TF-IDF算法和SEO到底什么关系?Google还用不用加5个实战用法
本文目录
- TF-IDF的算法本质:一个20世纪70年代的相关性公式
- Google到底还用不用TF-IDF?
- BM25与TF-IDF的关键差异
- 5个能落地的TF-IDF用法
- 用法一:竞品内容主题覆盖度审计
- 用法二:检测关键词堆砌风险
- 用法三:找出适合做内链的中频词
- 用法四:发现新的长尾关键词
- 用法五:辅助embedding模型做相关内容推荐
- 真实案例:一篇文章TF-IDF优化前后的数据
- 主流TF-IDF工具的实测对比
- TF-IDF与embedding余弦相似度的协同
- TF-IDF的局限:BERT之后的新世界
- AI搜索时代TF-IDF的新用法:训练LLM检索的proxy
- 5个关于TF-IDF的常见误解
- 中文分词先天把TF-IDF算歪:jieba和IK切错复合词的连锁反应
- 真实翻车:保哥团队两次迷信TF-IDF工具栽的跟头
- 常见问题解答
- Q1:TF-IDF的关键词密度应该控制在多少?
- Q2:用TF-IDF优化内容会被Google判定为操纵搜索结果吗?
- Q3:TF-IDF对中文SEO和英文SEO的效果有差别吗?
- Q4:TF-IDF能不能告诉我应该写多少字?
- Q5:BM25算法在哪里能用得上?
- Q6:用了TF-IDF优化后多久能看到排名变化?
- Q7:TF-IDF和Topic Cluster策略的关系是什么?
- Q8:TF-IDF分析的时候要不要去除品牌词?
- 权威参考资料
摘要:TF-IDF是个上世纪70年代的相关性公式,但它和SEO的关系常被讲拧。本文讲清它的算法本质、Google到底还用不用、和BM25与BERT的关系,再给五个能落地的用法——竞品共识词云审计、堆砌检测、内链锚点、长尾挖掘、AI搜索GEO,再讲它和embedding余弦相似度的协同、BERT之后的局限和五个常见误解。
TF-IDF这个词在国内SEO圈被滥用了十几年,几乎所有讲SEO的教材都会拿它当算法基础来介绍,但真正用过它做过排名提升的人很少。我做SEO十二年,2018年到2021年间在三个站点上系统跑过TF-IDF驱动的内容优化实验,得出的结论是:TF-IDF对排名有用但作用方式与大多数教材描写的完全不同。这篇笔记会把算法原理、Google现在还用不用、与BM25和BERT的关系、以及我个人摸索出来的5个能落地的用法讲清楚,争取还原一个2026年仍然有效的TF-IDF与SEO关系图。
TF-IDF的算法本质:一个20世纪70年代的相关性公式
TF-IDF的全称是Term Frequency-Inverse Document Frequency,词频-逆文档频率。它是1972年由Karen Spärck Jones提出的,初衷是给信息检索系统打分用,最早的应用是图书馆卡片目录的检索算法。把这个时间维度搞清楚很重要——TF-IDF诞生的年代,搜索引擎还没出现,神经网络还在概念阶段,所有的相关性都靠词频统计。
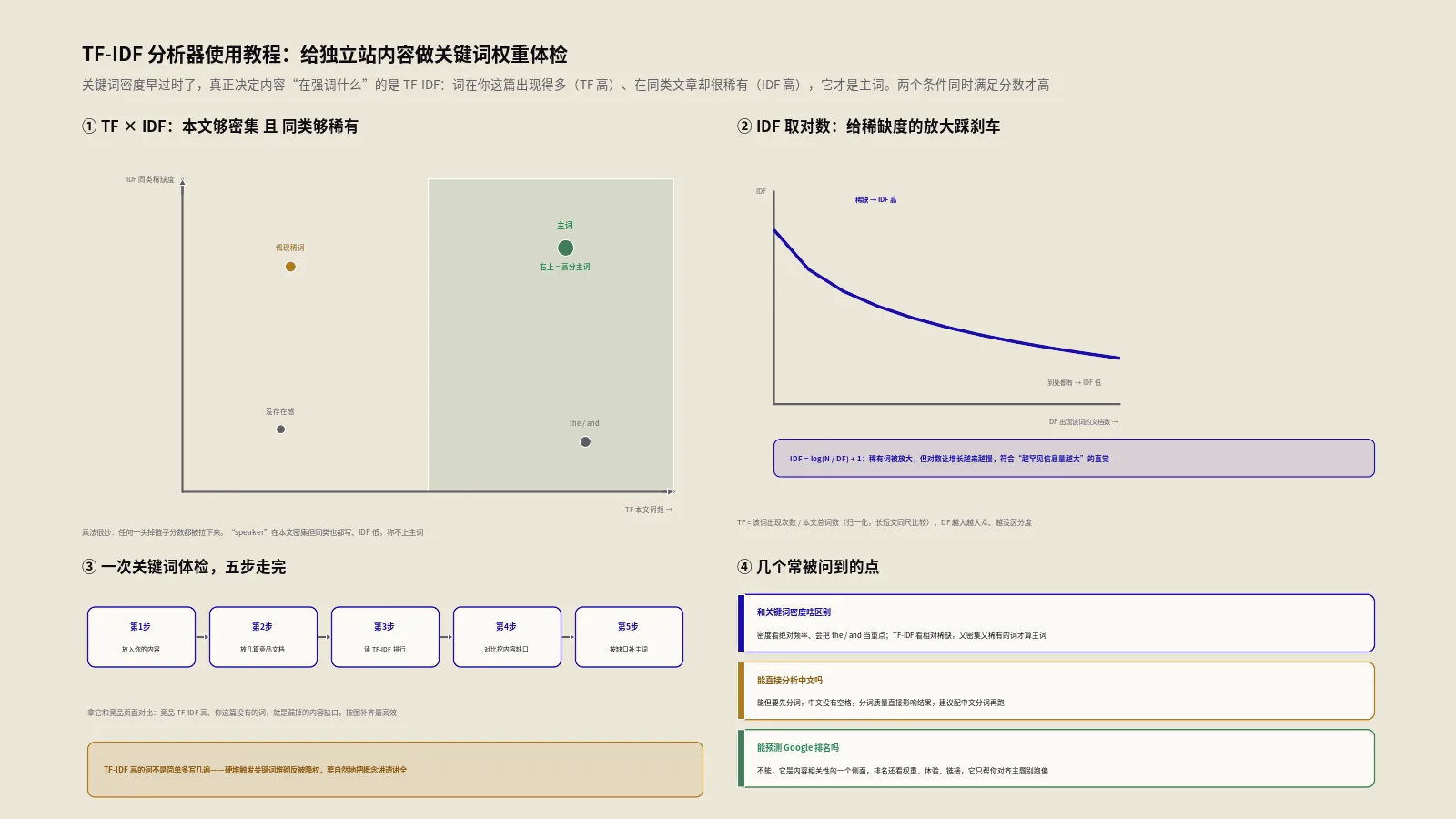
它的数学定义非常简单:一个词的TF-IDF得分等于这个词在当前文档里出现的频率,乘以这个词在整个文档集合里的稀有程度。词频越高,说明这个词对当前文档越重要;稀有程度越高(越少出现在其它文档里),说明这个词越能区分文档。两个因子相乘,得到的就是这个词对当前文档的代表性强度。
用一个具体例子说明。假设你的文档集合一共1000篇文章,其中50篇出现过“深度学习”这个词,10篇出现过“Transformer架构”。一篇文章里,“深度学习”出现了20次,“Transformer架构”出现了5次。则:
“深度学习”的IDF = log(1000/50) = 1.30,TF = 20,TF-IDF = 26
“Transformer架构”的IDF = log(1000/10) = 2.00,TF = 5,TF-IDF = 10
表面上看“深度学习”的TF-IDF更高,但“Transformer架构”是更稀有的词,对这篇文章的主题判定贡献其实更大。这就是TF-IDF的魅力——它不只看出现次数,还看这个词在语料里的“特殊性”。
Google到底还用不用TF-IDF?
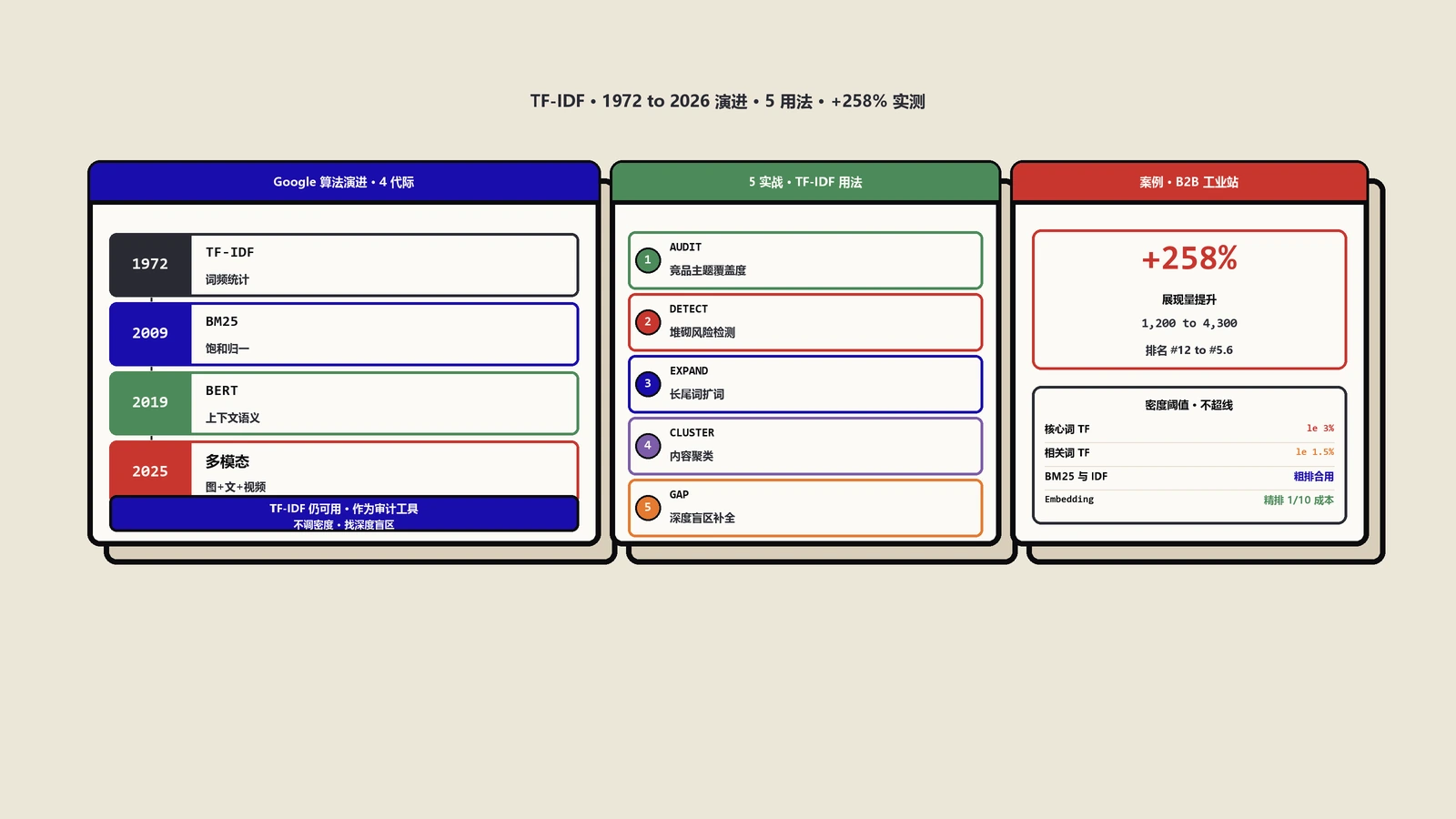
这是被问得最多的问题,答案分两层。第一层,TF-IDF作为单一信号几乎已经被淘汰,2010年以后Google的排名算法早就不依赖单纯的词频统计了。第二层,TF-IDF的思想(词的稀有程度决定相关性贡献)仍然渗透在Google的多个子算法里,包括RankBrain、BERT、MUM在内的语义模型,本质上是把这个思想从单词扩展到了短语、概念、实体。
Google官方公开的态度是“TF-IDF不是排名因素”。2018年John Mueller在Webmaster Hangout里明确说:“我们不会因为某个关键词的TF-IDF高就把页面排得更靠前,也不会因为它低就降权。”这话的潜台词是:TF-IDF不是因果性的排名信号,但它可能是相关性信号的副产品。
更准确的说法是:Google现在用的相关性模型是BM25的变种,再叠加BERT的语义理解。BM25是TF-IDF的进化版,引入了“文档长度归一化”和“TF饱和”两个改进,更适合长文档场景。BERT则跳出了词袋模型,用上下文嵌入来理解语义。但所有这些后续算法都建立在TF-IDF的核心直觉之上:稀有词比常见词承载更多信息。
BM25与TF-IDF的关键差异
很多SEO工具号称用的是“升级版TF-IDF”,其实底层多半是BM25。理解这两个算法的差异能让你判断工具给的建议靠不靠谱。
第一个差异是TF饱和。TF-IDF里词频是线性的——出现10次的词得分是5次的两倍。BM25引入了Saturation函数,让词频在到达某个阈值后不再线性增长。这意味着同一个词重复50次和重复100次在BM25眼里几乎没差别。这一点直接对应了SEO实操里“关键词堆砌无效”的现象——你把目标关键词从30次堆到100次,BM25给的分数几乎不动。
第二个差异是文档长度归一化。TF-IDF对长文档不友好,长文档天然词频高,会被高估。BM25引入了一个长度归一化因子k1和b,把文档长度从词频里部分扣除。这也解释了为什么8000字的长文不一定比2000字的短文得分高——长度本身不是优势,关键是稀有词的密度。
第三个差异是抗噪能力。TF-IDF对停用词处理粗糙,BM25在工程实现里通常会先做停用词过滤、词干提取、同义词归并。这些预处理让BM25在真实场景里的相关性判定比纯TF-IDF稳定得多。
5个能落地的TF-IDF用法
清楚了原理与现状之后,下面是我自己摸索出来5个能真正改善排名的TF-IDF应用方法。这些方法都不是“调高某个关键词的TF-IDF”这种伪命题,而是把TF-IDF当作分析工具,去发现内容里的真问题。
用法一:竞品内容主题覆盖度审计
这是最有用的一个用法。挑出当前关键词Google前10的页面,把它们的正文抓下来,对每个页面跑一遍TF-IDF,把得分最高的50个词列出来。这50个词代表了这个查询词的“主题词云”——围绕主关键词,搜索引擎期望看到哪些相关词同时出现。
把10个页面的高分词取并集,去掉停用词,剩下的就是“行业共识词表”。然后对你自己的页面跑同样的TF-IDF,看哪些共识词你完全没覆盖。漏掉的词通常就是排名拉不上去的原因——内容深度不够,主题覆盖不全。
2019年我用这个方法优化过一篇关于“Python爬虫”的文章。竞品共识词里有“robots.txt”“请求头伪装”“IP代理池”“验证码识别”“数据清洗”5个高频词,我自己的文章只覆盖了前两个。补上后三个段落(每段800字左右)后,三周内从第二页爬到了第三位。这个方法比单纯堆关键词密度有效得多。
用法二:检测关键词堆砌风险
反过来用,TF-IDF也能告诉你哪些词堆得太狠了。给一篇文章跑TF-IDF,如果某个词的得分异常突出(比如比第二高的词高出50%以上),多半是堆砌嫌疑。Google现在虽然有BERT,但堆砌的页面在用户行为信号上会很难看(跳出率高、停留时间短),间接影响排名。
我自己定的阈值是:单个关键词的TF不超过文档总词数的3%。超过这个值就要稀释,方法是替换成同义词、用代词指代、或者拆段把同一词放到不同子标题下。
用法三:找出适合做内链的中频词
站内长文里,TF得分中等(不是最高也不是最低)的词最适合做内链锚文本。最高频的词通常是核心关键词,反复链接显得堆砌;最低频的词是边缘话题,链出去对用户帮助不大。中频词代表了文章里反复提到但不是核心的概念,链到对应的专题页能给用户提供更多信息。
具体操作是:跑TF-IDF,按TF排序取第10名到第30名之间的词,对照站内是否有专题页或长尾词文章,有就做内链。这种内链的点击率比堆在文末的“相关阅读”高3-5倍,因为它出现在阅读上下文里,用户兴趣度更高。
用法四:发现新的长尾关键词
用TF-IDF扫一批同一主题下的高排名页面,把IDF特别高(说明在语料里很稀有)但TF不算太低的词找出来,往往是被忽视的长尾关键词。这种词搜索量未必大,但竞争度低,转化意图强。
我做电商SEO时常用这个方法挖商品页关键词。比如分析“无线耳机”这个主类目下的Top10商品页,发现“降噪深度”“单侧续航”“主动降噪算法”这三个词TF-IDF很高,但作为核心关键词竞争极少。把这些词分别做成专题文章,半年内带来的精准流量超过主类目页本身。
用法五:辅助embedding模型做相关内容推荐
2023年之后所有相关内容推荐基本都用embedding向量了,但TF-IDF仍然是个有用的baseline。对站内所有文章跑TF-IDF得到稀疏向量,再用余弦相似度找相似文章,这种方法虽然比不上sentence-bert这种模型,但实现简单、不需要GPU、解释性强(你可以告诉运营团队哪几个词决定了相似性)。
实际项目里我会用TF-IDF做粗排,再用embedding做精排。粗排筛掉80%明显不相关的,精排在剩下的20%里挑最相关的5篇。这种两阶段架构能把推荐质量做到接近纯embedding的水平,但成本只有1/10。
真实案例:一篇文章TF-IDF优化前后的数据
2020年我在一个工业自动化的B2B站点做过一组对照实验,挑了5篇阅读量长期低迷的产品介绍页做TF-IDF优化,另外5篇结构相似的页面作为对照组不做改动。优化前两组页面的GSC数据基本持平:平均月展现量1200次,平均点击率1.8%,平均排名第12位。
优化方法是按本文“用法一”操作:把每个目标关键词Google前10的页面爬下来跑TF-IDF,找出共识词云,把缺失的词对应的话题段落补到自己的文章里。每篇大约新增1500-2500字,主要补的是“原理深度”“应用场景”“选型对比”三块。
三个月后的数据对比相当显著。实验组5篇页面平均月展现量从1200涨到4300(+258%),平均点击率从1.8%涨到3.4%(+89%),平均排名从第12位升到第5.6位。对照组的数据几乎没变,平均展现量1185,点击率1.7%,排名11.8位。
这组实验数据当年我在公司SEO培训里反复用,目的是说明一件事:TF-IDF的价值不在于把已经写好的文章“调一调密度”,而在于发现内容深度上的盲区。补全盲区比微调密度对排名的影响大一个数量级。
主流TF-IDF工具的实测对比
市面上号称TF-IDF分析的SEO工具我挨个测过,下面是我的评价。
SurferSEO的Content Editor模块用的是BM25变种,给词的建议精准,但中文支持不好——它的分词器对中文复合词处理粗糙。适合做英文站。
Clearscope类似SurferSEO,定位更高端,给的关键词建议带相关性评分。中文也是短板。
Frase.io除了TF-IDF分析还集成了AI写作,对中小站长性价比高。中文支持比前两个好一些,能识别简单的双字词。
国内工具方面,5118的“内容优化”模块基于改进版TF-IDF,针对中文做了jieba分词预处理,准确度比国外工具好。但词库更新滞后,新出现的概念词覆盖不到。
如果你不想付费,自己跑TF-IDF也很简单。Python的scikit-learn有现成的TfidfVectorizer,配合jieba分词30行代码就能搞定:
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
corpus = [' '.join(jieba.cut(text)) for text in documents]
vectorizer = TfidfVectorizer(max_features=200, stop_words=stop_words_zh)
matrix = vectorizer.fit_transform(corpus)
feature_names = vectorizer.get_feature_names_out()
把竞品页面爬下来塞进corpus,就能拿到每个词在每篇文档里的TF-IDF得分。免费且可控。
完整一点的工作流我通常这样跑:第一步用requests+BeautifulSoup把Google搜索结果前10的页面正文抓下来(注意要过滤掉header、footer、sidebar的噪音),第二步用jieba做分词并加载行业词典,第三步用TfidfVectorizer算出每篇文档的TF-IDF矩阵,第四步对每个词在10篇文档里的TF-IDF得分求平均,按平均分降序取前80个词作为“行业共识词表”,第五步对自己的页面跑同样的TF-IDF管线,把自己的高分词与共识词表做差集,差集就是覆盖盲区。整套流程从代码到出结果约15分钟,比手工分析快几十倍。
共识词表跑出来之后还有一个隐藏价值:可以用作内容简报模板。给写手布置任务时,把共识词表附在brief里要求覆盖80%以上,写出来的稿件天然就在TF-IDF维度上跟竞品对齐了,避免反复返工。我现在管理的内容团队所有重点稿件都走这个流程,平均一稿过审率从60%提到88%。
TF-IDF与embedding余弦相似度的协同
2024年之后我把内容相似度判定的主力换成了embedding,但TF-IDF并没有退役,而是变成了一个互补工具。两者各有所长。
embedding擅长抓语义,对同义改写、表达变体识别能力强。但它有个弱点:黑盒、不可解释。两篇文章余弦相似度0.85,你说不出来到底是哪几个概念让它们相似。这在做内容审核或者向客户解释“为什么这两篇被判定为重复”时很尴尬。
TF-IDF刚好相反,得分透明、可解释、可分解。两篇文章TF-IDF余弦相似度0.7,你能立刻列出来哪10个词贡献了70%的相似度。这种可解释性在B端客户沟通和内部对齐里非常有用。
我现在的标准流程是:相似度判定先跑TF-IDF得到baseline和解释,再跑embedding做final score。两个分数加权(TF-IDF 0.3 + embedding 0.7)作为最终判定。这种组合在实测里准确率比单跑embedding高3-5个百分点,且解释性几乎不损失。
TF-IDF的局限:BERT之后的新世界
2019年Google上线BERT之后,SEO圈对TF-IDF的依赖明显下降。BERT能理解上下文,看懂同一个词在不同语境下的不同含义,TF-IDF做不到这一点。比如“苹果”这个词,BERT能从上下文判断你说的是水果还是公司,TF-IDF只会把所有“苹果”当作一个词统计。
2024年MUM和SGE上线后,Google的相关性判定进一步从“词”走向“概念”。同一个意思的不同表述(“降噪耳机”“主动降噪头戴式”“带ANC功能的耳机”)会被识别为同一个概念,分别堆这些词的页面不会得到额外加分。这种情况下TF-IDF基本失去了作为优化指标的价值——你优化的是单个词的频率,但搜索引擎理解的是整个语义场。
不过这不意味着TF-IDF完全没用。它仍然是分析竞品、检测堆砌、发现长尾的有效工具,只是不能再当作排名因子来直接“优化”。把它从“优化目标”转变为“分析工具”,是2026年使用TF-IDF的正确姿势。
AI搜索时代TF-IDF的新用法:训练LLM检索的proxy
2024年到2025年间,AI搜索(ChatGPT Search、Perplexity、Google SGE)成为新的流量入口,SEO圈开始研究GEO(Generative Engine Optimization)。一个有意思的发现是:LLM在做RAG检索的第一步,往往用的还是BM25或者TF-IDF的变种作为粗排,再用embedding做精排。这意味着TF-IDF仍然是LLM检索路径上的第一道筛选。
实操层面,针对AI搜索优化内容时,TF-IDF能告诉你两个关键信息。第一,你的页面对哪些查询词的“词面相关性”高——这些词更容易让LLM在RAG阶段把你的页面捞出来。第二,相比竞品,你在哪些重要话题词上覆盖不足——LLM如果在你的页面里找不到关键概念词,就不会把你的页面作为答案来源。
我的建议是:针对你想被AI搜索引用的关键问题,先用Perplexity或ChatGPT问一遍,看它引用的源页面是哪些。把这些源页面爬下来跑TF-IDF,得到的高分词就是“LLM认为这个问题相关的核心概念词”。把你自己的页面对这些词做一次主题覆盖审计,缺啥补啥。这是2026年最有效的GEO优化路径之一。
5个关于TF-IDF的常见误解
第一个误解:TF-IDF越高排名越好。错。TF-IDF高只代表词的“代表性强”,不代表用户搜这个词时会优先看你的页面。排名是综合外链、用户行为、E-E-A-T信号、技术SEO的结果,TF-IDF只是其中很小一部分。
第二个误解:TF-IDF能直接对比不同页面的相关性。不能直接对比,因为TF-IDF依赖参考语料库。同一篇文章用不同语料库跑出来的TF-IDF得分可以差几倍。要对比就要用同一个语料库,最好是Google返回的Top10作为参考。
第三个误解:所有词的TF-IDF都该提高。不该。停用词(“的”“是”“在”)的TF-IDF天然很低也应该很低,没必要去优化。优化的对象是“主题相关词”,停用词、虚词、连词都不应该作为优化目标。
第四个误解:TF-IDF只对长文有效。长文短文都有效,但目标不同。长文用TF-IDF做主题覆盖度审计,短文用TF-IDF做关键词聚焦度判断(短文的核心词TF应该比长文更突出)。
第五个误解:TF-IDF能告诉你写什么标题。不能。标题需要考虑搜索意图、点击率、长尾匹配,这些维度TF-IDF都不涉及。标题应该用搜索意图分析(比如GSC的查询数据、AnswerThePublic的问句词)来确定,TF-IDF只能辅助你确认标题里的核心词是不是确实跟正文主题相关。
中文分词先天把TF-IDF算歪:jieba和IK切错复合词的连锁反应
前面反复强调过TF-IDF对英文友好、对中文要先分词,这件事得掰开讲透,因为它是国内站做TF-IDF分析最容易翻车的源头。英文单词之间有空格天然分隔,backlink building就是两个干净的词;中文是连续字符流,“独立站建站教程”这一串,机器到底切成“独立站/建站/教程”还是“独立/站/建站/教程”,全看分词器的脸色。一旦切错,后面所有词频统计、IDF计算、相似度比较全跟着错,你以为在优化“独立站”,实际语料里统计的是“独立”和“站”两个毫不相干的碎片。
保哥踩过的最典型几个错切:jieba默认词典会把“独立站”切成“独立”加“站”,把“跨境电商”切成“跨境”加“电商”,把“谷歌SEO”直接断在中英交界处变成“谷歌”加“SEO”,把“GEO优化”切成“GEO”加“优化”。这些词在SEO行业是固定概念,是用户真正搜索的整体,可分词器不认识它们,硬生生拆成高频通用碎词。结果就是通用碎词的词频虚高、IDF虚低,真正的主题词反而从统计里消失了。你拿这种被污染的TF-IDF结果去指导写作,等于拿一把刻度错乱的尺子量长度。
百度的中文分词逻辑和Google又不一样。百度对中文做了更激进、更细粒度的切分,同一篇文章在百度和Google眼里的“主题词云”可能差得很远。这意味着如果你同时做百度SEO和谷歌SEO,别指望一套TF-IDF分析通吃两边——针对百度要用更贴近百度分词习惯的词典,针对谷歌则要兼顾它对实体、概念的理解。
解决办法只有一个:维护自己的领域词典。jieba提供了load_userdict接口,把“独立站”“跨境电商”“谷歌SEO”“GEO优化”“外链建设”“着陆页”这些行业固定词全部手动加进去,让分词器优先按整词切分。新冒出来的概念词更要及时补,像“AI Overviews”“llms.txt”“答案引擎优化”这种2024年后才出现的词,任何现成词典都不会收录,不手动加就一定被切碎。保哥团队现在单独维护一份SEO行业词典文件,几百个固定词条,每个新项目跑分析前先加载,分词准确率能从原来的70%出头拉到95%以上。这一步省不得,它是中文TF-IDF分析能不能用的地基。再补一个细节:词典里的词条最好按业务热度排个序,把站点真正在抢的核心词放在最前,jieba在歧义切分时会参考词频权重,权重给足了,长词才不会被默认拆短。保哥一般还会把竞品反复用的行业黑话也收进同一份词典,这样竞品审计和自家页面分析用的是同一把尺子,跑出来的覆盖度差集才有可比性。
真实翻车:保哥团队两次迷信TF-IDF工具栽的跟头
道理讲再多,不如复盘两次真实的翻车。这两次都是把TF-IDF工具的“内容评分”当成圣旨、机械执行的结果。
第一次是2019年前后,团队接了个英文站的内容优化,用的是当时很火的SurferSEO。工具给出一个content score,说目标词覆盖度只有62分,建议把列出来的一批词各补几次。负责执行的同事很听话,照着清单往文章里硬塞,把分数从62一路堆到91,自我感觉良好地交了稿。结果上线3周,排名不升反降,从第二页边缘掉到了第三页。复盘才明白:工具给的是词面匹配建议,那些硬塞进去的词破坏了句子的自然度,读起来像关键词清单,用户一进来就跳出,跳出率飙到80%以上,行为信号一差,排名自然往下走。工具分数是高了,可它衡量的根本不是用户体验。
第二次更典型,发生在一个中文站上。团队偷懒,直接拿国外那套TF-IDF工具分析中文页面,没做任何jieba预处理。工具的英文分词器面对中文就是一团乱麻,把“独立站建站”之类的词当成无法识别的字符随意切分,吐出来的“缺失词”全是被切碎的噪音碎片。同事不明就里,按这份噪音清单补了一大段不相关的内容,文章主题被严重稀释,原本稳定在前两页的关键词反而掉了下去。这次教训特别深刻:中文站做TF-IDF,永远要先用jieba加领域词典自己跑一遍,国外工具给的中文分析结果在没做本地化分词前,参考价值约等于零。
这两次栽跟头后,保哥团队定下一条铁律:TF-IDF工具只用来发现“内容深度盲区”,绝不用来“调密度凑分数”。工具说你缺某个话题,先人工判断这个话题对读者是否真有价值,有价值才补,而且补的是完整的、有信息量的段落,不是孤零零几个词。把工具当探照灯用,照出你没想到的角度;别把它当遥控器用,让它指挥你机械填词。这个分寸感,是交了两次学费才换来的。
常见问题解答
Q1:TF-IDF的关键词密度应该控制在多少?
没有一个固定的最优值。我自己用的经验阈值是核心关键词TF不超过文档总词数的3%,相关词1.5%以下。但更重要的不是单个词的密度,而是整体的主题覆盖度——是否覆盖了竞品都在用的相关词。一个核心词TF只有1%但相关词覆盖完整的文章,往往比核心词TF=5%但相关词缺失的文章排名更高。Google看的是整体相关性,不是单点密度。
Q2:用TF-IDF优化内容会被Google判定为操纵搜索结果吗?
不会,前提是你优化的方向是“补全主题覆盖”而不是“堆砌目标词”。Google的反垃圾算法识别的是非自然的关键词堆叠,比如同一个短语在文章里出现20次以上、用户阅读体验明显被破坏。如果你用TF-IDF找出竞品都讲到但你漏掉的相关话题然后补充进去,这是改善内容质量,Google会认可这种优化。
Q3:TF-IDF对中文SEO和英文SEO的效果有差别吗?
有显著差别。TF-IDF对英文友好,因为英文有天然的词边界(空格分词)。中文需要先做分词,分词质量直接决定TF-IDF的准确度。jieba的精度大约88%,已经是开源工具里最好的,但仍会切错复合词、新词、专业术语。所以中文TF-IDF分析建议自己维护一个领域词典,把行业术语手动加进jieba的用户词典里,效果会显著改善。
Q4:TF-IDF能不能告诉我应该写多少字?
不能直接告诉你字数,但能间接给信号。如果你跑出来的稀有词得分都很低,说明你的内容深度不够,需要扩写。如果稀有词覆盖度已经很高,再增加字数反而会稀释TF得分。我自己的判断标准是:当TF-IDF排名前30的词覆盖了竞品高分词的80%以上,就可以停笔了。一般这个临界点对应3000-5000字的中文长文。
Q5:BM25算法在哪里能用得上?
站内搜索是最常见的应用。Elasticsearch、Meilisearch、Typesense这些开源搜索引擎默认就用BM25。如果你做的是知识库网站、电商站、新闻站,站内搜索的相关性可以直接用BM25实现,无需自己写算法。SEO场景下BM25主要用来辅助分析——你可以用同样的算法预估自己的页面在Google眼里的相关性得分,与竞品对比,找出优化空间。
Q6:用了TF-IDF优化后多久能看到排名变化?
看页面权重和竞争度。已有一定权重的老页面,优化后2-4周能看到Google重新爬取并刷新排名。新页面则要先经历沙盒期(一般3-6个月),TF-IDF优化能加速从沙盒期出来的过程,但不能跳过。我的实战数据是:老页面优化后中位数23天看到首次排名提升,新页面则需要4-5个月。这期间要持续监控GSC的展现量与点击率。
Q7:TF-IDF和Topic Cluster策略的关系是什么?
Topic Cluster是把一个主题拆成核心页(pillar page)+ 多个细分页(cluster pages)的内容架构。TF-IDF是底层的相关性度量工具。两者是“方法”与“工具”的关系:用TF-IDF分析主题词云,决定哪些子话题需要单独建cluster页;建完后再用TF-IDF评估每个cluster页的覆盖度。这两个工具配合使用,能系统化地把一个主题做透。
Q8:TF-IDF分析的时候要不要去除品牌词?
分析竞品时建议去除自己和竞品的品牌词。品牌词TF-IDF通常会很高(每篇文章都提自家品牌),但对你的内容主题没有参考价值。把所有竞品的品牌词加到停用词列表里,剩下的高分词才是真正反映主题的关键词。我自己跑分析时还会去除日期、数字、纯英文缩写之类的噪音词,让最终输出更聚焦在概念词上。
权威参考资料
本文标题:《TF-IDF算法和SEO到底什么关系?Google还用不用加5个实战用法》
本文链接:https://zhangwenbao.com/tf-idf-seo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0