site:命令还是GSC,收录数据到底信谁?6场景选型决策与三源校准实战

本文目录
- site:命令和GSC到底测的是不是同一件事?
- “谁更准”这个问题为什么本身就问错了?
- 6种典型场景到底该用哪一个?
- 从这张表里能抽出哪3条决策原则?
- URL检查工具真的能“实时”判断单页收录吗?
- URL检查工具能告诉你什么?
- URL检查工具不能告诉你什么?
- 配额这一关也经常被忽略
- 请求编入索引按钮按下去之后到底发生了什么?
- 把site:数字当KPI是怎么坑掉一支SEO团队的?
- 怎么用site:×GSC×服务器日志三源校准一次性看穿真相?
- 三源对账的4步操作流程
- 什么时候三源全部用,什么时候省一个?
- 冷启动站、中型站、大型站使用决策有什么差异?
- 收录看不到的5种边缘案例你绕得过去吗?
- 收录数量之外焦点应该放在哪3件事上?
- 未收录URL的状态分布
- 收录但impression=0的URL占比
- 抓取健康度
- 常见问题解答
- site:命令显示0条结果是不是网站被完全去索引了?
- site:数字突然涨了10倍是好事吗?
- GSC URL检查显示已索引但site:搜不到怎么办?
- 新发布的页面要不要立刻按请求编入索引按钮?
- GSC的“已编入索引”和Bing Webmaster Tools的索引数能直接比较吗?
- 大站5万URL以上GSC索引报告卡在抽样1000行怎么办?
- 用第三方工具如Ahrefs/Semrush的“索引页面数”能替代GSC吗?
- 权威参考资料
摘要:查收录到底信site命令还是GSC?前者是抽样估算,后者是带一两天滞后的索引库快照。本文给准的三层定义、六种典型场景该用哪个、把site数字当KPI怎么坑掉一支团队,以及用site命令加GSC加服务器日志三源校准的四步对账,贯穿冷启动站到大型站的使用差异。
TLDR:问site:还是GSC谁更准本身就问错了——两者测的根本不是同一件事。site:命令测的是Google现在愿意展示给你的估算抽样,GSC测的是Google索引数据库的权威快照(带1到3天滞后)。决定何时信谁、何时并用、何时把两边都先放一边去看服务器日志,是这篇要讲清的事。
保哥把6场景选型决策、URL检查工具的实时性真相、请求编入索引按钮的5种被忽略、site:×GSC×日志三源校准、冷启动/中型/大型三层站点的工具组合差异,连同两套客户复盘一次串起来。读完你会发现,争论谁更准,远不如学会在什么场景信谁来得有用。
site:命令和GSC到底测的是不是同一件事?
大量SEO从业者第一次发现site:domain.com给出1.2万条结果、而GSC后台只有4800条已编入索引时,第一反应是“哪个错了”。其实两个数都没错,只是它们在度量两个完全不同的对象。
site:命令是Google公共搜索界面上的搜索语法,本质上是Google对你这个域的“展示候选池”做一次实时抽样估算。它会受当前PageRank阈值、爬虫近期采样口径、SafeSearch、Personalization、查询时间等多维因素干扰,同一查询刷新3次,数字可能晃5%到15%。Google Search Central 排查搜索流量下降的官方指南里也提到 site: 运算符给出的数字本身就不能当作索引依据。
GSC后台的“已编入索引”则是Google内部索引服务直接读取索引数据库的快照,延迟1到3天落到你看到的报表上。它接近你这个域名在Google索引库里真实存在的页面计数,但它不等于“会被任何用户查到”的页面数——这中间还隔着一层质量阈值与查询匹配。
两者关系类似超市的库存账和货架点数:库存账记得详细但更新有延迟,货架点数实时但只是抽样展示。问“哪个数更准”,就像问“账面更准还是点货更准”——取决于你要回答什么问题。
这里还有一层往往被忽略的因素:Google公共搜索界面上的site:数字不是直接从核心索引读取,中间隔着一层服务展示层缓存,缓存周期约15分钟到6小时不等。所以你看到的site:数字不仅是抽样、是估算,还可能是缓存里的旧抽样估算。三层不确定叠加,site:数字在数学意义上就不该被当成精确指标。
“谁更准”这个问题为什么本身就问错了?
“准”在数据语境里至少有3种含义:完整性(是否数到全量)、时效性(是否反映此刻)、有效性(是否对应真实价值)。site:和GSC在这3个维度上是错位互补的,不是简单的谁压谁。
| 维度 | site:命令 | GSC已编入索引 |
|---|---|---|
| 完整性 | 低(前数十页抽样展示) | 高(理论全量,但受1000行表格上限影响下钻精度) |
| 时效性 | 高(分钟级近实时) | 低(1到3天滞后,偶尔一周) |
| 有效性 | 低(混入参数URL、重复页、估算误差约±30%) | 高(已过canonical与去重决策,8种状态分流过滤) |
正确的提问不是“哪个更准”,而是“现在要做的这个决策需要哪一种准”。判断一个刚发布的页面有没有被搜到,时效性优先,site:单URL查询配合GSC URL检查;审计全站索引健康度,有效性与完整性优先,GSC索引报告是唯一答案。两者本来就是不同岗位的工具。
保哥常和团队讲一句话:site:是江湖速查不是审计工具,GSC是审计工具不是排名诊断器。把工具用错位,就是大量SEO诊断失误的源头。新人最容易踩的坑是把site:当作“Google之眼”——以为它能透视索引库的真相,其实它只是Google愿意展示给路人的橱窗摆设。橱窗摆设有它的用处,但拿它做月度审计就是另一码事。
6种典型场景到底该用哪一个?
把抽象的“看场景选工具”落到6个高频实操场景上,一张表能省去大量来回切换的犹豫。
| 场景 | 首选 | 备用 | 判断理由 |
|---|---|---|---|
| 新发布的1篇文章有没有被收录 | GSC URL检查工具 | site:精确URL | URL检查接近实时,能给出抓取/索引/规范化三层状态;site:有时延后5到30分钟 |
| 整站收录数趋势怎么走 | GSC索引报告 | 无 | site:数字浮动太大不可作趋势依据 |
| 某目录下页面是不是被批量抓掉 | site:domain.com/folder | GSC按路径过滤 | site:能秒级展示目录级抽样,GSC按路径过滤要1到3天补数 |
| 未收录页面为什么没收 | GSC URL检查+索引报告 | 无 | 原因诊断只有GSC 8种状态机制能讲清 |
| 子目录被同行用site:扫到没 | site:domain.com inurl:子串 | 无 | 这是竞品做的事,自己只能用site:模拟 |
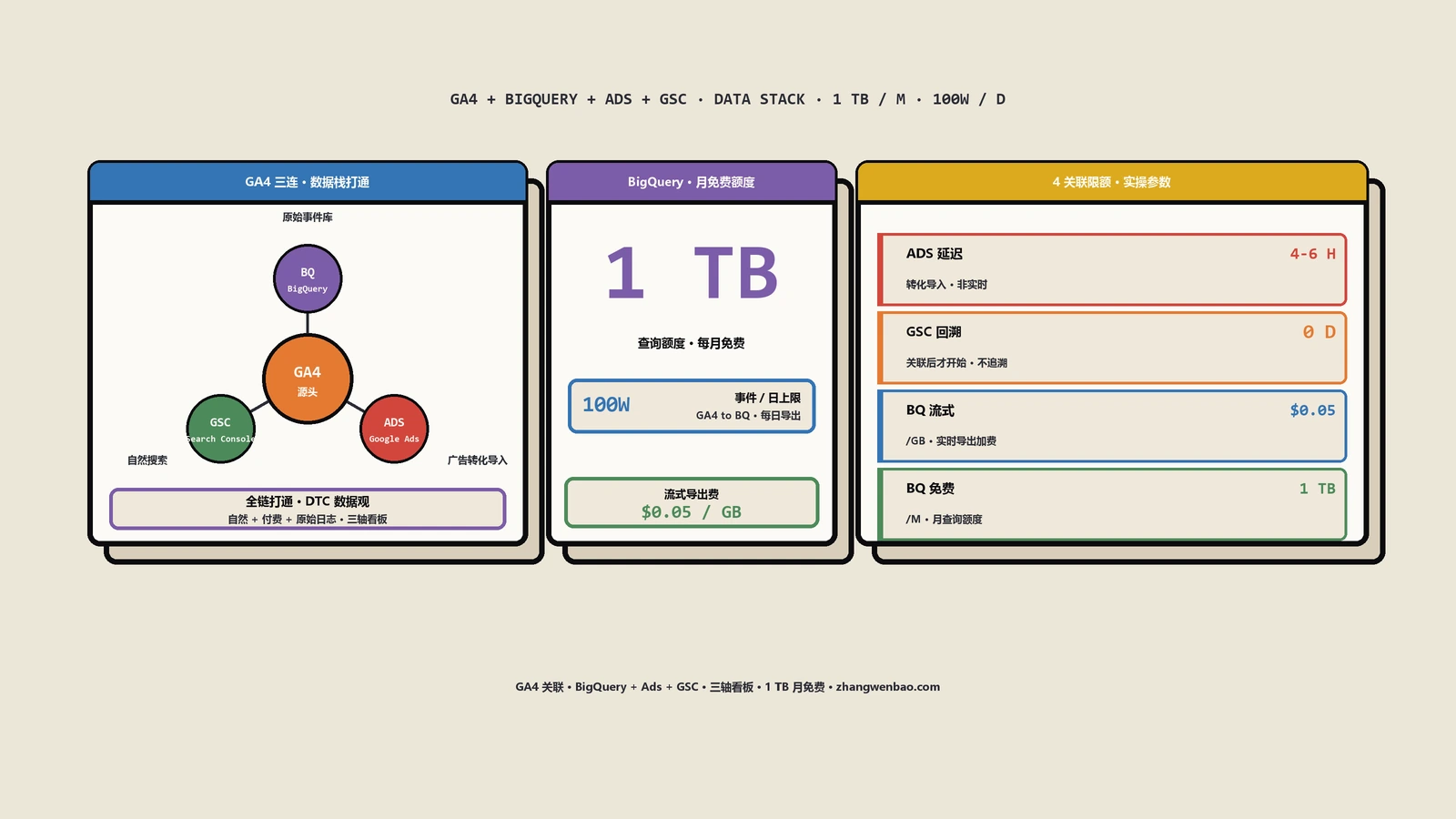
| 大型站索引健康度审计 | GSC API + BigQuery Export | site:抽查目录 | 5万URL以上site:命令直接失效,GSC需要工程化补全 |
从这张表里能抽出哪3条决策原则?
第一条原则:单点查询走URL检查、整体趋势走GSC、目录抽查走site:,三类问题三种工具,不要混用。第二条原则:site:命令越是要做“全站”判断越不可靠,越是要做“单点”或“目录抽查”越好用;GSC正好相反,单点查询不如URL检查灵敏,但全站审计是它的主场。第三条原则:当两个工具的答案出现冲突时,永远以GSC为主、site:为辅——除非GSC本身因配额或滞后明显失真,那时候要降级到服务器日志而不是降级到site:。
这套表跑下来你会发现一个规律:两个工具的最佳分工不重叠。试图用一个工具回答所有问题,是工具使用上的“万能锤思维”——手里握着锤子,看什么都像钉子。GSC像审计师的笔记本,site:像门口保安的目测,让审计师在门口查身份和让保安管账本,都是错配。
URL检查工具真的能“实时”判断单页收录吗?
很多人误以为GSC 的 URL Inspection Tool 官方文档里那套交互是真实时——按下“测试已发布的URL”按钮就立即得到当前Google索引状态。实际上它是“近实时”,存在一个常被忽略的60秒到5分钟级延迟,特别是高峰时段或大型站点上。
URL检查工具能告诉你什么?
当前是否被索引、规范URL是哪条、上次抓取时间、移动版可用性、增强功能(结构化数据、AMP)状态、是否被robots.txt或noindex屏蔽。能“实时测试”的部分是“模拟抓取当前线上版本”,不是“查询Google现在的最终索引状态”——两个动作差很远。模拟抓取看到的是站点此刻返回的HTML、robots指令、规范标签等;最终索引状态要等Google把抓取结果送回数据中心走完质量评估流水线,这条流水线短则数分钟长则数小时。
URL检查工具不能告诉你什么?
这条URL是否在用户查询里被实际展示过(要去效果报告看impression)、这条URL是否被Google判定为低质而扔进Crawled - currently not indexed(要去索引覆盖报告看分类)、整批URL的状态分布(URL检查是单条查的,不支持批量)、规范URL选择的具体冲突原因(要去canonical报告看,URL检查只显示结果不显示决策路径)。把单URL状态判断当成全站健康指标,是用错工具的典型表现。
配额这一关也经常被忽略
URL检查工具的UI入口实际约束在每分钟10次、每天50次到100次(不同站点配额浮动)。要批量做诊断,得走URL Inspection API,配额单独计算且更宽松(每天2000次起,企业型站点可以申请上调),但需要OAuth对接。三大数据黑洞那篇里展开过API那条路。日常排查用UI入口几条几条试就够,需要批量时直接上API而不是猛刷UI——猛刷UI会触发临时封锁,等数小时才解除。
请求编入索引按钮按下去之后到底发生了什么?
URL检查工具下面那个“请求编入索引”按钮,是无数SEO新人的安慰剂——按下去之后内心觉得已经把球踢回给Google了。真实情况是:按钮把这条URL塞进Google的一个高优先级抓取队列,但塞进队列不等于必然抓取,更不等于抓取后必然收录。
平均看,请求后24到72小时内Google会重新爬一遍这条URL,比正常发现流程快3到10倍。但请求会被Google忽略的常见原因有5个:
- 同一URL短时间内反复请求。系统识别为滥用,第二次以后请求会被静默丢弃,但UI仍显示“请求已接收”——这是设计上的反爬。所谓“短时间”在Google侧大约是7天滚动窗口,期间同URL最多被加速一次。
- URL已经处于Crawled - currently not indexed状态。意思是Google抓过、判断质量不够、扔回队列。再请求一次还是被判低质,按钮按一万次都没用,要先改内容。这是踩坑率最高的一类,新人会在“同一篇低质文章上反复请求20次然后疑惑”为什么不收——答案是Google早就抓过了,每次重新抓只是再确认一次它确实不行。
- 站点配额耗尽。Google公开说法是每天单站10次,实际经验值在5到15次之间浮动,超过后UI仍能点但不会真进队列。配额会在UTC时区的零点重置,跨时区运营要注意这一点。
- 这条URL被robots.txt屏蔽或返回4xx/5xx。请求会被立即拒绝,按钮变灰。如果你看到按钮可点但状态卡在“索引中”超过3天,去检查这条URL的HTTP响应码与robots指令,多半在那里出了问题。
- 整站质量信号偏低或新站沙盒期。新站特别是3个月以内的站,请求成功率显著低于成熟站。Google对新站走更保守的索引策略,请求编入索引按钮在新站上接近装饰。
这里有个反作用要警惕:在低质内容上猛按请求编入索引,等同于反复邀请Google来重新评估你的“低质判定”,几轮之后Google对整站的初始信任分会被拉低。请求编入索引是“我修过了请重审”的信号,不是“求你收一下”的催促按钮。这两种用法在系统看来差别巨大——前者是负责任的内容更新,后者是无意义的骚扰。
把site:数字当KPI是怎么坑掉一支SEO团队的?
保哥之前接手过一家东南亚美妆DTC客户,团队季度OKR写的是“将site:domain.com结果数从8200提升到1.2万”。3个月下来这个数字确实涨到了1.18万,看起来达标,但实际自然流量持平、转化反而掉了4个点。老板拿着数字开庆功会,营销总监心里隐约觉得不对,找到保哥来复盘。
查下来根因是:site:数字膨胀几乎全部来自参数URL未做canonical治理——产品筛选页带?color、?size、?sort等参数被Google当成独立URL索引,膨胀的3800个全是没有真实搜索价值的“幽灵URL”。同时GSC后台显示“Duplicate without user-selected canonical”状态的URL从1100涨到4900,这才是真相。
两个数据源放在一起看,故事就清楚了:site:数字涨的不是真实索引能力,是Google对参数URL的暂时容忍——这种容忍随时可能因为算法更新被收回,到时候站点会经历一次惨烈的索引断崖。
修复动作做了4步:①给所有参数URL补上指向标准URL的canonical;②robots.txt屏蔽特定参数组合的抓取;③用canonical决策逻辑那篇的9步排查表对照清理;④把团队季度KPI从“site:数字”换成“GSC已编入索引且产生过impression的URL占比”。半年后这个新KPI涨了31%,自然流量翻了一倍。期间site:数字反而从1.18万掉回到6800——但没人在意,因为新KPI已经把团队注意力锚定到真正能带来流量的页面上。
这个案例的教训不是“site:不能看”,而是把抽样估算当成绝对计数的KPI,必然引导团队朝错误方向努力。SEO团队的OKR要绑权威数据源,GSC某些字段+服务器日志组合才能扛住季度审视。一个常见的反问是:“GSC数据有延迟,怎么当季度OKR?”答案是季度本来就是1到3个月的尺度,几天滞后在这个尺度上完全可忽略——把延迟当借口往往是想用快但不准的数据偷懒。
怎么用site:×GSC×服务器日志三源校准一次性看穿真相?
site:和GSC都有结构性误差,最稳的诊断方法是把第三方源拉进来做三角校验。三个数据源各看一个角度,互相印证才能锁定真相。
| 来源 | 测量对象 | 强项 | 弱项 |
|---|---|---|---|
| site:命令 | Google公共展示候选 | 实时、零配置 | 抽样、估算、含参数噪声 |
| GSC索引报告 | Google索引库快照 | 权威、状态分类 | 滞后1到3天、1000行表格上限 |
| 服务器日志(Googlebot抓取) | 真实抓取行为 | 100%真相、毫秒级粒度 | 不区分索引与否、需要解析工具 |
三源对账的4步操作流程
第一步,导出GSC站点地图列表与索引报告的“已编入索引”URL,作为A集合;第二步,用site:domain.com抽样100条URL逐条核对是否在SERP出现,作为B样本;第三步,拉过去30天的Googlebot访问日志,提取唯一URL作为C集合;第四步,对A、B、C做集合运算:A∩C是“被抓被收的健康集”,A−C是“号称已索引但近期未被重新爬的潜在僵尸”,C−A是“被频繁抓但未被收的低质或新页”,B−A是“site:误报或正在等待索引落库的延迟集”。
三组差集每一组都对应一类待处理任务:僵尸URL评估要不要noindex、低质未收URL重写内容、site:误报URL等GSC刷新后再判断。这套对账保哥在三家对账方法那篇里用过Ahrefs/Semrush/GSC的版本,site:×GSC×日志这一版更聚焦索引可见度。
什么时候三源全部用,什么时候省一个?
常规月度审计,三源都用;新站冷启动期日志数据量不够,省日志保留site:+GSC即可;大型站超过20万URL,site:命令的抽样早已失去统计意义,省site:用GSC+日志双源就够,把节省下来的精力投到日志解析的工程化上。判断的核心是:每一源拿什么填补另一源的盲区,如果某一源的盲区已经被其他源覆盖,那一源就可以省掉,不要为了凑“三源”而强行用。工具组合的精神是分工,不是凑齐。
冷启动站、中型站、大型站使用决策有什么差异?
同一套工具在不同规模站点上的最优用法完全不同。把决策按站点规模分3层,比一刀切清晰得多。
| 规模 | 每日工具组合 | 每周 | 每月 |
|---|---|---|---|
| 冷启动站 <200 URL | 新发布每篇用URL检查+主动请求收录 | site:domain.com跑一遍数趋势 | GSC索引报告对照URL总数 |
| 中型站200到5万URL | 不主动看收录 | GSC索引报告 + site:抽查热门目录 | 导出GSC全量URL与sitemap做差集对账 |
| 大型站 >5万URL | 不主动看收录 | GSC API拉日报到BI | 三源对账 + GSC + BigQuery Export + 日志全跑 |
冷启动站的问题不在于工具用不准,而在于发文量小,每篇都重要,要保证每篇都进索引;这阶段site:命令查单URL比GSC URL检查响应快一点点,可以并用。中型站做不到逐篇盯,要靠GSC整体趋势看健康度,site:用于热点目录的抽查。大型站的site:命令几乎完全失效——5万URL以上的样本,site:展示的只是几百条头部抽样,看了等于没看,必须走API与日志工程化。
保哥前段时间帮一家北美B2B工业配件工厂客户做12万URL的索引诊断,全程没用过一次site:命令——不是排斥而是没意义。所有判断走GSC API批量拉URL Inspection、抓取统计报告、Apache日志解析,三周内把“已抓未收”占比从27%压到9%,期间site:命令的数字几乎没动过(仍然在3万附近浮动),但真实索引健康度已经天翻地覆。这是数据可观测性的常识:测量工具要匹配被测对象的量级,量级一变工具就要换。
收录看不到的5种边缘案例你绕得过去吗?
site:看不到、GSC也漏报的边缘场景,几乎都跟Google的内部规范化、版本管理或权限模型有关。常见5类,每一类都有人在上面栽过跟头。
- 已被robots.txt屏蔽但仍出现在索引里。Google的策略是“robots.txt控制抓取不控制索引”——只要外部有链接指向,Google可以基于链接信号建立无内容索引项。site:能搜到、GSC标“已索引但被robots.txt屏蔽”。解决要noindex而非robots.txt。详见noindex与canonical能同时设吗。这是新人最容易栽的一个坑——以为屏蔽抓取就等于屏蔽收录,发现搜索结果里还在就一脸懵。
- 已noindex但Google缓存仍未清。noindex发出后到Google真正从索引库里移除有1到3周延迟,期间site:还能搜到、URL检查会显示“由于noindex已排除”。noindex多久从SERP消失那篇详细展开过6场景。这类延迟在做合规下架时最让人头痛——内容明明已经按法务要求做了noindex,但用户还在搜索结果里能看到,业务方会以为没生效。
- ccTLD国家版本在本国可见、其他国家不可见。用美国IP的site:domain.de结果与德国IP不同,GSC不区分用户地理只显示一份。多区域站要走国家版本的Search Console属性单独看,不能用主站属性一把过。多语言/多区域电商最容易踩这个坑——以为德国版收录良好,结果美国用户搜不到一半URL。
- 移动版与桌面版分裂索引。移动优先索引切换不完全的老站,可能出现移动URL已索引、桌面URL未索引(或反之)的分裂情况。site:看不出来,GSC URL检查能切移动/桌面视角才能看出,参考移动优先索引机制。这类问题在2018年到2021年迁移期最常见,现在新站基本不会遇到,但有m.子域历史的老站还会零星出现。
- GSC域属性与URL前缀属性数据差异。同一站点用域属性看是8200条已索引、用URL前缀属性看是5300条,差额是子域和协议变体URL。网域vs网址前缀那篇的6场景选型表能直接套用。多数情况下推荐用域属性作主报表、URL前缀属性看子集,但不要混用两个属性的数字做加减。
这5类的共同点:site:作为公开搜索语法无法看到底层算法决策,必须借助GSC的权威视角与日志佐证。任何一个边缘场景被忽略,整站索引诊断都可能漏判。把这5类当作诊断流程的常规检查项,能避开大部分让人抓狂的“为什么数据对不上”深夜。
收录数量之外焦点应该放在哪3件事上?
跑完上面所有诊断,最后回到一个最容易被忽略的问题:盯着“已收录URL总数”这个数字,本身就是次优策略。收录是入场券不是终点,跟它强相关但被低估的3件事,价值远大于把site:数字盘出小数点。
未收录URL的状态分布
GSC索引报告里的“未编入索引”部分,按状态分8类(已抓取但未编入、已发现但未抓取、规范化重复、软404等)。这8类不是8个技术标签,是8条算法决策路径,那篇专题讲透了。盯这个分布的趋势比盯已收录数更有杠杆——状态分布告诉你Google为什么没收,已收录数只告诉你收了多少。一个典型的健康站“已抓取但未编入索引”占未收录总数应在15%以下,超过30%就是内容质量警报;“发现但未抓取”占比涨说明抓取预算分配出了问题,要去看抓取统计报告。
收录但impression=0的URL占比
很多页面收录了但在30天内0展示,意味着对任何查询都不够相关,相当于索引库里的僵尸。GSC效果报告按URL过滤能拉到这个清单。健康站点该比例在10%到25%之间,超过35%就是内容质量与收录排名流量三层模型里“收录但卡在排名”那一层的强警示。处理这类URL有3条路:①重写让它能匹配真实查询;②合并到相关性更强的URL并301;③直接noindex让索引预算释放给有效URL。三选一不要保留观望——僵尸URL会持续消耗站点的索引信任分。
抓取健康度
GSC抓取统计报告里看每日抓取请求数、平均响应时间、按响应代码分布的趋势。Googlebot抓取频次掉、5xx占比涨、平均响应时间超800毫秒,这3个信号任意一个持续2周就要立刻处理服务器侧。抓取健康是收录健康的上游,上游一坏整条诊断链都被污染。一个常被忽视的细节:Googlebot会根据站点的响应速度动态调整抓取频次——你慢它就少来,少来就发现更慢,恶性循环。所以服务器侧的TTFB优化对收录的影响比想象中大。
把焦点从“收录数量”挪到“未收录原因 + 收录但无展示 + 抓取健康”3件事上,相当于把SEO诊断从看体重的早晨秤升级到看体脂、肌肉量、基础代谢的体检报告。前者一秒看完心情起伏,后者真的能告诉你身体出了什么问题。一个体重数字降下来未必是好事——可能是脱水,可能是肌肉流失;一个收录数字涨上去未必是好事——可能是参数URL膨胀,可能是低质量页面被暂时收录后批量丢弃前的回光返照。
常见问题解答
site:命令显示0条结果是不是网站被完全去索引了?
不一定。先确认查询语法对不对(site:和域之间不能有空格、www与非www是不同实体);再用GSC URL检查任意1条已知存在的URL看具体状态;最后查GSC的“手动操作”和“安全问题”报告,确认有没有人工处罚。Google大规模去索引整站比想象中罕见,site:0条更常见的原因是查询拼错或刚发生暂时性故障,几小时内会恢复。
如果GSC URL检查显示有索引、但site:确实0条持续超过24小时,那要看是不是站点被打入临时降级——这种情况一般3到7天自动恢复,但要去查根因(多数是质量信号波动或被同IP邻居拖累)。
site:数字突然涨了10倍是好事吗?
大概率不是。突然暴涨通常是参数URL或分页未做canonical收敛导致的索引膨胀,或者被同一CDN下其他站点的URL误绑(多见于Shopify、Wix等共享主机环境)。先在GSC索引报告里看“已编入索引”的同期趋势,如果GSC平稳site:暴涨,几乎100%是索引膨胀问题,应当用canonical决策逻辑排查参数URL。处理思路一律是收敛而非放任——索引膨胀短期看是数字好看,中期一定会被算法判定为低质量站点而批量降权。
GSC URL检查显示已索引但site:搜不到怎么办?
这是正常的延迟现象——URL检查读的是Google内部索引状态,site:依赖的展示候选池更新更慢,差异24到72小时内会自动消失。
如果7天后仍然site:搜不到,看3个可能:①URL虽然索引但质量阈值低,被排除在公开搜索结果之外(GSC效果报告impression会是0);②URL有noindex的延迟生效;③Personalization导致你自己的浏览器拉到的SERP和别人不同,换隐身模式或不同IP再试。最后这一条最常被忽略——保哥见过太多人用自己长期登录的浏览器查自家URL,反而被Personalization拉偏了结果。
新发布的页面要不要立刻按请求编入索引按钮?
分情况。如果是重要落地页或时效性强的活动页,按一下能加速24到72小时;如果是普通博客文章站点本身有日活百次以上Googlebot抓取,等自然发现就够。每个站每天的请求配额有限(实际5到15次之间),要省着用在真正需要快收的页面上。频繁按低质页是反作用,前面讲过。判断的简易规则是:这条URL是不是值得Google额外消耗一次抓取预算?如果是,按;如果只是日常发文,让自然流程跑就好。
GSC的“已编入索引”和Bing Webmaster Tools的索引数能直接比较吗?
不能。两家搜索引擎的索引策略、规范化逻辑、质量阈值完全不同。Bing倾向收录更激进,相同站点Bing索引数常比Google高30%到60%。横向比要做但只比趋势不比绝对值——比如两个引擎都涨说明全站健康;只有Bing涨Google不涨,多半是Google的质量信号没过关,要回去看8种未收录状态分布。Bing SEO完全指南那篇展开了两家引擎的策略差异。
大站5万URL以上GSC索引报告卡在抽样1000行怎么办?
GSC UI界面有1000行硬上限,大站必须走3条路绕过:①GSC API的urlInspection批量接口(每天200K配额);②BigQuery Export把GSC数据导到数仓后无行数限制;③按URL路径分桶用过滤器分别取1000行再合并。
三大数据黑洞那篇把这3条路拆得很细,按操作步骤跟一遍就行。最容易忽略的一点是BigQuery Export需要单独开启并绑定计费账户,配置时要预算每天50MB到500MB的存储成本(按站点规模),但相对解决“看不见全量数据”这个根本问题,这点存储成本几乎可以忽略。
用第三方工具如Ahrefs/Semrush的“索引页面数”能替代GSC吗?
不能。Ahrefs/Semrush用自己的爬虫估算“Google收录数”,本质是另一种估算——他们既不是Google也没有Google的索引库访问权限,只能基于自家爬取数据反推。三家工具的索引数字常常差异巨大,Ahrefs和Semrush之间可能差50%以上。它们的真实价值在反向链接和关键词数据,索引计数只作参考。三家对账方法那篇专门讲怎么把三家工具数据对齐到一致的口径。
权威参考资料
本文标题:《site:命令还是GSC,收录数据到底信谁?6场景选型决策与三源校准实战》
本文链接:https://zhangwenbao.com/site-search-operator-vs-gsc-coverage-accuracy-decision.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0