G-Eval 2.0内容质量评估器怎么用?6维度量表给AI内容打分定级
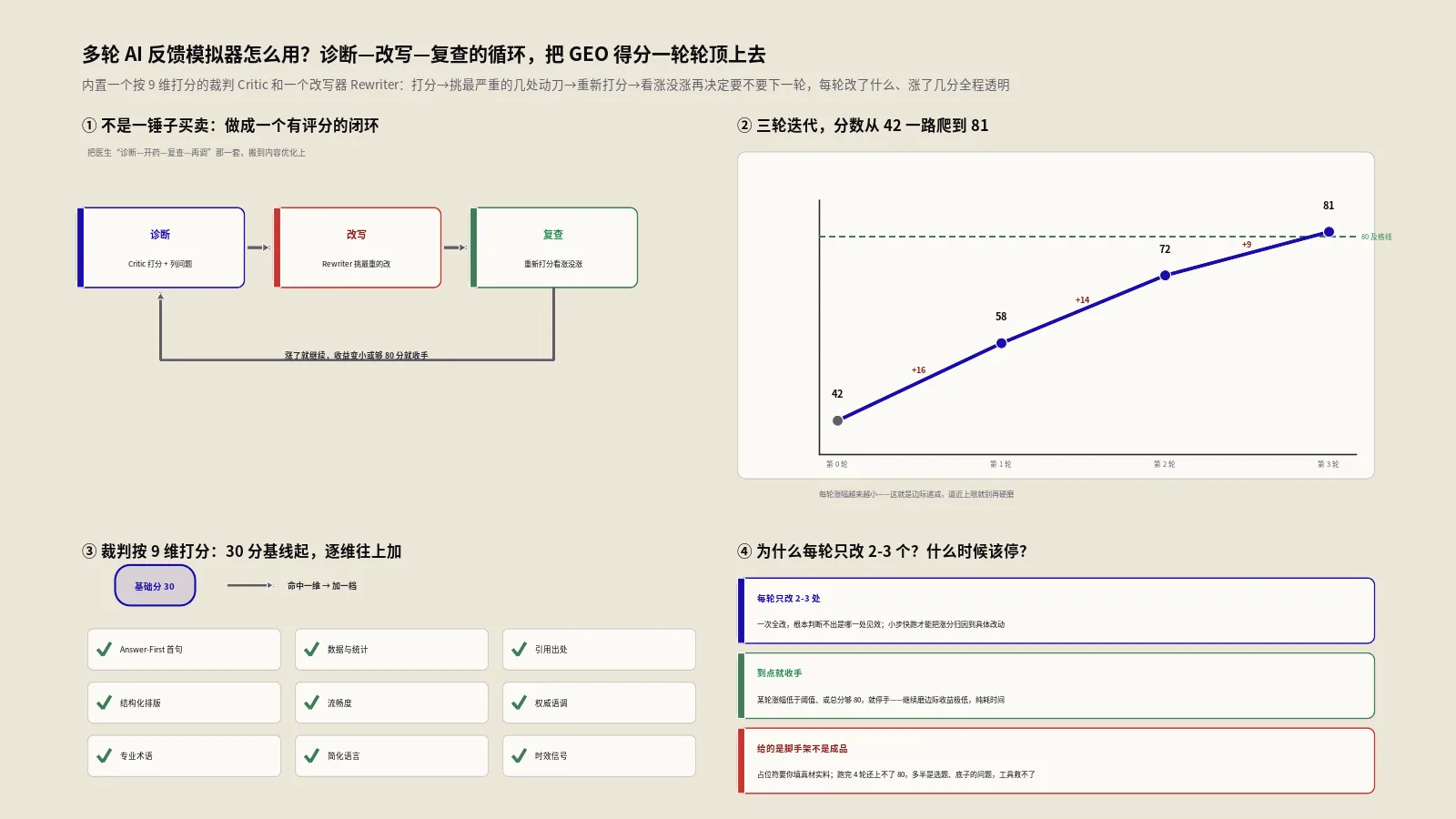
本文目录
- 内容质量这种主观的东西,真能用工具打分吗?
- G-Eval到底是什么,为什么它比老指标更可信?
- G-Eval 2.0在G-Eval基础上升级了什么?
- 6个评估维度分别在看什么?
- 为什么相关性的权重最高,占20分?
- 6级量表的1到6分该怎么解读?
- 综合评级A+到F是怎么算出来的?
- 这工具用的是真的大模型在打分吗?
- 优化前后对比功能该怎么用?
- 出海在线教育站怎么用它给课程介绍页质量定级?
- 拿到6维度分之后,薄弱维度该怎么补?
- 怎样的内容才能拿到A+卓越评级?
- 信息完整性这一维,工具怎么判断内容覆盖全不全?
- 引用价值维度为什么对AI搜索特别关键?
- 清晰度低分,常见是哪些结构问题?
- 实用性维度,怎样的内容算对用户真有帮助?
- 6维度评估适合中文内容吗?
- 多久该给核心页面重新评一次分?
- G-Eval 2.0和普通GEO评分器有什么不一样?
- G-Eval 2.0的评分和真实AI引用率挂钩吗?
- 新手用这工具,最容易踩的坑是什么?
- 评估完之后,怎么接进完整的GEO优化流程?
- 常见问题解答
- G-Eval 2.0内容质量评估器是用大模型打分的吗?
- 6个维度的权重可以自己调吗?
- 综合评级是C,到底是从哪几维拉低的?
- 优化前后对比时,两个版本必须改动很大吗?
- 所有维度都到4分了,还有必要继续优化吗?
- 这个评估结果能直接拿去说服老板或客户吗?
摘要:G-Eval 2.0内容质量评估器把“这篇内容到底好不好”这件主观的事,拆成6个维度、每个维度用6级量表打分,最后合成一个A+到F的综合评级。6个维度是相关性、信息完整性、可信度、清晰度、实用性、引用价值,各自有不同权重,加起来满分100。它还支持把优化前和优化后两个版本一起输入,逐维度对比分数变化,量化每次改动的实际效果。这篇教程拆开6个维度各看什么、权重为什么这么分、6级量表怎么解读、A+评级的硬条件,再讲清这工具和真正的大模型打分之间的边界,最后用一个出海在线教育站给课程介绍页定级的真实场景跑一遍。
内容质量这种主观的东西,真能用工具打分吗?
做内容的人都遇到过这个尴尬:你觉得这篇写得不错,编辑觉得一般,老板觉得不够专业,谁也说服不了谁,因为“好不好”全凭感觉,没有一把公认的尺子。到了AI搜索时代这个问题更突出——你得知道一篇内容够不够被AI引用,可你连“够好”的标准都说不清。
把质量量化,难点不在于打分本身,而在于打分得跟人的真实判断对得上。传统的自动评估指标,比如机器翻译领域的BLEU、摘要领域的ROUGE,都是靠跟标准答案比对字面重合度来打分,遇到需要创意和多样性的内容就抓瞎,跟人类评判的相关性很低。一篇换了说法但意思更好的内容,字面重合度低,这类指标反而给低分,显然不对。
G-Eval 2.0内容质量评估器走的是另一条路:不比对标准答案,而是模仿人类专家的评估思路,从多个维度分别判断内容质量,再合成总评。它要解决的就是“让内容质量有一把跟人类判断对齐的尺子”,把拍脑袋的争论变成可以逐维度讨论的分数。
G-Eval到底是什么,为什么它比老指标更可信?
G-Eval是近几年内容评估领域一个很有影响力的方法。Liu等人的G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment(EMNLP 2023)提出,用大模型加思维链、再配合一套表单填写式的打分流程来评估内容质量,核心创新是让模型先想清楚“好的内容该满足哪些评估步骤”,再据此逐项打分。
这套方法的可信度,论文用数据证明过:在摘要质量评估任务上,G-Eval用GPT-4做骨干模型,跟人类评判的斯皮尔曼相关系数达到0.514,大幅超过此前所有方法。换句话说,它打出来的分数排序,跟人类专家排出来的顺序高度一致。这就是它比BLEU、ROUGE这些老指标值钱的地方——老指标量的是字面重合,G-Eval量的是人会怎么看。
G-Eval 2.0在G-Eval基础上升级了什么?
原始G-Eval主要面向摘要、对话这类通用文本生成任务,而把它用到生成式引擎优化场景,需要一套更贴合GSE可见度的评估协议。Chen等人的Role-Augmented Intent-Driven Generative Search Engine Optimization(arXiv 2508.11158)正是在这个背景下提出了G-Eval 2.0,一个多维度的评估协议,让内容在生成式引擎里的可见度评估更公平、更细颗粒。
本工具就是把G-Eval 2.0这套思路产品化:把“内容在AI引擎里够不够好”拆成6个可判断的维度,每个维度用6级量表打分,6维度乘6级等于36种细分质量状态。Aggarwal等人的GEO: Generative Engine Optimization(KDD 2024)当年用的还是相对粗粒度的主观印象评分,G-Eval 2.0比它精细得多。维度更多、刻度更细,意味着你能精准定位到底是哪一项拖了后腿,而不是只知道“整体一般”。
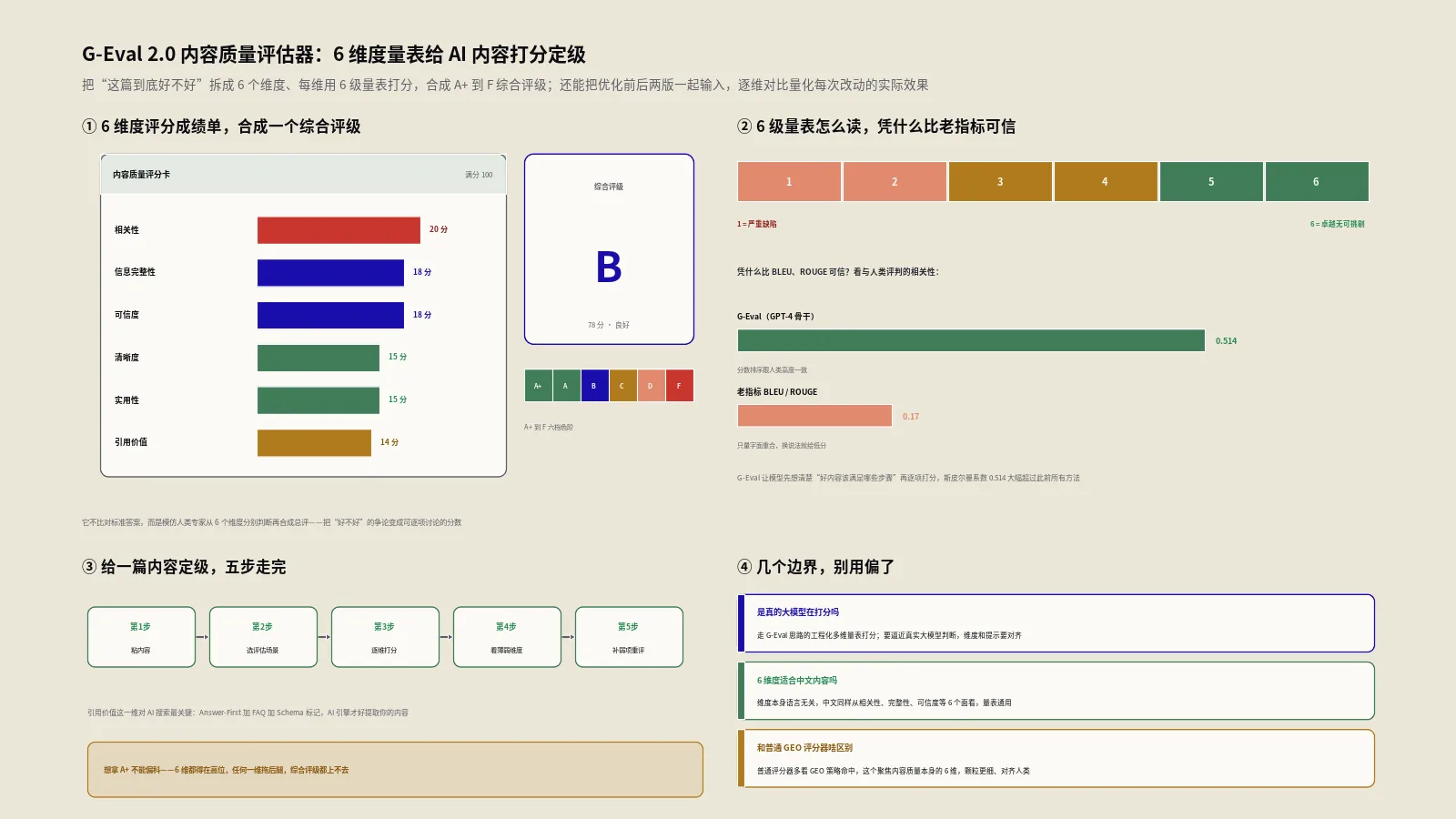
6个评估维度分别在看什么?
6个维度各管内容质量的一个侧面,权重不一样,加起来满分100。下面这张表是完整的维度和权重分配。
| 维度 | 权重 | 看什么 | 满分的样子 |
|---|---|---|---|
| 🎯 相关性 | 20分 | 内容跟目标查询的语义匹配度 | 标题首段精准命中查询核心词 |
| 📋 信息完整性 | 18分 | 是否覆盖查询的各个方面 | 定义、方法、原因、案例、注意事项都有 |
| 🔒 可信度 | 18分 | 数据支撑和来源引用 | 多处权威引用加多个具体数据 |
| 💎 清晰度 | 15分 | 结构和表达的清晰程度 | 标题分层、句长适中、段落不臃肿 |
| ⚡ 实用性 | 15分 | 对用户的实际帮助程度 | 可操作的步骤、建议、工具 |
| 📌 引用价值 | 14分 | AI引擎提取和引用的容易度 | Answer-First加FAQ加Schema标记 |
这6个维度不是随便凑的,每一项都对应AI引用内容时真实会权衡的因素:相关不相关、全不全、可不可信、清不清楚、有没有用、好不好提取。一篇内容可能在某几维很强、某几维很弱,分维度打分的意义就在于把这种不均衡暴露出来。
为什么相关性的权重最高,占20分?
相关性独占20分,是6个维度里最高的,逻辑跟其他GEO工具一脉相承:它是一道资格线。如果你的内容跟目标查询根本不匹配——用户问的是“怎么准备雅思口语”,你通篇在讲雅思阅读技巧,那么后面信息再全、引用再权威、结构再清晰,都没用,因为AI在第一轮就判定你答非所问,根本不会把你纳入候选。
相关性是前面那个1,其他5个维度是后面的0。前面的1立住了,后面的0才能放大价值;前面的1塌了,后面堆再多0也是0。所以用这个工具时,如果相关性维度分数低,别急着去补数据、改结构,先回头看内容的主题跟目标查询是不是真的对得上,把查询的核心词自然融进标题和首段,这一步的回报永远最高。
6级量表的1到6分该怎么解读?
每个维度都用1到6的6级量表打分,分档很明确。1到2分是薄弱,意味着这一维基本没做或者做得很差,需要大幅改进;3分是一般,有明确的不足,能看出来在做但不到位;4分是良好,基本达标,达到了可用的水平;5分是优秀,这一维做得很扎实;6分是卓越,顶级水平,几乎挑不出毛病。
实操里给自己定的目标可以这样:所有维度至少≥4分,保证没有明显短板;核心页面争取≥5分,让每一维都达到优秀。比6级量表更有意义的是看分布——如果6个维度有5个都是5分、唯独可信度只有2分,那优化方向就一目了然,集中火力补可信度即可,不用胡子眉毛一把抓。细颗粒度的好处就是让“该改哪”这件事不再靠猜。
综合评级A+到F是怎么算出来的?
6个维度的分数,工具会用两种方式汇总。一种是按权重加权,相关性的分乘20、信息完整性乘18,以此类推,加总后归一化到百分制,反映加权后的整体质量。另一种是直接取6个维度的算术平均分,落在1到6这个区间,用来定综合评级。
综合评级的档位是这样划的:平均分≥5.0是A+卓越,≥4.5是A优秀,≥3.5是B良好,≥2.5是C一般,≥1.5是D需改进,低于1.5是F薄弱。这套字母评级的价值在于给你一个一眼能懂的整体定位——A+和B的差距,比“82分和76分”这种数字更直观。需要说明的是这些档位阈值是工具的工程化设定,用来把连续分数切成方便沟通的等级,重点看评级的相对变化,优化后从C升到A,比纠结具体小数点更有意义。
这工具用的是真的大模型在打分吗?
这是必须讲清楚的一点:不是。真正的G-Eval需要调用GPT-4这个级别的大模型,让它带着思维链逐项判断,那才是论文里那套跟人类高度对齐的打分。本工具是个轻量代理,用一系列文本特征的正则检测来近似每个维度的得分——比如可信度维度,它数你内容里有多少处引用、多少个数据、多少段引述、多少个权威信号词,再据此折算成1到6分。
这种代理方式的好处是免费、秒出、不依赖任何接口,缺点是它逼近的是G-Eval的评估框架和维度结构,而不是大模型那种深层语义判断。所以它的定位是“快速体检”,帮你低成本地定位明显的维度短板和量化优化前后的相对变化;真要做高精度的质量裁决,还得上真实的大模型评估。把它当一把方便的卡尺,而不是精密的实验室仪器。
优化前后对比功能该怎么用?
这工具最实用的功能之一,是优化前后对比,用法就四步。
- 把原始内容粘进第一个框,再填上目标查询词。
- 把你改过的版本粘进第二个框,两个版本针对的是同一个查询。
- 点运行,工具会把两个版本都跑一遍6维度评估。
- 看逐维度的分数变化,哪一维涨了、涨了多少一目了然。
逐维度对比出来之后,你就能精确看到每一处改动落在了哪个维度上,而不是只有一个模糊的整体感觉。
这个对比的价值在于精确归因。你改了一通,到底哪一刀有用、哪一刀白费,光看整体感觉说不清。有了逐维度对比,你能清楚看到:补了三处引用,可信度从2分升到5分,这刀有用;调整了段落结构,清晰度从4分升到5分,小有改善;但相关性还是3分没动,说明你压根没碰到主题匹配这个真正的短板。每次优化都先在工具里跑一次前后对比,把“我觉得改好了”变成“数据显示哪几维改好了、哪维还没动”,决策就不再靠错觉。
出海在线教育站怎么用它给课程介绍页质量定级?
实际工作里接触过一个出海做技能培训的在线教育站,主打编程和设计类的录播课。他们有一批课程介绍页,想知道这些页面在AI搜索里的内容质量到底处在什么水平,于是拿G-Eval 2.0逐页过了一遍。
拿一个“Python数据分析入门课”的介绍页做例子。目标查询填“how to learn python for data analysis”,把页面内容粘进去,第一次评估综合只有C一般,平均2.8分。拆开看维度:相关性4分还行,但可信度只有2分、引用价值2分、信息完整性3分,全是硬伤。诊断很清楚——页面通篇在夸课程多好、讲师多牛,却没有任何可信的数据支撑,也没有适合AI提取的结构化内容。
针对性改了三处:在“学完能做什么”部分补了具体的学习成果数据和往期学员的真实项目案例,把可信度拉起来;开篇加了一句直接回答“零基础学Python数据分析需要多久、按什么路径学”的Answer-First总结,再补了一个常见疑问的FAQ模块,把引用价值做上去;又补全了课程大纲的各模块覆盖,提升信息完整性。
改完重新评估,综合升到A优秀,平均4.6分,可信度和引用价值都到了5分。两个版本一对比,每一维涨了多少清清楚楚,团队内部再讨论“还要不要继续改”时,终于有了数据而不是感觉。后来这套打分流程被固化成了他们课程页上线前的标准动作,每个新页面都得先过一遍6维度体检、补齐低于4分的维度才允许发布,整批课程介绍页的AI可见度肉眼可见地稳了下来。
拿到6维度分之后,薄弱维度该怎么补?
工具会针对每个低分维度给出具体的改进建议,照着做就行。相关性低,确保文章标题和首段包含目标查询的核心关键词,让主题一眼对得上。信息完整性低,补上缺失的内容方面,定义、方法、原因、案例、注意事项这几块查漏补缺。可信度低,加3处以上权威引用来源和具体数据,这是最容易快速见效的一刀。
清晰度低,加H2、H3标题拆分段落,把句长控制在15到40字之间,别让大段文字糊成一团。实用性低,补可操作的建议、步骤和工具推荐,让读者看完真能用上。引用价值低,加Answer-First开头、FAQ模块和Schema标记,把内容做成AI容易提取的结构。补的时候有个优先级原则:先补权重高又分数低的维度,比如可信度18分却只有2分,补它的边际收益最大;那些权重低或者已经4分以上的维度,往后放。
怎样的内容才能拿到A+卓越评级?
A+要求平均分≥5.0,意味着6个维度全都得达到优秀水平,没有任何一项拖后腿。这是个相当高的门槛,通常需要同时满足这几个条件:标题和首段精准匹配目标查询,相关性拉满;内容全面覆盖查询的各个方面,没有明显遗漏;有多处权威引用和具体数据撑着,可信度过硬。
同时还得结构清晰、标题分层、句长适中,读起来不费劲;给出实实在在可操作的建议和步骤,对用户真有帮助;并且采用Answer-First开头、配FAQ模块、打上Schema标记,让AI引擎一眼就能提取。这6条缺一不可。现实中大多数内容卡在可信度和引用价值这两维——前者要你舍得去找权威来源、填真实数据,后者要你愿意按AI友好的结构重组内容,这两件事都得花功夫,但也正是A+和B之间的真正分水岭。
信息完整性这一维,工具怎么判断内容覆盖全不全?
信息完整性权重18,仅次于相关性,它要回答的是“用户围绕这个查询可能关心的方方面面,你都覆盖到了吗”。一个查询背后往往藏着一串子问题,比如“怎么学Python数据分析”,用户其实想知道:要不要数学基础、按什么顺序学、用什么工具、学多久能上手、学完能做什么。这些方面缺得越多,完整性分越低。
工具近似这一维的方式,是检测内容里有没有覆盖定义、方法、原因、案例、注意事项这几类信息块,覆盖得越全分越高。这背后的实战意义是:AI在回答一个复杂查询时,会优先引用那些能一站式回答多个子问题的内容,因为它省事、信息密度高。所以提升完整性不是把内容写长,而是有意识地把查询拆成子问题,逐个补上,让你的内容成为这个查询下的“全科答案”而非“偏科答案”。
引用价值维度为什么对AI搜索特别关键?
引用价值权重14,数字不算最高,但在AI搜索时代它的实际分量被严重低估了。它衡量的是“你的内容好不好被AI提取”。同样优质的信息,一段裹在长句里、没有任何结构标记,和一段做成Answer-First开头加FAQ问答加Schema标记,AI提取的难易度天差地别。前者AI得费劲解析,后者AI能直接整块拎走。
在内容质量本身相当的情况下,引用价值往往就是被不被引用的胜负手。工具检测这一维,看你有没有把直接答案放在开头、有没有问答式的FAQ结构、有没有可被机器读取的结构化标记。提升它的动作很具体:每篇内容开头先用一两句把核心问题直接答了,把常见疑问整理成FAQ,再给关键信息加上结构化数据。这些都是低成本高回报的改造,尤其适合那些质量已经不错、就差临门一脚被AI看见的内容。
清晰度低分,常见是哪些结构问题?
清晰度权重15,看的是内容读起来顺不顺、结构清不清。低分通常栽在几个老毛病上。最常见的是大段文字糊成一坨,一个段落塞了三五个不同的点,读者得自己在脑子里拆,AI解析起来也费劲。其次是标题层级混乱或干脆没有,整篇平铺直叙,没有H2、H3帮读者建立信息骨架。
还有就是句子太长,一句话四五十字还不带停顿,绕来绕去。工具检测清晰度,会看句长是不是控制在合理区间、标题层级是否分明、段落是否适度拆分。改进的方向也对应这几点:一个段落只讲一个点,超过三五行就拆;该用标题分层的地方别省;长句主动断成短句。清晰度提上去,不光评分好看,真实的读者停留和AI提取都会跟着受益。
实用性维度,怎样的内容算对用户真有帮助?
实用性权重15,判断的是内容除了“说得对”,有没有“用得上”。很多内容知识点没错,但全是抽象描述,读者看完知道了概念却不知道该怎么做,这类内容实用性就低。高实用性的内容,会给出可操作的具体步骤、能直接照搬的建议、明确推荐的工具,让读者合上页面就能动手。
工具近似这一维,会检测内容里有没有可操作的建议、步骤化的指引、具体的工具或方法推荐。提升它的关键是把“是什么”往“怎么做”推进一步——讲完一个原理,紧跟着给一个落地的动作;提一个建议,配上具体怎么执行。这一维做得好的内容,不仅评分高,用户的实际反馈也好,因为它真正解决了问题,而AI也更愿意引用这种能直接帮到用户的实操内容。
6维度评估适合中文内容吗?
适合,但有一点要心里有数。这套6维度的评估框架——相关、完整、可信、清晰、有用、好引用——本身是语言无关的,无论中文英文,一篇好内容该满足的标准是相通的,所以拿来评中文内容的质量方向完全成立。
需要注意的是底层的特征检测。工具靠正则识别引用、数据、结构等信号,部分检测逻辑对中英文的适配程度不同,比如句长的合理区间,中文和英文的字符密度不一样,阈值会有差异。实战里建议把工具的分数当方向参考,而不是绝对刻度——它告诉你哪一维是短板、优化前后涨没涨,这个判断对中文内容依然可靠;至于具体分数的小数点,不必抠得太死。结合中文读者的真实阅读体验一起看,结论最稳。
多久该给核心页面重新评一次分?
评估不是一锤子买卖。内容会过时,竞争对手会更新,AI引擎的偏好也在变,今天评出来的A,半年后可能就掉到B了。比较合理的节奏是:核心页面每季度复评一次,重点看可信度维度——数据会过期、引用的来源可能失效,这一维最容易随时间衰减。
除了定期复评,还有几个该立刻重评的时机:内容做了较大改动后,跑一次确认改对了方向;发现某个核心查询的AI引用率掉了,回头评一下是不是质量出了问题;竞品在同一查询下明显发力时,对照评一评自己还有没有优势。把评估变成一个常态化的体检习惯,而不是发布前测一次就再也不管,才能让内容的AI可见度长期稳得住。
G-Eval 2.0和普通GEO评分器有什么不一样?
这两类工具容易混,但侧重点不同。普通的GEO评分器,比如GEO内容评分器,侧重的是从GEO优化策略的角度算可见性,看你用没用上Answer-First、引用、统计这些具体的优化手法,输出的是一个偏向“优化动作清单”的可见性分。
G-Eval 2.0更偏内容质量本身的评判,它的6个维度——相关、完整、可信、清晰、有用、好引用——是从“一篇好内容该是什么样”出发的,跟人类专家评内容的视角更接近,还带优化前后对比。两者可以配合用:先用GEO评分器看优化手法用全了没,再用G-Eval 2.0看内容质量到没到位。如果你想要的是更接近模型判断的效果预测,也可以参考GEO Critic代理评分器那套思路,从代理预测的角度补充判断。
G-Eval 2.0的评分和真实AI引用率挂钩吗?
有正相关,但不是一一对应。6维度评分高的内容,相关性强、信息全、可信、好提取,这些恰恰是AI引用时看重的因素,所以高分内容被引用的概率确实更高,这个大方向是成立的。但分数高不等于一定被引用,因为引用还是相对竞争的结果——你5分,竞品全是6分,照样轮不到你。
更准确的理解是:G-Eval 2.0评的是内容质量的“绝对底子”,决定你有没有被引用的资格;而能不能真正被引用,还取决于同查询下的竞争格局和引擎的随机性。所以实战里这两件事要分开测:用质量评估把自己这篇的底子打扎实,确保6维度没有硬伤;再用可见度模拟放进竞品池看相对位置。质量是基本盘,竞争是临门一脚,两头都顾上才稳。
新手用这工具,最容易踩的坑是什么?
最常见的坑是盯着综合评级,忽略维度明细。看到一个B就急着整体重写,其实展开看可能5维都是5分、只有可信度2分,真正要动的就一处。综合评级是给你一个总体定位,真正指导优化的是维度明细,永远从最低分的维度下手。
第二个坑是把代理分数当成精确真值去抠小数点。工具是规则化代理,4.6和4.7分的差别没有实质意义,有意义的是档位和趋势——是C还是A、优化后涨没涨。第三个坑是只在发布前测一次就不管了,前面说过内容会衰减,评估得常态化。避开这三个坑,这工具就能从“测着玩”变成真正驱动内容质量的抓手。
评估完之后,怎么接进完整的GEO优化流程?
质量评估是优化链路里承上启下的一环。它上承可见度模拟——如果你先用GEO-bench模拟测试平台跑出来发现内容被引用得少、印象分低,下一步就该用G-Eval 2.0做细颗粒度的质量体检,定位到底是可信度、引用价值还是别的哪一维出了问题。模拟告诉你“被引用得不够”,评估告诉你“因为质量的哪一维不行”。
它下接策略执行——拿到6维度的短板诊断后,如果你优化的是内容文章,按维度建议逐项补;如果优化的是电商产品描述,那就换一套电商特化的策略基准,参考电商GEO策略效果对比器去选打法。可见度模拟测“被不被引用”、质量评估测“质量好不好”、策略基准选“该上什么招”,三个工具串成一条从诊断到执行再到验证的闭环,比单用任何一个都更有章法。
常见问题解答
G-Eval 2.0内容质量评估器是用大模型打分的吗?
不是。它是个轻量代理,用文本特征的正则检测来近似每个维度的得分,比如数引用数、数据点、结构标题来折算分数,不调用任何大模型接口。真正的G-Eval需要GPT-4级别的大模型带思维链打分,那才是跟人类高度对齐的评估。本工具逼近的是G-Eval的评估框架和维度结构,定位是免费快速的体检,适合定位短板和量化前后变化,高精度裁决还得上真实大模型。
6个维度的权重可以自己调吗?
工具内置的权重是固定的:相关性20、信息完整性18、可信度18、清晰度15、实用性15、引用价值14。这套权重是按各维度对AI引用的影响程度工程化设定的,相关性作为资格线给了最高权重。一般不需要自己调,照着用就行。如果你的业务对某一维特别敏感,可以在解读结果时心里给它加权,但工具输出的综合评级是按内置权重算的,横向对比不同页面时口径一致反而更有参考性。
综合评级是C,到底是从哪几维拉低的?
看维度明细就知道。综合评级是6个维度平均分的结果,C代表平均分在2.5到3.5之间,说明有维度明显偏低。展开每个维度的分数,找出那几个1到3分的,就是拉低评级的元凶。通常最容易低分的是可信度和引用价值——前者要权威引用和数据,后者要Answer-First和结构化。优先补这两维里权重高的,综合评级往往能快速往上跳一档。
优化前后对比时,两个版本必须改动很大吗?
不必须,恰恰相反,改动越聚焦越能看清效果。对比功能的价值是精确归因,如果你一次只改一类东西,比如只补引用,那跑出来可信度维度的变化就干净地反映了这一刀的效果。改动太杂反而分不清是哪一处起了作用。建议把优化拆成几轮,每轮针对一两个维度改,每轮都跑一次前后对比,逐步把短板维度一个个补上去,比一次大改更可控。
所有维度都到4分了,还有必要继续优化吗?
看页面的重要程度。4分是良好、基本达标,对于一般的长尾页面,6维全4分已经够用,可以把精力转到别的页面。但对于核心页面、想重点抢AI引用的页面,值得继续往5分推,尤其是相关性、可信度、引用价值这三维,它们对能不能被AI引用影响最直接。把核心页从“达标”推到“优秀”,在竞争激烈的查询里往往就是被不被引用的差别。
这个评估结果能直接拿去说服老板或客户吗?
能,而且比口头争论有力得多。它最大的实战价值就是把“我觉得这篇质量不行”变成“6维度里可信度和引用价值都只有2分,这是数据”。优化前后对比更是利器,能直观展示一次改稿让哪几维涨了多少分、综合评级从C升到了A。但记得同时说明它是规则化代理而非大模型精判,给的是相对量级和方向,这样既有说服力又不夸大,沟通起来更扎实。
本文标题:《G-Eval 2.0内容质量评估器怎么用?6维度量表给AI内容打分定级》
本文链接:https://zhangwenbao.com/geo-geval-6-dimension-quality-scoring-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0