TF-IDF分析器使用教程:给独立站内容做关键词权重体检
本文目录
- 为什么关键词堆了一堆,搜索引擎还是没抓住重点?
- TF-IDF到底在算什么?三个变量一次说透
- 为什么IDF偏偏要取对数?稀缺性背后的数学直觉
- 拿三篇文档手算一遍,TF-IDF就彻底通了
- 这款TF-IDF分析器和市面上的有什么不一样?
- 手把手:怎么用TF-IDF分析器给一篇内容做关键词体检?
- 三种结果视图,分别在告诉你什么?
- 怎么拿它和竞品页面对比,挖出内容缺口?
- TF-IDF、余弦相似度、实体分析,三款工具怎么串成一条内容优化流水线?
- 从TF-IDF到BM25:现代搜索引擎其实在用什么升级版?
- 怎么把TF-IDF体检变成每月例行动作?
- 用TF-IDF优化内容时,哪些坑会让你越改越糟?
- 常见问题解答
- TF-IDF和关键词密度到底有什么区别?
- 这个工具能直接分析中文内容吗?
- 我应该放多少篇竞品文档才合适?
- TF-IDF高的词,是不是直接多写几遍就行?
- TF-IDF分析器算出来的结果,能预测我的Google排名吗?
- 它和余弦相似度工具配合,具体能解决什么问题?
- 权威参考资料
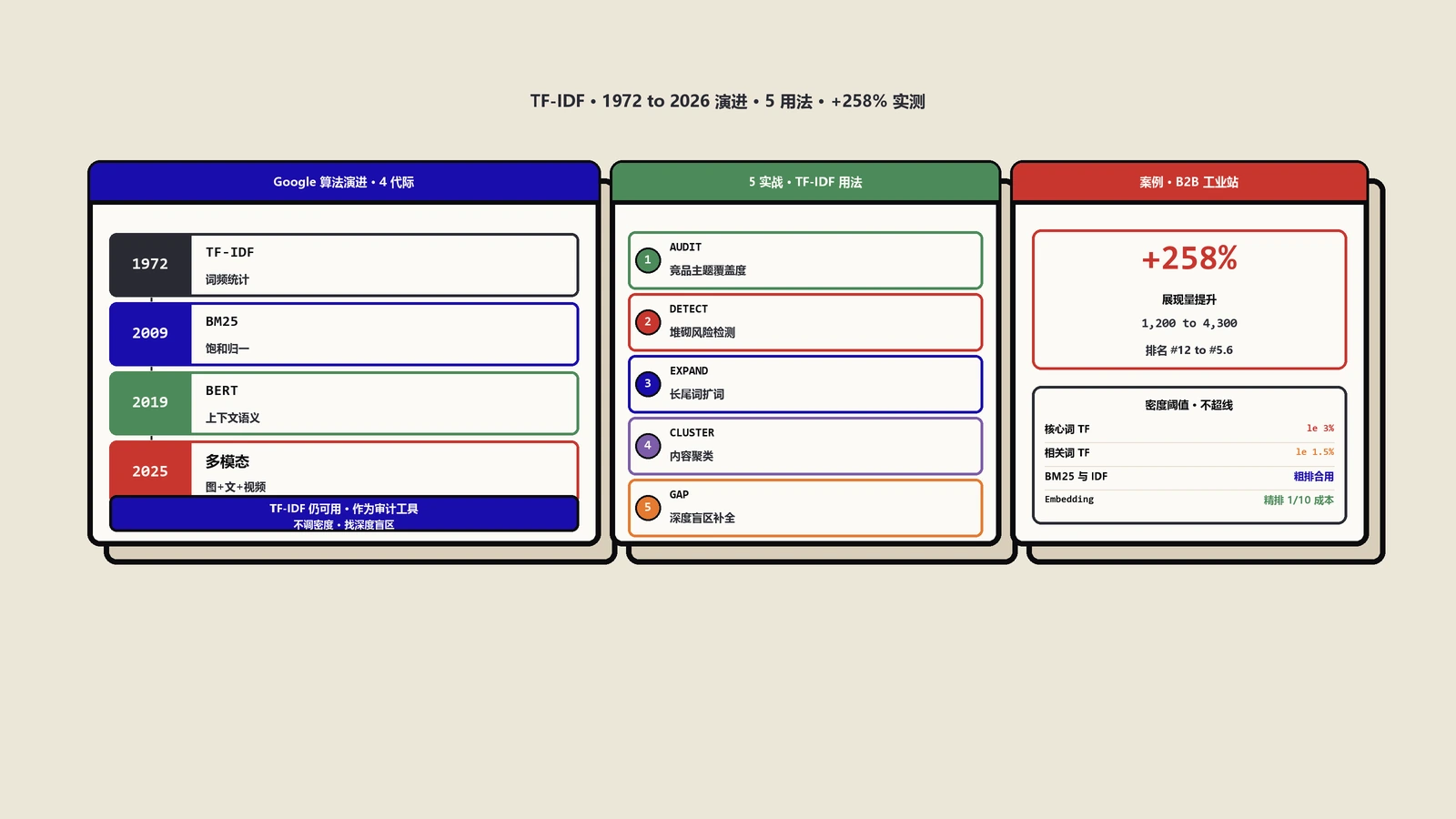
摘要:关键词密度早就过时了,真正决定一篇内容"在强调什么"的是TF-IDF权重——词在你这篇里出现得多(TF高)、在同类文章里却很稀有(IDF高),它才是这篇的主词。保哥这篇用自研的TF-IDF分析器,把词频、文档频率、IDF三个变量逐层拆开算给你看,再手把手教你给独立站内容做一次关键词权重体检,最后把它和余弦相似度、实体分析、可读性评分串成一条内容优化流水线。
先说一个保哥常被外贸朋友问到的场景:一篇产品页明明把目标词写了十几遍,Google排名就是上不去,丢给AI概览(AI Overview)也不被引用。问题往往不在"写得不够多",而在"重点压根没压对"。这篇教程要解决的,就是怎么用一把量尺,客观地看出一篇内容到底在强调什么、又漏掉了竞品都在写的什么。
为什么关键词堆了一堆,搜索引擎还是没抓住重点?
很多人优化内容的习惯,是盯着"关键词密度"那个百分比。词出现得越多,似乎就越相关。这个直觉在2005年也许还管用,今天只会把你带沟里。
道理不难懂。假设你写一篇关于"防水蓝牙音箱"的产品页,"the""and""speaker"这种词出现频率最高,但它们能代表这篇的主题吗?显然不能。高频不等于重要,这是关键词密度这套老办法最致命的盲区。
保哥在关键词密度这篇里掰扯过:纠结密度2% 还是3%,本身就是个伪命题。真正要回答的问题是——在一堆同类文章里,哪个词最能把"你这篇"和"别人那篇"区分开?
这正是信息检索领域50年前就给出的答案:TF-IDF。它不看绝对频率,而看"相对稀缺性"。一个词只有在你这篇里反复出现、在同行那一堆文章里却很少露面,它才配当这篇的主词。下面我们把这套算法一层一层算给你看。
TF-IDF到底在算什么?三个变量一次说透
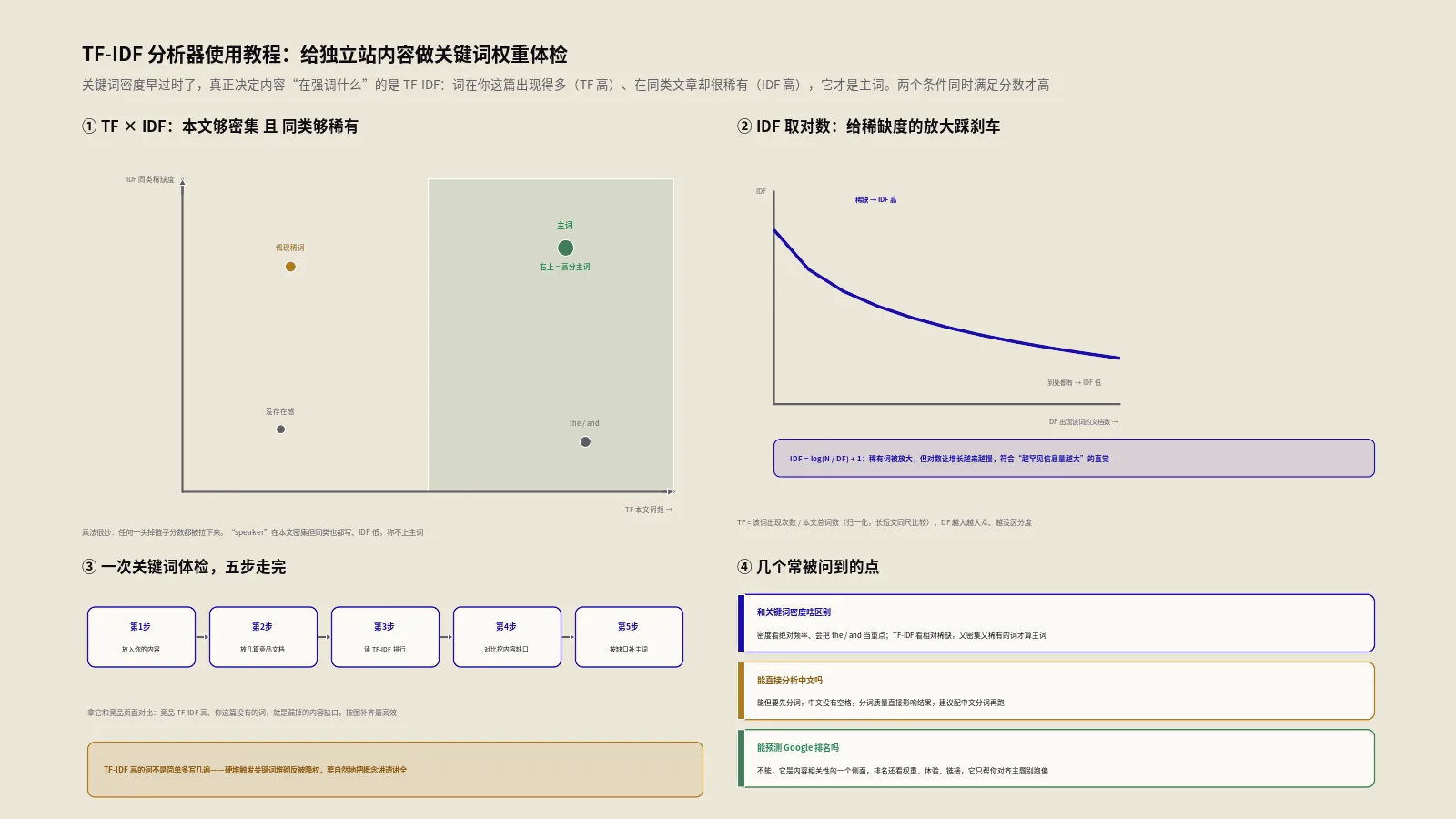
TF-IDF是两个量相乘:TF(词频)乘以IDF(逆文档频率)。听着玄乎,拆开就是小学算术。
第一个量,TF(Term Frequency,词频)。它衡量一个词在"单篇文档内部"的存在感。保哥这款分析器用的是归一化词频,公式很朴素:
TF(词, 文档) = 该词在本文出现次数 ÷ 本文总词数
为什么要除以总词数?因为不归一化的话,长文天生占便宜。一篇3000词的文章里"speaker"出现30次,和一篇300词的文章里出现10次,谁更强调这个词?显然是后者(占比3.3% 对1%)。除以总词数,长短文章才能放在同一把尺子上比。
第二个量,DF(Document Frequency,文档频率)。它统计一个词"在多少篇文档里出现过"。注意,是出现"过"就算一篇,跟它在某篇里出现几次无关。DF越大,说明这个词越大众、越没有区分度。
第三个量,IDF(Inverse Document Frequency,逆文档频率)。它是DF的反向放大,把"稀缺"翻译成一个分数。保哥工具里用的是平滑版本:
IDF(词) = log(N ÷ DF) + 1
这里N是你放进去对比的文档总数,DF是含这个词的文档数。一个词在所有文档里都出现(DF等于N),log(1) 等于0,加上平滑项1,IDF就是最低的1;一个词只在1篇里出现,N÷1取对数后会被显著放大,IDF就高。
最后,两者相乘:
TF-IDF = TF × IDF
这个乘法很妙:一个词必须"在本文够密集"且"在同类够稀有",两个条件同时满足,TF-IDF才高。任何一头掉链子,分数都被拉下来。斯坦福那本经典的信息检索教科书(IR Book)的tf-idf章节把这个性质总结得很准:当一个词"在少数文档里大量出现"时权重最高,"在很多文档里都出现"时权重最低。
为什么IDF偏偏要取对数?稀缺性背后的数学直觉
新手看到log就头大,其实这里的对数有非常朴素的现实意义,值得花两分钟想明白,你之后读结果会顺得多。
设想一下:如果不取对数,IDF直接用N÷DF,会发生什么?在100篇文档里只出现1次的词,权重会是出现2次的词的整整2倍。但从"信息价值"角度,这两个词的稀缺程度其实差不多,都属于"很罕见"那一档。直接相除会把这种微小差异放大到失真。
对数的作用,就是给这种放大"踩刹车"。它让权重随稀缺度增长,但增长得越来越慢——边际递减。这其实暗合信息论里的一个核心思想:一个事件越罕见,它携带的信息量越大,但信息量是按对数尺度增长的。
这套思路的源头,是剑桥学者Karen Spärck Jones在1972年那篇奠基论文里提出的。她的核心论断保哥用大白话转述一下:词的重要性应该和它出现的文档数成反比——越是只在少数文档里露面的词,匹配上它就越有价值。这个直觉,后来撑起了半个搜索引擎时代的排序逻辑。想啃原文的可以读她那篇《术语特异性的统计学解释》原始论文。
到了1988年,Salton和Buckley那篇系统比较各种词权重方案的论文用大量实验确认:基于"恰当加权的单个词"的索引,效果反而胜过那些花里胡哨的复杂表示。换句话说,TF-IDF这套朴素办法,皮实、好用、不容易翻车。这也是保哥把它做成工具的底气。
拿三篇文档手算一遍,TF-IDF就彻底通了
光盯公式容易飘,保哥用一个最小例子带你算一遍。假设语料里有3篇关于蓝牙音箱的英文文章(所以N等于3),我们盯住三个词,看它们在"文档1"(总词数按200算)里的表现。IDF用工具里的自然对数版本log(N÷DF)+1。
| 词 | 文档1出现次数 | TF(÷200) | 含该词文档数DF | IDF=log(3÷DF)+1 | TF-IDF |
|---|---|---|---|---|---|
| waterproof | 8 | 0.040 | 1 | 2.10 | 0.084 |
| speaker | 12 | 0.060 | 3 | 1.00 | 0.060 |
| bluetooth | 6 | 0.030 | 2 | 1.41 | 0.042 |
看出门道了吗?"speaker"出现12次,次数最多,可它在三篇里都泛滥(DF等于3),IDF被压到最低的1.00,TF-IDF只有0.060。而"waterproof"只出现8次,但它是文档1独有的(DF等于1),IDF高达2.10,TF-IDF反而冲到0.084拿了第一。
这就是TF-IDF最反直觉、也最有价值的地方:它能识别出"出现不算最多、却最能代表这篇"的那个差异化主词。"speaker"是这个品类谁都得提的套话,撑不起差异化;"waterproof"才是这篇真正想抢的卖点。关键词密度那套老办法,只会把"speaker"捧成第一,正好捧错。
这款TF-IDF分析器和市面上的有什么不一样?
网上TF-IDF工具不少,多数只能扔一段文字、列个词频表。保哥这款的差异,在于它默认就是"多文档对比"的思路——因为单篇算TF-IDF几乎没意义,IDF必须有一个"语料库"做参照才算得出来。
它的三个设计取舍,值得说一说,因为直接影响你怎么用:
| 设计点 | 具体做法 | 对你的意义 |
|---|---|---|
| 多文档槽位 | 可同时放入你的文章 + 多篇竞品,逐篇算TF-IDF | 把"自己"和"对手"放进同一个语料里横向比 |
| 停用词过滤 | 内置数百个英文功能词(the/and/is等)直接剔除 | 结果里不会被the、of这种噪音词刷屏 |
| 三视图输出 | 单篇TF-IDF榜 + 全局高IDF稀缺词 + 全文档共有词 | 一次看清"我强调啥""啥词稀缺""大家都在写啥" |
这里必须诚实地点一个边界:这款工具的分词和停用词表是面向英文的,它用的是按字母切词的正则,中文方块字切不开。所以它最对口的场景是英文独立站、外贸站、跨境内容——对保哥的读者来说,这恰恰是主战场。中文内容想做类似分析,得换中文分词的路子,这点别用错了。
手把手:怎么用TF-IDF分析器给一篇内容做关键词体检?
下面是保哥自己做内容审计时的标准动作,照着走一遍就上手。整个过程不用装任何软件,浏览器里就能跑完。
第1步,备齐语料。准备你要体检的那篇英文内容,再找3到5篇排在Google首页的同主题竞品页。竞品越对口,IDF参照越准。只放自己一篇是算不出有意义的IDF的。
第2步,分文档贴入。每个文档占一个槽位,给它起个好认的标签,比如"我的页""竞品A""竞品B"。HTML源码也能直接贴,工具会自动抽正文、剥标签。
第3步,点分析,先看自己那篇的TF-IDF榜。排在前面的词,就是算法判定"这篇在强调"的主词。对照一下:这些词是不是你真正想主打的目标词?如果你想打"waterproof speaker",它却把"battery"顶到第一,说明你的笔墨重心偏了。
第4步,看全局高IDF稀缺词。这一栏是跨所有文档里最稀有的词。它们往往是某篇独有的差异化角度——可能是个被你忽略的卖点,也可能是竞品在抢的长尾。
第5步,看共有词清单。所有文档都出现的词,基本就是这个主题"绕不开"的核心概念。如果某个共有词在你这篇里TF-IDF明显低于竞品,那就是你该补强的地方。
第6步,落到修改动作。把"重心偏了的词"调下来、"该补的共有词"加上去、"有价值的稀缺角度"补一段。改完再贴回工具复测一轮。
为了让搜索引擎和AI也能结构化地理解这套流程,保哥把上面的步骤也写进了页面的HowTo结构化数据里,有兴趣可以在源码里看到对应的JSON-LD标记。
三种结果视图,分别在告诉你什么?
很多人拿到一张词表就懵了,不知道该看哪个数。保哥按"产品经理读数据"的方式,把三个视图的用途讲清楚——每一栏对应一个你真正要做的决策。
视图一,单篇TF-IDF榜:回答"这篇在强调什么"。这是诊断"内容焦点"的主仪表盘。表里同时给出次数、TF、IDF和TF-IDF四列。重点看TF-IDF那列的排序,而不是次数。常有这种情况:某词次数最高,但因为它在每篇竞品里都泛滥(IDF低),TF-IDF反而靠后——这说明它是行业套话,撑不起你的差异化。
视图二,全局高IDF稀缺词:回答"哪些角度被大家忽略了"。IDF越高代表越稀有。这栏适合用来找内容缺口和长尾机会。一个高IDF词如果只在某个竞品里出现,那可能就是它的独门卖点;如果谁都没写透,那就是一片蓝海,值得你专门开一段甚至一篇去占。
视图三,共有词清单:回答"这个主题绕不开什么"。所有文档都包含的词,构成这个话题的"地基词"。工具会给出每个共有词的最大TF-IDF。你要做的是横向比:同样一个地基词,你的页面是不是把它写得比竞品更到位?缺了哪个地基词,基本等于内容有结构性漏洞。
把三个视图连起来读,你会得到一句很实在的诊断:"我这篇重心压在了X上(视图一),但这个主题真正绕不开的是Y(视图三),而我完全没碰到大家都忽略的Z(视图二)"。这一句话,胜过盯着密度百分比纠结半天。
保哥举一个去标识化后的真实切片。前阵子一个做瑜伽垫(yoga mat)的独立站客户,主打页迟迟卡在第二页。把它和首页五篇竞品一起跑了TF-IDF,三个视图各说了一句话。
视图一暴露了重心偏移。客户那篇TF-IDF榜首是"design"和"color",一看就知道笔墨全砸在外观上;而五篇竞品的榜首高度一致,都是"thickness"和"grip"——这才是买瑜伽垫的人真正在意的功能点。客户把卖点讲偏了。
视图三点出了结构性缺口。共有词清单里,"non-slip""eco-friendly""cushioning"五篇竞品全有,客户那篇要么TF-IDF极低、要么干脆缺席。这几个就是这个品类的"地基词",缺了等于内容有硬伤。
视图二递来一张差异化牌。高IDF稀缺词里冒出一个"alignment lines"(对位线,辅助初学者摆姿势的印记),只有一篇竞品轻描淡写带过。客户的垫子恰好有这个设计,却一个字没提。这就是现成的、能拉开差距的独门卖点。
诊断给完,改稿方向就不用拍脑袋了:把重心从外观挪回功能,补齐三个地基词,再单开一段讲透"alignment lines"。两个月后,这个页面进了首页。整个过程,工具没替客户写一个字,但它让"该写什么"这件事,从玄学变成了看图说话。
怎么拿它和竞品页面对比,挖出内容缺口?
TF-IDF分析器最值钱的用法,不是分析自己,而是把自己塞进竞品堆里一起算。保哥给一个外贸独立站常见的实操路径。
假设你做一款"宠物饮水机"的品类页,想抢Google首页。流程是这样:
先抓首页样本。搜你的目标词,把排前面的4到5个竞品页正文(或HTML)分别放进文档槽,加上你自己的页,一共5到6篇。
再做三件事的横向比对:
- 主词对齐没有?看自己那篇TF-IDF榜首是不是目标词。如果首页竞品的榜首高度一致(比如都是"water fountain"),而你的是"filter",说明你的内容定位飘了。
- 共有词补全没有?找出竞品共有、但你这篇TF-IDF偏低甚至缺席的词。这些往往是"用户期待但你没写"的信息点,比如"capacity""BPA-free""ultra-quiet"。
- 差异化抓住没有?从高IDF稀缺词里挑出有商业价值、但同行写得少的角度,作为你内容的独特锚点。
这套打法的本质,是把"凭感觉写内容"升级成"拿数据对标内容"。它不会替你写出好文案,但能保证你在动笔前,就知道这个主题的"及格线"画在哪、加分项藏在哪。关于怎么把这种内容缺口分析嵌进选词全流程,保哥在关键词研究升级成需求建模那篇里讲过更上游的思路,可以接着读。
TF-IDF、余弦相似度、实体分析,三款工具怎么串成一条内容优化流水线?
单用TF-IDF能解决"词该不该写、写够没有"的问题,但内容优化是个系统工程。保哥实际作业时,是把几款工具串起来用的,各管一段,互相补盲区。
第一道工序,TF-IDF分析器——管"词的权重"。先用它做前面讲的关键词体检,确定主词、补全共有词、挖出差异化角度。这一步解决"内容写不写得对"。
第二道工序,余弦相似度——管"页面之间像不像"。TF-IDF把每篇文档变成一个词权重向量之后,就能拿余弦相似度工具算两两之间的夹角。这步特别适合查"关键词蚕食"——如果你站内两个页面的余弦相似度过高,说明它们在抢同一批词,该合并或差异化了。保哥在余弦相似度压商品蚕食那篇里有完整打法。
第三道工序,实体分析——管"AI认不认得你"。到了AI搜索时代,光有关键词权重还不够,生成式引擎更看重"实体"和它们的关系。用实体分析器检查你的内容里有没有清晰的人物、机构、产品、概念实体,以及它们有没有被知识图谱关联。这一步,决定你能不能被AI概览引用。想系统补这块的,保哥实体SEO指南那篇讲得最全。
第四道工序,可读性评分——管"人读不读得下去"。词对了、不蚕食了、实体清楚了,最后还得让真人读得舒服。用可读性评分器跑一遍Flesch等指标,把那些长难句和三音节大词揪出来改短。
这四步连起来,就是一条"权重对标 → 去重防蚕食 → 实体强化 → 可读性打磨"的内容流水线。TF-IDF是这条线的第一道闸门,也是最该养成习惯的那一步。
从TF-IDF到BM25:现代搜索引擎其实在用什么升级版?
聊到这里得给你交个底:Google、Elasticsearch这类现代检索系统,早就不用最朴素的TF-IDF了,而是用它的进化版BM25。理解这层升级,能帮你避免对TF-IDF期望过高。
BM25在两个地方修补了TF-IDF的短板,都很有现实意义:
第一,词频饱和(saturation)。朴素TF-IDF里,一个词出现20次的权重是出现10次的整整2倍——线性增长,没有上限。但常识告诉我们,一个词从出现1次到5次,相关性提升明显;从50次到100次,其实没太大区别,甚至是堆砌信号。BM25引入一个饱和曲线,让词频的贡献涨到一定程度就趋于平缓。这等于从算法层面就给"堆词"判了死刑。
第二,文档长度归一化。BM25会参考"这篇相对于语料平均长度是长是短",对长文档的词频做折扣,避免长文仅仅因为字多就占便宜。TF-IDF的归一化TF也部分处理了这点,但BM25做得更精细、可调。
那为什么保哥的工具还用TF-IDF,不直接上BM25?因为对"内容诊断"这个目的来说,TF-IDF的输出更直观、更好解释——你能清清楚楚看到TF、IDF、乘积三列,知道每个分数怎么来的。BM25的参数(k1、b)会让结果变成一个更黑盒的分。做诊断要的是可解释,做排序才要的是精确,这是两个不同的取舍。你拿TF-IDF看清内容焦点,Google拿BM25去精排,各司其职。
怎么把TF-IDF体检变成每月例行动作?
工具再好,用一次就忘等于没用。保哥一直跟客户强调,内容优化不是一锤子买卖,而该像体检一样定期做。下面是保哥给团队定的一套可落地的月度SOP,你可以直接抄。
盘点优先级。每月初,从Google Search Console拉出"有曝光但点击率低""排在第5到15名"的页面——这些是离首页一步之遥、最值得抢救的。它们就是这个月TF-IDF体检的清单。
批量对标。对清单里的每个页面,搜目标词、抓首页前4到5篇竞品,连同自己丢进TF-IDF分析器。记录三件事:主词有没有偏、缺了哪些共有词、有没有可抢的稀缺角度。
排期改稿。把诊断结论翻译成具体改稿任务,塞进内容日历。注意别一次改太猛,一篇页面一个月动一次就够,改完留出时间让搜索引擎重新抓取、给出反馈。
回测闭环。下个月初再拉一次Search Console,看上月改过的页面排名和点击有没有动。有效就固化打法,没效就回头查是不是内容相关性之外的问题(意图不符、外链不足、体验拉胯)。
这套SOP的关键,是把TF-IDF从"灵机一动用一下的玩具",变成"嵌进内容运营节奏的固定工序"。能坚持做的人,半年后内容库的整体质量会和同行拉开肉眼可见的差距。
用TF-IDF优化内容时,哪些坑会让你越改越糟?
工具好用,但用歪了反而害事。保哥踩过、也见客户踩过的几个典型坑,挨个提醒一下。
坑一,把TF-IDF当成"再去堆词"的许可证。看到某个词TF-IDF该高,就生硬地往文里塞十遍,这是把老的关键词堆砌换了层皮。算法看的是相对权重,自然地把概念讲透,权重自然会上去;硬塞只会让句子别扭、被反作弊识别。
坑二,忘了TF-IDF完全不懂语义。它只认字面字符串,"car"和"automobile"在它眼里是两个毫不相干的词。所以它给的是"统计层面的词权重",不是"语义层面的相关性"。真正的同义、近义关系,得靠余弦相似度、词向量这类语义工具补上。
坑三,语料选错,结论全错。IDF是相对于你放进去的那批文档算的。如果你的竞品样本选得不对口(比如做B2B工业品,却放了一堆消费品博客),算出来的稀缺词和共有词全是噪音。语料质量决定结论质量,这是TF-IDF这类方法的命门。
坑四,拿它当排名预测器。TF-IDF高不直接等于排名高。Google今天的排序融合了几百个信号,搜索意图、E-E-A-T、链接、用户行为都在里头。TF-IDF只帮你把"内容相关性"这一块做扎实,它是必要条件之一,不是充分条件。保哥在TF-IDF和SEO到底什么关系那篇里专门聊过它在现代算法里的真实位置,建议配着读。
记住一句话:TF-IDF是一把好用的诊断尺,不是包治百病的药。它帮你看清问题在哪、缺口在哪、机会在哪,但把内容写好、把卖点讲透、把真实价值传递给读者,终究是人的活儿。工具负责把方向指对,把活干漂亮的,永远是握工具的那个人。
常见问题解答
TF-IDF和关键词密度到底有什么区别?
关键词密度只看一个词在单篇里的占比,高就算相关,完全忽略这个词在同类内容里是不是烂大街。TF-IDF多了一层IDF,会惩罚那些"谁都在用"的大众词、奖励那些"你独有"的稀缺词。所以TF-IDF衡量的是区分度,密度衡量的只是出现频率,后者早该被淘汰。
这个工具能直接分析中文内容吗?
不建议。这款TF-IDF分析器的分词是按英文字母规则切的,还内置了英文停用词表,处理中文方块字会切不开、结果失真。它的设计定位就是英文独立站、外贸和跨境内容。中文要做类似分析,需要换用支持中文分词(如结巴分词)的方案。
我应该放多少篇竞品文档才合适?
经验值是连同自己在内4到6篇,也就是3到5篇竞品。太少(比如只放2篇)IDF区分不出层次;太多则容易混进不对口的页面稀释信号。挑的时候认准"目标词Google首页、主题高度一致"这两个标准,样本对口比样本数量更重要。
TF-IDF高的词,是不是直接多写几遍就行?
恰恰相反。生硬堆词是把老式关键词堆砌换了个说法,既伤可读性又可能触发反作弊。正确做法是围绕该概念把内容讲透、讲全——补充细节、案例、相关子话题,词频会自然地、合理地上升,权重也跟着上去。算法奖励的是"把话题写明白",不是"把词重复够"。
TF-IDF分析器算出来的结果,能预测我的Google排名吗?
不能,也不要这么用。TF-IDF只覆盖"内容相关性"这一个维度,而现代搜索排序还融合了搜索意图、E-E-A-T、外链、页面体验、用户行为等几百个信号。把TF-IDF做好,只能保证你内容相关性这块达标且有差异化,它是排名的必要条件之一,不是充分条件。
它和余弦相似度工具配合,具体能解决什么问题?
最典型的是查关键词蚕食。TF-IDF先把每篇内容转成词权重向量,余弦相似度再算两个向量的夹角,得出页面之间"像不像"的分数。站内两个页面相似度过高,就说明它们在抢同一批词、互相内耗,该合并或做差异化。两款工具一前一后,正好串成一条诊断链。
权威参考资料
本文标题:《TF-IDF分析器使用教程:给独立站内容做关键词权重体检》
本文链接:https://zhangwenbao.com/tfidf-analyzer-content-keyword-weighting-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0