已收录页面加noindex后多久从SERP消失?6大场景实测
本文目录
- Google清除索引的常规处理时间
- 如何加快页面从SERP中的消失速度
- 添加noindex的注意事项
- 给网站批量添加noindex标签的最佳方案
- 实施前的关键准备
- 具体配置方法
- 实施后的验证与监控
- 常见注意事项
- 如何判断Googlebot是否已经重新抓取了添加noindex的页面?
- 使用 Google Search Console 直接验证
- 通过搜索引擎结果间接判断
- 注意事项与最佳实践
- 网站如何平衡noindex与nofollow的使用?
- 平衡使用的核心原则
- 实施建议与注意事项
- 总结
- 如何评估noindex和nofollow的使用效果?
- 监控索引状态与爬虫行为
- 分析搜索排名与流量变化
- 评估链接权重的分配
- 警惕常见问题与错误配置
- 常见问题解答
- 权威参考资料
摘要:给已收录的页面加noindex后,它要多久才从Google搜索结果里消失?本文讲清从几天到数月不等的处理时间,给加速消失的方法——比如用GSC的移除工具、批量配置noindex的方案,再讲noindex与nofollow怎么平衡使用,帮你尽快把低质页清出索引、不再拖累整站排名。
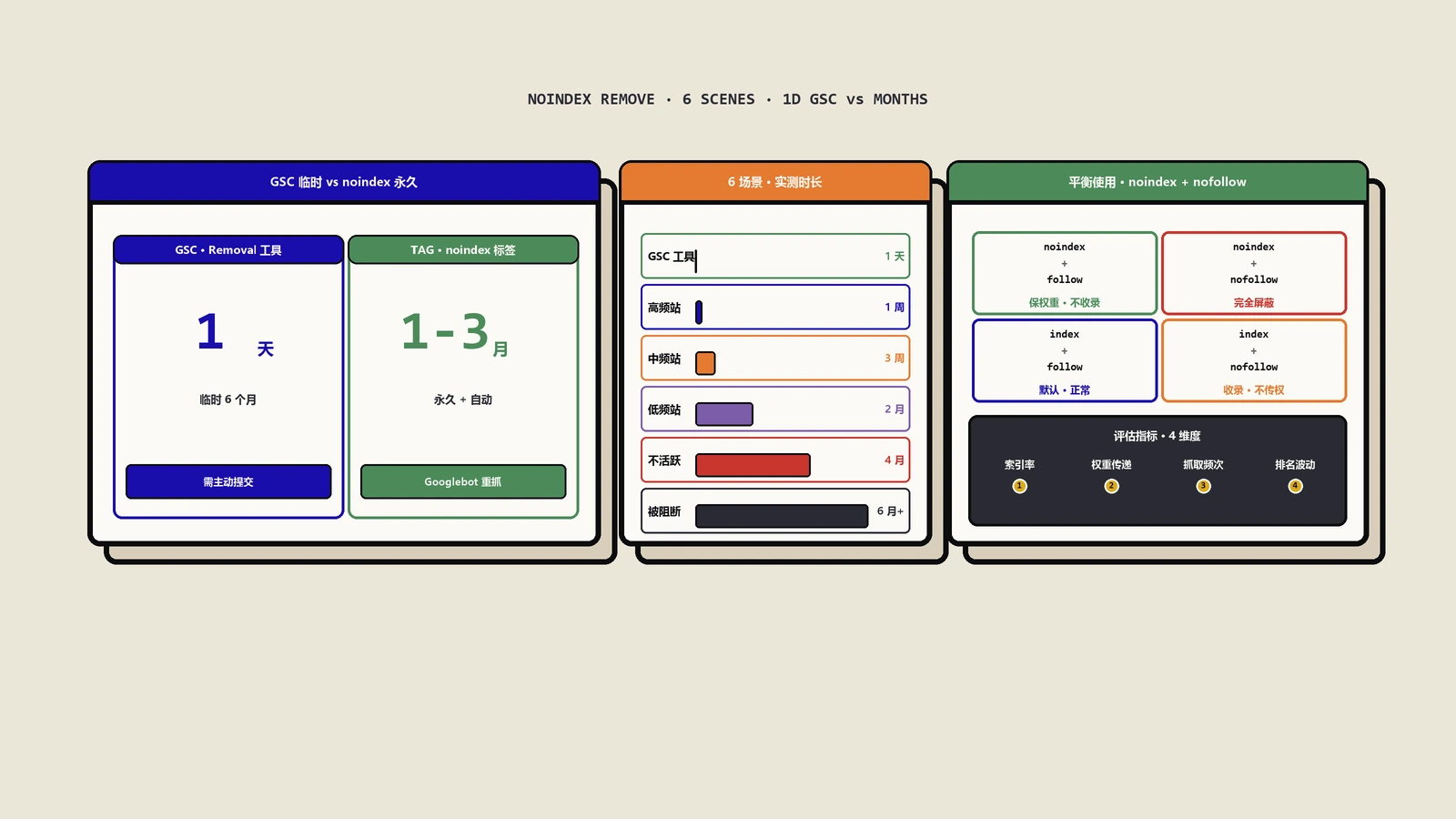
给已收录的页面添加 <a href="https://developers.google.com/search/docs/crawling-indexing/block-indexing?hl=zh-cn" rel="external noopener" target="_blank">noindex</a> 标签后,它们并不会立刻从 Google 搜索结果中消失。这个过程需要一些时间。下面保哥讲清原因、时间范围,再给几个加快处理的方法。
Google清除索引的常规处理时间
Google 需要重新抓取(re-crawl)这些已收录的页面后,才能发现并识别新添加的 noindex 标签。而 Googlebot 重新访问页面的频率并不固定,这通常会导致延迟。
- 一般需要数天到数月不等:这个时间取决于 Googlebot 下次抓取该页面的时间。对于更新较频繁的网站,Googlebot 访问会更勤快一些,可能几周内就能处理。对于一些不常更新的网站,这个过程可能会长达数月。
- Noindex 生效的前提:非常重要的一点是,要确保页面没有被
robots.txt文件屏蔽。如果robots.txt阻止了 Googlebot 访问,它将无法看到页面上的noindex标签,那么这个页面仍然可能会出现在搜索结果中。
如何加快页面从SERP中的消失速度
如果你希望页面能更快地从搜索结果中移除,可以尝试以下方法:
- 使用 Google Search Console 移除工具:这是最直接快速的临时解决方案。在 Search Console 的“移除”工具中提交网址,Google 通常会在大约 1 天内处理请求,使该网址进入“正在处理请求”状态并从搜索结果中临时移除(有效期约6个月)。但这只是临时隐藏,在此期间你需要确保
noindex或其他的永久性措施(如删除页面)生效,否则6个月后页面可能重新出现。 - 主动请求重新抓取:在 Google Search Console 的“网址检查”工具中输入添加了
noindex的页面网址,然后使用“请求索引”功能。这并不会立刻移除页面,但可以向 Googlebot 提示该页面有更新,有可能加快其抓取和发现noindex标签的过程。 更彻底的方法:如果你追求立即和永久性的移除,可以考虑:
- 直接删除页面:并从服务器返回
404(未找到)或410(已永久删除)状态码。这是最明确的告诉 Google 页面已不存在的方式。 - 设置密码保护:限制搜索引擎和普通用户访问该页面。
- 直接删除页面:并从服务器返回
添加noindex的注意事项
- 检查所有URL变体:一个页面可能通过多个不同的网址访问(例如,大小写不同、参数不同)。确保为所有可能被收录的网址变体都添加了
noindex标签或进行了处理,否则它们可能仍会出现在搜索结果中。 - 缓存和CDN:如果你网站使用了CDN或强缓存,需确保其已更新,不会向Googlebot提供旧版本的(不含
noindex的)页面。 - 使用“noindex”而非“robots.txt”:重申一下,
robots.txt文件中的Disallow指令是用来阻止抓取的,不能用来移除已索引的页面。相反,它可能会阻止 Googlebot 看到你的noindex指令。
给网站批量添加noindex标签的最佳方案
为大型网站批量添加 noindex 标签是一项重要的技术SEO工作,核心在于效率、准确性和可持续性。下面这张表把几种实施方式的核心要点摆在一起,方便你对照着选:
| 实施方式 | 适用场景 | 核心优势 | 注意事项 |
|---|---|---|---|
| 服务器端 (X-Robots-Tag HTTP 头) | 整个目录、特定文件类型(如PDF)、动态生成页面 | 批量处理,无需修改每个页面代码;可针对非HTML文件 | 需要服务器配置权限(如修改.htaccess, Nginx配置) |
| 模板/模块级 (Meta Robots 标签) | 特定页面类型(如标签页、作者存档页、感谢页面) | 在CMS模板或组件层面统一控制,一劳永逸 | 需要访问网站模板或代码库 |
| SEO插件 (WordPress环境) | 使用WordPress等CMS的网站,控制文章类型、分类等 | 用户界面友好,无需直接修改代码;适合非技术人员操作 | 功能取决于插件能力,可能产生插件依赖 |
实施前的关键准备
动手之前先把准备做足,能省掉后面一堆返工。
- 精准审计页面:使用网站爬虫工具(如Screaming Frog)或分析Google Search Console的“覆盖率报告”,精确找出所有需要添加
noindex的页面。制定清晰的规则,例如“所有/search/路径下的内部搜索结果页”或“所有PDF格式的说明书”。 - 确保页面可被抓取:这是最重要的前提。
noindex指令必须能被搜索引擎爬虫读取才能生效。如果页面被robots.txt文件屏蔽,爬虫将无法访问页面并发现noindex标签,导致指令失效。在添加noindex前,请确保目标页面未被robots.txt屏蔽。 - 制定回滚方案:操作前备份相关配置或数据库。万一误操作影响了重要页面,可以快速恢复。
具体配置方法
选择适合你技术环境的方法进行配置。
服务器端配置示例
Apache服务器(修改
.htaccess文件),例如阻止索引整个/private/目录:<FilesMatch "\.(pdf|doc)$"> Header set X-Robots-Tag "noindex" </FilesMatch>Nginx服务器(在服务器配置块中),例如阻止索引所有PDF文件:
location ~* \.(pdf)$ { add_header X-Robots-Tag "noindex"; }
- 模板级修改:对于需要
noindex的特定页面类型(如作者页),在其对应的HTML模板的<head>部分直接插入:<meta name="robots" content="noindex" />。 - WordPress插件设置:如果使用Yoast SEO或Platinum SEO Pack等插件,通常在文章/页面的编辑界面下方或插件的设置菜单中,可以直接为特定的“文章类型”或“分类法”批量设置
noindex。
实施后的验证与监控
标签加完不算完事,后面的验证和监控才决定指令到底有没有落地。
- 验证指令是否生效:使用Google Search Console的“网址检查工具”或直接使用网站爬虫工具重新抓取目标页面,确认
noindex标签或HTTP头已正确设置。 - 监控索引状态:在Google Search Console的“覆盖率报告”中关注“已排除”页面。随着时间推移,被正确添加
noindex的页面应会出现在“因‘noindex’标记而未编入索引”的部分。这表明你的指令已被Google识别和处理。 - 警惕索引数量异常:如果发现网站整体被索引的页面数量突然大幅下降,需排查是否误将重要页面添加了
noindex标签。
常见注意事项
- 不要与
robots.txt的 Disallow 混淆:robots.txt的Disallow是阻止抓取,而noindex是允许抓取但阻止索引。对于已索引的页面,如果只想让其从搜索结果中消失,应使用noindex并确保页面可被抓取,而不是用robots.txt屏蔽。 - 组合使用指令:如果需要同时阻止索引和不跟踪页面上的链接,可以组合指令,例如:
<meta name="robots" content="noindex, nofollow" />或在HTTP头中设置X-Robots-Tag: noindex, nofollow。 - 耐心等待:搜索引擎需要时间重新抓取页面并处理
noindex指令。批量操作后,所有页面从索引中消失可能需要几周甚至更长时间。
如何判断Googlebot是否已经重新抓取了添加noindex的页面?
要判断 Googlebot 是否已经重新抓取了您添加 noindex 的页面,并确认指令已生效,可以从下面这几个方法和指标入手核查。先看这张表里的检查方法和观察点:
| 检查方法 | 关键指标 / 观察点 | 所说明的问题 |
|---|---|---|
| Google Search Console (GSC) | - “网址检查”工具状态: - “覆盖率”报告 | - 直接确认抓取状态和所见内容 - 宏观监控索引页面的减少趋势 |
| 搜索引擎结果页 (SERP) | - site: 运算符查询结果- 页面缓存日期 | - 间接验证页面是否已从索引中移除 - 辅助判断最近抓取时间 |
使用 Google Search Console 直接验证
Google Search Console (GSC) 是解决这个问题最直接、最权威的工具。
使用网址检查工具:
- 在 GSC 顶部的搜索框中输入添加了
noindex的页面的完整 URL。 - 点击“测试实际网址”或“测试”按钮,然后选择“查看测试结果”。
在结果页面中,您需要重点关注两个部分:
- “覆盖率”:这里会显示该网址当前在 Google 索引中的状态。理想情况下,在
noindex被成功处理后,状态应为 “未编入索引”。 - “已抓取的页面”:点击这里可以查看 “Google 所见到的画面”。您需要确认您添加的
noindex元标签或 HTTP 头是否在 HTML 代码中正确显示。同时,工具也会明确显示 “已阻止的抓取资源:noindex 标记”,这是确认指令已被识别的直接证据。
- “覆盖率”:这里会显示该网址当前在 Google 索引中的状态。理想情况下,在
- 工具还会显示该网址最后一次被抓取的日期。如果这个日期晚于您添加
noindex的日期,说明 Googlebot 已经重新访问了该页面。
- 在 GSC 顶部的搜索框中输入添加了
查看覆盖率报告:
- 进入 GSC 的“覆盖率”报告(Coverage)。
- 关注“已排除”标签页。成功被
noindex排除的页面通常会归类在 “因‘noindex’标记而未编入索引” 的原因下。 - 这个报告提供了宏观视角,您可以观察一段时间内被标记为
noindex的页面数量变化,从而确认批量操作的效果。
通过搜索引擎结果间接判断
除了 GSC,您还可以直接在搜索引擎中验证。
- 使用
site:运算符:在 Google 搜索框中输入site:你的域名.com/具体页面路径。如果页面已成功从索引中移除,那么它将不会出现在搜索结果中。请注意,这种方法对于大量页面的检查效率较低。 - 查看缓存版本:在搜索结果中,点击网址下方的“缓存”链接,可以查看 Google 最近一次抓取该页面时的快照。如果缓存日期晚于您添加
noindex的日期,说明抓取已经发生。但请注意,缓存内容不一定实时更新,它只能作为辅助参考。
注意事项与最佳实践
- 确保页面可被抓取:这是
noindex指令生效的绝对前提。如果页面被robots.txt文件屏蔽,Googlebot 将无法访问页面并读取noindex指令,导致指令完全无效。 - 处理 JavaScript 渲染的页面:如果您的
noindex标签是通过 JavaScript 动态添加到页面中的,需要确保 Googlebot 能够成功执行并解析这些 JS 代码。使用 GSC 的网址检查工具查看“渲染后的”HTML 至关重要,它能确认 Googlebot 最终是否看到了noindex标签。 - 保持耐心:从 Googlebot 重新抓取页面到在索引中反映结果,需要一定的时间。对于大型网站,这个过程可能需要几周甚至更久。
把上面这几步走一遍,Googlebot 有没有重新抓、noindex 有没有生效,基本就能看清楚。GSC 里某个状态拿不准,多半是抓取还没跑完,再等一两周复查一次即可。
网站如何平衡noindex与nofollow的使用?
平衡使用 noindex 和 nofollow 至关重要,这直接影响搜索引擎的抓取预算、链接权重的分配以及整体的索引质量。两者各自管什么、典型用在哪,看下面这张表就清楚了。
| 特性 | noindex | nofollow |
|---|---|---|
| 控制目标 | 页面索引(是否进入搜索库) | 链接追踪(是否传递权重) |
| 应用层级 | 页面级(Meta标签或HTTP头) | 页面级(Meta标签)或链接级(rel属性) |
| 对爬虫影响 | 禁止将本页面内容编入搜索结果 | 不跟踪本页面上的链接,或特定链接 |
| 典型场景 | 重复内容页(如标签页)、内部搜索结果页、登录/支付页、站内信、低价值分页 | 用户生成内容链接(如评论)、广告/赞助链接、未信任的外部链接、低优先级内部链接(如“关于我们”) |
平衡使用的核心原则
在实际操作中,平衡使用这两个指令需要遵循一些核心原则,以确保SEO资源得到最有效的利用。
- 明确页面目标:首先判断一个页面是否希望被用户通过搜索引擎找到。如果答案是否定的(如内部搜索页、感谢页面),应优先考虑使用
noindex。对于需要被索引的页面,再评估其上的链接:哪些是您希望推荐并传递权重的(保持dofollow),哪些是需要控制权重流失的(使用nofollow)。 - 管理爬虫预算:搜索引擎分配给每个网站的抓取资源(爬虫预算)是有限的。对大型网站而言,使用
noindex阻止搜索引擎抓取和索引大量低价值或重复页面,可以将宝贵的爬虫预算引导至重要的内容页,提升核心页面的索引效率和新鲜度。 - 集中链接权重:通过
nofollow属性或页面级的nofollowMeta标签,可以阻止权重(或称链接权益)向不必要的页面(如后台登录页)或不受信任的外部页面流失。这有助于将权重集中传递给您希望提升排名的核心页面。一个关键点是,即使一个页面被设置了noindex,如果其上的链接是dofollow(默认状态),它仍然可以向目标页面传递权重。因此,对于既不想被索引,又想控制其链接权重传递的页面,可能需要组合使用noindex和nofollow。
实施建议与注意事项
在具体实施时,还有一些技术细节和最佳实践需要留意。
技术实现选择:
noindex:可通过<meta name="robots" content="noindex">标签实现,或通过服务器的X-Robots-Tag: noindexHTTP响应头实现,后者尤其适用于非HTML文件(如PDF、图片)。nofollow:可在单个链接的<a>标签中添加rel="nofollow"属性;如需对整个页面所有链接生效,可使用<meta name="robots" content="nofollow">标签。
- 确保指令可被读取:至关重要的一点是,确保设置了
noindex的页面没有被robots.txt文件屏蔽。如果robots.txt阻止搜索引擎抓取该页面,它将无法看到noindex指令,页面可能仍然会被保留在索引中。 - 避免指令冲突:不要在同一页面上同时使用
noindex和canonical(规范化)标签,因为它们会给搜索引擎发送矛盾的信号。 - 定期审查审计:大型网站的内容和链接结构会频繁变动。建议定期使用网站爬虫工具审核
noindex和nofollow的使用情况,确保没有误将重要页面设置为noindex,或错误地阻止了重要链接的权重传递。
总结
说到底,noindex 和 nofollow 是两件事:noindex 管哪些页面进搜索库,nofollow 管页面上的链接权重往哪流,先把意图分清楚再下指令。
一个清晰的策略是:
noindex, follow:适用于您不希望出现在搜索结果中,但希望爬虫能通过其上的链接发现更多内容或传递权重的页面(例如某些分类归档页)。index, nofollow:适用于您希望被搜索到,但不想让页面上的某些或所有链接传递权重的页面(例如新闻文章页,其中包含的广告链接)。noindex, nofollow:适用于既不需要被索引,也不需要跟踪其上链接的页面(如登录成功页、感谢页面)。
如何评估noindex和nofollow的使用效果?
评估 noindex 和 nofollow 的使用效果,关键在于持续追踪一些核心的SEO指标,观察指令实施后搜索引擎和用户与您网站互动的变化。主要的评估维度和方法,保哥整理在了下面这张表里。
| 评估维度 | 关键指标/方法 | 期望的效果 |
|---|---|---|
| 索引状态 | Google Search Console “覆盖率”报告 | 被 noindex 的页面应从索引中移除,归类于“已排除”项。 |
| 爬虫效率 | GSC “爬虫统计信息”中的已抓取URL数量 | 爬虫更专注于重要页面,抓取预算分配更合理。 |
| 链接权重分布 | SEO工具(如Ahrefs, SEMrush)分析内部链接图 | 权重通过 dofollow 链接集中流向高价值页面,减少损耗。 |
| 搜索表现 | GSC “搜索效果”报告(展示次数、点击量、排名) | 核心页面因资源集中而排名稳定或提升,整体流量健康。 |
| 流量质量 | 网站分析工具(如Google Analytics)的跳出率、停留时间 | 避免低质页面出现在搜索结果中,吸引更相关的用户,提升交互质量。 |
监控索引状态与爬虫行为
这是评估 noindex 效果最直接的一步。
- 确认页面已从索引中移除:在 Google Search Console (GSC) 的“覆盖率”报告中,成功添加
noindex的页面会逐渐从“有效”页面移动到“已排除”页面,并且原因会标注为“已添加‘noindex’标记”。您需要定期检查,确保目标页面已按预期被排除。 - 验证指令是否被正确读取:使用 GSC 的“网址检查”工具输入特定的已添加
noindex的URL。该工具会显示Google最后看到的页面快照,您可以确认noindex标签是否已被识别。 - 观察爬虫预算的使用:在 GSC 的“爬虫统计信息”中,您可以查看搜索引擎抓取您网站的活跃度。成功的
noindex策略会使爬虫更有效地抓取您希望被索引的重要页面,避免在低价值页面上浪费抓取预算。
分析搜索排名与流量变化
实施这些指令的最终目的是提升整体SEO健康度,因此需要关注宏观的搜索表现。
- 核心页面排名稳定性:在 GSC 的“搜索效果”报告中,重点关注您希望获得排名的核心页面的表现。理想情况下,在将低质或重复页面设置为
noindex后,搜索引擎会将更多资源分配给核心页面,其排名和获得的流量应保持稳定或有所提升。 - 整体流量质量提升:通过 Google Analytics 等分析工具,观察来自搜索引擎的用户行为指标,如跳出率和平均会话持续时间。有效的
noindex策略可以减少不相关搜索词带来的低质流量,吸引到更精准的用户,从而可能改善这些指标。
评估链接权重的分配
对于 nofollow,主要评估它是否有效引导了“链接权重”(或称PageRank)的流动。
- 分析内部链接图:使用 Ahrefs Site Audit 或 SEMrush 等专业的SEO工具,可以分析您网站的内部链接结构。检查是否已对“联系我们”、“登录页面”等无需权重的链接正确使用了
nofollow,从而确保权重被集中传递到重要的产品页或内容页。 - 审核出站链接:定期检查您网站上的出站链接,确保对广告、赞助链接或不可信的外部网站正确使用了
nofollow或sponsored属性。这可以保护您的网站声誉,避免被搜索引擎视为“链接农场”。
警惕常见问题与错误配置
在评估过程中,也需要注意一些陷阱:
- 错误配置:最严重的问题是页面同时被
robots.txt屏蔽又被设置了noindex。如果robots.txt阻止了爬虫访问,它将无法读取页面的noindex指令,导致页面可能仍保留在索引中。确保重要页面可被抓取是前提。 - 过度使用:对内链过度使用
nofollow会阻碍爬虫正常抓取网站结构,反而不利于索引。应仅对必要的链接使用。 - 定期审查:网站内容不断变化,需要定期(如每季度)重新审查
noindex和nofollow的使用,确保它们仍然符合当前的内容策略。
这几个维度盯住了,noindex 和 nofollow 到底有没有起作用,心里就有数了。其中索引覆盖率和爬虫统计这两块最值得每月看一眼,变化最先在这里露出来。
常见问题解答
如果我误将重要页面添加了 noindex,我该如何快速挽救?
第一步:立即移除。 尽快从页面代码中删除 noindex 标签或 X-Robots-Tag HTTP 头。第二步:请求抓取。 立即在 Google Search Console (GSC) 中对该页面使用“网址检查”工具并点击“请求索引”。
noindex 和 disallow 同时存在一个页面上会怎样?noindex 会失效。 robots.txt 中的 Disallow 阻止了 Googlebot 访问该页面,所以它无法读取页面 <head> 中的 noindex 标签。Google 会选择“不抓取”,但页面可能会因外部链接等原因继续保留在搜索结果中。
noindex 是否会像 Disallow 一样浪费我的爬虫预算?
恰恰相反。 noindex 指令允许 Googlebot 抓取页面,读取指令,然后将页面从索引中移除。这样,Googlebot 就不必再浪费时间反复抓取这个低价值的页面,从而有效节省了后续的爬虫预算。
添加 noindex 后,页面上的内部链接权重还会传递出去吗?
会。 默认情况下,<meta name="robots" content="noindex"> 等同于 <meta name="robots" content="noindex, follow">。页面被移除索引后,其上的链接权重(PageRank)仍然可以传递给链接的目标页面。
如果我想阻止索引,并且不想传递权重,应该使用什么指令?
您应该组合使用指令:<meta name="robots" content="noindex, nofollow">。这明确告诉搜索引擎不要索引此页面,并且不要跟踪或传递权重给页面上的任何链接。
我能只对百度蜘蛛(Baidu Spider)设置 noindex,而让 Google 继续索引吗?
可以。 您可以使用特定的 Meta Robots 标签。例如,只阻止百度索引:<meta name="Baiduspider" content="noindex" />。同时保留 Google 索引:<meta name="googlebot" content="index" /> 或不设置 Googlebot 标签(默认为索引)。
服务器端配置 X-Robots-Tag 和 HTML 的 Meta Robots 标签,哪个优先级更高?
X-Robots-Tag 优先级更高,并且更强大。 它是 HTTP 响应头的一部分,在浏览器渲染 HTML 之前就已发送。它可以对非 HTML 文件(如 PDF、图片)生效,而 Meta 标签只能用于 HTML 页面。
为什么我的页面被 noindex 后,通过 site: 搜索仍然能找到它?
这通常是由于延迟造成的。Googlebot 还没有完成重新抓取和处理指令。另一个原因是,您可能在 robots.txt 中屏蔽了该页面,导致 noindex 指令一直未被发现。
如果我将页面 noindex 后,又将其 301 重定向到另一个页面,会发生什么?
不建议这样操作。 Google 可能会忽略 301,并继续将原页面保留在索引中。正确的做法是:先确保 noindex 生效(从索引中移除),然后删除 noindex 标签,最后再设置 301 重定向。
对于 WordPress 博客的“标签归档页”,我应该使用 noindex, follow 吗?
通常是推荐的做法。 标签归档页内容通常与分类页或文章页高度重复,且索引价值低。使用 noindex, follow 可以避免重复内容问题,同时确保这些页面上的链接仍能将权重传递给实际的文章。
如何知道 Googlebot 抓取我的网站频率是多少?
您可以在 Google Search Console (GSC) 的**“爬虫统计信息”**报告中查看。该报告会显示 Googlebot 抓取您的网站的请求总数、下载量和平均响应时间,从而间接反映出抓取频率。
如果我删除了页面并返回 404,我还需要使用 GSC 移除工具吗?
不需要。 返回 404/410 是最明确的信号。Googlebot 发现 404 状态码后会最终移除该页面。GSC 移除工具可以加快临时移除的速度,但 404/410 是永久性解决方案。
我可以对一个 URL 的所有参数化变体(如 ?sort=a)批量设置 noindex 吗?
可以。 最有效的方法是通过服务器端配置 X-Robots-Tag,设置一个规则来匹配所有带有特定查询参数的 URL 模式,然后对其返回 noindex HTTP 头。
为什么 SEO 插件(如 Yoast)会在我的页面 <head> 中同时生成 noindex, follow 和 Canonical 标签?
这是一个常见错误(或过时配置)。 这两个标签会给 Google 发送矛盾信号:Canonical 说“请将权重归到这个 URL”,而 noindex 说“请不要索引这个页面”。在同一 URL 上,您应该只使用 Canonical 来解决重复内容问题。
noindex 指令对必应(Bing)和百度(Baidu)等其他搜索引擎也有效吗?
有效。 noindex 元标签和 X-Robots-Tag HTTP 头部是行业标准,主流搜索引擎如 Bing、Baidu、Yandex 等都支持并遵循这些指令。
如果我在页面的 <body> 部分添加了 noindex 标签,它会生效吗?
不会。 <meta name="robots" content="noindex"> 标签必须放置在页面的 <head> 部分才能被搜索引擎爬虫识别和处理。
权威参考资料
本文标题:《已收录页面加noindex后多久从SERP消失?6大场景实测》
本文链接:https://zhangwenbao.com/when-does-noindex-page-remove-from-google-search-results.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0