GEO内容评分器实战:把AI可见性拆成7个维度和9条策略,发布前先体检一次

本文目录
- 为什么你的内容排名第一,AI却还是不引用你?
- GEO内容评分器到底在算一件什么事?
- 评分背后那篇GEO论文到底验证了什么?
- 词数与内容量:多长才够被AI看得起?
- 位置调整分怎么算?为什么第一句往往决定生死?
- 语义相关性:查询词覆盖率是怎么变成分数的?
- 独特性与信息增益:AI为什么偏爱带数据的段落?
- 权威性信号:引用、作者、统计怎么叠成影响力分?
- 内容多样性与点击意愿这两维到底看什么?
- 九条GEO策略自检表:你的内容缺了哪几条?
- 七个维度怎么加权成一个最终总分?
- GEO内容评分器具体怎么操作?六步走完一轮体检
- 实战:把一个38分的B2B选型页救到90分
- GEO评分器和站内哪些工具串起来用最顺手?
- GEO评分能不能被刷出来?这工具的边界在哪?
- 用GEO内容评分器最容易踩的5个误区
- 常见问题解答
- GEO内容评分器和传统SEO的内容评分有什么区别?
- 这个评分器对中文内容准吗?
- GEO总分到多少才算合格?
- 提分最快的动作是哪个?
- 评分器和GEO可见性模拟器该用哪个?
- 权威参考资料
摘要:GEO内容评分器是一台“发布前体检仪”,它把“你的内容会不会被AI引用”这件玄学,拆成词数、位置调整分、7个主观印象维度和9条优化策略,套进一条加权公式算出0到100的GEO分。它的理论底子是KDD 2024那篇GEO论文:策略合规度占两成权重最高,位置感知和语义相关性各占15%,所以“开头第一句有没有给答案”往往比“文章有多长”更能决定胜负。这篇把每个维度的真实算法、一个B2B选型页从38分救到90分的全过程,以及它和可见性模拟器、实体分析器怎么串起来用,全部拆开讲清楚。
为什么你的内容排名第一,AI却还是不引用你?
先把答案放最前面:因为传统搜索排名考的是“整页相关性”,而生成式引擎考的是“这一段能不能被我直接抄进答案里”。这是两套完全不同的评判标准。你的页面在Google稳居第一,不代表豆包、DeepSeek、ChatGPT在回答用户问题时会把你这段话拎出来当依据。
保哥这两年帮出海独立站做GEO,最常遇到的场景就是这种:客户后台SEO数据漂亮得很,自然流量也稳,可一搜AI回答里全是同行的名字,自己一次都没被提及。问题不在“内容差”,而在“内容没被拆成AI愿意引用的形状”。
GEO内容评分器就是用来量化这件事的。它不预测排名,它预测“被引用概率”——把一段内容丢进去,连同你想命中的那个用户问题,它会告诉你这段话在AI眼里值多少分,以及具体是哪个维度拖了后腿。下面我们把这台仪器的内部一层层拆开。
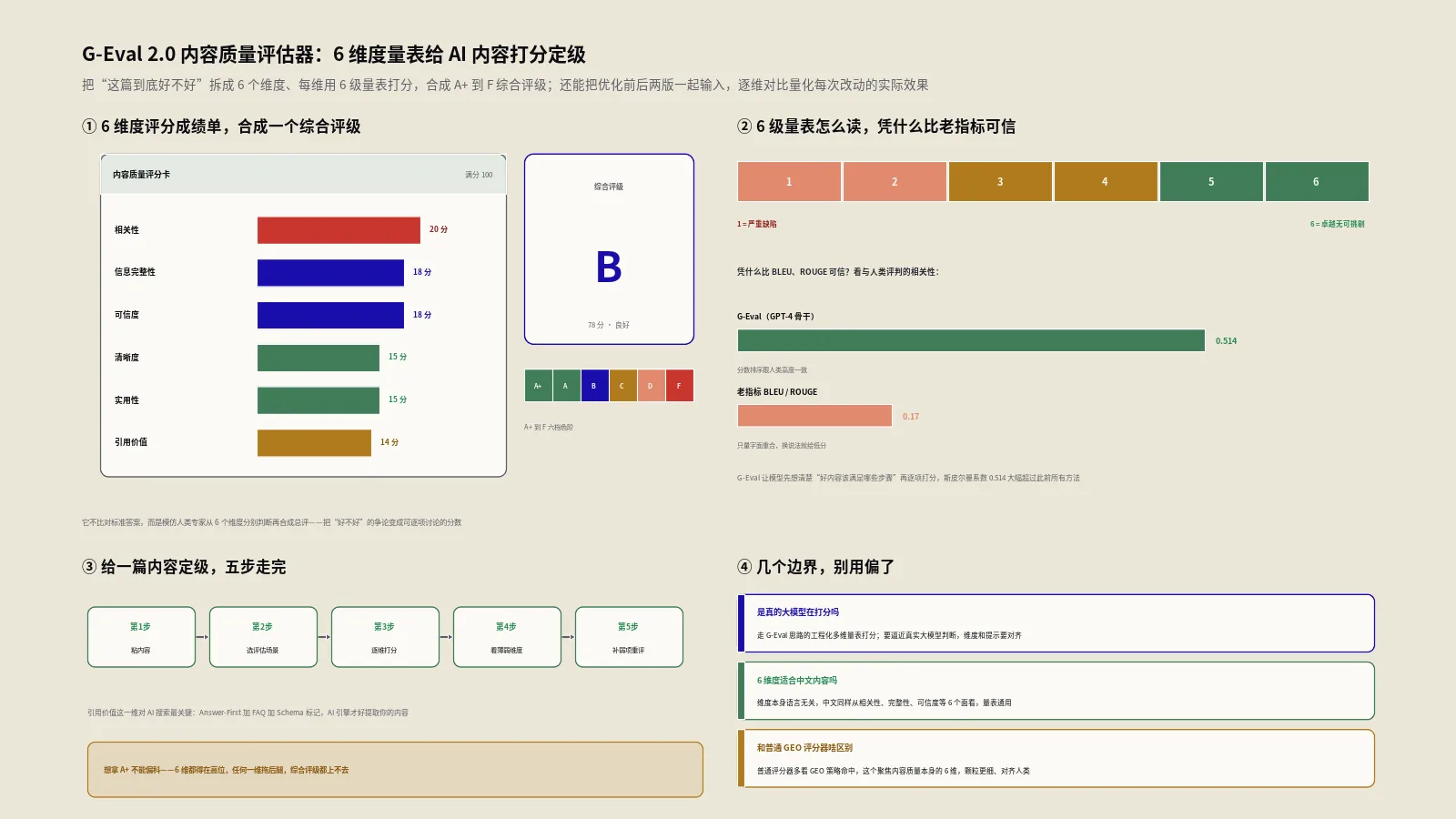
GEO内容评分器到底在算一件什么事?
它的总框架可以浓缩成一行:
可见性得分 = f(词数, 位置调整分, 7个主观印象维度)× 9条策略合规度
这一行不是拍脑袋来的。它直接对应KDD 2024那篇《GEO: Generative Engine Optimization》——论文做了一个叫GEO-bench的大规模基准测试,结论是:合理优化能把内容在生成式引擎里的可见性提升最高40%,而且不同领域的最优策略并不一样。评分器把论文里的维度和策略,落成了一套可计算、可复现的打分逻辑。
具体来说,它做三件事:先统计内容的基础形态(词数、句数、段落数、查询词覆盖),再算7个0到100的印象维度分,最后逐条检查9个优化策略合不合格,把这三层用加权公式合成一个总分。总分对应四个等级:75分以上叫“GEO就绪”,50到74叫“有优化空间”,30到49叫“需要大幅优化”,30以下就是“GEO基础薄弱”。
有意思的是权重分配。9条策略的平均合规度占了整整20%,是单项里最重的;位置感知和语义相关性各占15%;而很多人最在意的“内容量”反而只占8%。换句话说,光把文章写长,对GEO分的拉动很有限——这点后面会反复印证。
评分背后那篇GEO论文到底验证了什么?
评分器的可信度,归根结底押在那篇GEO: Generative Engine Optimization论文上。它不是观点文,而是一项跑了真实生成式引擎的实证研究,搞清楚它验证了什么,你才知道这些维度为什么该信。
论文做了一个叫GEO-bench的基准,覆盖了上万条跨多个领域的真实用户查询,逐条测试不同优化手法对“内容被生成式引擎引用的可见度”的影响。最硬的结论是:组合得当的优化能把可见度提升最高40%,而且——这点很关键——最优策略随领域而变,没有一招通吃的万能公式。
更反直觉的是策略之间的分化。论文实测里,引用权威来源、添加统计数据、加入专家引述这三条几乎在所有领域都稳定有效;而单纯堆关键词、强行拔高词汇花哨度这类手法,对某些引擎不仅没用,甚至会把可见度往下拽。这正是评分器把S1、S2、S9给高权重,却对关键词密度超标重罚的实证依据。
对中文从业者要补一句诚实话:这篇论文测的是英文生成式引擎(类Perplexity那一挂)。结论的方向性在豆包、DeepSeek、元宝上大概率成立,但具体的增益幅度需要你自己在目标引擎上做对照实验来校准。把论文当方法论罗盘,而不是照抄的施工图,这才是稳妥用法。
词数与内容量:多长才够被AI看得起?
先说最直觉的维度:内容量。评分器对词数的处理不是线性的,而是一张阶梯表。这里的“词数”指中文汉字加英文单词的总数(正则同时匹配单个汉字和完整英文词),所以对中文内容也适用。
| 词数区间 | 内容量得分 | 保哥解读 |
|---|---|---|
| ≥3000 | 100 | 足够AI从中挑出多个可引用片段 |
| 2000–2999 | 85 | 主流深度长文区间 |
| 1200–1999 | 70 | 合格的教程/指南门槛 |
| 800–1199 | 55 | 偏薄,覆盖面有限 |
| 400–799 | 40 | 容易被判信息密度不足 |
| 200–399 | 25 | 基本只够一个段落 |
| <200 | 10 | AI几乎无从引用 |
注意这一维在总分里只占8%权重。一篇3000词满分内容量的文章,对总分的贡献也就8分。所以保哥常跟客户讲:别把“写够字数”当成GEO的核心动作,它只是入场券,不是胜负手。真正的杠杆在后面那几个权重更高的维度。
这也解释了一个常见误判:有人把一篇800词的精悍答案硬注水到3000词,内容量分从55涨到100,可句子变得啰嗦、答案被稀释,反而拖累了位置调整分和流畅度策略,总分不升反降。长度是手段不是目的,这句话在GEO里比在传统SEO里更狠。
位置调整分怎么算?为什么第一句往往决定生死?
这是整个评分器里最值得琢磨的一块。位置调整分(Position-Adjusted Score)回答一个问题:你的核心答案,藏得有多深?算法是一条指数衰减曲线:
位置调整分 = e^(−首次命中句号位置 ÷ 总句数) × 100
翻译成人话:评分器先把内容切成句子,找出查询词第一次出现在第几句。如果第一句就命中,指数项是e的0次方等于1,得满分100;如果拖到很靠后才出现,分数就被指数级地压下去。
举个数:一篇内容总共40句,核心词第一次出现在第20句,那么位置调整分 = e^(−20÷40) × 100 = e^(−0.5) × 100 ≈ 61分。同样这篇文章,如果把核心答案提到第1句(位置0),分数立刻变成e^0 × 100 = 100分。一个段落的搬家,就是39分的差距。
除此之外还有一个Answer-First加成:只要查询词出现在前3句之内,就触发一个额外标记,位置感知维度直接再加20分(封顶100)。这两条机制叠加,把“开门见山”这件事的权重顶得非常高——位置感知在总分里占15%,是内容量的近两倍。
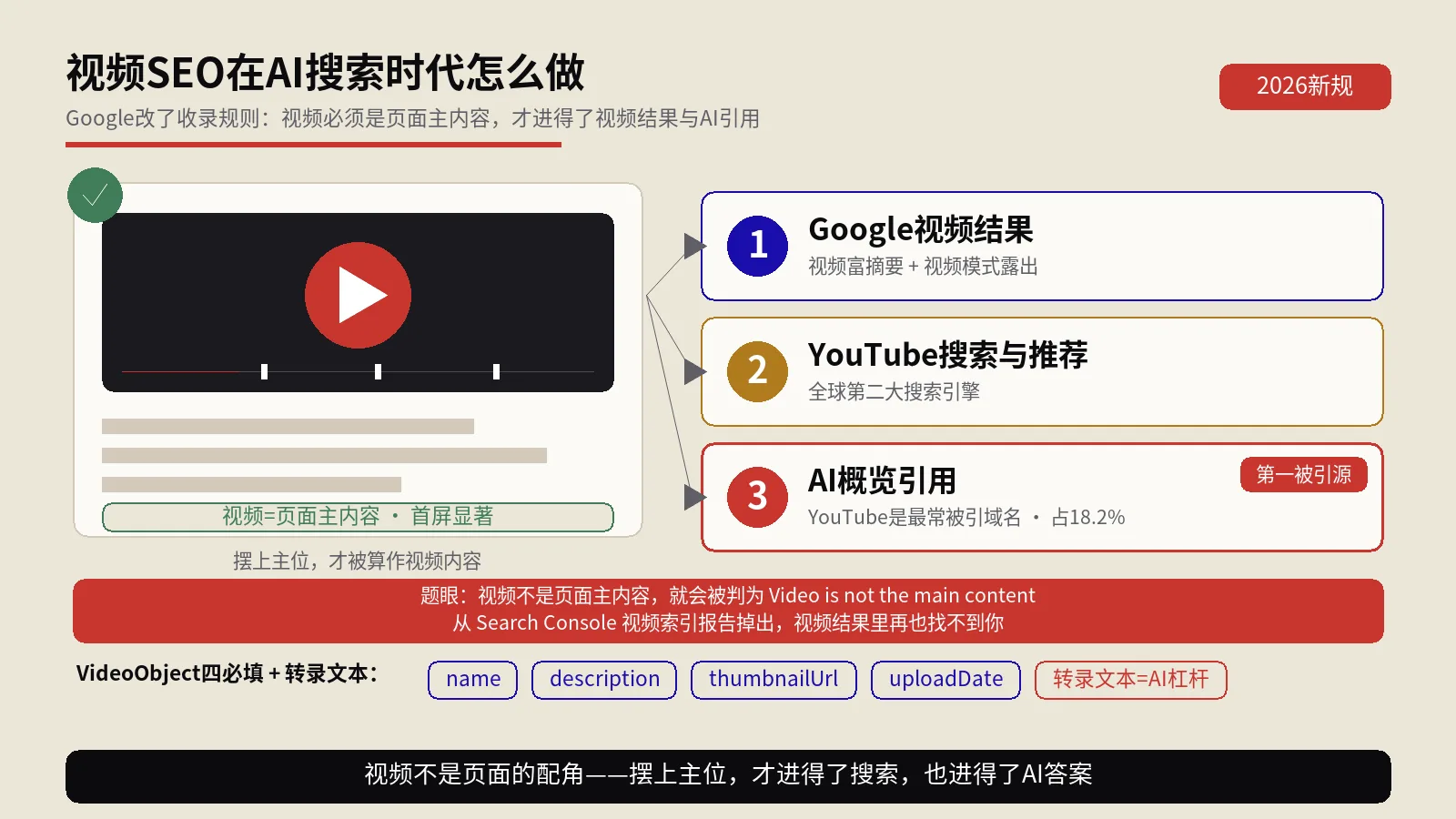
这跟保哥一贯的主张完全一致:GEO时代的文章,第一段必须先把答案给出来,再展开论证。倒金字塔结构不再只是新闻写作的讲究,而是AI能不能精准摘取你这段话的技术前提。保哥那篇用30天对照5种内容结构、复盘3个失败案例的实测里,开头直给答案的结构被引用率明显更高,跟这条位置衰减曲线是一个道理。
语义相关性:查询词覆盖率是怎么变成分数的?
语义相关性维度衡量“这段内容到底答不答得上那个问题”。它的公式是三项相加再封顶100:
语义相关性 = min(100, 查询词覆盖率 × 60 + 命中Answer-First则加20 + min(20, 词数÷50))
查询词覆盖率指的是:你设定的目标查询拆成几个词,其中有多少个真的在内容里出现过。比如目标查询是“离心泵选型方法”,拆成“离心泵/选型/方法”三个词,内容里三个都出现,覆盖率就是1.0,这一项拿满60分。
第二项呼应了前面的Answer-First:核心词在前3句出现,再补20分。第三项是词数的微弱加成,每50个词加1分,最多20分——又一次印证内容量只是配角。
这里藏着一个实操要点:很多人写内容只盯着主关键词,把长尾的限定词漏掉了。比如用户问的是“离心泵怎么防止气蚀”,你通篇讲离心泵却一次没提“气蚀”,覆盖率就被腰斩。GEO评分器逼你回到“用户到底问的是哪几个词”这个原点,这正是保哥讲独立站内容分层架构那套一层SEO一层GEO的5板块打法里强调的:GEO层的每一块都要对准一个具体问句,而不是泛泛覆盖一个大词。
独特性与信息增益:AI为什么偏爱带数据的段落?
独特性维度(也叫信息增益)是GEO里特别容易被低估的一维。生成式引擎在合成答案时,会优先挑那些“别处没有、信息密度高”的片段——也就是带具体数据、专有名词的内容。公式是:
独特性 = min(100, 数据点×8 + 专有名词×5 + 词数>500加15 + 词数>1000再加15)
“数据点”指那些带单位的数字,正则会去抓诸如“40%”“3倍”“200万”“1.5亿”以及billion、million、percent这类表达。“专有名词”抓的是连续大写开头的英文词组,比如品牌名、产品型号、机构名。每个数据点值8分,每个专有名词值5分,再加上两档词数门槛各15分。
这条算法的潜台词很直接:泛泛而谈的形容词在AI眼里等于没营养,带数字和实体的句子才有信息增益。保哥审稿时有个习惯——把每个“很多”“大幅”“显著”都揪出来,逼作者换成“47%”“从12秒降到3秒”这种能被AI当证据抄走的具体表述。这件事在GEO里的回报,比在传统SEO里高得多。
不过要诚实地点一句局限:这一维抓“专有名词”用的是英文大写规则,对纯中文内容里的中文品牌名、中文型号其实识别不到。所以中文站做这一维优化时,别只看工具给的专有名词计数,更要盯“数据点”那部分,把具体数字密度提上去才是对中文真正有效的杠杆。
权威性信号:引用、作者、统计怎么叠成影响力分?
影响力维度对应E-E-A-T里的权威与可信。它把几类信号加权叠起来:
影响力 = min(100, 引用链接数×12 + 有作者/来源标注加20 + 有统计数据加15 + 数据点×5 + 专有名词>3则加15)
这里“引用链接”指内容里出现的http/https外链,每条值12分;“作者或来源标注”是检测有没有出现“作者”“来源”“据⋯报告”“study”“research”这类词;“统计数据”看有没有百分比、小数、四位年份。
这套权重和Google对内容质量的判断高度同构。Google那份给人工评估员看的搜索质量评估指南反复强调,能拿出可信来源、有明确作者背书的内容,E-E-A-T信号更强。GEO评分器把这套逻辑量化了:你引用了3个权威来源,光这一项就36分到手。这也是为什么保哥要求每篇GEO内容都做“权威外链双重放置”——正文锚文本嵌一次、文末参考资料汇总一次,既给读者也给AI看清楚证据链。
内容多样性与点击意愿这两维到底看什么?
这两维一起说,因为它们都看“内容的形态丰不丰富”。
内容多样性看结构元素:H2到H4小标题(每个10分)、有序无序列表、表格(15分)、代码块(10分)、加粗强调(8分)、FAQ模块(12分),再加上段落数和句子数的小奖励。一篇结构扁平、从头到尾纯段落的文章,这一维会很难看;而拆了小标题、配了表格列表、带FAQ的文章轻松接近满分。
点击意愿看“可操作性信号”:内容里有没有“如何/步骤/方法/教程/指南”这类词(20分)、有没有“5个/3种/Top 10”这种数字列举(15分)、是否命中Answer-First(20分)、有没有Schema结构化数据(15分)、有没有FAQ(15分)、再加数据点的小分。
这两维各占总分10%。它们传递的信号很统一:AI喜欢“结构清晰、能直接拆段落、带可执行步骤”的内容。这恰好是结构化数据和HowTo模板的用武之地——而结构化数据本身你可以用站内的工具一键生成,后面串联那节会讲怎么配合用。
九条GEO策略自检表:你的内容缺了哪几条?
除了7个维度,评分器还会对照GEO论文里的9条优化策略逐条打分,这9条的平均分占了总权重的20%,是最重的一块。保哥把它整理成一张自检表,对着改最高效:
| 策略 | 评分逻辑(简化) | 论文实测增益 |
|---|---|---|
| S1引用权威来源 | 引用数×20 + 有统计15 + 有作者15 | 可见性 +21%~40% |
| S2添加统计数据 | 数据点×15 + 有统计20 | +15%~30% |
| S3添加专家引述 | 引号引述×25 + 有作者25 | 显著 |
| S4避免关键词堆砌 | 密度≤3%满分,越高越扣 | 堆砌反而降可见性 |
| S5流畅度优化 | 平均句长15–45字得满分 | 过长句被扣 |
| S6权威语调 | 专家表述/第一人称/作者/引用/数据叠加 | 增强可信 |
| S7专业术语 | 术语数×5 + 有代码15 + 有表格10 | 帮AI识别专业性 |
| S8结构化内容 | 标题/列表/表格/Schema/FAQ叠加 | 便于段落级提取 |
| S9 Answer-First格式 | 开头给答案80分,前3句命中再加20 | 论文称增益最高,达40% |
这张表最该被记住的是S1、S2、S9。GEO论文的实测里,引用来源、添加统计、Answer-First是增益最猛的三条,分别能把可见性顶到40%上下。保哥的经验是:一篇内容如果这三条都欠着,先别管别的,把这三条补齐,总分通常能跳一个等级。
S4那条要特别提醒:关键词密度超过3%就开始扣分,超过8%只剩10分。GEO跟传统SEO在这点上态度一致——堆砌不仅没用,还会被判作弊信号。Google的垃圾内容政策里把“为操纵排名而堆砌关键词”明确列为违规,AI引擎对这类信号同样敏感。
七个维度怎么加权成一个最终总分?
把前面所有分数合起来,就是这条复合公式。保哥把它和权重列成表,一眼看清谁说了算:
| 组成项 | 权重 | 地位 |
|---|---|---|
| 9条策略平均合规度 | 20% | 最重,胜负手 |
| 位置感知(Answer-First) | 15% | 开头给不给答案 |
| 语义相关性 | 15% | 答不答得上问题 |
| 影响力/权威性 | 12% | 引用与可信信号 |
| 独特性/信息增益 | 10% | 数据与实体密度 |
| 内容多样性 | 10% | 结构元素丰富度 |
| 点击意愿 | 10% | 可操作性信号 |
| 内容量 | 8% | 入场券,非杠杆 |
看清这张表,GEO优化的优先级就排出来了:先攻策略合规(尤其S1/S2/S9),再攻位置和相关性,最后才轮到把字数堆够。把精力倒过来花,是最常见的浪费。
这套“先量化再决定改哪里”的思路,和保哥讲用GEO可见性模拟器在发布前算清三项得分是同一条流水线上的两个环节:可见性模拟器用蒙特卡洛模拟“多轮提问里你被引用几次”,评分器则把单篇内容的优化空间逐维度标出来,两者一个看结果一个看过程,配合着用最顺手。
GEO内容评分器具体怎么操作?六步走完一轮体检
理论讲完,落到动手。保哥把一次完整体检拆成六步,照着走一遍,半小时就能让一篇内容脱胎换骨。
第一步,输入内容和目标查询。查询一定要写成用户真实的问法,比如“离心泵怎么选型”而不是干巴巴的“离心泵”,因为评分器要靠这个问句算覆盖率和位置。
第二步,读总分和等级,心里有个底。第三步,看七维雷达,哪一维最矮就先盯哪一维——这是杠杆最大的地方。第四步,对照9条策略表,重点确认S1引用、S2数据、S9 Answer-First这三条达没达标。第五步,按权重从高到低改稿:先把核心答案搬到第一段,再补引用和数据,最后才考虑加字数。第六步,改完重新跑分,验证有没有跨过目标等级。
实战:把一个38分的B2B选型页救到90分
讲个去标识化的真实案例。一家做工业水泵出海的独立站,有个产品教育页《离心泵选型指南》,自然搜索排名不错,但在AI回答“离心泵怎么选型”时从没被引用过。保哥拿评分器跑了一遍,初始分38,等级是“需要大幅优化”。逐维度看,问题一目了然:
| 维度 | 改造前 | 改造后 | 动作 |
|---|---|---|---|
| 语义相关性 | 58 | 100 | 补齐漏掉的“选型/方法”等限定词 |
| 位置感知 | 61 | 100 | 核心答案从第20句提到第1句 |
| 独特性 | 15 | 72 | 加入流量/扬程/气蚀余量等具体数据 |
| 影响力 | 15 | 91 | 补3条权威标准与手册引用 |
| 内容多样性 | 35 | 100 | 加选型对照表、步骤列表、FAQ |
| 点击意愿 | 20 | 100 | 加HowTo步骤与Schema |
| 内容量 | 55 | 70 | 从900词扩到1600词 |
| 策略均值 | 27 | 84 | 补齐S1/S2/S9三条 |
| 总分 | 38 | 90 | 跨两个等级到“GEO就绪” |
把改造前后的动作对照权重看,回报最高的三步非常清楚:把核心答案提到开头(位置感知+39,权重15%)、补齐引用与数据(影响力+76、独特性+57,且直接拉高策略均值)、加结构元素(多样性+65、点击意愿+80)。而那个大家最爱做的“扩字数”,内容量只从55涨到70,对总分的实际贡献不过1分出头。
这个案例最值得记住的不是“涨了52分”,而是涨分来自哪里——全是权重高的策略合规和位置项。如果这家客户当初只闷头加字数,分数可能从38爬到42就卡死了。这也是保哥反复强调“先量化、再决定改哪里”的原因:评分器最大的价值不是给你一个分数,而是告诉你该把有限的精力砸在哪。
GEO评分器和站内哪些工具串起来用最顺手?
单独用评分器只能算一篇内容的当下状态,真正的威力在于把它嵌进一条流水线。保哥日常的组合拳是这样的:
- 先用评分器定位短板:拿到七维雷达,找出最矮的那几维。
- 独特性低,转实体关联分析器:评分器告诉你“信息增益不足”,但不告诉你该补哪些实体。保哥拆过实体分析器的KGScore算法,它能挖出你内容里缺失的关键实体,让AI从“看见你”进阶到“引用你”。
- 流畅度策略低,转可读性评分器:S5流畅度被扣,说明句子太长。可读性评分器用6个公式量化难度,帮你把复杂句拆短。
- 结构化数据缺失,转结构化数据生成器:点击意愿和多样性里都看Schema,用结构化数据生成器一键产出HowTo、FAQPage的JSON-LD补上。
- 改完用可见性模拟器验收:评分器看单篇优化空间,可见性模拟器用蒙特卡洛模拟多轮提问里的实际被引用次数,一个看过程一个看结果。
这套组合的逻辑是:评分器是“分诊台”,告诉你病在哪一维;其他工具是“专科”,针对性地治。光有分诊不治,分数不会动;光埋头治不分诊,又容易治错地方。
GEO评分能不能被刷出来?这工具的边界在哪?
得把话说透:GEO内容评分器是一套启发式规则,不是真正的AI判官。它数的是外链数量、数据点个数、标题层级、核心词出现在第几句——这些都是“被引用概率的代理信号”,而不是引用本身。理解这一点,才不会用错它。
这意味着分数理论上能被“刷”。往内容里硬塞一堆不相关的数字,数据点维度会虚高;堆一排无关外链,影响力分也会涨。但这种刷分是典型的自欺:评分器被骗过去了,真正决定你被不被引用的生成式引擎可没那么好骗。它读的是语义、是上下文连贯、是答案到底对不对,表面信号堆出来的高分,换不来一次真实引用。
所以保哥给客户的定位很明确:把评分器当成一张“信号缺失检查表”,而不是一个要去通关的游戏分数。它的价值在于提醒你“这里缺引用、那段答案藏太深、这块没有结构化数据”,而你要补的,必须是真材实料的引用、真把答案提前、真做出能帮读者的结构。
这跟保哥一直讲的内容要经得起真人检验是一个道理:表面合规能骗过规则,骗不过真实读者,也骗不过最终来抓取你内容的AI。工具负责指出哪个信号弱,人负责保证补上去的东西配得上那个分数——这条分工,是用好任何SEO/GEO工具的底线。
用GEO内容评分器最容易踩的5个误区
保哥带客户用这工具,见过的坑总结成5条:
误区一:把GEO分当排名预测。它预测的是“被AI引用的概率”,不是Google排名。两者经常背离——排第一却零引用,正是这工具要解决的问题,别拿排名去验证它。
误区二:盯着内容量猛加字。前面算过,内容量只占8%权重。900词加到3000词,总分顶多动几分,还可能稀释答案密度反伤位置分。
误区三:目标查询写得太泛。输入“离心泵”和输入“离心泵怎么选型”,算出来的覆盖率和位置分完全不同。查询越接近用户真实问句,评分才越有指导意义。
误区四:迷信专有名词计数(中文站尤其)。专有名词检测走的是英文大写规则,对中文品牌型号识别不到。中文内容别被这个计数误导,把劲使在“数据点”密度上更实在。
误区五:改一次就完事。GEO是迭代游戏。AI引擎在变、竞品在改、你的查询意图也会漂。保哥的建议是每季度对核心页面重跑一次,把它纳入内容维护的固定动作,而不是发布前跑一次就再也不管。
常见问题解答
GEO内容评分器和传统SEO的内容评分有什么区别?
传统SEO评分看的是整页相关性、关键词布局、可读性,目标是排名。GEO评分器看的是“这段内容能不能被AI直接摘进答案”,核心是位置调整分、信息增益、引用信号这些生成式引擎关心的维度。最大的差异在于它把“开头第一句给不给答案”的位置权重顶得极高,这在传统SEO评分里几乎不被考虑。
这个评分器对中文内容准吗?
词数统计、查询覆盖、位置调整分、数据点检测这些对中文都有效,因为底层正则同时匹配汉字和英文。但“专有名词”那一项走的是英文大写规则,对中文品牌型号识别不到。所以中文站用它时,七维度里的独特性维度要结合人工判断,重点盯数据点密度,而不是只看专有名词计数。
GEO总分到多少才算合格?
75分以上是“GEO就绪”,这是保哥建议的发布门槛。50到74是“有优化空间”,能发但建议先补短板。30到49就别急着发了,说明位置、引用、数据这些核心信号普遍欠缺,改完再上。要注意分数是相对的,竞品都在涨,所以与其追求某个绝对数字,不如盯着“比上次跑分有没有进步、最低维度有没有被补上”。
提分最快的动作是哪个?
按权重和论文实测,三个动作回报最高:第一是Answer-First,把核心答案提到文章第一段,位置感知和S9策略同时受益;第二是补引用来源,影响力和S1策略一起涨;第三是加具体统计数据,独特性和S2策略联动。这三条凑齐,总分通常能跳一个等级,远比加字数划算。
评分器和GEO可见性模拟器该用哪个?
两个一起用,分工不同。评分器看“单篇内容还有哪些优化空间”,给你逐维度的诊断;可见性模拟器用蒙特卡洛模拟“在多轮真实提问里你大概会被引用几次”,给你一个结果预期。保哥的流程是:先用评分器把内容改到GEO就绪,再用可见性模拟器验收预期被引用率,两步走完才放心发布。
本文标题:《GEO内容评分器实战:把AI可见性拆成7个维度和9条策略,发布前先体检一次》
本文链接:https://zhangwenbao.com/geo-content-scorer-7-dimension-9-strategy-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0