页面不被Google收录怎么办?从症状分诊到动手修复的完整急救手册
本文目录
- 先分清你中的是哪一种“不收录”,四类症状的病根完全不同
- 打开GSC第一步看什么:把模糊的“没收录”翻译成精确状态
- “已发现-尚未编入索引”怎么救:这是抓取调度问题,不是内容问题
- “已抓取-尚未编入索引”是另一回事:价值阈值没过,得先治站再治页
- 只收录首页、内页全军覆没,多半是这5个站级故障
- “请求编入索引”那个按钮,正确用法和三个常见误用
- 内链是收录最被低估的杠杆,但千万别信那些“伪精确指标”
- 这些年遇到的“收录玄学”,再挨个拆穿几个
- 从提名到确认收录的闭环:等多久、怎么验证、怎么防回退
- 常见问题解答
- “已发现-尚未编入索引”和“已抓取-尚未编入索引”到底差在哪?我该先做什么?
- 我的站只收录了首页,内页一篇都没有,最可能是什么原因?
- 反复点“请求编入索引”能让页面更快收录吗?
- 是不是文章字数太少、加载太慢导致不收录?
- 网上说“一周只能加一个内链,否则触发反作弊”,是真的吗?
- 修复之后大概多久能看到收录?怎么确认真收了?
- 权威参考资料
摘要:页面不被Google收录,别急着反复点“请求编入索引”。第一步是去Search Console把症状翻译成具体状态——“已发现-尚未编入索引”是抓取调度问题,“已抓取-尚未编入索引”是质量阈值问题,“只收首页、内页全军覆没”多半是站级故障,三条路的修法完全不同。这篇是一份按症状分诊的动手急救手册:先定位状态,再对症给修复SOP,把“请求编入索引”用在刀刃上,用内链和站点结构把抓取预算引到该去的地方,最后教你怎么确认真收录了、怎么防回退。顺带把“一周只能加一个内链”“加载必须低于3秒否则不收录”这类流传已久的伪指标挨个拆穿。
“文章写得挺用心,发出去两周了,site一查只有首页,正文页连影子都没有。”这是保哥收到最多的一类求助。问题在于,大多数人一上来就把所有不收录都当成同一个病,然后套同一个偏方——疯狂点“请求编入索引”,或者听信某篇文章说“加载要小于3秒”就去折腾速度。结果是药不对症,越折腾越焦虑。
收录这件事,机理层面其实已经有不少人讲透了。如果你想搞清楚Google内部那套“已发现、已抓取、去重、Soft 404”的状态机到底怎么运转、算法为什么这么判,可以去读笔者那篇把8种GSC未编入索引状态拆成算法决策路径的长文,那是“为什么”。而这一篇不讲为什么,只讲“怎么动手”——拿到一个不收录的页面或一个只收首页的站,照着往下做就行。
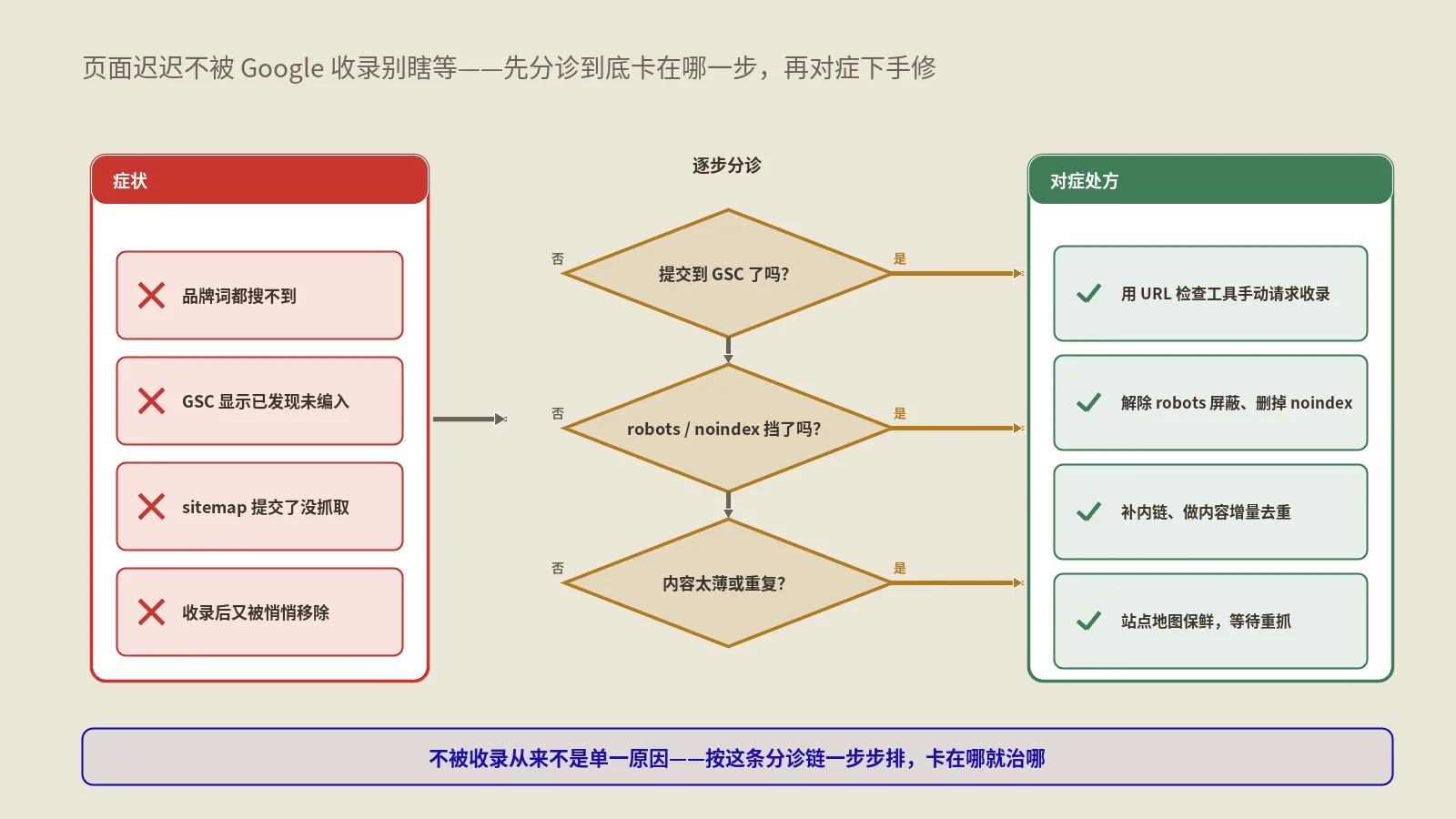
先分清你中的是哪一种“不收录”,四类症状的病根完全不同
“不收录”是个笼统的说法,真正决定你该往哪个方向使劲的,是症状的形态。笔者把它分成四类,先对号入座,再往下读对应的章节,能省掉大量瞎试的时间。
| 症状形态 | 典型表现 | 最可能的病根 | 对应章节 |
|---|---|---|---|
| 单页不收 | 大部分页面正常,个别新页迟迟不进索引 | 抓取调度优先级低,或这一篇本身价值信号不足 | 状态三、状态四 |
| 批量深层页不收 | 分类页、博客归档下一大批URL卡在“已发现” | 抓取预算被浪费、内链够不到、模板化薄内容 | 站级五故障 |
| 只收首页 | site查只有首页和少数几页,内页几乎为零 | 站点结构性问题:孤岛、渲染、canonical乱指 | 站级五故障 |
| 收了又掉 | 原本在索引里,某次更新后悄悄消失 | 反向转换:质量滑坡、误加noindex、模板事故 | 闭环与防回退 |
为什么一定要先分诊?因为这四类的修法是冲突的。比如“只收首页”是结构病,你再怎么优化单篇内容质量都没用,蜘蛛根本爬不到内页;反过来,“已抓取-尚未编入索引”是价值判断没过关,你再怎么加内链催抓取也是白催,它早就抓过了、是主动选择了不收。把结构病当内容病治,或者反过来,是新手最常见的两个死循环。
还有一个容易被忽略的前提:收录、排名、流量是三件事,得一层层往上看。很多人说的“不收录”,其实是“收录了但排不上、没人点”。笔者专门写过怎么把收录、排名、流量拆成三层来诊断,强烈建议先确认你卡的真是收录这一层,而不是把没排名误当成没收录——这两者在GSC里的表现和修法南辕北辙。
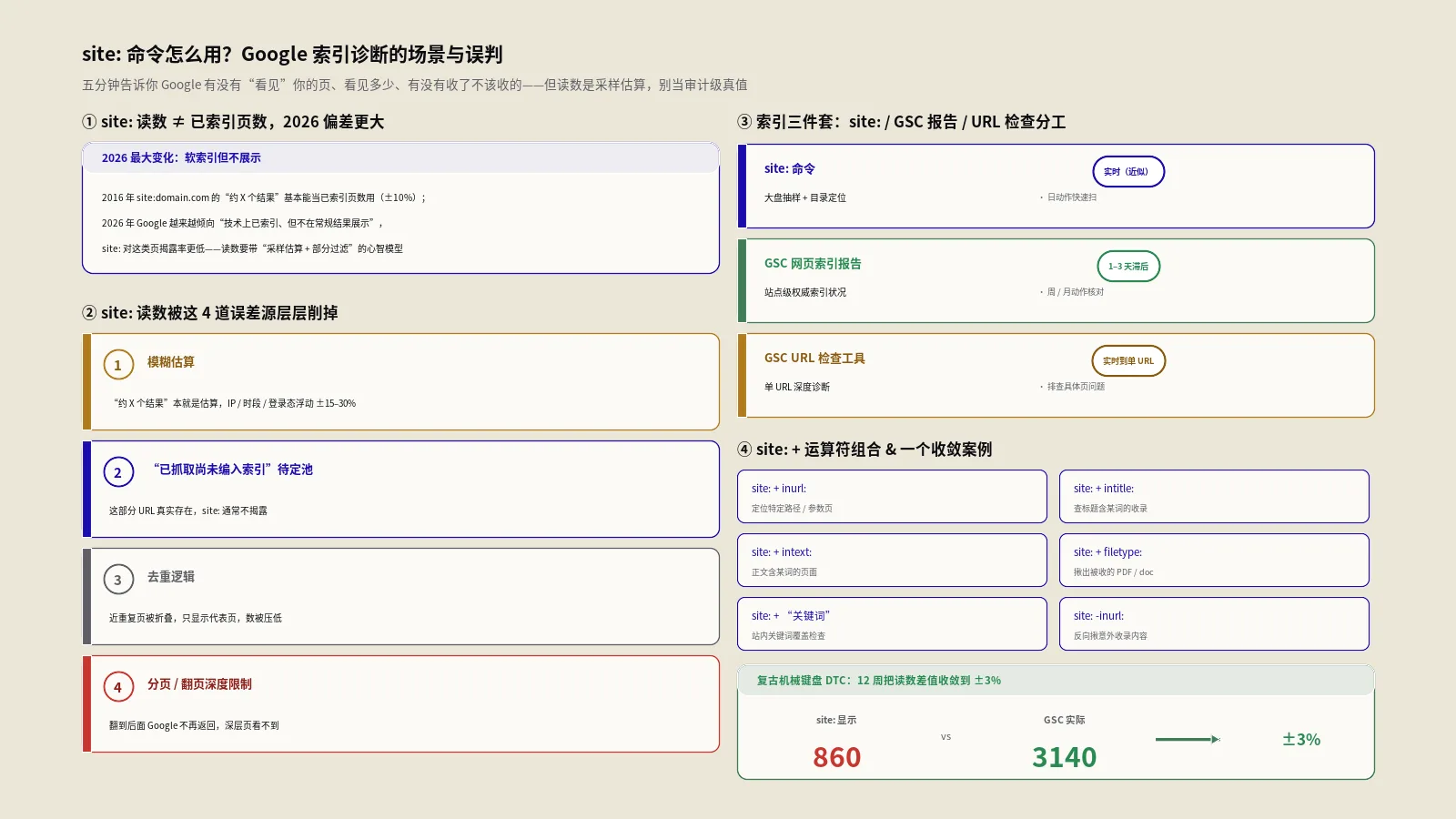
分诊做完,下一步是把“感觉它没收录”变成“GSC告诉我它处于什么状态”。凭site命令和肉眼是诊断不出病根的,必须打开后台看真实状态码。
打开GSC第一步看什么:把模糊的“没收录”翻译成精确状态
诊断从“网址检查”(URL Inspection)这个工具开始,它是整套手册里最该先动的那一步。把目标URL粘进Search Console顶部的检查框,回车,它会告诉你这个页面此刻在Google眼里的真实身份。重点看三行信息。
- “网址是否在Google上”:直接告诉你收没收录。显示“网址已编入Google索引”就是真收了;显示“网址未编入索引”,那下面会给出具体原因,这才是诊断的钥匙。
- 覆盖范围里的“状态短语”:这就是病名。最常见的两个是“已发现-尚未编入索引”(Discovered - currently not indexed)和“已抓取-尚未编入索引”(Crawled - currently not indexed),一字之差,病根天上地下,下面两章分别处理。
- “上次抓取时间”和“用户声明的规范网址 / Google选择的规范网址”:前者告诉你蜘蛛到底来没来过;后者如果两个值不一致,说明Google把这页判成了别人的副本,那是canonical问题,不是单纯不收录。
按Google官方页面索引报告(Page indexing report)的状态说明,这两个核心状态的定义是这样的:“已抓取-尚未编入索引”指页面被Google抓取了但没被收录,未来可能收也可能不收,无需重复提交;“已发现-尚未编入索引”指页面被发现了但还没被抓取,通常是Google想抓、但判断抓了会让你的服务器过载,于是把抓取计划往后排了。把这两句话嚼透,你就明白为什么修法不同——一个还没爬到,一个爬了不想要。
这里要纠正一个普遍的误区:很多人把“网址检查”里的“已编入索引”当成排名保证,其实它只回答收录这一个问题。一个页面可以稳稳收录在Google那套分层索引体系的底层,照样一个词都排不上。所以检查工具是用来确认收录状态的,不是用来判断你能不能拿流量的,别越级解读。
把单页状态确认完,如果你是“只收首页”或“批量不收”,还要去“页面索引”报告里看汇总,看那一大批URL集体卡在哪个状态、占比多少。状态对上了,才进入对症修复。
“已发现-尚未编入索引”怎么救:这是抓取调度问题,不是内容问题
先记住一句话:处在“已发现”的页面,Google根本还没抓过它。所以这一刻去改正文、堆字数、加图表,全是无用功——蜘蛛连看都没看过你改了什么。这一类要从“怎么让它愿意来抓、抓得过来”这个角度下手。
Google官方关于抓取预算优化的文档把“能抓多少”拆成两个变量:抓取容量上限(crawl capacity limit,取决于你服务器扛不扛得住、响应快不快、有没有频繁报错)和抓取需求(crawl demand,取决于Google觉得你这些URL值不值得抓、热不热门、内容新不新)。“已发现不抓”几乎都是这两个变量出了问题。对应的动手清单:
- 先排除服务器把蜘蛛劝退了。去服务器日志或GSC的“抓取统计信息”看,有没有大量5xx、平均响应时间是不是动辄一两秒。Googlebot连续撞墙会主动降速甚至停抓24小时,这时候你做再多内容都没用。把TTFB压下去、把500/503清零,是第一优先级。
- 把抓取预算从垃圾URL上抢回来。如果你的站有大量带参数的筛选页、会话ID、无限日历、低质标签归档,蜘蛛的额度全耗在这些垃圾上,正经内页自然排不上队。这一块怎么按占比排查、哪些该用robots挡、哪些该改POST,笔者在抓取预算优化那篇实操指南里给了完整的分桶方法,深层页大面积“已发现”的站,九成要先做这件事。
- 给孤立页搭内链桥。一个页面如果没有任何已收录页面链向它,Google发现它的唯一途径就是sitemap,优先级天然低。从首页、热门栏目页、相关高权重老文里,给它2到3条上下文相关的内链,等于告诉蜘蛛“这页和站内别的内容是连着的,值得来一趟”。
- 用sitemap兜底,但别指望它催收。sitemap保证Google知道这个URL存在,但它只解决“发现”,不提升“需求”。提交后该等还是得等。
真实节奏是这样:一个健康小站的新页,搭好内链、服务器正常,通常几天到两周内会从“已发现”转到“已抓取”再进索引。如果一个月还卡在“已发现”,那大概率不是这一篇的问题,而是整站的抓取预算或服务器健康出了系统性故障,要往站级排查走。
怎么判断到底是不是服务器把蜘蛛劝退了?去GSC的“设置-抓取统计信息”里看两条曲线:一条是“总抓取请求数”,一条是“平均响应时间”。健康的站,响应时间应该稳定在两三百毫秒级;如果你看到响应时间隔三差五飙到一两秒,或者抓取请求数在某个时间点断崖式下跌,那几乎可以坐实是服务器拖了后腿。再交叉看“按响应(状态码)划分”那一栏,5xx占比但凡上了个位数百分点,就该让运维先去查服务器,而不是继续折腾内容。这个动作很多人跳过,结果在内容上耗了几个月,根子却在一台扛不住的廉价虚拟主机上——抓取这一关都没过,后面谈再多内容质量都是空中楼阁。
“已抓取-尚未编入索引”是另一回事:价值阈值没过,得先治站再治页
这个状态的潜台词很扎心:Google已经亲自来读过你这页了,读完做了个决定——不值得占用索引位。它不是没看到,是看到了、选择了拒绝。所以这一类纯粹是质量与价值的问题,催抓取毫无意义,得回答一个问题:这页凭什么值得被收?
笔者处理这类问题的顺序是“先治站、再治页”,因为单页被拒往往是整站质量信号被拉低后的连带结果。
- 站级先看:你的站是不是有一大批“凑数页”。批量生成的薄标签页、抓取拼接的列表、互相高度雷同的模板页,这些会拉低Google对整站的质量预期,殃及本来不错的正经内容。在2023年那轮Helpful Content更新之后,这个状态在内容农场和模板站上集体爆发,就是这个机理。先把这些凑数页noindex或合并掉,整站的“信誉分”回来了,单页才好谈。
- 页级再看:这一篇有没有“独到的存在理由”。Google拒收的典型是那种“网上已经有一百篇一模一样的”页面。问自己:这页有没有别处没有的第一手信息、数据、案例、视角?如果只是把别人的观点换种说法复述,它在索引里就是冗余,被拒很正常。补的是“增量价值”,不是字数。
- 检查是不是被判成了副本。如果“Google选择的规范网址”指向了别的URL,那它不是嫌你差,是觉得你和某页重复、把那页当了代表。这时要查canonical标签指对没、参数页有没有正确归一、有没有www与非www、http与https的重复版本在打架。
修完之后,对这一类页面可以用一次“请求编入索引”告诉Google“我改过了,麻烦重新评估”。但记住,请求只是让它重新来读,读完收不收,还是看你这次补的价值够不够。我见过太多人改了一个标题就反复提交,那是在浪费配额。
举个保哥手上真实的例子。有个做户外露营装备的独立站,三百多个产品页里近一半卡在“已抓取-尚未编入索引”,店主一开始认定是抓取预算不够,催了一个月毫无动静。笔者拉下来一看,病根根本不在抓取——这些产品页的描述是从供应商那里整段复制的,几十个同类SKU共用一套模板话术,正文里除了规格表几乎没有任何独家信息。Google抓了,判定这批页面彼此雷同、对用户没有增量价值,于是集体拒收。后来的做法很笨但有效:先把真正卖不动、内容也最空的那批SKU直接noindex掉,把整站的质量信号先拉干净;剩下的主推款,一篇篇补上真实的使用场景、材质实测、和同类产品怎么取舍——也就是只有真用过这些装备的人才写得出的东西。整站的“信誉”回来之后,主推页是一批一批转正的,而不是一篇篇硬催出来的。这个顺序不能反:先把凑数页清掉再谈单页,比上来就死磕某一篇高效得多。
只收录首页、内页全军覆没,多半是这5个站级故障
“只收首页”是单独拎出来讲的一种症状,因为它几乎从不是内容问题,而是结构问题——蜘蛛进了门,却发现屋里没有路通向其他房间。逐个排查这5处:
- 内链孤岛:内页没有任何入口。最常见。首页是个花哨的全屏大图加一个“进入”按钮,导航全靠JS弹层,正文页之间互不链接。蜘蛛从首页进来,找不到任何指向内页的HTML链接,自然只能收首页。解法:让首页和栏目页有真实的
<a href>链向内页,别全压在脚本里。 - JS渲染黑洞:链接和正文都要执行脚本才出现。如果你的站是纯前端框架渲染,首屏HTML里几乎没有内容和链接,全靠浏览器跑完JS才生成,那Googlebot在抓取阶段拿到的就是个空壳。用“网址检查”里的“查看已抓取的网页”看Google实际拿到的HTML,如果是空的,问题就在这。
- canonical全站指向首页。一个被坑过无数人的低级事故:某个插件或模板把所有页面的canonical标签都写成了首页地址,等于每个内页都在主动告诉Google“我的正主是首页,别收我”。逐页看源码里的
rel="canonical"指向,是不是都指对了自己。 - robots或noindex误伤。检查robots.txt有没有不小心Disallow了内页目录,检查内页模板的
<head>里有没有遗留的noindex标签(开发环境带过来的最常见)。这两个一旦中招,内页神仙难救。 - sitemap缺失或只列了首页。新站尤其要确认sitemap真的包含了所有内页URL,而不是插件默认只生成了首页或几个栏目页。在GSC提交sitemap后,看它报告的“已发现URL数”对不对得上你的真实页面数。
这5项里,内链孤岛和canonical误指是出现频率最高的,建议从这两个先查。站级故障的特征很好认:不是某一篇出问题,是同一模板下的一整批URL集体阵亡。一旦确认是结构病,修好之后往往是一批页面一起开始进索引,比一篇篇救效率高得多。
保哥见过最哭笑不得的一例:一个新站做了大半年,内页死活不收,店主前后换了三家“SEO优化”服务都没解决,钱没少花。最后扒一眼源码,两分钟就找到了——建站时套的那个主题,默认把所有页面的canonical都写死成了首页地址。等于这站每一个内页都在异口同声地告诉Google“别收我,我的正主是首页”。改一行模板配置,两周内内页齐刷刷开始进索引。这种结构性事故的吊诡之处就在于:花再多钱在内容上都没用,但找对地方一下就解决。所以遇到“只收首页”,第一反应应该是打开内页源码看canonical和内链,而不是去怀疑文章写得好不好。
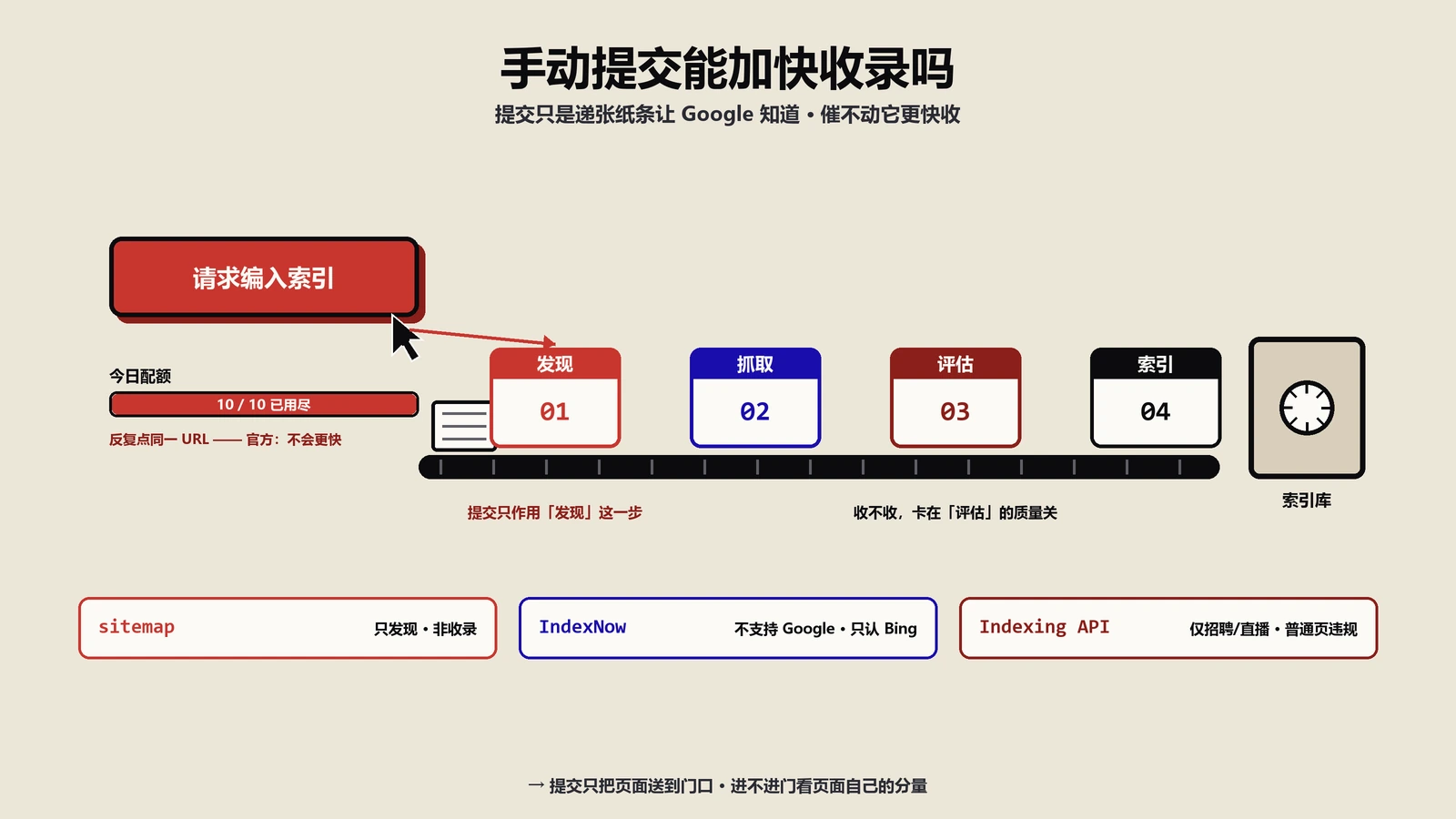
“请求编入索引”那个按钮,正确用法和三个常见误用
几乎每个人都用过“请求编入索引”,但用对的人不多。先把它的本分说清楚:它是个“发现加速”工具,作用是让Google把这个URL排进抓取队列、来读一次。Google官方在URL检查工具的帮助文档里把话讲得很直白:每天能提交的索引请求有上限;提交请求不保证页面会被收录;批量提交应该改用sitemap。这三句话直接对应三个最常见的误用。
| 误用 | 真相 | 正确做法 |
|---|---|---|
| 把它当排名手段,收录后还反复点 | 它只负责让蜘蛛来读,和排名、流量没有半点关系 | 页面收录后就别再碰这个按钮,去做内容和内链 |
| 一篇篇手动提交几百个URL | 有每日配额,手动批量既慢又会撞限额 | 批量收录靠提交并维护好sitemap,请求按钮只点真正紧急的少数页 |
| 改一个字就提交一次,催了又催 | 反复提交同一URL不会提速,可能纯属浪费额度 | 实质性改过内容后提交一次,然后耐心等重新评估 |
那它什么时候真有用?两个场景:一是你刚发布或刚实质性修改了一个重要页面,想让Google早点来读,点一次,合理;二是诊断用——提交后看它返回的抓取结果,能立刻告诉你这页能不能正常抓、状态码对不对、规范网址判成了谁。把它当诊断探针,比当催收工具有价值得多。
顺便说一个已经过时的“老偏方”:早些年流行的 google.com/ping?sitemap= 那个主动通知接口,Google已经在2023年正式停用了,现在调它没有任何效果。还在教这招的教程,基本可以判定它的其他内容也老旧了,别照着做。
内链是收录最被低估的杠杆,但千万别信那些“伪精确指标”
前面几章反复提到内链,因为它确实是普通人手里最有效、最可控的收录杠杆——它同时作用于“发现”(给孤岛页搭桥)和“价值”(用相关上下文为目标页背书)。但内链这件事,恰恰是各路SEO玄学伪指标的重灾区,得专门拎出来正本清源。
内链真正起作用的原理其实朴素:从一个已经被Google信任、经常来抓的页面,放一条上下文相关的链接指向目标页,相当于把蜘蛛的来访动线和一部分信任传导过去。所以好内链的标准只有三条,全是定性的——来源页本身得是被信任、被频繁抓取的;锚文本要能说清目标页讲什么;链接要在正文里、有真实上下文,而不是塞在页脚链接墙里凑数。就这些。
现在看看源头那类内容农场文是怎么把这件事神化的,以及为什么不能信:
- “一周只能加1个内链,单次超过3个会触发SpamBrain反作弊警报”——纯属编造。SpamBrain针对的是垃圾内容和操纵性链接,不存在“内链频率配额”这种东西。一篇长文一次性加七八条相关内链,是再正常不过的事。
- “裸链接收录概率比文字链接低68%”“超链接文字在排序里权重占15%”——这种精确到个位数的百分比,Google从来没公布过任何一个,都是为了显得专业硬造的。看到精确小数点的“算法权重”,基本可以直接判定是编的。
- “来源页Ahrefs UR必须≥30才算高权重”——UR是Ahrefs这家第三方工具的私有评分,Google的算法根本不认识它。拿一个工具的内部指标当Google的收录门槛,是张冠李戴。
- “锚文本必须4到8个单词、段落必须40到60字、颜色对比度4.5:1”——对比度4.5:1是无障碍(WCAG)的可读性建议,是好事,但它和“能不能被收录”毫无因果关系。把无关的可用性参数包装成收录硬指标,是这类文章惯用的障眼法。
把这些伪指标清出脑子,你会发现内链操作反而轻松了:找几篇真正相关、本身收录良好的老文,在正文里自然地链向新页,锚文本写清楚对方讲什么,就够了。不需要掐着秒表算一周加几条,更不用查什么对比度。
这些年遇到的“收录玄学”,再挨个拆穿几个
除了内链,收录这个话题周围还飘着一堆似是而非的硬指标,新手最容易被这些“看起来很懂”的数字唬住,然后把精力全花在错地方。笔者按出现频率,再拆几个流传最广的:
“加载速度必须低于3秒,否则不收录。”速度影响的是排名层面的体验信号(Core Web Vitals是个轻量排名因素),而且作用在排名不在收录。一个慢页面照样能被收录,只是排名时可能吃点亏。把速度当成收录的开关,是混淆了收录和排名两层。当然,慢到Googlebot频繁超时的程度会影响抓取,那是另一回事,前面讲服务器健康时说过了。
“文章必须800字(或某个固定字数)才满足E-E-A-T才会收录。”不存在收录字数线。一个300字但精准回答了某个具体问题的页面,可能比3000字的注水长文更容易收录。Google判的是“有没有独到价值”,不是字数。E-E-A-T是关于经验、专业性、权威性、可信度的综合信号,跟字数表没关系。
“正文和别处重合超过80% 就被打入备用库。”这个具体的80% 阈值是编的,Google没公布过任何去重百分比线。重复内容确实会导致Google选一个代表URL、把其余判为副本,但这是相对的去重判断,不是卡着某个数字的硬开关。
“DOM节点要少于1500、嵌套不能超过32层,否则渲染失败不收录。”Googlebot渲染确实有资源上限,过度臃肿的页面渲染可能不完整,这个方向是对的;但“1500节点 / 32层”这种精确数字是凑出来的伪标准。与其记数字,不如记原则:让核心内容和链接在原始HTML里就能拿到,别全压给JS。
识别伪指标有个简单的判据:凡是给出Google从未公开过的精确数字(精确的百分比、精确的秒数、精确的节点数)并声称是“算法硬指标”的,先打个问号。Google公开的几乎都是方向性建议——“提升内容质量”“确保可被抓取”“别让服务器过载”,而不是一张可以照着填的参数表。把方向性原则吃透,比背一堆假数字管用得多,也不会被带沟里。
从提名到确认收录的闭环:等多久、怎么验证、怎么防回退
修完之后最熬人的是等待,而且很多人不知道怎么确认“真的收了”,于是天天site一下、心态起伏。把这最后一步做成闭环,焦虑会少很多。
现实的时间预期。别信“72小时必收”这种话术。健康小站的新页,从修复到进索引,通常几天到两三周;大站或质量信号偏弱的站,一个月甚至更久都正常。处在“已抓取-尚未编入索引”的页面,转正时间最不可控,因为它取决于Google对你整站价值的重新评估,这是个慢变量。把心理预期放到“以周为单位”,而不是“以天为单位”。
怎么算真验证。三个口径,从弱到强:
- 最弱:
site:你的域名/路径能搜到。能搜到说明收了,但搜不到不代表没收(site命令本身有偏差,这点笔者在别处专门聊过),所以它只能用来证实、不能用来证伪。 - 较强:GSC“网址检查”实时检查,显示“网址已编入Google索引”。这是最权威的单页确认。
- 最强:在GSC的“效果”报告里,这个页面开始有真实的展示次数(impressions)。有展示,说明它不仅进了索引,还真的进入了某些查询的候选池——这才是收录有意义的终点。
怎么防回退。收录不是一锤子买卖,它会因为质量滑坡、误操作而反向掉出索引。建立两道简单的监控:一是每个月扫一眼GSC的“页面索引”报告,看“未编入索引”的总数是不是在异常上涨,涨了就去看新增的是哪一批、什么状态;二是任何一次模板改动、插件更新、迁站之后,抽查几个重点页的“网址检查”,确认没有被误加noindex、canonical没被改乱。这两件事每月花十分钟,就能在掉量演变成灾难之前把它摁住。
防回退里笔者踩过最多的坑,是“迁站”和“批量改模板”。有一次帮客户把站从老CMS迁到新框架,迁完首页排名都还在,过了三周流量却莫名其妙往下掉——回头一查,新框架的文章模板在 <head> 里默认带了 noindex,开发自测时加的,上线忘了摘。这种事故的可怕之处在于它有延迟:当天不掉,要等Google重新抓到那批页面、按 noindex 把它们逐步移出索引,往往是两三周之后,等你发现流量掉了再去查,已经白白损失一整轮。所以任何一次伤筋动骨的改动之后,当天就抽查几个重点页的“网址检查”,确认收录状态和canonical没被改乱,是性价比最高的一道保险。
说到底,收录这件事没有玄学,也没有什么一招见效的秘籍。它就是一条朴素的链路:能被发现(内链 + sitemap + 服务器扛得住)、被认为值得抓(抓取预算没被浪费)、被判定值得收(有独到价值、不是副本)。这篇手册的每一章,其实都在修这条链路上的某一环。按症状找到你断的是哪一环,对症修,然后以周为单位耐心等验证——比你反复点一百次“请求编入索引”有用得多。
常见问题解答
“已发现-尚未编入索引”和“已抓取-尚未编入索引”到底差在哪?我该先做什么?
差在Google有没有真正读过这一页。“已发现”是还没抓,属于抓取调度问题,要从内链、服务器健康、抓取预算下手让它愿意来抓;“已抓取”是抓了但觉得不值得收,属于价值问题,要补独到内容、清理整站的凑数页。第一步永远是用GSC“网址检查”确认你处在哪个状态,再决定方向,千万别两个状态用同一套打法。
我的站只收录了首页,内页一篇都没有,最可能是什么原因?
九成是站级结构问题,不是内容问题。按顺序查这五处:内页有没有真实的HTML内链入口(不是全靠JS)、是不是纯前端渲染导致Googlebot拿到空壳、canonical是不是被插件全指向了首页、robots或noindex有没有误伤内页、sitemap是不是只列了首页。最高频的是内链孤岛和canonical误指,先查这两个。
反复点“请求编入索引”能让页面更快收录吗?
不能,而且可能浪费每日配额。这个按钮的作用只是让Google把URL排进抓取队列来读一次,它不保证收录、和排名更是毫无关系。正确用法是:新发布或实质性改过的重要页面点一次,然后耐心等;批量收录靠维护好sitemap,不靠手动一个个提交。改一个字就提交一次是典型的无效操作。
是不是文章字数太少、加载太慢导致不收录?
多半不是。不存在“低于多少字不收录”的字数线,一篇短而精准的页面照样能收;加载速度影响的是排名层面的体验信号,作用在排名而非收录这一层(除非慢到Googlebot频繁超时才会牵连抓取)。把精力放在“这页有没有别处没有的价值”和“蜘蛛能不能抓到、爬得过来”上,比纠结字数和秒数有用得多。
网上说“一周只能加一个内链,否则触发反作弊”,是真的吗?
是编的。不存在内链频率配额这种规则,SpamBrain针对的是垃圾内容和操纵性链接,不管你一篇文章里放几条相关内链。一次性给长文加七八条上下文相关、锚文本清晰的内链完全正常。看到精确到“一周一条”“权重占15%”这种Google从未公布的硬数字,基本可以判定是伪指标,别信。
修复之后大概多久能看到收录?怎么确认真收了?
健康小站通常几天到两三周,大站或质量偏弱的站一个月以上也正常,“以周为单位”预期更现实。确认收录从弱到强有三个口径:site命令能搜到(只能证实不能证伪)、GSC“网址检查”显示“已编入索引”(最权威的单页确认)、GSC效果报告里这页开始有真实展示次数(最有意义的终点,说明它真进了查询候选池)。
权威参考资料
本文标题:《页面不被Google收录怎么办?从症状分诊到动手修复的完整急救手册》
本文链接:https://zhangwenbao.com/google-not-indexed-fix-playbook.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0