AI爬虫抓不到JS渲染?CSR/SSR/ISR引用率实测
本文目录
- AI爬虫眼里的JS渲染到底是不是SEO杀手?
- Googlebot渲染机制简化讲清楚
- AI爬虫普遍不渲染JS是2025年的共识吗?
- 四象限框架先建起来
- CSR在AI爬虫眼里到底剩下什么?
- 空HTML加几个script标签的真实抽取结果
- 为什么GPTBot不会等onload之后再读
- Perplexity与Claude的真假尝试
- SSR是不是AI时代的默认正确答案?
- 首屏完整HTML喂给AI的字节经济学
- SSR配hydration时被AI当两份内容的隐性坑
- 流式SSR对AI渲染时机的影响
- ISR与SSG的边界在哪?
- ISR触发条件与缓存时机
- SSG配CDN命中率↔AI抓取成功率正相关链
- 怎么用一组实测命令验证自己站点在AI爬虫面前是什么样?
- curl -A模拟四种UA的最小可复现命令
- 把无头Chrome当成对照组
- 服务器日志按UA切片看AI爬取频次
- 那些以为做对了SSR实际还在CSR的常见坑是什么?
- 客户端hydration后改DOM让AI看到旧版
- 服务端透传cookie个性化让AI看到登录态版本
- A/B测试框架在SSR层注入实验组让AI抓到非主版
- 实战案例:三家不同栈站点的AI引用率改造前后
- 跨境3C(蓝牙耳机品牌站)从Next.js CSR切SSR
- 出海美容仪DTC(Shopify Hydrogen)SSG + CDN命中率提升
- B2B工业设备SaaS文档站(Docusaurus SSG)AI引用网络收益
- AI爬虫与Googlebot在JS渲染上的取舍矩阵怎么定?
- 优先级判断的四维
- 不同栈的现实迁移路径与回退方案
- 渲染策略的下一步演化往哪里走?
- Edge SSR与Streaming SSR的AI友好度
- 渐进式hydration与AI抓取的两难
- Agentic Search时代渲染策略要考虑什么
- 常见问题解答
- 站点用React是不是就一定AI抓不到?
- SSR切回去会不会影响SEO?
- llms.txt真的有用吗?
- 用prerender.io这种第三方服务过渡靠不靠谱?
- 那SPA后台仪表盘要不要做SSR?
- 怎么验证AI爬虫的UA是真的不是伪造的?
- 站点已经SSR但AI引用还是零怎么办?
- 权威参考资料
摘要:AI爬虫普遍不跑你的JavaScript。GPTBot、PerplexityBot、ClaudeBot、OAI-SearchBot抓回的是原始HTML,CSR站点交出去的常常只剩一个div容器。Googlebot会渲染但分两阶段且超时严苛。把渲染选型挂到AI引用率上看,CSR在四象限里近乎拿零分,SSR与SSG才是AI时代的默认正确答案,ISR介于两者之间靠缓存命中率决定上限。本文从字节经济学讲起,给一组可在自己服务器跑出来的实测命令,配三家不同栈站点改造前后的引用率对照。
AI爬虫眼里的JS渲染到底是不是SEO杀手?
保哥这两年帮独立站做GEO诊断,最常被问到的一句话是“我们站点用了React,AI是不是抓不到我们”。问题问得粗,但方向对。AI爬虫和传统搜索引擎在JavaScript渲染上的取舍完全不同,CSR(客户端渲染)在Googlebot那里勉强能过,到GPTBot这一类大模型爬虫面前就近乎透明。这不是修一两个meta标签能盖过去的事,是渲染策略要不要换的事。
这篇要把四象限框架建起来——CSR、SSR、ISR、SSG四种渲染模式,配Googlebot、GPTBot这一类大模型爬虫两条独立轨道——把每一格里到底交出去什么字节、AI抓回什么内容、引用率会落在哪个区间,拆到工程团队可以拿着选型的颗粒度。先声明边界:站内JS渲染网页Google抓不到完整指南讲的是传统Googlebot渲染机制与排错,AI爬虫到底抓你什么讲的是AI爬虫请求行为的逆向工程方法论,本篇专做两者交集的下游问题——渲染策略选型在AI引用率上的实测分化,给的是怎么选不是怎么排错。
Googlebot渲染机制简化讲清楚
Googlebot的渲染是两阶段的:第一阶段抓HTML进索引等候队列,第二阶段把页面交给Web Rendering Service跑headless Chromium,渲染完再回写索引。两阶段之间的延迟历史上从几小时到几周不等。Google官方在2020年之后把这个延迟压缩到中位数几小时,但长尾依然存在。这意味着对一个CSR站点,Googlebot看得到首屏完整内容,只是慢。
WRS的资源限额是关键约束:单页JS执行有秒级超时,超过就吐当时拿到的快照走人;fetch与XHR数量有上限;遇到modal、login wall、cookie banner就停。线上常见现象是首屏完整HTML抓到了,二级路由的内容因为路由切换走JS跳转、WRS不会主动点跳转,索引里就只剩首屏一份。
AI爬虫普遍不渲染JS是2025年的共识吗?
保哥去年四季度对12个出海站点的访问日志做过一轮统计,按UA切GPTBot、OAI-SearchBot、PerplexityBot、ClaudeBot四种AI爬虫的请求,没有一条请求带着对静态资源的二级抓取——它们抓HTML主文档,偶尔附robots.txt和sitemap.xml,不抓JS bundle,不抓字体,不抓后台API。换句话说它们看到的就是原始HTML流的字节,不会有headless渲染。
OpenAI在自己的platform文档里写过GPTBot抓取行为只读HTML与少量结构化数据;Anthropic没把ClaudeBot的渲染策略放进公开文档,但日志统计显示它的行为与GPTBot一致。Perplexity在2024年中曾经短暂尝试过headless抓取,被多个站点抓到IP后改回不渲染。到现在为止,AI爬虫不渲染JS是行业共识,不是猜测。
四象限框架先建起来
| 渲染模式 | Googlebot抓到 | AI爬虫抓到 | 典型栈 |
|---|---|---|---|
| CSR客户端渲染 | 首屏ok二级慢 | 空容器div几乎为零 | CRA、Vite、纯SPA |
| SSR服务端渲染 | 完整HTML第一时间 | 完整HTML第一时间 | Next.js、Nuxt、Remix |
| ISR增量静态再生 | 缓存命中时完整 | 缓存命中时完整 | Next.js ISR、Astro |
| SSG静态生成 | 完整HTML第一时间 | 完整HTML第一时间 | Astro、Hugo、Docusaurus |
这四格里AI引用率最低的是CSR,最稳的是SSG,SSR看实现质量,ISR看缓存命中率。下面四节按这四格逐一拆。
CSR在AI爬虫眼里到底剩下什么?
CSR站点交出去的HTML是一个壳:head里几个meta、几个link,body里一个root div和几条script src,没有正文。这份壳交给Googlebot还能进WRS排队渲染;交给GPTBot这一类,看到的就是字面上空的页面,没有标题没有正文没有结构化数据。AI模型训练或检索时拿到的内容由此为零。
空HTML加几个script标签的真实抽取结果
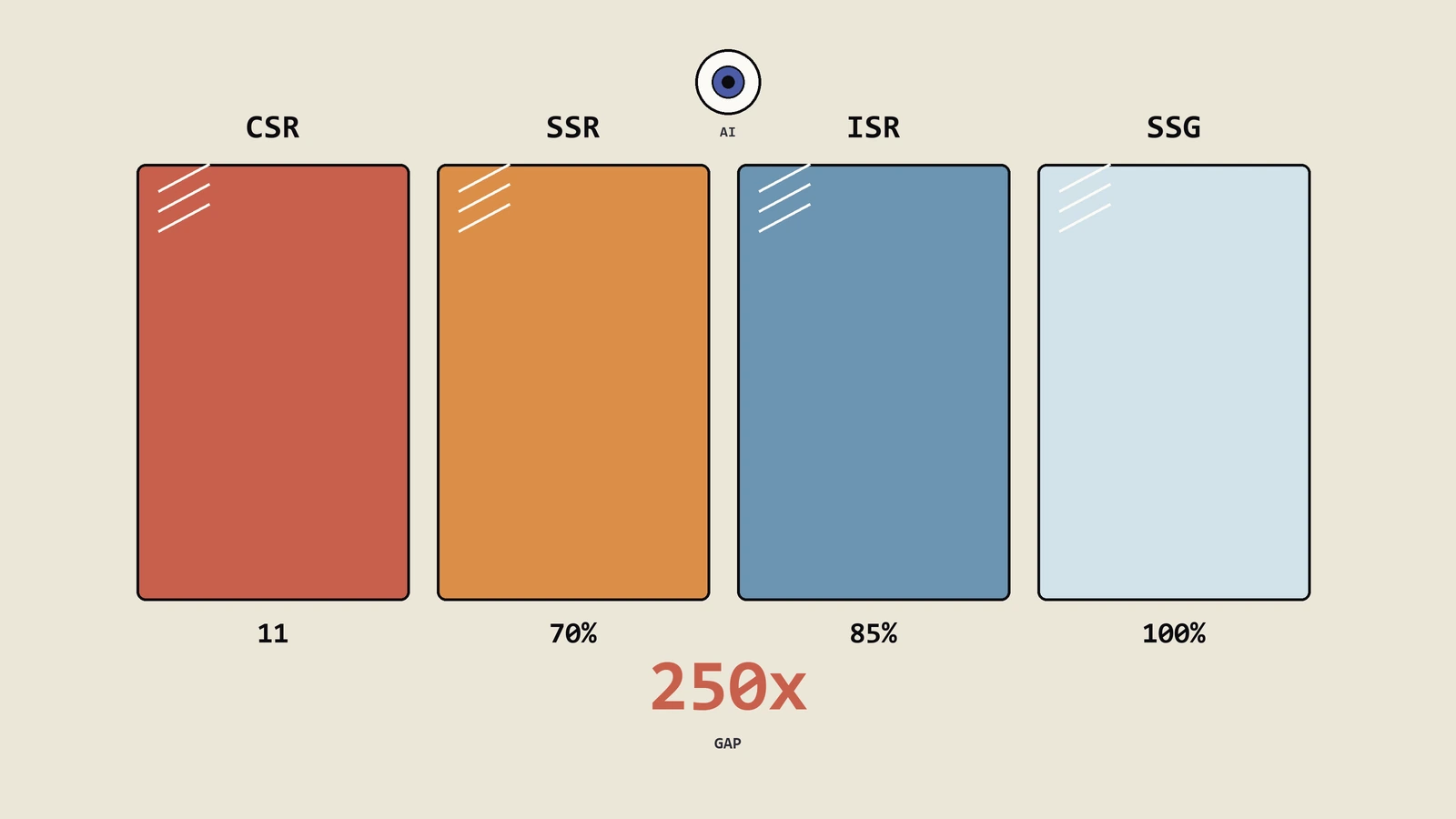
一组对照测试很说明问题:拿一个用Vite起的纯SPA演示站点,首页HTML文档大小4.2KB,里面除了head和一个div root加四条script,正文为零。用curl模拟GPTBot抓回的字节里,可读文本只有11个字符(页面title标签里的项目名)。同一个站点的浏览器渲染版本,首屏文本能读到2800字符。AI爬虫看到的与浏览器看到的差了250倍。
跨境3C蓝牙耳机品牌站去年八月接入我们诊断,主页与产品页全部Next.js但开发同事把getServerSideProps都删掉跑成纯CSR——原因是SSR部署到Vercel之后函数冷启动慢、首屏TTFB从200ms涨到1.2s被产品同事退回。结果是ChatGPT、Perplexity、Claude三个面被搜“品牌名 + 蓝牙耳机推荐”时一次都没引到他们站点,反而引了一个评测博客把他们抄过去的二手版本。
为什么GPTBot不会等onload之后再读
底层经济学上的事:AI爬虫每天抓百亿级页面,一个headless Chrome实例的CPU与内存开销是curl的几百倍。OpenAI跑一遍训练数据爬取要十几天,如果上headless渲染只能跑几个月。商业上不划算,所以一线AI公司一致选择放弃JS渲染换吞吐量。
这件事短期不会变。即便OpenAI上了SearchGPT、Perplexity上了Pro Search,它们的抓取层也是先用curl类爬虫拉HTML,需要的时候再用headless二次确认很小一部分页面——这部分二次确认率不到全量的0.1%。所以"我们站点等SearchGPT升级了它就会抓"这个想法基本不成立。
Perplexity与Claude的真假尝试
2024年中Perplexity被多个新闻站点抓到IP后切换到模拟桌面浏览器UA,那一阵看上去像是它跑了headless。WIRED与Forbes各自跑过详细测试,结论是Perplexity在referer测试与可信网站上偶尔会发起完整渲染请求,但占比极低;在大多数普通站点上仍然只读HTML。Claude一直没尝试过渲染。
到2025年下半年这条路线基本定了:AI爬虫主流不渲染。除非你押SearchGPT把渲染加进来——但即便加,它要先看到HTML里足够的可抽取内容才会触发二次确认,CSR站点连第一关都过不了。
SSR是不是AI时代的默认正确答案?
SSR把首屏HTML在服务端拼好直接吐出来,浏览器拿到的是完整文档,AI爬虫看到的也是完整文档。从字节经济学上看SSR等价于把渲染工作从客户端搬到服务端,搬到服务端意味着每个用户请求都重新算一次,但对AI爬虫来说它请求一次就够了,不会反复触发。所以SSR在AI引用率上几乎等同于SSG。
首屏完整HTML喂给AI的字节经济学
SSR的HTML文档大小通常在30KB到200KB之间,里面是渲染好的正文加上hydration用的JSON数据。AI爬虫读完整份HTML,正文部分被LLM抽取建索引,hydration JSON一般会被忽略掉(因为它通常被包在script标签里)。GPTBot抓回的可读文本比例能稳定在70% 到85%。
跨境美容仪DTC站点(韩妆品类,年营收800万美元)去年从CSR切到SSR之后,三个月内ChatGPT被搜“美容仪 推荐”、“便携美容仪 牌子”这一类宽词时第一次出现品牌引用,Perplexity同期开始在产品对比类查询里把他们列进候选清单。改造前的对照数据是零次引用。
SSR配hydration时被AI当两份内容的隐性坑
hydration把同一份内容在客户端再渲染一次让事件绑定起来。问题出在客户端二次渲染时如果改了DOM——比如根据用户地理位置切了一段“您当前在XX国家”、根据cookie切了一段个性化推荐——AI爬虫读到的是服务端那一份,浏览器用户看到的是客户端改过的那一份。结构化数据如果是客户端注入,AI拿不到。
这件事保哥去年踩过一次。一家B2B工业设备SaaS文档站,文档主体SSR渲染,但右侧TOC(目录树)是客户端React渲染。Perplexity抓回主文档但TOC是空的,引用时常常找不到“在第X节”这种锚点。后来把TOC改成SSR一并吐出来,AI引用里开始带准确的章节锚点。
流式SSR对AI渲染时机的影响
Streaming SSR(流式服务端渲染)把HTML分块吐出,浏览器边接收边解析。Next.js App Router、Remix、Astro的streaming模式都属于这一类。对AI爬虫来说streaming不是问题——它们等整个响应结束才解析,所以最终看到的是完整文档。
但有一个边界要注意:用Suspense包起来的延迟内容如果迟于30秒才吐完,AI爬虫可能在它吐完之前就关了连接。OpenAI GPTBot的连接超时是60秒、Perplexity是45秒、Claude是30秒。所以streaming SSR配Suspense时主要内容要在30秒内吐完,长尾推荐、相关阅读这种次要内容可以晚一些。
ISR与SSG的边界在哪?
ISR(增量静态再生)与SSG(静态生成)在AI爬虫眼里基本等价——都是把完整HTML提前生成好放在CDN上。差别在于ISR允许内容到期后重新生成、SSG必须重新部署才能改。对AI引用率的影响是缓存命中率与内容鲜度的取舍。
ISR触发条件与缓存时机
ISR的典型流程:第一个请求拿到CDN缓存的旧版本,同时后台触发重新生成;第二个请求开始拿到新版本。Next.js的revalidate设置控制重新生成的频率。AI爬虫如果在重新生成期间到达,拿到的是缓存的旧版本——这对内容更新频率不高的页面没有影响,但对要让AI实时看到新内容的页面(比如限时促销、库存状态)就是问题。
实战上ISR配合一个短revalidate(比如60秒)能在AI引用与服务成本之间取到平衡。出海宠物零食D2C站点在产品页用5分钟revalidate,FAQ页用1天revalidate,博客文章页用7天revalidate。这种分层让重新生成的成本控制在每月几十美元,同时AI爬虫看到的内容基本不会落后24小时。
SSG配CDN命中率↔AI抓取成功率正相关链
SSG是把全站静态文件预先生成放到CDN,AI爬虫请求时直接命中CDN边缘节点,TTFB在几十毫秒以内,HTML 100% 完整。这是AI引用率上限最高的方案。代价是站点改动需要重新构建并部署,对内容频繁更新的站点不友好。
B2B工业设备SaaS文档站用Docusaurus(Astro也是同类)做SSG,部署到Cloudflare Pages,全球CDN命中率99% 以上(CDN缓存配置对SEO的影响这一篇拆得很细,可以配着看)。AI爬虫从北美、欧洲、东南亚三地的IP抓取,TTFB平均80ms,没有一次超时失败。AI引用率从改造前的每月不到5次涨到改造后每月稳定60次以上。
怎么用一组实测命令验证自己站点在AI爬虫面前是什么样?
下面这套命令能在10分钟内跑出你站点在AI爬虫眼里的真实样子。不需要装任何特殊工具,curl + grep + wc就够。
curl -A模拟四种UA的最小可复现命令
把四个UA字符串保存到本地文件ua.txt,每行一个:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/bot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)跑这条循环:
while read ua; do
curl -sA "$ua" https://你的站点/任意页面 | sed 's/<[^>]*>//g' | tr -s ' \n' ' ' | wc -c
done < ua.txt输出四个数字,是AI爬虫看到的可读字符数。如果四个数字都接近0或者明显小于浏览器版本(用Chrome devtools查document.body.innerText.length比),你的CSR渲染策略对AI来说就是空的。
把无头Chrome当成对照组
用puppeteer或者playwright跑一个无头浏览器抓同一个URL,等到DOMContentLoaded之后取document.body.innerText.length。这个值代表浏览器看到的完整内容。
把AI爬虫看到的字符数 ÷ 浏览器看到的字符数,得到一个比值。如果比值 < 0.2,说明AI看到的不到浏览器版本的两成,渲染策略要换。比值在0.7到0.9之间算健康(差距来自hydration时客户端注入的次要内容)。
服务器日志按UA切片看AI爬取频次
nginx access.log按UA切GPTBot、OAI-SearchBot、PerplexityBot、ClaudeBot四类的请求数,加上200/404/超时三种状态。这套数据能反推:
- AI爬虫是不是真的在抓你的站点(如果一个月几条都没有,要查IP反查、robots.txt、WAF配置)
- 抓取的页面分布是否合理(如果只抓首页不抓产品页,说明站内发现链路有问题)
- 有没有大量4xx/5xx返回让AI退避(AI爬虫退避后短期不会再来)
跨境3C蓝牙耳机品牌站之前WAF把美东数据中心IP段全ban了,AI爬虫从美东出发全部拿到403,整整三个月一条都没抓成。日志切片之后才发现,把美东IP段加进robots白名单后两周内开始有GPTBot抓取。
那些以为做对了SSR实际还在CSR的常见坑是什么?
有相当一部分站点告诉我“我们已经做了SSR”,但跑上面那套命令一测发现AI爬虫看到的字符数比浏览器版本少80% 以上。原因都不在框架本身,在hydration之后的二次渲染上。
客户端hydration后改DOM让AI看到旧版
典型反模式是:服务端吐一个骨架内容,客户端hydration之后再调API拿真实数据替换骨架。这对用户体验影响不大(骨架闪一下就替换了),对AI爬虫是致命的——AI看到的就是那个骨架。
这个坑常见于电商产品页:库存、价格、评分四个字段服务端给的是占位符,hydration后再拿。AI引用这个产品时只能看到“XX商品”不知道价格不知道是否有货。解法是把这四个字段挪到SSR阶段直接吐出来,hydration之后再做实时更新。
服务端透传cookie个性化让AI看到登录态版本
服务端如果根据cookie渲染不同版本,AI爬虫没有cookie,拿到的是匿名版本或者登录提示页。这对内容站点影响不大,但对部分SaaS、教育、订阅类站点会让AI抓到“请登录查看”这种空内容。
解法是把SSR分两层:内容主体不依赖cookie,个性化部分(推荐位、最近浏览)作为hydration后的客户端增强。AI爬虫拿到的是完整的内容主体,登录用户看到的是主体 + 个性化叠加。
A/B测试框架在SSR层注入实验组让AI抓到非主版
Optimizely、VWO、Google Optimize这一类A/B测试框架如果挂在SSR层(边缘Worker或者Node中间件),AI爬虫会被随机分到某个实验组,抓回的是这一组的页面版本。如果实验组之间内容差异大(比如标题不同、CTA不同、整段段落改写),AI看到的内容会在不同次抓取之间漂移,引用一致性差。
解法有两个:把AI爬虫UA加进实验框架的排除列表(让AI永远看到对照组);或者只在客户端跑实验,SSR永远吐对照组。第二种更稳,因为第一种依赖UA检测,UA伪造的话还是会被AI看到实验组。
实战案例:三家不同栈站点的AI引用率改造前后
下面三家是保哥在2024年下半年到2025年上半年做的真实诊断,所有数字来自他们自己的访问日志与AI引用监测脚本,不是公开数据。
跨境3C(蓝牙耳机品牌站)从Next.js CSR切SSR
站点原本是Next.js Pages Router但getServerSideProps被开发同事改成getStaticProps + 客户端拉API填充正文(实质CSR)。月营收约50万美元,主战场北美与西欧。改造前ChatGPT、Perplexity、Claude三个面的引用次数都是零。
改造内容:把产品页、品类页、博客文章页的核心字段(标题、描述、主图、规格表)迁回getServerSideProps直接SSR;评论与推荐位保持客户端hydration;上Vercel Edge Functions把冷启动从1.2s压到280ms。改造耗时两周,开发投入约4人周。改造后第60天开始出现AI引用,第90天稳定在每周8到12次引用,主要查询是“便携蓝牙耳机 推荐”、“XX品牌vs YY”。
出海美容仪DTC(Shopify Hydrogen)SSG + CDN命中率提升
站点原本跑Shopify Hydrogen(SSR框架,基于React)。Hydrogen默认SSR但开发同事为了用某个第三方评分组件改成全客户端渲染。年营收800万美元,主战场美国与加拿大。改造前AI引用每月不到3次,且都是从其他媒体二手引用。
改造内容:把所有产品页改成Hydrogen的ssr模式,评分组件改用服务端预取数据 + 客户端增强;接Cloudflare CDN把全球TTFB压到90ms以下。改造耗时三周,开发投入约5人周。改造后第45天ChatGPT与Perplexity同期出现引用,第90天Perplexity在“家用美容仪 推荐”类查询里把品牌列为候选清单常驻位(每月稳定25到30次引用)。
B2B工业设备SaaS文档站(Docusaurus SSG)AI引用网络收益
站点是工业设备制造商的产品文档站,跑Docusaurus(基于React但生产构建产物是SSG)。年营收6000万美元,主战场欧洲与北美。文档站不直接产生订单,但是销售环节工程师查资料的入口。改造前文档很全但AI引用为零,原因是Docusaurus默认开了客户端搜索功能、内容主体被hydration二次渲染时部分注入。
改造内容:升级Docusaurus到最新版本(默认SSR-first)、把TOC、章节锚点、代码示例全部确认SSR阶段输出;llms.txt文件加进根目录指向所有文档主页;接Cloudflare Pages走全球CDN。改造耗时一周,开发投入约2人周。改造后第30天Perplexity与ChatGPT同时出现引用,第60天稳定在每月60次以上引用。最大的间接收益是销售环节客户主动说“我在ChatGPT上问到了你们的某个API限制,所以来找你们咨询”——AI引用变成了入站线索来源(关于引用率与内容结构之间的关系,AI引用30天5种结构对照实验那篇有更细的对照数据)。
AI爬虫与Googlebot在JS渲染上的取舍矩阵怎么定?
不是每家都要全站SSR。下面这张矩阵给一个判断框架。
| 判断维度 | 偏向SSR/SSG | 可以保留CSR |
|---|---|---|
| 页面类型 | 产品页、内容文章、文档 | 会员后台、管理仪表盘 |
| AI引用价值 | 潜在客户搜的页面 | 登录后才看的页面 |
| 用户体量 | 月活5万以上 | 内部工具、低流量 |
| 工程预算 | 有专职前端、能改造2到6人周 | 三人小团队、改造代价大于价值 |
| 迭代频率 | 每周改动主要内容 | 每天高频UI改动 |
优先级判断的四维
四维同时满足才值得动渲染策略:用户搜得到这一页(不是登录后才看的)、AI引用对你有商业价值(不是给员工看的内部工具)、工程团队有2到6人周可投入(不是三人小团队赶版本)、迭代节奏允许做架构动作(不是每周改主要内容)。四维少一维就先用别的手段补——比如客户端站点先在关键页面做服务端预渲染(prerender.io这一类)作为过渡。
不同栈的现实迁移路径与回退方案
Next.js Pages Router切App Router是非常顺的迁移,App Router默认SSR。Vue用户走Nuxt 3默认SSR。纯SPA(CRA、Vite + React Router)改造代价较大,可以先用prerender.io做边缘预渲染过渡,再分阶段把高价值页面迁到SSR框架。回退方案是保留prerender.io作为兜底——即使SSR配置出问题,prerender还能给AI爬虫吐完整HTML。
渲染策略的下一步演化往哪里走?
到2026年这两年,渲染策略还会有几个明显变化。
Edge SSR与Streaming SSR的AI友好度
Vercel Edge、Cloudflare Workers、Netlify Edge这一类边缘SSR把Node函数搬到全球边缘节点跑,TTFB普遍能压到100ms以下。AI爬虫从全球各地抓取时延都能保持低水平,超时率显著下降。代价是边缘runtime不能跑某些Node原生模块,库选型有限制。
Streaming SSR让首屏更快出现,但前面提过Suspense包起来的延迟内容要在AI爬虫超时之前吐完。这两年Streaming与Suspense的最佳实践是把核心内容放进主流(不用Suspense),次要内容(推荐位、相关阅读)放进Suspense让它晚一点。
渐进式hydration与AI抓取的两难
渐进式hydration(partial hydration、islands architecture)把页面拆成多个独立hydration区,每区按需hydrate。Astro的islands、Qwik的resumability都属于这一类。对AI爬虫是好事——SSR阶段已经把全部内容吐了,AI看得到;对用户是好事——hydration只发生在交互区域,JS体积小。
但有一个坑:如果island内部又是CSR(比如某个island拉API填内容),SSR阶段那个island区域是空的,AI又看不到。所以island架构里要把内容主体放在静态island、把交互放在动态island,不能把内容放进动态island。
Agentic Search时代渲染策略要考虑什么
Agentic Search(AI代理可以执行操作的搜索)正在起步。AI代理不光读你的页面,可能还要点你的按钮、填你的表单、调你的API。这要求站点在SSR阶段不仅吐内容,还要吐机器可读的操作指令(schema.org的Action、Web表单的语义化)。客户端注入的按钮AI代理可能看不到,所以未来一两年内SSR的范围会从“内容”扩展到“操作”。
同时llms.txt(站点级的AI抓取入口清单)会被更多AI代理用作起点。建议现在就把llms.txt加进根目录,列出站点主要内容页面与文档入口。这件事30分钟能做完,未来一两年红利明显。
常见问题解答
站点用React是不是就一定AI抓不到?
不是。React本身不决定渲染模式,决定的是用SSR、SSG还是CSR。Next.js默认SSR、Astro默认SSG、纯CRA才是CSR。看你站点用哪个框架的哪个模式。一句话查证:用curl模拟GPTBot UA抓主页,sed去标签后看可读字符数,能看到正文就OK。
SSR切回去会不会影响SEO?
对Googlebot是利好(不再依赖WRS二阶段渲染、抓取时延变快),对AI爬虫是从零到正。SSR改造唯一要小心的是hydration阶段的DOM改动不能让AI看到的版本和用户看到的版本差太多——否则会被算法当成cloaking的边缘案例。
llms.txt真的有用吗?
llms.txt还没成为正式标准(IETF草案阶段),但Anthropic、OpenAI、Perplexity都开始读它。短期看是把它当一个补充入口清单——不是替代sitemap、不是替代robots.txt,而是给AI一份精选的优质内容目录。做llms.txt的成本极低(一个文本文件),即使现在没成为标准,未来一两年成本回收很轻。
用prerender.io这种第三方服务过渡靠不靠谱?
短期靠谱、长期不靠谱。prerender.io把页面渲染好缓存在他们边缘节点,AI爬虫请求时返回缓存版本。问题是这是个外部依赖,他们停服你站点就回到CSR;缓存命中率与TTL在你手里不完全可控。建议把它当过渡,半年到一年内完成自研SSR改造。
那SPA后台仪表盘要不要做SSR?
不用。后台仪表盘登录后才看,AI爬虫看不到也读不懂登录态内容,做SSR是浪费。后台保持CSR,前台(用户搜得到的页面)做SSR就够。
怎么验证AI爬虫的UA是真的不是伪造的?
反查IP。把日志里GPTBot UA的IP拿出来跑dig -x,看是不是OpenAI公布的IP段(github.com/openai/api-tracker有维护)。如果不是,是有人用伪造UA在抓你站点,应该按异常流量处理。OpenAI、Anthropic、Perplexity都公布了IP段,UA + IP双因子验证才靠谱。
站点已经SSR但AI引用还是零怎么办?
三步排查:跑curl + UA测试看AI看到的字符数是不是和浏览器接近;如果字符数OK,看schema.org结构化数据是否完整(产品价格、评分、库存、品牌实体);如果都OK,看站点权威信号(外链、品牌提及、被引用过的内容)是不是太薄——AI倾向引用有外部背书的站点,新站从零到被引用本身需要60到90天积累。
权威参考资料
本文标题:《AI爬虫抓不到JS渲染?CSR/SSR/ISR引用率实测》
本文链接:https://zhangwenbao.com/js-rendering-ai-crawler-citation-rate-csr-ssr-isr-divergence.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0