全,可以延伸看我们团队拆过的结构化数据提取与审计方法。
Claude的打分逻辑为什么显得最“挑”?
Claude偏好深度推理、平衡观点、逻辑严谨。它的加分项里,内容深度(超过1500字)加10分、有引用来源加10分、数据支撑(2个以上数据点)加8分、含清晰定义加7分。到这里跟ChatGPT还有点像,但Claude多了几个别人没有的“挑剔”维度。
一是正反面分析:内容里出现优点与缺点、利与弊这种Pros/Cons式的平衡论述,加6分。二是专业资质信号:出现PhD、CFA、“年经验”“资深”“认证”这类专家身份标记,加6分。三是结构层级清晰(至少4个标题)加5分——它要的标题层级比别的引擎都多一层。
Claude的隐藏脾气还在于“反夸张”。虽然这一点更多体现在它的偏好规则而非这个模拟器的加分项里,但理解它有助于你判断分数:一篇通篇“全网最强”“史上最好”的营销文,即便数据再多,Claude也未必买账。要在Claude栏拿高分,得让内容显得克制、平衡、有出处、有边界。这套“挑剔”其实跟人类专业读者的口味高度一致——这也是为什么按Claude标准改过的内容,往往整体可信度都更高。
Grok吃哪一套?
Grok的权重表和Perplexity有点像,都把日期标记放在最高(加12分),体现它对时效和热点的偏好。除此之外,标题匹配加8分、数据支撑加8分、含直接回答加7分、有来源引用加7分、内容深度(1000字以上)加6分、列表结构加5分、问答格式加5分、有Schema加4分。
Grok要的是“新、直、有料”:时效新、答案直给、有数据有出处。它不像ChatGPT那样非要2000字的长篇,1000字就给内容深度分;但它对“绕圈子不给答案”很不耐烦——问答格式、直接回答这两项就是在奖励那些开门见山的内容。如果你的内容在Grok栏低,多半是太啰嗦、没标时间、或者缺少能被直接当答案复述的那一两句话。
五大引擎的“人格”一张表能看明白吗?
把五个引擎的偏好横向摆在一起,差异一目了然。这张对比表是这个工具最有价值的部分——它让“分引擎优化”从一句口号变成可操作的清单。
| 引擎 | 最高加分项 | 核心偏好 | 倍数系数 | 低分时先查 |
|---|---|---|---|---|
| ChatGPT | 内容充足(2000字,+12) | 权威长篇+数据+出处 | 1.1 | 字数、数据点、引用来源 |
| Perplexity | 日期标记(+12) | 时效+Answer-First+多源 | 1.15 | 更新日期、首段答案、外链 |
| Google AI Overview | 标题含关键词/Schema(+10) | 结构化数据+排名信号 | 1.2 | Schema、H标签、Meta |
| Claude | 内容深度/引用(+10) | 深度+平衡+专业资质 | 1.15 | 正反分析、专家信号、克制语气 |
| Grok | 日期标记(+12) | 时效+直接回答+数据 | 1.2 | 时间、直答句、问答结构 |
读这张表的正确姿势不是“五个都拉满”,而是先看你的主战场是哪个引擎。如果你的目标用户主要在用Perplexity做产品调研,那就死磕时效和Answer-First;如果你做的是Google生态里的内容,Schema和H标签的底子最该先夯实。先打透主力引擎,再用这张表的差异去补其他引擎的短板,性价比最高。
工具靠什么判断你的内容命中了哪些信号?
上面那些加分项,工具不是靠读懂你的内容来判断的,而是靠一套双语正则匹配。理解这一点很关键——它决定了工具的能与不能。工具内置了8组双语特征检测,每组对应一类信号。
- 定义格式:匹配“是指”“定义为”“refers to”“is defined”等,判断你有没有Answer-First式的定义句。
- 操作步骤:匹配“步骤”“第一步”“Step 1”“how to”等。
- 正反面:匹配“优点/缺点”“pros and cons”“优势/劣势”等。
- 问答格式:匹配问号、“常见问题”“FAQ”“问:/答:”等。
- 引用来源:匹配“根据”“据……报告”“according to”“study”“research”等。
- 作者信息:匹配“作者”“author”“written by”“撰写”等。
- 日期标记:匹配“发布于”“更新于”“published”以及各种年月日格式。
- 专业资质:匹配“年经验”“专家”“资深”“PhD”“CFA”“certified”等。
这套机制的好处是快——不调用任何大模型,毫秒级就能给出结果。代价是它认的是“形式”而非“真意”:你写“根据一项研究”会被判定为有引用来源,哪怕后面没真的给出处;反过来,你用了一种它词库里没有的表达方式,明明有出处也可能漏判。所以工具的分数是个“形式合规度”的代理指标,不是内容质量的终极裁决。
数据点是怎么数出来的?
数据支撑这一项,工具用一个专门的正则去数“数据点”:百分比(35%、35‰)、金额($1,000、$1.5m)、数值词(5 million、10万、100亿、5倍)、以及两位以上的小数。命中几次就计几个,不去重、不评估质量。
这意味着一个实操要点:想在“数据支撑”上拿分,与其写“销量大幅增长”,不如写“销量增长了38%”;与其写“很多用户好评”,不如写“累计获得12000条好评、平均4.8分”。把模糊的形容词换成具体数字,既能讨好工具的检测逻辑,也确实让内容对真实读者更有说服力。这是少数几个“优化工具”和“优化质量”高度重合的地方。
它怎么挑出“最可能被引用”的5个句子?
除了给五个引擎打分,工具还会把你的内容切成句子,逐句打分,挑出最可能被AI直接复述的Top 5。句级打分的规则是:句子里出现目标关键词加20分、含数据点加15分、含定义词加15分、含引用词加10分、句长落在理想区间加5分。
理想句长是分语言的:中文30到150字符、英文60到400字符。太短的句子信息量不足、太长的句子AI不好整句摘取。这个Top 5列表的实战价值在于:它直接告诉你“如果AI要引用你,最可能引用这几句”。你可以拿这几句去对照——它们是不是准确表达了你最想被传播的观点?如果AI最可能复述的句子恰好是你内容里最平庸的那几句,说明你的“金句”埋得太深,得往前提、往句子里塞关键词和数据。
关键词密度0.5%到3%是什么讲究?
在Google AI Overview的打分里,有一项是关键词密度落在0.5%到3%之间加5分。密度的算法很直接:关键词出现次数除以总词数,再乘100。这是整个工具里唯一带点TF(词频)逻辑的维度,其余全是二值判断或简单计数。
0.5%到3%这个区间是SEO行业的经验法则,不是Google官方文档里的硬标准,本质上是工程化设定。它的提醒意义大于精确意义:低于0.5%,说明你可能通篇没怎么提到目标主题词,主题相关性弱;高于3%,则有关键词堆砌的嫌疑,这在AI时代反而是负面信号。把它当成一个“别走极端”的提示就好,不必为了卡进区间而生硬塞词。
一份内容怎么用这个模拟器做一次完整体检?
把工具用出价值,靠的不是跑一次看个分,而是一套固定动作。我们团队的标准流程是这样的。
- 确定目标查询词。先想清楚这篇内容到底想在AI搜索里赢下哪个问题,把那个最核心的查询词作为输入,而不是随便填个宽泛大词。
- 跑五引擎基线分。把URL或内容贴进去,记下五个引擎的初始分,重点圈出最低的那两个引擎——它们是你投入产出比最高的改进方向。
- 对照权重表定位失分点。拿最低分引擎的权重表逐项核对:是缺日期、缺Schema、缺数据、还是缺Answer-First?把缺的项列成一张待补清单。
- 按清单改一轮,只动最低分引擎的项。比如Perplexity低,就专门补更新日期、改写首段成直给答案、增加外链,先别管别的引擎。
- 重新跑分,看最低分引擎是否抬升、其他引擎是否被误伤。确认这一轮净收益为正,再处理下一个最低分引擎。
- 检查Top 5句子。确认AI最可能引用的5句话,正好是你最想被传播的核心观点;如果不是,把金句前提、加数据、塞关键词。
这套流程的精髓是“一次只攻一个引擎”。同时改五个引擎的项,很容易左手补的右手拆——比如为讨好ChatGPT把内容堆到3000字,结果稀释了Perplexity要的Answer-First密度。分步走、每步复跑,才能看清每个动作的真实收益。
跑出低分,先改哪里最划算?
工具的建议是分级的:缺引用来源这类硬伤标为error(最该先改)、缺Schema这类标为warn(次优先)、还能再增强的点标为pass。按这个优先级走通常没错,但我们团队还会叠一条经验:先改那些“一次改动、多个引擎受益”的项。
比如“补一个清晰的更新日期”,同时讨好Perplexity和Grok两个引擎;“把首段改成Answer-First”,对Perplexity、Google AI Overview、Claude都有正向作用;“把模糊形容词换成具体数据”,几乎所有引擎都加分。这些“通用增益项”应该排在最前面,先吃掉它们,五个引擎的分会一起往上走。等通用项榨干了,再去抠某个引擎的专属脾气。
这些分数和数字,是论文还是工程设定?
必须诚实交代:这个工具不调用任何一个引擎的真实API。它没有连ChatGPT、没有连Perplexity,更没有跑RAG或向量检索。所有的引用概率,都是作者根据各引擎的公开行为和文档观察、推断出可能的权重,再用代码模拟出来的。
所以那些权重数字——ChatGPT内容充足加12分、Perplexity日期加12分、各引擎倍数系数1.1到1.2——本质上都是工程化设定,是“相对量级的刻度”,不是官方算法参数。工具里唯一跟官方框架挂钩的,是它反复强调的E-E-A-T(经验、专业、权威、可信)信号——这是Google官方关于“创建有用、可靠、以人为本内容”的指南里明确的内容质量评估维度,工具对作者、日期、专业资质的加分,都呼应这套官方框架。
正确的使用心态是:把分数当“相对诊断”而非“绝对预测”。它能可靠地告诉你“这篇内容在Perplexity这个维度上明显比在ChatGPT维度上弱”,帮你定位短板;但它给不了“这篇内容有73%的概率被Perplexity引用”这种精确承诺。GEO论文证实了优化方向的有效性,但具体到某一篇的引用率,还得拿真实引擎去查询验证。
为什么不该追求五个引擎都满分?
跑出五个分数后,最常见的冲动是把每一栏都拉到90分以上。但这往往是个陷阱,原因有两层。
第一层是边际收益递减。把一篇内容从某引擎的40分提到75分,靠的是补几个硬伤(加日期、上Schema、改Answer-First),改动小、收益大;但从75分抠到95分,要满足的全是细枝末节的次要项,改动大、收益却很薄。把精力平摊到五个引擎冲满分,等于把宝贵的时间花在了收益最低的地方。
第二层是引擎之间会互相打架。讨好ChatGPT要内容够长(2000字门槛),可堆字会稀释Perplexity看重的Answer-First密度;讨好Gemini系要段落精简,又和ChatGPT的长篇偏好相左。强行让五栏都满分,常常是按下葫芦浮起瓢,最后哪个引擎都没真正讨好到,内容本身还被改得四不像。
更聪明的目标是“主战场冲高、其余及格”。把主战场引擎做到85分以上,其他引擎靠通用增益项维持在及格线(60分上下)即可。这样既保住了主战场的竞争力,又没在次要引擎上过度投入,性价比最高。满分思维在AI搜索优化里,大多数时候是个昂贵的执念。
模拟器的边界到底在哪?
用任何模拟工具,都得先想清楚它的边界,否则容易被分数牵着鼻子走。这个AI搜索模拟器有三条边界要记牢。
第一,合规不等于必然被引用。工具检测的是“形式上命中了多少偏好信号”,这是被引用的必要条件而非充分条件。一篇满分内容,如果在真实检索里压根排不进候选池,AI根本看不到它,谈何引用。所以GEO要和基础的可发现性(被抓取、被索引、检索相关性)配合,而不是替代它。
第二,正则检测有误差。它认形式不认真意,会把“假装有出处”判成有引用、会漏掉它词库外的表达。分数高低看趋势就好,别为了零点几分较真。
第三,引擎会变。这套权重是对当前引擎行为的快照,而AI引擎的更新速度极快。今天Perplexity重时效,明年可能调整。所以工具适合用来做“方向性诊断和阶段性复检”,不适合当成一成不变的金科玉律。想从机制层面理解AI引用到底怎么发生,可以延伸读我们拆过的RAG引用模拟的检索-生成-评估三阶段,那篇讲的是更接近真实引擎工作流的模拟逻辑。
实战案例:珠宝首饰出海站的五引擎体检
去年我们团队接手过一个做轻奢银饰的出海独立站,主力市场在北美,内容团队写了不少“如何挑选925银项链”“银饰怎么保养不发黑”这类导购科普,传统Google排名还不错,但客户发现:用户越来越多通过ChatGPT、Perplexity问“best sterling silver necklace for sensitive skin”这类问题,而AI的回答里几乎从不提他们的站。
我们拿主推的那篇“敏感肌银饰选购指南”跑了一遍五引擎模拟,结果很说明问题:ChatGPT给了68分(内容够长、有数据),但Perplexity只有41分、Google AI Overview只有39分。对照权重表,病因清清楚楚——Perplexity低是因为全文没有一处更新日期,首段绕了三句才说到“敏感肌该选什么”;Google AI Overview低是因为整篇裸奔,连Article Schema都没上,更别说FAQ Schema。
按“通用增益项优先、一次攻一个引擎”的流程,我们先补了显眼的“最后更新于2026年X月”、把首段改写成开门见山的Answer-First结论、再把分散在正文里的过敏数据集中成一句“医用级925银含92.5%纯银,镍释放量低于0.28μg/cm²/周,符合欧盟REACH标准”。这一轮下来,Perplexity从41升到72。
第二轮专攻Google AI Overview,补齐Article和FAQPage两套Schema、规范H标签层级,这一栏从39跳到78。三周后回看,这篇在Perplexity和ChatGPT的实测引用明显增多,带来的自然咨询量比改之前涨了约四成。
这个案例最值得记的一点是:内容本身的“干货”一个字没删,我们只是把同样的干货,改成了不同引擎认得出的形式。这恰恰印证了那句话——好与对,不是一回事。
怎么用五引擎差异反推内容策略?
工具用熟了,会催生一种更高阶的用法:不是被动地拿现成内容跑分补漏,而是在动笔之前就根据目标引擎反推内容形态。如果这篇的主战场是Perplexity,那从第一段就该是Answer-First、必带更新日期、多挂外链;如果主战场是Google AI Overview,那Schema和H标签得在内容规划阶段就设计好。
更聪明的做法是设计“五引擎通吃的骨架”:开头Answer-First(讨好Perplexity和Claude)、正文嵌入具体数据(讨好所有引擎)、关键信息上表格和列表(讨好Google AI Overview和Gemini系)、结尾给正反平衡的判断(讨好Claude)、全文标清作者和日期(讨好ChatGPT和时效控们)。这样一套骨架,五个引擎的基础分都不会太难看,再针对主力引擎做局部加强即可。
关于不同引擎的偏好规则到底差在哪、该怎么针对性改写,可以接着看我们拆的三大生成引擎偏好规则的合规检测,那篇把引擎偏好拆得更细,正好和这里的“骨架”思路互补。
模拟分和真实引用差多少才该担心?
常有人问:我跑出来某引擎80分,但真实搜索里就是不被引用,是工具不准吗?这里要分两种情况。
一种是分数高但内容压根没进检索候选池——这不是模拟器的锅,是你的可发现性出了问题(没被抓取、索引慢、或检索相关性太低)。模拟器假设你已经被检索到了,它只评估“被检索到之后,被选中引用的概率”。这种情况要回头去查技术SEO和索引状态。
另一种是分数和真实表现长期系统性背离——比如工具一直给你Claude高分,但Claude就是不引用。这时可以反过来用:把工具的权重表当假设,去真实引擎做小批量查询实验,记录真实引用情况,再回头校准你对这个引擎的判断。模拟器的最大价值,从来不是替代真实测试,而是把“该测哪些假设”收敛到几个明确的方向上,让你的实验不再大海捞针。把模拟当望远镜、把实测当尺子,两者配合才是正解。如果想系统地搭建这种“假设-实测-校准”的进化式优化框架,可以延伸看我们拆的用演化算法迭代GEO策略组合的方法。
常见问题解答
这个模拟器的引用概率分准吗,能信几分?
它准在“相对诊断”,不准在“绝对预测”。工具不调用任何引擎真实API,分数是基于对各引擎公开行为观察设定的工程化刻度。它能可靠地告诉你“这篇在Perplexity维度比在ChatGPT维度弱”,帮你定位短板和优化方向;但给不了“有X%概率被引用”的精确承诺。把它当望远镜定方向,最终效果一定要拿真实引擎查询来验证。
五个引擎的分数,我该先盯哪一个?
先盯你的主战场引擎,再补短板。如果目标用户主要用Perplexity做调研,就死磕Perplexity要的时效和Answer-First。无主战场时,优先改“一次改动、多引擎受益”的通用增益项:补更新日期、把首段改成直给答案、把模糊形容词换成具体数据。这些项榨干后,五个引擎的分会一起往上走,再去抠单引擎的专属脾气。
为什么我内容质量很高,某个引擎分却很低?
因为工具认形式不认真意。它靠双语正则匹配检测信号,你的高质量内容如果没标日期、没上Schema、首段没直给答案,工具就检测不到对应信号,分自然低。这恰恰是它的价值——提醒你“好内容也要用引擎认得出的形式来呈现”。对照低分引擎的权重表逐项补形式,分会很快上来。
关键词密度一定要卡进0.5%到3%吗?
不必死抠。这个区间是SEO行业经验法则、工具的工程化设定,不是Google硬标准。它的意义是提醒你别走极端:低于0.5%说明主题相关性可能太弱、高于3%有堆砌嫌疑。自然写作通常本来就落在这个范围里,为卡区间而生硬塞词反而得不偿失,尤其AI时代关键词堆砌是负面信号。
这个工具和真正的GEO效果评测有什么区别?
这个模拟器是“形式合规度”的快速代理,毫秒级出结果,适合日常起草和改稿时随手体检。而严肃的GEO效果评测(比如RAG引用模拟、多维质量裁判)更接近真实引擎的工作流,会模拟检索-生成-评估三阶段,结论更接近实战但成本更高。实操中先用这个模拟器快速定位形式短板,再用更重的评测工具或真实查询验证关键结论,是性价比最高的组合。
补Schema对哪个引擎帮助最大?
对Google AI Overview帮助最大,它是五个引擎里对结构化数据最敏感的——页面有Schema加10分、FAQ Schema再加8分、HowTo Schema加6分。Perplexity、Claude等对Schema也有少量加分但权重低得多。如果你的主战场是Google生态,Schema是必修课;如果主攻ChatGPT、Perplexity,Schema是锦上添花,应排在补日期、补数据、改Answer-First之后。
权威参考资料
本文标题:《AI搜索问答模拟器怎么用?一份内容跑五引擎体检看清谁愿意引用你》
本文链接:https://zhangwenbao.com/ai-search-simulator-5-engine-citation-probability-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0