英文语法检查器靠谱吗?纯规则引擎扫拼写冠词错的能力与边界

本文目录
- 它到底是不是一个“会语法”的检查器?
- 它的检测能力,到底分成哪几大块?
- 拼写检查是怎么做到的?靠一本内置的错词典
- a还是an,它凭什么判断?
- your和you're这类错,它真能分清吗?
- 主谓一致和混淆词,它能逮住哪些固定错型?
- 标点、多空格、俚语这些,它也管吗?
- 它给的那个分数,是怎么算出来的?
- 为什么被动语态被标成“建议”而不是“错误”?
- 英文内容的低级错误,为什么值得在发布前扫一遍?
- 电动牙刷那个站,我们用它扫出了什么?
- AI写的英文内容,还需要用它筛一遍吗?
- 为什么说它最大的风险,是“过度信任”?
- 它会误报吗?哪些情况最容易冤枉好句子?
- 这把规则尺子,量不准哪些东西?
- 纯本地运行,除了快还有什么好处?
- 它该放在内容质检流程的哪一环?
- 低级错误真正损害的,到底是什么?
- 常见问题解答
摘要:这把英文语法检查器,本质是一台纯本地运行的正则规则引擎——它不懂语义、不调用任何AI,全靠一批写死的规则去字面匹配:上百个常见错拼词、a和an的搭配、your跟you're这类易混词、多余空格和被动语态。它的真正价值是发布前的“低级错误粗筛”,几秒钟扫掉那些一眼就丢人的拼写和明显笔误。但你得认清它的天花板:它看不懂上下文,your用得对不对它只看后面那个词;它会误把正确的被动语态、正常的句子标出来;它完全不支持中文,也抓不出复杂从句里的真语法错。把它当一道便宜的初筛,而不是能代替人工校对的编辑。
做出海内容的人都有过这种尴尬:一篇英文落地页发出去了,过两天客户回一句邮件,礼貌地指出标题里有个单词拼错了。recieve 写成了这样、definately 又来一次——这些错误不致命,但它们像衣服上的污渍,让你辛苦打磨的专业形象瞬间打折。
英文语法检查器,就是用来在发布前扫掉这类低级错误的。市面上这类工具很多,从浏览器插件到在线网页都有。这篇要拆解的,是一款轻量的、纯浏览器端运行的规则检查器。搞清楚它的内部逻辑,你才能知道哪些活它能干、哪些活你千万别指望它,从而把它放在内容质检流程里最合适的位置。
它到底是不是一个“会语法”的检查器?
先把最关键的真相摆出来:它不会语法,至少不是你以为的那种“懂”。它的内核是一套纯正则表达式规则——把你输入的文本,拿一条条写死的模式去字面匹配,匹配上了就报一个问题。整个过程没有任何自然语言处理、没有任何AI模型、不理解任何一个词的含义。
这意味着什么?意味着它的能力完全等于那批规则的覆盖范围。规则里写了 teh 要改 the,它就能抓 teh;规则里没写的错误,它就完全看不见。它不是在理解你的句子,而是在拿一张“常见错误清单”逐条对照。理解了这一点,后面所有的能力和局限,你都能推导出来。
还得提一句它的宣传。工具界面上写着“100+ 条规则引擎”“500+ 常见拼写错误”,听着很唬人。但扒开实际逻辑数一数,规则总数大概七十多条,内置的错拼词对是一百零几个。这个数字差距不影响它好不好用,但它提醒你:别被宣传的体量带偏,它就是一份不算大的规则清单,干的是粗活。
它的检测能力,到底分成哪几大块?
把它能干的活归归类,心里会更有数。它的规则大致分这么几块:拼写错拼(高频错词黑名单)、冠词搭配(a和an)、主谓一致(人称和动词配不配)、易混词(your跟you're那一类)、标点(多空格、逗号句号周围的空格)、风格建议(被动语态、俚语口语词)。看着挺全,但每一块的深浅差得远。
这几块里,可信度是分层的。拼写黑名单和标点检查最硬,命中基本就是真问题;冠词和主谓一致中等,覆盖的是常见错型;而易混词和风格建议最软,靠搭配猜、误报多,只能当提醒。用的时候按这个可信度分层去对待结果,比一视同仁地全信或全不信,要靠谱得多。
拼写检查是怎么做到的?靠一本内置的错词典
它的拼写检查,方式朴素得有点可爱:内置了一张“常见错拼对照表”,大概一百多组,左边是高频拼错的写法、右边是正确写法。recieve 对 receive、seperate 对 separate、occured 对 occurred,全是英语母语者都常踩的经典坑。你的文本里只要出现了表左边那些写法,它就标出来、给出右边的正确版本。
这种方式的优点是准——表里有的,几乎不会误报,因为这些错拼本身就不是合法单词。缺点也很明显:表外的拼写错误,它一个都抓不到。你随手把一个词敲错成另一个同样不在表里的错拼,它视而不见;更别说那种“拼写正确但用错词”的情况,比如把 form 写成 from,两个都是合法单词,它根本无能为力。
所以它的拼写检查,本质是“高频错拼黑名单”,而不是真正的拼写校验器。真正的拼写校验得有完整词典做底,逐词查在不在词典里。这款工具没那么重,它赌的是“最常见的那一百多个错拼,覆盖了你日常会犯的大部分低级拼写错”——这个赌注在轻量场景下大体成立,但你心里要清楚它只是黑名单,不是全词典。
a还是an,它凭什么判断?
冠词a和an的误用,是英文里另一类高频低级错。工具对此有几条专门规则,但它的判断逻辑值得细说,因为这里藏着英语的一个常见误区。规则上,它默认元音字母前面该用an、辅音字母前面该用a,这是大多数人学的版本。
但英语真正的规则不是看字母,而是看发音。Purdue OWL的“A versus An”讲得很清楚:用a还是an,取决于后面那个词的开头是不是元音“发音”,而不是元音字母。所以 an hour 是对的——hour的h不发音,开头是元音音;a university 也是对的——university开头虽是元音字母u,但发的是辅音的y音。
这款工具聪明地用了一份小白名单来打补丁:它硬编码了hour、honest这类“字母是辅音但开头发元音”的词,也硬编码了university、unique这类“字母是元音但发辅音音”的词,遇到这些特例就反过来判。但白名单就那么十几个词,覆盖不了所有情况。碰到白名单外的特例,它还是会按字母想当然地判错。这是规则引擎的典型软肋——能处理列进表里的,处理不了表外的。
your和you're这类错,它真能分清吗?
your与you're、its与it's、their与there与they're——这些同音异义的混淆,是英文写作里最招人嫌的低级错。工具对它们也有规则,但实现方式非常“启发式”,理解了你才知道该信它几分。
它的做法不是真的去分析语法结构,而是看“关键词搭配”。比如它有一条规则:your 后面紧跟 welcome,多半是把 you're welcome 写错了,于是标出来。再比如 its 后面跟着 a、the、not 这类词,它怀疑你想写的是 it's。本质上,它是在赌“这几个特定的搭配,出错的概率很高”。
这种打法的问题在于:它只看那紧挨着的一两个词,完全不看整句话在说什么。如果你的 your 用得其实没错,只是恰好后面跟了它盯防的那个词,它照样会冤枉你。反过来,你在它没设防的位置上把your和you're用混了,它一点反应都没有。它能抓的,永远只是那几个被硬编码进规则的高危搭配,不是真正意义上的“分清”。
主谓一致和混淆词,它能逮住哪些固定错型?
主谓一致它有几条规则,盯的都是最常见的人称动词错配。he don't 提示改成 he doesn't、he have 提示 he has、I was 跟 we was 这种人称配错也在盯防范围——全是英语初学者高频踩的坑。但它只认这几个被写进规则的固定组合,稍微复杂一点的主谓结构,它就够不着了。
混淆词也是同一套路数。除了your和you're,它还盯 then 和 than(比较句里常混)、affect 和 effect(动词名词混)、loose 和 lose(多一个o少一个o)、to 和 too(该强调“太”的时候漏了一个o)。这些都是英文里出了名的高频混淆对,母语者也常写错。
但和易混词一样,它的判断全靠字面搭配,不看语义。affect 和 effect 到底该用哪个,得看整句话在说什么,它只能看到这个词出现了、提个醒,没法替你定夺。所以这些提示同样是“嫌疑”级别,得你自己结合句意去确认,别看到标红就闭眼改。
标点、多空格、俚语这些,它也管吗?
管,而且标点这块还是它比较靠谱的一档。它能抓出连续的多个空格、逗号后面忘了加空格、逗号或句号前面多了空格、省略号点太多之类的格式毛病。这些都是规则明确、几乎不会误判的机械错,扫一遍清掉,文本立刻清爽不少,也显得更专业。
俚语和口语词它也盯,内置了二十来个最常见的,gonna 提示 going to、wanna 提示 want to,还有 kinda、gotta 这种。在正式的商业文案、产品描述里,这些口语词显得不够专业,工具帮你标出来,你可以斟酌要不要换成正式说法。
不过这个俚语库就二十来个词,覆盖很有限,稍微生僻点的口语、网络缩写它就认不出了。和它别的能力一样,这块也是“常见的能抓、生僻的漏掉”。把标点当成它的强项、俚语当成顺手的辅助,这个定位就对了。
它给的那个分数,是怎么算出来的?
工具会给你的文本打一个一百分制的分。这个分不是什么玄学,公式很直白:从一百分起扣,扣多少取决于错误的“加权数量”除以文本长度。错误越多、文本越短,扣得越狠;同样数量的错误,摊在一篇长文里,扣分就轻。
不同类型的错误,权重还不一样。语法类的错最重,拼写次之,标点更轻,风格类(比如被动语态)最轻。这个设计是合理的——一个语法错比一个多余空格严重得多,分数理应区别对待。它还设了个上限,最多报两百个问题,超了就不再往下列,免得一篇满是错的文本把界面撑爆。
但这个分数你得辩证地看。它衡量的只是“踩中了多少条规则”,而不是“英语写得好不好”。一篇用词地道、逻辑清晰但恰好有两个错拼的好文章,分数可能比一篇平庸但规规矩矩的文章还低。把它当一个“低级错误密度”的粗略指示灯就好,别把它当英文水平的成绩单,那是它扛不起的评价。
为什么被动语态被标成“建议”而不是“错误”?
工具里有一条检测被动语态的规则,但它很有分寸地把命中结果标成“风格建议”,而不是“错误”。这个克制非常对。被动语态根本不是语法错误,很多时候它还是更恰当的选择。
Purdue OWL关于主动与被动语态的说明里就指出:当动作的执行者不重要、未知,或者你想强调被作用的对象时,被动语态是有效且恰当的;科学写作里更是惯用被动。所以一刀切地把被动语态全打成错误,是外行做法,这款工具没犯这个错,值得肯定。
它检测的方式依然是正则:盯着“be动词加上一批特定过去分词”的模式。问题在于,这种字面匹配会误伤。比如 The report was based on data 里的 based,其实更像形容词,整句不是典型的被动滥用,但它照样会标出来。所以被动语态那些提示,你扫一眼、自己判断要不要改即可,它只是提个醒,远不是定论。
英文内容的低级错误,为什么值得在发布前扫一遍?
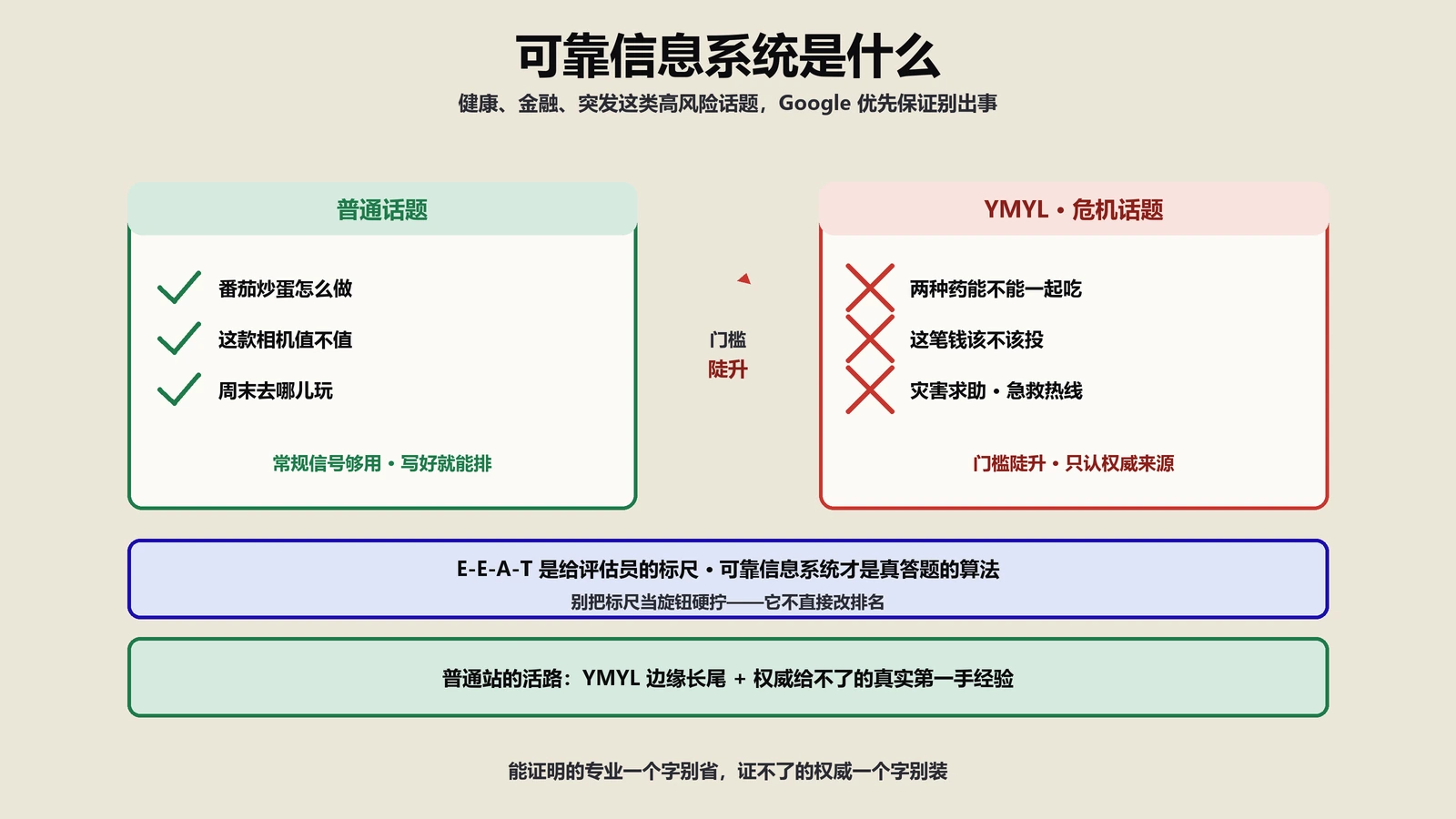
有人觉得,几个拼写错无伤大雅,读者能看懂就行。但在出海SEO的语境里,这事没那么轻飘。Google关于打造有用内容的指南里,明确把“内容是否有拼写或风格问题”列进了评估内容质量的自查清单——低级错误是会拖累内容可信度的信号之一。
更现实的是用户感受。一个英文落地页满是拼写错,海外用户的第一反应往往是“这家不专业,甚至可能是骗子”,转化率和信任度直接受损。E-E-A-T里的可信度,恰恰是从这些细节里一点点攒起来或败掉的。低级错误就像服务员衬衫上的污渍,菜可能很好吃,但客人已经先皱了眉。
所以发布前花几秒钟扫一道,性价比极高。它挡不住所有错,但能挡掉那些最显眼、最伤形象的低级笔误。这道粗筛的意义不在于“完美”,而在于“兜底”——别让一个本可以避免的拼写错,毁了整页内容的第一印象。
电动牙刷那个站,我们用它扫出了什么?
去年帮一个做电动牙刷的出海站做内容审计,他们的英文产品描述是外包翻译的,量很大、价格很便宜。我们抽了几十个页面,先用这把检查器粗扫一遍,结果挺能说明问题:高频错拼一抓一大把,occured、seperate 这种经典错遍地都是,冠词a/an也错了不少。
但更值得说的是它没扫出来的那些。我们人工复核时发现,真正影响阅读的问题——句子结构生硬、时态前后不一致、用词不地道——这些它一个都没标,因为这些超出了它那套字面规则的能力。换句话说,它帮我们快速清掉了“脏”,但“不通顺”“不地道”这些更深的毛病,还得靠人。
所以那次审计我们的用法是:先拿工具把所有页面粗扫一遍,批量清掉低级错拼和冠词错,这一步又快又省;再把页面交给懂行的母语编辑做精校,专攻地道和流畅。工具负责扫地,编辑负责装修,分工明确,效率比一上来就全靠人工高得多,成本也压下来了。
AI写的英文内容,还需要用它筛一遍吗?
这是个越来越常见的场景。现在很多出海团队用AI批量生成英文内容,有人觉得机器出来的英文不会有低级拼写错,没必要再筛。这个判断对了一半:AI生成的文本,经典的拼写错确实很少,那张错拼黑名单大概率扫不出几个来。
但机器生成的内容有它自己的毛病。它可能在某些语境下用词不当、可能冒出不符合品牌调性的口语化表达、也可能在多轮编辑拼接之后引入多余空格、标点不规范这类格式问题。这些恰恰是规则检查器的强项——它不在乎内容是人写的还是机器写的,只忠实地按规则去扫格式和搭配。
所以即便是AI生成的内容,发布前用它过一道也不亏,成本就几秒钟。它扫的是格式和机械层面的整洁度,和AI擅长的内容生成是两个维度的事,正好互补。把它当成AI内容流水线末端的一道格式质检,是个挺合适的安排。
为什么说它最大的风险,是“过度信任”?
用这类工具,最危险的不是它能力有限,而是用的人不知道它能力有限。一旦你默认“它没报错就等于英文没问题”,就会放松本该有的人工把关,让那些它根本看不见的深层问题——生硬的句式、不地道的表达、复杂的语法错——堂而皇之地发出去,还以为已经检查过了。
反过来,过度信任它报出的每一条,也会出问题。前面说了它误报不少,尤其被动语态和易混词那两档。要是你看到标红就无脑全改,很可能把本来正确、甚至更好的表达给改坏了。这两种过度信任,一种让你漏掉真问题,一种让你改错对的地方,都是实打实的坑。
正确的心态,是把它当一个“话不多、但偶尔会看走眼的助手”:它提的醒值得听,但每一条都要你自己拍板。它负责把可疑的地方圈出来,判断权始终攥在你手里。守住这个边界,它就是个趁手的工具;一旦把判断权也交出去,它就成了误导你的源头。
它会误报吗?哪些情况最容易冤枉好句子?
会,而且误报是规则引擎的固有毛病,你必须有心理预期。最典型的就是上面说的被动语态——很多其实是形容词、或者本就该用被动的句子,会被无差别地标出来。被动那一档的提示,误报率是几档里最高的。
其次是那些“看搭配猜错误”的易混词规则。你的 your、its 用得明明没错,只因为后面恰好跟了它盯防的词,就被点名。还有 affect 和 effect、loose 和 lose 这类,它只看单词出现、不看实际语义,判断只能算“提个醒”,相当一部分是虚惊。
正确的态度是:把它给的每一条都当“待核查的嫌疑”,而不是“已确认的错误”。拼写黑名单那部分基本可信,但易混词和风格类提示,你得逐条用脑子过一遍,确认是真错才改。指望它给的结果零误报、闭眼全改,反而会把本来对的地方改错。
这把规则尺子,量不准哪些东西?
把它的能力边界一次性说清。第一,它完全不支持中文,只认英文,给它中文它什么也干不了。第二,它没有任何语义理解,看不懂上下文,所有判断都停留在字面模式匹配这一层,前面反复强调过。
第三,它抓不到复杂的真语法错。逗号拼接、悬垂修饰语、代词指代不清、复杂从句的时态混乱——这些需要真正分析句子结构才能发现的问题,它的规则覆盖不到,全是漏网之鱼。它能抓的,是he don't、between you and I这种被写进规则的固定错型。
第四,它的俚语和口语词库也很小,就二十来个,gonna、wanna 这种最常见的能认,稍微生僻点的口语就漏了。把这些边界连起来看——不支持中文、没有语义、抓不到复杂语法错、词库都不大——你就明白它的定位:一把只能量“常见低级错”的小尺子,量不了“写得好不好”这件大事。
纯本地运行,除了快还有什么好处?
它整套规则都跑在你自己浏览器里,文本不上传任何服务器,这点在内容安全上是实打实的好处。你要检查的可能是还没发布的新品文案、是带着商业机密的产品描述,本地处理意味着这些内容不会经过第三方、不会被留存,省去了一层泄密的担忧。
即开即用也是优势。不用注册、不用登录、不消耗任何额度,打开网页粘进文本就出结果。临时要扫一段英文、手边又没有专业工具的时候,这种零门槛的便利很顶用。当然,便利的代价就是能力有限——它换来的是隐私和速度,牺牲的是深度,这笔账你心里得算清楚。
它该放在内容质检流程的哪一环?
定位对了,它就好用;定位错了,就会害你。它的正确位置,是内容质检流程的最前端、最粗的那一道初筛。英文初稿出来,先用它过一遍,几秒钟批量清掉错拼、冠词、多余空格这些机械错误,把后面人工或AI精校的负担减下来。
- 整段粘贴,一键粗扫。把英文初稿整段贴进工具跑一遍,让它把所有命中规则的拼写错、冠词错、多余空格、易混词一次性都标出来,先拿到一张问题清单。
- 按可信度分层处理。拼写黑名单和标点这类硬错,确认后直接改;被动语态和易混词这类软提示,逐条结合句意判断,是真错才动手,别看到标红就无脑全改。
- 交给母语者精校。机械错清完后,把内容交给懂行的人或更专业的工具,专攻句子是否地道、逻辑是否通顺这些规则引擎根本看不见的深层问题。
这一步之后,才轮到更深的检查。比如内容的可读性、句子的难易节奏,可以接可读性评分器看难度分布;篇幅是否达标、字数够不够,用字数统计工具核一遍。这些工具各管一段,串起来才是一条完整的内容质检线,而语法检查器是其中负责“扫地”的第一棒。
它也是出海内容发布前那套技术自查的一环。和盘点外链域名的域名提取器、核对网址编码的URI编解码器放在一起,构成内容真正推出去之前的几道关卡。每道关卡都不贵,但每道都能挡掉一类发出去才后悔的事故。
低级错误真正损害的,到底是什么?
把视角拉远一点看,发布前扫低级错这件事,价值远不止“改对几个单词”。真正受损的,是品牌在海外用户心里的信任账户。一个拼写错也许只值一秒钟的尴尬,但当一个页面里这样的错堆叠起来,用户对整个品牌的判断,就会悄悄滑向“这家不太靠谱”。
这种损害是隐性的、累积的,也是最难量化的。你很难统计到底有多少潜在客户,因为一个低级错就默默关掉了页面、转头去了竞品。正因为难量化,它常被忽视;可恰恰是这些看不见的流失,在持续地侵蚀着转化率。发布前那几秒钟的检查,挡住的就是这类悄无声息的损失。
对出海品牌来说,英文是门面,门面上的污渍再小也是污渍。工具的能力虽然有限,但它守的正是这道门面的底线——把那些最显眼、最伤信任的低级错,挡在上线之前。从这个角度说,它扫掉的不是几个单词,而是一个个本可能因为糟糕第一印象而流失的客户。
常见问题解答
它能代替Grammarly这类专业工具吗?不能,两者根本不在一个量级。专业工具背后有完整词典、有真正的自然语言处理、甚至有AI模型,能理解上下文、能抓复杂语法错。这款工具是纯正则规则引擎,只能抓被写进规则的那批常见低级错。它的定位是轻量、即开即用、数据本地不外传的快速粗筛,不是专业校对的替代品。
为什么我明明拼错了,它却没标出来?因为它的拼写检查靠的是一份一百多个词的“高频错拼黑名单”,不是完整词典。你拼错的那个词如果不在这份黑名单里,它就抓不到。尤其是“拼写正确但用错词”的情况,比如把form写成from,两个都是合法单词,它更是完全无能为力。它的拼写能力,就是这份黑名单的边界。
被动语态的提示,要不要全改成主动?不要。被动语态不是错误,很多时候还是更恰当的选择,尤其在强调动作对象、或执行者不重要时。工具把它标成“建议”而非“错误”正是这个道理。那些提示你扫一眼、自己判断,该用被动的地方坚决留着,别被工具带着无脑改成主动,那样反而会让句子变别扭。
它支持检查中文内容吗?完全不支持。它的所有规则都是为英文设计的,错拼表、冠词规则、易混词全是英文。给它中文文本,它要么什么都不报、要么报出毫无意义的结果。中文内容的检查,得用别的针对中文的工具。
用它扫完没报错,是不是就说明英文没问题了?绝对不能这么理解。没报错只意味着“没踩中它那七十多条规则”,不代表内容真的没问题。句子生硬、用词不地道、复杂语法错、逻辑不清——这些它统统看不见。它扫干净只是清掉了最表层的低级错,真正的质量,还得靠懂英文的人去把关。
本文标题:《英文语法检查器靠谱吗?纯规则引擎扫拼写冠词错的能力与边界》
本文链接:https://zhangwenbao.com/grammar-checker-rule-based-english-proofreading-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0