分页SEO和无限滚动到底怎么选?四种方案完整机制对照
本文目录
- 分页和无限滚动到底差在哪?
- Googlebot抓的是文档,不是浏览体验
- View All、传统分页、Load More、Infinite Scroll四种实现的根本差异
- rel=prev/next死了,留下的真空怎么填?
- 从2011到2019的旧世界与新世界的断点
- Google现在到底用什么信号判断分页关系?
- Googlebot怎么模拟翻页?哪些操作它不做?
- 不会滚动、不会点击、只跟a标签
- JS渲染的“假”分页器陷阱
- 四种方案的索引覆盖率与权重稀释差多少?
- View All的内链权重集中度最高
- 传统分页的两难:第2页之后流量塌方
- Load More按钮的工程化代价
- 纯客户端无限滚动 = 灾难现场
- 独立站电商PLP到底应该选哪个?
- 商品数小于50用View All
- 商品数50到1000用渐进增强infinite scroll或Load More
- 商品数大于1000用传统分页加分面落地页
- 内容站和列表页又该怎么选?
- 博客归档不超过5页就直接View All
- 媒体站新闻流分页vs Load More的取舍
- canonical / noindex / sitemap与分页器的搭配怎么写?
- 第2页canonical应该指向自身,不要指向第1页
- 哪些场景才该给分页页noindex,follow?
- sitemap是否要把分页页全列进去?
- 保哥的独立站PLP实测复盘(北美宠物用品DTC)
- 原始方案:纯客户端infinite scroll
- 诊断6步:从GSC到site: 到日志
- 改造方案与8周流量数据
- 常见的7个分页SEO误区
- 常见问题解答
- rel=prev/next真的不能再用了吗?
- 无限滚动一定是SEO灾难吗?
- View All一页加载所有商品会不会拖慢LCP?
- 电商站第2页之后流量为零,是不是分页方案选错了?
- Next.js默认的无限滚动如何SEO化?
- 分页页应该noindex吗?
- 分页页的canonical怎么写?
- 分页页要不要进sitemap?
- Load More按钮怎么做才SEO友好?
- 移动端体验和SEO抓取可达性冲突时优先哪个?
- 权威参考资料
摘要:分页和无限滚动从来不是体验团队的小问题,而是直接决定电商集合页、内容站归档页的收录率、权重传导和重复内容风险的工程大事。rel=prev/next自2019年被Google弃用后,旧方案大批失效;现在View All、传统分页、Load More按钮、纯客户端无限滚动这四种主流实现,对Googlebot的行为差异巨大。本文从抓取与渲染机制入手,给出独立站电商和内容站的工程决策矩阵、配套canonical与sitemap写法,附一份北美宠物用品DTC客户的8周改造实测复盘和7个高发误区清单。
保哥这些年帮独立站做技术SEO审计,遇到的“前端选择拖死自然搜索”的案例里,分页和无限滚动几乎稳排前三。前端团队按用户体验KPI推无限滚动,运营按转化率KPI推Load More,SEO这边等到三个月后看Search Console才发现:集合页深层商品页根本没进索引,第2页之后的着陆词归零,权重像漏斗一样从首屏漏掉。问题的根源不是“哪种方案最好”,而是大家都没搞清Googlebot怎么读这些前端模式、它的渲染队列里到底愿意为列表型页面花多少预算。
这篇我把四种方案放到同一张评估矩阵里,按抓取覆盖率、权重传导效率、重复内容风险、移动端体验、技术维护成本五个维度逐一拆。中间穿插一段宠物用品DTC客户的8周改造实战、列表页SEO的canonical与sitemap配套写法,以及一份新手最容易踩的7条误区清单。
分页和无限滚动到底差在哪?
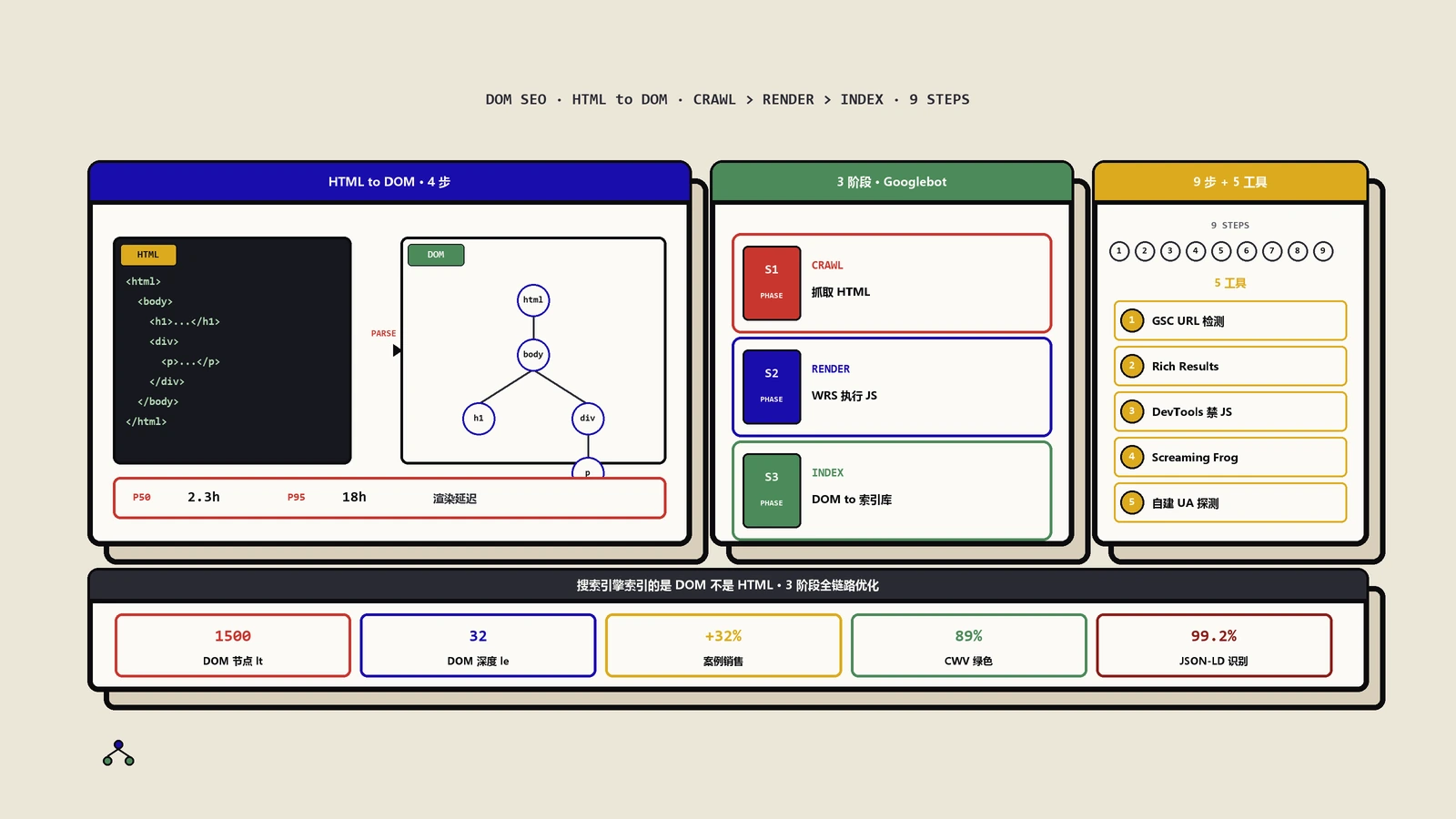
这两个词常被放在一起讨论,但实质完全不是同一类。分页是一种URL模式:一组同类内容被切成多个独立可访问、可索引的URL(通常带 ?page=2 或 /page/2/),每个分页都是一份完整的服务端文档。无限滚动是一种交互模式:用户向下滚动时,前端通过JS动态向DOM追加新内容,URL可能变也可能不变,原始HTML文档里通常只有第一屏。
这意味着分页是HTTP层的事,浏览器和Googlebot都可以靠 a 标签直接跳到任意一页;无限滚动是JS渲染层的事,依赖客户端事件触发,Googlebot抓不抓得到要看它当天愿不愿意为这个域跑JS渲染队列。把它们当一回事的工程团队,往往一边引入了无限滚动的体验、一边丢掉了分页带来的可索引性。
Googlebot抓的是文档,不是浏览体验
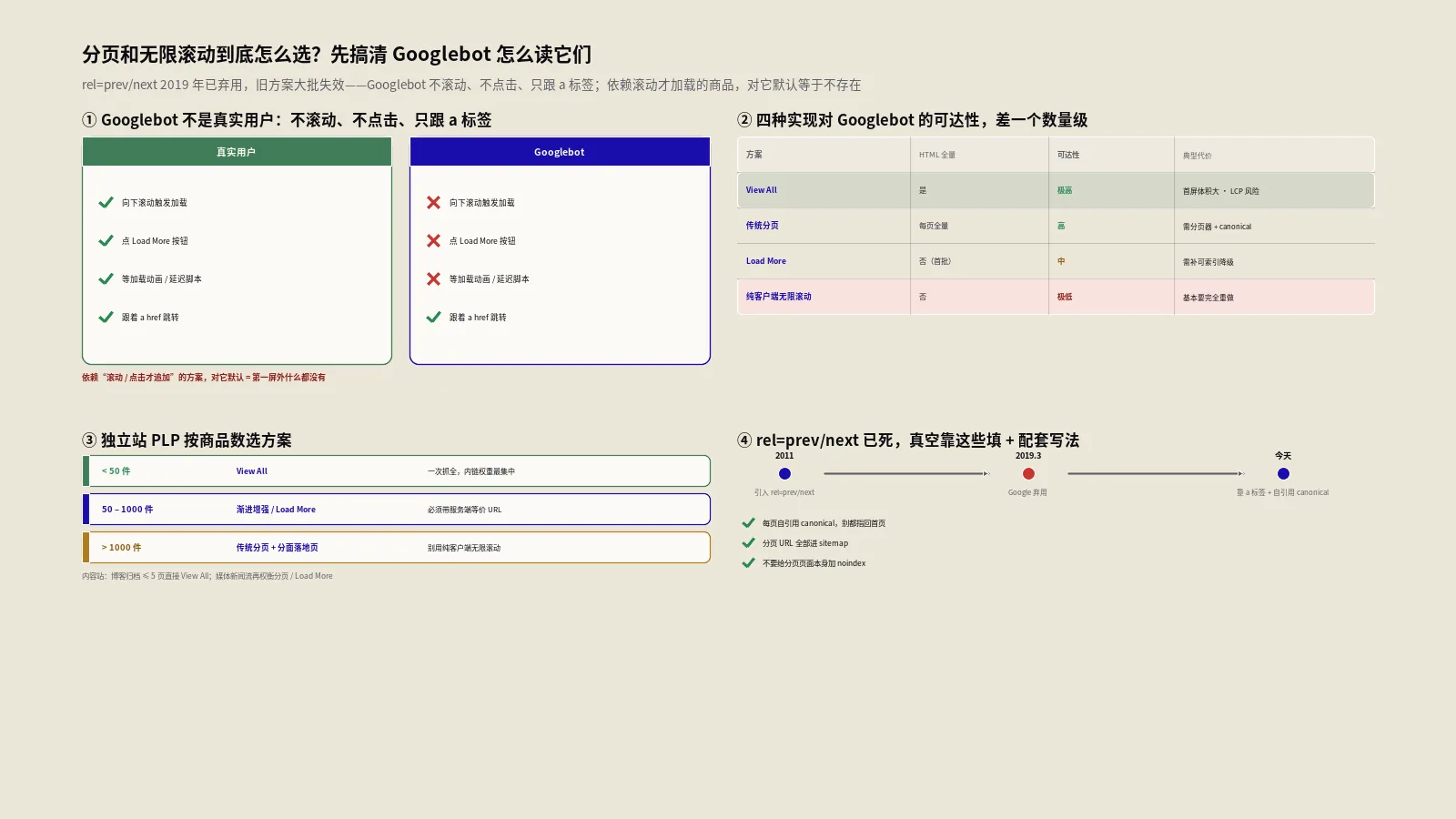
Googlebot不是一个会滚屏、会点击、会等加载动画的真实用户。它是一个HTTP客户端加一个简化的Chromium渲染引擎,按抓取队列里的URL一个个发请求、拿HTML、再决定要不要进渲染队列补一次JS执行。它读DOM、找 a href,把发现的新URL塞回队列。它不会模拟scrollY增加触发IntersectionObserver、不会点Load More按钮、不会等setTimeout延迟脚本。
这条机制是讨论分页SEO的地基。任何依赖“用户向下滚动才追加新内容”的方案,对Googlebot来说默认等价于第一屏内容外什么都没有。除非工程上有显式的、非交互依赖的URL入口能让它发现下一段,否则后面那些商品Googlebot永远看不到。
View All、传统分页、Load More、Infinite Scroll四种实现的根本差异
把四种方案对照看一眼差异就清楚了:
| 方案 | URL是否变化 | HTML是否含全量内容 | Googlebot默认可达性 | 典型工程代价 |
|---|---|---|---|---|
| View All(单页全展示) | 不变 | 是 | 极高 | 首屏体积大,LCP风险 |
| 传统分页(独立URL) | 变 | 每页全量 | 高(靠a标签) | 需要分页器组件、canonical策略 |
| Load More按钮 | 可选 | 否(首批) | 中(取决于实现) | 需要补可索引降级方案 |
| 纯客户端Infinite Scroll | 不变 | 否(首批) | 极低 | 需要完全重做 |
四种方案的差距不是体感差异,而是数量级差异。一个2000件商品的电商集合页,用View All时Googlebot一次抓全;用传统分页时只要分页器a标签写对,几周内能爬完;用Load More时如果不做服务端等价URL,第一屏外的1800件商品默认全部隐身;用纯客户端无限滚动时哪怕渲染完成后DOM里有内容,Googlebot也未必愿意每次抓取都执行JS、滚到底等待新批次加载。
rel=prev/next死了,留下的真空怎么填?
2019年3月Google Search Liaison的John Mueller在Twitter上确认:rel=prev和rel=next多年没有被用作索引信号,2019年也没打算重启。这条声明把2011年以后建立的“标准分页SEO写法”一夜间作废。这之后社区花了几年时间补认知差,到现在很多CMS默认模板里还在自动注入rel=prev/next,看不出是无用还是有害。
这玩意儿现在的实际状态:保留它没坏处,浏览器辅助技术和部分非Google引擎仍读取它;删掉也没坏处,Google已经不再依靠它来识别分页组关系。问题在于rel=prev/next死了之后,Google现在到底用什么判断“这一组URL是同一个集合的分页”。答案是:它不再判断了。Google把每一页都当独立URL评估,按页面自身的内容质量、内链信号、用户行为决定排名和索引地位,不再合并权重、不再把第2页的信号回流给第1页。
从2011到2019的旧世界与新世界的断点
旧世界的分页SEO看起来很优雅:rel=prev/next告诉Google这是一组分页、用rel=canonical指向View All或第一页、第2页之后给noindex,follow。这套写法在2012到2018年间被广泛布道、写进无数博客和工具默认模板。它的底层假设是Google会主动合并分页组、把信号传给入口页。
新世界完全相反。Google不再合并、不再传递、不再视分页为“一组”。这意味着第2页就是一个独立页面,第3页也是。如果第2页内容只是第1页商品的换批排序、没有任何独立价值(独立的过滤组合、独立的内容增量、独立的实体覆盖),它本来就该被Google自然识别为薄页或近重复页面,不需要你显式noindex它,它自己也不会有什么排名。
Google现在到底用什么信号判断分页关系?
说“不再判断”也不完全准确。Google仍然会通过URL模式(/category/?page=2)、内链锚文本(“下一页”、“2”、“3”)、面包屑、sitemap里的层级关系等多个软信号识别出“这是一组分页”。但识别出来不代表会合并权重,更不代表会做信号回流。它只是让Google在抓取调度上知道这些URL属于同一域的同一类目,从而决定要不要把这一组放进抓取优先级队列。
对实操来说这条机制翻译过来就是:分页器的a标签写法要保证Google能爬到所有分页URL,但不要再依赖任何信号合并机制来“救”第2页之后的薄页排名。要救得靠让这些页本身有独立价值,或者用View All把它们合并掉,或者直接noindex接受第2页之后无流量。
Googlebot怎么模拟翻页?哪些操作它不做?
把Googlebot当成一个非常笨的爬虫想象:它打开你的页面、读HTML、找到所有 a href 指向同域的链接、把它们塞进待抓取队列、然后离开。它不滚动、不点击、不悬停、不等延迟、不响应IntersectionObserver。哪怕它跑JS渲染,渲染完成后它读到的还是渲染完那一瞬的DOM快照,DOM之后的所有交互变化它都看不到。
这条认知是诊断“为什么我的集合页第2页之后没收录”的入口。绝大多数情况下答案就是:你的分页方式根本没给Googlebot一个能不靠交互到达后续页面的 a 入口。
不会滚动、不会点击、只跟a标签
这条规则严格到什么程度:哪怕你的“下一页”按钮长得像一个 a 标签、视觉上完全一样,只要它的HTML实际是一个 button 元素加onclick跳转,Googlebot也不跟。它跟的是DOM里实打实存在的 a href,URL必须能直接HTTP GET拿到内容、不依赖任何客户端状态。
这条机制衍生出一个常见的“假分页器”陷阱:很多前端框架的分页组件用React Router或Vue Router做客户端路由,URL看起来在变(实际只是history.pushState),Googlebot跟过去发现服务端响应的是SPA框架壳子、内容靠JS才能填进去。这种情况下渲染队列能不能补救要看Googlebot当天的心情和这个站的整体渲染优先级,可控性极差。
JS渲染的“假”分页器陷阱
更微妙的一个翻车场景:分页器是真 a 标签,但点进第2页时URL是 /category/?page=2#products,服务端忽略hash,所有page参数也忽略,返回的还是第1页内容;只有JS跑起来后才根据URL重新渲染第2页的商品。Googlebot跟过去,发现第2页HTML和第1页一模一样,自动把第2页判为重复页、合并到第1页,从此第2页商品永远不在索引里。
这种情况要靠服务端渲染或服务端响应不同分页参数返回不同内容的能力来根治。这是分页SEO排查时最隐蔽、也是大型SPA站最容易翻的一类车。
四种方案的索引覆盖率与权重稀释差多少?
抛开具体场景,单看Googlebot视角下的客观差异:
View All的内链权重集中度最高
View All方案下,整个集合的所有内容浓缩到一个URL。所有指向该集合的外链、所有内部导航的锚文本权重、所有用户行为信号全部归一到这一页。内链网络上它是一个超级节点,权重传导效率最高。代价是首屏HTML体积、LCP风险、移动端滚动体验,但这些可以用懒加载图片、虚拟滚动容器、骨架屏等工程手段缓解。
对内链架构而言这是最干净的方案。详见内链架构与权重传导这套配套讨论。
传统分页的两难:第2页之后流量塌方
传统分页方案下,第1页、第2页、第3页都是独立URL,理论上都能收录、都能拿排名。但实务中第2页之后绝大多数集合页流量趋近于零,原因有三:第2页本身没有独立查询意图与之匹配(用户搜“户外宠物推车”不会搜“户外宠物推车 第2页”)、第2页内容是第1页的同质换批排序、其他站点几乎不会从外链指向第2页。这导致传统分页方案下,分页器以下的URL形成一个庞大的低质量URL集群,对站点整体的内容质量评估反而是拖累。
救法是让分页器后的页有独立价值:例如分页器和过滤器配合,第2页变成“户外宠物推车 大型犬款 第2页”,挂上独立H1、独立meta、独立面包屑路径。这条思路天然和分面导航SEO重叠,配套讨论见分面导航与筛选器URL治理。
Load More按钮的工程化代价
Load More按钮的卖相在UX层很好:用户看完第一批主动决定要不要继续,比无限滚动更可控、比传统分页更顺滑。但SEO层要付双倍工程代价:要让按钮在JS不跑时降级成一个真 a href 指向 ?page=2 的可点击链接、且服务端能根据page参数返回对应分批商品。这种“渐进增强”实现方式做对了等价于传统分页(Googlebot可达)加按需加载(用户更顺),做错了等价于纯客户端无限滚动(Googlebot完全瞎)。
实务里70%的Load More实现都是错的——按钮是button onclick fetch,没有 a href 降级,服务端不响应page参数。这种实现在Lighthouse跑分上看不出问题,在Googlebot视角下完全等价于“第一屏外什么都没有”。
纯客户端无限滚动 = 灾难现场
纯客户端无限滚动是SEO层最糟糕的方案:用户滚动触发IntersectionObserver,前端fetch下一批商品的JSON数据,DOM追加新元素,URL完全不变。Googlebot抓的就是初始HTML,没有任何机制让它发现并访问后续批次。这等价于把集合页除了第一屏之外的所有商品对Google隐身。
真实见过的最严重一次是一家3000件SKU的家居DTC站,纯客户端无限滚动跑了11个月,第一屏36件以外的2964件商品全部不在Google索引里,自然搜索流量长期只来自首页和10来个手工建的着陆页。这个案例的诊断和改造路径在下面的实测复盘段会详细拆。
独立站电商PLP到底应该选哪个?
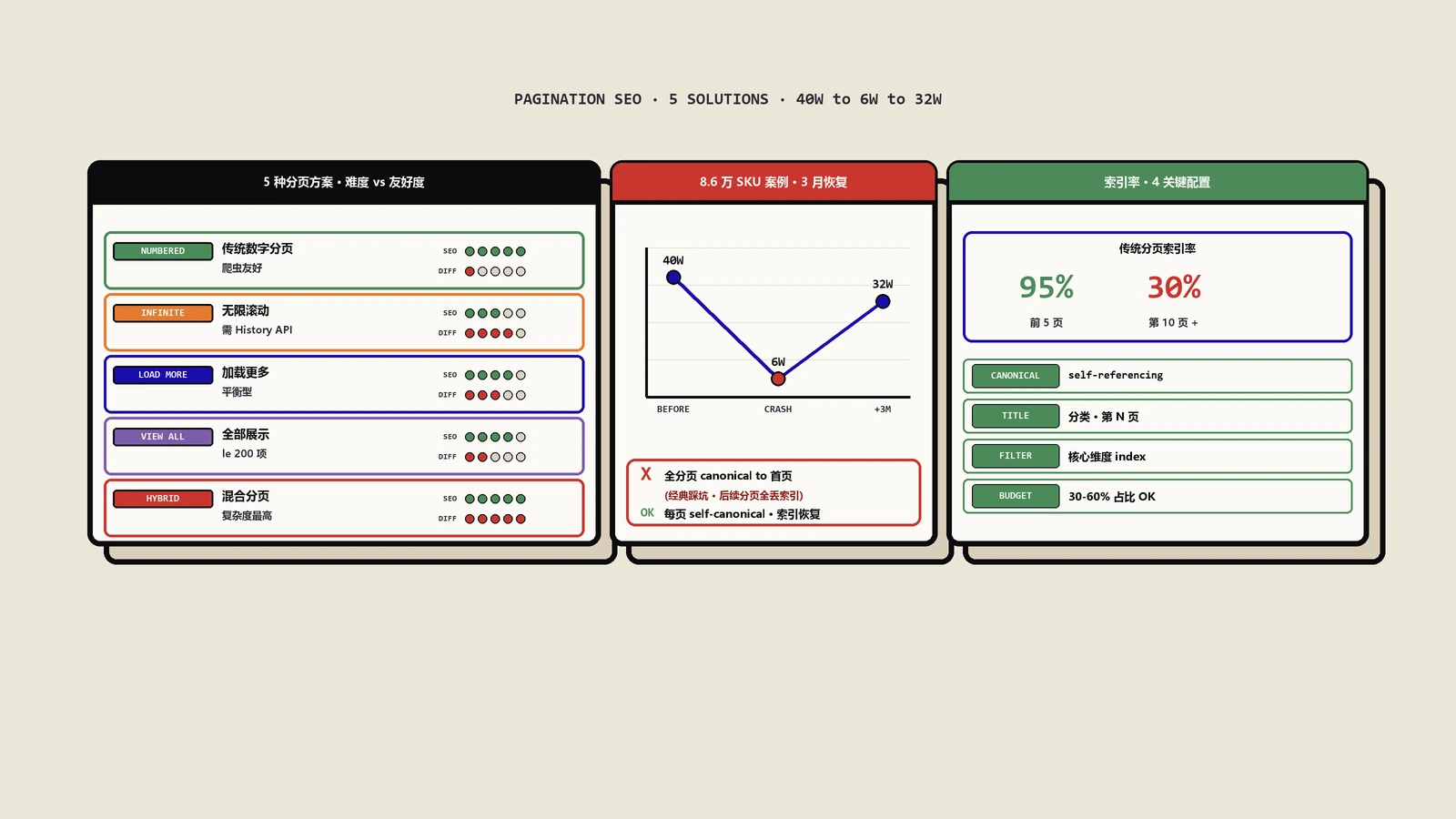
没有“哪种最好”,只有“在你的商品数量、查询意图分布、技术栈条件下哪种最适合”。我用一份决策矩阵给所有PLP工程团队当起点:
| 集合规模 | 推荐方案 | 关键配置 | 典型陷阱 |
|---|---|---|---|
| 商品数 ≤50 | View All单页全展示 | 图片懒加载、首屏18件预渲染 | 过度图片优化忽视LCP |
| 50到500 | 渐进增强Load More | a标签降级、服务端响应page参数 | JS不跑时分页器不可用 |
| 500到3000 | 传统分页 + 过滤组合落地页 | 每页canonical自指、面包屑独立 | 分页页和过滤组合页重复 |
| 3000以上 | 传统分页 + 分面导航严格白名单 | 每页noindex,follow阈值规则 | 抓取预算被组合爆炸消耗 |
商品数小于50用View All
商品数在50以内的集合页,View All几乎是默认选项。一页加载全部商品的HTML体积可控(每件商品约2到4KB的HTML加上图片地址,50件总和约150到300KB),首屏LCP用图片懒加载和fetchpriority调优即可压在2.5秒内。所有外链和内链的权重都集中到这一个URL,对类目权威性建立最有利。
这个规模的集合用分页反而把流量打散:50件商品分5页,每页10件,第2到5页天然薄、几乎没独立查询意图、内链权重被稀释。除非有非常强烈的UX理由(例如设计要求严格的栅格分页节奏),否则没有任何SEO收益。
商品数50到1000用渐进增强infinite scroll或Load More
这个量级的集合既不适合View All(首屏太重)也不适合纯传统分页(10到100页的分页器看着就丑、且大部分分页第2页之后没流量)。渐进增强方案是甜区:用户看到的是Load More或自动滚动加载,体验顺;Googlebot看到的是降级后的 a href 分页器,可达。
实现要点:分页器组件用真 a 标签,href 指向 /category/?page=N 这种独立可访问URL;服务端响应page参数返回对应分批的商品HTML(不能是SPA壳子);JS跑起来后用IntersectionObserver拦截a点击行为,改成AJAX追加DOM;URL用history.pushState同步更新但不刷新页面。这套做完后浏览器视角下是无限滚动体验、Googlebot视角下是传统分页可索引性。
商品数大于1000用传统分页加分面落地页
商品数过千后纯分页本身价值有限——第2页之后的薄页问题加剧、抓取预算消耗大。这时候应该把SEO流量增长的赌注从“分页页”换到“分面导航着陆页”:把分类与品牌、价格区间、属性筛选交叉出有真实查询需求的页面,给它们独立H1、独立meta、独立canonical,让它们承担长尾关键词流量。原始分类页的分页器仍然存在(让Googlebot能爬完所有商品建索引),但分页本身不指望产出排名。
这种架构需要严格的分面白名单与组合爆炸控制,否则会反过来吃掉抓取预算。配套的子集合页SEO工程见电商PLP集合页机制完整指南。
内容站和列表页又该怎么选?
内容站(博客、新闻、知识库)的列表页和电商集合页的逻辑略有差异。内容列表页本身几乎不带商业转化压力,主要是为单篇文章供给抓取入口和内链。这意味着列表页自身的排名能力可以放弃、不需要硬塞H1和meta优化,但抓取可达性要保住——所有文章必须能从首页通过列表页路径在3到4跳内被Googlebot抓到。
博客归档不超过5页就直接View All
普通博客单分类、单标签下的文章数大多在30到100之间,分5到10页。这种规模强烈推荐View All单页全列:所有文章卡片放一页、按发布时间倒序、每个卡片只显示标题加发布日期加摘要(不要带正文片段,会产生大量低质量重复内容)。整页HTML体积可控、内链分布扁平、抓取一次抓完。
这种方案下原本“博客分类 第2页”那种几乎零流量的URL直接消失,索引膨胀风险也跟着消失。
媒体站新闻流分页vs Load More的取舍
媒体站新闻流文章数动辄上千上万,View All不可能。这时候要么用传统分页保抓取可达性、要么用渐进增强Load More。媒体站的特殊性是新文章发布速度快、抓取频率本身就高,Googlebot通常会保持较高频率回访首页和频道页,所以从抓取覆盖率角度问题不大。重点要解决的是分页器以下的薄页堆积、以及老内容在分页深处如何被持续发现的问题。
实务里媒体站的标准做法是首页只保留最新30到50条、分页器只给Googlebot走(用户用搜索而非分页找老文)、加上完整的归档专题页矩阵把旧内容用专题页路径重新组织起来。
canonical / noindex / sitemap与分页器的搭配怎么写?
分页SEO的“标签写法”经常被新手过度强调,实际上这块在rel=prev/next死后简化了很多。这里直接给一份可落地的搭配表:
第2页canonical应该指向自身,不要指向第1页
这是新世界里和旧世界完全相反的写法。旧世界(2014到2018)流行第2页canonical指向View All或第1页,目的是合并权重。新世界Google不合并、还会因为内容明显不同(第2页商品和第1页不重叠)而直接忽略这条canonical,第2页要么自然进入索引(如果内容有价值),要么自然出索引(如果薄)。
建议把第2页之后的canonical都设为自指(指向自己的完整URL,包含分页参数)。这样写既符合Google的当前指引、又不会因为canonical被忽略而产生不可控的索引信号噪声。canonical自指的整体写法可对照canonical URL完整设置指南。
哪些场景才该给分页页noindex,follow?
给分页页noindex,follow的合理场景只有两个:第一,分页器下的页内容确实是薄的同质换批排序、没有独立查询意图,且短期内没有改造为分面落地页的计划;第二,整站抓取预算紧张(百万级URL站点),分页页的抓取浪费明显大于其潜在排名价值。除此以外,noindex是过度防御。
反过来,绝大多数中小站点(10万URL以内)的分页页直接让它们自然进出索引就行:有价值的留下、薄的自动出。强行noindex是给Googlebot加无谓的判断负担。
sitemap是否要把分页页全列进去?
不要。sitemap的本义是“我希望Google优先抓取并收录的URL”,分页页(第2页之后)极少满足这个条件。sitemap应该只列:所有商品详情页、所有分类首页(第1页)、所有真正有独立查询意图的分面落地页。第2页之后留给Googlebot自己从分类首页的分页器一路爬。
把分页页塞进sitemap是把抓取预算分给本来就不该排名的URL,得不偿失。sitemap的整体策略往里再深一层是另一篇技术讨论的事,本文不展开。
保哥的独立站PLP实测复盘(北美宠物用品DTC)
2023年底接的一个北美宠物用品DTC客户,主营高端户外宠物推车、宠物背包、外出训练装备,全站约3000件SKU,集合页层级有4个主分类和22个子分类,纯客户端无限滚动跑了11个月。客户最初的诉求是“自然搜索流量上不去”,但进去做技术SEO审计时直接定位到的根因不是流量优化,而是抓取覆盖率塌方。
原始方案:纯客户端infinite scroll
客户用的是Shopify加一个第三方collection增强主题,集合页默认Shopify分页器被覆盖、改成滚动到底自动fetch下一批24件商品的纯客户端实现。URL完全不随分页变化,所有商品的JSON数据通过Shopify Storefront API在客户端拼装。Lighthouse性能跑分尚可(LCP 2.1秒、INP 180毫秒),UX也没毛病。问题完全藏在SEO层。
诊断6步:从GSC到site: 到日志
保哥的诊断路径标准化:第一步GSC抽取所有商品URL的索引状态,发现3000件商品里只有842件被Google索引(28%)、剩下2158件全部停留在“已发现,但未编入”或“已抓取,但未编入”状态。第二步site: 操作符抽样,搜了8个主分类,每个分类site: 返回的商品数都在24到48件之间,刚好是无限滚动第一批或第二批的量。第三步爬日志(用Shopify提供的请求日志加上Cloudflare日志拼起来)按user-agent过Googlebot,发现Googlebot在11个月里访问集合页约15万次,但从未访问过任何分页URL(因为根本没有分页URL可达)。第四步用爬虫工具Screaming Frog模拟Googlebot跑全站,结果它也只能找到约900件商品,和GSC数据吻合。第五步抽样人工核验,确认未收录商品URL确实可独立访问、内容完整,问题不在商品页本身。第六步分析自然搜索流量的着陆词分布,确认所有非品牌词流量都来自约15个手工建的着陆页和首页本身,集合页贡献接近零。
改造方案与8周流量数据
改造方案落到三件事:第一,把无限滚动改为渐进增强Load More——分页器a标签真实存在指向 /collections/{category}?page=N、服务端响应page参数返回对应分批商品HTML、JS跑起来后才拦截a点击改为AJAX追加。第二,给22个子分类加分面着陆页矩阵——用价格区间和适用宠物体型这两个维度共建出约45个有真实查询意图的着陆页(用Ahrefs和SEMrush对照搜索量筛出的有人搜的组合)。第三,sitemap重做——只列商品详情、分类首页、45个分面着陆页,移除原有的所有utm与sort参数URL。
改造完成后第3周开始GSC的“已抓取,但未编入”队列被消化,到第5周3000件商品的索引覆盖率从28%升到94%;第8周自然搜索流量较改造前提升约2.7倍,新增的流量主要来自分面着陆页和原本未收录的商品长尾词,集合页本身的排名变化反而不显著(这符合预期:集合页本来就不是SEO主战场,是抓取入口)。
常见的7个分页SEO误区
整理一份保哥在客户审计里反复见到的高发误区清单,每条配机制简释:
- 误区一:还在为rel=prev/next写正确实现而较劲。这玩意儿在Google视角下早已是装饰品,写不写都不影响排名,把精力花在抓取可达性上更划算。
- 误区二:第2页canonical指向第1页。2014年那套写法,今天会被Google忽略canonical并把第2页按独立页评估,结果可能更差。
- 误区三:默认给所有分页页加noindex,follow。除非站点URL量过百万、抓取预算紧张,否则不必要——薄页Google会自己识别处理。
- 误区四:分页器是button onclick而不是a href。Googlebot不点击,等价于分页路径不存在。Lighthouse看不出来这个问题。
- 误区五:纯客户端infinite scroll配Lighthouse高分就觉得没事。性能跑分和SEO抓取覆盖率是两套指标,性能好不代表Googlebot抓得到。
- 误区六:sitemap把所有分页页塞进去希望加速收录。反而是稀释抓取预算的常见做法,应该只列真正有独立价值的URL。
- 误区七:把分页页的薄页问题指望GSC URL检查工具一个一个救。这是URL量级层面的系统问题,单页操作救不过来,得回工程层重做分页器与分面策略。
这7条误区有个共同特征:都源于把分页当成一个“标签和指令的小问题”而不是“抓取可达性的工程问题”。把视角从meta标签往上拉一层、回到Googlebot怎么读DOM怎么发请求,绝大多数分页SEO决策就清晰了。
常见问题解答
rel=prev/next真的不能再用了吗?
Google自2019年起明确不再把rel=prev/next用作索引信号,写不写都不影响排名。可以保留(浏览器辅助技术和部分非Google引擎仍读取),也可以删,对SEO是中性。
无限滚动一定是SEO灾难吗?
不是。做成渐进增强方案(分页器a标签降级可达加JS增强体验),就能等价于传统分页保抓取覆盖率。纯客户端追加而URL不变的版本才是灾难。
View All一页加载所有商品会不会拖慢LCP?
几百件以内通常可控,靠图片懒加载与fetchpriority调优能压在2.5秒内。上千件确实拖,这时候应该改用传统分页加分面落地页矩阵的组合架构。
电商站第2页之后流量为零,是不是分页方案选错了?
可能是分页方案问题,也可能是分页页本身内容薄、没独立查询意图、内链网络里没有锚点。先核三件事再决定要不要换方案:第2页是否有独立面包屑、是否被内链指向、内容与第1页差异度是否足够。
Next.js默认的无限滚动如何SEO化?
用SSG或SSR把每页商品作为独立可索引URL预渲染、并保留真 a 标签的分页器;客户端再做infinite scroll增强体验。两者并存才稳。纯CSR客户端追加方案对Googlebot几乎不可见。
分页页应该noindex吗?
绝大多数中小站点不需要,让分页页自然进出索引即可。只有百万级URL站点抓取预算紧张时,才考虑给第2页之后noindex,follow来集中抓取资源。
分页页的canonical怎么写?
自指。第2页canonical写自己(含page参数),不要指向第1页或View All。指错会被Google忽略,产生不必要的索引信号噪声。
分页页要不要进sitemap?
不要。sitemap只列真正希望优先收录的URL,分页页留给Googlebot自己从分类首页爬过去。塞进去反而稀释抓取预算。
Load More按钮怎么做才SEO友好?
关键是渐进增强:HTML里的按钮要降级为真 a href 指向 ?page=2,服务端响应page参数返回对应分批商品HTML;JS跑起来后才用事件拦截改成AJAX追加DOM。这样Googlebot看到的是传统分页、用户看到的是按需加载。
移动端体验和SEO抓取可达性冲突时优先哪个?
不应该冲突。渐进增强方案下两者可以同时满足。如果团队在两者之间纠结,多半是工程实现选错了路径(直接上纯客户端方案),回到渐进增强思路重做即可。
权威参考资料
本文标题:《分页SEO和无限滚动到底怎么选?四种方案完整机制对照》
本文链接:https://zhangwenbao.com/pagination-infinite-scroll-seo-mechanism-complete-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0