Google有用内容系统HCU把站打掉了,怎么一步步恢复?
本文目录
- 有用内容系统到底是个什么东西?
- 它为什么是“站点级”而不是“页面级”?
- 它和一次性算法更新有什么区别?
- Google 那套自评问题,到底在问什么?
- HCU 和熊猫算法是同一个问题换皮吗?
- 2024 年 3 月并入核心后,“HCU”这个词还成立吗?
- 2023 年 9 月那次到底发生了什么?
- 为什么这次连一些好站也被误伤了?
- 什么样的站会被有用内容系统判定掉量?
- 联盟营销站和“最佳X”清单站为什么是重灾区?
- 纯 AI 批量生成的内容站会怎样?
- 大站出租板块为什么单独被 site reputation abuse 政策点名?
- 怎么判断自己是不是被 HCU 拖累了?
- 该看哪些数据信号?
- 哪些“掉量”其实不是 HCU?
- 掉量之后到底该怎么恢复?
- 站点级内容体检怎么做?
- 提升、合并、noindex 还是删?
- 怎么把“第一手经验”真正注入内容?
- 恢复要等多久?
- 一个真实恢复案例的时间线长什么样?
- 站内架构和内链算不算质量信号?
- 哪些操作做了反而更糟?
- 常见问题解答
- 有用内容系统和核心更新是一回事吗?
- 把低质量页面全删掉,排名会回来吗?
- 用 AI 写内容就一定会被 HCU 判定吗?
- 恢复一般需要多久?
- 掉量了,但品牌词还在,这正常吗?
- 怎么确认我是被 HCU 而不是技术问题影响?
- site reputation abuse 和 HCU 是同一个东西吗?
- 权威参考资料
摘要:有用内容系统不是一次性更新,是常驻运行的站点级分类器,判你的站为人写还是为搜索引擎写,再用全站权重压排名——这就是加FAQ、改标题这种页面级动作救不了它的原因。重灾区是规模化薄内容、套模板联盟站和为词而生的博客。恢复靠目录级自查、成规模砍掉为搜索而写的内容,再跨越多次核心更新慢慢回评。
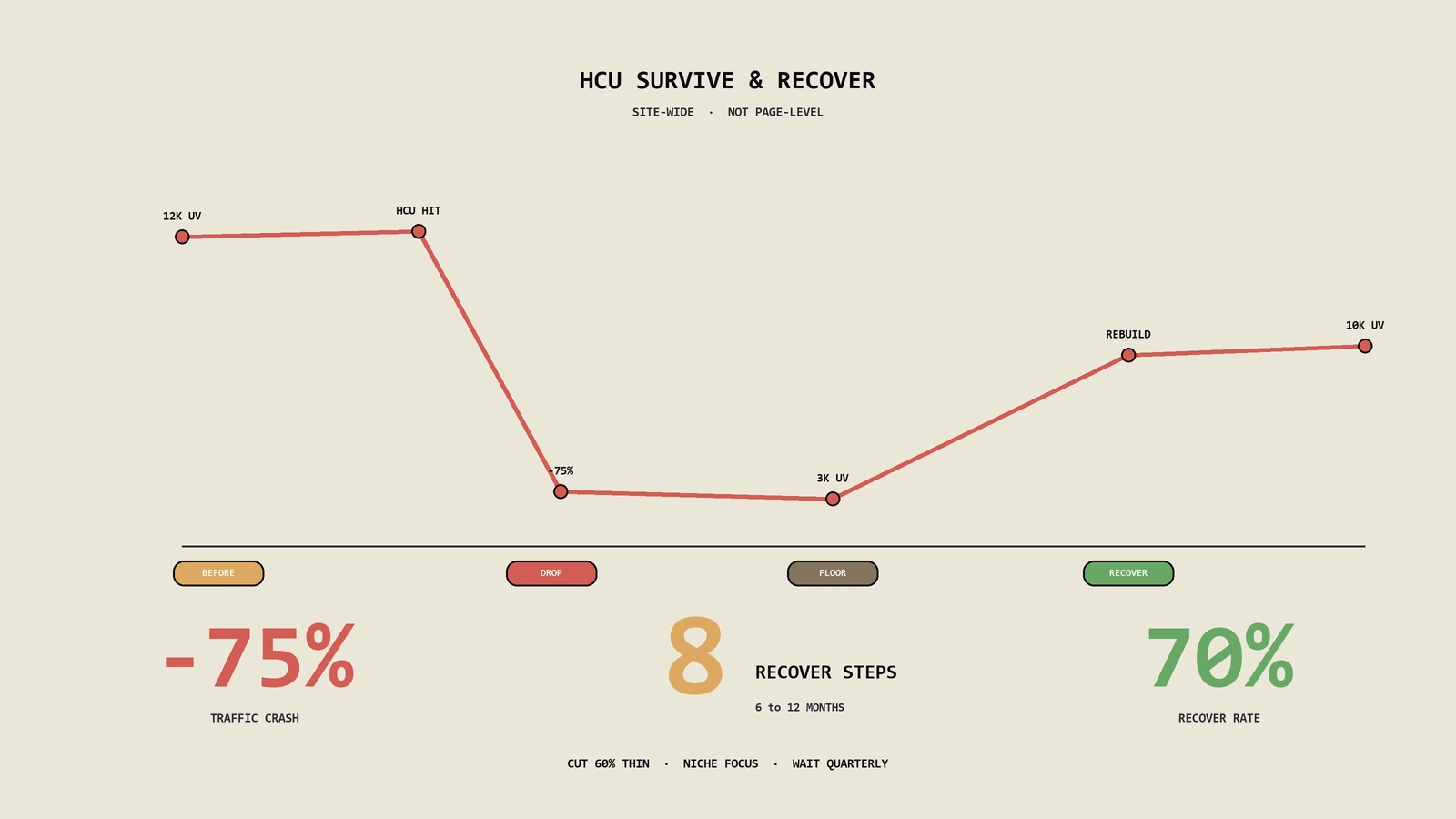
2023 年 9 月那次有用内容更新放出来之后,保哥手头一个北美家居品类的内容型独立站,三周内自然流量从日均一万二掉到三千出头,掉的几乎全是非品牌长尾词。客户第一反应是“我们文章质量挺高啊”,第二反应是赶紧加 FAQ 结构化数据、改了几十个标题。两个月过去没有任何起色——因为他们在用页面级的工具,去修一个站点级的判定。这篇就把这套判定到底怎么运作、为什么常规 SEO 动作无效、以及怎么真的爬出来,掰开讲。
有用内容系统到底是个什么东西?
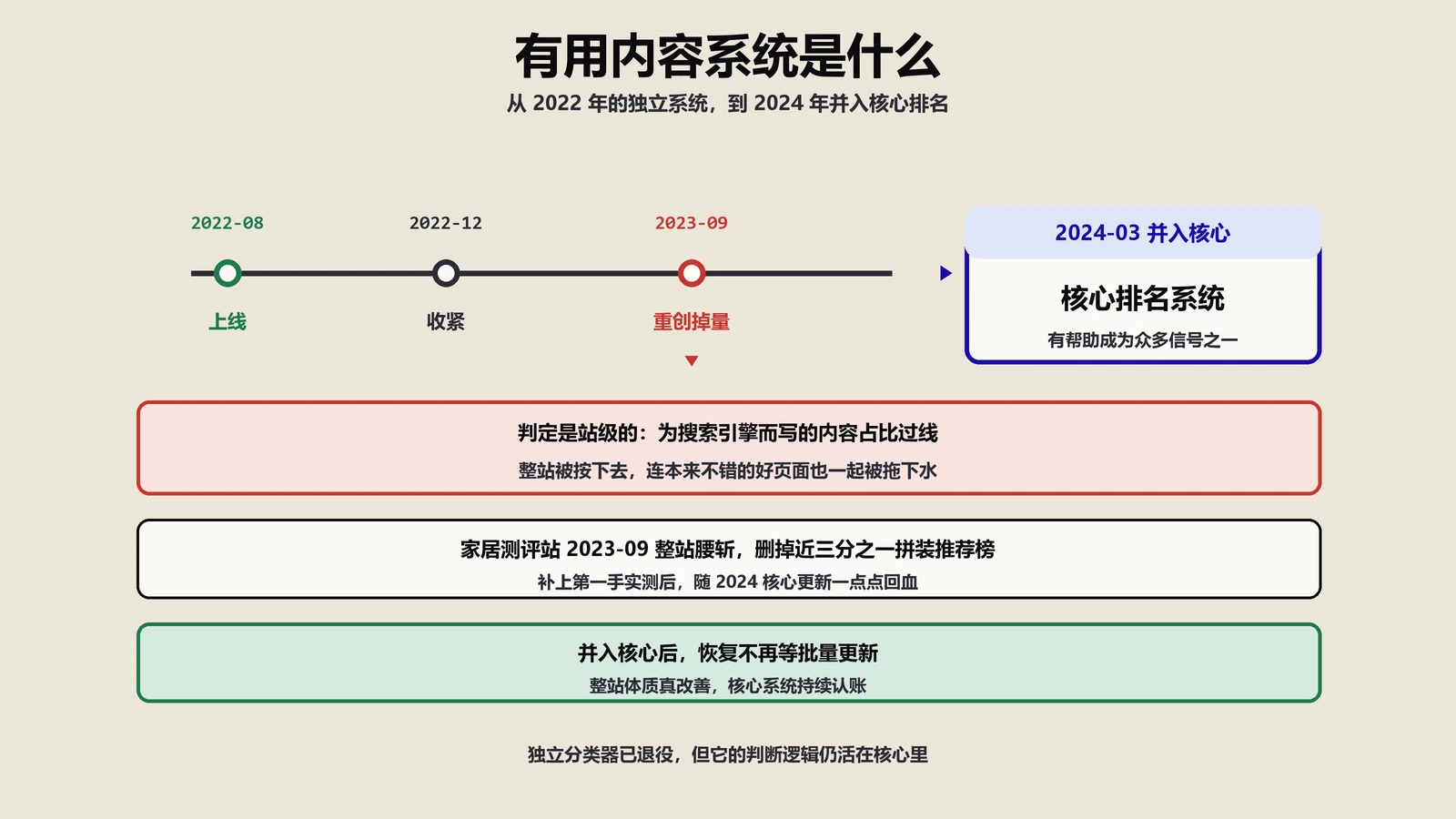
先把名字这事说清楚,因为绝大多数掉量的人连对象是谁都没搞明白。它最早叫 Helpful Content Update(有用内容更新),2022 年 8 月 25 日先在英文搜索上线;同年 12 月扩展到全部语言,Google 顺手把称呼改成了 Helpful Content System——从“更新”改成“系统”,这一个词的变化,是整件事最容易被忽略也最关键的地方。
“更新”给人的心智模型是:算法在某天跑了一遍,给页面打了分,分打完就结束了,下次更新前不会再动。Panda 早期就是这种节奏,按月手动 push。但“系统”意味着它是常驻的——它持续对站点做评估,并产出一个信号,这个信号实时参与排名计算。你今天发的内容,明天就在被它看;你三个月前清掉的垃圾页,它也不是立刻就忘。把它理解成“一次考试”,你就会做出“考砸了赶紧补考”的错误动作;把它理解成“一个一直在观察你的信用评分系统”,你才会做对。
它为什么是“站点级”而不是“页面级”?
这是和普通排名信号最本质的区别。Google 在官方文档里反复用的措辞是 site-wide signal——它判定的不是“这一篇有没有用”,而是“这个站整体是不是大量为搜索引擎堆内容”。一旦它认定你站上有相当比例的内容是“为了排名而生产、对真实用户价值很薄”的,它会用一个全站性的权重压低你整个域名的表现,包括那些本身写得很好的页面。
这就解释了客户那个百思不得其解的现象:明明有几篇是请行业专家写的深度长文,凭什么也跟着掉?因为系统不是逐页给你算账,它在算的是“这个站值不值得在搜索结果里被优先展示给人”。你站里有三百篇为长尾词批量产的薄文,二十篇真材实料的好文就会被这三百篇拖下水。Panda 当年也是这个逻辑,只不过 Panda 盯的是“内容农场式的薄页面”,HCU 把范围扩到了“整个站的内容是不是以人为先”。关于站点级判定这层逻辑,熊猫算法那篇里拆得更细,两者放一起看会更通透。
它和一次性算法更新有什么区别?
核心更新(core update)是周期性的、有明确发布窗口的、会被官方公告的事件。有用内容系统在 2024 年 3 月之前还保留过几次带名字的“刷新”(比如 2023 年 9 月那次,杀伤面极广),但它的本体是连续评估。这带来一个很多人想不到的后果:你的恢复,往往要等到一次较大的核心更新或系统重评,信号才会被重新计算一遍,而不是“我改完了刷新一下排名就回来”。这点后面讲恢复路径时会再展开,先记住——它的时间尺度以季度计,不以天计。
Google 那套自评问题,到底在问什么?
Google 公开过一组让站长自查的问题,原文几十条,零散又抽象。把它消化掉,背后其实只有四根轴,盯着这四根轴改,比逐条对着官方清单打钩有用得多。
- 受众是不是真实存在的。你这批内容,有没有一群本来就关注你、会觉得“幸好有这篇”的人?还是纯靠搜索导流、读者读完即走、不会记得你是谁?前者是“为人”,后者是“为搜索”。
- 有没有第一手的东西。这篇里有没有原始实测、亲历、原创分析、独到判断——而不是把别处五篇拼成一篇。系统问的不是“信息全不全”,是“这些信息在你这里有没有增值”。
- 谁写的、凭什么信。内容能不能让人看出背后是真懂这行的人,敢署名、敢给可验证依据,而不是匿名拼装、含糊其辞。
- 是不是先有关键词再硬凑。这篇是因为“有人真的需要”才写,还是因为“这个词有搜索量”才写?是不是为凑长尾把一个主题硬拆成几十篇?读者读完还要不要再去别处补完整?
有个比官方清单管用得多的粗暴自测:把这篇的目标关键词全抠掉,单看正文,还有没有人愿意读完?读完会不会想存下来、转给同行?两个都答“不会”,这篇在系统眼里就是“为搜索而生”的典型。
HCU 和熊猫算法是同一个问题换皮吗?
是,也不全是。说“是”,因为内核诉求一脉相承:搜索引擎要把“真正帮到用户的内容”排在“为了截流量而批量制造的内容”前面。从 2011 年 2 月的 Panda、到 2012 年的企鹅(那是外链方向,不在这条线上)、再到 2022 年的 HCU、最后 2024 年 3 月并入核心——这条线一直在回答同一个问题:怎么把“替用户解决问题的人”和“蹭关键词的人”分开。
说“不全是”,因为打击面变了。Panda 时代的典型受害者是 eHow 那种问答内容农场——一个 query 一篇五百字的稀汤页面。HCU 时代的受害者画像完全升级了:用 AI 批量铺“2024 年最好的 X 推荐”的联盟站、把别处信息二手聚合却没有任何第一手验证的“how-to 大全”、为了覆盖长尾把同一主题拆成几十篇互相内卷的 SEO 文。Panda 打的是“写得太薄”,HCU 打的是“根本没打算帮人,只是想排名”——后者是动机判定,比前者狠得多,也模糊得多。
2024 年 3 月并入核心后,“HCU”这个词还成立吗?
严格说,不成立了。2024 年 3 月的核心更新里,Google 明确说把“有用内容系统”的能力拆解、并入了核心排名系统的多个信号,不再作为一个独立命名的系统单独跑、也不再单独发“有用内容更新”的公告。这件事的实操含义被严重低估:
- 没有“恢复信号灯”了。以前还能盯着“下一次 HCU 刷新”这个节点等翻身,现在它散在核心里,你只能跟着一次次核心更新观察整体趋势,判断恢复变得更难、更需要耐心。
- “质量”不再是可单独优化的开关。它和其它核心信号交织在一起,意味着你没法只动一个杠杆就把它单独拉回来——必须整体把站做成“为人而建”的样子。
- 2024 年 5 月之后还衍生出独立政策。比如针对“大站出租板块给第三方铺低质内容”的 site reputation abuse(站点声誉滥用),那是单独的垃圾政策,不等于 HCU,但精神同源,很多人把两者混为一谈,处理动作就会错。
2023 年 9 月那次到底发生了什么?
有用内容系统上线后杀伤面最广的一次,是 2023 年 9 月那回。大量内容站、食谱站、how-to 站、联盟站在两三周内自然流量被砍掉一半甚至更多,行业里一片哀嚎。那次形态高度一致:掉的几乎全是信息型非品牌流量,品牌词基本没动,且不是个别页掉,是整段目录一起塌——这正是站点级判定的典型指纹。
更值得说的是后续。Google 在那之后陆续承认,这一轮误伤了一批本不该受影响的对象——有真实第一手经验的独立小站、小型垂直论坛、个人创作者,也被一起压了下去。围绕“独立创作者被算法误杀”的讨论在 2023 年底到 2024 年相当激烈,Google 也在 2024 年的调整里加进了对小型独立站点的额外考量,并在 2024 年 3 月把整个系统并入核心、同时把“大站出租板块寄生低质内容”单拎出来用 site reputation abuse 政策处理。
为什么这次连一些好站也被误伤了?
因为站点级分类器看的是“整体信号”,它没聪明到能精确认出“这一篇是真专家写的、放它一马”。一个小站如果结构上长得像“为搜索堆出来的”——大量薄分类页、TAG 页、为长尾拆得很碎的文章——哪怕核心几篇是真材实料,整体信号也可能把它带进沟里。这给的教训不是“算法不公所以躺平”,而是“为人而建”不只是单篇内容质量,还包括整个站在结构上看起来是不是为人服务的——这条直接引出后面恢复部分要讲的站内架构。
什么样的站会被有用内容系统判定掉量?
把官方那套自评问题翻译成人话,中招画像其实很清晰。下面这张表按这两年经手的案例归了类,左边是特征,右边是它为什么触发判定。
| 站点类型 | 典型特征 | 为什么会被判定 |
|---|---|---|
| 联盟营销 / 推荐清单站 | 大量“最好的X”“X对比”,没买过没测过,参数全抄官网 | 没有第一手经验,内容可被任何人原样复述,对用户增量为零 |
| 二手聚合 how-to 站 | 把各处教程拼起来,没有自己跑通过,截图都没有 | “为搜索而存在”特征极强,用户读完还得再去别处验证 |
| AI 批量生成站 | 同一模板灌长尾,结构高度对称,无人工增值 | 不是因为 AI,是因为零编辑、零经验、零事实核验 |
| 失控的 UGC / 论坛 | 灌水帖、SEO 垃圾帖占比高,无审核 | 站点整体“可信内容密度”被拉低,连带优质板块 |
| 出租板块的大站 | 主站权威,但优惠券/外包目录给第三方铺量 | 触发 site reputation abuse,精神同源处理另算 |
联盟营销站和“最佳X”清单站为什么是重灾区?
因为这类内容最容易被一个问题击穿:“写这篇的人,到底有没有真的用过、买过、对比过?”一篇“2023 年最值得买的五款扫地机”,如果参数表是抄的、优缺点是洗的、没有一张自己拍的照片、没有一句“我家这台用了三个月滚刷卡头发”的话,它对用户的增量就是零——用户在十个长得一模一样的页面里随便点哪个都没区别。系统判定的恰恰是这个“可替代性”。保哥给一个做户外装备的出海客户做诊断时,把他们 180 篇“best of”稿子按“有没有第一手证据”过了一遍,能留下硬证据的只有 11 篇——这个比例,掉量是必然的,不掉才奇怪。
纯 AI 批量生成的内容站会怎样?
这里要替 AI 说句公道话,也要泼盆冷水。Google 的官方立场是明确的:不反对用 AI 生产内容,反对的是低质量、为操纵排名而生产的内容——无论是人写的还是机器写的。所以“用了 AI 就一定中招”是误读。真正中招的,是那种把 AI 当批量铺货机器、零人工编辑、零事实核验、零经验注入的用法。判断边界其实有一条很糙但好用的标准:这篇 AI 初稿,有没有经过一个真懂这行的人,加进至少一个“AI 编不出来的东西”——一个真实数据、一次踩坑、一张自己的截图、一句反常识的行业判断?加得进,AI 是提效工具;加不进,那就是在给自己站埋雷。
大站出租板块为什么单独被 site reputation abuse 政策点名?
2024 年 5 月这条政策针对的是一种很赚钱也很伤站的玩法:一个权威大站,把某个目录(优惠码、外包评测、第三方专栏)租出去,让别人借主站权重铺低质量的赚钱内容。它和 HCU 不是一回事——HCU 是算法系统判定,site reputation abuse 一开始有人工处理成分,处理对象是“寄生的那个目录”而不是整站。把它和 HCU 混在一起的人,常犯的错是“整站大改”,结果伤了本来没问题的主站。对象判断错,动作一定错,这是这一段最该记住的。
怎么判断自己是不是被 HCU 拖累了?
这一步九成的人做错,因为他们盯着单个关键词排名看。站点级判定要用站点级数据看。诊断顺序固定,就三步。
该看哪些数据信号?
打开 Search Console,不要看“某个词掉了没”,按下面这几个维度看结构性变化:
- 按目录拆 impression。用页面路径过滤,看
/blog/、/reviews/、/guides/各目录的曝光曲线。HCU 型掉量的指纹是“某些目录整片塌方,另一些几乎没动”——那些塌的目录,往往就是当初为搜索批量产的。 - 品牌词 vs 非品牌词分开看。HCU 掉量极典型的形态是品牌词稳、信息型非品牌词整体下滑——因为系统压的是“你凭内容质量去截泛流量”的能力,不压认你这个品牌的人。
- 时间窗对齐已知更新。把掉量起点精确到天,去比对已确认的核心更新/系统刷新窗口(2023-09、2024-03 这些)。对得上,HCU/核心质量信号嫌疑就大;对不上,先怀疑别的。
哪些“掉量”其实不是 HCU?
这一步是省钱的关键,别一掉量就往 HCU 上套,按下面这张排除清单先过一遍。
| 现象 | 更可能的真因 | 怎么快速验证 |
|---|---|---|
| 全站突然清零、连品牌词都没了 | 技术问题:误 noindex、robots 封禁、迁移没做对 | 查 GSC 覆盖率报告 + 抓取 live 测试,几分钟出结果 |
| 个别页排名换位,整体没塌 | 常规核心更新的相关性重排 | 看是不是只有部分 query、竞品有没有同步变动 |
| 每年同期都降,过段时间自己回 | 季节性,不是惩罚 | 拉两年同比,形状一致就是季节 |
| 曝光在但点击掉 | SERP 改版:AI 概览、精选摘要挤压点击 | 看 impression 平稳但 CTR 结构性下降 |
这四种里,技术问题最常被误判成 HCU,结果是花三个月重写内容,其实改一行 meta robots 就能解决。诊断阶段多花半天,能省后面三个月。
掉量之后到底该怎么恢复?
先说一句客户最不爱听但必须说的实话:有用内容系统的恢复,没有快捷键,时间尺度以季度计,而且 2024 年 3 月并入核心之后,连“恢复信号灯”都没有了。能做的不是“等翻盘”,是把站真的改成“为人而建”,然后跨过若干次核心更新窗口,让信号被重新计算。下面这条路径,是保哥给那个家居客户跑了大半年、最终非品牌流量爬回原来约七成的实际做法。
站点级内容体检怎么做?
把站上所有索引页拉成一张清单,每一篇只回答一个问题:这篇是为某个真实的人解决某个真实问题而写的,还是为了某个关键词排名而存在的?不要纠结打分体系,就用三档标记——“留”(有第一手价值,人会感谢你写了它)、“改”(主题有价值但执行是为搜索而写的,能救)、“砍”(纯关键词页,没有任何不可替代价值)。体检的颗粒度是目录,不是单页:哪个目录“砍”的比例过半,那个目录就是拖累全站的源头,要整段处理而不是零敲碎打。
提升、合并、noindex 还是删?
这是决策矩阵,也是最容易做错的一步。先把一个被广泛误传的说法纠正了:“把低质页删光就能恢复”不成立。Google 多位发言人多次表态,移除内容本身不是恢复路径,整体质量的真实提升才是;删页只是在你确认这些页“永远不可能有价值且在稀释站点信号”时的清场动作,不是疗效来源。决策按下面来:
- 提升:主题有真实需求、你又确实有第一手积累的,重写——注入原始数据、实测、案例,把它做成“同主题里别人替代不了的那一篇”。这是真正产生恢复效果的动作,应该占你工作量的大头。
- 合并:为长尾内卷拆出来的同主题多篇,合成一篇权威的,旧 URL 做 301 指向新页。既消灭薄内容,又集中信号。
- noindex:对用户有用但不该参与搜索竞争的页(站内功能页、薄但必要的工具页),从索引里拿掉但保留给用户。
- 删:只对“无价值 + 无流量 + 无外链 + 永不可能改好”的页用,删完返 410/404。它的作用是停止稀释,不是疗效。
怎么把“第一手经验”真正注入内容?
这是含金量最高也最被做歪的一步。绝大多数人理解的“加 E-E-A-T”就是加个作者框、挂个 LinkedIn、底部写句“本文由资深专家审核”——这些信号有用,但它们是包装,不是内容本身的经验密度。系统判的是内容里有没有“只有真做过的人才写得出来的东西”:一个你自己测出来的数据、一次具体到日志字符串的踩坑、一张你拍的而不是官网的图、一句反直觉但你能给出理由的判断。把一篇二手聚合稿改成有经验的稿,不是润色,是补做事实——这块和 E-E-A-T 是不是排名因素那篇讲的“信号清单”要配合着用:信号清单解决“怎么让机器识别到经验”,这里解决“先得真有经验可识别”。顺序不能反。
举个具体的改法对照,体感比讲原则清楚。一篇“怎么选跨境物流”的二手聚合稿,原文长这样:列了 DHL、FedEx、UPS、邮政小包四种,每种抄一段官网时效和价格区间,结尾一句“根据需求选择合适的方式”。这种稿子十个站长写出来一模一样,系统判它“可替代、无增值”一点不冤。有经验的改法不是把它润色得更通顺,是补做事实:补一张“同一个 2 公斤包裹、同一条美国线、四家实测到手时效与到岸成本”的对照表(数据是自己发过货跑出来的);补一段“旺季 DHL 时效崩盘那两周怎么临时切线”的踩坑;补一个判断——“客单价低于某个数,所有商业快递都不划算,老实走邮政小包”,并给出这个数怎么算。改完之后这篇就变成别人抄不走的,因为那张表和那个数,只有真发过货的人给得出。这才是“注入第一手经验”的实际操作,不是加个作者框,是补做别人没做过的事。
改完怎么验证改对没有?很糙但有效的一条:把这篇拿给一个同行看,问他“这里面有没有哪句话是你抄不来、得自己真做过才写得出的”。他指得出来,这篇就过了;他通篇找不到,说明你只是把二手信息换了种说法,系统也会这么判。
恢复要等多久?
给个实操中验证过的时间预期,免得决策人每周来问。改造本身(一个中等规模内容站,几百篇量级),认真做要一到三个月;改完之后,要等系统在后续核心更新里重新评估,这个窗口又是一到两次核心更新,常常再加三到六个月。也就是说,从动手到看见结构性回升,半年到一年是正常区间,期间还会有反复。2024 年 3 月并入核心后没有了独立的“有用内容刷新”节点,所以别指望某一天突然全回来,更可能是某次核心更新后某些目录先回一截,再下一次又回一截。把这个预期提前跟决策人对齐,比技术活本身还重要——保哥见过太多站,改造方向其实对,撑不过等待期被老板叫停推倒重来,前功尽弃。
一个真实恢复案例的时间线长什么样?
把开头那个北美家居内容站的恢复过程按时间摊开,比讲抽象方法有用。脱敏后的时间线大致是这样:
- 掉量起点。2023 年 9 月那次更新后三周,自然流量从日均约 1.2 万掉到 3 千出头,掉的几乎全是非品牌长尾,品牌词曲线几乎一条直线没动。
- 第一个月,走错路。团队按惯性加 FAQ 结构化数据、批量改标题描述,动了几十个页面,零起色——页面级动作对站点级判定无效,这一个月基本白费。
- 第二个月,换打法。把全站约四百多个索引页按“留 / 改 / 砍”过一遍,发现两个为长尾批量产的目录里“砍”的比例超过六成——源头定位到了。
- 第二到四个月,动手术。内卷的同主题碎文合并成权威长文、旧 URL 做 301;有真实积累的主题重写并补进实测数据和自拍图;功能性薄页 noindex;纯关键词页删掉返 410。存量薄内容占比从约六成压到一成五以内。
- 跨过 2024 年 3 月核心更新。改造完不是立刻回,是等。那次核心更新后,先回来的是被重写过、注入了第一手经验的那个目录,其它目录还没动。
- 第八到十个月。又跨过一次核心更新窗口,非品牌自然流量回到掉量前约七成并趋稳,品牌词全程没受影响。没回到 100%,也没指望回到——有些为搜索硬造的流量,本来就不该属于这个站。
这条时间线里最值钱的不是某个动作,是“第一个月白费 + 半年以上等待期”这两段——它们才是真实的,而不是教程里那种“三步恢复”的幻觉。
站内架构和内链算不算质量信号?
算,而且常被忽略。站点级判定看的是整个站“为谁而建”,结构本身就是信号的一部分:主题是不是成体系、相关内容能不能被读者顺畅找到、内链是服务阅读还是纯为传权重而互指。一个站到处是空壳分类页、为关键词硬造的 TAG 页、锚文本清一色精确匹配的互链网络,哪怕单篇还行,整体也会透出“为搜索而建”的气味。把内链做成“读者读完这篇自然想看的下一篇”,而不是“这个词我要给它导权重”,是恢复期最容易被低估、性价比却很高的一块——它和搜索引擎抓取、索引与主题理解的机制是同一套逻辑的两面:机器怎么理解你的站,取决于你的站是不是真为人组织的。
哪些操作做了反而更糟?
掉量之后人会慌,一慌就会做下面这些事,每一件都在加深判定或者浪费恢复窗口:
- 疯狂发新文。用更多“为搜索而写”的内容去填,等于往判定里加料。掉量期该做的是减存量薄内容,不是加增量。
- 全站批量挂 AI 生成 FAQ + 堆结构化数据。这是页面级 SEO 动作,对站点级质量判定基本无效,还可能因为 FAQ 答非所问反噬体验。
- 大改版动 URL 结构。掉量期再叠加一次 URL 迁移风险,等于在病人身上再做一台不必要的手术,信号全乱、归因更难。
- 去买外链或找黑帽“快速恢复”。HCU 是内容质量方向的判定,外链救不了,还可能引来链接垃圾方向的二次问题。
- 盯单页排名做微调。把精力耗在“这个词今天升了两位”上,完全错过了“整站为谁而建”这个真正的杠杆。
- 整站搬去新域名想“重新开始”。有用内容系统是站点级质量判定,换域名不会让判定凭空消失,只会把多年积累的外链、品牌、索引信用一次清零,等于重病之下再自断一臂——这是掉量恐慌里最贵的一个错。
- 反复提交收录、求“重新审核”。这是算法层面的质量信号,不是人工处罚,根本没有“申诉/恢复审核”这种入口。频繁提交重新索引、催 Google 重抓既加不了速,还把精力从真正该做的内容改造上挪走了。
一句话收口:有用内容系统不是来惩罚你某几个页面的,它是在回答“这个站值不值得被推荐给人”。所以解药从来不在 SEO 工具箱里那些页面级开关,而在一个更朴素的问题——如果搜索引擎明天不存在了,你站上还有多少内容,是会有人专门来读、读完还想转给朋友的?把这个比例做高,剩下的交给时间。
常见问题解答
有用内容系统和核心更新是一回事吗?
不是。核心更新是周期性、有公告、有明确窗口的排名调整。有用内容系统是连续运行的站点级质量判定,2024 年 3 月已并入核心信号、不再单独命名。两者常同期发生,要靠掉量形态和时间窗区分。
把低质量页面全删掉,排名会回来吗?
不会自动回来。Google 多次表态删除本身不是恢复路径,整体质量真实提升才是。删页只适用于无价值无流量无外链且永不可能改好的页,作用是停止稀释信号,不产生疗效。
用 AI 写内容就一定会被 HCU 判定吗?
不一定。Google 反的是低质量、操纵排名的内容,不是 AI 本身。判断标准:AI 初稿有没有经懂行的人补进真实数据、踩坑、原创判断等“AI 编不出来的东西”,有则是工具,没有就是埋雷。
恢复一般需要多久?
几百篇量级的站,认真改造一到三个月,之后还要跨一到两次核心更新窗口重评,常再加三到六个月。从动手到结构性回升,半年到一年是正常区间,且会有反复。
掉量了,但品牌词还在,这正常吗?
非常典型。有用内容系统压的是你靠内容质量去截非品牌泛流量的能力,不影响认你品牌的人。品牌词稳、信息型非品牌词整片下滑,正是 HCU 型掉量的指纹之一。
怎么确认我是被 HCU 而不是技术问题影响?
先排除技术因素:查 Search Console 覆盖率报告和实时抓取测试,确认没有误 noindex、robots 封禁或迁移失误。技术问题常表现为全站含品牌词一起清零,HCU 是品牌词稳、按目录结构性下滑。
site reputation abuse 和 HCU 是同一个东西吗?
不是。site reputation abuse 是 2024 年 5 月单独的垃圾政策,针对大站出租板块寄生低质内容,处理对象是那个目录而非整站。和 HCU 精神同源但处理动作不同,混为一谈会导致整站误伤。
权威参考资料
本文标题:《Google有用内容系统HCU把站打掉了,怎么一步步恢复?》
本文链接:https://zhangwenbao.com/google-helpful-content-system-hcu-recovery-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0