Commodity Content是什么?谷歌正在批量清掉的“可替代内容”长什么样
本文目录
摘要:你有没有过这种憋屈:一篇内容查了资料、认认真真写了三千字,结构清晰、该有的都有,发出去却石沉大海?问题很可能不在“写得好不好”,而在它“可不可被替代”。谷歌内部有一套机制专门干这件事:判断你这篇相比全网已有的内容,到底提供了多少新东西。提供不了,它就是一篇commodity content(商品化内容),写得再工整也挤不进好排名。这篇带你看懂谷歌怎么识别可替代内容、non-commodity到底差在哪三样、以及出海独立站怎么把内容从“可替代”改造成“非你不可”。
先讲个扎心的现象。很多出海独立站的运营,内容产出节奏拉得很满,一周三五篇,标题规整、配图齐全、关键词也塞了,数据却纹丝不动。他们百思不得其解:我明明很努力啊。但努力的方向,可能从一开始就错了——他们产的,全是谷歌眼里“随便哪个同行都能写出来”的东西。
这背后藏着一个这几年越来越关键、却被中文圈讲得很模糊的概念:内容的“可替代性”。理解它,你才能想明白为什么有些内容天生就排不上、为什么AI批量生产的稿子正在被系统性地清理,以及你该把宝贵的时间和预算,到底投到哪种内容上。下面一层层拆开讲。
什么是Commodity Content?为什么你写得越认真,排名越上不去?
Commodity Content,直译是“商品化内容”,但它的精髓用四个字概括最准:可被替代。指的是那种能被全网大量网站轻松复制、谁写出来都差不多的内容。
典型长什么样?“新手做SEO的10个技巧”“2026年家居流行趋势”“选跑鞋要注意的7件事”——这类标准清单、泛泛的入门指南、浮于表面的概念解释,就是commodity content的标准像。它们不是错,也不是质量差,单看每一篇都挑不出毛病。问题在于:它提供的信息,全网已经有几百上千个页面讲过了,一模一样。
这就解释了那个憋屈的现象:你写得很认真、很工整,但“工整”恰恰是commodity content的特征——因为它本质上是在复述行业里人尽皆知的常识,复述得再流畅,也还是复述。谷歌要解决用户的搜索需求,但它没有理由把第1001个讲同样内容的页面排到前面去,那对用户毫无增量价值。
很多人到这儿会反驳:可我看那些大站的清单文排得挺好啊。没错,但请注意——它们能排上去,往往是因为站点本身权重高(还记得页面被分进哪个索引层、很大程度由站点级信号决定吗),而不是因为那篇commodity内容本身有多强。一个新站、一个权重还没立起来的出海独立站,想靠commodity content去硬碰这些大站,几乎是必输的牌。关于页面为什么会因为站点成色被打入低层,可以看站内这篇谷歌分层索引机制:你的页面被丢进Base、Zeppelin还是Landfill,commodity content正是填埋场(Landfill)的常住居民。
这里要厘清一个常见的混淆:commodity content不等于“短内容”或“写得潦草的内容”。恰恰相反,很多commodity content篇幅很长、排版精美、数据图表一应俱全——它只是把全网都有的信息,包装得更漂亮了一点而已。判断的标尺从来不是长度或精致度,而是“这些信息别处有没有”。一篇两千字的精美攻略,如果讲的全是行业通识,它在谷歌眼里和一篇三百字的草草总结,本质是同一类东西:可替代。想通这一点,你就不会再拿“我写得很用心、很长”来安慰自己了。
再补一个出海场景里特别高发的commodity陷阱:直接翻译。很多团队把中文的爆款攻略机翻成英文挂上独立站,以为自己搬运了优质内容。但站在谷歌的角度,这篇英文内容讲的东西,英文世界早有无数原生页面覆盖过了,翻译并不产生任何信息增益——它只是把一份commodity从一种语言搬到了另一种语言。跨语言搬运,搬来的往往还是commodity,甚至因为表达生硬、水土不服而更糟。真正有价值的,是你基于本地市场的真实观察和一手数据,写出连英文母语世界里也没人讲过的角度——那才是翻译永远替代不了的增量。
谷歌到底怎么识别“可替代内容”?信息增益专利说透了机制
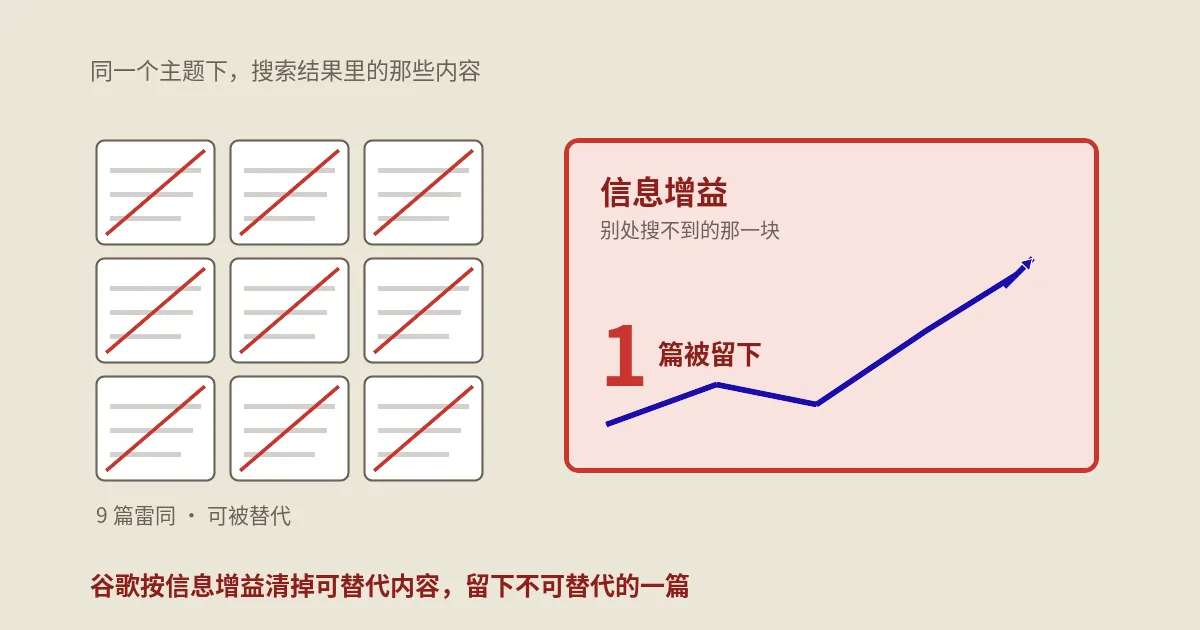
光说“可替代”太虚,谷歌是怎么量化这件事的?这里有个硬核但极其重要的机制,叫信息增益(Information Gain)。
谷歌在2018年申请、2024年6月正式获批了一项专利,名字叫《Contextual estimation of link information gain》(专利号US20200349181A1)。它的核心思想是给文档算一个“信息增益分”——衡量的是:相比用户已经看过的那些文档,你这篇额外提供了多少新信息。注意这个参照系,它不是孤立地评判你写得好不好,而是把你放进“全网已有内容”这个大池子里,看你有没有带来增量。
这个机制简直就是为commodity content量身定做的判官。一篇标准清单文,信息增益分必然很低——因为它讲的东西,用户在前十个搜索结果里早看腻了,你这篇没带来任何新东西。而一篇基于第一手数据、独到分析的内容,信息增益分就高,因为它提供了别处找不到的信息。谷歌不是在问“你写得对不对”,而是在问“你有没有说一些别人没说过的、有价值的东西”。
把信息增益和前面讲的分层索引连起来看,整个逻辑就闭环了:信息增益低的commodity content,拿不到进入高质量索引层的门票,被分流到几乎不参与排名的低层;信息增益高的内容,才有资格进Base层去竞争。这也是为什么谷歌官方在它的内容指南里反复追问创作者一个问题——“你的内容是否提供了原创的信息、报道、研究或分析?”这句话不是客套,它直接对应着信息增益这个底层评判逻辑。这套官方自评标准,我放在文末参考资料里,值得逐条对照自己的内容。
信息增益还有个容易被忽略的妙用:它和搜索结果的多样性直接挂钩。谷歌在返回结果时,并不想给用户十个内容雷同的页面,那体验很差。所以一篇信息增益高的内容,即便它的站点权重不是最顶尖的,也可能因为“提供了别人没有的角度”,被谷歌捞进结果里去丰富多样性。这对中小出海站是个难得的突破口:你拼不过大站的权重,但你可以靠独家增量,挤进那个“为了多样性而保留的位置”。这也是为什么有时候一篇极其垂直、极其独到的小众内容,能在巨头环伺的搜索结果页里硬生生占住一席之地。
那信息增益分到底怎么影响排名位置?谷歌的机制大致是这样:初步检索会先拉出一批最相关的结果,然后在补充检索(secondary results)这个环节,为了让结果集更丰富、更不重复,会优先纳入那些相比已选内容信息增益更高的页面。换句话说,信息增益不只是一个“质量分”,它更像一张“差异化入场券”——你越是提供别人没有的增量,越容易在第二轮筛选里被捞进来。对那些靠权重挤不进第一梯队、却确实有独到内容的中小站页面来说,这是个被绝大多数人忽略的上位通道。看懂这条通道,你就知道为什么死磕独家增量,对小站是性价比最高的策略。
Non-Commodity不是“多加点东西”,而是哪三样?
知道了什么是commodity,反过来——non-commodity content(非商品化内容)该怎么做?这里有个巨大的误区必须先破除:non-commodity不是在commodity的基础上“多加点东西”、多堆几段、多塞几个数据就行了。那只是更长的commodity而已,信息增益一样是零。
真正的non-commodity content,靠的是三样东西,缺一不可:
- 独特性(Unique)。你得有别人没有的视角、观点或切入角度。同样讲一件事,你能看到别人看不到的那一层。
- 具体性(Specific)。不是放之四海皆准的通用规则,而是具体到某个场景、某个数字、某个真实决策的细节。越具体,越难被替代。
- 真实性(Authentic)。来自第一手的经历或知识,是你亲自做过、踩过、验证过的东西,而不是东拼西凑的二手转述。
举个出海卖家能秒懂的对比。一个做美妆护肤的DTC独立站,写“油性皮肤护理的8个建议”——这是commodity,全网烂大街。但如果它写的是“我们分析了2000个客户的复购数据,发现含某成分的产品在湿热气候地区退货率高出40%,于是我们这样调整了配方推荐逻辑”——这就是non-commodity。独特(自家数据视角)、具体(2000个客户、40% 这种实打实的数字)、真实(亲自做的分析)。前者谁都能写,后者只有这家店能写。这就是不可替代性的来源。
这三样其实和谷歌强调的E-E-A-T里的“经验”(Experience)高度重合——亲历、第一手、有真实细节。想系统理解这套质量信号怎么搭,可以配着站内这篇E-E-A-T完整指南与8大信号清单一起看,non-commodity本质上就是把E-E-A-T落到每一篇具体内容上的产物。
这三样里,出海独立站最容易做到、却最常被白白浪费的,是“真实性”。你每天都在跟真实的海外客户打交道、处理真实的订单和退货、收到真实的产品反馈——这些第一手素材,是任何一个坐在办公室里查资料的写手都编不出来的。可惜的是,太多团队把这些金子般的一手信息烂在客服系统和后台数据里,却跑去抄竞品的通用攻略。把你业务里真实发生的事如实写出来,本身就是成本最低的non-commodity。它不需要你多有文采,只需要你愿意把真实的细节呈现出来,这恰恰是抄袭者和AI永远给不了的。
为什么AI泛滥的当下,这个区分突然变得生死攸关?
Commodity和non-commodity的区分一直存在,但为什么是现在、突然变得这么要命?答案两个字:AI。
2025年下半年开始,全网新发布的内容里,相当大一部分是AI改写、AI洗稿出来的。AI最擅长干什么?正是批量生产commodity content——它把全网已有的信息重新组织、换种说法吐出来,又快又流畅。但请注意一个本质:改写,按定义就是“不产生新信息”。AI把一篇文章洗成另一篇,信息增益是零,因为它没有任何超出原始语料的新东西。
这下你就明白谷歌为什么把信息增益这个机制推到了前所未有的核心位置。当commodity content的生产成本被AI拉到趋近于零、全网被洗稿内容淹没时,信息增益就成了那把最锋利的筛子——它专门度量“新颖性”,而新颖性恰恰是洗稿这个动作天生缺失的东西。谷歌用它来对抗内容通胀,再自然不过。
这对出海独立站是个残酷但也公平的信号。残酷在于:你想靠AI批量铺commodity content抢流量的路,基本被堵死了,铺得越多,越可能被判定为低质内容工厂,反噬整站。公平在于:那些AI给不了的东西——你的第一手经验、真实数据、独到判断——反而因为稀缺,变得前所未有地值钱。关于规模化、模板化内容是怎么被谷歌的有用内容系统集中清理的,站内这篇Google HCU有用内容系统完整指南与恢复实战讲得很透,本质上HCU打击的,就是站点层面堆积的commodity content。
保哥这两年观察下来,那些在AI浪潮里不仅没垮、反而流量逆势上涨的出海站,有个共同点:它们早早就停止了和AI拼产量的愚蠢竞赛,转而把人力压到AI做不了的地方——实地测评、客户深访、自有数据分析。当全网都在用AI批量吐commodity时,一篇带着真实体温的non-commodity,反而成了稀缺品,信息增益的优势被无限放大。这是一场反直觉的竞赛:产得越慢、越重、越难,护城河反而越宽。想明白这层,你就不会再焦虑“同行一天发十篇而我只发一篇”了——你们产的根本不是同一种东西。
这里也得给个务实的提醒:non-commodity不等于篇篇都要惊天动地的独家大数据。有时候一个真实的小细节、一次具体的客户对话、一张你自己拍的产品对比图,就足以构成增量。门槛没你想的那么高,难的是养成“凡事问一句这有没有新东西”的习惯。把这个意识装进脑子,你会发现日常业务里到处是别人没有的素材,只是过去你从没把它们当回事,白白浪费了。
一篇内容是不是commodity,自己怎么测?
道理懂了,落到操作上:我写完一篇,怎么自己判断它到底是commodity还是non-commodity?给你四个能当场上手的检验问题。
第一问,可替代性测试。把你这篇的核心内容,想象成搜索结果里的一条。问自己:如果用户已经看了前面五个结果,我这篇还能给他任何新东西吗?如果答案是“好像没有,我讲的他们都讲过”,那它就是commodity,信息增益接近零。
第二问,信息源测试。这篇内容里的关键信息,是来自你的原始数据、亲身经历,还是来自“我综合了几篇行业文章”?前者是non-commodity的根基,后者是commodity的标志。一篇全靠聚合二手信息拼出来的文章,再长也是可替代的。
第三问,确定性测试。commodity content有个语言特征:满篇都是“可能”“一般来说”“建议你”这种模棱两可的对冲措辞,因为作者自己也没真做过,不敢下结论。而non-commodity敢给出确定的判断——“在湿热地区就别推这个配方”——因为它背后有真实依据撑腰。你回头看自己的稿子,模糊词越多,越可能是commodity。
第四问,边界测试。检查你的“差异化”是在主题范围内做深,还是靠扯开话题、东拉西扯来凑独特。真正的non-commodity是在同一个主题里挖得比别人深,而不是为了显得不一样而跑题。在语义边界内做深,才是谷歌想要的增量。把这四问养成发布前的习惯动作,你的内容质量地基会比绝大多数同行扎实得多。
这四个测试里,最值得反复用的是第一个——可替代性测试。它可以简化成一句口头禅,发布前默念一遍:“凭什么是我?”凭什么用户要看我这篇,而不是已经存在的那一千篇?如果你答得出一个具体的、别人给不了的理由,这篇就值得发;如果你支支吾吾,只能说出“我写得比较全”这种话,那它大概率就是又一篇commodity,发了也不过是给填埋场再添一块砖。把“凭什么是我”刻进发布前的肌肉记忆,比任何花哨的内容模板和AI提示词都管用。
出海独立站怎么把commodity内容改造成non-commodity?
光会判断不够,关键是会改造。一个出海独立站,手里往往已经有一堆commodity内容,全删了不现实,怎么把它们盘活?保哥常用的是下面这套改造路径。
第一步,换信息源。这是最根本的一招。把内容的信息来源,从“竞品研究、行业聚合”换成“自家业务数据”。你有客户、有订单、有退货记录、有真实的咨询对话——这些是全网独一份的金矿。一篇“如何选户外背包”的commodity文,换成“从我们三年的退货数据看,80% 的退货是因为用户低估了背负系统的重要性”,立刻就有了别人复制不了的内核。
第二步,在主题边界内往深里挖。别人讲“怎么做”,你就讲“为什么这么做、什么情况下别这么做、我们试错踩过哪些坑”。同一个主题,你比所有人都多挖三层,深度本身就是不可替代性。
第三步,把对冲措辞换成有依据的确定结论。每当你想写“一般建议……”时,停一下,问自己:基于我的实际经验,我能不能给一个更确定的判断?能,就把模糊词删掉,给结论加上你的依据。确定性是non-commodity的气质。
第四步,建立你自己的分析框架。最高阶的差异化,是你总结出一套别人没有的、命名过的方法论或判断模型。当读者只能在你这儿学到这套框架时,你就彻底不可替代了。去年保哥帮一个做出海3C配件的独立站做内容改造,就是把原来一堆“产品使用技巧”的commodity文,全部重构成基于他们自家售后数据的“高频故障归因 + 选购避坑”体系,半年后这批改造过的页面,自然流量涨了一大截,因为每一篇都讲了别处查不到的东西。
改造的时候还有个心态要摆正:不是每一篇commodity都值得救。有些页面既没流量、信息又彻底大路货,与其花力气改造,不如果断合并或删掉,把省下的精力投到真正有潜力的内容上。改造的对象,应该是那些“主题有价值、只是写法太通用”的页面——它们底子还在,缺的只是注入你的独家信息源。分清哪些该救、哪些该弃,本身也是内容运营的基本功,眉毛胡子一把抓,只会把自己累死还看不到效果。
商品化内容搜索量明明最大,放弃它不可惜吗?
讲到这儿,必须诚实地面对一个矛盾,否则就是耍流氓:commodity content对应的那些大词、宽泛词,搜索量往往是最大的。“怎么选跑鞋”的搜索量,肯定碾压“跑鞋在400英里后的磨损分析”。一刀切地放弃commodity,是不是把最大的流量蛋糕拱手让人?
这是个好问题,答案是辩证的。首先得承认:对一个权重不够的新站,那些高搜索量的commodity大词,本来也排不上,放不放弃都拿不到,纠结它没意义。你硬冲只是浪费弹药。
其次,AI概览(AI Overview)的普及,正在改变commodity内容的价值。那些有标准答案的commodity查询,谷歌越来越倾向于直接用AI概览在搜索页给出答案,用户根本不点进任何网站。换句话说,commodity content即便排上去了,能拿到的点击也在被AI概览持续蚕食。你赌的那个“高搜索量”,正在贬值。
但反过来也不能极端。non-commodity内容有时确实没法很好地服务那些最宽泛的搜索意图——用户就想快速知道“选跑鞋看哪几点”,你甩给他一篇深度磨损分析,可能并不解渴。所以成熟的做法不是非此即彼,而是想清楚两者各自的角色定位。这就引出了最后一个关键问题:到底该怎么配比。
还有个更深的趋势值得出海人警惕:随着AI概览和AI搜索越来越普及,用户的搜索行为正在悄悄分化。要“快速标准答案”的那部分需求,越来越多被AI直接接走了;而真正还会点进网站、愿意花时间读完的用户,往往是带着更具体、更深、AI三言两语满足不了的需求来的。这意味着non-commodity内容对应的那部分流量,不仅质量更高、转化意图更强,还更抗AI的冲击。从生意的角度看,这部分用户才是出海独立站真正该死磕的对象——他们不只是流量数字,更是实打实的潜在下单者。
所以与其纠结要不要放弃高搜索量的commodity大词,不如换个问法:我有限的资源,投在哪种内容上回报更高?对绝大多数出海独立站,答案都是后者——那些搜索量没那么吓人、但意图精准、又能被你的独家增量牢牢占住的长尾词。流量的绝对数字会骗人,能转化成订单的那部分流量才是真的。盯着虚荣的大词流量眼红,不如把精准的、能下单的流量稳稳攥在自己手里。
commodity与non-commodity,到底该按什么比例配?
纯做non-commodity太理想化,纯做commodity又没出路,真实世界的内容策略,是一个组合配比的问题。保哥给出海独立站的建议是按站点阶段动态调整。
新站起步期,重心压在non-commodity上。这个阶段你权重低、commodity大词根本抢不到,唯一能撕开缺口的,就是那些竞争小、但你有独家信息增益的non-commodity长尾内容。用它们建立站点的初始质量信号,让谷歌先认可你“这个站能产出别处没有的东西”。这是为整站的索引层级打地基。
成长期,开始有策略地补commodity。当站点积累了一定权重、有了一批non-commodity撑场的内容后,可以适当补一些做得比同行更好的commodity内容,去覆盖那些必要的宽泛词——但前提是,你得借着已有的站点权重去做,而且尽量在commodity的框架里也塞进一点non-commodity的内核,别做成纯粹的复述。
任何阶段,都别让commodity拖累整站。这是底线。一堆纯commodity的薄页面挂在站上,会拉低整站的平均质量信号,把你往低质内容工厂的方向推。定期审计,把那些既没流量、又毫无信息增益的纯commodity页面清理或合并掉,给站点级信号松绑。
说到底,commodity和non-commodity的配比,不是一个固定公式,而是一种持续的判断:你的每一分内容预算,是花在“又一篇谁都能写的东西”上,还是花在“只有你能提供的增量”上。想清楚这个,你对内容的投入就会和那些还在拼命堆量的同行,拉开根本性的差距。在AI把commodity内容打成白菜价的时代,能产出真正不可替代内容的能力,才是出海独立站最硬的护城河。
最后给一个能落地的盘点思路:每个季度做一次内容体检,把所有页面按“信息增益高低”和“带来流量多少”两个维度分成四个象限。高增益、高流量的,是你的王牌,持续加固;高增益、低流量的,多半是优化空间,调标题、补内链给它导流;低增益、高流量的,靠的多半是历史权重撑着,盯紧别掉、有余力就注入点增量;低增益、低流量的,果断合并或删除,别让它拖累整站。这套四象限盘点做顺了,你的内容资产会越来越健康,整站的质量信号也会跟着稳步往上走,形成正向循环。
这套打法,听起来确实比无脑堆量累得多,做起来也是。但出海这门生意,拼到最后从来不是比谁发得多,而是比谁的内容能在用户和谷歌那里同时立得住。commodity content就像快消品,多而廉价、随时可被替代;non-commodity则像手艺品,慢工出细活,却能沉淀成别人抢不走的资产。在一个AI能瞬间复制一切“可复制之物”的时代,你唯一的安全区,就是去做那些不可复制的事。这不只是一套SEO方法论,往大了说,它也是出海品牌能不能活得长久的底层逻辑——能被轻易替代的东西,从来都卖不上价。
最后送你一句话,记住它,胜过记住本文所有的方法论:在内容这件事上,别问“我怎么才能写得更多”,要问“我怎么才能写得更不可替代”。前者让你一头扎进和全世界、和AI拼产量的内卷里,越卷越累、越累越没价值;后者让你跳出那场注定没有赢家的竞赛,去专心做那件只有你能做的事。方向对了,慢一点,真的无妨。
常见问题解答
Commodity content是不是就等于低质量内容?不完全是。commodity content单看质量未必差,它可能写得工整、信息也准确。问题在于“可替代”——它讲的东西全网已有大量雷同页面,没带来新信息(信息增益低)。所以它不是“写得烂”,而是“没必要由你来写”。
信息增益是谷歌真实在用的机制吗?有专利支撑。谷歌2018年申请、2024年获批了《Contextual estimation of link information gain》专利(US20200349181A1),核心就是衡量一篇内容相比用户已看过的文档提供了多少新信息。在AI洗稿泛滥的当下,它的权重被推到了非常核心的位置。
把commodity内容写得更长、更详细,能变成non-commodity吗?不能。加长只是变成更长的commodity,信息增益还是零。non-commodity的关键不是长度,而是独特性、具体性、真实性——有没有别人给不了的视角、具体细节和第一手经验,跟字数多少没关系。
用AI写内容是不是一定会被判成commodity?看你怎么用。如果只是让AI把现有信息改写、聚合,那产出必然是commodity,信息增益为零。但如果你用AI辅助整理你自己的原始数据、真实经验,再注入独到判断,产出依然可以是non-commodity。问题不在工具,在于有没有新信息。
commodity content搜索量大,完全放弃会不会丢流量?分情况。新站本来就抢不到高搜索量的commodity大词,放弃没损失。而且AI概览正在直接回答这类标准查询,commodity内容即便排上也拿不到多少点击。比起赌贬值中的大词,不如把弹药投在你有信息增益的non-commodity上。
出海独立站没有大量原始数据,怎么做non-commodity?数据只是来源之一。你的客户咨询记录、退货原因、真实使用反馈、自己测试产品的过程,全是独家信息源。哪怕样本不大,“我们亲自测了这5款、结果是这样”也比聚合二手信息强得多,关键是亲历和具体。
怎么快速判断自己一篇内容是不是commodity?问一句话:用户看完搜索结果前五名后,我这篇还能给他新东西吗?答不上来,就是commodity。再看信息源(自家数据还是二手聚合)、措辞(确定结论还是满篇“可能”),基本就能判定。
权威参考资料
本文标题:《Commodity Content是什么?谷歌正在批量清掉的“可替代内容”长什么样》
本文链接:https://zhangwenbao.com/commodity-content-information-gain-seo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0