CDN对SEO到底有什么影响?6层缓存与边缘路由实战
本文目录
- CDN的"快"和SEO到底是什么关系?
- 静态加速、抓取行为、内容传达——这三件事别再混着说
- 一张速度曲线骗过PageSpeed却没救SEO的真实场景
- SEO在CDN层面真正该管的6件事
- 边缘缓存、回源缓存、浏览器缓存这三层缓存怎么配才不打架?
- 三层缓存的TTL不该一样长
- HTML缓存的"激进度"到底激进到哪一步才不伤SEO
- 一个真实跨境母婴DTC的过激缓存灾难复盘
- Googlebot与AI爬虫到底走不走CDN?怎么验证它没被错杀?
- 边缘节点IP分布与Googlebot IP段几乎不重叠
- WAF的Bot Management把Googlebot当bot的三种触发
- 反向DNS验证Googlebot的标准动作
- 多CDN切换、灰度、并存时的SEO风险点在哪里?
- 多CDN流量切分时的边缘节点缓存不一致
- CDN切换中301链断裂与canonical冲突
- 一个B2B工业出海客户多CDN踩坑实例
- 跨境双CDN与多区域部署怎么不损SEO?
- 国内+海外双CDN分流的DNS层vs域名层方案
- 国别访问差异导致Googlebot抓到"错版本"
- 一个3C配件出海客户香港回源海外节点案例
- 主流CDN厂商SEO配置差异在哪里?怎么挑?
- 六家厂商Bot Management与SEO敏感设置对照表
- 国内CDN必备的备案与回源配置坑
- 一张厂商挑选决策矩阵
- CDN出故障时SEO防御怎么做才不掉量?
- 故障三类信号:抓取404峰vs 503峰vs软404峰
- 灾备DNS切换的TTL机制与回源备份
- 一个DTC家居站CDN瘫机12小时的GSC流量曲线复盘
- 把CDN和SEO两条线打通的8项配置清单
- 常见问题解答
- CDN会直接影响Google搜索排名吗?
- 开了Cloudflare之后GSC的抓取统计变慢了,是CDN的问题吗?
- 国内站套CDN会被百度认作多IP从而判定作弊吗?
- Page Rule把HTML缓存设了1小时,Google会更新慢一截吗?
- 多个域名共用一个CDN账号,会被Google判作站群吗?
- CDN跨境跳转IP解析得到不同节点,会让hreflang失效吗?
- 切完CDN之后是不是该把所有内链改成HTTPS?
- 权威参考资料
摘要:套CDN之后SEO到底动了哪条线?保哥这几年带过的项目里,CDN出问题不是"快不快"的事儿,是"Googlebot走不走得通、抓的是哪份缓存、节点回不回得了源"这一串。这篇把六层缓存、Bot Management误封、多CDN切换、跨境双节点、六家主流厂商配置差异和故障防御一起串成一条线,给你一张配完不会塌的实操地图。
CDN的"快"和SEO到底是什么关系?
我见过太多客户拿着PageSpeed的95分截图来问"我都做到这样了流量怎么还在跌"。CDN把页面变快是真的,但快只是表象,对SEO真正起作用的,是CDN在你和搜索引擎中间多塞了一层网络代理——这层代理同时决定了爬虫拿到什么内容、什么时候拿、能不能拿到。
速度只是这层代理一个副产物。配错了它,速度照样飞,但你已经悄悄把Googlebot喂了一份过期一周的HTML,或者把它当成bot拦在门外,或者让它在不同地区抓到风格迥异的两份页面。这种事儿在控制台里看不到,只能在日志里翻。
静态加速、抓取行为、内容传达——这三件事别再混着说
静态加速指的是图片、CSS、JS这类二进制和文本文件被推到边缘节点,用户和爬虫离得最近的那个节点直接吐出来。这部分对SEO贡献几乎只有"页面更快",不会改变内容本身。
抓取行为是说Googlebot发请求过来,CDN决定它走哪个节点、是不是要回源、是不是要给challenge、是不是给假数据。这一层一旦设错,可能把搜索引擎拦在门外好几周,等你看到流量塌方再排查,已经损失上千的预算了。
内容传达讲的是HTML本身被缓存之后,搜索引擎拿到的是"现在的版本"还是"两小时前的版本"还是"完全错的版本"。新闻类、电商促销页、AI生成的实时内容,对这一层最敏感。三件事经常被技术团队当一件事说,实际它们的SEO权重完全不同。
一张速度曲线骗过PageSpeed却没救SEO的真实场景
有个做跨境母婴DTC的客户,2023年中找保哥时拿出来的Lighthouse报告漂亮得不得了——LCP 1.4秒、CLS 0.02、INP 180毫秒,全绿。但GSC里"已发现-未编入索引"占比一直涨,每月稳定在20%~25%。
那次跟客户技术合伙人看Cloudflare页面规则,发现他们把HTML的TTL设成了4小时,Cache Level直接拉到"Cache Everything"。意思是Googlebot来抓的时候,吃的可能是四小时前缓存的版本——而那个版本对应的产品已经下架了、URL指向变了、内链改过了。每次抓取吃到的"快照"和数据库实时状态对不上,索引器自然丢手。
这事儿一调整,HTML缓存改成只缓存5分钟、并且每次发版主动purge对应URL,"已发现-未编入"两个月内回落到6%。速度数字一分没变,但SEO能见度起来了。这就是典型的速度骗过监测、却没救SEO的局面。
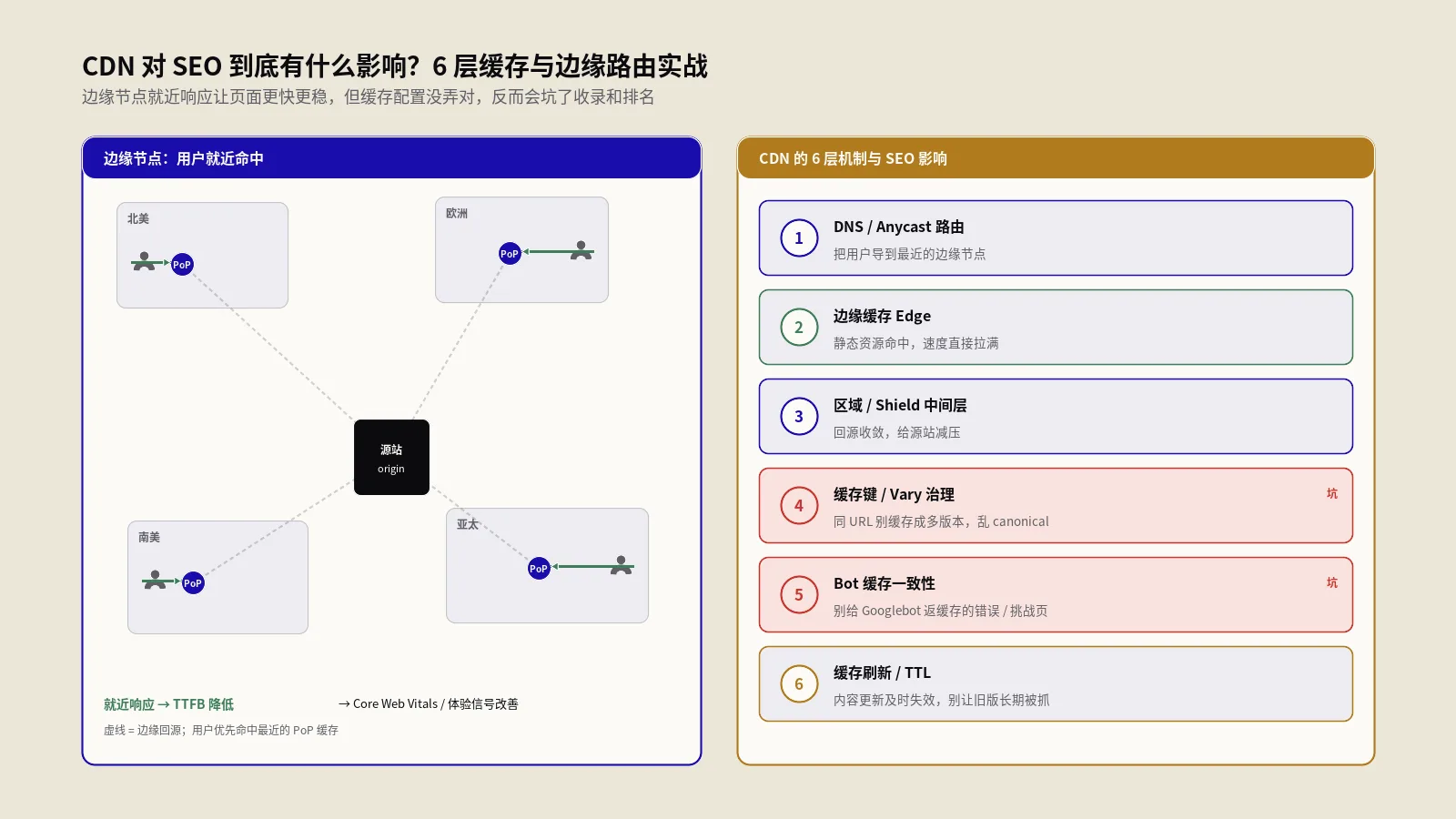
SEO在CDN层面真正该管的6件事
把这层代理拆细看,SEO真正要盯的是六个动作:HTML的缓存策略与TTL长度、爬虫识别与白名单维护、回源链路的健康度、跨地域节点的内容一致性、安全防护规则对bot的误伤、故障切换时的SEO防御。这六件事每一件都能单独写一篇,但它们彼此勾连,单独看也没法做对决策。后面六个H2会一个一个拆开讲,先在脑子里挂上这张图。
很多团队的问题不是"懂不懂CDN",是把CDN当成"加速工具",配完忘了它还是搜索引擎和你网站之间的中间人。一旦视角换成"中间人",下面所有决策都顺了。
边缘缓存、回源缓存、浏览器缓存这三层缓存怎么配才不打架?
一个完整的请求链路是:用户/爬虫→边缘节点→源站→源站缓存(比如Varnish/Nginx FastCGI cache)→应用层→数据库。CDN这一层在边缘节点和源站之间,往下走还有源站自己的缓存层,再往上是用户端浏览器缓存。三层叠加之后,"一次更新需要多久全部生效"这件事就变得很关键。
三层缓存的TTL不该一样长
边缘缓存的TTL(Time To Live)决定了边缘节点要不要回源问"内容更新了没"。源站缓存的TTL决定应用层要不要重新生成HTML。浏览器缓存的TTL决定用户/爬虫端是不是要重新请求。三层TTL如果都设4小时,最长可能有12小时延迟才把更新推全。
对SEO最舒服的配置是边缘短、源站可短可长、浏览器极短甚至禁缓存。原因很简单——你不希望Googlebot在边缘节点拿到4小时前的内容,但希望源站可以把数据库压力分摊掉。具体到秒数:HTML边缘TTL建议60到300秒,资源类(CSS/JS/图)按版本号哈希走长期缓存(一年也行,反正改了文件名)。
浏览器缓存对HTML建议no-store或者private、max-age=0。这点跟"加速"目标看似矛盾,但对一个回头客占比高的电商站,缓存5秒的HTML并不会让用户感觉更慢——RTT本来就只占总加载时间的5%。配合Google抓取频次优化12项实操那篇一起看,能判断TTL变长之后多久会触发Googlebot降频。
HTML缓存的"激进度"到底激进到哪一步才不伤SEO
"激进度"是个非官方说法,用来区分团队在HTML缓存上的胆量。低激进=完全不缓HTML、每次回源;中激进=缓60到300秒、配主动purge机制;高激进=缓几小时甚至几天、靠版本字段或者stale-while-revalidate续命。
低激进对SEO最稳但源站压力大、流量高峰崩盘风险高;中激进是绝大多数中型电商站的最优解;高激进只有内容更新频率极低的资讯站、品牌站可以玩,并且必须配合精准的cache-tag和purge API。
这里有个常被忽略的细节:Cloudflare的Cache Level有"Standard"和"Cache Everything"两档,后者默认会把HTML也缓上。很多客户开了"Cache Everything"以为只是加速静态资源,不知道HTML也被吃进缓存了,结果搜索引擎拿到的全是过期版本。Cache Rules要么明确写HTML不进缓存,要么写明短TTL。
一个真实跨境母婴DTC的过激缓存灾难复盘
2023年第四季度有个客户面临黑五大促前两周突然丢索引,三千多页降到一千五百多。同样还是上面那家母婴DTC,他们临时把所有页面缓存TTL从4小时改成24小时,目的是"扛流量峰值"。改完第二天Googlebot日抓取量掉了70%——因为它发现内容大量返回相同的Last-Modified和ETag,认为没必要再回访。
同一个版本被Google当成"几个不同时间点的同一份内容",加上他们促销页商品状态高频变化,索引器拿到的"已售罄"快照根本不准。两周后大促开了,但搜索流量比上一年下降38%。
处置:边缘TTL改回300秒、Last-Modified按真实数据库变更时间生成、stale-while-revalidate设60秒。三周后抓取量恢复,但促销窗口已经错过。教训是:缓存TTL不能为了"扛峰值"反向加长,扛峰值靠预热+流量控制+源站缓存,不靠延长边缘HTML TTL。
Googlebot与AI爬虫到底走不走CDN?怎么验证它没被错杀?
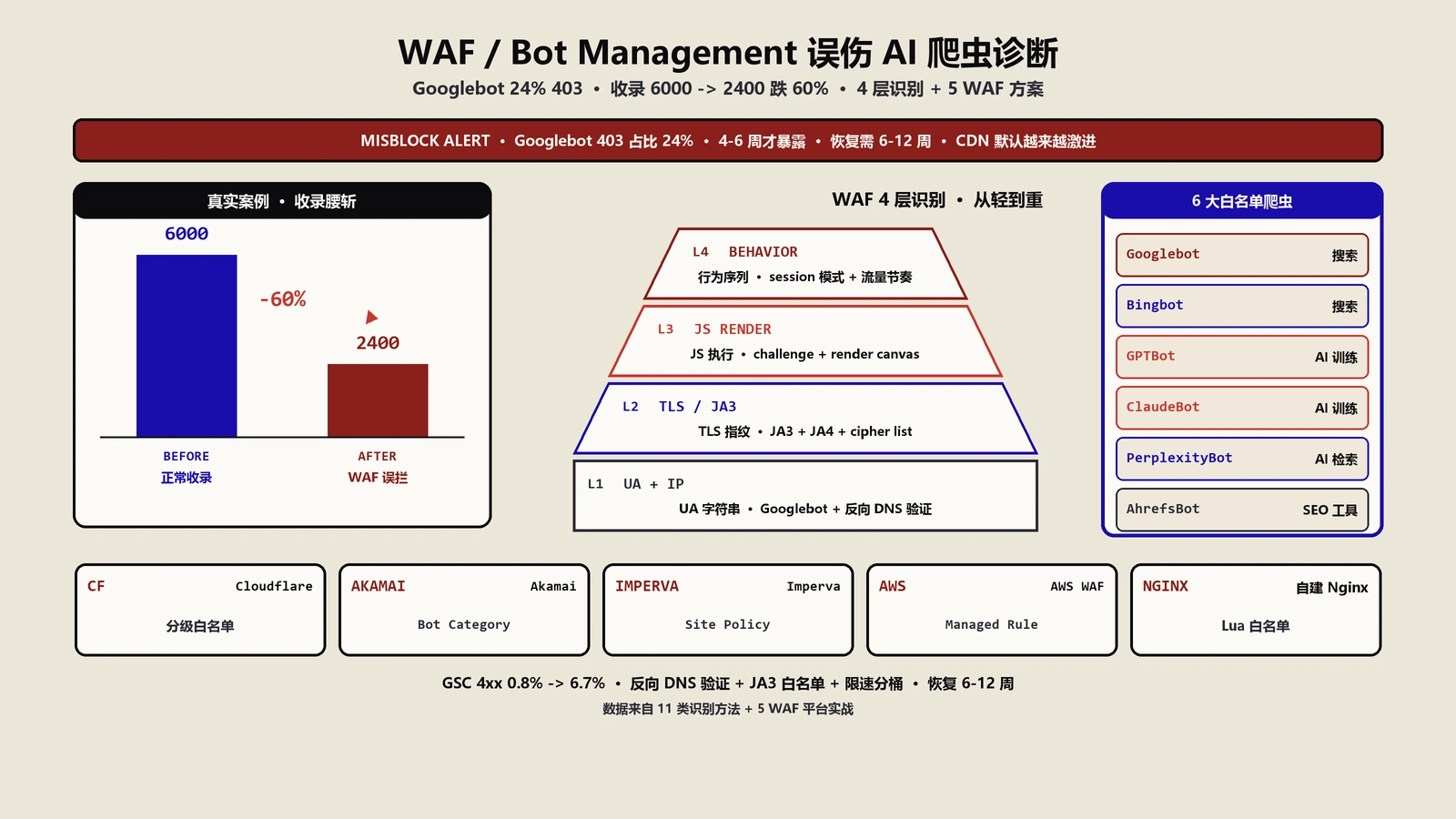
这是CDN+SEO场景里出问题最多、技术团队又最不熟悉的一块。Googlebot发请求过来,先打到CDN边缘节点。这一刻的几个判定,决定它能不能拿到真实页面:UA是不是被WAF识别为bot、IP是不是被列在bot challenge的列表、是不是触发了rate limit、是不是被Bot Management的JS challenge拦下。任何一个判定走错,它就拿不到200。
边缘节点IP分布与Googlebot IP段几乎不重叠
Googlebot的IP段Google官方公布在 developers.google.com的googlebot.json,一个公开维护的JSON清单。这份清单内容动态变化,每周都可能加几条。CDN的边缘节点IP是CDN自己分配的,跟Googlebot IP段几乎零重叠——也就是说,Googlebot永远是"外人"打进CDN,没法靠IP白名单一劳永逸。
这就解释了为什么很多团队在CDN里看到大量"未知bot"流量被拦时,里头很可能就有Googlebot。Cloudflare、Akamai的Bot Management基于行为画像,但行为画像不是100%,误伤是常态。Bot Score低于阈值的请求会被challenge或者block,Googlebot第一次抓你的小站时行为模型还没建好,被误伤的概率不低。
WAF的Bot Management把Googlebot当bot的三种触发
第一种触发:UA伪装识别。CDN会用UA+IP做双因子识别,光看UA说自己是"Googlebot/2.1"是不够的,要IP段对上才算。问题在于很多WAF规则集没维护到最新Googlebot IP段,会把真Googlebot误判成"伪造UA",直接block。
第二种触发:访问频率超阈值。新站上线后被Googlebot集中抓取的那几天,每秒可能有几十个请求打到CDN,rate limit默认值"60次/分钟/IP"会瞬间被打爆。结果就是Googlebot前1分钟正常抓,之后全部返回429。GSC的"抓取异常"会出现一串"5xx错误"或"已抓取但超时"。
第三种触发:Bot Fight Mode开启时的JS challenge。Cloudflare的"Bot Fight Mode"会给所有未识别bot发JS challenge,Googlebot无法执行复杂JS challenge,结果就是拿到的全是challenge page而不是真HTML。这玩意儿在免费版默认就开了,得手动关掉或者明确给Googlebot开"Verified Bot"白名单。
反向DNS验证Googlebot的标准动作
怎么确定日志里那条请求真的是Googlebot而不是别人冒名顶替?Google官方反向DNS验证流程说得很清楚:拿到IP后做PTR查询,得到的hostname必须以"googlebot.com"或"google.com"结尾;然后再正向解析这个hostname,得到的IP必须和原IP匹配。两步都对才算真Googlebot。
这事儿可以在Nginx里用ngx_http_geoip2_module配合PTR查询脚本做实时验证,也可以在日志层用ELK Pipeline离线做。更推荐离线做——实时PTR查询会拖慢响应。爬虫真实抓取偏好的代码逆向那篇里讲过类似手法,配CDN日志一起用最完整。要把这层"中间人"看得更清楚,可以配合搜索引擎抓取索引排名三段机制那篇一起读。
有个客户做B2B工业出海的,2024年初接到内部安全告警说"被Googlebot大规模刷",准备直接ban IP。保哥让他们先做反向DNS验证,结果96%确实是真Googlebot,4%才是冒名顶替的内容采集器。如果当时一刀切ban掉,等于自断SEO供电。验证之后只ban那4%假货,主索引一动没动。
多CDN切换、灰度、并存时的SEO风险点在哪里?
大客户经常用多CDN——海外Cloudflare、国内阿里云CDN、视频走Akamai、图片走腾讯云。多CDN本身是好事,能做容灾、能省钱、能选最优路径。但每多一家CDN就多一层缓存逻辑、一套WAF规则、一份配置漂移风险。
多CDN流量切分时的边缘节点缓存不一致
典型场景:A厂CDN缓了v1版本的HTML、B厂CDN缓了v2版本,DNS轮询或者按地域分流时,Googlebot同一时间从两个不同节点拿到两份不一样的页面。索引器很容易判定"近似重复内容"或"内容不稳定",权重打折。
这事儿没法靠"配相同TTL"解决,因为两家CDN的回源时机、缓存hit/miss不同步是常态。靠谱的解法是:要么主CDN负责HTML、备CDN只负责静态资源(按URL pattern分流);要么所有CDN必须配cache-tag主动purge机制、源站发版时同时调多家CDN的API让缓存同步失效。
CDN切换中301链断裂与canonical冲突
CDN层经常会处理URL规范化——比如把www.example.com跳到example.com、把http跳到https。一旦切换CDN,两家厂商的"自动规范化"规则未必一致。原来A厂CDN把"/category"301跳到"/category/",B厂可能默认不加斜杠,结果Googlebot发现同一个内容存在两个URL,canonical乱了。
更隐蔽的是CDN里设了Page Rule强制改写canonical标签——比如有些团队为了避免移动版和桌面版被判重,在CDN层注入canonical。换CDN之后这条规则没迁移过去,整站canonical集体丢失。这种事儿在切换后两到三周内开始显形,GSC会大批"canonical:未指定"。
一个B2B工业出海客户多CDN踩坑实例
2023年协助过一个做工业泵阀出海的B2B客户,他们因为海外节点不稳定,决定把美洲流量切到Fastly、欧洲流量留Akamai。切完两个月后欧洲产品页排名从平均第4掉到第11。
翻日志发现:美洲Fastly节点的缓存策略保留了原Akamai的TTL=60秒HTML,但canonical注入规则没迁移;欧洲Akamai上canonical注入还在工作。结果美洲节点返回的HTML全部canonical丢失,Google开始把美洲产品页的反向链接权重转移到了不同URL变体。
修复:在Fastly的VCL里补回canonical注入规则、把原TTL改成与Akamai一致的300秒、调GSC的国别定位排除美洲。三个月内欧洲排名恢复,但中间损失订单不下20万美元。教训:多CDN不是配多家厂商就完事,规则迁移要做配置对照表逐条核对,发版日志要打通。
跨境双CDN与多区域部署怎么不损SEO?
做跨境业务的站点,没有CDN几乎跑不起来——国内用户想看美西节点的站,延迟动辄500毫秒,转化率直接打折。但跨境CDN的SEO配置又比单区域复杂得多,因为Googlebot的爬取地区你控制不住,它从哪个数据中心发请求过来你都得正常给页面。
国内+海外双CDN分流的DNS层vs域名层方案
第一种方案:DNS智能解析(GeoDNS)。国内DNS服务商根据用户IP分配到不同节点——大陆用户解析到阿里云CDN,海外用户解析到Cloudflare或Fastly。优点是用户无感、URL不变;缺点是DNS缓存TTL影响切换速度、对Googlebot来说它从美国数据中心查DNS会拿到海外节点,可能跟你的目标用户访问的节点完全不是同一份缓存。
第二种方案:域名层分流。比如cn.example.com走国内CDN、www.example.com走海外CDN。两套URL两套站点用hreflang关联。优点是缓存彻底隔离、可控;缺点是hreflang配置一旦出错整组失效(参考 hreflang国际化SEO完整指南),并且权重分散在两个子域上。
对DTC独立站,更稳的方案是子目录而非子域、保持URL一致性优先(链接权重不分散)。子目录方案配CDN层智能路由(按地域回源到不同源站)能兼顾SEO权重集中和缓存隔离,但配置门槛高,需要懂CDN边缘脚本(Worker、VCL、EdgeWorkers)。
国别访问差异导致Googlebot抓到"错版本"
很多跨境站会做"按访问者IP切换语言/货币/产品库"。如果在CDN层直接返回不同HTML、URL却不变,对Googlebot是灾难——它从美国IP抓,拿到的是美元定价英文版;从印度IP抓拿到的是卢比定价;同一个URL几个版本,Google无法决定该索引哪份。
合规的做法是不同语言、不同货币、不同产品集对应不同URL,CDN层做canonical保护,hreflang告诉Google这些是平行版本而不是重复内容。301跳转必须用客户端真实地理位置(GeoIP)而不是CDN边缘节点位置,否则Googlebot从某个边缘节点抓时直接被301到错的版本。
一个3C配件出海客户香港回源海外节点案例
2024年初有个客户做3C配件出海,主市场是东南亚和欧洲,源站在香港。海外Cloudflare节点遇到东南亚访问时性能差得离谱——TTFB常常800毫秒以上。原因是Cloudflare东南亚节点回源到香港绕了一圈。
解决方案:在新加坡部署一个回源缓存层(用阿里云轻量服务器+Nginx FastCGI cache),Cloudflare东南亚节点先回源到新加坡,新加坡再异步回源到香港。东南亚TTFB从800毫秒降到180毫秒,Googlebot抓取超时率从7%降到0.8%。
SEO收益:东南亚关键词排名平均上升4.2位,Mobile Usability报告里的"加载慢"页面从320个降到41个。这种回源链路优化对SEO的杠杆比单纯调TTL大得多。
主流CDN厂商SEO配置差异在哪里?怎么挑?
六大CDN厂商在国内国外都很常见,但每家对bot的处理、对HTML缓存的默认值、对canonical的支持都不一样。下面这张对照表是保哥这几年帮客户配置时整理出来的核心差异点。
六家厂商Bot Management与SEO敏感设置对照表
| 厂商 | Verified Bot白名单 | HTML缓存默认 | Bot Score可见度 | 边缘脚本能力 | SEO敏感坑 |
|---|---|---|---|---|---|
| Cloudflare | 免费即有、Googlebot/Bingbot默认放行 | 默认不缓、Cache Everything手动开 | 企业版可见、专业版聚合 | Workers全功能 | Bot Fight Mode默认开、误伤新站Googlebot |
| Akamai | Bot Manager Premier付费模块 | 按Cache Key定义、灵活 | 分级Bot Category报表 | EdgeWorkers按调用收费 | 缓存Key默认含设备类型、可能误判移动桌面分版 |
| Fastly | VCL手写规则、放行Googlebot需自己加 | 默认不缓HTML | 有Edge日志、需自己拉 | VCL+Compute@Edge最强 | VCL不熟容易把Vary写错导致Google看到Vary:User-Agent混乱 |
| CloudFront | 需要Lambda@Edge自己识别 | 按Cache Behavior+Origin决定 | 实时日志Kinesis | Lambda@Edge+CloudFront Functions | Cache Behavior多了容易冲突、HTML走错Behavior缓4小时 |
| 阿里云CDN | 百度蜘蛛/谷歌蜘蛛白名单可配 | HTML默认不缓、文档可配 | 需要单独买阿里云盾WAF模块 | EdgeRoutine(限商业版) | "伪静态加速"开关常被误开、HTML也进缓存 |
| 腾讯云CDN | Bot防护模块按需开 | HTML默认不缓 | Web应用防火墙报表 | 边缘函数(SCF on Edge) | "全站加速"和"内容分发"两条产品线规则差异大、切换时易漏 |
这张表里的"SEO敏感坑"那列才是真正决定踩不踩雷的关键。买什么版本、用什么模块都是次要的,关键是把每家厂商默认开关里那个会误伤Googlebot的开关找出来手动关掉,或者明确白名单放行。
国内CDN必备的备案与回源配置坑
国内CDN绕不开备案。源站如果在境外,CDN要在国内分发就必须走"国际CDN"产品线,不需要备案但费用高、节点少。如果源站在境内,备案是硬门槛,备案号变更或者失效会导致整个CDN加速立即停止——这事儿一旦发生,整站从Googlebot到百度蜘蛛全部拿到关停页。
回源配置上,国内CDN默认会强制HTTPS,源站如果还跑HTTP,CDN会做边缘HTTPS+回源HTTP。这个组合对SEO有个隐藏坑:Googlebot能看到HTTPS版本,但内部链接如果是HTTP的相对路径,会出现mixed content警告。建议源站直接上HTTPS、CDN透传,省掉协议转换中间层。
一张厂商挑选决策矩阵
跨境出海、源站在境外、技术团队懂VCL/Worker:选Cloudflare或Fastly。Cloudflare胜在生态完整、免费额度大;Fastly胜在控制力、缓存策略最灵活。
大型企业、合规要求高、要做精细化Bot分类:选Akamai。贵但稳定、行业认证齐全。中小型出海团队不必上这一档。
国内业务为主、有备案、要兼顾百度SEO:选阿里云CDN或腾讯云CDN。两家差异不大,看公司云资源生态。腾讯云在"全站加速"上HTML加速比阿里云激进,慎用。
跨境+国内双业务:双CDN方案(前面H2-5讲过的两种),不要试图用一家厂商一把抓——没有任何一家在国内外都最优。
CDN出故障时SEO防御怎么做才不掉量?
CDN厂商会宕机。Cloudflare 2022年7月那次全球宕机1.5小时,影响几百万个站点;Fastly 2021年6月那次半小时把Reddit、Amazon、GitHub一起带下线。这种事儿对SEO的影响不止"用户访问不了"——Googlebot那一刻抓你网站,拿到的是503或者timeout,会触发抓取频率自动降级。
故障三类信号:抓取404峰vs 503峰vs软404峰
第一种:CDN返回404峰。常见于CDN配置漂移、源站迁移没同步、回源URL映射错。Googlebot连续几小时拿到404会把对应页面打上"已下线"标记,恢复后还要重新申报。日志里看就是GSC"已发现404"骤升。
第二种:5xx服务端错误峰。多数是回源失败或CDN本身宕机。Google对5xx的容忍度比404高——它会理解为"临时不可用",几小时内不会降权。但持续超过24小时的5xx会被判定为"长期不可用"。
第三种:软404峰。CDN在故障时返回的"自定义错误页"经常用HTTP 200状态码。Google抓到的页面长得像错误,但状态码是200,索引器会把"sorry我们出了点问题"这种页当成内容索引进去。这种软404对SEO的杀伤力最大、最难恢复。
灾备DNS切换的TTL机制与回源备份
CDN宕机时的灾备方案:DNS切换到备用CDN或者直接指向源站。这事儿的关键是DNS的TTL——主CDN的解析记录如果TTL=86400,切换之后整一天里部分DNS递归服务器还在缓存旧解析,Googlebot可能还是访问到挂掉的CDN。
对SEO敏感的站点,CDN层CNAME记录TTL建议设到120秒到300秒,平时不影响性能,关键时刻能在5分钟内完成全网切换。代价是DNS查询频次略增,但相对于宕机损失完全不算什么。
另一条防御线是源站直链兜底。在CDN前面加一层GLB(全局负载均衡),CDN挂时GLB自动绕过CDN直连源站。需要源站有足够带宽承接突发流量,对中型站这是性价比最高的灾备投入。
一个DTC家居站CDN瘫机12小时的GSC流量曲线复盘
2024年一家DTC家居客户,主CDN某个深夜突然瘫了12小时,技术值班晚发现4小时,灾备DNS切换又因为TTL=3600拖了大半天才生效。整个故障窗口里Googlebot抓了3.7万次,6成拿到504/502。
GSC流量曲线表现:故障当天点击量正常(因为DNS缓存让用户还能访问),故障后第三天点击量掉28%,第七天最低点掉45%。原因是Googlebot把那批504/502当作"页面不稳定",重新评估页面在SERP的可见度。
恢复路径:用GSC的"URL检查"对核心商业页逐条提交重新索引、把站点地图重新ping一遍、把Server Log里所有故障期间被抓的URL导出来做异常报告。三周后流量回到故障前80%,五周回满。中间损失订单约15万美元,相当于一次"小型核心更新"级别的灾难。教训是DNS TTL在SEO看来不只是性能数字、是灾备速度的决定项。
把CDN和SEO两条线打通的8项配置清单
把前面六个H2讲的都收成一张可执行清单,给你和团队做发版checklist用。每一项后面那个时间是建议每次发版后或者每季度审计要花的时间。
- HTML边缘TTL限定60到300秒、配合主动purge机制——发版后立即调CDN purge API、不依赖TTL自然过期(每次发版10分钟);
- Verified Bot白名单核对Googlebot/Bingbot/Baiduspider/SOGOU/Yandex/AI Crawlers列表,Bot Fight Mode类的默认开关明确关闭(每季度30分钟);
- 反向DNS验证脚本部署在日志层,定期跑全量日志识别假冒Googlebot、白名单合法bot(每月1小时);
- canonical注入规则、HTTPS强制、URL规范化(斜杠、大小写)等边缘脚本明确归档,多CDN环境下做配置对照表逐条比对(CDN切换时1天);
- 404/5xx/软404错误页一律返回正确状态码(404=404、5xx=5xx、不要返回200错误页)、配合CDN边缘的客户化错误模板(每次错误页改版后30分钟);
- DNS TTL对CNAME记录限定120到300秒、确保灾备切换5分钟内全网生效(一次性配置);
- 跨境多区域部署用子目录+hreflang+CDN层地理路由,不要用URL层GeoIP重定向(架构期决策、改动成本最大);
- 每月一次CDN日志+源站日志+GSC抓取统计三方对账,识别"CDN吞掉的抓取量"——CDN日志显示Googlebot来过、源站日志没看到、GSC统计也没记录,说明边缘层吃下了请求没传给Google(每月2小时)。
这8项不是一锤子买卖,是发版节奏里要嵌进去的常态动作。CDN配置漂移是隐形的SEO杀手,一年下来如果没人盯,差不多三五项会悄悄走偏。
常见问题解答
CDN会直接影响Google搜索排名吗?
不会直接影响。CDN作为中间层不在Google的排名因子里。但它通过页面加载速度(Core Web Vitals)、抓取可达性、内容一致性这三条间接路径影响排名。配错的CDN比没CDN更伤SEO。
开了Cloudflare之后GSC的抓取统计变慢了,是CDN的问题吗?
大概率是。Cloudflare的"Bot Fight Mode"默认开启会给Googlebot发JS challenge,Googlebot拿不到真HTML、Google判定抓取效率低、自动降低抓取频次。解决:到Security>Bots里关掉Bot Fight Mode,或者在Verified Bots列表确认Googlebot在白名单。
国内站套CDN会被百度认作多IP从而判定作弊吗?
不会。百度对CDN的处理跟Google一样、把CDN边缘节点当作合法分发节点。但如果你的CDN配置导致同一URL返回不同内容、不同canonical、不同TDK,那才是判作弊的真正原因。配CDN前先在百度搜索资源平台把网站类型和归属确认好。
Page Rule把HTML缓存设了1小时,Google会更新慢一截吗?
会。Googlebot抓取频率虽然有"重新抓取"机制,但对长期不变的HTML它会显著降低抓取频次。1小时TTL对促销页、库存页、新闻页都太长。建议HTML边缘TTL不超过300秒、配主动purge。
多个域名共用一个CDN账号,会被Google判作站群吗?
不会。判站群靠的是内容相似度、内链结构、所有权信号,CDN账号同源并不是判定信号。Cloudflare、Akamai这种厂商一个账号挂几十个域名再正常不过。但如果多个域名共用同一CDN账号且做了交叉内链、相似度高内容,那是真的会被判站群、跟CDN无关。
CDN跨境跳转IP解析得到不同节点,会让hreflang失效吗?
不会让hreflang失效,但可能让Googlebot拿到"错的版本"。hreflang本身只是页面级标签,不被CDN影响。但如果CDN在边缘按IP区分返回不同HTML(同一URL两份内容),Google看到的版本可能跟hreflang声明的不一致。解决:让CDN对所有Googlebot请求返回同一份"默认版本"内容、用301跳转去做地理区分、用hreflang关联各版本。
切完CDN之后是不是该把所有内链改成HTTPS?
如果原来站点已经全HTTPS,CDN层只是套了一层,那内链不用改、保持站内绝对路径或者相对路径HTTPS就行。如果原来站点是HTTP、CDN层做HTTPS终止+回源HTTP,那源站HTML里的相对路径会变成HTTPS(CDN边缘改写),但绝对路径的HTTP内链需要批量改成HTTPS或者协议相对(//开头)以避免mixed content。
权威参考资料
本文标题:《CDN对SEO到底有什么影响?6层缓存与边缘路由实战》
本文链接:https://zhangwenbao.com/cdn-cache-configuration-seo-impact-edge-routing-complete-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0