多轮AI反馈模拟器怎么用?诊断改写复查迭代拉高GEO得分
本文目录
- 一、为什么内容优化总在原地打转,改完还是不被引用?
- 二、Critic-Rewriter多轮迭代,到底是哪来的硬核思路?
- 三、Critic这个裁判,是按哪9个维度给内容打分的?
- 四、分数是怎么从30分起步一路加上去的?
- 五、Rewriter拿到差评后,具体会动哪些刀?
- 六、工具凭什么决定"够了,可以收手"?
- 七、为什么每轮只改2到3个问题,不一次改完?
- 八、怎么用这套模拟器把一篇内容打磨到能被引用?
- 九、案例:一篇智能手表评测,3轮迭代从42分到81分
- 十、模拟器给的是成品还是脚手架?有哪些局限要认清?
- 十一、用多轮模拟器最容易踩的坑有哪些?
- 十二、它和评分器、改写器这些工具怎么配合?
- 十三、为什么有的内容跑完4轮还是上不了80分?
- 十四、多轮迭代的分数,能拿来横向比较不同文章吗?
- 常见问题解答
- 多轮迭代和单次优化到底差在哪?
- 9个评分维度的分值是论文里的吗?
- 工具会自动帮我改好内容吗?
- 占位符里的示意数字能直接用吗?
- 为什么迭代到4轮就停了?
- 分数刷得越高越好吗?
- 跑模拟器之前需要做什么准备?
- 这工具对中文内容适用吗?
- 权威参考资料
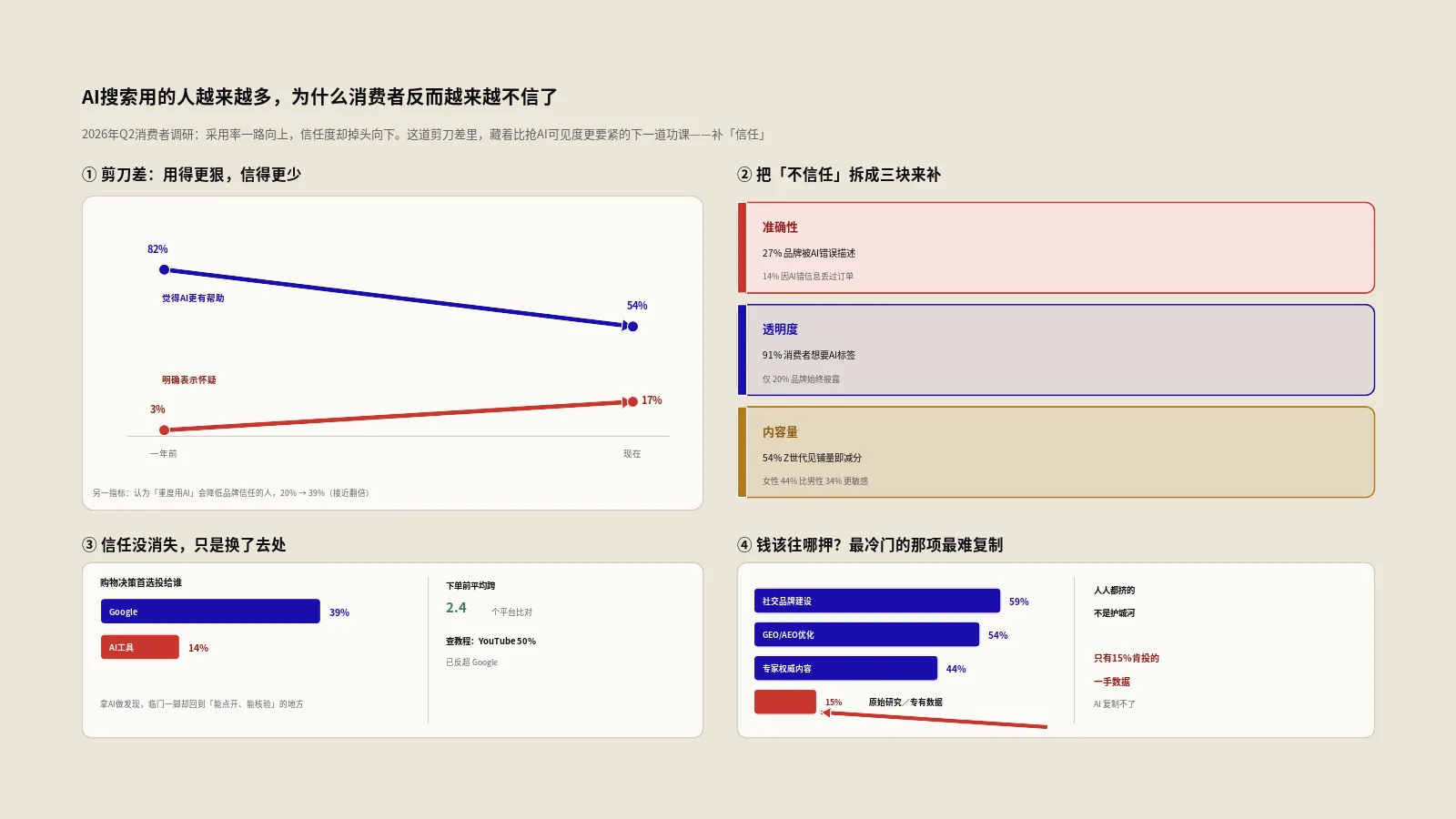
摘要:内容优化最怕的,是改一次就交差,结果还是不被AI引用。多轮反馈模拟器把这个过程做成了循环:它内置一个裁判(Critic)按9个维度给你的内容打分、开出问题清单,再让一个改写器(Rewriter)针对最严重的几个问题动刀,改完重新打分,看涨了多少,然后决定要不要再来一轮。几轮下来,GEO得分从薄弱一路爬到优秀,每一轮改了什么、涨了几分,全程透明可见。这篇把9维度怎么打分、改写器怎么动刀、什么时候该收手,连同一个3轮迭代的真实案例一次讲透。
做内容优化的人,多半都有过这种挫败:对着一篇不被引用的文章,凭感觉东改一句西加一段,改完自我感觉良好,发出去却依然石沉大海。问题出在哪?多半是因为优化成了一锤子买卖——改一次就完事,既没有客观的评判标准,也没有改完之后的复查。
真正的优化,应该像医生看病:先诊断,再开药,然后复查,不行再调方案。多轮反馈模拟器干的,就是把这套"诊断—开药—复查—再调"的循环搬到了内容优化上。保哥这篇就来拆一拆它背后的门道。
一、为什么内容优化总在原地打转,改完还是不被引用?
先说清楚单次优化的死穴。你改一篇文章,通常是凭经验抓几个你觉得有问题的点,改完就发。这里有两个致命缺陷:第一,你的判断是主观的,可能漏掉了真正关键的问题;第二,你没法知道这次改动到底有没有效果,因为没有一个量化的分数前后对比。
结果就是,你以为改好了,其实可能只动了无关紧要的皮毛,真正让AI不愿引用的硬伤——比如开头没有直接答案、通篇没有数据支撑、结构松散——一个没碰。下次还是不被引用,你又凭感觉改一遍,如此往复,原地打转。
迭代优化的思路完全不同。它把每一轮都变成一个有客观评分的闭环:先用统一的标准给内容打分,揪出所有问题并按严重程度排序;然后只改最严重的几个;改完立刻重新打分,用分数的变化验证这次改动是否有效。有效就继续,收益变小就停手。每一步都有数据说话,不再靠感觉。这就是多轮反馈模拟器的核心价值。
二、Critic-Rewriter多轮迭代,到底是哪来的硬核思路?
这套机制不是凭空发明的,它站在两篇论文的肩膀上,这里得把来龙去脉讲诚实了。
最核心的迭代机制,源头是Madaan等人2023年那篇 Self-Refine: Iterative Refinement with Self-Feedback(arXiv 2303.17651)。这篇论文提出了一个很优雅的想法:让模型先生成一个初稿,然后用同一个模型给自己的初稿提反馈,再根据反馈去改,如此反复,形成一个反馈到改进的循环。论文在7类任务上验证,这种自我迭代比一次性生成的效果平均好了约两成。模拟器里"Critic评估、Rewriter改写、再评估"的循环结构,正是这个思路的工程化落地。
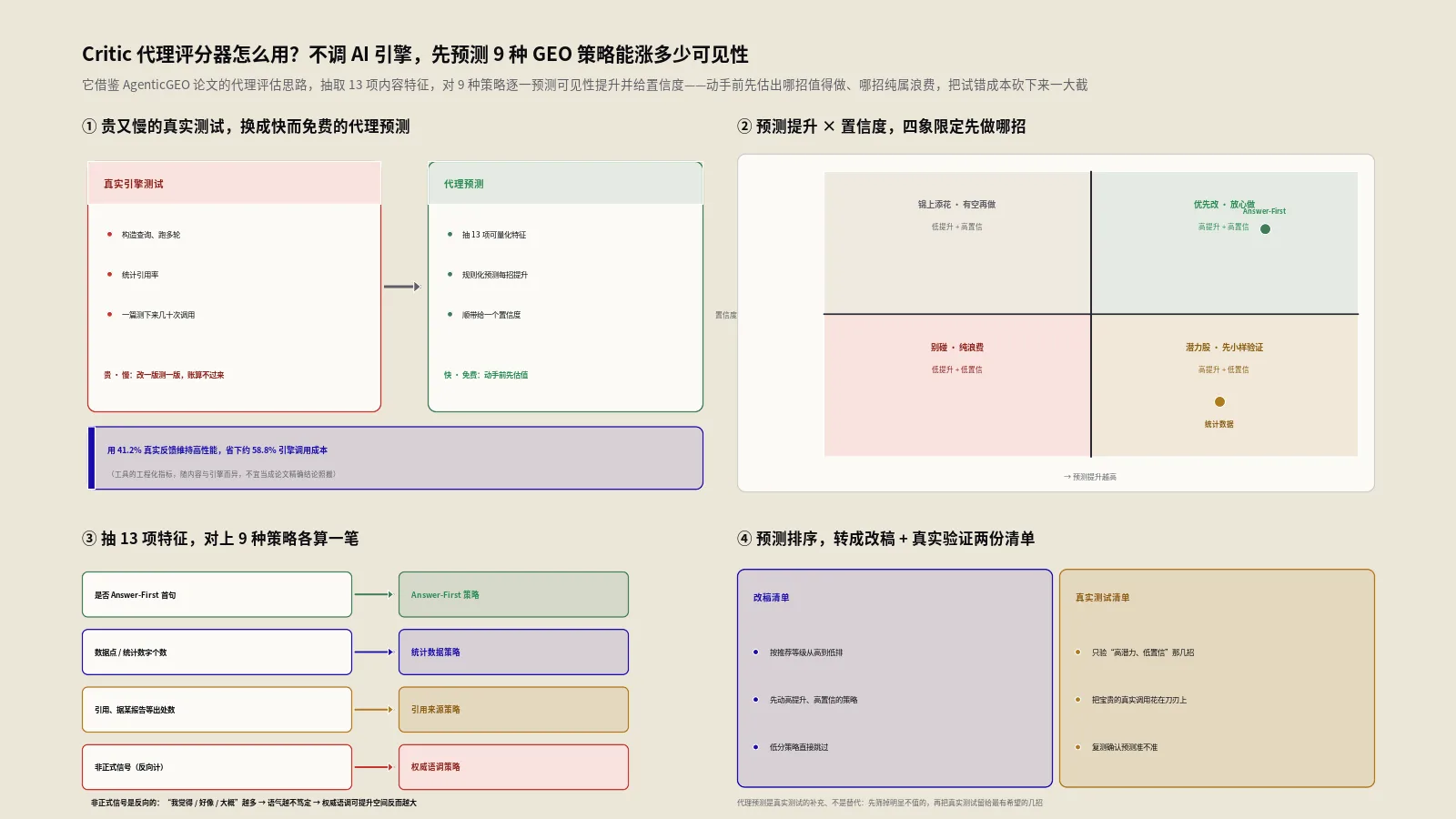
另一个借鉴,来自 AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization(arXiv 2603.20213)里的Co-Evolving Critic设计。这篇论文的Critic,是一个轻量的代理模型,用来逼近真实AI引擎的反馈,从而省去每次都去调用昂贵引擎的成本。模拟器借的就是这个思路——它的Critic不去真的请求ChatGPT或Perplexity,而是用一套规则来逼近AI引擎大概会怎么评判一篇内容。
这里必须说句实在话,免得误导你:模拟器是顺序式的多轮改写(借Self-Refine),而AgenticGEO论文本身用的是更复杂的进化算法框架,两者并不等同。更重要的是,下面要讲的那套9维度评分规则、具体分值和停止阈值,都是工具自己的工程化设定,不是哪篇论文里的现成结论。论文给的是方法论的骨架,分值是保哥团队按GEO实战经验填进去的血肉。这一点拎清楚了,你才能正确地看待工具给出的分数——它是一个内部一致的相对标尺,不是绝对真理。
三、Critic这个裁判,是按哪9个维度给内容打分的?
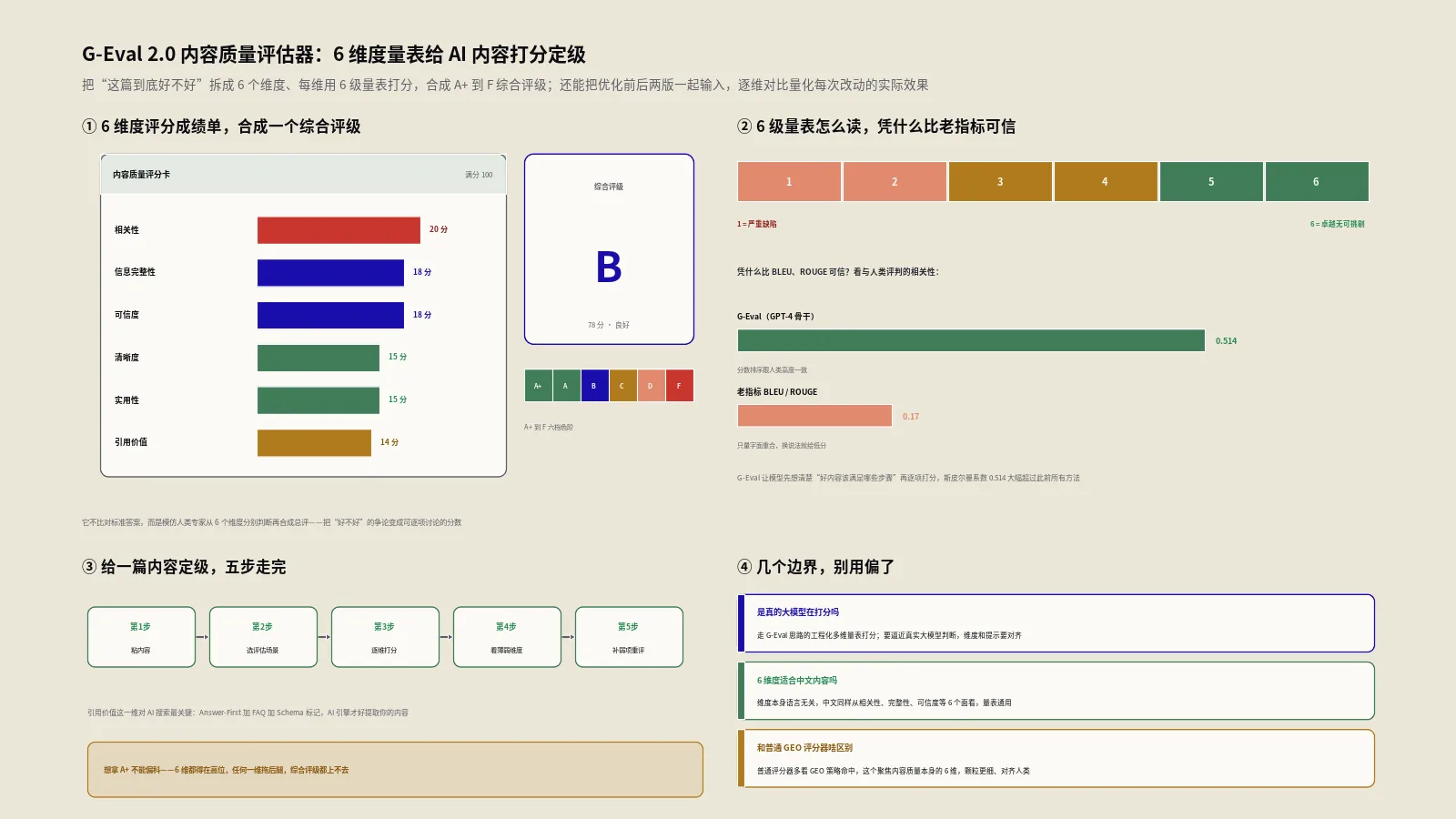
Critic的评分,从30分的基础分起步,然后按9个维度逐项加分。这9个维度,对应的正是普林斯顿团队那篇 GEO: Generative Engine Optimization 论文(arXiv 2311.09735)里验证过的、能提升AI引用率的内容策略。下面这张表把每个维度怎么查、加多少分讲清楚。
| 维度 | 怎么检测 | 加分 |
|---|---|---|
| 答案前置 | 首句是否直接给出定义或答案 | +12 |
| 引用来源 | 网址、据某报告、研究表明等信号 | ≥3个加12,≥1个加6 |
| 统计数据 | 带百分比、倍数、量纲的具体数字 | ≥3个加10,≥1个加5 |
| 结构化 | 标题数乘3,加列表,加表格 | 最高加10 |
| 权威语调 | 研究表明、数据显示等正式表达 | +8 |
| 流畅度 | 平均句长落在18到40字区间 | +8 |
| 专家引述 | 带引号的专家观点引述 | +8 |
| 内容深度 | 总字数,1500字以上最佳 | 最高加8 |
| FAQ模块 | 是否包含常见问题板块 | +5 |
把基础分30加上这9项满分,理论上限刚好压在100分附近,再做一次封顶。最后按总分划档:75分以上是优秀,50到74分是良好,30到49分是需改进,30分以下是薄弱。
这套维度设计有个巧妙之处:它把"被AI引用"这件相对玄学的事,拆成了9个可以机械检测的具体特征。你不用再纠结"我的内容到底够不够好",只要照着9个维度逐项对,缺哪个补哪个,方向非常明确。这也是为什么保哥一直说,GEO优化不是玄学,是有迹可循的工程。
四、分数是怎么从30分起步一路加上去的?
光看表格还不够直观,拿一段真实内容手算一遍你就彻底明白了。假设有这么一段智能手表的产品介绍初稿:一段两百来字的文字,开头没有直接定义,通篇没有任何引用来源,只提了一个"续航7天"的数据,没有任何小标题或列表,语气里还夹着"应该挺不错的"这种不确定表达。
按9维度逐项打分:基础分30;答案前置——首句没直接给定义,0分,记一个高严重度问题;引用来源——一个都没有,0分,又一个高严重度问题;统计数据——有1个,加5分,记一个中严重度问题;结构化——没有任何标题列表表格,0分,再一个高严重度问题;权威语调——没有正式表达反而有不确定语气,0分;流畅度——假设平均句长正常,加8分;专家引述——没有,记一个中严重度问题;内容深度——才两百字远不够,0分加一个低严重度问题;FAQ——没有,0分。
加总:30加5加8,等于43分,落在需改进档。同时积累了一串问题,按严重程度排好序:答案前置、引用、结构这三个高严重度的排在最前面。这就是Critic一轮评估的完整产出——一个分数,加一张排好优先级的问题清单。接下来就轮到Rewriter出手了。
五、Rewriter拿到差评后,具体会动哪些刀?
Rewriter不是漫无目的地乱改,它严格对着Critic列出的问题清单,按问题类型套用对应的改写策略。每种问题都有一套固定的动刀方式。
答案前置缺失,它在开头插入一个直接回答的段落框架,提示你用一句话先把核心答案抛出来。引用缺失,它在文末加一个参考来源的章节模板,留好占位让你填权威链接。数据不足,它会把内容里的模糊词替换成带具体数字的表达,比如把"很多"换成"超过78% 的"——注意这里的数字是示意占位,提醒你去补真实数据,而不是让你直接用。
结构松散,它给你加上H2标题提示和一个FAQ章节模板。语气不确定,它把"我觉得、好像、大概"这类词替换成"研究表明、事实上、精确地说"。句子太长,它会尝试在逗号或分号处把超过60字的长句拆成两句。缺专家引述,它补一段引述模板,留好位置让你填行业专家的观点。
这里要特别拎清楚一个关键局限:Rewriter给的大多是脚手架,不是成品。它加的是占位符和模板框架——"[请填入直接答案]""[补充权威来源]""[专家观点]"——真正的料还得你自己往里填。它替你解决的是"结构上缺什么"的问题,帮你把骨架搭好;但"内容上填什么",机器代替不了你对业务的理解。把这点想明白,你就不会对工具产生不切实际的期待。
六、工具凭什么决定"够了,可以收手"?
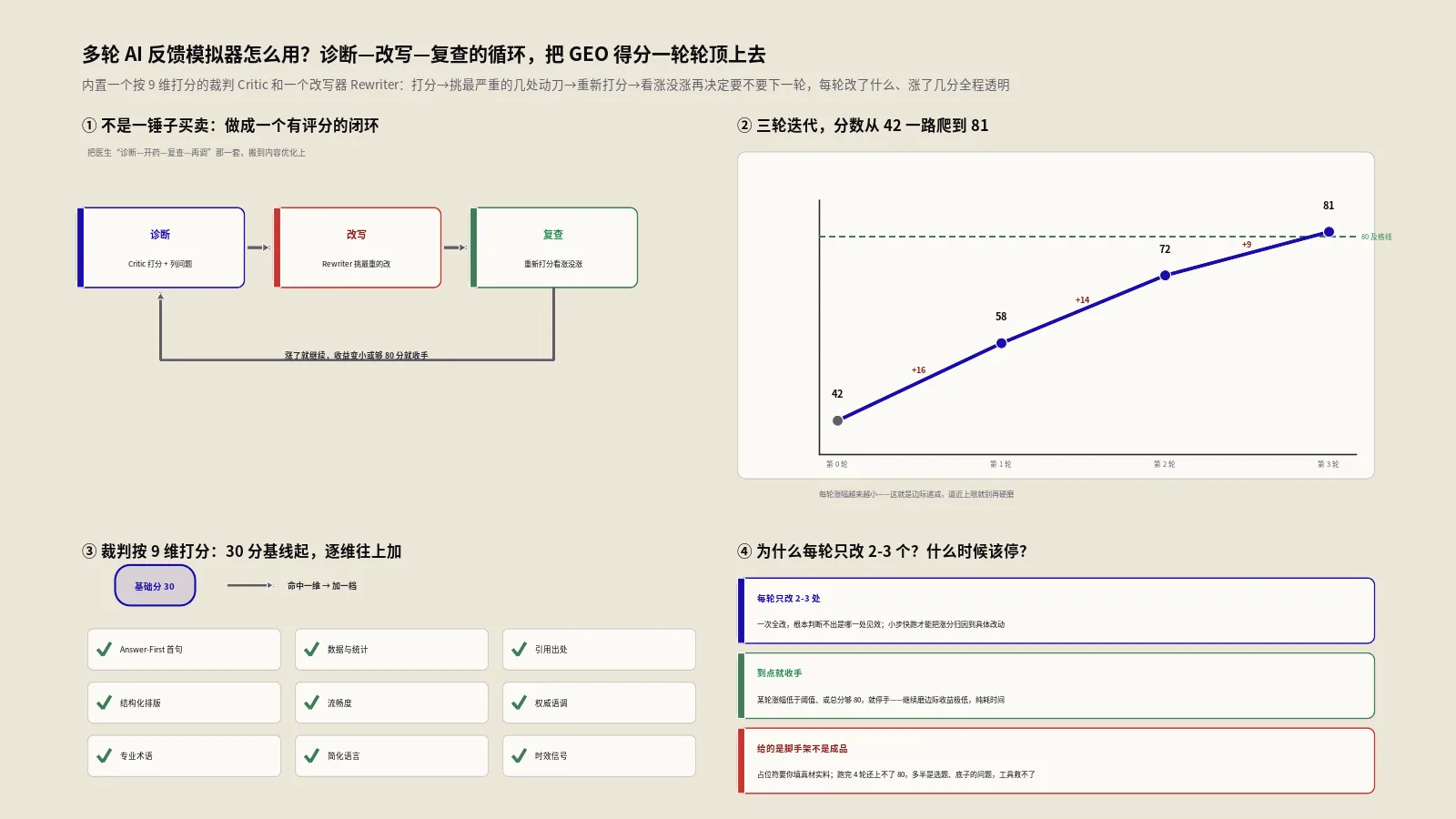
迭代不能无限循环,否则既费时又会陷入过度优化。模拟器内置了三个停止条件,满足任何一个就建议收手。
第一个条件是达标即停:当某一轮的得分达到80分以上,且剩余的问题不超过1个,说明内容已经达到优秀水平,没必要再折腾。第二个条件是轮次封顶:迭代到第4轮就强制停止,因为经验上4轮之后,机械改写能做的都做完了,再往上提升就需要人工深度介入了。
第三个条件最有意思,叫收益递减即停:如果这一轮的得分比上一轮只涨了3分或更少,说明优化已经进入平台期,继续迭代的边际收益太低,不如停下来把精力花在填充真实内容上。这个设计很符合实战直觉——优化到后期,分数的增长一定是越来越慢的,聪明的做法是见好就收,而不是死磕那最后几分。
这三个停止条件合在一起,让整个迭代过程既不会半途而废,也不会用力过猛。它在"改得不够"和"改得过头"之间,划出了一条相当务实的中间线。
七、为什么每轮只改2到3个问题,不一次改完?
你可能会问:既然Critic一次就揪出了所有问题,为什么Rewriter不一口气全改完,非要分好几轮?这背后是个挺讲究的设计哲学。
每一轮,Rewriter只挑严重程度最高的2到3个问题来改。这么做有三个理由。第一,聚焦。一次只改最关键的几个,改动幅度可控,不会把内容搅得面目全非。第二,可验证。改完立刻重新打分,你能清清楚楚看到这几个改动带来了多少分的提升,因果关系一目了然,而不是一锅乱炖之后不知道哪个改动起了作用。
第三,也是最重要的——问题之间是有依赖的。比如你先把结构搭起来(加了H2和FAQ),下一轮再检测内容深度时,标准就变了;你先补了答案前置,专家引述的优先级可能就往后挪了。分轮处理,让每一轮的诊断都建立在上一轮改进后的最新状态上,这比一次性把所有问题拍死要科学得多。这其实也是Self-Refine那套循环的精髓:改进是渐进的,每一步都基于前一步的反馈。
八、怎么用这套模拟器把一篇内容打磨到能被引用?
原理铺垫够了,实操起来就六步一个循环。
第1步,粘贴内容。把你要优化的文章正文粘进去,填上这篇内容想拿下的目标查询词。
第2步,运行第一轮。Critic按9维度给出初始分数,列出所有问题并排好优先级。
第3步,查看改写建议。Rewriter针对最严重的2到3个问题,给出具体的改写方案和占位框架。
第4步,填充真实内容。这是最关键的一步——把工具留下的占位符,换成你自己的真实数据、真实引用、真实观点。脚手架是工具搭的,料得你来填。
第5步,运行下一轮。用填充后的内容再跑一轮,看分数涨了多少,新的问题清单是什么。
第6步,达标即收手。当分数稳定在80分以上,或者每轮提升已经很小,就可以定稿了。
粘贴内容,模拟器内置的Critic会按9个维度给你打分、开出按严重度排序的问题清单,Rewriter针对最严重的几个问题给出改写方案,改完重新打分。诊断、开药、复查一轮轮跑,把GEO得分从薄弱推到优秀,每轮改了什么、涨了多少全程可见。
九、案例:一篇智能手表评测,3轮迭代从42分到81分
去年保哥团队帮一个做跨境智能手表的DTC品牌优化内容。他们有一篇核心评测文章,目标查询是"best budget smartwatch",写得挺卖力,但AI搜索里几乎从不引用它。我们把它丢进模拟器,跑了三轮,过程很有代表性。
第一轮,初始得分42分,需改进档。问题清单很扎眼:开头没有直接回答"哪款平价智能手表最值得买",而是从品牌故事讲起(答案前置缺失,高);通篇没有一个权威引用(引用缺失,高);结构是一大段一大段的流水账,没有小标题(结构松散,高)。Rewriter针对这三个高严重度问题动刀,加了答案前置框架、参考来源章节、H2与FAQ结构。我们照着把占位符填实——开头补了一句直接的推荐结论,引用了两家科技媒体的实测数据,把内容拆成了清晰的章节。重新打分,65分。
第二轮,65分良好档,但还有问题:数据点不足,只有零星几个参数(统计数据不足,中);没有专家或用户的直接引述(专家引述缺失,中);个别地方还有"应该还行"的不确定语气(权威语调,中)。我们补了一张三款手表的参数对比表,塞进了具体的电池容量、防水等级、屏幕亮度数字,引用了一段资深数码博主的评价,把含糊的措辞改成了肯定的表达。再打分,75分。
第三轮,75分,临门一脚。剩下的主要是流畅度(有几个长句超过60字)和内容深度(还能再充实)。我们拆了长句,补了一段"不同预算档位怎么选"的实用建议。第三轮打分81分,达到优秀档,且剩余问题不足两个,触发达标停止条件。三轮收工。
结果没让人失望。这篇文章重新发布六周后,在几个AI搜索引擎里开始被稳定引用,尤其是"平价智能手表推荐""百元智能手表哪个好"这类查询,命中率明显上来了。自然搜索带来的产品页访问翻了一倍多。三轮迭代,分数从42到81,背后是答案前置、权威引用、数据支撑、结构清晰这些实打实的改进——每一分的提升,都对应着内容质量的真实进步。
这个案例还有个容易被忽略的细节值得说:三轮里真正花时间的,不是工具跑分,而是每轮之间填充真实内容那一步。工具几秒钟就给出问题清单和改写框架,但把两家科技媒体的实测数据找来、把三款手表的参数核准、把数码博主的评价征得授权引用,这些活儿前后花了大半天。这恰恰印证了那句话:工具搭脚手架,真料靠人填。把这点认清,你就不会指望跑几轮分数就能凭空变出好内容——它只是帮你把该补的地方一个不漏地标出来,让功夫花在刀刃上。
十、模拟器给的是成品还是脚手架?有哪些局限要认清?
这一节得泼点冷水,免得你对工具期待过高。模拟器最大的局限,前面其实已经反复强调了:它给的是脚手架,不是成品。
它能告诉你"这里缺一个数据",但它变不出真实的数据;它能提示你"这里该有专家引述",但它造不出真实的专家观点。它替换的那些示意数字——比如把"很多"换成"超过78% 的"——是占位符,是提醒你去补真料的标记,绝对不能直接拿去用。如果你偷懒,把这些示意数字当真发出去,那就是在内容里埋假数据,迟早被用户和AI双双识破,得不偿失。
第二个局限,是评分基于规则而非真正的语义理解。Critic检测的是特征的有无——有没有数据、有没有引用、有没有结构,但它判断不了这些数据准不准、引用权不权威、结构合不合理。一篇堆满了无关数据和注水引用的内容,照样能骗到高分。所以高分只是必要条件,不是充分条件,最终的质量把关还得靠人。
第三个局限,是它面向的策略偏通用。9个维度是GEO的通用最佳实践,但不同行业、不同平台的AI引擎,偏好其实有差异。国内的百度、豆包跟海外的ChatGPT、Perplexity,引用逻辑不完全一样。把模拟器当成一个帮你查漏补缺的通用体检仪很合适,但别指望它能替代针对具体平台的精细调优。认清这些边界,你才能把工具用在刀刃上。
十一、用多轮模拟器最容易踩的坑有哪些?
几个高频的使用误区,提前给你打个预防针。
第一,直接用占位符里的示意数字。这是最危险的坑。工具填的"78%""65%"都是示意,是让你替换的,不是让你用的。每一个占位符都必须换成你能背书的真实数据,一个都不能漏。
第二,盲目追求高分。有人非要把分数刷到95分以上才罢休,结果为了凑数据、凑引用,往内容里硬塞一堆无关的东西,可读性反而崩了。记住分数是手段不是目的,80分往上、且内容真实有料,就该收手。
第三,跳过填充直接跑下一轮。有人图快,Rewriter加完占位框架就直接跑下一轮,没把真实内容填进去。这样分数是涨了(因为结构特征满足了),但内容还是空的,纯属自欺欺人。每一轮之间,填充真实内容这步绝对不能省。
第四,忽略目标查询的对齐。模拟器评的是内容质量的通用维度,但它不替你判断内容方向对不对。如果你的内容方向本身就跑偏了(答非所问),那分数再高也没用。所以跑模拟器之前,最好先用意图和覆盖度工具把方向和覆盖面定好,再来打磨质量。
十二、它和评分器、改写器这些工具怎么配合?
多轮反馈模拟器不是孤立的,它在整个GEO工具链里有明确的位置,跟几个兄弟工具配合起来才完整。
往前看,它接的是方向和覆盖。你得先用查询变体覆盖度测试器确保内容覆盖面够广,再用模拟器去打磨质量。方向和覆盖是地基,质量打磨是装修,顺序不能反——在一篇方向错了的内容上反复迭代分数,是白费劲。
横向看,它跟单次评分工具是互补的。如果你只想快速看一眼内容的GEO得分,用GEO内容评分器跑一次就够;但如果你想系统地把一篇内容优化到位,模拟器的多轮迭代更合适,它不只告诉你分数,还带着你一步步改上去。
再往深了说,模拟器的Critic跟GEO Critic代理评分器是同源的思路——都是用轻量代理逼近AI引擎的反馈,区别在于一个偏单点预测,一个偏多轮迭代。而当内容优化定稿、发布上线之后,怎么持续监控引用效果、决定要不要再迭代,那就该交给AI引用率监控闭环了。一整套串下来,从方向到覆盖、到质量、到上线监控,GEO优化才算闭环。
十三、为什么有的内容跑完4轮还是上不了80分?
实战里偶尔会碰到这种情况:一篇内容老老实实跑了4轮,分数却卡在70分上下,怎么都摸不到80分的优秀线。遇到这种优化天花板,通常不是工具的问题,而是内容本身有几类硬伤,机械改写填不平。
最常见的一类,是内容深度先天不足。9维度里内容深度要1500字以上才拿满分,如果你的内容本身就只有六七百字,无论怎么调结构、改语气,深度这一项的分始终上不去,整体就被拖住。这种情况光靠迭代没用,得回去实打实地扩充内容——补案例、补数据、补子话题,把篇幅做厚。
第二类,是缺乏真实的权威背书。引用来源这一项要3个以上权威引用才满分,但如果你的领域本身缺乏可引的权威资料,或者你偷懒没去找,那这一项也补不上。这时候得花真功夫去挖权威来源——行业报告、官方文档、学术研究,找到了引用进去,分自然上来。
第三类,是话题本身不适合堆数据。有些偏感性、偏体验的内容,比如品牌故事、使用感受,天然就没那么多硬数据和统计可放,统计数据这一项很难拿高分。对这类内容,与其硬凑数据把它写得不伦不类,不如接受它在某些维度上分数偏低。记住,80分是个理想目标,不是所有内容都必须达到的铁律,重要的是真实和有用,而不是分数好看。
十四、多轮迭代的分数,能拿来横向比较不同文章吗?
这是个容易误用工具的地方。模拟器给的分数,到底能不能用来比较两篇不同文章谁更好?答案是:可以参考,但要小心。
分数本质上是一把内部一致的尺子。同一篇内容迭代前后的分数对比,是非常可靠的——因为衡量标准完全一样,分数涨了就是真的改好了。但拿两篇主题、篇幅、类型都不同的文章比分数,就得打个折扣。前面说过,有些话题天生不适合堆数据,它的分数偏低不代表质量差,只是不符合某几个维度的偏好而已。
所以更稳妥的用法是:把分数当成同一篇内容纵向进步的标尺,而不是不同内容横向排名的依据。如果非要横向比,也只在同类型、同量级的内容之间比才有意义——比如比较两篇都是产品评测的文章,分数高低还是能说明一些覆盖度和结构上的差距的。
还有个进阶用法,是用分数给一批存量内容做体检排序。把站内同类型的几十篇文章都跑一遍,按分数从低到高排,最低的那批就是优先要优化的对象。这种批量诊断、找出短板的玩法,比一篇篇凭感觉挑要高效得多,特别适合内容量大的站做存量盘点。
一个实操建议:给存量内容做体检排序时,别只看总分,也看每篇卡在哪几个维度。如果你发现一大批文章都栽在引用来源这一项,那说明整个内容团队的引用习惯有系统性问题,与其一篇篇补,不如先立个规矩,所有新内容必须带够权威引用。分数报表看多了,往往能看出团队层面的通病,这比单篇优化更有杠杆。
常见问题解答
多轮迭代和单次优化到底差在哪?
单次优化是凭感觉改一次就完事,没有量化标准也没有复查。多轮迭代每一轮都有客观评分:先打分揪问题,再改最严重的几个,改完重新打分验证效果。每一步都有数据说话,能清楚看到改动是否有效,而不是改完不知道有没有用。
9个评分维度的分值是论文里的吗?
不是。9个维度对应的内容策略来自GEO论文的验证,但具体的分值、基础分30、各维度加几分、停止阈值,都是工具自己的工程化设定。这套分数是一个内部一致的相对标尺,用来横向比较和追踪进步,不是绝对的权威评分。
工具会自动帮我改好内容吗?
不会,它给的是脚手架不是成品。Rewriter加的是占位符和模板框架,比如直接答案的位置、参考来源的章节、专家引述的模板。真正的数据、引用、观点还得你自己填。它解决结构上缺什么,内容上填什么得靠你。
占位符里的示意数字能直接用吗?
绝对不能。像把很多换成超过78% 的,这个78% 是示意占位,是提醒你去补真实数据的标记。直接用等于在内容里埋假数据,迟早被识破。每个占位符都必须换成你能背书的真实数据。
为什么迭代到4轮就停了?
因为经验上4轮之后,机械改写能做的基本都做完了,再往上提升需要人工深度介入。加上还有两个停止条件:分数到80以上且问题不超过1个,或者某轮提升只有3分以内(收益递减)。满足任一个就建议收手,避免过度优化。
分数刷得越高越好吗?
不是。分数是手段不是目的。为了凑高分往内容里硬塞无关数据和引用,可读性会崩,反而伤害体验。80分往上、且内容真实有料就该收手。高分只是必要条件,不是内容好的充分条件,最终质量还得人来把关。
跑模拟器之前需要做什么准备?
最好先把内容方向和覆盖面定好。模拟器评的是质量的通用维度,不替你判断方向对不对。建议先用意图解码器定方向、用查询变体测试器铺覆盖,确认内容答对了问题、覆盖面够广,再用模拟器打磨质量。方向错了,分数再高也没用。
这工具对中文内容适用吗?
大体适用,但要打个折扣。9维度的检测对中英文都做了适配,但部分信号词和句长标准更偏中文习惯调过。更重要的是,国内的百度、豆包跟海外引擎引用偏好不同,模拟器给的是通用体检,具体平台的精细调优还得结合平台特性。当通用查漏工具用很合适,别当平台专用方案。
权威参考资料
归根结底,多轮反馈模拟器教给我们的,不只是一个工具的用法,而是一种内容优化的方法论:别再凭感觉一锤子买卖,把它变成有评分、有复查、可迭代的工程。三件套到这里就齐了——方向用意图解码定,覆盖用查询变体铺,质量用多轮迭代磨。把这套循环跑顺了,内容被AI引用,就不再是碰运气的事。
本文标题:《多轮AI反馈模拟器怎么用?诊断改写复查迭代拉高GEO得分》
本文链接:https://zhangwenbao.com/geo-multi-turn-critic-rewriter-iteration-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0