向量分数0.89就代表内容对齐了?别把精确当成准确

本文目录
- 我们从关键词匹配走到向量对齐,到底进步了什么?
- 0.89的余弦相似度,到底在说一件什么事?
- 为什么说"更精确"不等于"更准确"?
- Netflix那篇论文,给余弦相似度泼了盆什么冷水?
- 换一个嵌入模型,同一篇内容的分数为什么就变了?
- Google、OpenAI、Perplexity真按你算的余弦分数排你吗?
- 这其实是Goodhart定律又演了一遍
- 那向量分数就一无是处吗?一个"客户流失"的例子
- 除了"虚高",分数还会"虚低"——模型读不懂你的时候怎么办?
- 分数该当指南针,还是当判决书?
- 出海多引擎下,单一模型的分数为什么更靠不住?
- 这跟我之前讲的那些余弦相似度工具矛盾吗?
- 一张"别为分数优化"的内容团队自检表
- 三个真实场景:分数用对了和用砸了
- 常见问题解答
- 权威参考资料
摘要:这两年做内容,多了一件以前做不到的事——你可以给"这篇内容到底对不对得上用户想搜的东西"打一个精确的分数了。用嵌入模型把内容和查询都变成向量,算个余弦相似度,0.89,看着比过去抠关键词密度专业多了。可越是漂亮的小数点,越容易让人栽跟头。这个分数的真相是:它只是在某一个模型自己理解语言的空间里,量出来的一个方向,不是Google、不是ChatGPT、更不是用户真实判断相关性的口径。Netflix在WWW 2024发的一篇论文已经证明,余弦相似度在某些情况下能给出近乎任意、毫无意义的结果;MTEB榜单也摆明了换个模型分数就翻盘。这篇文章不劝你别用向量工具,恰恰相反——我自己也天天用——它要讲清楚的是另一件事:怎么把这个分数当成指南针来用,而不是当成判决书,怎么躲开把分数本身当成目标之后必然踩中的Goodhart陷阱。
先说个让人有点不舒服的场景。你手里有篇关于"如何防止客户流失"的文章,关键词全都覆盖到了,密度、布局、内链都挑不出毛病。可你跑了一遍向量对齐分析,发现它在语义上其实更偏向"如何衡量客户流失",而不是"如何防止"。这两件事差得远——一个讲怎么诊断,一个讲怎么动手干预。关键词工具一辈子都发现不了这种漂移,向量工具一下就照出来了。
这是向量对齐真正厉害的地方,我不否认。可同样是这套工具,跑出来一个"0.89"的相似度,很多人会立刻把它读成"对齐做得很好,可以发了"。问题就出在这一步——从"工具照出了一个方向"到"我拿到了一个真相",中间那道坎,绝大多数人没看见就跨过去了。
有位在搜索行业摸爬了二十多年的老兵Duane Forrester最近把这件事点破得很狠:内容对齐终于能测量了,而这恰恰是最危险的部分。保哥读完很有共鸣,因为这些年带团队跑这套分数时,反复见过同一种翻车。今天就把这件事掰开揉碎讲一遍,讲给天天和余弦相似度、嵌入模型打交道的SEO和出海的朋友。
我们从关键词匹配走到向量对齐,到底进步了什么?
得先承认进步是实打实的。早些年判断一篇内容相不相关,靠的是词面重叠——你搜"客户流失",页面里得出现"客户流失"这几个字,出现得越多、位置越靠前,就被认为越相关。TF-IDF把这套思路做到了极致,给每个词算个权重,衡量它在这篇里有多重要、在全网里有多稀缺。这套方法管用了很多年,但它有个死穴:它只认字,不认意思。
"防止客户流失"和"客户留存策略",词面上几乎不重叠,意思却高度一致;"苹果手机"和"苹果产地",词面上都有"苹果",意思却风马牛不相及。纯靠词面匹配,前者会被判成不相关,后者会被判成相关,全反了。
向量对齐就是来补这个洞的。它用嵌入模型把每段文字映射成一串数字——一个高维空间里的坐标。意思相近的文字,坐标也相近;意思无关的,坐标就离得远。然后用余弦相似度量两个向量之间的夹角,夹角越小、值越接近1,就认为语义越贴。这一下,机器终于能"读懂"意思了,而不只是数词。
这套思路其实不新。早在上世纪60年代,Cornell的Gerard Salton就在他的SMART检索系统里搭起了向量空间模型的雏形,把文档和查询都当成向量来比。变的是这些年嵌入模型的能力——从早期的词袋、word2vec,到现在动辄上千维、由大模型骨架训练出来的嵌入,捕捉语义的精细度完全不是一个量级。所以今天你能在工具里看到一篇内容对某个查询的对齐分数,精确到小数点后两位。这是真进步。
可进步带来一个副作用:它太像"真相"了。关键词时代,没人会把"关键词密度2.3%"当成内容好坏的铁证,大家心里有数那是个粗糙的代理。到了向量时代,一个"0.89"的余弦值,反而被很多人当成了盖棺定论。精度上去了,对它的怀疑却下来了——这才是危险开始的地方。
0.89的余弦相似度,到底在说一件什么事?
我们把这个分数拆开看。当工具告诉你某篇内容对某个查询的余弦相似度是0.89,它真正在说的是:在这一个特定嵌入模型对语言的理解方式里,这两段文字的向量方向很接近。
请注意这句话里每一个限定词,它们都是有分量的。
- "在这一个特定嵌入模型里":换一个模型,同样两段文字可能算出0.71,也可能算出0.93。每个嵌入模型都是用不同的数据、不同的目标训练出来的,它们各自构建了一套自己的语义空间。0.89是这个空间里的坐标,不是宇宙真理。
- "向量方向很接近":余弦相似度量的是夹角,是方向上的接近,不直接等于"语义上完全一致",更不等于"这篇内容能解决用户的问题"。方向对,落点未必对。
- "两段文字":它比的是你喂进去的那两段文本之间的关系,不是你的内容和"真实搜索系统眼里的相关性"之间的关系。后者要复杂得多。
说白了,0.89是一个方向性的信号,告诉你"大致八九不离十",而不是一份"已对齐,准予放行"的判决书。它是模型内部的一次测量,带着这个模型全部的偏见和局限。你把它当参考,它很有用;你把它当事实,它就开始骗你。
为什么说"更精确"不等于"更准确"?
这是整件事的核心,也是最反直觉的一点。精确和准确,是两码事。
精确,说的是你给出的数字有多细、多稳定——小数点后能报到两位、每次跑都一样,这叫精确。准确,说的是这个数字离真相有多近。一把尺子可以每次都精确地量出"3.47厘米",但如果它本身刻度是歪的,那它再精确,量出来的也是错的。
向量对齐分数的麻烦正在于此:它非常精确,精确到能给你报小数点后好几位,但它的准确性——也就是它有多贴合真实搜索系统的判断——是个大问号。而人脑有个根深蒂固的毛病:看见小数点,就自动信任。一个写着"对齐度89.3%"的进度条,比一句"这篇大概还行"要可信得多,哪怕后者可能更接近真相。
这就是Forrester说的那个"危险的部分"。危险不在于分数错——它可能方向是对的——而在于它的精确外表,骗过了你本该保留的那份怀疑。你停止了追问"这个分数到底测的是什么、测得准不准",直接拿它当结论往下走。一个被小数点掩盖掉的错误,是最难被发现的,因为它根本没让你起疑。
Netflix那篇论文,给余弦相似度泼了盆什么冷水?
这不是我危言耸听。2024年的ACM Web Conference上,Netflix的Harald Steck、Chaitanya Ekanadham和来自Netflix与Cornell的Nathan Kallus,发了一篇标题就很扎心的论文——《余弦相似度量的真是相似度吗?》。
他们的结论,简单说就是:在某些情况下,嵌入向量的余弦相似度会给出近乎任意、因而毫无意义的结果。这不是说余弦相似度总是错,而是说它的可靠性,远没有大家默认的那么稳。论文从数学上分析了一类常见的线性模型,发现有些模型算出来的余弦相似度甚至不唯一——同一份数据,因为训练时正则化方式的不同,相似度会被隐式地拉成完全不同的值。换句话说,分数高低,有时候反映的不是语义,而是模型训练时的一些技术选择。
他们还指出,余弦相似度在实践中有时候比直接用未归一化的点积效果更好,但有时候反而更差,没有一个放之四海皆准的保证。
我第一次读到这篇时挺受触动的。一群顶级推荐系统团队的研究者,他们靠余弦相似度吃饭,却专门写文章提醒大家别太信它。这恰恰说明,越是天天用这个工具的人,越清楚它的边界在哪。反倒是把它当新玩具的人,最容易过度信任。这篇论文我放在文末的参考里,做SEO但有点技术底子的朋友值得读一遍原文。
换一个嵌入模型,同一篇内容的分数为什么就变了?
如果说Netflix那篇是从数学上拆台,那MTEB榜单就是从实践上摊牌。
MTEB全称大规模文本嵌入基准,是个专门测各种嵌入模型能力的排行榜,覆盖8大类任务、上百个数据集、112种语言。它最有价值的发现不是"谁是第一",而是一个让人清醒的事实:没有任何一个模型能在所有任务上都最强。一个在检索任务上称王的模型,换到聚类任务上可能就拉胯;在语义相似度上拔尖的,未必能把重排任务做好。
这意味着什么?意味着你算出来的那个对齐分数,强烈依赖于你用了哪个嵌入模型。同一篇内容、同一个查询,用模型A可能是0.88,用模型B可能就掉到0.79。哪个才是"真的"?都不是,也都是——它们各自是各自空间里的真,但没有一个是用户真实感受里的真。
我见过有团队为了把对齐分数从0.85刷到0.90,反复改写一篇本来读着很顺的文章,改到最后人话都不像了。后来换了个嵌入模型一测,发现原来那版分数反而更高。那一刻就很魔幻——他们花了大半天,优化的不是内容质量,而是去迎合某一个模型的口味。这就引出了下一个问题:真正给你排名的那些系统,到底用不用你算的这个分数。
Google、OpenAI、Perplexity真按你算的余弦分数排你吗?
答案是:基本不会,至少不会以你想的那种方式。
Google官方那份《深入了解Google搜索的工作原理》里说得很清楚,相关性是由数百个因素共同决定的——内容本身、用户的位置、语言、设备,以及一大套排名系统层层叠加的结果。它当然用到了语义理解的技术,但绝不是简单地"算个余弦相似度然后排序"。中间还有召回、粗排、精排、重排好几道工序,每一道都在叠加新的信号。你在自己工具里算的那个孤立的余弦值,跟这条复杂流水线的最终输出,根本不是一个东西。
AI搜索这边也一样。ChatGPT、Perplexity这些系统在决定引用谁的时候,背后是它自己的检索管线、自己的重排逻辑、自己的一套判断,而且各家都不一样、都不公开。你用某个开源嵌入模型算出来的对齐分数,跟Perplexity实际怎么挑内容,中间隔着十万八千里。
所以这里有个特别要命的认知错位:你以为你在测"我的内容跟用户需求对不对得上",其实你测的是"我的内容跟我的查询,在我选的这个模型眼里,方向接不接近"。这中间套了三层代理,每一层都在和真相之间拉开距离。把最后这个数字当成第一件事的答案,逻辑上就是错位的。
这其实是Goodhart定律又演了一遍
讲到这儿,绕不开一条老规律——Goodhart定律:当一个度量变成了目标,它就不再是一个好的度量。
这条定律在SEO圈里其实大家早就吃过亏。当年关键词密度被当成目标,于是有了关键词堆砌;当外链数量被当成目标,于是有了链接农场;当停留时间被当成目标,于是有了把文章拆成十几页强迫你翻页的烂招。每一次,都是同一个剧本:一个本来还算有用的代理指标,一旦被当成要冲的KPI,就立刻被人玩坏,最后既伤了用户,也没换来真排名。
向量对齐分数,正站在重演这个剧本的门口。一旦团队的目标变成"把对齐分数刷到0.9以上",而不是"把这篇内容写得真能解决用户的问题",那这个分数立刻就废了。人们会开始为了讨好某个嵌入模型而塞词、改句、调结构,产出一堆分数漂亮但读着别扭的东西。模型被骗过去了,用户却被赶跑了。
更隐蔽的是,这一次的诱惑比以往都大,因为这个指标看起来太科学了。关键词密度好歹大家心里有数那是个糙活,向量余弦相似度披着数学和AI的外衣,让人很难对它保持警惕。越是看着权威的指标,越容易让人忘了它也只是个代理。这一点,我在讲GEO内容评分器怎么用、它的边界在哪那篇里也专门提醒过:分数是用来发现问题的,不是用来当成绩单的。
那向量分数就一无是处吗?一个"客户流失"的例子
当然不是。我前面就说过,我自己天天在用。关键是用在它真正擅长的地方。
回到开头那个客户流失的例子。你写了篇《如何防止客户流失》,标题、关键词都对准了"防止"。但向量分析告诉你,这篇内容在语义上其实更靠近"衡量客户流失"——因为你全篇都在讲怎么算流失率、怎么做留存分析、怎么看队列数据,唯独"具体该做哪些动作去留住人"讲得很薄。
这就是向量工具最值钱的用法:它能照出语义漂移。你以为你在写A,实际写出来的是A的近亲B。这种偏差,关键词工具完全看不见——因为"客户流失""留存""流失率"这些词,A和B里都有。只有在语义空间里,才能看出这篇文章的重心整体偏了。
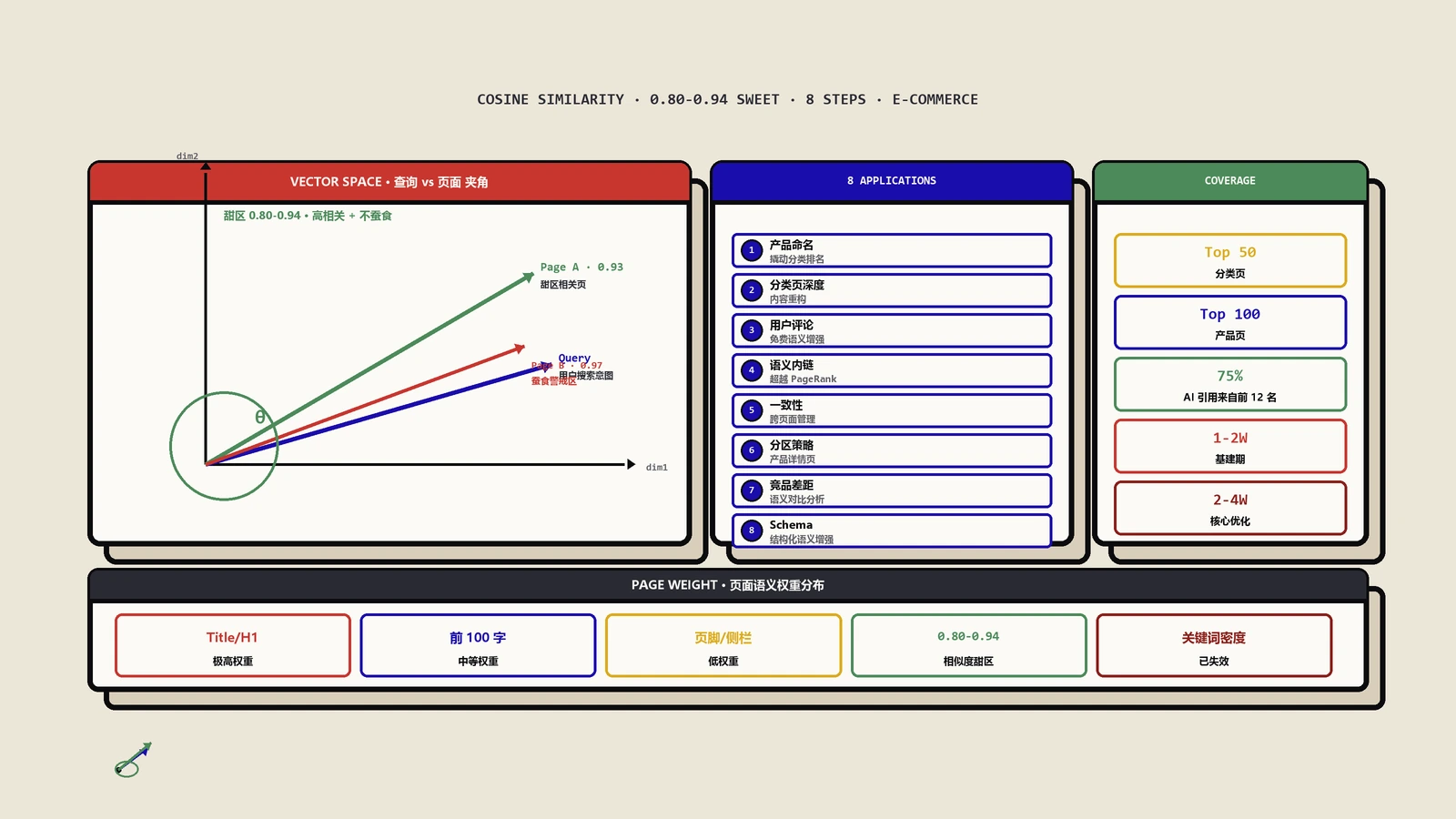
注意这里的用法逻辑:向量分数在这里是个诊断信号,它指给你看"重心好像偏了,去查一下",而不是给你下结论"对齐度74%,不合格"。前者引发的是人的思考和复查,后者引发的是机械的刷分。同一个工具,用法不同,一个帮你,一个害你。我在电商场景用余弦相似度压商品蚕食那篇里拆过一整套实战应用,那些用法之所以成立,前提全都是"拿分数当线索去查",而不是"拿分数当终点去冲"。
除了"虚高",分数还会"虚低"——模型读不懂你的时候怎么办?
前面讲的都是"分数虚高骗了你",但还有一种反向的坑,更隐蔽,也更伤人:分数虚低。
什么意思?当你的内容里有大量专业术语、行业黑话、新概念,或者一个市场上刚冒出来的新品牌词,嵌入模型很可能"读不太懂"——因为它训练时压根没怎么见过这些语料。结果就是,一篇专业深度极高、对真正的目标用户极其对路的内容,被模型判了个低分。你要是照着这个低分去"改进",大概率会把内容往大白话、往泛泛而谈上掰,反而把它最值钱的专业壁垒给削平了。
这种事在两类内容上特别容易发生。一类是高度垂直的B2B专业内容,比如跨境合规、工业参数、医疗器械,模型对小众语料吃得不透;另一类是走在行业前沿的新概念内容,你在讲一个市场刚开始讨论的东西,模型的语义空间还没来得及把它纳进去。这两类,恰恰是最有信息增益、最该被看重的内容,却最容易被向量分数低估。
所以遇到分数低,第一反应别是"赶紧改",而该是先分两种情况判断:到底是内容真的跑题了,还是模型读不懂这块领域?判断方法也不玄乎——找一个真正懂这个领域的人来读,或者看看真实的目标用户、真实的咨询转化怎么反馈。如果专家说这内容很对路、客户也认,那低分就是模型的问题,不是内容的问题,放心把它发出去。把这一步交给人,是因为模型在它的知识盲区里给的分,没有参考价值,硬信反而会让你亲手毁掉好东西。
分数该当指南针,还是当判决书?
把上面的道理收拢成一句可操作的话:向量对齐分数是指南针,不是判决书。指南针告诉你大概朝哪个方向走,路还得你自己看着走;判决书是直接定罪,没有商量余地。把这个分数当指南针,你就活了;当判决书,你就被它绑架了。
具体怎么做,我自己总结了几条:
- 看趋势,别抠绝对值:同一个模型下,改写前0.74、改写后0.86,这个"涨了"是有意义的,说明你的调整方向对。但0.86这个绝对值本身,别赋予它太多含义,更别拿它跟别人用别的模型算的数字比。
- 多个信号三角验证:别让向量分数单独说话。把它和真实的搜索表现、用户行为、实际被AI引用的情况放一起看。分数高但没人点、没人引,那分数就是假的。多个口径互相印证,才靠得住。
- 分数和判断冲突时,信判断:如果一篇内容你读着觉得真好、真能解决问题,但分数不高,先别急着改它去迁就分数。很可能是模型的口味问题。反过来,分数很高但你读着觉得空,那就相信你的眼睛。
- 永远问一句"这分数是哪个模型给的":换工具、换模型前后的数字不可直接比较。心里始终装着"这只是某个空间里的测量"这根弦。
这套思路,本质上跟我一直强调的"技术指标服务于判断,而不是替代判断"是一脉相承的。技术SEO里也有同样的坑——很多人把各种工具的满分当成终点,结果分数全绿了排名还是不动,问题其实出在搜索意图根本没对齐这种工具量不出来的地方。分数解决的是"看得见的部分",真正决定生死的,常常是分数照不到的那块。
出海多引擎下,单一模型的分数为什么更靠不住?
对做出海、要同时讨好多个AI引擎的朋友,这件事还要再加一层麻烦。
前面说了,每个嵌入模型有自己的语义空间。而你现在面对的不是一个搜索引擎,是Google、Bing、ChatGPT、Perplexity、Gemini一大串,每一个背后的检索和理解机制都不一样。你拿某一个开源嵌入模型算出来的对齐分数,连贴合一个引擎都未必准,更别说同时代表这一整排引擎了。
更要命的是多语言。同一篇内容翻成英文、西班牙文、阿拉伯文,在嵌入空间里的表现可能差异很大——很多嵌入模型在英文上训练得最足,到了小语种语义捕捉就明显变糙。你用一个偏英文的模型去测西语内容的对齐,那个分数的可信度还要再打个折。
所以出海场景下,我的建议反而更保守:把向量分数的权重调低,把真实的跨引擎表现调高。一篇内容到底有没有对齐,最终还得看它在不同引擎、不同语言市场里,到底有没有被引用、有没有带来真实的人。关于同一份内容换个引擎就没人引用的问题,我在用TF-IDF分析器给内容做关键词权重体检那篇里也聊过,无论是老派的TF-IDF还是新派的向量,思路都一样:工具给线索,引擎给答案,人给判断。
这跟我之前讲的那些余弦相似度工具矛盾吗?
读到这儿,熟悉我的朋友可能会犯嘀咕:你之前明明写过好几篇教大家用余弦相似度、用向量、用各种评分器的文章,现在又来泼冷水,这不前后打架吗?
不打架,反而是配套的。这就像驾校先教你怎么开车,再单独拿一节课讲怎么不出事故——后者不是否定前者,是给前者加一道安全护栏。
那些讲怎么用的文章,解决的是"工具怎么操作、能干哪些活"的问题,那是基本功,得会。这篇解决的是另一个层面的问题:"会用了之后,怎么不被工具反过来牵着鼻子走。"前者教你拿起锤子,后者提醒你别把所有问题都看成钉子。一个偏应用,一个偏认知,两边都需要,缺哪边都容易出岔子。
说到底,所有这些向量工具、评分器、相似度算法,都是放大你判断力的杠杆,不是替代你判断力的开关。它们能帮你看到肉眼看不见的语义漂移,能帮你在一堆内容里快速定位哪篇可能有问题,这些都是真本事。但"这篇到底好不好、该不该这么写、能不能解决用户的真问题",这个最终的判断,得你自己下。工具越强,越要守住这条线,否则就会出现一种很荒诞的局面:你买了越来越精密的仪器,却把自己越用越蠢。
一张"别为分数优化"的内容团队自检表
把这篇的东西落成几条能贴在工位上的提醒,给团队用:
- 有没有把分数写进KPI?一旦"把对齐分数刷到X以上"成了考核项,Goodhart陷阱基本就锁定了。考核内容质量和真实效果,别考核某个中间指标。
- 改写之后,是内容更好了,还是只是分数更高了?每次为了提分而改稿,回头读一遍:人话还在不在?读者读着是更顺了还是更别扭了?分数涨、可读性跌,这种改写就是亏的。
- 这个分数,跟真实表现对得上吗?定期把高分内容和它真实的点击、停留、被引用情况放一起核对。如果一堆高分内容没人理,那这套分数对你这个站就是失灵的,该换口径了。
- 换个模型测过吗?关键内容别只信一个嵌入模型的结果。多跑一两个模型,看分数稳不稳。波动大的,说明这个判断本身就不牢靠,别拿它当铁证。
- 分数和人的直觉打架时,谁说了算?团队里要有共识:最终拍板的是人的判断,分数只是参考。一个有经验的编辑说"这篇不行",哪怕分数0.92,也得认真听。
三个真实场景:分数用对了和用砸了
讲点具体的,三个保哥打过交道的不同类型客户,看同一套向量分数怎么一个用活、一个用死。
第一个是做户外储能的DTC品牌。他们内容团队一度很迷向量评分,给每篇产品教程都卡了个对齐分数门槛,不到0.85不让发。结果几个月下来,文章越写越像,全在反复堆"便携储能电源露营户外应急"这类高对齐词,读着像产品说明书。后来保哥让他们把硬门槛拆了,改成"分数低于0.7的,人去看一眼是不是真跑题了",其余一律以编辑判断为准。文章重新有了人味,真实的搜索停留和咨询转化反而上来了——因为用户要的是"这电源能不能带我露营三天",不是一堆贴着标签的关键词。
第二个是做宠物保健品的DTC客户,他们用得就很聪明。他们不拿分数当门槛,而是拿它当"体检报告"。每个月批量跑一遍内容库,把那些标题和正文语义漂移特别大的文章挑出来——比如标题写"猫咪关节保养",正文却大半在讲产品成分表。挑出来之后,是人去判断要不要重写,怎么重写。分数在这里只负责"报警",决策权全在编辑手里。这套用法,跟我前面讲的"诊断信号"完全吻合,效果也最稳。
第三个是个做财税合规的B2B站,他们的教训在另一头。这类内容专业性极强,一篇讲"跨境电商增值税申报"的深度文,里头大量法规术语、流程细节,用通用嵌入模型一测,对齐分数经常不高——因为模型对这种小众专业语料训练不足,根本"读不太懂"。他们一开始照着低分使劲改,把专业内容往大白话上掰,结果把最值钱的专业深度给改没了。后来想明白了:是模型不行,不是内容不行。这种高专业度的内容,向量分数的参考价值本就有限,得更多靠领域专家和真实客户反馈来判断。这正是前面说的——分数和判断冲突时,信判断。
三个客户,同一套工具,结局天差地别。差别从来不在工具本身,而在于他们把这个分数当成了什么:当成判决书的那个被绑架了,当成指南针和体检报告的那两个,把工具用成了帮手。
常见问题解答
向量对齐分数到底准不准,我还能不能用?
能用,而且该用,但要用对地方。它准的是"语义方向上的大致接近",这件事它做得比关键词工具好得多。它不准的是"这就是真实搜索系统和用户的相关性判断"。把它当线索、当诊断信号、当体检报告,它很有用;把它当最终结论、当KPI去刷,它就开始坑你。一句话:信它的方向,别信它的小数点。
不同工具算出来的对齐分数不一样,该信哪个?
哪个都别单独信。分数不同,是因为它们背后用的嵌入模型不同,各自有各自的语义空间,这是正常现象,不是哪个出了bug。正确做法是看趋势而非绝对值——在同一个工具、同一个模型下,改写前后的变化才有意义。跨工具的绝对分数没有可比性。真要拍板,把分数和真实的点击、引用、转化放一起三角验证。
为什么我把对齐分数刷得很高,排名却没动?
大概率是踩了Goodhart陷阱。Google的排名由数百个因素决定,中间还有召回、粗排、精排、重排好几道工序,你用某个开源模型算的孤立余弦值,跟这条流水线的最终输出不是一回事。你刷高的只是"讨好某个嵌入模型"的程度,不是"真实相关性"。把劲儿从刷分挪回到"内容到底能不能解决用户问题"上,排名才可能动。
Goodhart定律具体怎么避开?
核心就一条:别让任何中间指标变成目标。把考核放在你真正想要的结果上——内容质量、用户满意、真实转化,而不是放在对齐分数、关键词密度这类代理指标上。指标用来发现问题、辅助判断可以,一旦它变成团队要冲的KPI,就一定会被人玩坏。这是几十年屡试不爽的规律,SEO圈已经吃过太多次亏了。
出海做多语言内容,向量分数能信吗?
要打更大的折。大多数嵌入模型在英文语料上训练得最充分,到了小语种语义捕捉明显变糙,你用偏英文的模型去测西语、阿拉伯语内容的对齐,分数可信度本就不高。再加上你要面对的是多个机制各异的AI引擎,单一模型的分数更代表不了全局。出海场景我的建议是把向量分数权重调低,把不同引擎、不同市场的真实引用和转化表现调高。
那以后是不是干脆别看分数,全凭经验判断算了?
也不必走到另一个极端。纯凭经验有经验的盲区,向量工具恰恰能照出一些人眼难察的语义漂移,这是它实打实的价值。理想状态是人机配合:工具负责快速扫描、报警、提供线索,人负责理解、判断、拍板。抛弃工具回到纯手工,和迷信工具放弃判断,是同一枚硬币的两面,都不可取。
权威参考资料
本文标题:《向量分数0.89就代表内容对齐了?别把精确当成准确》
本文链接:https://zhangwenbao.com/content-alignment-vector-score-trap.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0