Google分层索引揭秘:你的页面被丢进Base、Zeppelin还是Landfill?

本文目录
摘要:你的页面被谷歌抓了、甚至在站长后台显示“已编入索引”,却死活挤不进搜索结果——很多时候不是内容不够好,而是它一进门就被分到了错误的那一层。谷歌的索引从来不是一个平面的大池子,而是分成三层:Base、Zeppelin、Landfill。2024年泄露的内部文档把这件事彻底坐实了。这篇带你拆透三层各装什么、到底是谁决定你落在哪一层、掉进最底层还有没有救,以及一个出海独立站怎么避免上线第一天就被丢进“填埋场”。
先说一个让无数独立站卖家抓狂的场景。你辛辛苦苦写了一篇产品长文,提交了sitemap,过几天打开Google Search Console,状态显示“已抓取 — 尚未编入索引”,或者更气人的,“已编入索引”但你拿关键词去搜,翻到第8页都找不到自己。于是你开始怀疑人生:是不是关键词没堆够?是不是外链太少?是不是该再加几个H2?
保哥做了二十多年SEO,常年给出海DTC独立站做顾问,见过太多人在这个岔路口往错误的方向使劲。真相往往很扎心:你的页面质量可能根本不是瓶颈,问题出在它被谷歌放进了一个“几乎不参与排名”的索引层。这不是玄学,是有专利、有泄露文档、有内部系统名字撑着的硬机制。下面我们一层一层揭开。
为什么你的页面“抓了、也收录了”,却死活排不上?
这件事的根子,在于大多数人把“抓取”“索引”“排名”当成了一条直线:谷歌爬到我 → 把我存进索引 → 我就能参与排名。错就错在最后那一步。
真实的链路里,“被存进索引”和“被存进哪一层索引”是两码事。谷歌的搜索系统在响应一次查询时,并不会把全网几千亿个页面平铺开来挨个比对——那样的算力成本是任何公司都扛不住的。它的做法更聪明:把文档按预估的重要程度,提前分进不同的“货架”,查询来了先翻最顶上那层货架,质量够高、结果够多就停手,根本不往下翻。
所以你会遇到一种很拧巴的状态:谷歌确实抓到了你,也确实给你建了索引条目,但把你扔进了最底下那层货架。用户的查询压根没翻到那一层,你自然就“查无此页”。说白了,收录只是拿到了入场券,能不能上场,看你被分到了哪个看台。对一个英文站林立、竞争惨烈的出海赛道来说,这个差别往往就是“有自然流量”和“零自然流量”之间的天堑。
这也解释了一个长期被误读的现象——GSC里那个“已抓取 — 尚未编入索引”。很多人以为是谷歌没抓全、或者抓取预算不够。其实不少情况是:谷歌看了你一眼,评估完直接把你判去了最底层,连建主索引条目都省了。瓶颈不在“爬虫够不够勤快”,而在“分配把你放到了哪儿”。这个区分极其关键,后面专门有一节来掰扯抓取预算这个被甩锅最多的背锅侠。先把它记在心里:能不能被翻到,取决于层级,而不是取决于谷歌有没有“看见”你。
Google的索引,根本不是一个大池子?
分层索引不是某个SEO博主拍脑袋编的概念。它有两条独立的证据链,一条是公开了二十年的专利,一条是2024年炸开的内部文档。两头一对,这事基本盖棺定论。
先看专利。早在2004年,谷歌就申请了一项名为《Index partitioning based on document relevance for document indexes》的专利(专利号US7293016B1)。它写得明明白白:被索引的文档按一个“静态排名”(static ranking)来排列、分区;查询时先访问第一个分区,只有当后续分区里某个文档的静态排名高到一定阈值时,才会继续往下一个分区搜。翻译成人话——谷歌二十年前就在专利里写好了“分层、先翻高层、不够再往下”的玩法。同期还有Anna Patterson那项著名的短语索引(phrase-based indexing)专利,思路一脉相承:索引不是均质的,是有结构、有层次、有取舍的。
专利只能证明“谷歌想这么干”,真正把“它确实这么干了、而且现在还在干”坐实的,是2024年3月那场泄露。谷歌内部的Content Warehouse API文档被意外发布到GitHub上,足足2596个模块、上万个属性。在这堆文档里,有一个系统的名字格外刺眼——SegIndexer,它的职责描述就一句话:把文档放进索引里的不同层级(tiers)。配套还有一个叫 scaledSelectionTierRank 的属性,以及索引阶段(内部代号Alexandria)的 IndexTier 分类。这些字段直接给三个层级起了内部名字:Base、Zeppelins、Landfills。
这就是证据链的闭环:二十年前的专利说了“会分层”,二十年后的泄露说了“分层的系统叫SegIndexer、三层分别叫什么”。中间这二十年,supplemental index(补充索引)这个老概念也一直是同一件事的不同马甲——谷歌2007年悄悄取消了搜索结果里的“补充结果”标签,但底层的分层逻辑从没消失,只是不让你看见了而已。一个东西名字换了三轮、标签撤了,核心机制却二十年如一日地在运转,这本身就说明它有多重要。
关于这次泄露的逐模块拆解,业内做得最透的是Mike King那篇长文,他把Mustang、NavBoost、各种Twiddler之间的关系理得很清楚;而把分层命名(Base/Zeppelins/Landfills)和 scaledSelectionTierRank 单独拎出来讲明白的,是Shaun Anderson对PerDocData文档模型的解析。这两篇我都放在文末的参考资料里,想深挖的可以去对原文,别只听二手转述。
顺带把分层在整条排名管线里的位置说清楚,你会更明白它为什么这么要命。一次查询进来,谷歌大致是这么走的:先由打分系统(泄露文档里管它叫Mustang)算出一批候选,而这批候选到底从哪儿捞,正是由分层决定的——优先从Base层取,不够才往下探;捞出来之后,再交给一堆被称作Twiddler的重排函数做微调。看明白了吗?分层发生在整条排名链路的最上游,它决定的是你有没有资格被放进那个“候选池”。在最上游就被刷掉,后面那些你绞尽脑汁优化的页面因素、关键词布局、内链锚文本,根本没机会登场。这就是为什么很多人页面级的优化做到极致,排名却纹丝不动——力气全使在了下游,而卡你的闸在上游。
Base、Zeppelin、Landfill三层,各自的真实面目是什么样?
名字听着玄乎,其实拿快递分拣中心来类比一下就全懂了。同一个仓库,包裹会按时效和价值分进不同区域:次日达的高优先件放在离出货口最近、随时调得到的核心区;普通件放在常规货架;而那些地址不全、反复退回、没人认领的,堆在最角落的暂存区,基本不参与正常发货流转。谷歌的三层索引,就是这么个分拣逻辑。
| 层级 | 内部代号 | 装什么页面 | 排名待遇 |
|---|---|---|---|
| 第一层 | Base(基础层) | 高质量、原创、有需求支撑的页面 | 主力排名索引,绝大多数搜索结果从这里出;用户查询第一站就翻这层 |
| 第二层 | Zeppelin(齐柏林层) | 中等质量、价值模糊的页面 | 只有当基础层结果不够用时,才会被“扩展搜索”捞一下,排名机会大幅缩水 |
| 第三层 | Landfill(填埋场) | 低质、重复、单薄(thin)内容 | 几乎在排名流程开始前就被取消资格,约等于“收录了但永不出场” |
这里有个细节值得单独点一下:根据泄露文档的解析,链接的权重也跟着层级走。来自Base层页面的链接,传递的权重远高于来自Landfill层页面的链接。这一下就解释了为什么你买的那些站群外链、目录外链基本没用——发出链接的那些页面本身就躺在填埋场里,它们给你投的票,谷歌根本不怎么记。你以为买了100条外链,实际有效的可能就个位数。这也是为什么同样花一万块预算,有人买来一堆数字好看却毫无作用的链接,有人却只换三五条真正管用的——差别就在源页面在哪一层。
那怎么大致判断一个页面够不够格进Base层?没有官方清单,但结合泄露信号和这些年的实操,大致绕不开这么几条:内容有没有真正解决某个具体查询的需求、有没有第一手信息或数据增量、页面所在站点的整体权重托不托得住、有没有真实用户的点击与停留在给它背书。这几条里,前两条靠单篇努力就能改善,后两条只能靠站点级的长期积累。新站最容易卡在后两条上——单篇写得再惊艳,站点权重托不起,照样进不了Base。这也是为什么“先建站点权重、再上内容产量”这个顺序对出海新站如此关键,后面专门会讲。
保哥去年帮一个做跨境宠物用品的DTC独立站做诊断,就撞上过这个坑。站长很得意地说自己半年攒了三百多条外链,可Ahrefs上DR纹丝不动,目标关键词也不涨。我拉了一批源页面出来看,七成以上是那种内容空洞、模板批量生成的“资源页”——典型的填埋场住户。三百条听着唬人,能进Base层、真正算数的没几条。这事后来我在站内那篇网站权威到底是什么、DR怎么一步步提上去里展开讲过,外链质量从来不是数数游戏,是“源页面在哪一层”的游戏。
决定你落在哪一层的,为什么不只是页面质量?
这是整件事里最反直觉、也最容易被忽略的一点。大部分人默认:页面写得好就进Base,写得烂就进Landfill,单页定生死。错。
泄露文档透露的真相是:static rank(静态排名)不只看单个页面,整个站点的信号会影响一个新页面的初始层级分配。也就是说,你这篇新文章还没怎么被用户检验过,谷歌就已经先根据“你这个站平时什么成色”给它派了个起始座位。影响这个起始座位的,包括但不限于:
- 站点的整体链接情况——有多少高质量站点指向你;
- 历史上被用户从搜索结果点进来的次数和频率;
- 站点级的权重沉淀;
- 外链的质量构成(注意是质量,不是数量);
- 用户行为数据——停留、点击、回访;
- 历史点击表现。
看出问题了吗?这是一个不折不扣的“马太效应”循环。一个已经有权重的老站,发一篇新文,默认分到较高的层级,于是获得更多曝光,用户点击、停留进一步强化了它的位置,下一篇又站在更高的起跑线上。而一个权重薄的新站,新文默认被丢进低层,曝光少得可怜,没有曝光就没有用户信号,没有信号就更涨不上去——越穷越没机会,越没机会越穷。
这对出海新站尤其残酷。你做美妆、做户外装备、做3C配件,对面排在前面的可能是经营了十几年、攒了海量品牌外链的老牌竞品。同样一篇评测,它发出来默认进Base层当天就排上,你发出来默认进Zeppelin甚至Landfill,石沉大海。不是你内容差到哪里去,是你俩的页面从落地那一刻起就不在同一层货架上。理解了这点,你就不会再为“我明明写得更用心却排不过它”而钻牛角尖——这是结构性差距,不是临场发挥的差距。
想理解这套“站点级信号”具体由哪些东西构成、又该怎么系统性地往上做,我建议配着站内这篇E-E-A-T完整指南与8大信号清单一起看,它把“怎么让谷歌觉得你整个站靠谱”拆得比较细。站点级信号这东西,你越早开始攒,后面的每一篇内容就越省力。
“抓取预算不够”是不是被滥用最多的伪诊断?
来了,那个被甩锅最多的背锅侠。每当页面收录不理想、排名上不去,总有人第一反应是:“肯定是抓取预算(crawl budget)不够,得优化爬虫效率。”然后一头扎进robots.txt、nofollow、URL参数清理里折腾半天。
我不是说抓取预算完全不重要,对那种几百万页的超大电商站它确实是个真问题。但对绝大多数中小独立站来说,把排名问题归咎于抓取预算,是一个典型的误诊。真正的瓶颈往往不在抓取层(crawling),而在服务层(serving)——也就是前面反复讲的分层分配。
逻辑很简单:谷歌可能早就把你的页面抓了,甚至索引了,但分配到了Zeppelin或Landfill。这种情况下,你把抓取预算优化到天上去,让爬虫每天来你站里跑一百趟,也改变不了你躺在低层这个事实。爬虫勤快和你能不能排名,是两个不同环节的事。你拼命擦的那扇窗,根本不是漏水的那扇。
怎么快速分辨自己是哪种情况?给你一个粗糙但管用的判断:如果你的页面在GSC里大面积是“已发现 — 尚未抓取”,那可能真有抓取层的问题,值得查查抓取预算和站点架构;但如果是大面积“已抓取 — 尚未编入索引”,甚至“已编入索引”却毫无排名,那八成是分层在作祟,再优化抓取也是白费力气,该去做的是站点级质量的事。关于抓取预算到底该怎么科学看待、哪些站才真需要管它,站内这篇谷歌抓取预算优化的12项实操指南给了一套完整的判断框架,建议先读它确认自己到底是不是真的有抓取问题,别一上来就乱投医。把力气花在错误的环节,是SEO里最常见也最隐蔽的浪费。
举个最典型的误诊场景:某个出海独立站的站长发现新品页迟迟不收录,二话不说就去砍内链、调sitemap优先级、甚至上日志分析工具死盯爬虫,折腾了整整一个月毫无起色。后来扒服务器日志才发现,爬虫来得勤快得很、页面也早就被抓了,只是全被丢进了Zeppelin——因为整个站是三个月前才新建的,站点级权重根本还没立起来。这种情况下真正该做的,是去攒几条像样的高质量外链、把几个核心品类页做深做透,而不是在抓取这个根本没毛病的环节上空耗时间和预算。方向一旦错了,你越勤奋,离正确答案反而越远——先花一天把诊断做对,往往胜过闷头优化一整个月。
为什么HCU一砸,很多站一整年都翻不了身?
理解了分层,你才能真正看懂HCU(Helpful Content Update,有用内容更新)这类站点级打击的恐怖之处。
过去大家以为算法更新是“一篇篇文章判罚”——这篇没用降这篇的权。但从分层视角看,HCU的本质是站点级的层级重新分配。它不是把你某几篇文章往下挪,而是把你整个站的“起始座位”整体下调一档甚至几档。原本默认进Base的页面,现在默认进Zeppelin;原本在Zeppelin的,直接掉进Landfill。一夜之间,全站所有页面的起跑线集体后移。这就是为什么很多被HCU命中的站,流量不是跌20%、30%,而是断崖式地跌70% 以上——因为这是系统性的整体降层,不是零敲碎打的扣分。
更让人绝望的是翻盘周期。行业里有人长期追踪过近400个被HCU打击的站,数据触目惊心:被打击一年后,只有大约22% 的站出现了20% 以上的流量回升,而完全恢复的,被形容为“异常值”级别的稀有。将近两年过去,大部分站再也没回来。站点级降层一旦发生,翻盘成本是以“年”为单位计的。对一个靠自然流量养现金流的独立站来说,这几乎等同于宣判生意停摆。
还有一个特别讽刺的发现:那些少数恢复了的站,相当一部分根本没做什么惊天动地的改造,有的只是降低了发文频率,有的只是减少了广告密度,然后就在某次核心更新里被算法重新上调了。这说明恢复很大程度上来自谷歌算法侧的重新评估,而不是站长那些焦头烂额的“抢救动作”。这个真相有点反鸡汤,但必须讲清楚:很多时候你能做的,是停止伤害、耐心等待重估,而不是病急乱投医地继续往一个已经被判低层的站里猛灌内容——那只会让算法更确信你是个内容工厂。关于站点声誉这类整体性信号是怎么被谷歌的垃圾政策盯上的,站内这篇站点声誉滥用与寄生SEO的三方防御可以对照着看,它讲的就是“整个站被打标签”是怎么回事。
怎么判断自己的页面到底卡在哪一层?
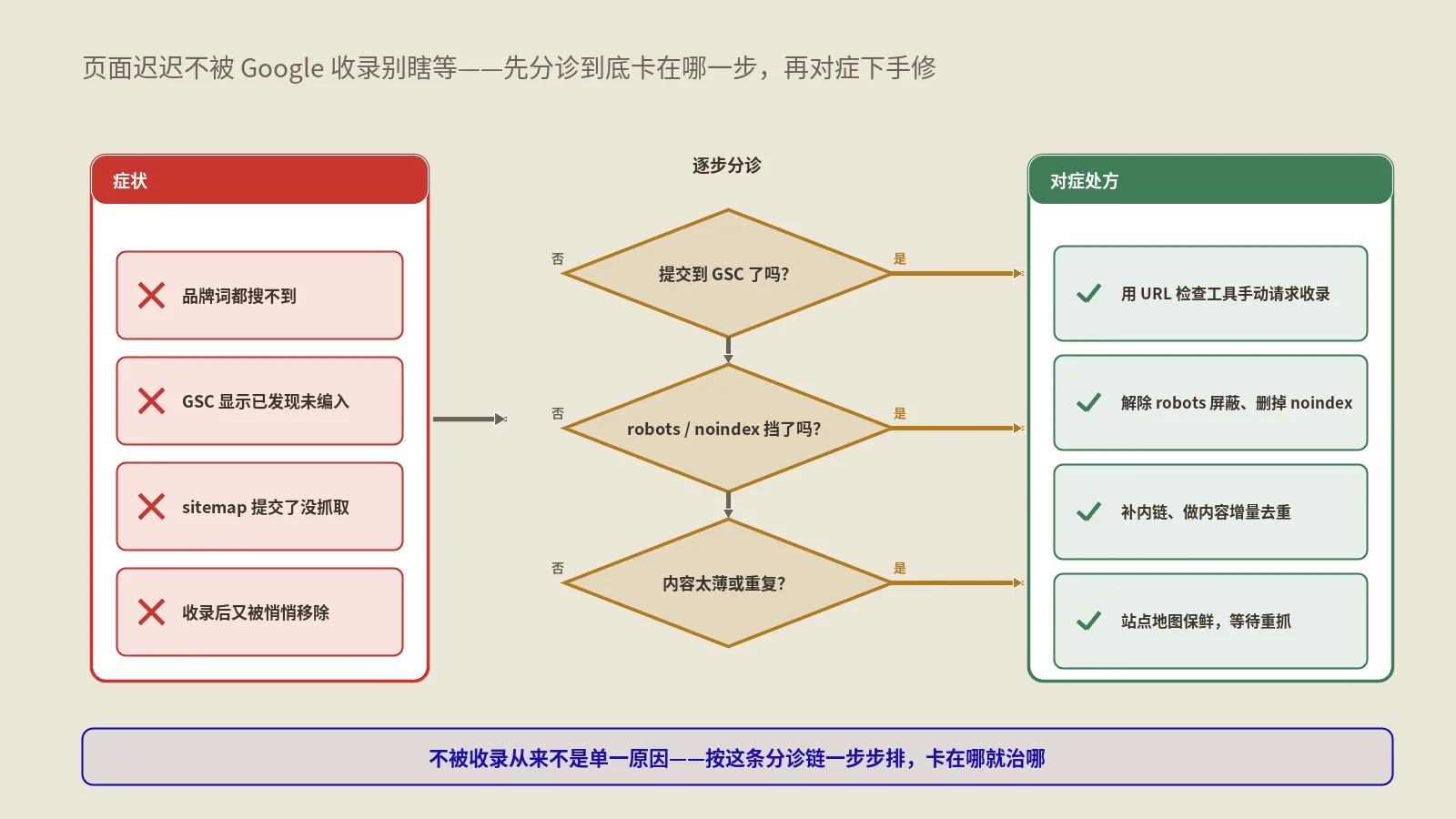
讲了这么多机制,最实际的问题来了:我怎么知道自己某个页面现在到底躺在哪层货架上?谷歌不会给你发通知,但有一套间接的体征可以让你八九不离十地推断出来。这部分是源头那些只讲理论的文章普遍缺的,这里给你一套能直接上手的自查动作。
第一步,看收录与排名的错位。拿页面的精确标题或一整句话,加引号丢进谷歌搜。如果连这种完全唯一、几乎没竞争的查询都搜不到你,那这页大概率躺在Landfill,连出场资格都没拿到。如果精确查询能搜到、但稍微泛一点的关键词就消失,那它八成在Zeppelin——被收录在册,但只在“结果不够用”时才被捞出来。
第二步,查GSC的状态分布。把“已抓取 — 尚未编入索引”和“已编入索引但零展示”的页面单独拉一张表。前者是连主索引都没进的填埋场候选,后者是典型的低层囚徒。这两类页面占比越高,说明你的站点级层级越可能整体偏低。这张表建议每个月拉一次,变化趋势比某一天的快照更能说明问题。
第三步,盯展示量而非排名。排名会骗人(个性化、地域化让它忽上忽下),但GSC的“展示次数”很诚实。一个页面如果长期展示量趋近于零,说明它根本没被放进用户查询会翻到的那层。展示量是分层最直接的体温计,比任何第三方工具的“预估排名”都靠谱。
第四步,做站点级横向对比。把你站里表现最好的几个页面和最差的几个页面放一起看,如果差距小、整体都不行,那问题大概率在站点级层级(整个站被压低了);如果是个别页面拉胯、其他都正常,那才更可能是单页质量问题。这个区分决定了你接下来该“治站”还是“治页”,方向错了全盘皆输。
把这四步走一遍,你心里就有谱了:到底是某几篇文章需要回炉,还是整个站的地基需要重打。别再笼统地说“我排名不好”,要能说出“我大概率是站点级被压在了Zeppelin”——诊断精确到这个颗粒度,药才下得准。
掉进Landfill之后,到底还有没有救?
先说结论:有救,但成本极高,而且越往后拖越贵。低层不是死刑,但它是个深坑,爬出来要费的劲,远大于当初不掉进去要费的劲。
救援的核心逻辑只有一条:停止单页层面的小修小补,转向站点级权重的系统性重建。因为决定你层级的是站点级信号,你逐篇改title、加关键词,对整体层级几乎是杯水车薪。具体该往哪几个方向使劲:
- 先止血,再生长。把站里那些单薄、重复、纯凑数的页面找出来,该删的删、该合并的合并。一堆填埋场页面挂在站上,会拖累整个站的平均成色,等于一直在给谷歌递“我这站质量一般”的信号。砍掉它们,是给站点级信号松绑的第一步。很多独立站为了“看起来内容丰富”铺了几百个空洞的产品页,恰恰是这堆东西在拉低全站层级。
- 把有限的弹药集中到少数页面上。与其发50篇平庸内容,不如把这50篇的功夫砸进5篇真正有深度、有第一手经验、别人替代不了的文章。让这几篇先冲进Base层,用它们带动站点级评估回升。
- 去赚高层页面的链接。记住链接权重跟着层级走,所以你要的不是“多”,是“来自Base层页面的链接”。一条来自真正权威站正文里的链接,顶得过一百条填埋场资源页的链接。宁可花三个月磨一条真链接,也别一周买一百条垃圾链接。
- 把发布节奏降下来。前面说过,部分恢复的站恰恰是降低了发文频率。在一个被压低的站上疯狂堆量,只会让算法更确信你是个内容工厂。慢下来,把每一篇都做成精品,反而是更快的路。
保哥得说句实在话:翻盘这事,七分靠把地基重新夯实,三分靠耐心等谷歌的下一次重估。它不是一周两周的事,做好打持久战的心理准备。但反过来想,正因为爬出来这么难,那些已经稳稳待在Base层的站,护城河也就这么宽——这也是为什么把站点级质量当成长期资产来经营,回报会这么可观。你今天多受的这份累,本质上是在给竞品砌一道他们短期内翻不过来的墙。
还有一个被很多人忽略的点:层级的重新评估不是实时的。你今天把低质页面清理干净、补上几篇精品,谷歌不会明天就给你升层。它需要重新抓取、重新累积用户信号、再赶上一次合适的更新窗口,这个周期短则数周、长则数月。所以千万别上周改完、这周就天天盯着排名刷新,那只会让你焦虑到做出更多自乱阵脚的动作。给自己定一个季度级的观察周期,把时间留给算法重新认识你——这种沉得住气的耐心,本身就是低层翻盘最稀缺的能力。
新站新页面,怎么避免一上来就被丢进填埋场?
治病不如防病。如果你正在做一个新的出海独立站,或者准备给老站上一批新内容,下面这套“别让自己起步就掉坑”的打法,比事后救援划算一万倍。
第一,发布前先做SERP侦察,别盲目增产。动笔之前,先去搜你要做的那个关键词,看清楚现在排在前面的是什么成色的内容、什么量级的站。如果头部全是权威大站的深度长文,而你是个新站还想用一篇泛泛而谈的文章去挤,那它大概率一落地就进低层。要么换更长尾、竞争更小的切入点,要么把内容做到能跟头部掰手腕的深度。先看清战场,再决定打不打、怎么打。
第二,先建站点权重,再上内容产量。新站最忌讳的就是上线第一周哐哐发100篇。站点级信号还是一张白纸,这100篇大概率集体进Landfill,而且一堆低质页面会反过来把你这张白纸直接染成“内容工厂”的底色。正确的顺序是:先用少而精的几篇打底,去赚几条像样的链接,让站点级权重有个基本盘,再逐步、稳定地放量。地基没打好就盖楼,盖得越快塌得越惨。
第三,每一篇新内容都要有“别人给不了”的东西。分层系统在筛的,本质就是“你这篇值不值得占Base层的坑”。能让你脱颖而出的,永远是第一手经验、真实数据、独到判断这些AI和同行抄不走的东西。保哥之前帮一个做出海家居SaaS工具的团队起步,就坚持让他们每篇都绑定自家产品的真实使用数据和客户踩坑案例,量虽然上得慢,但十几篇里有大半直接进了Base层、稳定带量。慢就是快,在分层这件事上体现得淋漓尽致。
第四,搭好内部链接,让权重在站内流动。新页面靠老页面的内链“引荐”,能更快获得初始层级的认可。把你站里已经在Base层的强页面,用合理的内链指向新页面,相当于老员工带新人,比让新页面孤零零地自生自灭强得多。
这几条说到底就一句话:分层系统奖励的是“克制的高质量”,惩罚的是“无节制的平庸量产”。想清楚这点,你对内容节奏的判断就会和大多数还在拼命堆量的同行拉开差距。这也是谷歌这次泄露给所有SEO从业者最大的一课——别再问“我怎么骗过算法”,要问“我怎么真的值得被放进第一层”。把这个问题想透了,你做的每一个动作,方向都不会错得太离谱。说到底,分层索引这套机制不是用来吓唬人的,它反而给你指了条明路:与其在算法的表面动作上疲于奔命,不如老老实实把站点级的质量地基夯结实——这是唯一一条无论谷歌怎么折腾算法都不会过时的路,也是出海独立站真正的护城河所在。
常见问题解答
“已编入索引”是不是就代表我能参与排名了?不一定。编入索引只说明谷歌给你建了条目,但条目可能在Zeppelin甚至Landfill层。这两层的页面要么只在结果不够时才被捞出来、要么在排名流程开始前就被取消资格。收录只是入场券,进哪层货架,才决定你上不上得了场。
Base、Zeppelin、Landfill这三个名字是真的还是SEO圈编的?是真的。它们来自2024年泄露的谷歌Content Warehouse API文档,由SegIndexer系统和scaledSelectionTierRank等属性确认;更早还有2004年的分区专利US7293016B1佐证分层逻辑。两条证据链互相印证,不是民间臆测。
我外链买了一大堆,为什么DR和排名都不动?很可能因为那些外链来自躺在Landfill层的低质页面。链接权重跟着层级走,填埋场页面投出的票谷歌基本不记。与其追求数量,不如想办法拿到来自Base层权威页面正文里的链接,一条顶一百条。
我的页面收录了却零排名,是不是该去优化抓取预算?大概率不是。零排名通常是分层(服务层)问题,不是抓取层问题。抓取预算优化只对几百万页的超大站才有意义,中小站把排名问题甩锅给抓取预算,是最常见的误诊。该做的是站点级质量,而不是擦那扇没漏水的窗。
被HCU打击后,多久能恢复?做好以年为单位的心理准备。有追踪数据显示,被打击一年后仅约22% 的站出现20% 以上回升,完全恢复属于罕见。而且恢复往往来自谷歌的算法重估,而非站长的抢救动作。停止伤害、夯实地基、耐心等待,比病急乱投医更有效。
怎么判断我是站点级被降层,还是单个页面质量差?做横向对比。如果全站页面普遍表现差、差距不大,问题大概率在站点级层级;如果只是个别页面拉胯、其余正常,才更可能是单页质量问题。这个区分决定你该治站还是治页,方向错了会白费力气。
新站应该一上线就大量发文抢收录吗?千万别。新站站点级信号还是白纸,海量发文大概率集体进低层,还会把你染上内容工厂的底色。正确顺序是先用少而精的内容打底、赚几条像样的链接建立基本权重,再稳步放量。慢就是快。
权威参考资料
本文标题:《Google分层索引揭秘:你的页面被丢进Base、Zeppelin还是Landfill?》
本文链接:https://zhangwenbao.com/google-index-tiers-base-zeppelin-landfill.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0