Critic代理评分器怎么用?不调用AI引擎就预测9种GEO策略的可见性提升
本文目录
- Critic代理评分器到底解决什么问题?
- 它背后的Surrogate Critic是什么来头?
- 工具提取哪些内容特征来做预测?
- 每种策略的效果是怎么预测出来的?
- 九种策略的预测逻辑还有哪些值得注意的?
- 置信度和推荐等级该怎么理解?
- 拿一个出海SaaS落地页预测会怎样?
- 为什么代理预测能省这么多成本?
- 预测出的优先级,怎么转成改稿和测试的双清单?
- 这工具和真实引擎测试是什么关系?
- 代理Critic和完整的AgenticGEO系统差在哪?
- 这工具怎么和别的GEO工具串起来用?
- 六步用好Critic代理评分器的操作教程
- 第1步:粘贴内容
- 第2步:选择要预测的策略
- 第3步:运行预测
- 第4步:看推荐排序
- 第5步:识别高潜力低置信策略
- 第6步:按结论执行与验证
- 这工具适合用在哪些场景?
- 哪些情况下Critic的预测最容易失手?
- 怎么验证Critic自己到底准不准?
- 用之前要注意什么?
- 常见问题解答
- Critic预测和真实测试差多少?
- 置信度低的策略是不是就不能做?
- 它和GEO内容评分器有什么不同?
- 为什么有的策略预测提升那么低?
- 不选策略全跑一遍和只选几个有区别吗?
- 这工具收费吗,有调用次数限制吗?
- Critic推荐的策略,执行顺序重要吗?
- 预测里的基线35分是什么意思?
- 不同AI引擎的预测能通用吗?
- 内容太短能预测吗?
- 预测结果会随内容修改而变化吗?
- 预测结果能直接拿去汇报吗?
- 权威参考资料
摘要:这款Critic代理评分器借鉴了AgenticGEO论文里的Co-Evolving Critic思路,做了一个轻量的代理预测模型。你把内容贴进去,它先抽取13项可量化特征,再针对9种GEO策略逐一预测“如果我对你这篇内容用这一招,可见性大概能涨多少”,同时给出一个置信度,告诉你这条预测它有几分把握。最大的价值是:不用真去调用ChatGPT、Perplexity这些引擎跑测试,就能在动手前先估出哪招值得做、哪招纯属浪费,把试错成本砍下来一大截。
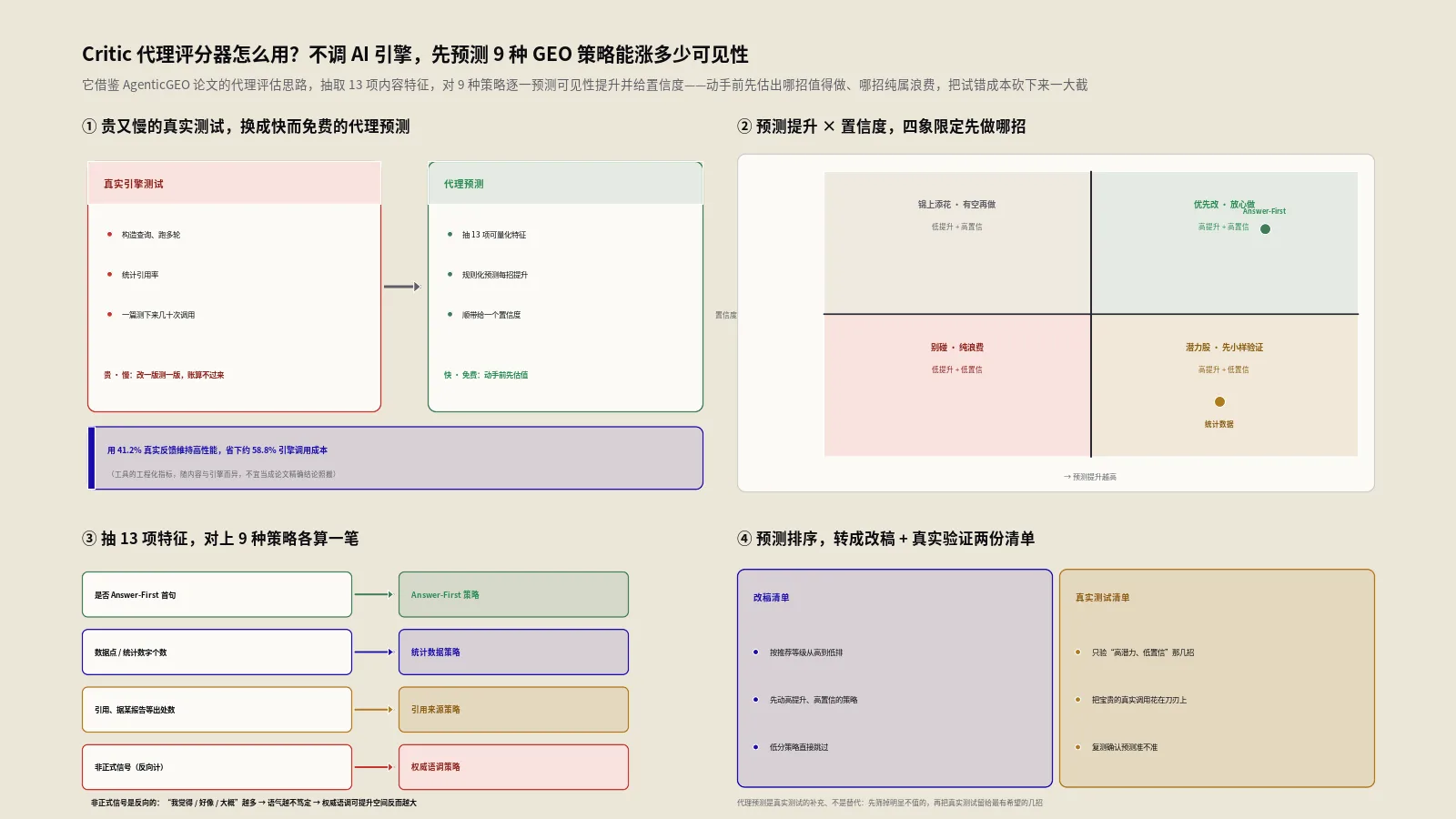
做GEO优化最折磨人的不是不知道有哪些策略,而是改完之后心里没底——这一版到底有没有用?想知道答案,最硬核的办法是真去AI引擎里跑测试,可这事又贵又慢:要构造查询、跑多轮、统计引用率,一篇内容测下来几十次引擎调用就没了,改一版测一版,成本和时间都顶不住。
有没有办法在掏钱跑真实测试之前,先有个靠谱的预估?保哥这次拆的这款Critic代理评分器,干的正是这件事。它把学术界用来降低GEO优化成本的“代理评估”思路做成了一个能直接用的工具。
Critic代理评分器到底解决什么问题?
核心问题就一个字:贵。GEO优化本质是个反复试错的过程——改一版、测一版、看效果、再改。而每次“测一版”如果都靠真实AI引擎,调用成本会迅速堆高,尤其当你有成百上千个页面要优化时,这笔账根本算不过来。
代理评分器的解法是用一个轻量的预测模型,去逼近真实引擎的反馈。它不真去问AI,而是根据内容特征,估算每种策略大概能带来多少可见性提升。预测虽然不如真实测试精确,但它快、它免费,足够你在动手前筛掉那些明显不值得做的策略,把宝贵的真实测试次数留给最有希望的几招。
换句话说,它把“盲目改一通再去测”变成了“先预测、按预测排序、只验证高潜力策略”。试错从撒网变成了精准打击。
它背后的Surrogate Critic是什么来头?
这工具不是凭空造的,它的方法论来自2026年的一篇GEO研究。AgenticGEO: 用于生成式引擎优化的自进化智能体系统 这篇论文提出了一个关键组件:Co-Evolving Critic,一个轻量的代理模型,用来逼近引擎反馈,从而指导策略的选择和精修。
论文点出的痛点和前面说的一模一样:要有效优化这些策略,需要从引擎那里拿到大量交互反馈,而这在现实中代价高得不切实际。Co-Evolving Critic就是为了“缓解交互成本”而生的——用一个代理去近似昂贵的真实反馈,让搜索和规划过程不必每一步都去敲引擎的门。
需要诚实说明的是,这款在线工具是对论文思路的一个工程化简化。论文里的Critic是和主系统协同进化的模型,而工具为了能即时运行,把它落地成了一套固定的规则化预测引擎。工具界面上标注的“用41.2% 的真实反馈保持高性能、节省约58.8% 引擎调用成本”是工具基于这套方法设定的工程化指标,方便你直观理解它在省什么,具体数字会因内容和引擎而异,不宜当成论文的精确结论照搬。
工具提取哪些内容特征来做预测?
预测的第一步是把内容拆成机器能算的特征。工具会抽取13项,它们正好对应着9种策略各自关心的信号。
| 特征 | 含义 | 主要服务于哪种策略预测 |
|---|---|---|
| 词数、句数 | 内容体量 | 整体提升空间估算 |
| 平均句长 | 每句字数 | 流畅度 |
| 是否有Answer-First | 首句含定义句式 | Answer-First |
| 引用数 | 链接、据某报告、according等 | 引用来源 |
| 数据点数 | 带量纲的数字 | 统计数据 |
| 引述数 | 成对引号里的长内容 | 专家引述 |
| 标题数、列表项数 | h2到h4、li标签 | 结构化 |
| 是否有表格、FAQ | table标签、常见问题区块 | 结构化 |
| 正式信号数 | 研究、数据、evidence等 | 权威语调 |
| 非正式信号数 | 我觉得、好像、maybe等 | 权威语调(反向) |
| 是否有Schema | JSON-LD或itemscope | 结构化、技术信号 |
这里有个巧妙的设计:非正式信号是反向的。“我觉得、好像、大概”这类词出现得越多,说明内容语气越不笃定,权威语调的提升空间反而越大——因为有一堆可以替换成笃定表达的地方。Critic正是靠这种特征与策略的对应关系,来判断每招该不该用。
每种策略的效果是怎么预测出来的?
抽完特征,工具对9种策略逐一跑预测。每条预测都从一个35分的基线可见性出发,再根据特征算一个提升量lift加上去,最后夹在0到50之间,加到基线上就是预测的优化后得分。这里挑几个有代表性的逻辑讲讲,你就懂它的脾气了。
Answer-First。如果内容首句没下定义,工具判定提升空间大,给一个35加内容体量的高lift,置信度88;要是已经有Answer-First了,就只给5分的边际lift,置信度反而升到92——因为“已经做了,再做没用”这个判断很确定。
引用来源。工具算一个缺口:理想是至少3个引用,你差几个,lift就按差额乘以10给。引用越接近理想,置信度越高;一个引用都没有时,置信度会降到72,因为从零开始的预测不确定性更大。
统计数据。同样按3个数据点的缺口算,但有个惩罚:如果内容里非正式信号太多(超过2处),lift会被扣5分,因为“我觉得大概”这种语气会削弱数据的权威感,加了数据也救不回来。
权威语调。这条最能体现特征驱动。非正式信号超过2处时,lift直接给18加上信号数乘以3,意思是你有越多不笃定的表达可以替换,权威语调的提升就越大;反过来,如果你已经满是研究、数据这类正式信号,lift只给4,因为没什么可改的了。
结构化。工具先算一个结构分:标题数乘3,加列表项分封顶10,加表格5,加FAQ 5。结构分低于10给22的高lift,10到20给12,20以上只给4。要是没有FAQ,再额外加5——因为补FAQ是结构化里性价比最高的一招。
九种策略的预测逻辑还有哪些值得注意的?
前面讲了几种代表性策略,剩下几种的预测逻辑也各有脾气,一并说清,你才能完整看懂结果表。
专家引述。按理想2段引述算缺口,每缺一段给15分的高lift,是单招里给分最猛的之一。但它的置信度往往偏低,因为从零段引述预测能涨多少本身就不确定。所以专家引述常常是预测高、置信低的典型,最该拿去验证。
流畅度。看平均句长落不落在18到40字的理想区间。落在区间内只给8分,说明已经够好;偏离越远lift越高。这条置信度普遍很高,因为句长是个很确定的指标,算得准。
简化语言。平均句长超过35字才给较高lift,否则只给8。如果内容正式信号很多、专业度高,还会额外加分,因为越专业的内容简化空间越大,读者门槛降得越多。
专业术语。正式信号不足时给15分,说明缺专业度;已经够专业则只给5。这条对B2B、技术类内容尤其值得看,因为这类内容缺术语会显得不够内行。
置信度和推荐等级该怎么理解?
每条预测除了提升量,还带两个判断维度,看懂它们才不会被单一数字带偏。
第一个是置信度,范围50到98,表示Critic对这条预测有几分把握。85以上是高置信,意味着可以直接执行;低于85是中置信,建议执行后再用真实测试验证一下。置信度低不代表预测错,而是说这种情况下代理模型的把握没那么大。
第二个是推荐等级,直接按提升量分档:提升20以上是强烈推荐,10到20是推荐,5到10是可选,5以下就是效果有限、别浪费力气。这一档帮你快速决定做不做。
真正要警惕的是“高提升、低置信”的组合:Critic预测某招能涨很多,但自己也没多大把握。这种策略不是不能做,而是最该拿去做真实测试验证的——预测给了你方向,但赌注押下去之前,值得花一次引擎调用去确认。
拿一个出海SaaS落地页预测会怎样?
保哥拿一家做项目管理SaaS的出海工具站举例。他们有篇主打“best project management software for remote teams”的博客,想冲AI推荐位。把全文贴进Critic,抽出来的特征大致是:词数1200、没有Answer-First、引用1个、数据点2个、引述0段、非正式信号3处(满篇I think、maybe)、有6个列表项和4个标题、没有表格和FAQ、没有Schema。
跑完9种策略,预测结果排序如下。
| 策略 | 预测提升 | 置信度 | 推荐等级 |
|---|---|---|---|
| Answer-First | +46% | 88(高) | 强烈推荐 |
| 专家引述 | +38% | 65(低) | 强烈推荐 |
| 权威语调 | +27% | 82(中) | 强烈推荐 |
| 引用来源 | +20% | 80(中) | 强烈推荐 |
| 专业术语 | +15% | 72(中) | 推荐 |
| 统计数据 | +9% | 78(中) | 可选 |
| 结构化 | +9% | 90(高) | 可选 |
| 流畅度 | +8% | 92(高) | 可选 |
这张表信息量很大。预测提升最高的是Answer-First(+46%),而且置信度高达88——既值得做、Critic又有把握,这是该第一个执行的。专家引述预测 +38%,看着诱人,可置信度只有65,因为这篇一段引述都没有,从零预测不确定性大。它被标成强烈推荐,但更该被拿去做真实验证,而不是闷头就改。
有意思的是权威语调。这篇满是I think、maybe,非正式信号3处,所以工具预测把这些改成笃定表达能涨27%,置信度也不低。这条很容易被人忽略,但Critic一眼揪了出来:你的问题不只是缺东西,还在于语气太虚。
反观统计数据和流畅度,预测提升都只有个位数。这篇已经有了2个数据点、句子也算顺,再在这两项上使劲,回报有限。Critic直接劝你别浪费力气。这家SaaS站照预测顺序先做了Answer-First和权威语调,省下的真实测试次数,全砸在了验证专家引述这条高潜力但没把握的策略上。
为什么代理预测能省这么多成本?
很多人第一反应是:不就估个数吗,能省多少?这事得算笔账。
真实GEO测试的成本来自两头。一头是引擎调用本身,要测一种策略有没有用,得构造多组查询、跑多轮、统计引用率,一种策略一篇内容轻松几十次调用。另一头是迭代次数,GEO是反复试错,改一版测一版,九种策略全靠真实测试筛,调用次数是策略数乘以迭代数,往上滚得飞快。
代理预测把第一道筛选从真实调用换成了免费的规则计算。九种策略里,可能有五六种一眼就被预测判成效果有限或已经做满,这些根本不用花真实调用去测。真实测试只留给那两三种高潜力的,调用次数一下从几十次压到个位数。这就是代理评估能把试错成本砍下一大截的来源——不是预测有多神,而是它帮你避开了大量注定无效的测试。
预测出的优先级,怎么转成改稿和测试的双清单?
预测跑完,怎么把结果变成行动?最实用的办法是拆成两张清单。
第一张是直接改清单,装那些高提升、高置信的策略,比如前面SaaS案例里的Answer-First和权威语调,预测准、把握大,排进本周就改。第二张是先验证清单,装高提升、低置信的,比如那个 +38% 但置信度只有65的专家引述,先安排一次真实AI测试,确认了再挪进直接改清单。
至于预测提升个位数的策略,两张清单都不进,直接搁置。这样团队的精力和测试预算就被精准切成了三块:马上改、先验证、暂时不碰。把这份预测结果再叠到 GEO策略组合热力图的ROI排序 上看,单招预测和组合性价比互相印证,优先级会更稳。
这工具和真实引擎测试是什么关系?
这是用这款工具前必须想清楚的一点:Critic是代理,不是替代。它的定位是省成本,不是免去验证。
代理预测的本质是用规则去近似真实引擎的复杂判断,再准的代理也有偏差。所以正确的工作流是:用Critic把9种策略快速筛一遍,砍掉效果有限的,对高置信的直接执行,对高提升但低置信的,再花真实测试去确认。它帮你把可能要做几十次的真实测试,压缩到只验证最关键的几次。
关于代理评估到底能省多少、又该怎么和真实验证配合,保哥之前专门写过 Critic方法让GEO测试成本大幅下降的原理,那篇偏方法论,讲清了代理为什么能省成本;本文这篇是工具的上手教程,讲清这套方法具体怎么用。两篇配合着看,一个懂原理、一个会操作。
另一篇关于 AgenticGEO碾压14种基线方法的实测数据分析,则把这套自进化系统的底层逻辑讲透了,想深挖代理Critic在完整系统里扮演什么角色,可以接着读那篇。
代理Critic和完整的AgenticGEO系统差在哪?
有人读了AgenticGEO论文会问:这个在线工具和论文里那套自进化系统是一回事吗?不完全是,讲清楚有助于你正确看待预测结果。
论文里的AgenticGEO是一整套自进化框架,用MAP-Elites档案不断演化出多样化的组合策略,Co-Evolving Critic只是其中负责快速估反馈的一个零件,而且它会随着系统运行持续学习、和主系统协同进化。这套东西重,也需要训练。
这款在线工具取的是Critic这个零件的核心思想——用代理逼近昂贵反馈来省成本——但为了能即开即用,把它做成了不需要训练的规则引擎。好处是零门槛、即时出结果,代价是它不会自我进化、预测精度不如论文里那个会学习的版本。理解这层差别,你就知道该把它当一个快速、免费的筛选器,而不是论文级的精密仪器。
这工具怎么和别的GEO工具串起来用?
Critic在GEO工作流里处在“执行前的最后一道闸”,它前面是诊断和决策,后面才是真改。保哥的串法是这样的。
先用 GEO内容评分器 给整篇定个基线分;再用 GEO策略组合热力图 看哪两招组合最划算;锁定候选策略后,用本文这款Critic代理评分器逐一预测效果、排个序,把没把握的拎出来留待验证;最后才动手改。这样一套下来,每一步决策都有数据撑着,不靠拍脑袋。
🤖 工具直达
Critic代理评分器 · 免费在线 · 粘贴内容即出9种策略的预测提升、置信度与推荐等级,不用调用AI引擎:zhangwenbao.com/tools/geo-critic.php
六步用好Critic代理评分器的操作教程
第1步:粘贴内容
把文章内容连HTML标签一起贴进去,至少30个字符。保留标签工具才能检测结构化、Schema这些特征。
第2步:选择要预测的策略
默认会预测全部9种策略。如果你心里已经有几个候选,也可以只勾选关心的那几种,结果更聚焦。
第3步:运行预测
点击预测,工具在服务端抽取13项特征,再对每种策略算出预测提升、置信度和推荐等级。
第4步:看推荐排序
结果按预测提升从高到低排好,强烈推荐的排最前。先扫一眼前几名,心里就有了优先级。
第5步:识别高潜力低置信策略
重点找那些预测提升高、但置信度低于70的策略。工具会专门提示有几个低置信策略,它们就是该花真实测试去验证的对象。
第6步:按结论执行与验证
高置信的直接动手改;低置信的先用真实AI引擎测一次确认效果,再决定改不改。让真实测试只花在刀刃上。
这工具适合用在哪些场景?
实际工作里,这工具主要用在这几类活上。
批量页面的优先级筛选。有几十上百个页面要优化,不可能每个都去跑真实测试。用Critic先把每个页面的高潜力策略筛出来,按预测提升排个总序,资源就能集中到回报最高的页面和策略上。
改稿方案的快速决策。团队对某篇该怎么改有分歧时,把几个方案分别贴进去预测,用数据说话,比开会吵半天高效。
真实测试预算的分配。真实引擎测试有成本,Critic帮你把有限的测试次数分配给最该验证的策略——也就是那些高提升、低置信的,避免把钱花在已经很确定的事情上。
新手的策略入门。不熟悉9种GEO策略的人,用Critic跑几篇就能直观看到不同内容下哪招有效、哪招无效,比啃理论上手快。
优化前后的对照存档。改稿前后各跑一次预测,把两次结果存下来。预测提升的下降幅度,能侧面反映你这一版改到了什么程度,给团队复盘提供一个量化的参照点。
哪些情况下Critic的预测最容易失手?
用久了就会发现,代理预测在某些情况下偏差会变大。提前知道这些坑,你就能在该警惕的时候多留个心眼。
第一种是内容很短或结构残缺。特征抽取依赖足够的文本和标签,几百字以下、或纯文本没标签的内容,算出的句长、结构分都不准,预测自然飘。第二种是混合语言内容。中英文混排会让分词和信号词识别打架,正式信号、非正式信号都可能数错,权威语调这类靠信号词的预测就不靠谱了。
第三种是内容本身质量两极分化。规则引擎擅长判断缺不缺某个信号,但判断不了信号的质量。一篇堆了十个无关链接的内容,引用来源使用度会很高,Critic以为你做够了,其实那些链接毫无价值。遇到这类情况,预测值要打个问号,人工过一眼比什么都强。
怎么验证Critic自己到底准不准?
既然Critic是代理,难免有人担心:它自己准不准,我怎么知道?这是个好问题,也有办法应对。
办法是建立你自己的校准记录。挑几篇内容,按Critic的预测做了某个策略,再用真实AI测试测出实际提升,把预测值和实际值都记下来。攒上十几条,你就能看出Critic在你这类内容上的系统性偏差——是普遍高估还是低估,哪类策略偏差大。
有了这份校准记录,就能给Critic的预测加一个经验修正:比如发现它对专家引述总是高估,以后看到引述的预测就主动打个折。代理工具最聪明的用法,不是盲信它的绝对值,而是摸清它的脾气、用你自己的数据去校准它。这样它在你手里会越用越准,慢慢变成贴合你内容风格的私人预测器。
用之前要注意什么?
几个边界得先讲清,免得用偏。
第一,它是规则化的代理,不是真实引擎。预测基于内容特征和固定规则,反映的是“按经验这招大概有多大空间”,不等于真实引用率。把它当筛选器和排序器,别当最终裁判。
第二,预测的策略效果均值来自GEO论文。工具里每种策略标注的平均提升,比如Answer-First约40%、专家引述约41%,来自 GEO: Generative Engine Optimization论文 的实验。但论文是数据集平均值,落到你这篇具体内容上,Critic才会结合特征给出个性化的预测。
第三,验证环节不能省。Critic的价值是减少真实测试次数,不是取消。尤其对高潜力低置信的策略,省下的预算就该花在验证它们上。学术界对这一点也很谨慎,2026年的多智能体GEO研究 From Experience to Skill: 通过可复用策略学习做生成式引擎优化 专门设计了带因果归因的双分支评估协议来核验每次编辑的真实效果,可见“预测之后必验证”是这套方法的标配,不是可选项。
第四,中文内容要打折看。特征抽取的分词、句长、信号词都偏英文,对中文会有偏差。结构化、Schema这类不依赖语言的预测仍可靠,语言强相关的几项需要人工复核。
常见问题解答
Critic预测和真实测试差多少?
代理预测本质是用规则近似真实引擎的判断,会有偏差,具体差多少取决于内容类型和引擎。它的定位不是替代真实测试,而是帮你在测试前筛掉明显不值得做的策略,把真实测试集中到高潜力的几招上。所以别纠结绝对数值,把它当相对排序和筛选工具用最稳妥。
置信度低的策略是不是就不能做?
不是。置信度低只说明Critic对这条预测把握不大,不代表预测错。正确做法是把高提升、低置信的策略拎出来,优先用真实AI测试验证。验证通过就放心做,这恰恰是Critic帮你省成本的方式——把测试用在最该用的地方。
它和GEO内容评分器有什么不同?
评分器给整篇内容打一个当前的总分,回答你现在几分;Critic则预测如果用某种策略,分数能涨多少,回答接下来做哪招最值。一个看现状,一个看未来增量,配合用就是先知道差距、再知道怎么补。两者的分工在 GEO内容评分器的七维度九策略拆解 里讲得更细。
为什么有的策略预测提升那么低?
因为你这篇内容在那一项上已经做得不错了。比如你的句子本来就顺,流畅度优化自然没多大空间;你已经有几个数据点,再加数据的边际效果也有限。Critic是按你内容的实际情况个性化预测的,提升低恰恰说明这块不用再花力气。
不选策略全跑一遍和只选几个有区别吗?
结果上没区别,工具对每种策略的预测是独立计算的,跑全部还是跑几个,单个策略的预测值都一样。只选几个的好处是结果更聚焦、好读,适合你心里已经有候选的时候。想全面比较就跑全部。
这工具收费吗,有调用次数限制吗?
完全免费,也没有次数限制。它在服务端用规则计算,不消耗AI引擎的付费额度,你可以随便跑、反复跑。这也正是代理预测的意义——把要花钱的真实测试,换成免费随便用的快速预估,想测几遍测几遍。
Critic推荐的策略,执行顺序重要吗?
重要。建议先做高置信的,再做验证通过的高潜力策略。原因是每做完一项,内容特征就变了,剩下策略的预测也会跟着变——比如你补了Answer-First,再跑一次预测,其他策略的优先级可能重排。所以别一次性按初版预测把所有策略都改完,做一项、重测一次、再决定下一项更稳。
预测里的基线35分是什么意思?
工具假设任何内容都有一个35分的基线可见性,每种策略的预测提升都是在这个基线上往上加,加完封顶100。所以你看到的优化后得分,是基线加预测提升的结果。这是个简化设定,主要用来让不同策略的预测有个统一起点好比较,不必纠结它的绝对值。
不同AI引擎的预测能通用吗?
工具的预测基于GEO通用策略和内容特征算,不区分具体引擎,给的是一个跨引擎的平均参考。但不同引擎口味不同,比如Perplexity更看重引用和经验。所以预测当通用方向看可以,落到具体引擎时,最好还是用那个引擎的真实测试去校准。
内容太短能预测吗?
工具要求至少30个字符才能跑,但内容太短预测意义不大。特征抽取依赖足够的文本量,几十字的内容算出来的词数、句长、信号数都不可靠。建议拿成篇的内容来预测,至少几百字以上,结果才有参考价值。
预测结果会随内容修改而变化吗?
会,而且这正是它的用法。每改一版重新跑一次,你能看到对应策略的预测提升下降、置信度上升,说明这一项的空间被你填上了。把历次预测连起来看,就是一条优化进度曲线,比单看某一次的分数更有意义。
预测结果能直接拿去汇报吗?
可以当决策参考,但汇报时要说清它是代理预测、不是真实数据。比较稳妥的说法是用它做优先级排序的依据,再附上对高潜力策略的真实验证结果,预测加验证两条腿走路,结论才站得住。
本文标题:《Critic代理评分器怎么用?不调用AI引擎就预测9种GEO策略的可见性提升》
本文链接:https://zhangwenbao.com/geo-critic-surrogate-agent-effect-prediction-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0