电商SEO语义优化实战:余弦相似度压商品蚕食八大应用
本文目录
- 搜索引擎如何"读懂"你的页面:从关键词匹配到语义向量
- 向量嵌入:文本变数字的底层技术
- 向量维度与语义颗粒度的关系
- 余弦相似度的数学原理与SEO含义
- 为什么关键词密度已经失效
- 余弦相似度在电商SEO中的8大实战应用
- 应用一:产品命名——撬动分类页排名的语义杠杆
- 应用二:分类页内容深度重构
- 应用三:用户评论——免费的语义增强引擎
- 应用四:语义内链矩阵——超越PageRank的链接策略
- 应用五:跨页面语义一致性管理
- 应用六:产品详情页的语义分区策略
- 应用七:竞品语义差距分析——最低成本的排名提升方法
- 应用八:结构化数据的语义增强作用
- 余弦相似度的测量方法:从代码到工具
- 方法一:Python脚本精确计算
- 方法二:免费工具辅助分析
- 方法三:竞品对标法
- 余弦相似度在AI搜索时代的战略地位
- AI搜索引擎的引用逻辑
- 对电商SEO的四大战略启示
- 规模化实施路线图:从单页面到全站语义网络
- 第一阶段:基础设施搭建(1-2周)
- 第二阶段:核心页面优化(2-4周)
- 第三阶段:系统化扩展(持续迭代)
- 进阶避坑指南:余弦相似度优化中的常见误区
- 误区一:追求极高的余弦相似度
- 误区二:忽略搜索意图类型
- 误区三:只优化文本忽略页面结构
- 误区四:忽视负面语义信号
- 误区五:将余弦相似度当作唯一排名因素
- 常见问题
- 余弦相似度和TF-IDF有什么区别?
- 余弦相似度高就一定能获得好排名吗?
- 电商网站如何大规模优化余弦相似度?
- 产品评论真的能提升页面的余弦相似度吗?
- 余弦相似度对AI搜索(GEO)有什么具体影响?
- 如何判断我的页面余弦相似度是否需要优化?
- 普通SEO从业者如何入门余弦相似度优化?
- 权威参考资料
摘要:电商SEO怎么从关键词填充升级到语义优化?本文深度解析余弦相似度在电商里的底层原理和实战应用,给八大落地策略——产品命名、分类页优化、评论语义挖掘、语义内链矩阵等,帮你用语义相似度压住商品页之间的关键词蚕食,让搜索引擎更准确地理解每个页面到底在卖什么。
你在产品页面上堆了一堆关键词,内链布局也花了不少心思,甚至TDK都逐页手工打磨过——但排名就是上不去。反观竞争对手,页面看起来平平无奇,关键词密度可能还不如你,却牢牢占据搜索结果首页。
问题出在哪?很可能出在一个你还没真正重视的技术维度——余弦相似度(Cosine Similarity)。
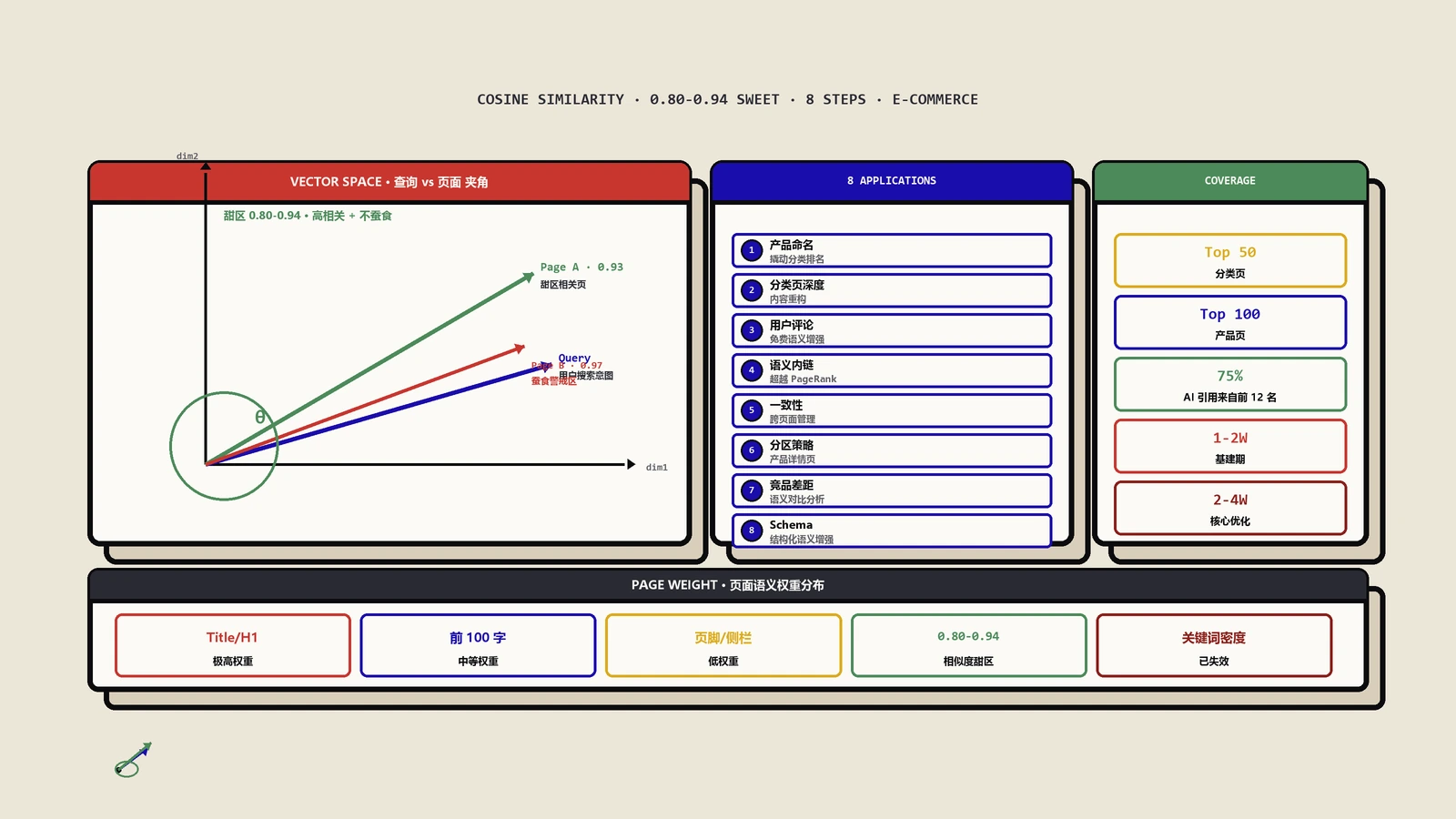
余弦相似度是一种通过计算两个向量之间夹角来衡量文本语义相似程度的数学方法。 它不关心两段文字有多少完全相同的词,而是把文本转化为高维空间中的向量,测量这两个向量的方向是否一致。方向越一致(夹角越小),语义越接近,余弦值越趋近于1;方向越偏离,语义越远,值越趋近于0。
在Google的BERT、MUM等模型以及ChatGPT Search、Perplexity等AI搜索引擎的底层架构中,余弦相似度是判断"你的内容是否真正回答了用户问题"的核心度量指标之一。掌握这个概念并将其落地到电商SEO实操中,是从"关键词堆砌"跨越到"语义优化"的分水岭。
搜索引擎如何"读懂"你的页面:从关键词匹配到语义向量
向量嵌入:文本变数字的底层技术
向量嵌入(Embeddings)是将自然语言文本转换为数字向量的技术,是现代搜索引擎和大语言模型理解内容的基石。 搜索引擎在处理你的网页时,并不是像人一样逐字阅读,而是通过深度学习模型将整段文本编码为一个包含数百甚至数千个维度的向量——可以简单理解为高维空间中的一个"坐标点"。
举个具象化的例子来说明:
- "男士户外登山靴"被编码后的向量可能是[0.82, 0.15, 0.93, 0.41, ...]
- "户外徒步鞋男款防水"的向量可能是[0.79, 0.18, 0.91, 0.38, ...]
- "女士真丝晚礼服"的向量可能是[0.12, 0.88, 0.05, 0.72, ...]
前两个向量的方向高度一致,余弦相似度接近1,搜索引擎据此判断它们在讨论同一个话题。第三个向量指向完全不同的方向,余弦相似度接近0,属于毫不相关的内容。
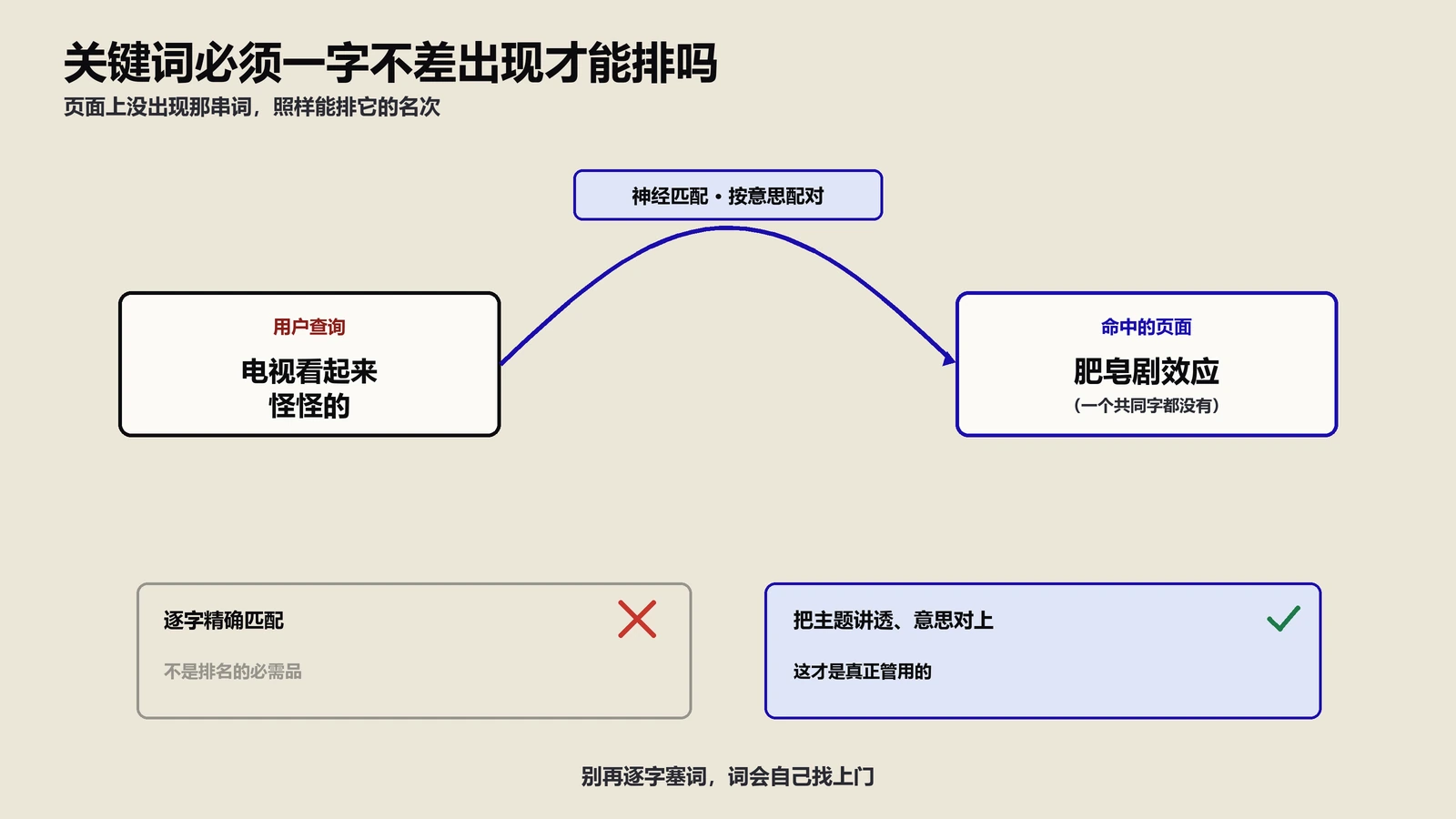
这里需要特别理解的一个关键点是:Google已经不再简单计算你的页面出现了多少次"登山靴"这个关键词。它在计算的是你整个页面内容的语义向量与用户查询语义向量之间的余弦距离。 这意味着即使你的页面一次都没出现"登山靴"这三个字,只要整体内容在语义空间中与"登山靴"的查询向量足够接近,你依然有排名机会。
向量维度与语义颗粒度的关系
很多SEO从业者对向量嵌入的理解停留在"文字变数字"这个表层概念上,但实际上向量的维度数量直接决定了语义表达的精细程度。Google目前使用的嵌入模型维度通常在768维到1024维之间,这意味着每段文本被映射到一个768维或1024维的空间里。
维度越高,模型能捕捉的语义细节就越丰富。比如在低维空间中,"登山靴"和"徒步鞋"可能几乎重叠,但在高维空间中,模型能够区分"登山靴更强调防护性和支撑性"而"徒步鞋更强调轻量化和灵活性"这种细微的语义差异。
这对SEO的实操启示是:你的产品描述不能只停留在品类词层面,还需要深入到具体属性、使用场景、材质工艺等细分维度,才能在高维向量空间中精准定位到目标查询。
余弦相似度的数学原理与SEO含义
余弦相似度的计算公式是:
相似度 = (A·B) / (|A| × |B|)
其中A·B是两个向量的点积,|A|和|B|分别是向量的模。你不需要手动去算这个公式,但需要深刻理解它的含义:
| 余弦相似度值 | 语义含义 | 对SEO的指导意义 |
|---|---|---|
| 0.95-1.0 | 语义几乎完全一致 | 警惕内容重复或抄袭问题 |
| 0.80-0.94 | 高度语义相关 | 理想的页面与查询匹配状态 |
| 0.60-0.79 | 中等语义相关 | 存在明显的优化提升空间 |
| 0.30-0.59 | 弱语义相关 | 内容方向可能偏离目标查询 |
| 0-0.29 | 几乎无关 | 页面与目标查询没有语义关联 |
值得注意的是,余弦相似度的阈值并不是固定的。不同的查询类型、不同的行业领域,Google对"高度相关"的阈值判断可能不同。信息型查询("什么是登山靴")对语义匹配的宽容度通常比交易型查询("买男士登山靴")更高。
为什么关键词密度已经失效
传统的关键词密度优化建立在一个过时的假设之上:重复使用关键词能提高页面与查询的相关性。但在向量嵌入的世界里,这个假设不成立。
原因很简单:反复堆砌同一个关键词并不会改变你的页面向量的方向。 向量嵌入模型在编码时会对词频做归一化处理,也就是说"登山靴"出现3次和出现30次,对最终的页面向量方向影响极小。更糟糕的是,过度堆砌一个词还会稀释其他语义信号的贡献,导致页面向量在某些维度上出现偏斜,反而降低与目标查询的余弦相似度。
真正能提升余弦相似度的做法是:使用与目标查询语义相关的丰富多样的词汇和表达方式。 比如围绕"男士登山靴"这个目标查询,你的页面应该自然地覆盖"防水透气""Vibram大底""中帮设计""崎岖地形""Gore-Tex面料""户外徒步""脚踝支撑""防滑耐磨"等语义相关术语,而不是把"男士登山靴"重复20遍。
如果你想更深入了解从关键词频率分析到语义相关性评估的演进过程,建议阅读TF-IDF与SEO的关系这篇文章,它详细解释了TF-IDF作为关键词时代核心分析方法的技术原理,以及为什么在语义时代它正在被向量嵌入和余弦相似度所补充甚至替代。
余弦相似度在电商SEO中的8大实战应用
理解了底层原理,接下来看余弦相似度如何在电商网站的各个优化环节中具体发挥作用。
应用一:产品命名——撬动分类页排名的语义杠杆
这是余弦相似度在电商SEO中最被低估也最强大的杠杆效应:优化每个产品详情页(PDP)的语义相关性,会直接拉升所属分类页(PLP)的整体排名。
底层逻辑是这样的:分类页上展示的是一组产品,搜索引擎会将这组产品的标题、描述、属性等文本信息聚合起来,生成分类页的"综合语义向量"。如果每个产品的命名都与分类页的核心查询语义一致,分类页的综合向量就会更精准地指向目标查询方向。
用一个对比表格来说明:
| 产品命名方式 | 对分类页语义向量的影响 | 余弦相似度效果 |
|---|---|---|
| "XR-500" | 零语义贡献,纯型号编码 | 拉低分类页与"男士登山靴"的相似度 |
| "男士登山靴XR-500" | 直接贡献核心语义 | 显著提升分类页与核心查询的相似度 |
| "男士防水登山靴XR-500——适合崎岖山路的中帮徒步鞋" | 强语义贡献+长尾覆盖 | 大幅提升相似度,同时命中多个长尾查询 |
六步实操落地方案:
第一步:建立品类命名公式。 统一格式为"[性别/适用人群]+[核心品类词]+[核心差异化属性]+[型号/系列名]"。例如"男士防水登山靴K2-Pro"。
第二步:在产品标题中必须包含分类页的核心关键词。 如果分类页的目标查询是"男士登山靴",那么该分类下每个产品的标题都应包含"男士登山靴"或其紧密语义变体(如"男士徒步靴""男款登山鞋")。
第三步:产品描述前100字内集中使用语义相关术语。 搜索引擎对页面开头的内容赋予更高的权重。在描述的前100字里,密集但自然地使用"防水""透气""耐磨""户外""崎岖地形""脚踝支撑"等与核心查询高度相关的术语。
第四步:产品属性字段使用行业标准术语。 不要用自创的"超级防滑3.0技术"这类营销话术作为属性值,而应使用"Vibram橡胶外底""Gore-Tex防水膜""EVA中底"等行业通用术语——因为用户在搜索时使用的就是这些标准术语。
第五步:为产品标题创建语义变体。 在Meta Title、H1标签、面包屑导航中使用同一查询的不同语义表达,比如H1用"男士防水登山靴XR-500",面包屑用"男士户外徒步鞋",这样能覆盖更多的语义维度。
第六步:批量审计现有产品命名。 导出全站产品标题数据,检查有多少产品标题只包含纯型号或品牌名而缺少品类语义信号。优先修正这些"语义空白"产品。
应用二:分类页内容深度重构
很多电商网站的分类页只有一个筛选器和产品网格,可索引的文本内容几乎为零。从余弦相似度的视角来看,这是一场灾难——搜索引擎无法从纯产品列表中提取到足够的语义信号来准确计算与查询的向量距离。
高排名电商分类页的共同特征是拥有丰富的可索引文本内容。 保哥审计过大量排名靠前的电商分类页,总结出以下内容模块框架:
模块一:分类介绍段落(300-500字)。 在产品列表上方或下方放置3-5段介绍文字,自然融入核心关键词及其语义变体。比如"男士登山靴"分类页可以包含"如何根据地形选择登山靴""登山靴与徒步鞋的区别""常见登山靴材质对比"等内容。
模块二:选购指南或FAQ。 直接在分类页嵌入3-5个常见问题,如"男士登山靴怎么选尺码""什么材质的登山靴最防水""新手适合什么类型的登山靴"。这些问答内容与用户搜索查询的语义距离极近,能大幅提升分类页的余弦相似度。
模块三:使用场景描述。 描述产品适用的具体场景:"适合5000米以下中低海拔徒步""适合多日重装穿越""适合湿滑岩石路面日常轻徒步"等。场景描述能引入大量长尾语义信号。
模块四:品牌/材质/功能的筛选维度说明。 为每个筛选维度(品牌、价格区间、功能特性等)提供1-2句简短的文字说明,让搜索引擎理解筛选器背后的语义含义。
关于分类页筛选器的更多SEO优化细节,电商网站产品分类页的过滤器如何进行SEO这篇文章有非常系统的实操指导,涵盖了URL处理、索引控制和内容优化等多个维度。
应用三:用户评论——免费的语义增强引擎
用户评论是电商SEO中最被忽视的余弦相似度提升来源。
当真实买家在评论中写下"买来爬黄山穿的,防水效果很好,下雨天走了两个小时脚完全没湿""鞋底抓地力不错,碎石路上也很稳"这类内容时,他们实际上在用最自然的用户语言为你的页面注入大量语义信号。而这些自然语言表达与搜索查询之间的语义距离,往往比精心撰写的营销文案更近——因为搜索者和评论者使用的是同一套日常词汇体系。
但大量电商网站犯了一个严重的技术错误:评论区使用JavaScript异步加载,或者只展示前5条评论,其余全部隐藏在"查看更多"按钮后面。 这意味着搜索引擎在抓取你的页面时,根本看不到这些宝贵的评论内容,你白白浪费了最有价值的语义资产。
七步评论语义优化方案:
第一步:确保至少前20-30条评论以服务端渲染(SSR)的方式直接输出在HTML源码中。 不依赖JavaScript渲染,让Googlebot能直接抓取。
第二步:实施Review Schema结构化数据。 为每条评论标注评分、作者、日期等结构化信息,帮助搜索引擎精确理解评论内容的性质。
第三步:在评论收集环节设计引导性问题。 不要只问"满意度如何",而是引导用户描述具体的使用场景,比如"您在什么场景下使用这款产品?""哪个功能最让您满意?"这样收集到的评论天然具备更高的语义密度。
第四步:创建"精选评论"板块。 人工挑选语义最丰富、最具代表性的5-10条评论放在页面显眼位置,确保搜索引擎优先抓取这些高质量语义内容。
第五步:评论分类标签化。 将评论按"防水性能""舒适度""耐久性""尺码准确性"等维度打标签分类展示,这本身就为页面添加了结构化的语义信号。
第六步:回复评论时融入语义关键词。 品牌官方回复评论时,自然地提及产品的核心属性和品类词,比如"感谢您对我们这款男士防水登山靴的认可,Gore-Tex面料确实在防水透气方面表现出色"。
第七步:定期监控评论内容中的新兴语义信号。 用户评论中可能出现你没有预料到的搜索词汇,比如某段时间大量用户提到"轻量化",这可能意味着"轻量化登山靴"是一个新兴的搜索趋势,你应该在产品描述中及时覆盖。
应用四:语义内链矩阵——超越PageRank的链接策略
传统的内部链接策略聚焦于PageRank权重传递和锚文本关键词优化。但从余弦相似度的视角来看,内部链接还承担着一个更深层的功能:构建页面之间的语义关联图谱。
当搜索引擎发现你的"男士登山靴"分类页链接到了"登山袜推荐""登山杖选购""户外背包推荐""山地徒步路线"等页面时,它不仅仅是在计算链接权重的流向——它在构建一个以"户外徒步装备"为核心主题的语义集群(Topic Cluster)。在这个语义集群中,每个页面都在为集群的核心主题贡献语义信号,而核心主题页面(Pillar Page)的向量则因为这些语义关联的存在而变得更加精准和权威。
语义内链矩阵的构建框架:
| 核心页面(Pillar) | 强语义关联内链(必须有) | 中等语义关联内链(建议有) | 弱语义关联内链(视情况) |
|---|---|---|---|
| 男士登山靴分类页 | 登山靴保养指南、登山鞋垫推荐、登山靴尺码对照表 | 户外徒步路线推荐、登山装备清单、高海拔徒步注意事项 | 户外服装搭配、运动营养补充 |
| 男士跑步鞋分类页 | 跑步袜推荐、跑鞋缓震技术对比、跑鞋寿命判断 | 马拉松训练计划、跑步损伤预防、跑步配速表 | 运动手表推荐、运动饮料对比 |
内链布局的三条原则:
原则一:强语义关联内链放在页面主体内容区域。 在正文中以自然的上下文推荐方式嵌入,而不是扔在侧栏或底部的"相关推荐"区块里。
原则二:锚文本要语义多样化。 不要所有指向"登山靴保养指南"的锚文本都用"登山靴保养",可以交替使用"如何保养你的登山靴""延长登山靴使用寿命的方法""登山靴日常护理技巧"等语义变体。
原则三:定期用数据验证语义集群的效果。 在Google Search Console中观察核心页面的查询报告,看是否有更多的语义相关查询开始匹配到你的核心页面。
应用五:跨页面语义一致性管理
余弦相似度不是单个页面的孤立指标。搜索引擎会评估你整个网站在特定主题上的语义一致性——即你的产品页、分类页、博客文章、FAQ页面在讨论同一个话题时,是否使用了一致的核心术语和语义框架。
一个常见的反面案例:产品页标题用的是"登山靴",分类页面包屑写的是"徒步鞋",博客文章标题用的是"户外鞋",FAQ页面又变成了"爬山鞋"。虽然这些词在日常语境中意思相近,但在高维向量空间中它们的向量方向存在细微差异。当整个网站的术语使用混乱时,你的主题集群(Topic Cluster)的语义凝聚力就会被显著稀释。
建立全站语义术语表的四步方法:
第一步:确定每个品类的"主术语"。 基于搜索量和用户习惯,为每个品类选定一个主术语。比如确定用"登山靴"而非"徒步鞋"作为核心品类词。
第二步:列出每个主术语的"同义变体"和"语义扩展词"。 "登山靴"的同义变体包括"徒步靴""户外靴",语义扩展词包括"防水""中帮""Vibram大底"等。明确规定主术语出现频率最高,同义变体按比例自然使用。
第三步:将术语表下发到所有内容生产环节。 产品编辑、文案撰写、客服回复模板、用户评论引导问题等所有涉及内容产出的环节,都要按照术语表执行。
第四步:每季度审计一次全站术语使用情况。 用爬虫工具抓取全站页面,统计各品类核心术语的使用频率和分布情况,发现并修正偏差。
你可以使用TF-IDF分析器来对比你的页面与排名靠前的竞品页面之间的关键词权重差异,精准定位你的语义覆盖盲区。
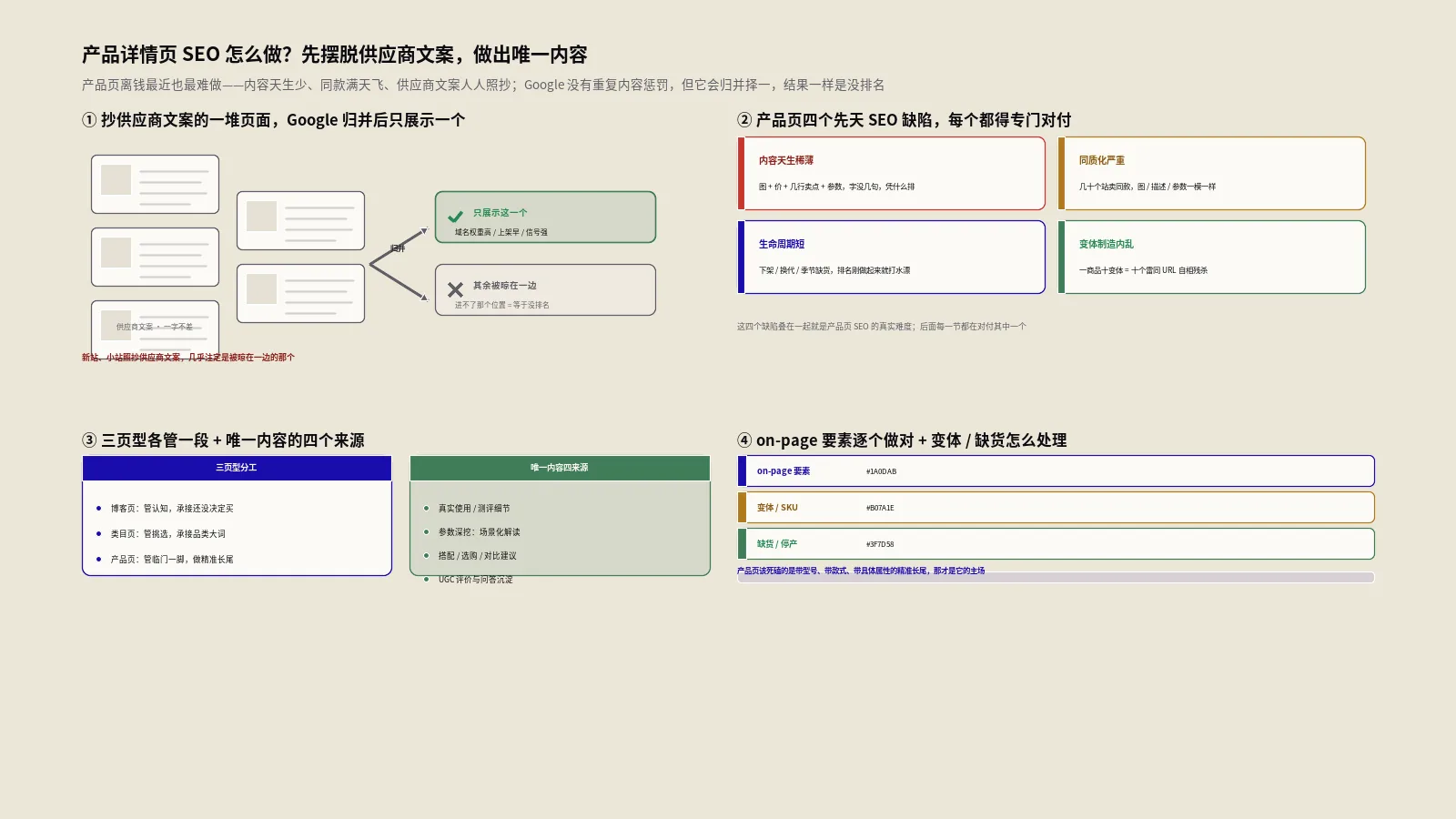
应用六:产品详情页的语义分区策略
一个常被忽略的技术细节是:搜索引擎的嵌入模型在处理长文本时,通常不是一次性编码整个页面,而是分段编码后再聚合。这意味着页面不同区域的内容对最终向量的贡献权重是不同的。
根据保哥的测试观察和行业共识,电商产品页面的语义权重分布大致如下:
| 页面区域 | 语义权重(估算) | 优化重点 |
|---|---|---|
| Title标签 | 极高 | 必须包含核心品类词+核心差异属性 |
| H1标题 | 极高 | 与Title语义互补,避免完全重复 |
| 产品描述前100字 | 高 | 集中使用语义相关术语 |
| 产品属性/规格表 | 中高 | 使用行业标准术语 |
| 产品描述中后段 | 中 | 覆盖长尾语义和使用场景 |
| 用户评论区 | 中 | 确保可索引,引导高质量评论 |
| 面包屑导航 | 中低 | 使用品类语义词 |
| 页脚和侧栏 | 低 | 不要在此区域堆砌关键词 |
实操建议: 将最重要的语义信号集中在Title、H1和产品描述的前100字中。不要把核心语义信息埋在页面底部或折叠区域里。
应用七:竞品语义差距分析——最低成本的排名提升方法
竞品语义差距分析是实操中见效最快的余弦相似度优化手段。方法很简单:找出排名前三的竞品页面覆盖了哪些你没有覆盖的语义信号,然后补上去。
五步竞品语义差距分析流程:
第一步:确定目标查询和对标竞品。 选择你想排名的核心查询,找到该查询下排名前三的竞品URL。
第二步:提取竞品页面的核心语义术语。 用NLP工具(如Surfer SEO、Clearscope,或自行使用Python的TF-IDF库)提取竞品页面中出现频率最高、TF-IDF值最突出的术语列表。
第三步:对比你的页面与竞品的语义差距。 列出竞品使用了但你没有使用的术语。这些就是你的"语义盲区"。
第四步:自然地将缺失的语义术语融入你的内容。 注意是"自然融入",不是机械插入。比如竞品页面普遍提到了"Vibram大底"和"脚踝支撑",而你的页面没有,那就在产品描述或选购指南中自然地讨论这些属性。
第五步:使用余弦相似度内容语义分析器验证优化前后的语义匹配度变化。 量化评估你的优化是否真正拉近了页面向量与目标查询向量之间的距离。
应用八:结构化数据的语义增强作用
Schema结构化数据在余弦相似度优化中扮演着一个独特的角色:它不是直接改变页面的文本向量,而是帮助搜索引擎更准确地识别页面中的实体和属性,从而更精准地计算语义匹配度。
举个例子:当你在产品页面的Product Schema中标注了"brand""material""color""category"等属性时,搜索引擎能够明确知道"Gore-Tex"是材质属性而非品牌名,"男士"是目标人群而非产品颜色。这种精确的实体识别能力会让搜索引擎在计算余弦相似度时更加准确。
电商产品页必备的Schema属性:
- Product Schema:name、description、brand、sku、gtin、material、color、size
- Offer Schema:price、priceCurrency、availability、priceValidUntil
- AggregateRating Schema:ratingValue、reviewCount、bestRating
- Review Schema:author、datePublished、reviewBody、reviewRating
- BreadcrumbList Schema:完整的品类层级路径
关于实体SEO和结构化数据如何帮助搜索引擎构建对你网站内容的语义理解,实体SEO指南这篇文章有非常系统和深入的解析,值得反复研读。
余弦相似度的测量方法:从代码到工具
方法一:Python脚本精确计算
对于有技术能力的SEO团队,推荐使用Python的sentence-transformers库进行精确的余弦相似度计算:
from sentence_transformers import SentenceTransformer, util
# 加载预训练模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 你的页面内容(建议取前500字作为样本)
page_content = "男士防水登山靴,采用Gore-Tex防水透气面料,Vibram橡胶大底..."
# 目标查询
target_query = "男士登山靴"
# 计算嵌入向量
embeddings = model.encode([page_content, target_query])
# 计算余弦相似度
similarity = util.cos_sim(embeddings[0], embeddings[1])
print(f"余弦相似度: {similarity.item():.4f}")进阶用法——批量对比多个页面与同一查询的相似度:
import pandas as pd
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
target_query = "男士登山靴"
query_embedding = model.encode(target_query)
pages = {
"你的产品页": "男士防水登山靴XR-500,采用Gore-Tex...",
"竞品A产品页": "户外徒步鞋男款,Vibram橡胶外底...",
"竞品B产品页": "男士户外登山靴,中帮设计...",
}
results = []
for name, content in pages.items():
page_embedding = model.encode(content)
sim = util.cos_sim(page_embedding, query_embedding).item()
results.append({"页面": name, "余弦相似度": round(sim, 4)})
df = pd.DataFrame(results).sort_values("余弦相似度", ascending=False)
print(df.to_string(index=False))这个脚本能让你量化地看到自己的页面与竞品页面在语义匹配度上的差距,非常直观。
方法二:免费工具辅助分析
不会写代码也完全没问题。以下工具可以帮你评估内容的语义相关性:
Google NLP API(免费额度): 可以分析页面中的实体识别结果和显著性得分(Salience Score),虽然不是直接输出余弦相似度,但能帮你判断页面的核心语义主题是否与目标查询一致。
Surfer SEO的Content Editor: 提供页面与目标查询的语义覆盖度评分,本质上就是在用NLP技术评估语义相关性。
Clearscope: 基于NLP分析给出内容优化建议和语义评分,特别擅长发现语义缺口。
Google Search Console的查询报告: 虽然不能直接看到余弦相似度数值,但你可以通过观察页面匹配到哪些查询、CTR和排名表现,间接判断语义匹配的效果。如果你的页面开始匹配到越来越多的语义相关查询(而不只是完全匹配的关键词查询),说明你的语义优化正在生效。
方法三:竞品对标法
最简单也最实用的方法:
- 用Screaming Frog或类似工具抓取排名前3的竞品页面全文
- 用TF-IDF分析工具提取竞品页面的高权重术语
- 对比找出你的页面缺失的语义术语
- 自然融入后,用Google Search Console追踪排名变化
- 每两周重复一次,持续缩小语义差距
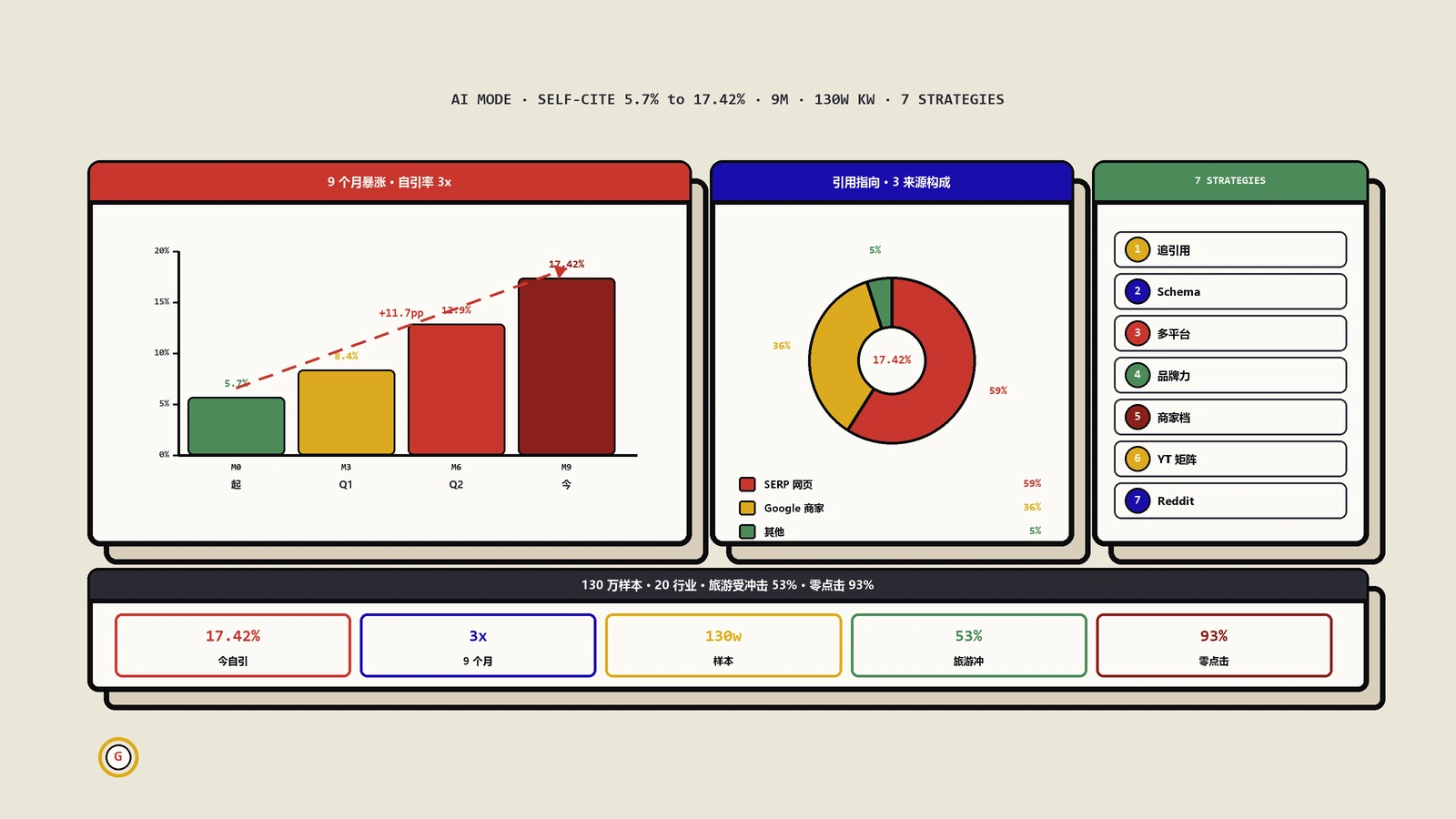
余弦相似度在AI搜索时代的战略地位
AI搜索引擎的引用逻辑
随着Google AI Overviews、ChatGPT Search、Perplexity等AI搜索引擎的普及,余弦相似度的重要性被进一步放大。
AI搜索引擎在生成回答时,需要从大量候选页面中选择引用来源。选择的核心标准之一就是:候选页面的内容向量与AI生成回答文本的内容向量之间的余弦相似度。 研究数据显示,Google AI Overview中引用的链接有约75%来自自然搜索前12名的结果,而这些被引用页面与AI生成回答之间存在显著的语义相似性相关。
换个角度说:你的页面内容与AI可能生成的"标准答案"越接近,被AI引用为信息来源的概率就越高。
对电商SEO的四大战略启示
启示一:产品页面不只是给消费者看的,更要能被AI系统准确理解和引用。 这意味着产品描述不能只是感性的营销文案,还必须包含精确、结构化、信息密度高的内容。
启示二:结构化数据的战略价值升级。 Schema标记帮助AI系统精确识别产品实体和属性关系,在AI搜索引擎的引用决策中发挥关键作用。
启示三:FAQ内容成为AI搜索的核心入口。 用户向AI提问的格式("什么是最好的男士登山靴""登山靴怎么选")与FAQ内容的格式天然高度匹配。围绕用户可能向AI提出的问题来组织FAQ内容,能大幅提升被AI引用的概率。
启示四:信息密度比内容长度更重要。 AI搜索引擎偏好信息密度高、结构清晰、能直接回答问题的内容。一段200字的精准回答,可能比2000字的空泛描述更容易被AI引用。
关于GEO(生成式搜索引擎优化)的完整实施策略,建议深入阅读GEO实施策略终极指南,它涵盖了结构化数据、内容组织、权威信号等多个维度的系统性优化方法。
规模化实施路线图:从单页面到全站语义网络
对于拥有几千甚至几万SKU的电商网站,逐页面手工优化余弦相似度是不现实的。以下是保哥建议的规模化实施路径:
第一阶段:基础设施搭建(1-2周)
任务一:建立标准化产品数据模板。 确保每个产品的标题、描述、属性字段都包含统一的语义元素。模板公式:[品类词]+[核心差异属性]+[型号]。描述模板:前100字包含品类词+2-3个核心属性词+1个使用场景描述。
任务二:创建全站语义术语表。 为每个一级品类和二级品类确定主术语、同义变体和语义扩展词。
任务三:技术审计评论索引状态。 检查全站产品评论是否被搜索引擎可索引,修复JavaScript延迟加载导致的评论不可见问题。
第二阶段:核心页面优化(2-4周)
任务四:优化Top 50分类页的内容深度。 为流量最大的50个分类页创建300-500字的介绍内容,包含核心查询的语义变体和常见FAQ。
任务五:优化Top 100产品页的产品命名和描述。 按照语义命名公式重新优化排名潜力最大的100个产品页。
任务六:部署结构化数据。 为所有产品页添加完整的Product + Offer + Review Schema。
第三阶段:系统化扩展(持续迭代)
任务七:构建语义内链矩阵。 基于品类之间的语义关系,建立自动化或半自动化的内部链接推荐系统。
任务八:持续监测和迭代。 每月使用GSC查询报告追踪目标查询的排名变化和匹配查询的变化趋势。每季度更新一次语义术语表,纳入新兴的搜索趋势术语。
任务九:建立语义优化的量化评估体系。 对核心产品页定期进行余弦相似度测试,建立与竞品的语义差距对比数据库,将语义匹配度作为内容质量的KPI之一。
进阶避坑指南:余弦相似度优化中的常见误区
误区一:追求极高的余弦相似度
余弦相似度不是越高越好。当你的页面与查询的相似度达到0.95以上时,搜索引擎可能会怀疑你的内容是为了迎合算法而机械生产的,或者存在内容抄袭的嫌疑。理想的目标范围是0.80-0.94,这意味着高度语义相关但仍保持内容的独特性和原创价值。
误区二:忽略搜索意图类型
不同类型的搜索意图,对应的最佳余弦相似度优化策略是不同的:
| 搜索意图类型 | 示例查询 | 优化策略差异 |
|---|---|---|
| 信息型 | "登山靴怎么选" | 内容要全面、多角度覆盖,语义宽度比深度更重要 |
| 商业调研型 | "男士登山靴推荐" | 需要对比、评价类语义信号 |
| 交易型 | "买男士登山靴" | 产品属性、价格、购买便利性等语义信号优先 |
| 导航型 | "XX品牌登山靴官网" | 品牌实体和官方身份信号最重要 |
误区三:只优化文本忽略页面结构
余弦相似度计算不只看纯文本内容。页面的HTML结构(标题层级、列表格式、表格等)也会影响嵌入模型对内容的理解。一个有清晰H2/H3层级结构、有序列表和对比表格的页面,比一大段无结构的纯文本在语义表达上更精准。
误区四:忽视负面语义信号
页面上不相关的内容会引入负面语义信号,拉偏页面向量的方向。比如在"男士登山靴"产品页面的侧栏或底部推荐区展示大量"女士连衣裙""儿童玩具"等完全不相关的产品,会稀释页面的语义聚焦度。确保页面上的所有内容模块(包括推荐区、广告区)都与页面的核心主题语义相关。
误区五:将余弦相似度当作唯一排名因素
余弦相似度解决的是"语义相关性"这一个维度的问题。但搜索排名是"相关性×权威性×用户体验"的综合函数。一个余弦相似度极高但域名权威度低、外链质量差、Core Web Vitals不达标的页面,依然可能排在语义匹配度较低但权威度更高的页面后面。余弦相似度是排名优化的必要条件,但不是充分条件。
常见问题
余弦相似度和TF-IDF有什么区别?
TF-IDF是一种基于词频统计的方法,衡量的是某个词在特定文档中相对于整个文档集合的重要程度。余弦相似度则基于向量嵌入技术,衡量的是两段文本在整体语义层面的接近程度,它能捕捉到同义词、上下文关系等TF-IDF无法处理的语义信息。两者不矛盾,TF-IDF可以帮你发现页面中缺失的重要术语,而余弦相似度帮你评估整体的语义覆盖是否到位。可以说TF-IDF是关键词时代的核心分析方法,余弦相似度则是语义搜索时代的核心度量指标。
余弦相似度高就一定能获得好排名吗?
不一定。余弦相似度高意味着你的内容与搜索查询在语义上高度匹配,但排名还受到域名权威度、外链质量、用户体验指标(Core Web Vitals)、E-E-A-T信号、内容新鲜度等多个因素的综合影响。余弦相似度解决的是"相关性"问题,但最终排名是"相关性×权威性×体验"三者的乘积效应。一个语义匹配度极高但域名权威不足的新站页面,短期内可能仍然排在语义匹配度一般但权威度很高的老牌网站后面。
电商网站如何大规模优化余弦相似度?
关键在于建立系统化的模板和标准化流程,而非逐页面手动调整。具体包括:统一全站产品命名规范(品类词+属性+型号),为每个分类页创建语义丰富的介绍内容模板,确保用户评论对搜索引擎可索引并添加Review Schema,构建基于品类语义关系的自动化内部链接系统。对于SKU数量特别大的站点,可以使用NLP工具批量分析现有页面与目标查询之间的语义差距,按照"差距最大+流量潜力最高"的优先级排序进行优化。
产品评论真的能提升页面的余弦相似度吗?
能,而且效果往往超出预期。用户评论中的自然语言表达——包括使用场景描述、产品感受、与竞品的对比评价等——为页面注入了搜索引擎可直接提取的高质量语义信号。这些信号之所以特别有价值,是因为评论者和搜索者使用的是同一套日常词汇体系,它们与搜索查询的语义距离往往比经过修饰的营销文案更近。前提条件是确保评论内容对搜索引擎可见——不要全部用JavaScript异步加载或隐藏在"查看更多"按钮后面。
余弦相似度对AI搜索(GEO)有什么具体影响?
影响非常直接。AI搜索引擎在选择引用来源时,内容与AI生成回答之间的语义相似度是核心参考指标之一。研究表明被AI Overview引用的页面与AI回答文本之间普遍存在高余弦相似度相关性。这意味着在GEO时代,你的内容需要"预判"AI可能生成的回答风格和内容框架,围绕用户可能向AI提出的问题来组织内容,确保答案直接、结构化、信息密度高。FAQ格式的内容在这方面有天然的优势。
如何判断我的页面余弦相似度是否需要优化?
最简单的判断方法:在Google Search Console的"效果"报告中查看你的页面匹配了哪些查询。如果你的"男士登山靴"产品页主要匹配的是品牌词和精确匹配词(如"XR-500登山靴"),而几乎没有匹配到语义相关的非品牌查询(如"防水徒步鞋男款""户外登山鞋推荐"),说明你的页面语义信号不够丰富,余弦相似度有明显的优化空间。另一个判断信号是:如果竞品页面在你的目标查询上获得的展示次数远高于你,且竞品页面的内容覆盖了更多的语义相关术语,那么语义差距就是你当前最需要弥补的短板。
普通SEO从业者如何入门余弦相似度优化?
不需要掌握数学公式或会写代码。最实用的入门路径是:用竞品分析思维找出排名前三的页面使用了哪些你没有的语义相关术语,然后自然融入到你的内容中。同时善用NLP类SEO工具(如Surfer SEO、Clearscope)获取语义优化建议。如果有技术能力,可以用Python的sentence-transformers库批量计算页面与目标查询的余弦相似度分数,建立量化的优化基准线。最重要的思维转变是:停止纠结关键词密度,开始关注语义覆盖的广度和深度。
权威参考资料
本文标题:《电商SEO语义优化实战:余弦相似度压商品蚕食八大应用》
本文链接:https://zhangwenbao.com/cosine-similarity-ecommerce-seo-semantic-optimization.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0





写得很干,特别是关于分类页那套语义矩阵的逻辑,深感认同!我们做跨境项目时也是顺着这个思路走。不过后来发现,当产出量级上去后,用相似度作为单一 KPI 容易跑偏(比如 LLM 会自己编造不存在的产品特性来迎合高分)。我们最近在管线里加了一道防线:把核心卖点(KSP)强制拆解成三元组关系,在入库前做一轮无大模型参与的‘确定性’事实校验(Fact-grounding)。只有通过了三元组结构对齐的内容才算及格。
文章里确实更侧重"怎么把相似度用起来",对分数本身的可信度边界没有展开讲。你说的这个问题我们在实际项目里也遇到过,特别是用LLM批量生成产品描述的时候,模型为了语义对齐会"创造性地补全"一些根本不存在的参数或卖点,跑出来的相似度好看,但内容经不起验证。
KSP拆解成三元组做Fact-grounding这个思路很扎实,相当于在语义打分之前加了一层结构化的"硬约束",把内容的事实性和语义相关性拆成两个独立维度来评估,而不是全押在cosine similarity一个指标上。