URI编解码器怎么用?中文URL编码、UTM参数转码与GSC乱码网址还原
本文目录
- 编码、解码到底在折腾什么?
- 编码和加密,是不是一回事?
- 为什么同一个汉字,编出来三种结果都不一样?
- component、uri、full三种模式,分别该用在哪?
- 空格为什么有时变 %20、有时变加号?
- 解码时,为什么加号有时变空格、有时不变?
- 哪些字符必须编码,哪些动都不能动?
- URL解析功能,能帮你看清一条乱码网址的真身吗?
- 给中文关键词做UTM追踪链接,正确姿势是什么?
- 编码后网址膨胀了一截,这个膨胀率有什么用?
- 机械键盘那个站,我们靠它排掉了什么坑?
- 批量处理一批网址,有什么上限要注意?
- 编码后的网址放进sitemap,有什么格式要求?
- 查询参数的顺序和重复,会被当成不同网址吗?
- 把历史遗留的加号编码链接批量统一,值得做吗?
- 编码不统一,会给技术SEO埋下什么隐患?
- 一个汉字三段、一个表情四段,这些字节是怎么算的?
- 解码时碰到残缺或非法的百分号,会出什么岔子?
- 编码这一步,放前端做还是后端做更稳?
- 这个工具碰不了哪些硬骨头?
- 编解码器算不算技术内容“发布前自查”的一环?
- 常见问题解答
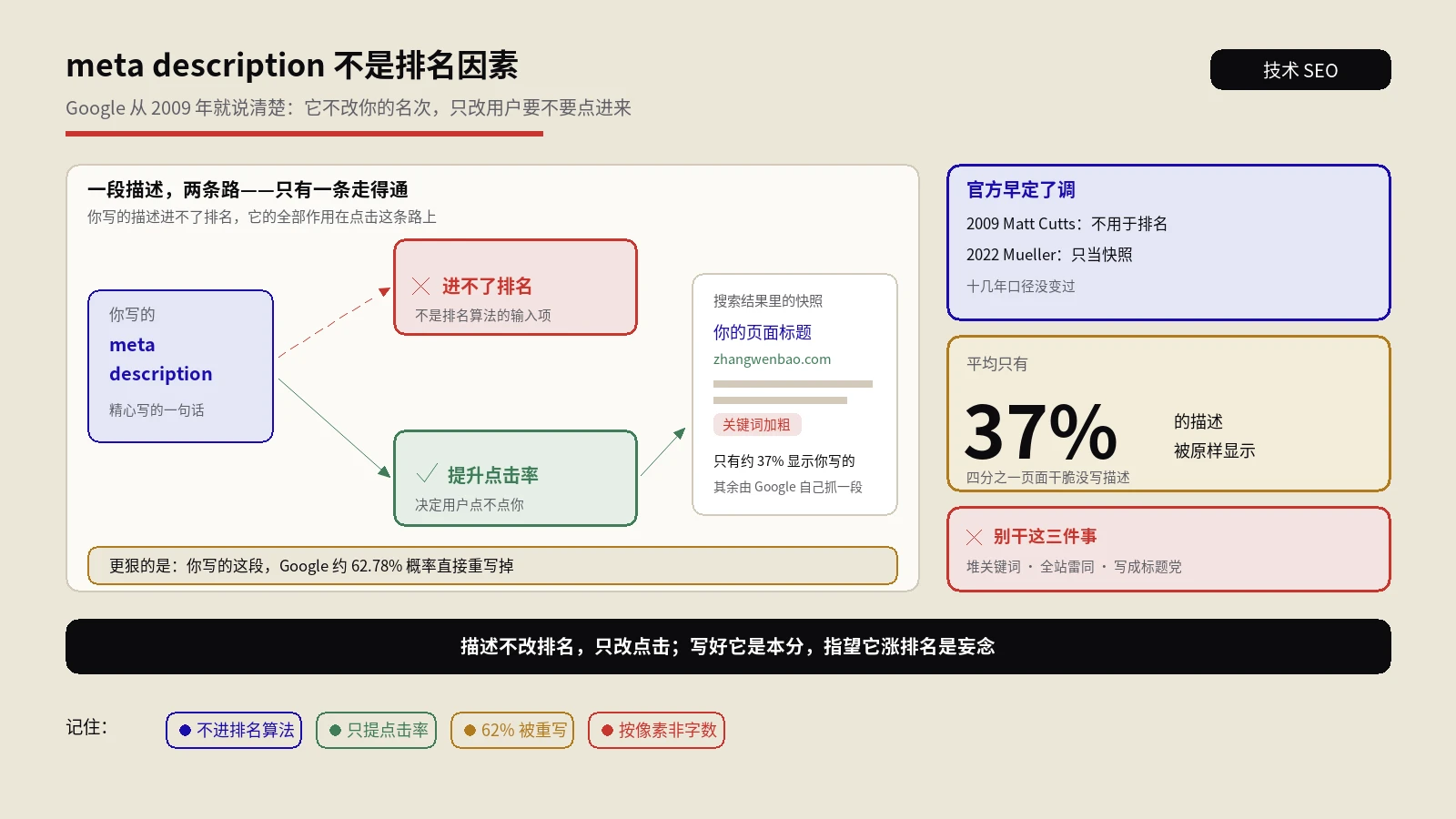
摘要:URI编解码器解决的是一个看着小、踩起来疼的问题——网址里只要塞了中文、空格或者特殊符号,就必须转成百分号开头的那串编码,否则链接会断、参数会丢、追踪会乱。这个工具把编码、解码、URL结构拆解三件事捏在一起,还提供了三种编码模式让你按场景挑。难点恰恰在那三种模式:同一个汉字,按整段网址编、按单个参数编、按表单方式编,结果就是不一样,用错了照样出问题。它还能把一条满屏百分号的乱码网址拆回人能读的样子,这在排查GSC里的怪URL时特别管用。但它不认中文域名的国际化编码、不替你规范化路径、字符集也锁死了UTF-8,这些边界得心里有数。
做技术SEO的人,迟早会撞上这么一类问题:明明在后台填的是中文搜索词、是带空格的活动名,链接一发出去就变成了一长串 %E4%BD%A0 这样的天书;或者反过来,GSC的覆盖率报告里冒出一条满屏百分号的怪URL,你盯着它半天,认不出这到底是站里哪个页面。
这两个方向的麻烦,根子是同一件事——URL编码。网址这东西能用的字符其实很有限,超出范围的内容都得转成百分号加十六进制的形式才能安全传输。把人能读的内容转成这串编码,叫编码;把这串编码还原回人能读的样子,叫解码。URI编解码器,就是同时干这两件事、外加帮你把网址结构拆开看的工具。
它本身不复杂,复杂的是背后那套规则,以及规则里几个特别容易绊倒人的细节。这篇就把编码到底在编什么、三种模式差在哪、空格和加号那点恩怨、怎么用它给中文做追踪链接、又有哪些它根本碰不了的硬骨头,一次性讲清楚。
编码、解码到底在折腾什么?
先从最基础的讲起。一条网址,按规范只允许出现一小撮安全字符:大小写字母、数字,再加上几个像连字符、点号这样的符号。除此之外的东西——汉字、空格、问号、和号——要么有特殊语法含义、要么压根不在允许范围内,直接塞进网址会让浏览器或服务器犯迷糊。
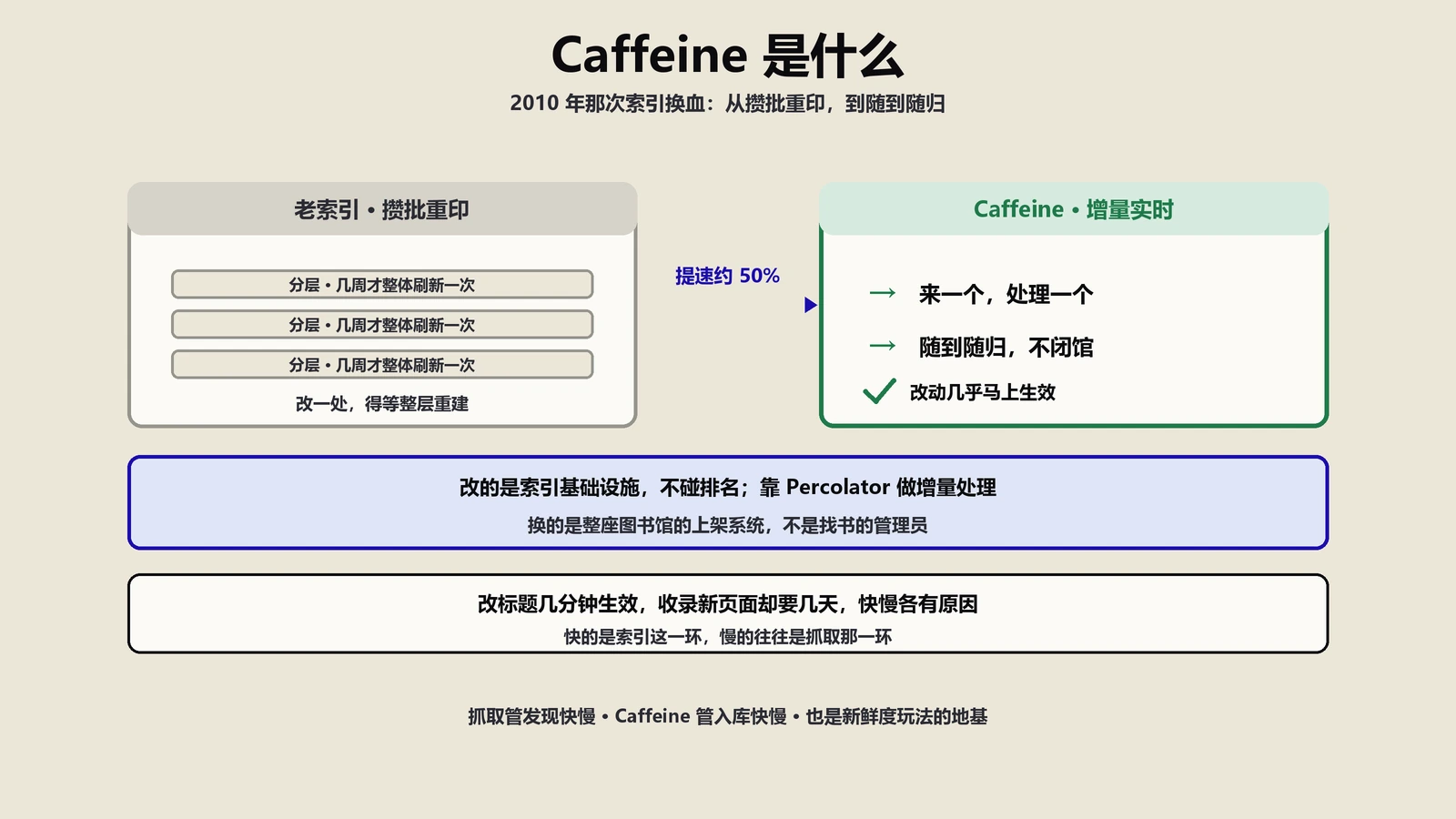
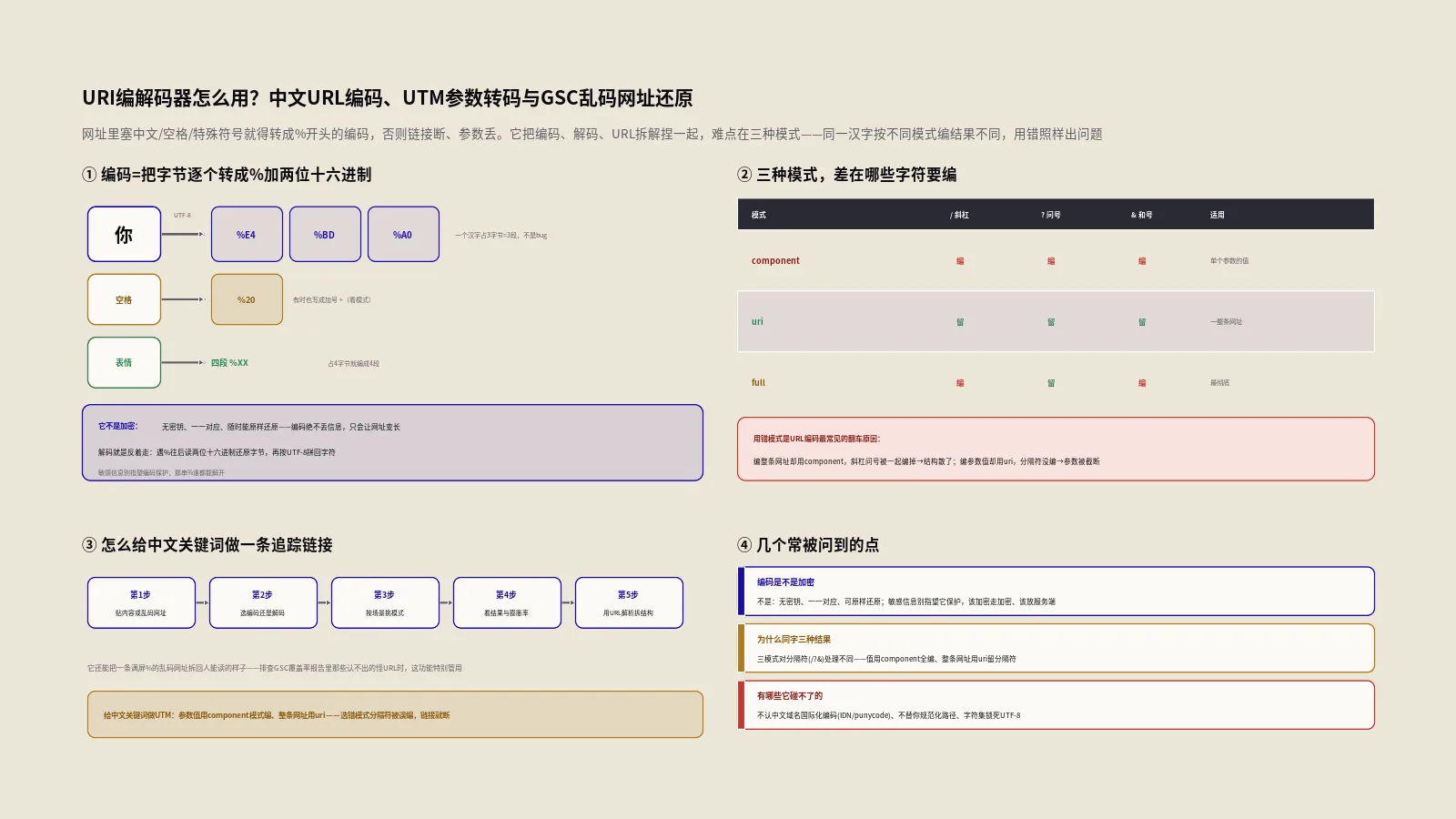
百分号编码就是为了解决这个。它的规则朴素到近乎笨:把那个字符在底层的字节,一个字节一个字节地,转写成“百分号加两位十六进制”。一个英文字母占一个字节,编出来就是一个百分号片段;一个汉字在UTF-8下占三个字节,编出来就是三段百分号片段连在一起。所以一个“你”字会变成 %E4%BD%A0,三段,不是它出了bug,是它本来就占三个字节。
解码是反过来走一遍:遇到百分号就往后读两位十六进制,还原成那个字节,再按UTF-8把字节拼回字符。理解了这个底层机制,你就不会再被那串天书吓到——它不是加密,没有密钥,就是个一一对应的转写,任何时候都能原样还原。这也是为什么编码绝不会丢信息,只会让网址变长。
编码和加密,是不是一回事?
这是个特别普遍的误解。看到一串看不懂的 %E4%BD%A0,很多人第一反应是“这是不是加密了”。不是。编码和加密是两码事:加密的目的是让没有密钥的人看不懂、是为了保密;而百分号编码毫无保密意图,它就是个公开的、一一对应的转写规则,任何人都能照着规则原样还原回去。
把这点想清楚很重要,因为它直接影响你怎么对待网址里的编码内容。编码后的参数,该脱敏的还得脱敏——别以为编了码就安全了,那串百分号谁都能解开。真正的敏感信息,该走加密、该放服务端,绝不能指望URL编码来保护,它压根没这个能力。
反过来,也别把编码想得太玄乎。它不会改变内容的含义、不会丢信息、不需要任何密钥,就是个为了让内容能安全地在网址里传输而做的格式转换。看懂了这层,你面对满屏百分号时就不会再发怵,知道它随时能还原成人话。
为什么同一个汉字,编出来三种结果都不一样?
这是整个工具最该搞懂的地方。它提供了三种编码模式,对应着三套略有差异的规则,名字分别叫component、uri和full。同一段输入,挑不同模式,输出可能不一样——而用错模式,恰恰是URL编码最常见的翻车原因。
差异的核心,在于“哪些字符要编、哪些字符放过”。网址里有一批字符是有语法职责的,比如斜杠分隔路径、问号引出查询串、和号分隔参数。问题来了:当你编码的是一整条网址时,这些分隔符得保留原样,否则结构就散了;可当你编码的只是某个参数的值时,这些分隔符必须被编掉,否则它们会被误当成结构的一部分,把参数搅乱。
component模式最严格,把所有有语法含义的字符统统编码,只放过那一小撮绝对安全的字符——这对应着前端常用的encodeURIComponent,专门用来编“网址的一个零件”,比如单个参数值。uri模式宽松些,它保留了斜杠、问号、井号这些结构字符,适合编一整条完整网址。这两者的区别,MDN的encodeURIComponent文档讲得最清楚:后者会比前者多编一批属于URI语法的字符。
第三种full模式,对应的是另一套更老的表单编码习惯,它和component几乎一样严格,唯独在空格的处理上分了岔——这个岔口太重要,下面单开一节讲。先记住一句话:编参数值用component,编整条网址用uri,对接老式表单提交用full。
component、uri、full三种模式,分别该用在哪?
把场景对号入座,比死记规则管用。你手上要编的,如果是一个要拼进网址的“值”——搜索关键词、活动名、商品标题、一个中文标签——那就用component,它会把这个值里所有可能破坏网址结构的字符都老实编掉,拼进去绝对安全。这是日常用得最多的一种。
如果你手上是一整条已经组装好的网址,只是想把里面的非法字符补编一下、又不想破坏它的结构,那用uri。它会很有分寸地放过斜杠、问号这些骨架字符,只编那些确实越界的内容。注意,uri模式不能用来编参数值——因为它会放过和号,而参数值里万一真有个和号,就会被误读成参数分隔符,把后面的内容截断。
full模式的使用场景相对窄,主要是和那些遵循老式表单编码约定的系统对接时用。很多后端语言里默认的URL编码函数,走的就是这套约定。如果你发现按component编出来的链接,对方系统解出来空格变成了别的东西,那多半就是两边的空格约定没对上,这时候切到full试试。
选错模式的后果,轻则参数值里的特殊字符没编、链接点开就报错或丢参数,重则结构字符被乱编、整条网址直接失效。所以别嫌三种模式麻烦,它不是在炫技,是真有三种不同的活要干。拿不准时有个笨办法:编单独一个值,无脑选component,基本不会错。
空格为什么有时变 %20、有时变加号?
空格是URL编码里最经典的一个坑。同样一个空格,有的工具编出来是 %20,有的编出来是个加号,两边还都振振有词说自己对。这不是谁错了,是历史上留下了两套并存的约定。
按RFC 3986这套现代规范,空格就该编成 %20,干净利落。但更早的HTML表单提交约定里,空格被编成加号,这套约定至今仍在大量系统里活着。所以你会看到:component和uri模式遵循现代规范,空格走 %20;而full模式沿用表单约定,空格走加号。这就是三种模式那个“唯一分岔”的真相。
这个差异在后端语言里也一模一样地存在。PHP的rawurlencode手册就明确写着,它按RFC 3986把空格编成 %20;而另一个老牌函数urlencode则把空格编成加号,专门用于查询串。这两个函数的分工,正好和工具里component与full两种模式的差别对上号。
实战里怎么避坑?认准你的目标系统吃哪一套。绝大多数现代场景,尤其是路径部分,用 %20 准没错;只有当你明确知道对方是按老式表单约定解析、且处理的是查询串时,才用加号那套。两套混着用,最常见的事故就是空格在传输途中变成了一个莫名其妙的加号,或者反过来。
解码时,为什么加号有时变空格、有时不变?
编码侧的空格分岔,到了解码侧会原样镜像回来,制造出另一个对称的坑。工具解码时,其实跑了两套逻辑给你对照:一套严格按现代规范,只认百分号片段,把网址里原本的加号当成普通加号、保持不动;另一套沿用表单约定,在还原百分号的同时,把加号一律当成空格还原。
这就解释了那个让人摸不着头脑的现象。一条网址里有个加号,你解出来发现它有时变成了空格、有时还是加号——取决于你(或者某个系统)用的是哪套解码逻辑。如果原始链接里的加号本意就是“加号”这个符号,你却用了表单那套解码,它就会被错误地变成空格,意思全拧了。
所以工具把两种解码结果都摆出来给你看,是有意为之:你可以一眼对比,判断这条网址当初到底是按哪套编的,从而选对那个还原结果。排查线上链接异常时,这个对照特别值钱——很多“参数值里凭空多了个空格”的诡异bug,根子就是编码和解码两侧的加号约定没对齐。
哪些字符必须编码,哪些动都不能动?
想真正用明白编码,得知道字符其实分三类。第一类是非保留字符,包括所有字母、数字,加上连字符、点号、下划线、波浪号这四个符号。这类字符在网址里永远安全,任何模式都不会去编它们,编了反而是错。
第二类是保留字符,它们有明确的语法职责,又细分成两组:一组是通用分隔符,像冒号、斜杠、问号、井号、方括号、和号;另一组是子分隔符,像叹号、美元号、单引号、括号、星号、加号、逗号、分号、等号。这些字符RFC 3986 URI通用语法规范里列得清清楚楚,它们是否被编码,正是三种模式拉开差异的那条分界线。
第三类,就是上面两类之外的一切——汉字、空格、各种非英文符号。这类毫无悬念,任何模式下都必须编码,否则网址非出问题不可。把这三类记在脑子里,你再看三种模式,就不是在背规则,而是在理解“这个模式选择放过了哪些保留字符”,一下子就通透了。
这里还藏着一个对技术SEO的提醒:编码方式的不一致,会制造出大量内容相同、形态不同的网址。同一个页面,大写编码和小写编码、该编的没编和不该编的编了,在搜索引擎眼里可能就是几条不同的URL,稀释抓取、分散权重。所以编码这件事,规范统一比什么都重要。
URL解析功能,能帮你看清一条乱码网址的真身吗?
这是工具里我个人最常用的一块。除了编解码,它还能把一整条网址按结构拆开:协议是什么、域名是哪个、端口、路径、查询串、锚点,一项项列出来;更贴心的是,它会把查询串里的每个参数拆成“名”和“值”的配对,并且把那些百分号编码的值,顺手解码成人能读的样子。
这个功能在排查GSC异常时简直是救命的。覆盖率报告、效果报告里,经常有一条长得吓人、满屏百分号的URL,你光看根本不知道它对应站里哪个页面、带了什么参数。把它丢进解析,参数被拆开、中文被还原,这条网址的真身立刻显形——哦,原来是带了某个中文筛选条件的分类页。
它和域名提取那条线也能配合。当你需要先从一堆链接里提出域名、再逐条拆解结构看清细节时,可以先用域名提取器把范围收敛到引荐域,再用这里的解析功能深挖单条网址。一个管广度、一个管深度,分工很自然。
给中文关键词做UTM追踪链接,正确姿势是什么?
出海做内容,免不了要给推广链接打UTM追踪参数。麻烦在于,很多团队习惯用中文给活动、来源命名——“春节大促”“小红书”之类。这些中文一旦直接拼进UTM参数,链接在传播途中极易因为各处编码处理不一致而损坏,数据采集跟着乱套。
正确的做法是:在拼接前,把每个中文参数值单独用component模式编码一遍,再组装进链接。因为UTM参数都是查询串里的“值”,必须用最严格的那套规则,确保中文和可能出现的空格、特殊符号全部被安全编掉。这一步做对了,链接无论被转发到哪、被哪个平台二次处理,参数都能完整地传到分析后台。
- 逐个编码参数值。把活动名、来源、媒介这些中文或带空格的UTM参数值,一个一个单独用component模式编码,确保里面的特殊字符全部被安全转义,绝不留裸中文。
- 组装成完整链接。把编好的参数值按
utm_source、utm_medium、utm_campaign的格式拼到目标网址后面,参数之间用和号分隔、问号引出查询串,结构别拼错。 - 回贴解码验证。把拼好的整条链接再丢回工具解码一遍,确认每个中文参数都能正确还原成原来的值,没有乱码、没有双重编码的痕迹,确认无误再拿去投放。
当然,更省心的是直接用专门的链接构建工具把参数拼好,再用编解码器做个验证。想系统地给推广链接配追踪参数、统一命名规范,可以配合 UTM链接构建器一起用;编解码器在这条流程里的角色,是那个帮你确认“中文到底有没有被正确编进去”的质检员。两者搭着用,中文UTM才稳。
编码后网址膨胀了一截,这个膨胀率有什么用?
你会注意到,工具在编码结果旁边给了几个数字:输入多少字符、占多少字节、编码后多长、其中有多少个字符被编了、整体膨胀了百分之多少。这个膨胀率不是凑数的装饰,它能帮你提前预判网址长度风险。
道理很直白:纯英文的内容,编完几乎不膨胀;而中文内容,一个字三个字节、编成三段百分号,长度会暴涨好几倍。如果你的网址里塞了大量中文参数,编码后的实际长度可能远超你的直觉。而过长的URL,在某些老旧系统、某些分享场景、甚至某些服务器配置下,是会被截断的。
所以当你设计一套要带中文参数的链接结构时,先拿典型值编一遍、看看膨胀率和最终长度,心里就有底了。如果发现膨胀得太离谱、网址长到危险,那就是个信号——也许该把中文参数换成短代码、或者重新设计参数方案。这是个小指标,但在URL结构设计阶段,能帮你避开一类隐蔽的坑。
机械键盘那个站,我们靠它排掉了什么坑?
前阵子帮一个做客制化机械键盘的出海站排查问题,他们的现象很典型:站内搜索带中文关键词时,生成的分享链接发到海外社群,对方点开有一部分直接打不开,报参数错误。老板一开始以为是服务器的问题,查了半天没头绪。
我们把那条出问题的分享链接,丢进编解码器的解析功能一拆,根源立刻清楚了:他们前端拼链接时,对中文关键词用的是uri模式那一档的编码,结果关键词里恰好有用户输入的和号,没被编掉,传到对方那边被当成了参数分隔符,后面的内容全被截断,参数自然就错了。
修正方案很简单:把参数值的编码从uri改成component,让和号这类字符也被老实编掉。改完之后,我们又用工具的批量功能,把站内几类典型的带参链接各编一遍做回归验证,确认都没问题才上线。这个案例里,工具没干什么惊天动地的事,但它把一个藏在编码模式里的隐形bug,几秒钟就照出了原形。
顺便说,这类“参数编码出错”的坑,在对接第三方API时格外密集。最典型的症状是“参数收到了、但值不对”:你传的中文,对方收到的是乱码或问号;你传的带特殊符号的值,对方收到的被截断了半截。这类问题十有八九是两边的编码环节没对齐,拿编解码器把发出的值和文档要求的编码方式一比,根子很快就清楚。
更隐蔽的是“签名校验失败”。很多API要对参数做签名,签名基于参数的原始值算。如果你在签名前后对参数做了不一致的编码,算出来的签名和对方对不上,请求直接被拒,而报错往往只冷冰冰地说一句签名错误,绝不会提醒你是编码的锅。这种时候,把参数逐个解回来核对,常常是唯一能定位问题的办法。
批量处理一批网址,有什么上限要注意?
工具支持批量,可以一次粘进多条网址,统一编码或统一解码,再统一导出。这在做回归验证、或者要把一整批旧链接转换格式时很省事。但有个数量上限得记住:单次批量处理有个几百条的封顶,超过的部分会被截断,不会报错也不会提示,容易让你误以为全处理完了。
所以批量量大的时候,得自己留个心眼分批跑,或者处理完核对一下输出条数和输入是不是对得上。这个上限是出于性能考虑设的,不是bug,但不知道的话确实会埋个雷——你以为五百条全转好了,其实后面一截根本没动。
还有一点很实用:批量导出的结果会保持你输入时的顺序,方便和原清单逐行对照核验。做回归验证时,这个顺序一致性很关键——你能直接比对第几行编码前后是否对应,而不用担心顺序被打乱后对不上号,几百条一眼扫过去心里就有数。
另外,批量模式下所有条目共用同一种编码模式和方向,不能这条编、那条解,也不能这条用component、那条用uri。需要混合处理时,就得分组、分批来。把这两点记牢,批量功能用起来就踏实了。
编码后的网址放进sitemap,有什么格式要求?
这是个容易被忽略、却实实在在影响收录的细节。当你把带参数的网址写进XML sitemap时,光做百分号编码还不够,还得做一层XML实体转义。两者是不同层面的事:百分号编码管的是网址本身的合法性,XML转义管的是这串网址放进XML文件里时不破坏文件结构。
最常见的就是和号。一个带多参数的网址里有和号分隔参数,这个和号在XML里是特殊字符,必须写成对应的实体形式,否则sitemap文件会解析报错、整份地图作废。这一步纯靠手写很容易漏,是不少sitemap提交失败背后的隐形原因。
工具能帮你确认网址本身的百分号编码对不对,但XML实体转义这一层,得在生成sitemap时单独处理。把这两层分清楚——先用编解码器保证网址合法,再在写入XML时做实体转义——sitemap才不会在这种小地方翻车。
查询参数的顺序和重复,会被当成不同网址吗?
很可能会。对搜索引擎来说,?a=1&b=2 和 ?b=2&a=1 是两条字符不同的网址,哪怕它们指向的内容完全一样。参数顺序不固定、或者同一个参数重复出现,都会制造出一堆内容相同、字符串不同的网址,又是一轮抓取浪费和权重分散。
工具不会替你重排参数、也不会合并重复——它只忠实地按你给的原样拆解。但它的解析功能能让你一眼看清一条网址到底带了哪些参数、有没有重复、顺序如何,这是你判断要不要做规范化的第一手依据。把几条可疑网址拆开比一比,问题往往立刻浮现出来。
治本的办法在你的系统侧:固定参数的输出顺序、去掉无意义的重复参数、把追踪类参数统一处理。工具在这里是个诊断器,帮你发现“同一个页面怎么冒出这么多变体网址”,至于动手收敛,得回到生成网址的那段逻辑里去改。
把历史遗留的加号编码链接批量统一,值得做吗?
有些站早年用的是加号编空格那套老约定,积累了一大批这种链接。要不要批量转成现代规范的百分号形式?答案是看情况,别为了统一而统一。如果这些老链接还在正常工作、还在被正常收录,贸然改动反而会制造一批新旧网址,得用跳转去衔接,成本一点不低。
真正该动手的,是那些正在出问题的链接——加号被错误解析、参数损坏、数据采集失真的那些。这种情况用工具的批量功能,把它们集中解码、确认问题,再统一编成正确形式,是值得的。但范围一定要圈准,只动出问题的,别一刀切把全站链接都翻新一遍。
操作前先用工具拿几条典型链接试转、确认转换结果符合预期,再批量跑、并配合跳转规则衔接好新旧地址。URL这层东西牵一发而动全身,编码统一是好事,但动作要轻、范围要小、衔接要稳,这是改造历史链接的基本分寸。
编码不统一,会给技术SEO埋下什么隐患?
前面点了一句,这里展开说。同一个页面、同一份内容,如果编码方式不统一,搜索引擎很可能把它们当成好几条不同的网址。最典型的是大小写:百分号编码里的十六进制,%E4 和 %e4 表示的是同一个字节,但当成字符串比对时它们并不相等。有的系统编成大写、有的编成小写,同一个中文参数就裂成了两条不同的URL。
还有该编不编、不该编乱编的情况。比如波浪号这个非保留字符,本不该编码,可有些老库会把它编成 %7E;又比如某些本该编码的字符被漏掉了。这些差异单看无伤大雅,但累积起来,会让搜索引擎面对一大堆内容相同、形态各异的网址,抓取预算被白白浪费、页面权重被稀释分散,这是技术SEO很忌讳的局面。
应对的思路是“全站统一一套编码规范”,再配合规范标签把重复形态收敛到一个标准网址。这和slug的治理其实是同一套思路——URL这层东西,一致性压倒一切。想系统地把网址结构、停用词、大小写这些一并理顺,可以参考 URL slug优化器那套打分逻辑,和编码规范一起,构成网址层面的整洁度基线。
一个汉字三段、一个表情四段,这些字节是怎么算的?
前面说一个汉字编成三段百分号,背后是UTF-8这套字符编码的规则。UTF-8是变长的:ASCII范围内的英文字母、数字,一个字符占一个字节,编出来一段;绝大多数汉字落在三字节区间,编出来就是三段;而emoji表情、一些生僻字会落到四字节区间,编出来是四段。
工具旁边给的“字节数”和“字符数”两个指标,差别就在这。一句纯英文,字符数和字节数相等;一句中文,字节数差不多是字符数的三倍;混着表情符号的文案,字节数还会更高。把这个关系吃透,你就能在动手前预判一段文案编码后大概会膨胀到什么程度。
这对设计带参网址有实际意义。如果你的参数值里可能混入emoji——比如允许用户用表情来命名的场景——那编码后的长度会比纯中文还夸张。提前用工具拿极端值试一把,看看字节数和最终长度,能帮你在结构设计阶段就避开“网址超长被截断”这类隐患。
解码时碰到残缺或非法的百分号,会出什么岔子?
正常的百分号片段是“百分号加两位十六进制”,三个字符一组。但现实里你会遇到残缺的——百分号后面只跟了一位、或者跟了两个根本不是十六进制的字符。这种非法片段,解码时要么被原样保留、要么解出乱码,具体看实现,但共同点是:结果不可靠,不能当真。
更隐蔽的是字节拼不回字符的情况。百分号片段还原出的是一个个字节,这些字节得恰好能按UTF-8拼成合法字符才行。要是某条网址当初是用别的字符集编的、或者中途被截断了,字节序列对不上UTF-8,解出来就是一堆替换符或乱码。这不是工具的毛病,是输入本身就已经坏了。
所以碰到解码结果是乱码时,先别急着怀疑工具,反过来想想:这条网址是不是被截断了?是不是用了非UTF-8的字符集编的?是不是上游本来就拼错了?工具忠实地按UTF-8解给你看,那串乱码恰恰是个有用的信号,提示你上游的编码环节出了问题。
编码这一步,放前端做还是后端做更稳?
这是工程实践里常争的一个点。前端编码的好处是离用户输入最近,用户敲完中文、拼链接前顺手就编了;后端编码的好处是集中可控,所有出站链接走统一的编码逻辑,不依赖各个前端页面各自为政。两种都有道理,真正的关键是别两头都编、也别两头都不编。
最常见的事故,恰恰是“编了两次”。前端编了一道、后端没意识到又编了一道,结果百分号本身又被编了一遍——% 变成了 %25,整条网址彻底乱套,这就是所谓的双重编码,排查起来特别烦人。反过来,两头都以为对方会编、结果谁都没编,中文裸奔进网址,照样出问题。
工具在这种场景里,是个绝佳的对照器。把前端生成的链接和后端最终发出的链接,分别丢进解码看一眼,是不是出现了 %25 这种双重编码的痕迹,一比就知道哪个环节多伸了手。约定好编码只在一处做、并用工具定期抽查,是避免双重编码最实在的办法。
这个工具碰不了哪些硬骨头?
它的边界,比能力更需要你记清楚。第一条最容易踩:它不支持中文域名的国际化编码。像“中文.com”这种域名,背后有一套叫Punycode的专门转换规则,把中文域名转成 xn-- 开头的ASCII形式。这个工具只会把中文当普通字符做百分号编码,给不出正确的域名编码——域名层面的编码,它够不着。
第二,它不做URL规范化。网址里那些 ../ 的相对路径、重复的斜杠、多余的点号,它原样保留、不替你化简。如果你需要的是把一条网址整理成最简范式,那是另一类工具的活,别指望它顺手干了。
第三,它不做查重和去冗余。同一个参数在网址里出现了好几次、参数顺序乱七八糟,它不会合并、不会重排、不会警告,只忠实地按你给的原样拆解。第四,字符集锁死了UTF-8,不能切换成别的编码——绝大多数现代场景这没问题,但万一你对接的是个用老式字符集的古董系统,它给出的字节就对不上了。
最后一条老生常谈:它只做格式层面的转换,不碰网络。它不验证这条网址能不能打开、域名存不存在、参数对不对。把这几条边界——不认国际化域名、不规范化、不查重、锁死UTF-8、不验可达——记在心里,它就是个趁手的编码质检台;忘了,就可能在某个细节上栽个不大不小的跟头。
编解码器算不算技术内容“发布前自查”的一环?
把它放进出海内容发布前的自查清单里,是很合适的。一条要对外发布的带参链接、一个要投放的UTM追踪地址,发出去之前用它验一遍——中文有没有被正确编码、有没有双重编码的痕迹,几秒钟的事,能挡掉一类发出去才发现、想改都来不及的事故。
它和发布前的其它技术自查是一条线上的。提取外链域名盘点链接档案、检查英文文案的低级错误、核对网址编码——这些都是内容真正推出去之前,该挨个过一遍的技术关卡。比如英文落地页发布前,配合英文语法检查器扫一遍拼写语法,再用编解码器确认链接编码无误,两道关一过,心里就踏实多了。
说到底,这类工具的共同气质是“便宜的保险”——花几秒钟做个机械检查,换掉一个可能要花几小时排查的线上事故。URL编码这种藏在细节里、平时不显眼、出事却很要命的东西,恰恰最值得在发布前用工具兜一道底。
养成这个习惯的成本几乎为零,收益却可能很大。把编码自查固化进你的发布流程清单,和检查标题、检查描述、检查结构化数据放在一起,它就从“想起来才做”变成了“每次必做”,那些藏在细节里的编码事故,自然就被挡在了上线之前,而不是上线之后再来救火。
常见问题解答
编参数值到底该用哪种模式,能给个一句话的准则吗?能:拼进网址的单个“值”一律用component。无论是搜索关键词、UTM参数、还是中文标签,只要它是要塞进查询串或路径里的一个零件,component都会把所有可能搞坏网址的字符编掉,最安全。只有当你编的是一整条已组装好的完整网址、想保留它的结构时,才用uri。
为什么我编出来的链接,空格被变成了加号?因为你用的是full模式,或者目标系统走的是老式表单编码约定,这套约定下空格就是编成加号的。如果你需要的是符合现代规范的 %20,改用component或uri模式即可。两套约定都对,关键是和你的目标系统对齐,别混用。
GSC里一条全是百分号的怪URL,怎么知道它是站里哪个页面?把整条URL粘进工具的解析功能,它会把路径和每个查询参数拆开,并自动把百分号编码的中文值解码还原。中文一还原,这条网址带的是什么筛选条件、对应哪个页面,通常就一目了然了。这是排查GSC异常URL最快的一招。
中文域名能用它来编码吗?不能,至少不能得到正确结果。中文域名需要的是Punycode编码,会转成 xn-- 开头的形式,这是域名系统专用的一套规则;而这个工具只会把中文做普通的百分号编码,那串结果放进域名位置是无效的。域名的国际化编码,得用支持Punycode的专门工具。
这个工具和我直接在浏览器控制台敲编码函数,有区别吗?能力内核是一样的,差别在效率和直观。工具把三种模式、编码解码双向、URL结构拆解、膨胀率统计、批量处理都摆在一个界面里,还把容易混淆的两种空格约定并排展示,省去你反复回忆函数名和试错的功夫。临时编一两个值,控制台够用;要排查、要对比、要批量,工具明显顺手。
本文标题:《URI编解码器怎么用?中文URL编码、UTM参数转码与GSC乱码网址还原》
本文链接:https://zhangwenbao.com/uri-codec-percent-encoding-encode-decode-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0