E-E-A-T到底是不是排名因素?怎么落到可执行清单

本文目录
- E-E-A-T到底是不是一个排名因素?
- 既然不是直接因素,谷歌为什么还反复强调它?
- E-E-A-T和有用内容是一回事吗
- 怎么用这个方向预判核心更新会打谁
- 从E-A-T到E-E-A-T,这套概念是怎么一步步长出来的?
- 质量评估指南在这里扮演什么角色
- Medic更新为什么是E-A-T的成名战
- 2022年加上的那个Experience改变了什么
- 谷歌用什么信号去近似E-E-A-T?
- 经验靠什么体现
- 专业性靠什么体现
- 权威性靠什么体现
- 可信度为什么是地基
- 普通站怎么把E-E-A-T落到可执行的清单上?
- 关于E-E-A-T最常见的几个误解是什么?
- 常见问题解答
- E-E-A-T是谷歌的直接排名因素吗?
- 没有E-E-A-T分数,那怎么知道自己做得好不好?
- 加个作者简介和头像就能提升E-E-A-T吗?
- 非YMYL的普通内容站需要管E-E-A-T吗?
- 2022年加的那个Experience和Expertise有什么区别?
- E-E-A-T做好了排名就会涨吗?
- 掉量后怀疑是E-E-A-T问题,第一步该查什么?
- 权威参考资料
摘要:E-E-A-T不是Google算法里的打分项,没有E-E-A-T分数,它不直接进排名公式——官方反复澄清过。但它确实影响排名,因为整套系统是朝它描述的方向调的,质量评估员的打分只回流训练算法、不作用于你的页面。所以别问怎么把分从60提到80,要问哪些可观测信号在被当成它的近似,再去补那些信号。
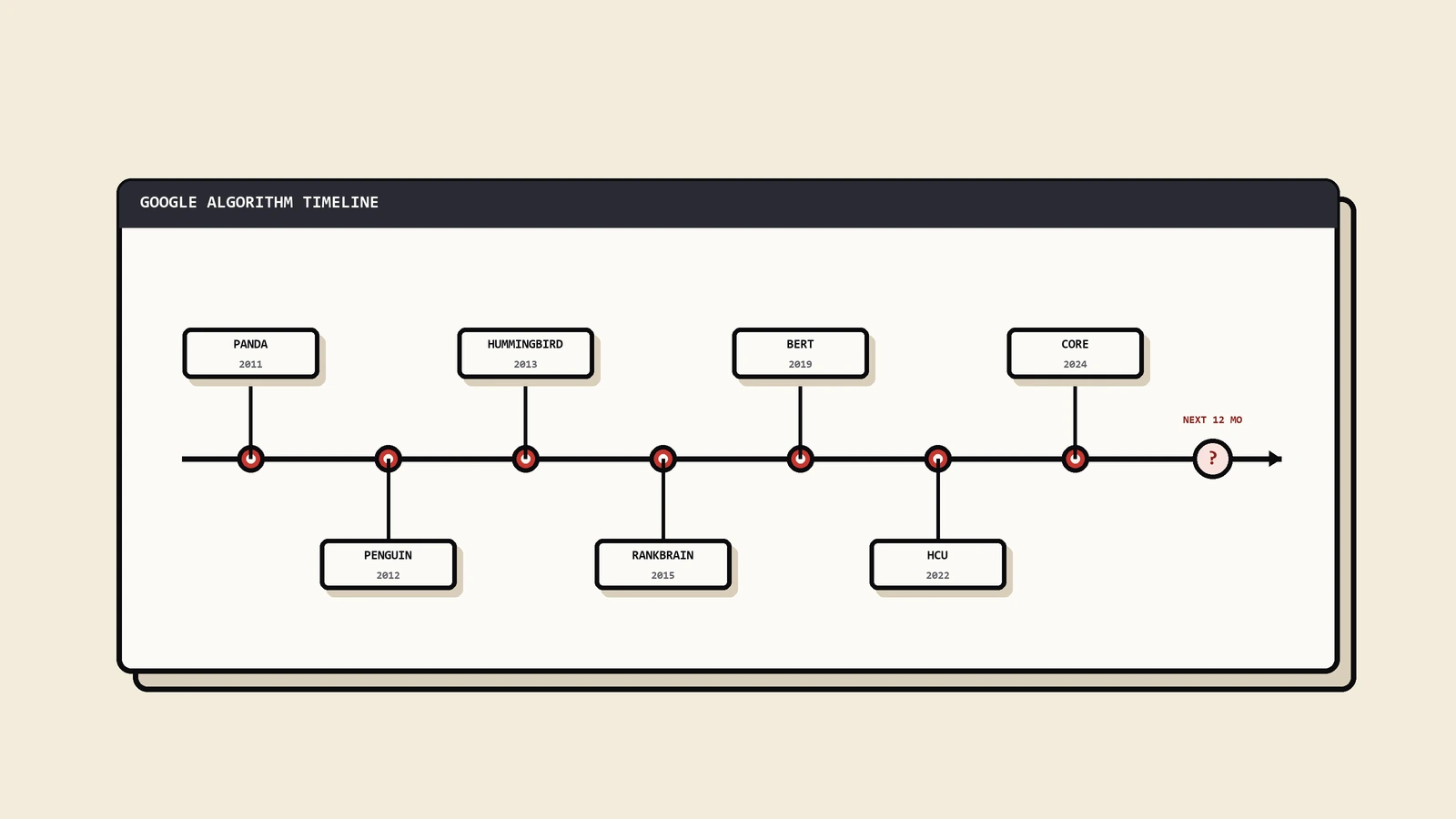
2018年8月初那次后来被业内叫做Medic的核心更新,把一批健康、医疗、财务类网站的排名搅了个天翻地覆。一个做营养补剂的北美客户当时找过来,流量一周掉了将近一半,团队翻遍了技术SEO清单,sitemap、速度、结构化数据全是绿的,百思不得其解。保哥看完那个站第一反应不是查代码,是去翻它的内容是谁写的——一整站几千篇关于“吃什么补什么”的文章,没有一个真实作者署名,没有任何医学背景背书,引用的全是自家博客互相链。问题不在技术,在这个站对它所处的高风险领域,完全拿不出任何“凭什么该信你”的东西。那一年之后,E-A-T这个词开始被整个行业挂在嘴边,也开始被严重误解。
误解的核心就一句话:很多人把E-E-A-T当成了一个谷歌会给你打分的算法项,于是开始问“我的E-E-A-T分数是多少”“怎么把E-E-A-T从60提到80”。这个问法本身就错了,而且错得会让你在错误的方向上使劲。要把这件事说清楚,得先回到它到底是什么。
E-E-A-T到底是不是一个排名因素?
直接给结论,而且这是谷歌官方多次明确过的:没有一个叫E-E-A-T的排名因素,谷歌也不会给你的页面算一个E-E-A-T分数塞进排名公式。它不是PageRank那种可计算的量,也不是速度、移动友好那种有明确开关的信号。
那它是什么?它是谷歌《搜索质量评估指南》里的一个核心概念,是谷歌雇佣的成千上万名质量评估员在给搜索结果打“这个结果好不好”的人工评分时,被要求重点考量的维度。关键在于:这些评估员的打分不会直接改变任何一个页面的排名。他们的评分是用来评价谷歌算法改动好不好的——谷歌调一版算法,让评估员去看新结果是不是整体更符合E-E-A-T描述的那种“高质量”,如果是,这版改动就更可能被推上线。
所以E-E-A-T和排名的关系是间接的、但极其真实的:它不进公式,但整个公式是朝着它描述的方向被一轮轮调出来的。打个比方,它不是考卷上的某一道题,它是出题人心里那个“什么样的学生算好学生”的标准——你答不出某道具体题目它不直接扣你分,但整张卷子的设计、评分的松紧,都是围着那个标准转的。理解了这层,你就不会再去问“E-E-A-T分数怎么提”,而会去问“谷歌用哪些算法信号在逼近这个标准,我在这些信号上表现如何”。
既然不是直接因素,谷歌为什么还反复强调它?
有人会说:既然不进公式,那谈它有什么用,我盯着具体排名信号优化不就行了?这恰恰是另一个误区。
谷歌反复强调E-E-A-T,是因为它在告诉你算法这些年迭代的总方向。有用内容系统、一轮接一轮的核心更新、对内容农场和低质聚合站的持续打击,背后的判定标尺基本都和E-E-A-T同源。你可以不关心这个词,但你绕不开它描述的那种站点画像——一个没有真实经验、拿不出专业背书、在行业里没有被认可、让用户没有理由信任的站,在今天任何一次核心更新里都是高危对象。这类站被算法收拾、再花很大力气恢复的过程,和当年内容农场被熊猫打掉如出一辙,熊猫算法掉量后的恢复逻辑那篇讲的那套“先确诊质量根因再动手”的思路,放到E-E-A-T相关的掉量上同样成立,因为它们本质是同一个标尺的不同年代版本。
换句话说,盯着具体信号优化没错,但如果不理解这些信号共同指向的那个标尺,你会陷入“打地鼠”——这个信号补一下、那个信号修一下,下一次核心更新照样掉,因为你一直在补症状,没对齐那个总方向。
E-E-A-T和有用内容是一回事吗
这是个高频混淆点,得切开。有用内容系统是一套真实在算法层面运行、会兑现成排名变化的判定机制;E-E-A-T是一个描述“什么样的内容算高质量”的概念框架。两者高度同源——有用内容系统想识别的“为人而非为搜索引擎写、作者有真本事和真经验”,几乎就是E-E-A-T的算法化表达。但它们不是一个东西:一个是标尺,一个是按这把标尺造出来的其中一台秤。理解这层的实用价值在于,你不该问“有用内容系统的规则是什么”然后去逐条应对,而该问“我的内容符不符合E-E-A-T描述的那种好”,后者对了,面对的就不只是某一个系统,而是所有朝这个方向调的系统。
怎么用这个方向预判核心更新会打谁
把E-E-A-T当方向而不是分数,最实在的好处是它能让你提前判断风险,而不是每次更新后被动救火。每次核心更新落地,去看排名互换的两边:掉的那批站,共性几乎总是某个E严重缺失——大量无署名洗稿(缺经验)、泛而不专的内容工厂(缺专业)、靠操纵链接撑起来的虚假权威(缺权威)、有可信度硬伤的交易站(缺信任);涨的那批,往往正好在对应维度有真东西。所以自查不用等更新:拿你最重要的那批页面,对照前面四个维度逐一问“这一项我拿得出真凭实据吗”,哪一项答得心虚,哪一项就是下次更新的风险敞口。这比更新后扒变化日志要主动得多。
从E-A-T到E-E-A-T,这套概念是怎么一步步长出来的?
把演变史捋清楚,比记住当前定义更有用,因为每一步变化都对应着谷歌当时想解决的一类真实问题,知道它从哪来,才知道它要往哪去。
质量评估指南在这里扮演什么角色
这套概念的源头是《搜索质量评估指南》,一份谷歌公开的、给人工评估员用的打分手册。E-A-T最早就是写在这份指南里的评分维度,2014年前后这份指南公开后,业内才第一次看到谷歌内部是用什么标准在定义“高质量结果”。必须记住的一点:这份指南不是算法文档,是给人看的评分标准。它不会告诉你某个信号的权重是多少,它告诉你的是谷歌希望最终被排上去的内容长什么样。把它当算法手册逐条抠权重,方向就错了;把它当“谷歌的审美说明书”来读,才用对了。
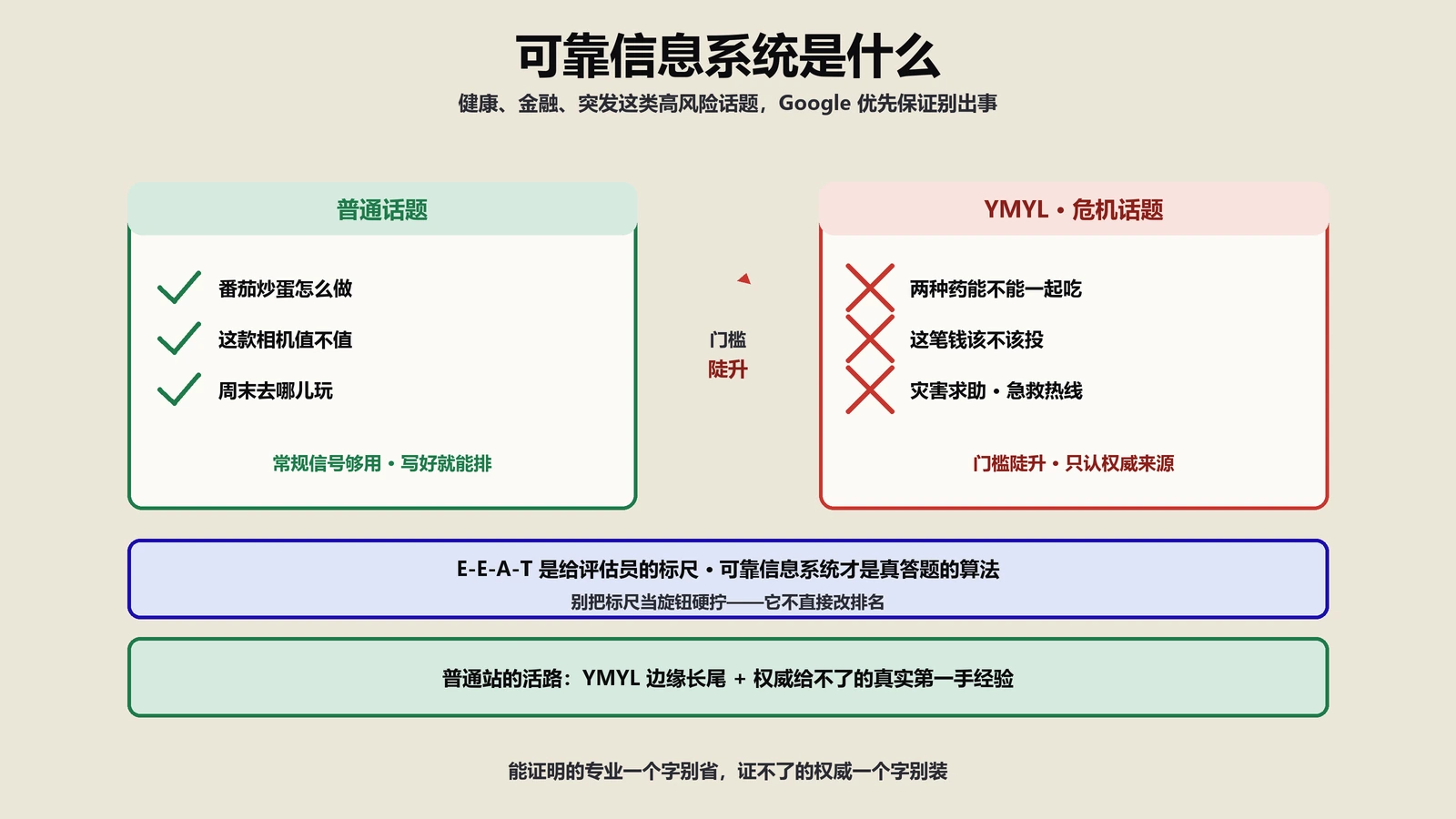
这份指南本身也在持续演化,节奏值得知道。它最早内部使用,2013到2015年间逐步对外公开,里面有一套页面质量分级——从最低到最高几档,E-A-T是评估员给一个页面定档时的核心依据之一。YMYL(你的钱或你的人生)这个概念也在指南里被一版版细化,从笼统的“高风险话题”逐渐明确到健康、金融、安全、重大决策等具体类目。理解这套机制的闭环很重要:谷歌工程师调一版算法,把新旧搜索结果给评估员盲评,评估员按指南打分,分数反过来告诉工程师这版改动是不是让结果更靠近“高质量”的标准——评估员不碰你的排名,他们校准的是算法该往哪调。这就是为什么谷歌愿意公开这份指南:它不怕你知道标准,它怕你不知道标准还在瞎做。
Medic更新为什么是E-A-T的成名战
2018年8月那次核心更新(业内称Medic)是个引爆点。它大面积影响了医疗、健康、财务这类一旦内容出错就可能危害用户的领域,也就是谷歌说的YMYL。掉量的站有一个共同点:内容看起来专业,但拿不出真实的专业背书和可信度证据。这次更新让整个行业第一次直观感受到,E-A-T不是务虚的概念,它会以核心更新的形式实打实地兑现成排名变化。从那以后,作者身份、资质背书、内容溯源这些以前被当成锦上添花的东西,在高风险领域变成了生死线。
把Medic放进更长的脉络里看会更清楚。2019年的BERT更新常被混进来谈,但它解决的是机器对语言和意图的理解,跟E-A-T不是一回事,别把两者搅在一起。真正让E-A-T从“评估员的标准”变成“算法能兑现的东西”的关键载体,是2022年8月的有用内容系统——它第一次把“内容是不是真的为人写、有没有真本事和真经验”这件事,做成了一个能在算法层面持续生效的判定,后来还被并入核心更新一起跑。所以这条线是连贯的:质量评估指南先定义了标准(E-A-T),Medic这类核心更新证明这个标准会兑现成排名,有用内容系统则让这种兑现变成常态而不是偶尔一次的大地震。看不到这条线,你会以为E-E-A-T是某次更新临时冒出来的概念,于是每次核心更新都措手不及。
2022年加上的那个Experience改变了什么
2022年12月,谷歌在E-A-T前面加了一个E——Experience,第一手经验,整套概念正式变成E-E-A-T。这一步不是文字游戏,它回应的是一个很现实的变化:网上越来越多内容是“懂行的人写的正确但没温度的话”,甚至是机器批量生成的看似专业的内容,谷歌想把“这事我真干过、我有第一手经历”这类只有亲历者才写得出的内容单独拎出来加权。一篇相机评测,参数列得再全,不如一句“这台机器我背着爬了三次山,电池在低温下的真实表现是这样”值钱——后者是Experience,前者顶多是Expertise。这个E的加入,直接抬高了真实经历在内容价值里的位置,也让“洗稿+专业术语堆砌”这条路更难走了。
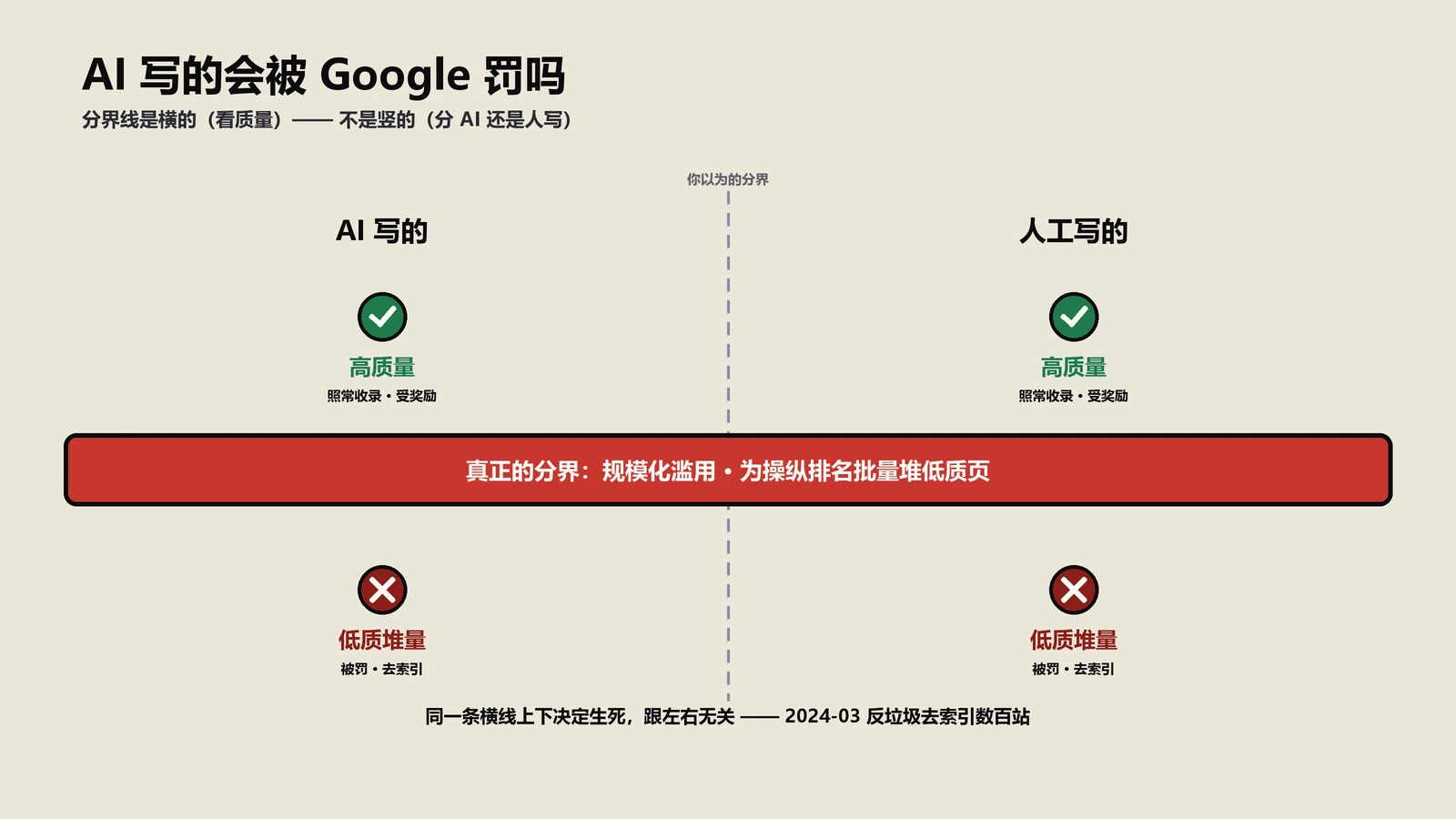
这一步之后指南还在继续迭代,有一个调整很多人没注意,但对落地很关键:谷歌把表述从过去偏重“作者的E-A-T”,调整成同时看内容本身、站点整体和作者三个层面,并明确指出对很多内容来说,证明可信的方式未必是作者光环,而是内容本身够不够实在、站点整体可不可信。这等于堵死了“给每篇文章硬塞一个名人作者就完事”的捷径。同期谷歌对AI生成内容也给了官方口径:判断标准始终是内容质量与是否符合E-E-A-T,而不是内容由人还是机器产出——这条后面讲误解时还会回到。把演变史看到这里,一个清晰的方向就出来了:谷歌十来年一直在做同一件事,就是让“拿不出真东西的内容”越来越难靠包装蒙混过关,每一次概念升级都是在堵一个新出现的包装漏洞。
谷歌用什么信号去近似E-E-A-T?
这是最该花力气的一节,因为这才是可操作的部分。既然E-E-A-T本身不是信号,谷歌就必须用一堆可观测、可计算的信号去逼近它。把这些信号拆开看,落地动作自然就清楚了。
经验靠什么体现
经验类信号的核心是“这内容里有没有只有亲历者才会有的细节”。算法层面对应的是原创性、第一手细节密度、与全网已有内容的差异度,以及内容里是否出现具体的、可验证的亲历要素:具体时间、具体场景、具体数据、具体失败教训。一篇全是通用结论、网上随处可见说法的内容,这些信号必然弱;一篇带着具体翻车细节和复现路径的内容,这些信号强。这也是为什么纯改写、纯综述类内容这两年越来越难做。
给一个能立刻用的自查动作:把文章里的作者署名、品牌、站名全部抹掉,再读一遍,看还能不能让人感觉到“这是真干过这事的人写的”。如果抹掉身份信息后,内容跟全网随便一篇综述没区别,那经验信号就是空的,加多少作者光环都补不回来。这也是纯AI批量产出最容易露馅的地方——它能写得很顺、很全,但写不出那种只有踩过坑才会有的、带着具体数字和懊恼的细节。差异度低、第一手要素缺失,是经验信号弱最常见的两个根因。
专业性靠什么体现
专业性信号围绕“写这个的人/这个站,在这个主题上够不够格”。对应的可观测信号包括内容的准确度与深度、术语使用是否到位、是否有作者信息且作者与主题相关、站点在该主题上的内容是否成体系而不是东一篇西一篇。注意它是分主题的——一个站在A领域很专业不代表在B领域也是,谷歌对“主题相关的专业性”比对“泛泛的站点权威”更敏感。
“分主题”这点值得多说一句,因为它推翻了很多人对“权威站”的想象。一个什么都写的大杂烩站,看起来内容很多,但在任何单一主题上的专业性密度都是稀的;一个只深耕一个窄领域、把这个领域的问题成系统答透的小站,在这个主题上的专业性信号反而更强。自查的问题不是“我站内容多不多”,而是“就我最想排的这个主题,我的内容深度和系统性,放到这个领域里排得上号吗”。贪多求全,恰恰是专业性最大的稀释剂。
权威性靠什么体现
权威性是这几个里最接近传统SEO信号的一个,它问的是“别人认不认你”。对应的主要是站外信号:高质量、相关、自然产生的链接与提及,行业内被引用、被讨论的程度,品牌在该领域被搜索的情况。它和外链的关系最直接,但要点是“相关且自然”——一堆不相关的低质链接不仅不构成权威,反而是反向信号。怎么把内容做到值得被自然引用,比怎么去搞链接更接近权威性的本质。
保哥早年踩过一个很典型的坑,值得直接拿出来讲。一个做户外装备测评的客户,权威性一直上不去,团队的方案是“那就去搞链接”,买了一批看着相关的链接,结果排名不升反降——因为那批链接来源同质、自然度差,在算法眼里那不是权威背书,是操纵信号。后来彻底换思路,把测评做到真有人愿意主动引用:每篇带可复现的实测方法和原始数据,行业论坛和真实玩家开始自发引用其中的数据图,再配合产品本身口碑把品牌搜索量带起来。一年多,权威性才真正起来。结论很朴素:权威性是别人给的,不是自己刷出来的,所有想绕过“值得被引用”这一步直接拿权威的动作,最后都会被算法当成反向信号。
权威性里有个最容易被观测、却最少被用的代理信号:品牌搜索量。一个在某领域真有分量的站,会有人直接搜它的名字,或者搜“某品牌+某主题”。这个信号造不了假,刷不出来,且能直接看——在搜索数据报告里筛品牌词查询的趋势,在趋势工具里看品牌搜索的长期走向。它上升,说明你在这个领域的权威是真在积累;长期平的,说明你做的内容也许有点流量,但没有沉淀成“被记住、被主动找”的权威。把品牌搜索趋势当成权威性的体检指标,比盯着外链数量有用得多,因为它衡量的是“有多少人记住了你并主动回来找你”,这才是权威最本质的样子,而外链数量只是它的一个侧影。
可信度为什么是地基
谷歌明确说过,Trust是E-E-A-T里最重要的一个,另外三个都是服务于它的。可信度对应的信号很杂但很硬:站点是否安全(HTTPS)、是否有清晰的联系方式与主体信息、电商站的退换货与支付是否透明、内容是否准确不误导、是否有大量用户负面反馈、YMYL内容是否有适当的资质与免责。前三个E再强,可信度塌了,整个就塌了——一个经验丰富、很专业、被广泛引用,但被大量用户投诉欺诈的站,谷歌不会给它好结果。把可信度当地基,其余三个当地基上盖的楼,这个次序不能反。
| 维度 | 它在问什么 | 近似它的主要信号 |
|---|---|---|
| 经验(Experience) | 这事你真干过吗 | 原创性、第一手细节密度、与全网内容的差异度 |
| 专业(Expertise) | 你够格写这个吗 | 准确度与深度、作者与主题相关性、主题内容成体系 |
| 权威(Authoritativeness) | 别人认你吗 | 相关自然的链接与提及、行业引用、品牌搜索 |
| 可信(Trust) | 有理由信你吗 | 安全、主体透明、内容准确、交易可信、无大量负反馈 |
可信度有几个近乎一票否决的体检项,值得单独列出来对照:站点能不能安全访问、有没有真实可查的主体与联系方式、涉及交易时条款与售后是否讲清楚、内容里有没有明显的事实错误或误导性承诺、全网对这个品牌有没有成规模的负面反馈。任何一项严重不合格,前面三个E做得再好也兜不住。还有一个反常识但很关键的点:可信度是慢变量。掉量后临时加个联系页、补个隐私政策,不会第二天就把信任补回来——信任的积累和流失都是缓慢的,这意味着可信度基建必须前置、长期维护,指望出事了再补,时间上根本来不及。
普通站怎么把E-E-A-T落到可执行的清单上?
很多人一谈E-E-A-T就默认在说YMYL大站,其实非高风险的内容站、电商、B2B同样吃这套,只是力度和侧重不同。给一份不分行业都能照着做的落地清单,重点是每一条都对应前面拆过的某个信号,不是空喊。
- 内容溯源:重要内容有真实作者,作者信息能体现其与主题的相关性,不是放个虚构头像和一句套话简介——这对应专业性信号。
- 第一手要素:每篇核心内容里至少要有一处只有亲历者写得出的具体细节(数据、场景、失败教训),这是经验信号最直接的抓手。
- 主题成体系:围绕一个主题把相关问题成系统地覆盖,而不是什么热写什么,让站点在某个主题上形成深度,对应主题专业性。
- 可信度基建:HTTPS、清晰的关于与联系页、真实主体信息、电商把交易条款讲透——这是地基,缺一不可。
- 自然权威积累:把内容做到值得被同行自然引用,而不是反过来去刷链接;行业讨论和品牌搜索是慢变量,但它是真权威。
保哥带过的一个B2B工业设备客户,没有任何YMYL属性,但内容长期上不去。问题诊断下来不是技术,是整站文章像一个不存在的人写的——没作者、没案例、没有一句“我们在某个项目里实际遇到过”。后来的做法很朴素:让真正的工程师按项目复盘写,每篇带具体工况和踩过的坑,作者就用工程师真名加岗位。半年多之后,那些带真实项目细节的页面排名稳步起来,靠的不是什么E-E-A-T技巧,就是把前面这几条信号一条条做实了。如果你的内容做了这些还是不动,问题可能在别处,内容做了却不排名的系统排查那篇可以对照着往下查。
清单是通用的,但不同类型的站,发力的重心很不一样,平均用力反而低效。下面这张表是按站点类型给的侧重建议,照着把有限精力压到最该补的那一两项上:
| 站点类型 | 最该补的E | 具体抓手 | 常见短板 |
|---|---|---|---|
| 内容 / 测评站 | 经验 + 权威 | 第一手实测细节、可被自然引用的原始数据 | 通篇综述、无亲历、靠刷链接 |
| 电商站 | 可信 + 经验 | 交易条款透明、真实使用与售后内容、真人测评 | 只有商品参数,零可信度基建 |
| B2B / 服务站 | 专业 + 经验 | 真实项目复盘、署名到具体岗位的专家 | 内容像没人写的、零案例 |
| 个人博客 | 经验 + 可信 | 把“我亲身做过”讲透、作者与主体真实可查 | 泛泛而谈、身份模糊 |
| YMYL站 | 四项全要、可信优先 | 资质背书、事实准确、来源可溯 | 专业包装但拿不出可信度证据 |
看这张表会发现一个共性:几乎每一类的常见短板里都有“经验缺失”。这不是巧合——前三个传统维度大家多少都在做,唯独“拿出真做过的证据”这一项,是最难造假、也最被普遍忽略的,恰恰是2022年那个E被单独拎出来的原因。所以如果只能先补一项,对绝大多数非YMYL站,先补经验,性价比最高。
还要补一句反向提醒:不是所有掉量都该甩锅给E-E-A-T。它现在成了个万能背锅侠,技术问题、意图错配、季节性波动,都有人一掉量就归因到E-E-A-T然后瞎补作者框。判断它是不是真根因,有个朴素办法:把掉量的页面拉到一起,看它们有没有共同的质量短板(无作者、无一手、可信度缺失、洗稿同质),同时排掉技术和意图层面的解释。如果掉的页面质量短板高度一致、技术面又没硬伤,才大概率是E-E-A-T方向的问题;如果掉的页面质量参差、毫无共性,那大概率是别的原因,往E-E-A-T上使劲就是白费。一个能省很多冤枉路的习惯:掉量当天先把受影响页面导出,按主题、模板、有无作者、是否洗稿几个维度交叉切一遍,共性会自己浮出来——有共性才谈得上是不是E-E-A-T,没共性就别往这上面想。先确诊再下药,这点和算法掉量恢复完全一致。
关于E-E-A-T最常见的几个误解是什么?
把前面散落的澄清收一收,几个最坑人的误解集中说一遍。
第一个,“加个作者框就有E-E-A-T了”。作者信息是专业性信号的一种体现,但它是结果不是开关。给一篇没有任何第一手内容的文章硬安一个作者框,信号是空的,谷歌看的是这个作者与主题的真实相关性和内容本身的质量,不是有没有那个框这个动作。
第二个,“E-E-A-T是算法打分项”。前面讲透了,没有这个分数,它通过一堆信号被间接逼近。所以也不存在“E-E-A-T优化工具”能给你算个分数,给你算分数的工具算的是它自己定义的代理指标,不是谷歌的。
第三个,“做好了E-E-A-T排名就一定涨”。它是必要不充分。它对齐的是质量总方向,但具体排名还受意图匹配、竞争强度、技术健康等一堆因素影响。E-E-A-T做扎实更多是让你在核心更新里不掉、有资格参与竞争,不是按个按钮就涨。
第四个,“E-E-A-T是2022年才有的新东西,以前不用管”。它的内核(E-A-T)在质量评估指南里存在了十年以上,2018年Medic就实打实兑现过。2022年只是加了一个E,把“真实经历”单独强调出来,不是凭空造了个新标准。把它当新概念,等于无视了它背后十来年一以贯之的方向,每次核心更新都会重新被打一遍。
第五个,也是这两年最热的,“AI生成的内容必然没有E-E-A-T”。谷歌官方口径很明确:判断的是内容质量和是否符合E-E-A-T,不看生产方式是人还是机器。AI内容的真问题不在“是AI写的”,而在它天然缺第一手经验、容易产出与全网高度同质的内容——也就是经验和差异度信号弱。换句话说,不是AI这个工具被判死刑,是“无经验、无差异、批量灌”这种用法撞在了E-E-A-T的枪口上。用AI辅助但补足真实经历和独到判断的内容,照样能符合标准。
第六个,“只有YMYL才需要管E-E-A-T”。YMYL领域要求确实最严,但谷歌的质量标尺是普适的,非YMYL站只是容错高一些,不是不适用。如果你做的恰好是高风险领域,落地策略要更系统,这部分可以专门看YMYL高风险行业的E-E-A-T策略那篇;而在AI搜索越来越多直接引用内容的当下,权威信号怎么强化才能被AI优先引用,又是另一个延伸场景,强化E-E-A-T信号提升AI引用率那篇做了实测拆解。本篇守住一件事就够:先把“它不是分数、是方向”这个认知摆正,后面所有动作才不会跑偏。把这六个误解逐条对照自己团队最近半年说过的话和做过的动作,大概率能找出至少一两处一直在错误方向上花的力气——E-E-A-T这件事上,少做错事,往往比多做动作更值钱。
常见问题解答
E-E-A-T是谷歌的直接排名因素吗?
不是。谷歌官方多次明确没有E-E-A-T分数,它不进排名公式。它是质量评估指南里的概念,评估员据此打分来评价算法改动好坏,整套排名系统朝它描述的方向迭代,所以它影响排名但方式是间接的。
没有E-E-A-T分数,那怎么知道自己做得好不好?
看谷歌用来近似它的可观测信号:内容有没有第一手细节、作者与主题是否相关、内容是否成体系、站点可信度基建是否齐全、是否有相关自然的引用。逐条评估这些,比追求一个不存在的分数靠谱得多。
加个作者简介和头像就能提升E-E-A-T吗?
不能只靠这个。作者信息是专业性信号的体现,但前提是作者与主题真实相关、内容本身有质量。给空洞内容硬套作者框,信号是空的。它是结果的呈现,不是可以单独拧的开关。
非YMYL的普通内容站需要管E-E-A-T吗?
需要。谷歌的质量标尺是普适的,YMYL只是要求最严、容错最低。普通站容错高一些,但内容没经验、没溯源、没可信度基建,一样会在核心更新里掉,只是没有YMYL那么剧烈而已。
2022年加的那个Experience和Expertise有什么区别?
Expertise是“你够格写这个”,靠知识与资质;Experience是“这事你真干过”,靠第一手经历。一篇评测把参数列全是Expertise,写出只有亲自用过才知道的细节才是Experience。加这个E就是为了给真实经历单独加权。
E-E-A-T做好了排名就会涨吗?
不一定,它是必要不充分。它让你对齐质量总方向、在核心更新里不掉、有资格竞争,但具体排名还取决于意图匹配、竞争强度、技术健康等。把它当不掉队的地基,而不是涨排名的开关。
掉量后怀疑是E-E-A-T问题,第一步该查什么?
先确诊不要急着改。核对内容有没有真实作者与第一手细节、可信度基建是否齐全、是否在低质聚合或洗稿模式上、掉的页面有没有共同的质量短板。先找到质量根因,再动手,逻辑和算法掉量恢复一致。
权威参考资料
本文标题:《E-E-A-T到底是不是排名因素?怎么落到可执行清单》
本文链接:https://zhangwenbao.com/eeat-ranking-factor-myth-signal-checklist.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0