程序化SEO怎么做不被算法当薄页?三要素实战
本文目录
- 程序化SEO到底是什么?
- 三要素:词库、数据源、模板
- 三要素中数据源是命门
- 和“内容工厂”的边界
- pSEO和内容工厂的本质差别在哪?
- 区分点是“每页独有数据”
- Google看见的是什么
- 和内容工厂兄弟篇的边界
- 把pSEO当数据资产复用,不是文字批量生产
- 什么生意适合做pSEO?
- 五类高适配场景
- 五类典型陷阱场景
- 判定矩阵
- pSEO的词库怎么搭?
- 从笛卡尔积出发
- 剪枝的三个条件
- 剪枝后的现实分布
- 词库工程化:用数据库不用Excel
- pSEO的数据源怎么找才合规?
- 自有数据:最稳但最少
- 公开数据:合规且海量
- 采集数据:灰色地带
- 真实案例
- pSEO模板怎么设计才不被判薄页?
- 差异化锚点至少三层
- 模板共用元素的安全比例
- 动态FAQ与动态表的设计
- 反模式:换词不换数据
- 模板的可读性与AI抽取友好兼顾
- 多语言pSEO的额外坑
- pSEO在HCU时代还能不能做?
- HCU专项做了什么
- HCU之后存活的三条件
- HCU打pSEO的具体信号
- 真实案例:合规pSEO在HCU之后涨
- 怎么决定pSEO项目要不要继续推?
- 信号一:单页收益小于单页成本
- 信号二:长尾密度过度集中
- 信号三:HCU或核心更新后的曲线
- 项目终止判据
- 终止不等于失败
- 启动6个月内的关键里程碑
- 大规模pSEO的工程化挑战有哪些?
- 索引控制:不要一次放完
- 抓取预算的分层管理
- 质量回归的自动化监控
- 团队配置:开发+SEO+运营三角
- 预算分配的经验比例
- 外包能否做pSEO
- pSEO和AI Overviews怎么并存?
- AI Overviews偏爱的pSEO块
- 可被引用的pSEO块设计
- 引用换流量还是引用换品牌
- 真实数据
- 常见问题解答
- 程序化SEO和内容工厂的根本区别是什么?
- 什么生意适合做程序化SEO?
- 什么场景做pSEO一定会翻车?
- pSEO的词库怎么搭?
- pSEO的数据从哪来才合规?
- pSEO模板怎么设计才不被判薄页?
- pSEO在HCU有用内容系统时代还能不能做?
- 怎么决定pSEO项目要不要继续推?
- 权威参考资料
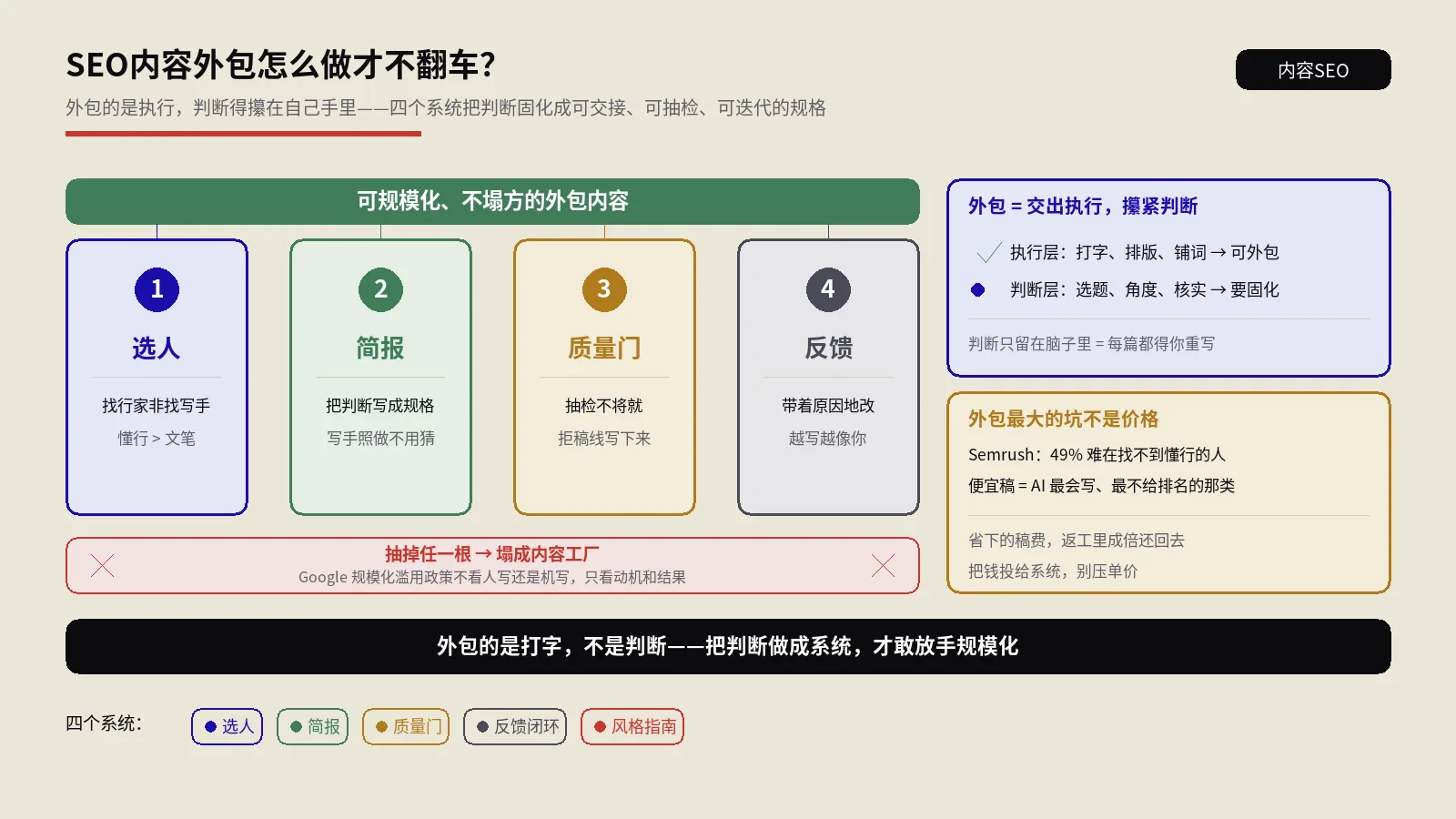
摘要:程序化SEO(pSEO)和内容工厂不是一回事,但90%的中文SEO圈把这两件事混着用,结果就是看到的反面案例多、做对的真实案例少。pSEO本质是用一套模板复用每页独有的稀缺数据,三要素是词库×数据源×模板。三条缺一条都塌:词库没意图、数据没独有性、模板没差异化。
HCU之后这件事的门槛被抬得很高,但并没有死。存活下来的pSEO项目都满足三个硬条件:单页对应真实长尾查询、单页注入了独有数据、生成节奏与索引控制配对。本文给适合判定矩阵、剪枝公式、五类典型陷阱、HCU存活三条件、单页收益账与可被AI Overviews引用的pSEO块设计。
程序化SEO在英文圈被Sahil Lavingia、Tim Soulo这些人讨论过很多次,从Nomad List到Zapier App Directory到G2的对照页,都是已经被验证有效的范式。在中文圈这件事被广泛误读,多数人把pSEO等同于“用AI批量生成长尾页”,于是2023到2024年那一波pSEO热潮过去之后,留下的是一堆HCU之后被打到的项目和“pSEO已死”的论断。这两件事都是错的——错的是做法,不是范式。
下面把pSEO的机制拆透:它和内容工厂的差别在哪、三要素怎么搭、什么生意适合做、什么场景会翻车、HCU之后还能不能做、怎么决定项目要不要继续推。
程序化SEO到底是什么?
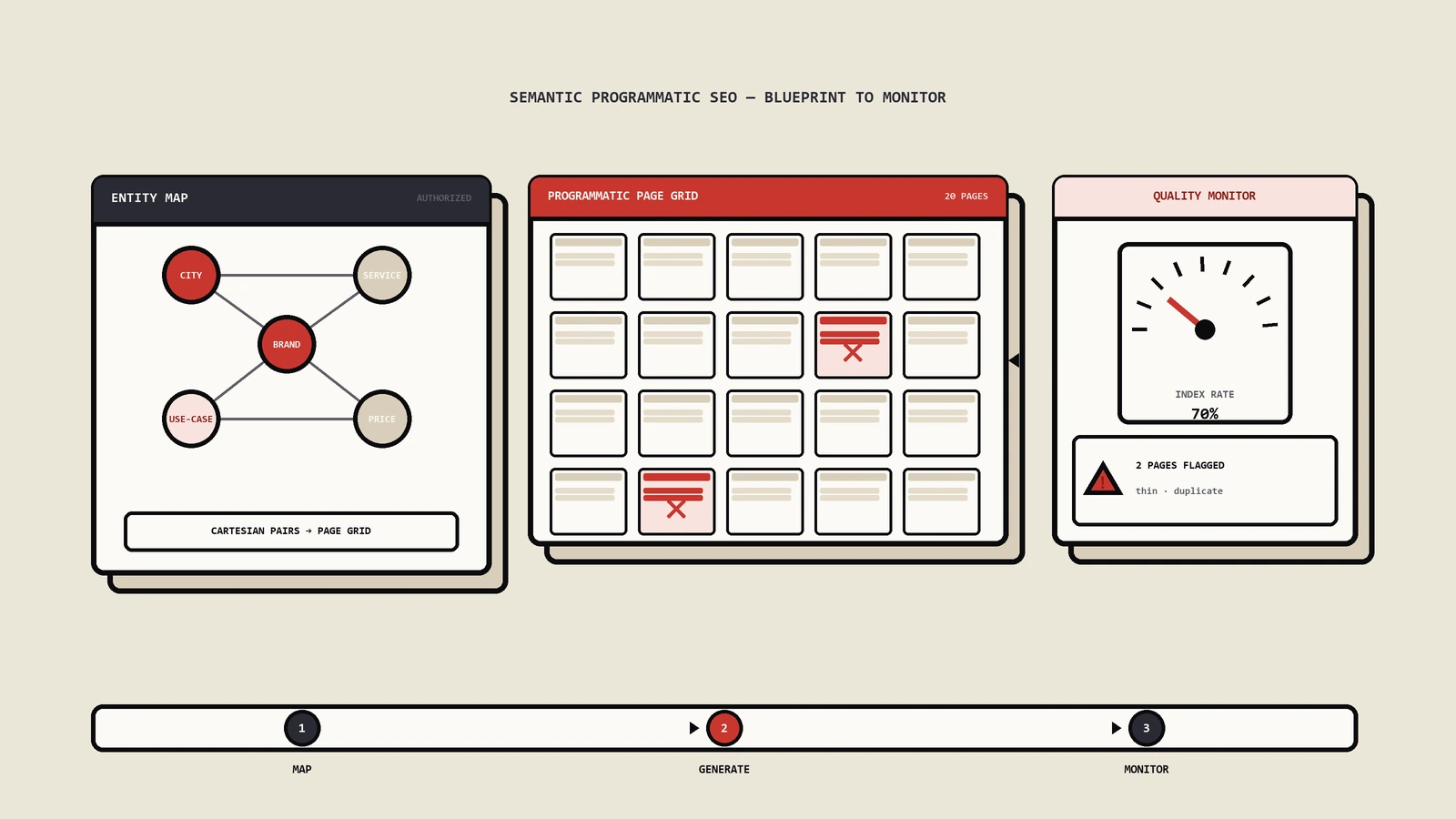
不严谨的说法是“用模板批量生成页面做SEO”——这个描述把pSEO和内容工厂、AI批量改写、关键词页面注水混成了一类。严谨的说法是:用一套页面模板,针对一个有规则的查询意图矩阵,每页注入独有的、真实的、对用户有具体价值的数据,规模化生成可索引的着陆页。
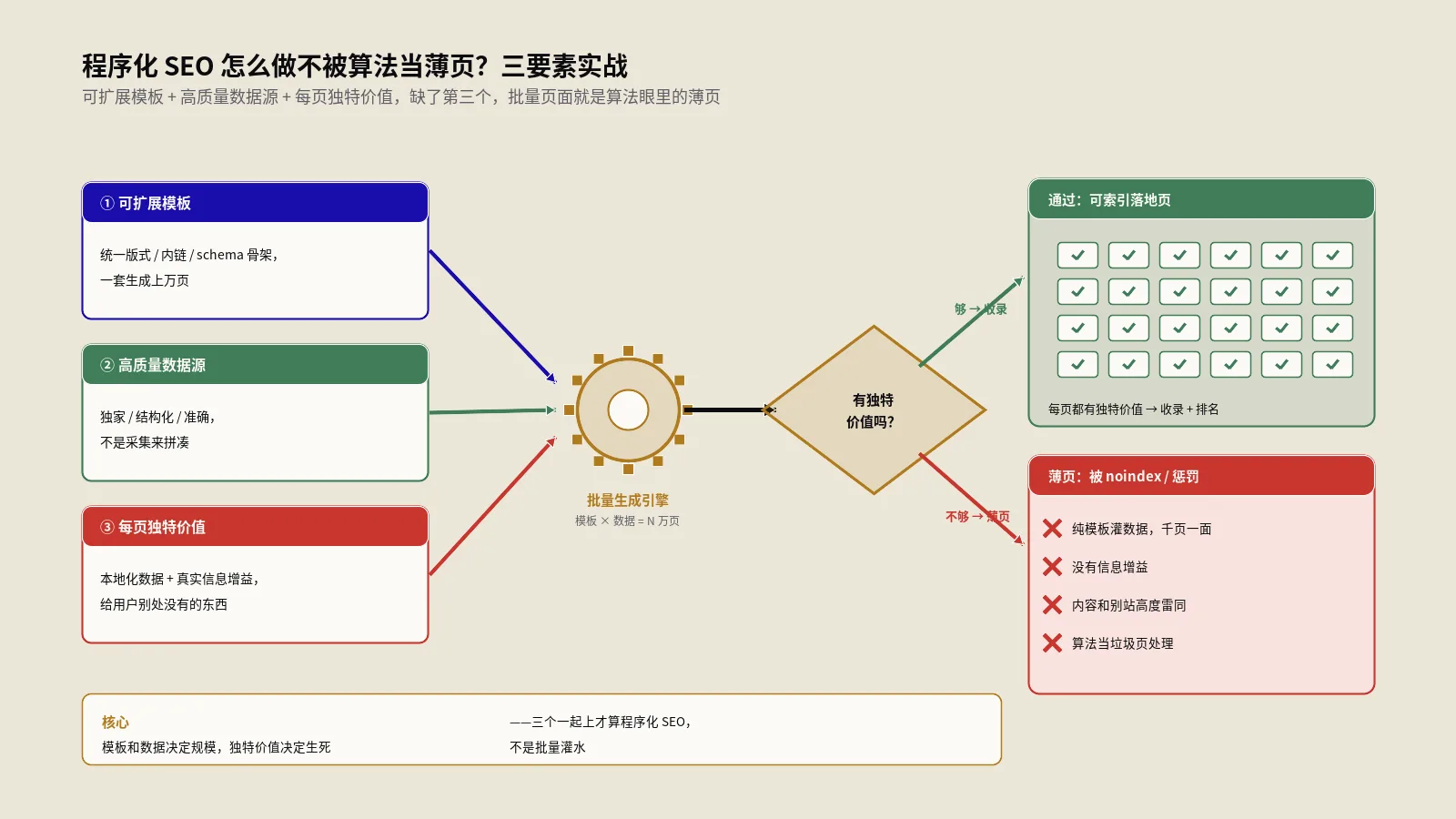
三要素:词库、数据源、模板
pSEO永远是这三件事的组合:
- 词库:一组按规则可枚举的查询意图。规则通常是2-4个维度的笛卡尔积,比如“城市×服务类型”“产品类型×对比品牌”“工具名×集成对象”。维度的关键是每个维度的取值组合都有真实搜索量。
- 数据源:每个词库节点对应的独有数据。比如比价站每个城市每个服务的真实价格区间、招聘站每个职位每个城市的薪资分布、工具站每个参数组合的真实计算结果。
- 模板:把数据按一致的版式渲染成页面的脚手架。模板的差异化能力决定了Google看到的是“一万页内容”还是“一万份模板复制”。
三要素中数据源是命门
没词库做不出页面,没模板做不出规模,但没数据源就只能做出薄页。判断一个pSEO项目能不能做下去,第一个问题永远是:你这一万页中每一页都有真实独有的数据吗?没有就立即停。这条比任何工具选型都重要。
和“内容工厂”的边界
内容工厂是用模板套生成同质化文字,每页对用户的边际价值为零;pSEO是用模板复用每页独有的稀缺数据,每页对应一组真实查询意图与数据答案。两者在工程层面看起来都是“批量”,在用户层面价值差异巨大。Google的HCU、SpamBrain、PageRank-style信号叠加之后,对“同质化”的识别能力已经远超关键词层。
pSEO和内容工厂的本质差别在哪?
这条很多人答错。常见错误答案:内容工厂用AI、pSEO用模板。错的,两者都可以用AI或模板,区分点不在工具。
区分点是“每页独有数据”
把任意两页内容并排放,问一个外行用户:这两页有什么不同?
- 如果答案是“只有标题里几个词不同,内文几乎一样”——那是内容工厂。
- 如果答案是“标题不同、内文核心数字/事实/参数都不同,且这些差异对我的决策有意义”——那是pSEO。
Zapier的“X与Y如何集成”页面是典型pSEO——每页讲两个具体软件如何对接,配什么trigger、什么action,截图、链接、流程都不同。同样模板,一万页,每页都独立有用。一个伪pSEO示例:“XX城市XX服务推荐”,每页只是把城市名替换、推荐列表是同一份全国通用——这是内容工厂。
Google看见的是什么
Google的内容相似度比对不是文字层的暴力字符比对,是嵌入向量空间的语义相似度。文字稍变、数字稍换,Google看得到模板复制;只有当独有数据真正承载了核心价值,向量空间里才会被识别为独立内容。这就是为什么单纯换词、换标题、AI重写都骗不过去——HCU之后这件事被进一步强化。
和内容工厂兄弟篇的边界
内容多发布SEO时代过去了那篇是从反面讲“为什么AI批量内容会被算法清”。本文从正面讲“pSEO在算法允许的边界内怎么做”。两件事是同一币的两面:内容工厂死了,pSEO仍然活着,因为后者每页都有数据稀缺度做地基。
把pSEO当数据资产复用,不是文字批量生产
这是pSEO最常被误读的一点。pSEO的目标函数不是“多发文章”,是“把同一份独有数据的价值复用到多个查询意图上”。Zillow的每个房源页是同一份MLS数据按城市/邮编/小区/价格区间多维度切片;Skyscanner的每个航线页是同一份航班数据按出发城市/到达城市/季节切片。底层数据没变,但每个切片对应一个独立的搜索意图,因此每页都有人搜、每页都有用。把pSEO当数据资产复用之后,团队角色和工程做法都会变——数据团队成为pSEO项目的核心,不再是“内容团队多招几个写手”。
什么生意适合做pSEO?
不是所有生意都适合。我见过的失败案例里,约一半是“生意本身不适合pSEO但硬上”导致的。先看适合的五类。
五类高适配场景
| 类型 | 典型站 | pSEO维度 | 独有数据 |
|---|---|---|---|
| 比价/聚合 | NerdWallet, ConsumerAffairs | 产品×维度×地区 | 实时价格、用户评价分布 |
| 本地服务 | Yelp, Thumbtack | 服务×城市×需求 | 本地商家列表、价格区间 |
| 工具计算器 | OmniCalculator | 计算类型×场景×输入范围 | 每页一组真实计算结果 |
| 招聘/房产/票务 | Indeed, Zillow, Skyscanner | 类目×位置×筛选条件 | 实时职位/房源/航班数据 |
| SaaS集成/对照 | Zapier, G2 | 工具×对照对象/集成对象 | 每对组合的真实集成路径 |
这五类的共同特征:用户需求维度组合多(百到万级)、每个组合有真实长尾搜索、每页有独有真实数据。三个条件叠加,pSEO才有机会做出价值。
五类典型陷阱场景
反过来五类是陷阱:
- 纯品牌词或单一服务:维度不够(只有一个),凑不出pSEO的笛卡尔积。
- 非标品+主观决策:比如奢侈品、艺术品、定制服务,决策因子主观、长尾搜索意图弱,pSEO效率低。
- 查询意图被Google直接给答案:比如汇率转换、单位换算这类Google直接给答案的,做了pSEO也拿不到点击。
- 纯内容站非数据站:比如新闻博客类,没有独有结构化数据可注入,做模板等于内容工厂。
- 低毛利+高获客成本:pSEO要有工程投入,单页收益<单页成本时项目活不下去。
判定矩阵
合并适合与陷阱的判据,给一张项目立项前必做的快速判定矩阵:
| 判据 | 合格阈值 | 不合格意味着 |
|---|---|---|
| 查询维度数 | ≥2,理想3-4 | 维度=1做不成笛卡尔积 |
| 每维度有效取值 | ≥30 | 组合空间太小,不需要程序化 |
| 每组合搜索量 | P50≥10/月 | 大部分组合是死页 |
| 每页独有数据 | 至少3-5个差异字段 | 少于这个数会被识别为模板复制 |
| 单页收益预期 | ≥单页运维年成本 | 项目长期不可持续 |
pSEO的词库怎么搭?
词库的本质是“一组按规则可枚举的查询意图”。规则一定,词库就一定,工程上是数据库表,不是关键词列表。
从笛卡尔积出发
先定维度。最常见是2-4个维度。比如城市(300个)×服务类型(50个)=15000个组合;产品类型(200个)×对比品牌(50个)×对比维度(10个)=100000个组合。组合空间一旦上百万,必须剪枝,否则索引控制、抓取预算、内容质量三条全炸。
剪枝的三个条件
剪枝公式:保留组合 = 有真实搜索量AND有商业价值AND不重叠现有内容。
- 有真实搜索量:用GSC、Ahrefs、Semrush拉每个组合的月搜索量,砍掉0搜索量的“死组合”。这一步通常能砍掉50%-70%。
- 有商业价值:保留信息意图+商业意图+交易意图的,砍掉纯信息意图但无变现路径的。
- 不重叠现有内容:与站内已有页面做语义重叠度比对,重叠度>0.7的合并不新建,避免自相残杀。
剪枝后的现实分布
实操中100万原始组合剪到3-5万可生成页是常见区间。前1%页面贡献60%流量、前10%页面贡献90%流量是经验值。剩下90%页面可能只贡献10%流量——但这90%页面如果数据真实独有、运维成本可控,仍然该留,因为它们撑起了主题权威与AI抽取覆盖。
词库工程化:用数据库不用Excel
5000条以上的词库不要用Excel管理,会出问题。建议用一张数据库表,每行一个组合,字段包含维度值、搜索量、商业价值分、状态(待生成/已生成/已下线)、单页绩效(impressions、clicks、conversions)。这张表本身就是pSEO项目的中心账本。
pSEO的数据源怎么找才合规?
数据是pSEO的命门,但数据来源也是pSEO项目最容易踩法律雷的环节。常见的三类来源各有不同的合规边界。
自有数据:最稳但最少
用户上传、平台行为、交易记录、自有专业判断——这些都是自有数据。最大的优势是无法律风险、独有度高、Google难以伪造。劣势是数据量受限于业务规模,新平台几乎没有自有数据可用。这一类适合已经有一定用户基础的SaaS、电商、社区类产品做pSEO。
公开数据:合规且海量
政府开放数据(GDP、人口、犯罪率、教育资源)、官方API(汇率、天气、航班、运动赛事)、可Crawl的标准化数据(维基百科、开源软件文档)——这些都是公开数据。合规且海量,是出海站和工具站最常用的pSEO数据源。注意:
- 政府开放数据要看许可证条款,多数是CC-BY/CC0可商业使用。
- 官方API要看ToS,多数允许付费商业使用但禁止再分发原始数据。
- Crawl公开网页要遵守robots.txt和ToS,不能绕过反爬虫。
采集数据:灰色地带
从竞品、第三方平台、社交媒体采集数据——这类合规风险最高。被采集方一旦提起诉讼,pSEO项目可能直接死掉。我的经验值:项目早期可以做小规模采集做验证,规模化生产期前必须切换到合规数据源。规模上去后维权风险是非线性翻倍的,单个站做小规模采集没事,每月10万页规模化采集会被精准盯上。
真实案例
有家做在线教育SaaS的客户站,2022年用pSEO做“城市×学科×机构对比”页,跑了三个月发现单页收益还不错。问题是数据源是从竞品平台采集的,规模做到5万页时收到了对方的律师函。最后项目下线、把5万页全部301到主站、白做了半年。教训写在词库表的最前面:数据合规度也是剪枝条件之一。
pSEO模板怎么设计才不被判薄页?
模板设计是pSEO项目的核心工程。差异化不到位的模板会被Google识别为模板复制,全项目跟着塌。
差异化锚点至少三层
合格的pSEO模板必须在三个层级做差异化:
- 标题层:H1按字段动态生成,且生成出的标题必须对应真实搜索意图。不要简单做“词A+词B”拼接,要按用户的查询习惯做语序与连接词调整。
- 内容层:每页注入≥3-5个独有数据字段。比价站要有真实价格、招聘站要有真实薪资分布、本地站要有真实商家列表。这些数据必须能被用户直接验证。
- 结构层:按字段值动态调整H层级、表格行数、FAQ。同一模板,纽约的页面H2有6个、底特律的页面只有3个,因为底特律的服务密度低,不需要凑那么多H2。
模板共用元素的安全比例
不是所有元素都要差异化。导航、页脚、面包屑、相关链接区是模板共用的,这部分被Google理解为站点共用结构、不算重复内容。但首屏H1-首屏第一段的前30%必须独有,否则会被识别为模板复制。我的工程经验值:独有内容占整页字数的比例不能低于60%-70%,否则HCU之后会被标记为薄页。
动态FAQ与动态表的设计
FAQ是pSEO模板里最能拉差异化的地方。同一模板,按字段值动态生成不同FAQ问题与答案。比如本地服务pSEO,纽约的FAQ可能讨论“纽约市5区有什么地区差异”,亚特兰大的FAQ可能讨论“亚特兰大都市圈外的覆盖问题”。这种动态FAQ既是差异化锚点、也是FAQPage JSON-LD的天然素材,AI Overviews引用率高。
反模式:换词不换数据
最常见的失败模板:用一个通用文本,把里面的城市名/产品名/品牌名换一下就当做新页。我见过一个出海招聘项目,模板就是“在[城市名]找[职位名]工作怎么样?”,下面接的是同一份全国通用内容。做了2万页,6个月后被HCU清掉95%。教训写在墙上:差异化不到字段层就不要做pSEO。换词不换数据,本质是用工程手段做内容工厂——HCU之后等于自杀。
模板的可读性与AI抽取友好兼顾
pSEO模板还有一个易被忽略的设计点:模板生成出来的内容必须人读得动,不能只追求“关键词全覆盖”。常见错误是为了塞关键词把H2全写成“XX在YY的ZZ怎么样”这种关键词堆砌句。读者扫一眼觉得很怪、跳出率高。合规做法是写自然问句,把维度值放在问句的合适位置而不是堆在标题前缀。模板里每一个动态字段插入点都应该过一遍“这句话人读起来顺不顺”的人测。
多语言pSEO的额外坑
出海pSEO常做多语言版本,每多一种语言就是组合数翻倍。这里有个隐藏成本:翻译质量决定每页是否真的对当地用户有价值。机翻直接上的pSEO页面,HCU之后掉得最快——因为机翻文本在向量空间里离原文相似度过高,被识别为低质重复变体。多语言pSEO要么人工译要么用专业领域微调过的MT,再要么干脆只做核心几种语言。
pSEO在HCU时代还能不能做?
能做。2022年HCU上线、2023年9月HCU专项更新打掉一批pSEO站之后,行业里流行“pSEO已死”的说法。但实际数据是:合规且有数据稀缺度的pSEO项目仍然在涨,被打掉的全是“pSEO伪装的内容工厂”。
HCU专项做了什么
2023年9月Google上线HCU专项更新,主要打击三类站:纯AI生成的“伪原创聚合”、模板套生成的无独有数据pSEO、site reputation abuse(站点权威被借给与主题无关的薄页)。pSEO项目要重点关注前两类。HCU有用内容系统那篇讲过HCU的识别机制与恢复路径,本文重点在pSEO视角下的存活条件。
HCU之后存活的三条件
- 单页对应真实长尾查询。每页都有用户在搜(即便是月10次的小搜索量也算),不是凭空生成的。
- 单页注入了独有数据。前面讲过的≥3-5个差异字段,且这些字段对用户决策有具体价值。
- 生成节奏与索引控制配对。不是一夜放10万页,是按周或按月分批放、放完观察索引率与流量曲线再决定是否继续放下一批。
三条任一不满足,HCU之后大概率被清。三条都满足的项目,HCU之后反而更稳——因为竞争对手被清掉了一波,SERP空间被空出。
HCU打pSEO的具体信号
从被打的项目复盘,HCU识别pSEO问题站的几个主要信号:
- 同模板下的页面在文本嵌入向量空间里聚得太紧(语义重复度过高)。
- 大批pSEO页面的GSC平均停留时长低于站点中位数(用户不读)。
- pSEO页面的反链结构异常稀疏(没人愿意链接)。
- pSEO页面的索引率长期低于50%(Google看了不想收)。
这几个信号反过来就是合规pSEO的自检清单:模板差异化、停留时长接近站点中位、能拿到部分自然反链、索引率≥70%。
真实案例:合规pSEO在HCU之后涨
有家做出海招聘的SaaS站,2021年开始做pSEO,到2023年HCU专项之前有约15万索引页。HCU之后这家站的索引页数没动,但流量反而涨了18%。原因是同赛道的两个竞品(伪pSEO,每页只换城市名)被清掉了70%页面,SERP空间空出来,他们的合规页吃到了之前被竞品占的位置。这是“pSEO存活下来”的典型剧本。
怎么决定pSEO项目要不要继续推?
项目跑起来之后,最难的决策是“继续推还是回炉”。这两个信号一出现就要慎重。
信号一:单页收益小于单页成本
把所有页的月度自然流量×CR×AOV算出来,除以页数,得到“单页月收益”。把生成、维护、内链管理的人力时间折算成钱,除以页数,得到“单页月成本”。如果单页收益<单页成本,且这个比值持续3个月不改善,项目不应该继续放新页,应该回炉看模板和数据是否需要重构。
信号二:长尾密度过度集中
健康的pSEO项目流量分布大约是“前10%页贡献60%流量、后90%页贡献40%流量”。如果实际是“前5%页贡献95%流量、后95%页几乎死页”,那意味着剪枝过粗、词库选错了维度。这种情况下不要继续放量,先重新剪枝,把死页下线或noindex,再重新设计词库。
信号三:HCU或核心更新后的曲线
每次Google核心更新之后48-72小时观察GSC曲线。如果pSEO页面的曲线掉幅大于全站非pSEO页面,说明你的pSEO项目处在算法的“边界带”,HCU之后会被反复扰动。这时候应该收缩页数(保留前30%高表现页、其他下线),把模板和数据进一步打磨之后再考虑放量。
项目终止判据
三条任一持续6个月以上的,应该考虑终止:
- 单页收益<单页成本,且新数据源无法接入。
- HCU/核心更新后多次掉幅持续,模板优化无效。
- 词库的笛卡尔积空间已被同赛道大型平台覆盖(如aggregator类巨头进场)。
终止不等于失败
pSEO项目终止常被团队当成耻辱,其实是健康决策。Zillow、Airbnb、Skyscanner这些今天看起来是pSEO范本的站,背后都有多个被关掉的pSEO实验。关键是终止后的资产处置:高表现页保留并接入主体业务,中等表现页301到最相关的分类页,低表现页直接410下线。301整体打包到主域名首页是最差做法——会被Google识别为操纵性redirect、伤主域名权重。
启动6个月内的关键里程碑
正常推进的pSEO项目,6个月内应该见到以下里程碑:第4-6周首批生成页(500-1000页)索引率>=60%;第8-10周首批页开始有自然流量进来;第12周GSC平均CTR>=1.5%;第16-20周首批页面开始有自然反链;第24周单页收益与单页成本比值>=2。任何一个里程碑落后2-3周以上,应当回炉检查,不要靠继续放量来掩盖单页质量问题。
大规模pSEO的工程化挑战有哪些?
把模板写完只是开始。规模上百万页之后,几个工程问题不解决,项目会从内部塌。
索引控制:不要一次放完
把10万页一夜推上线是pSEO项目最常见的死法。Google看到突然多出10万页,会有几种反应:拒收(索引率<30%)、低质评级(核心更新被打)、抓取预算饥饿(重要页反而不被抓)。合规做法是按周或按月分批放,每批3000-10000页,放完观察索引率与GSC质量信号再放下一批。
抓取预算的分层管理
规模上去后必须做抓取预算分层。前10%高价值页(高搜索量、高商业价值)放在Sitemap优先级最高,主导航或聚合页直链可达。中间60%中价值页放Sitemap但不显式内链。后30%低价值页(实验性、长尾兜底)放在分批Sitemap里,按周扫描索引率,索引率持续<30%的下线或合并。索引膨胀机制那篇讲过站点级索引膨胀的全套诊断与处置矩阵,pSEO项目按里面那套来管index governance,能避开90%的常见坑。
质量回归的自动化监控
大规模pSEO项目必须有自动化质量监控。每周扫一遍所有pSEO页的几个指标:
- 索引状态(是否被收录)。
- 平均停留时长(是否高于站点中位数的50%)。
- 独有字段完整性(是否有空字段或fallback文案)。
- 外链增长率(是否有自然反链进来)。
有页面在某个指标上持续低于阈值就触发回写或下线。这套监控自己写一个200-300行Python脚本就够,不需要昂贵商业工具。
团队配置:开发+SEO+运营三角
pSEO项目失败的另一个常见原因是团队配置错。纯SEO团队做不出模板,纯开发团队不懂搜索意图,纯运营团队不懂数据架构。健康的pSEO项目至少需要一个三角:SEO人定词库与模板差异化策略、开发人写生成与监控管线、运营人填数据并处理质量回归。三角缺一角,项目很难活过6个月。
预算分配的经验比例
合规pSEO项目的总投入里,工程开发约占25%-35%(一次性建管线后边际成本低)、数据获取与维护约占35%-45%(持续投入)、SEO策略与质量回归约占15%-25%、运营与监控约占10%-15%。这个分配跟内容工厂正好相反——内容工厂80%的钱花在“多生产”,pSEO 60%+的钱花在“数据准”。预算分配出错的项目,多半会逐步退化成内容工厂。
外包能否做pSEO
多数情况不能。pSEO的核心资产是“你的独有数据”,把数据交给外包团队既有合规风险也有持续运维难度。可以外包的环节是工程实现(模板编码、监控脚本),不能外包的是词库设计、数据采集与清洗、质量回归。整包外包的pSEO项目,失败率超过70%——不是外包团队不行,是这件事的核心不在“执行”,在“判断”,而判断只有真正在自家业务里浸泡过的人才做得出来。能把判断权外包出去的项目本来也就不需要做pSEO,做几篇通用内容反而更划算。
pSEO和AI Overviews怎么并存?
AI Overviews改变了pSEO项目的目标函数。原来pSEO追求“被Google收录并排到SERP前10”,现在还要追求“被AI Overviews抽出来引用”。两个目标大体一致但有细分。
AI Overviews偏爱的pSEO块
从观察到的引用规律:AI Overviews引用pSEO页面时,最常引用的是“数据点+一句话解释”这种格式。比如比价站的“纽约市2BR月租金中位数:$3,200,2024年同比+4.2%”——一行数字加一行解释,AI Overviews抽出来直接放在答案里。AI Overviews完整指南那篇从全站视角讲过怎么被AI抽出来,本文重点是pSEO模板层级怎么内置“可被引用块”。
可被引用的pSEO块设计
合规pSEO模板里应该有一段“可被引用的核心数据块”,结构上:
- 一个简洁的H2或H3标题,对应一类AI可能被问到的子问题。
- 一段开门见山的数据点+解释(30-80字)。
- 对应的结构化数据(Dataset或Article的mainEntity)。
这种块在AI Overviews里被引用的概率,比同样信息散在长段落里高3-5倍。
引用换流量还是引用换品牌
AI Overviews引用之后,点击率比传统SERP第一位低很多(约30%-50%)。pSEO项目要重新评估目标:如果纯追求流量CR,AI Overviews引用是损失;如果追求品牌曝光与权威建立,AI Overviews引用是增量。出海工具站和SaaS对照站更倾向于后者,把AI引用当作品牌建设的一部分,不计较单次点击损失。
真实数据
有家做跨境票务比价的客户站,2024年AI Overviews上线之后,pSEO页面被引用率从0涨到约8%。引用页面的CR比未被引用页面低约38%,但来自AI Overviews的用户后续30天的复访率高出约2倍——他们记住了品牌。运营团队最终的决策是不优化(既不强加rel=noindex拦AI、也不为追AI引用改写),保持现状,把AI引用当作长期品牌资产建设。
常见问题解答
程序化SEO和内容工厂的根本区别是什么?
内容工厂是模板套生成的同质化文字;程序化SEO是模板复用每页独有的稀缺数据。前者每页对用户的边际价值为零,后者每页对应一组真实的查询意图与数据答案。区别不在工具,在数据稀缺度。
什么生意适合做程序化SEO?
五类高适配:比价/聚合类、地理位置x服务的本地搜索、工具站的参数计算页、招聘/房产/票务的长尾筛选、SaaS的功能对照与集成清单。共同点是用户需求维度组合多、每个组合都有真实长尾搜索、每页都有独有数据。
什么场景做pSEO一定会翻车?
三类典型陷阱:没有独有数据只靠模板凑、查询意图本身不存在长尾的领域(如纯品牌词或单一服务)、HCU之后还在做的纯关键词组合页(没有任何信息增量)。这三类做出来短期可能涨流量,6-12个月必被算法清。
pSEO的词库怎么搭?
本质是笛卡尔积加剪枝。先用2-4个维度做关键词矩阵(如品类×城市×需求),跑一遍组合数估算,然后用搜索量、商业价值、与现有内容重叠度三条件剪枝,剪到留下的每条组合都有真实搜索且能被独有数据支撑。
pSEO的数据从哪来才合规?
三类来源:自有数据(用户上传/平台行为/交易记录,最稳)、公开数据(政府开放数据/官方API/可Crawl的标准化数据),采集类要看ToS和Robots,灰色地带不要做。法律风险大、规模上去后维权风险翻倍。
pSEO模板怎么设计才不被判薄页?
差异化锚点至少三层:标题层(按字段动态生成不同搜索意图组合)、内容层(每页注入独有数据如行情/参数/真实评论)、结构层(按字段值动态调整H层级、表、FAQ)。三层都做才能让每页对Google看起来是独立内容而不是模板复制。
pSEO在HCU有用内容系统时代还能不能做?
能做但门槛高了。HCU之后存活的pSEO都满足三条:单页有真实独有数据、模板按字段差异化不只是替换、生成节奏与索引控制配对(不是一夜放10万页)。不满足任一条的pSEO项目都会被打到。
怎么决定pSEO项目要不要继续推?
看单页收益与单页成本的比值,加长尾密度分布。如果10万页里有80%流量在前5%,剩下95%页几乎不带流量,那意味着剪枝过粗;如果单页收益<单页运维成本,意味着模板没找到长尾甜区。两个信号任一出现都要回炉而不是继续放量。
权威参考资料
本文标题:《程序化SEO怎么做不被算法当薄页?三要素实战》
本文链接:https://zhangwenbao.com/programmatic-seo-template-data-source-quality-scalability-mechanism.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0