GSC URL检查API怎么批量监控收录?2000条配额下的监控管线实战
本文目录
- 先把两个API分清,别再拿错工具
- URL检查API到底能告诉你什么
- 为什么非得批量,界面一条条点不行吗
- 配额这道硬墙:2000一天、600一分钟
- 监控场景一:批量揪出“已抓取-尚未编入索引”
- 监控场景二:canonical不一致,Google选了别的
- 监控场景三:掉索引预警,靠快照对比
- 监控场景四:新内容收录时效追踪
- 监控场景五:robots和meta意外拦截自查
- 怎么搭一条会自己报警的监控管线
- URL从哪来:sitemap还是数据库
- 配额不够,就分层抽样
- 把资源拆细,配额能翻好几倍
- 不想写代码:Screaming Frog现成接好了
- 它和界面、site: 命令、覆盖报告怎么配合
- 读懂返回值:几个字段一起看才准
- AI搜索时代,这套监控更值钱
- 一个外贸独立站的实战切片
- 五个常见误区
- 常见问题解答
- URL检查API和Indexing API到底有什么区别?
- 每天2000次的配额够用吗?
- 不会写代码能用这个API吗?
- API返回的coverageState怎么读?
- 多久跑一次监控合适?
- 都用AI搜索了,盯传统收录还有必要吗?
- 权威参考资料
摘要:站点一上规模,收录就成了一笔糊涂账:GSC界面一次只能查一条URL,几千个页面靠人眼根本盯不过来。URL检查API(URL Inspection API)就是Google官方开的批量通道,每个资源每天2000条,能把每条URL的收录状态、Google选定的规范网址、最后抓取时间、抓取与索引是否被拦统统拉回来。这篇讲清楚它和那个总被搞混的Indexing API到底差在哪、能监控哪五类问题、配额这道硬墙怎么绕、怎么搭一条会自己报警的收录监控管线,以及不想写代码时怎么用Screaming Frog现成接。读完你手里就有一套能落地的批量收录体检方案。
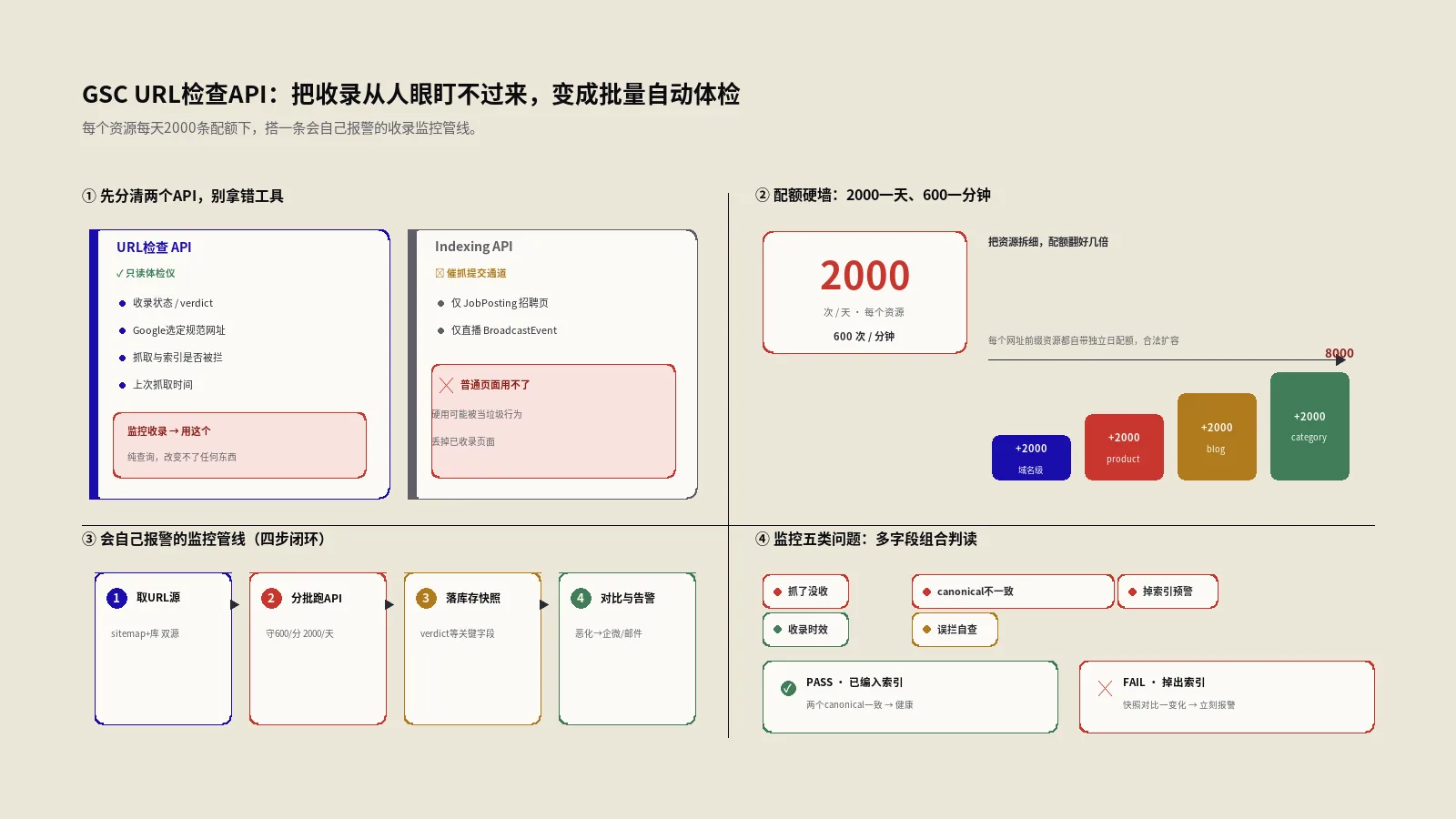
先把两个API分清,别再拿错工具
聊批量监控之前,必须先拆掉一个把无数人坑进去的误会:Google跟Search Console相关的“接口”不止一个,最常被混为一谈的是两个——URL检查API(URL Inspection API)和Indexing API。名字都带index的味道,干的活儿却南辕北辙。
URL检查API是只读的。你喂给它一个URL,它把这条URL在Google眼里的真实状态原样吐回来:有没有被收录、Google给它选的规范网址是哪个、上次什么时候抓的、抓取允不允许、索引允不允许。它不会改变任何东西,纯粹是个“体检仪”。
Indexing API完全是另一回事。它是用来主动通知Google“这个URL更新了,来抓一下”的提交通道。关键的坑在这儿:按Google官方政策,Indexing API只支持两类内容——带JobPosting结构化数据的招聘页,以及嵌在VideoObject里的BroadcastEvent直播页。普通博客文、产品页、分类页统统不在支持范围内。市面上一堆插件把Indexing API包装成“一键催收录”卖给所有人用,2025年5月Google搜索关系团队还专门出来重申过:对不支持的内容格式,这个接口随时可能停掉,硬用甚至有被当作垃圾行为处理、丢掉已收录页面的真实案例。
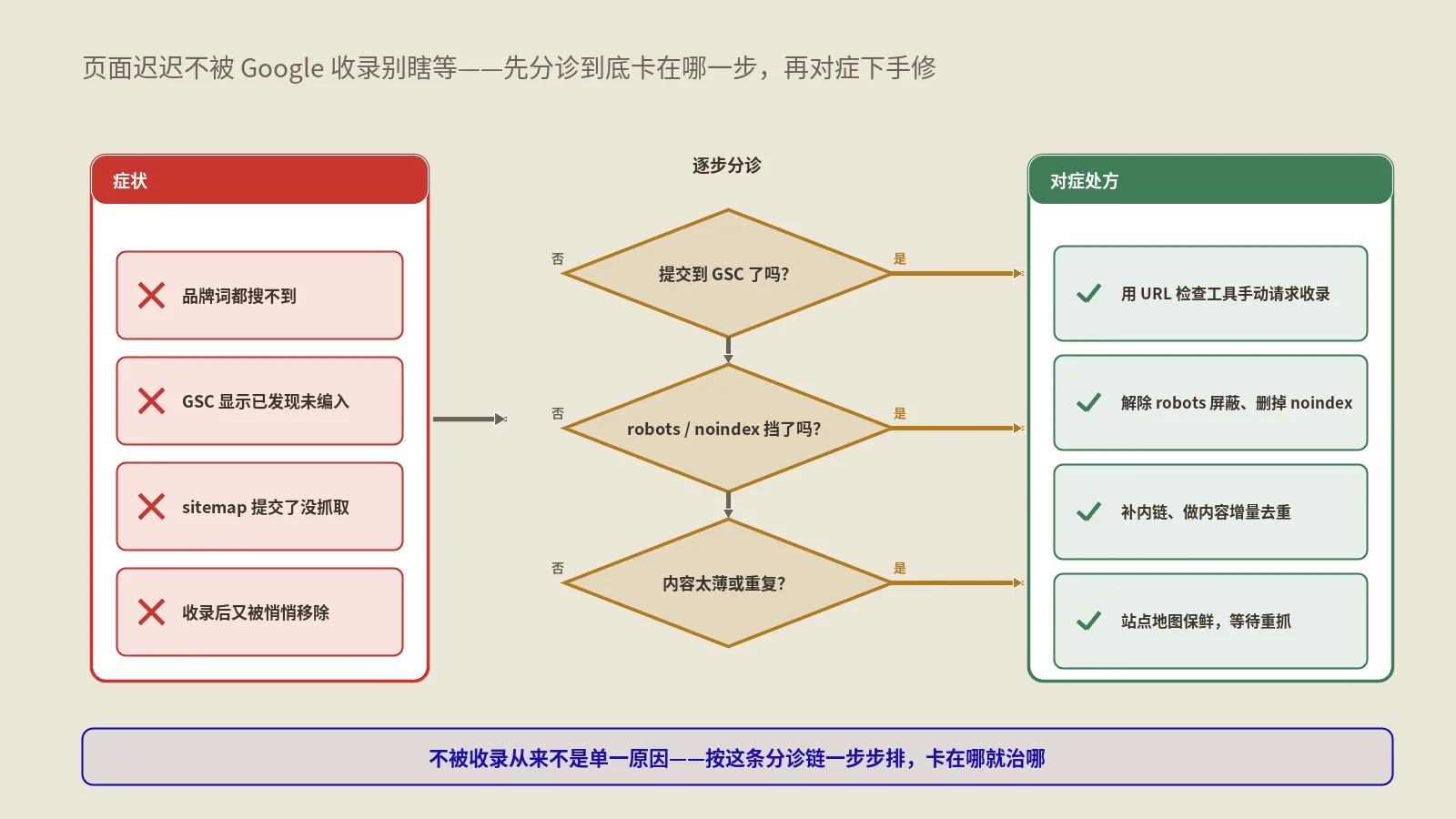
所以记牢这条分工:想知道页面收录状态、做批量诊断和监控,用的是URL检查API;想给招聘页或直播页催抓,才轮到Indexing API。这篇全程只谈前者。至于普通页面的收录怎么催、迟迟不收录怎么救,那是另一套打法,可以看保哥写过的页面不被Google收录的急救手册,本文聚焦在“怎么大规模地看清楚状态”。
URL检查API到底能告诉你什么
把工具用好的前提,是知道它能返回哪些字段。URL检查API的返回值结构和你在GSC界面里点“网址检查”看到的几乎一一对应,核心都装在indexStatusResult这块里,常用的有这几个:
- verdict(总判定):PASS、PARTIAL、FAIL、NEUTRAL四种,一眼看出这条URL整体过没过关。
- coverageState(覆盖状态):最有信息量的一项,比如“已提交并编入索引”“已抓取-尚未编入索引”“已发现-尚未编入索引”“重复网页,Google选择的规范网址与用户指定的不同”。这串状态背后是一整套算法决策,每一种代表卡在了哪个环节。
- robotsTxtState:ALLOWED还是DISALLOWED,robots.txt有没有拦住它。
- indexingState:索引允不允许,会标出是被noindex元标签拦了,还是被HTTP响应头里的X-Robots-Tag拦了。
- lastCrawlTime:上次抓取时间,判断内容新鲜度和抓取频率的硬证据。
- pageFetchState:页面抓取结果,SUCCESSFUL、SOFT_404、各类服务器错误一目了然。
- googleCanonical与userCanonical:Google实际选定的规范网址,以及你自己在页面里声明的规范网址。这两个一旦对不上,就是重复内容或自相残杀的强信号。
- crawledAs:以移动端还是桌面端的身份抓取的。
- referringUrls与sitemap:哪些页面链向它、它被收录在哪个sitemap里。
除了indexStatusResult,返回值里还有mobileUsabilityResult(移动可用性)、richResultsResult(富媒体结果)、ampResult(AMP)三块。这些字段的官方定义和取值,Google在 网址检查工具的官方帮助文档里讲得最清楚,搭监控之前建议把每个状态对应的含义先过一遍,省得后面对着一串英文枚举值发懵。这套字段含义本身就是排查地图——比如批量拉回来后看到一片“已抓取-尚未编入索引”,你就知道问题不在抓取,而在内容质量或重复度这一层。
为什么非得批量,界面一条条点不行吗
GSC界面里的网址检查很好用,但它有个致命限制:一次只能查一条URL,查完还得手动等它跑、手动读结果。站点只有几十个页面时这没问题,一旦上了几千、几万个页面,人工逐条检查就成了不可能完成的任务。
更现实的痛点是,GSC界面和Search Console的其它报告还各有自己的天花板。比如效果报告导出最多1000行、覆盖报告里每类问题示例也只给一小撮样本,想拿到全量、可对账的逐条数据,界面这条路走不通——这套界面侧的数据限制保哥在GSC三大数据黑洞那篇里专门拆过。URL检查API的价值就在这里:它把“逐条精确状态”这件事变成了可以程序化、可以批量、可以定时跑的工程动作。你可以一晚上把核心页面全扫一遍,落进数据库,第二天早上直接看哪些页面状态变了。
这也是它和site: 命令最根本的区别。site: 命令给的是个估算的大概数,告诉你“大约收录了多少”;URL检查API给的是每一条URL在Google索引系统里的确切判定。到底该信哪个、什么场景用哪个,保哥在site: 命令还是GSC信谁那篇里做过三源校准,结论很简单:要精确到单条URL的真相,URL检查API是目前最权威的源。
配额这道硬墙:2000一天、600一分钟
用这个API之前,必须先认清它的硬限制,否则监控方案设计出来根本跑不动。按 Search Console API官方用量限制文档,URL检查的配额是每个资源每天2000次查询(QPD)、每分钟600次(QPM)。注意这是“每个资源”,不是每个账号,也不是每个域名——后面会讲到这条限制怎么被巧妙绕开。
项目层面还有一层更高的天花板:每天1000万次、每分钟15000次。但对绝大多数站点来说,卡死你的永远是那个2000一天的资源级配额。这意味着什么?如果你的站有5万个URL,想全站每天扫一遍,纯靠单个资源的配额,得跑25天才能轮完一圈。这个数字直接决定了你的监控策略不能是“无脑全扫”,而必须是“有优先级的抽样”。
这道墙不是缺陷,是Google防止接口被滥用的设计。认清它,才能把每天宝贵的2000次额度花在刀刃上——核心赚钱页面值得天天看,海量长尾页面排着队慢慢轮。
监控场景一:批量揪出“已抓取-尚未编入索引”
这是URL检查API最高频的用法。“已抓取-尚未编入索引”(Crawled - currently not indexed)是个让无数站长头疼的状态:Google来抓了,但看完决定不收。少量出现是正常的,一旦成片出现,就是内容质量、重复度或站点整体权威度出了系统性问题。
Ahrefs在关于“已抓取-尚未编入索引”的分析里说得很直白:这个状态往往指向内容太薄、和站内其它页面重复、或者整体价值不足以让Google觉得值得占用索引空间。靠GSC界面你只能看到一个总数和零星几个样本,根本不知道具体是哪几百个URL中招。用API批量拉一遍,把所有coverageState等于这个值的URL全捞出来,你才能真正动手——是该合并、该删、还是该加料。这一步是从“知道有问题”到“知道改哪儿”的关键跳跃。
每种“未编入索引”状态背后的算法逻辑不一样,处理方式也不同。这套状态机的完整决策路径,可以对照站内那篇GSC索引覆盖8种状态机制来读,API拉回来的coverageState字段值,和那篇讲的状态是一套东西。
监控场景二:canonical不一致,Google选了别的
googleCanonical和userCanonical这两个字段对不上,是个被严重低估的预警信号。你在页面里规规矩矩声明了规范网址,结果Google偏不认,自己挑了另一个URL当规范版本——这通常意味着站内有重复内容、参数页泛滥、或者内链信号把权重导错了地方。
界面里逐条看这俩字段慢得要命,但用API批量比对就快了:把两个字段不相等的URL全筛出来,立刻就能看到重复内容的全貌。这对电商站尤其重要——筛选参数、排序参数、变体页很容易制造出一堆Google不认账的规范网址。批量揪出来之后,再回到内链架构和canonical声明上做归一治理,效率比一条条点高出好几个量级。
监控场景三:掉索引预警,靠快照对比
页面今天好好收录着,明天可能就悄悄掉了。改版、误加noindex、服务器抽风、被算法重新评估,都可能让原本PASS的页面变成FAIL。如果只在出问题后才偶然发现,流量可能已经掉了一大截。
监控的精髓就在“对比”二字。把每次API跑出来的结果存成快照,落进数据库,下一次跑完和上一次比:哪些URL从“已编入索引”变成了“未编入索引”,哪些verdict从PASS掉到了FAIL。这种变化才是真正值得报警的信号。单次快照只能告诉你此刻的状态,时间序列才能告诉你趋势——而趋势里藏着所有掉索引事故的早期预兆。这也是为什么监控管线一定要落库、要留历史,而不是跑完看一眼就扔。
监控场景四:新内容收录时效追踪
发了新文章、上了新产品,多久被Google收录?这个数据对评估站点健康度和抓取预算极有价值。新站或权威度不足的站,新内容可能要等好几天甚至几周才进索引;健康的成熟站往往几小时到一天就收了。
用API盯住最近发布的一批URL,每天跑一遍,记录它们从“已发现”到“已抓取”再到“已编入索引”的时间线,你就有了一条客观的收录时效曲线。这条曲线掉头变慢,往往是抓取预算吃紧或站点信号变差的早期警报,比等到流量下滑再回头查要早得多。把它和服务器日志里的Googlebot抓取频率放一起看,新鲜度问题基本能定位到根。
监控场景五:robots和meta意外拦截自查
最冤的掉收录,是自己人手滑造成的:上线时忘了删测试环境的noindex、robots.txt误拦了某个目录、CDN配置在响应头里塞了X-Robots-Tag。这类问题在界面里一个个查能查到崩溃。
API的robotsTxtState和indexingState两个字段专治这个。批量跑一遍,把robotsTxtState等于DISALLOWED、或indexingState不等于“允许索引”的URL全筛出来,一眼就能看出哪些重要页面被自己人误拦了。改版上线后跑这么一遍,等于给收录上了一道保险,这比事后从流量曲线里反推问题省心太多。
怎么搭一条会自己报警的监控管线
把上面五个场景串起来,就是一条完整的收录监控管线。骨架四步:
- 取URL源:从sitemap或自己的数据库里拉出要监控的URL清单,按重要性分层。
- 分批跑API:遵守600/分钟、2000/天的配额,控制好请求节奏,别一股脑打爆触发限流。
- 落库存快照:把每条URL的关键字段(verdict、coverageState、两个canonical、lastCrawlTime)连同跑批日期存进数据库。
- 对比与告警:和上一次快照比对,状态恶化的URL推到通知渠道(邮件、企业微信、Slack都行)。
认证这块要走OAuth,前提是这个资源已经在你的Search Console账号里验证过。请求体很简单,本质就是给urlInspection.index.inspect这个端点发一个带目标URL和资源地址的JSON,比如:
POST https://searchconsole.googleapis.com/v1/urlInspection/index:inspect
{
"inspectionUrl": "https://example.com/product/abc",
"siteUrl": "sc-domain:example.com"
}返回的就是前面讲的那一大坨字段。语言用Python还是Node不重要,重要的是把“取数-落库-对比-告警”这条闭环跑起来,并且让它定时自动跑——监控的价值全在“自动”和“持续”这两个词上,跑一次的体检和天天跑的监控,是完全不同的两件事。
告警这一步最容易翻车的地方是阈值没设好。一上来就把任何状态变化都推通知,结果每天几十条消息,看几天就没人理了,监控形同虚设。比较稳的做法是分级:核心赚钱页面只要从PASS掉到FAIL,立刻高优先级告警,单条都要管;长尾页面则设个比例阈值,比如某个目录下未编入索引的占比一夜之间涨了五个百分点才报,单个长尾页掉了不必惊动人。再配上一条“连续两次跑批都异常才告警”的去抖动规则,能滤掉Google索引本身的短期波动,避免被一惊一乍的假警报反复打扰。把噪音压下去,留下来的每一条告警才值得认真对待,这是监控能长期坚持下来的前提。
URL从哪来:sitemap还是数据库
监控清单的来源直接决定监控的盲区。最省事的是直接读sitemap,但sitemap里的URL不等于站点全部URL——孤岛页面、被遗漏的页面恰恰不在sitemap里,而这些往往才是问题高发区。
更稳的做法是双源:sitemap给一份,站点数据库或爬虫全量抓一份,两份取并集。这样既能监控“我以为该收录的页面”(sitemap),也能照看到“我可能忘了的页面”(数据库里有但sitemap没有)。对内容量大的站,再叠一层优先级标签——哪些是核心赚钱页、哪些是长尾、哪些是辅助页——为下一步的分层抽样做准备。
配额不够,就分层抽样
2000一天对大站永远不够,所以聪明的监控方案从不试图天天全扫,而是按价值分层、按节奏轮询:
- 核心页面:每天扫。带来主要流量和转化的那几百个页面,值得每天占用一部分额度盯紧。
- 重要长尾:每周扫。有一定流量的中段页面,一周一次足够发现趋势。
- 全站长尾:每月轮。海量低流量页面,用每天剩余的额度排队慢慢轮,一个月覆盖一圈。
- 新发内容:发布后连扫几天。专门追踪收录时效,进了索引就降频。
这套分层的本质,是承认“不是所有URL都同等重要”。把有限的2000次额度,按页面对生意的贡献来分配,才是大站监控的正解。
把资源拆细,配额能翻好几倍
这是个很多人不知道的技巧:2000的配额是按“资源”算的,而一个域名在Search Console里可以验证成多个资源。除了域名级资源,你还可以为子目录、子域名分别建立网址前缀资源,每个新资源都自带独立的2000次日配额。
举个例子,一个电商站把 /product/、/blog/、/category/ 分别验证成独立的网址前缀资源,加上域名级资源,理论上每天能查的总量就从2000涨到了8000。对URL数量庞大的站,这是合法、官方支持的扩容手段,比单纯等额度刷新实在得多。代价只是初期多做几次资源验证,长期看非常划算。
不想写代码:Screaming Frog现成接好了
不是每个SEO都想自己写脚本维护管线。好消息是,Screaming Frog这类成熟工具早就把URL检查API集成进去了。按 Screaming Frog自动化URL检查API的官方教程,你只要在爬取时连上GSC账号、勾选URL Inspection,它就会在爬虫数据旁边自动拉回每个URL的收录状态,单个资源同样受2000/天的配额约束,结果能从批量导出菜单直接导成表格。
这条路对中小站尤其香:不用碰OAuth、不用自己写落库逻辑,爬一遍就能拿到收录状态、富媒体结果、引用页面这些数据。当年Screaming Frog刚接入这个能力时,Search Engine Journal的报道就点明了它最大的意义——让批量核对URL收不收录、有没有警告,从一件苦活变成了爬虫顺带就干完的事。当然,工具接的是同一个API,配额墙一样躲不掉,定时自动化、历史对比这些深度需求,最终可能还是得回到自建管线。先用工具把场景跑通,需求长出来了再上代码,是更稳的节奏。
它和界面、site: 命令、覆盖报告怎么配合
Search Console这套工具一路演变到今天,已经从早年单纯的“站长工具”长成了一个覆盖收录、效果、体验、链接的完整诊断平台,光是和收录沾边的入口就好几个,各自看问题的角度不一样——这段历史和功能版图,维基百科的Google Search Console词条梳理得比较系统。理解它们的分工,才知道URL检查API该补在哪一格。URL检查API不是来取代谁的,而是补上一块拼图。可以这么分工:
- 覆盖报告(页面索引报告):看全站宏观趋势,哪类问题在涨在跌。
- site: 命令:手头快速估个大概,几秒钟看个量级。
- GSC界面网址检查:深挖单条URL,看实时抓取、申请重新编入索引。
- URL检查API:批量、逐条、可落库、可对比的精确状态,是监控自动化的引擎。
这几样配合起来用:覆盖报告发现某类问题在涨,API批量定位到具体是哪几百个URL,界面深挖典型样本搞清根因,改完再用API跑一遍确认修复生效。这是一条从宏观到微观再回到验证的完整闭环。
读懂返回值:几个字段一起看才准
新手最容易犯的错,是只盯着verdict一个字段。其实单看任何一个字段都可能误判,得组合着读。举几个常见组合:
verdict是PASS、coverageState是“已提交并编入索引”、两个canonical一致——这是最健康的状态,不用管。verdict是NEUTRAL、coverageState是“已抓取-尚未编入索引”——抓到了没收,去查内容质量。indexingState标了被noindex拦、但你压根没想拦它——这是误伤,赶紧改。googleCanonical和userCanonical不一致、coverageState提到重复网页——重复内容问题,去理顺canonical和内链。pageFetchState是SOFT_404,但页面其实正常——可能是内容太薄被判软404,得加料。
把这套“字段组合到诊断”的对应关系做成一张速查表,监控管线告警时直接套表给结论,团队里不懂技术的人也能看懂下一步该干嘛。这一步做扎实,监控才真正变成生产力,而不是又一堆没人看的数据。
AI搜索时代,这套监控更值钱
有人会问,都AI搜索了,盯传统收录还有意义吗?意义反而更大了。AI概览、AI模式从哪儿取内容?绝大部分还是从Google已经索引的网页里召回。一个页面连传统索引都没进,AI引用它的概率几乎为零——没被收录,就等于在AI的候选池里不存在。
所以收录依然是地基,地基不稳,上面盖的GEO优化全是空中楼阁。更关键的是,AI搜索对内容质量和规范网址一致性的要求只高不低,前面讲的“已抓取未编入索引”成片出现、canonical被Google改判这些问题,在AI时代会被进一步放大。用URL检查API把收录这层地基天天盯牢,恰恰是做好AI可见性的第一步,而不是过时动作。
一个外贸独立站的实战切片
保哥手边有个做户外储能的独立站客户,产品SKU加上博客有小一万个URL。之前他们完全靠GSC界面零散地看收录,直到某次大改版后流量莫名其妙掉了两成,才回头排查,发现一整个产品系列因为模板里误带了noindex,整批掉出了索引,而这事儿已经持续了快三周。
后来给他们搭了套基于URL检查API的监控:核心产品页和高流量博客每天扫、长尾每周轮,落库做快照对比,verdict从PASS掉到FAIL的URL第二天就推企业微信告警。上线后没多久就抓到一次CDN配置变更导致部分页面响应头多了X-Robots-Tag的事故,从出问题到收到告警不到一天,改回去后又用API确认了批量恢复。同一类事故,监控前花了三周才发现,监控后一天就堵住——这就是把收录从“偶尔看看”变成“持续盯着”的差别。
五个常见误区
误区一:拿URL检查API去催收录。它是只读的体检仪,改变不了任何东西。想催收录是Indexing API的活,而且Indexing API只认招聘和直播两类内容,普通页面用不了。
误区二:想天天全站扫一遍。2000的日配额对大站根本不够,硬扫只会让监控方案跑不完。正解是按价值分层抽样,核心页天天看,长尾排队轮。
误区三:跑完看一眼就完事。不落库、不留历史,等于丢掉了监控最值钱的部分。掉索引预警全靠时间序列对比,单次快照看不出趋势。
误区四:只看verdict一个字段。单字段容易误判,必须几个字段组合着读,coverageState、两个canonical、indexingState一起看才得出靠谱结论。
误区五:以为有了API就不用界面和覆盖报告了。它们各管一段,宏观趋势看报告、批量定位用API、深挖根因回界面,配合才完整。
常见问题解答
URL检查API和Indexing API到底有什么区别?
URL检查API是只读的,用来查询URL在Google索引里的真实状态,做诊断和监控;Indexing API是用来主动通知Google来抓取的提交通道,而且按官方政策只支持带JobPosting的招聘页和嵌在VideoObject里的BroadcastEvent直播页,普通页面不能用。想监控收录用前者,别拿错了。
每天2000次的配额够用吗?
对小站够,对几千上万URL的大站远远不够。应对办法有两个:一是按页面价值分层抽样,核心页每天扫、长尾每周或每月轮;二是把站点在Search Console里拆成多个网址前缀资源(按子目录或子域名),每个资源都有独立的2000次日配额,能成倍扩容。
不会写代码能用这个API吗?
能。Screaming Frog这类工具已经把URL检查API集成好了,连上GSC账号、勾选对应选项,爬取时就会自动拉回每个URL的收录状态并支持批量导出,同样受2000/天的配额约束。先用工具把监控场景跑通,等深度需求(定时自动、历史对比、自动告警)长出来了,再考虑自建脚本管线。
API返回的coverageState怎么读?
coverageState是最有信息量的字段,告诉你这条URL卡在收录的哪个环节。常见值有已提交并编入索引(健康)、已抓取-尚未编入索引(抓了没收,多半是内容质量或重复问题)、已发现-尚未编入索引(连抓都还没抓,常和抓取预算有关)、重复网页规范网址不一致(重复内容信号)。每种状态对应不同的处理动作,建议对照GSC索引覆盖状态机制逐一摸清。
多久跑一次监控合适?
按页面分层定节奏:核心赚钱页面每天跑一次,及时发现掉索引;重要长尾每周一次看趋势;全站长尾用每天剩余额度排队,一个月覆盖一圈;新发布的内容发布后连续扫几天追踪收录时效,进索引后降频。关键是定时自动跑并落库对比,而不是想起来才跑一次。
都用AI搜索了,盯传统收录还有必要吗?
非常有必要。AI概览和AI模式主要从Google已索引的网页里召回内容,页面连传统索引都没进,被AI引用的概率几乎为零。收录是GEO和AI可见性的地基,地基不稳上面全白搭,所以用URL检查API盯牢收录,反而是做好AI时代可见性的第一步。
权威参考资料
本文标题:《GSC URL检查API怎么批量监控收录?2000条配额下的监控管线实战》
本文链接:https://zhangwenbao.com/gsc-url-inspection-api-bulk-index-monitoring.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0