移动优先索引:Googlebot渲染机制与桌面掉量自救
本文目录
- 移动优先索引到底改了排名的哪一层?
- “移动优先”不是“移动友好”
- 从mobile-first到mobile-only:双爬虫时代彻底退役
- 动的是“页面定义”这一层,不是“排名因素”
- Googlebot到底怎么抓、怎么渲、怎么入库?
- 抓取的不是浏览器,是HTTP请求列表
- evergreen Chromium之前与之后
- 渲染队列与第二波抓取的时间差
- JS执行权限、超时、字段隐藏的真实边界
- 桌面≠移动版本的差异,是怎么变成掉量的?
- 响应式、独立m.站、动态适配三型的现实分布
- 差异内容、产品评价、表格被折叠
- 结构化数据、meta robots、canonical的对齐陷阱
- 桌面型掉量的诊断流程是什么?
- GSC的URL检查是地基
- 渲染后DOM对比
- 分流测试与双视角抓取记录
- 真实复盘:跨境美妆DTC的桌面型掉量教训
- 移动优先索引时代的落地策略是什么?
- 响应式优先是默认答案
- 独立m.站的退役路径
- 动态适配的少数派生存指南
- 渐进增强而非桌面优先
- 性能、Core Web Vitals与移动优先的边界
- 常见问题解答
- 移动优先索引和移动友好是同一件事吗?
- 桌面端独有的内容是不是会被Google直接忽略?
- 现在还需要单独做m.开头的独立移动站吗?
- 为什么GSC里URL检查的渲染结果和Chrome里看到的不一样?
- Core Web Vitals是不是只看移动端?
- 动态适配现在还能不能用?
- 权威参考资料
摘要:移动优先索引不是给手机端额外加分,而是把Google用来评估全部排名的“正本页面”从桌面版换成了手机版。这个改动从2018年滚动开始、到2023年10月桌面爬虫彻底退役,等于把整套SEO底座的“页面”定义换掉。桌面≠移动版本的内容差异、被折叠的段落、被脚本失败的渲染,今天都会直接换算成可见度损失。本篇按算法机制、Googlebot渲染演变、三型适配落地、桌面型掉量诊断四段拆开讲,配真实复盘与决策矩阵。
移动优先索引到底改了排名的哪一层?
保哥这些年带过一堆从2016、2017开始就有桌面端老站基础的外贸站、内容站、独立站,移动优先索引这件事,是少数几个被名字翻译反复带偏的算法变更之一。很多读者第一次听到这个词,下意识理解成“Google更看重移动端体验”,于是去做了一堆移动友好度的修补,掉量却没缓解。这是因为这件事改的根本不是排名因素,而是排名链路的最上游:用谁的版本来当那个被排名的“页面”。
分清楚这一点之前,所有后续的优化动作都容易跑偏。所以这一节我不急着讲怎么修,先把这件事在算法层到底动了哪个螺丝拆清楚。
“移动优先”不是“移动友好”
2015年那一波叫Mobilegeddon的更新,本质是Google在桌面端排名分数里加了一项移动友好度信号——你的页面在手机上能不能正常看、按钮间距够不够大、字号默认是不是太小,影响的是排名分数加多少。它没有动“拿谁当页面”这个最底层假设,正本依然是桌面版URL抓回来的HTML。
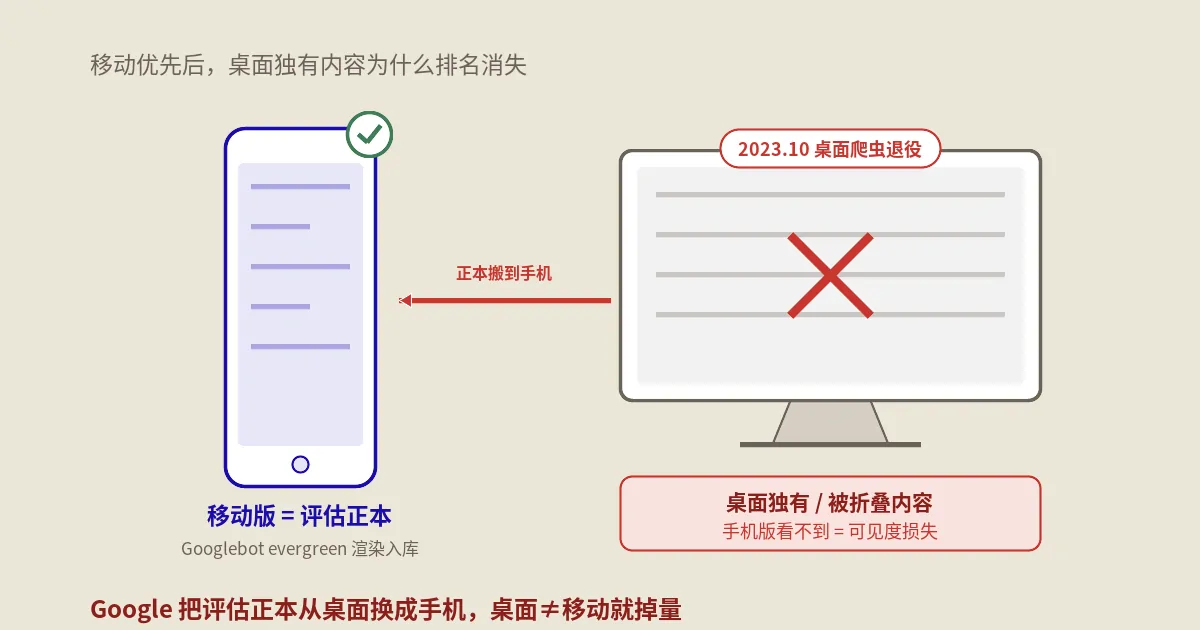
移动优先索引(mobile-first indexing)是另一回事。Google官方在2018年3月那篇博客里写得非常直白:以后我们用智能手机版的Googlebot抓回来的版本,当作索引和排名的主版本,桌面版的版本只是辅助参考。这意味着如果你的移动版页面里少了一段内容,那段内容就基本上不在索引里、不参与排名,哪怕桌面版还在好好地写着。
这两件事很容易混的根因在于名字翻译。中文里“优先”和“友好”都偏向定性,听起来都像是一种加权偏好。但mobile-first在英文里有明确的工程语义,对应的是技术决策里那种“先把这条路径走通、再考虑兜底”的设计原则。在这个语境里,桌面版变成了那个兜底的fallback,而不是基准。
从mobile-first到mobile-only:双爬虫时代彻底退役
2018年开始滚动只是序章。Google用了五年多时间,把全网域名分批迁移到这个新机制下;新建域名一开始就直接走移动优先,老域名按数据迁移就绪程度排队。到2020年的时候,Google又给出一个原计划2021年彻底切换的时间表,后来因为客观原因延期了两次。
真正的终章在2023年10月。那个月Google正式宣布:桌面端的Googlebot爬虫,从这一刻起停止抓取那些之前因为各种历史原因还在用桌面版当主索引的网站,把它们也都搬到移动版作主索引的路径上。从此进入mobile-only阶段——Google搜索的全网索引里,所有页面都以手机端Googlebot抓到的版本为正本,桌面版独占的内容彻底失去“正本”资格。
这件事对小站的实际冲击是被低估的。因为这中间五年里,移动优先索引被讲得太多、被实际理解得太少;很多站长以为已经切了、其实自己的域名一直在桌面版兜底;2023年10月的最后一刀下来,那些一直靠桌面版独有内容撑着排名的页面,突然在几周内可见度断崖。
动的是“页面定义”这一层,不是“排名因素”
SEO行业讨论算法变更时,习惯性地往“这次又是哪个排名因素被调权”这个方向想。移动优先索引让所有这种讨论方式失灵,因为它根本不在排名因素这一层。
排名是一个链路:Google先抓取页面,把HTML和资源拉回来;再解析、渲染、入库形成索引条目;查询时再从索引里召回、按一堆信号打分排序。移动优先改的,是从“抓什么、把什么写进索引条目”这两步开始,整个链条往下都被换了输入。
这就是为什么很多桌面端排名掉了的站,去检查Core Web Vitals、检查外链、检查内容质量都看不出问题——因为问题不在打分阶段,而在更上游:Google眼里的“你的页面”和你眼里的“你的页面”根本不是同一份HTML。
Googlebot到底怎么抓、怎么渲、怎么入库?
讲清楚“正本”被换之后,下一个绕不开的问题就是:那个新正本是怎么生成的?Googlebot smartphone的工作流,跟很多人想象中那种“拿浏览器打开就看到了”差得有点远。这一段是诊断桌面型掉量的基础知识。
抓取的不是浏览器,是HTTP请求列表
Googlebot的第一步行为不是“访问这个URL”,而是发起一个HTTP请求,用Googlebot smartphone的User-Agent字符串带上自己的标识,去拿那个URL返回的初始HTML。这一步拿回来的是服务端直接吐出的原始HTML,里头有什么是什么——如果你的内容是后端渲染好的,第一步就拿到了;如果是前端框架在浏览器端渲染的,第一步只能拿到一个空壳子加一堆JavaScript引用。
这个区分很重要。前几年很多DTC独立站用React、Vue做的单页应用,Googlebot第一步看到的只是一个<div id="app"></div>,加一堆<script src="...">。如果Google止步于此,你这一站基本上等于不存在。
所以Google才有了第二步:把这些拿到的资源列表排队,等待渲染。这里有一个关键的现实:渲染是排队的,不是立刻发生的,而且队列长度并不公开。
evergreen Chromium之前与之后
2019年之前,Googlebot的渲染引擎是基于Chrome 41版本的老内核——你没看错,Chrome 41,2015年发布的那个版本。这个老内核不支持现代JavaScript的很多语法、不支持很多Web API、对ES6+的特性兼容性糟糕。那几年里只要你的前端代码用了较新的语法,Googlebot渲染就直接失败,页面对Google来说就是空白。
2019年5月Google宣布了evergreen Googlebot:渲染引擎升级到最新稳定版Chromium,而且承诺以后会持续跟着Chromium升级走。从这一刻起,Googlebot的渲染能力理论上跟一个用户用Chrome打开你的站差不多了。但“理论上”这三个字很重要,因为它和真实用户行为之间还有几道实际差异,下面会展开。
对老站来说,2019年的这次升级是一次安静的红利——你之前因为兼容性问题而对Google不可见的那些前端代码,从那一年起开始能被抓到了。业内见过不止一家2017年前后做的SPA站,2019年之后才发现“原来我们一直没被收录这么严重”,因为他们在2019年之前就放弃了,停在了空白页结论上。
渲染队列与第二波抓取的时间差
evergreen Chromium之后,渲染问题从“能不能做”变成了“什么时候做”。Googlebot的工作流分两波:第一波把原始HTML和它直接引用的资源拉回来,先放进一个粗糙的初始索引;第二波把这页面送进渲染队列,等空闲时再用Chromium跑一次完整渲染、拿到最终DOM,再用最终DOM去更新索引。
两波之间的间隔,Google官方从未公开过具体时长,行业实测从几小时到几周不等,取决于站点权重、内容更新频率、Googlebot分配给你的预算。对于权重高、更新快的站点,两波几乎是连着的;对于新站、内容站、长尾站,第二波可能要排几天甚至几周。
这就带来了一个很多人没意识到的副作用:你的页面如果只在第二波渲染后才能看到关键内容,那这页面在被索引的最初一段时间里,等于只有那个空壳子。这段时间Googlebot对你这页的判断、给你打的初始分数、决定要不要花更多预算抓取,都是基于那个空壳子的。第二波渲染补救上来的时候,初始信号已经被记下了。
JS执行权限、超时、字段隐藏的真实边界
渲染并不是Chrome跑一遍就完事。Googlebot渲染时有几条硬约束,跟真实用户的浏览器不一样:
- 不接受用户交互。任何需要点击、滚动、悬停才能触发的内容加载,Googlebot都不会触发。无限滚动里第二屏之后的内容、点击展开的常见问题、悬停才显示的产品规格,全都看不到。
- 不持有Cookie、不持有登录态、不带历史记录。任何依赖会话或个性化才显示的内容,Googlebot拿到的是默认未登录、未授权的版本。
- 有渲染超时。Google没公开过具体阈值,但行业实测和Mueller、Splitt等人多次公开发言指向五秒上下作为参考——这个数字会变,但作为设计上限值是稳的。超过这个时间还没完成的脚本和资源,Googlebot就放弃了。
- display:none和visibility:hidden的内容是被解析的,但权重低于可见内容。你想隐藏一段帮助SEO,行不通;你以为隐藏起来的过期文案,Google也能看到。
这四条放一起,决定了Googlebot渲染后的最终DOM和你打开Chrome看到的最终页面之间,永远存在一道差。这道差的大小,就是你这站“Google眼里和用户眼里”的不一致程度,也就是潜在掉量风险的来源。
| 阶段 | 动作 | 常见踩雷点 |
|---|---|---|
| 第一波抓取 | HTTP请求拿原始HTML与直接引用资源 | SPA空壳、404兜底页、CDN对Googlebot UA返回错误 |
| 初始解析 | 从原始HTML构造粗索引条目 | 关键内容靠JS注入、meta robots写在客户端 |
| 渲染队列 | 排队等Chromium跑完整渲染 | 等待时间从几小时到几周,新站尤其慢 |
| 渲染执行 | 跑JS、拿最终DOM | 超时、不持登录、不交互、不滚动 |
| 索引更新 | 用最终DOM替换粗索引 | 第一波坏印象已落地,需要等下次更新 |
桌面≠移动版本的差异,是怎么变成掉量的?
讲完正本被换、Googlebot怎么生成新正本,第三段就到了最实战的部分:什么样的差异会变成可见度损失,怎么变。这是保哥过去几年帮客户做诊断时最常见的几个掉量画像,按发生频率从高到低排。
响应式、独立m.站、动态适配三型的现实分布
讨论桌面≠移动差异之前,先看一下三种适配方式各自的现状。这关系到你这站的差异在哪一层。
响应式设计(responsive web design):同一个URL、同一份HTML,靠CSS媒体查询在不同屏幕宽度下展示不同样式。HTML源码完全一样,理论上桌面和移动版本看到的内容没有任何差异,只是排版不同。Googlebot smartphone拿到的HTML和Googlebot desktop拿到的HTML是完全相同的,只是Googlebot smartphone会按手机视窗去理解CSS。
独立移动站(separate mobile site,俗称m.站):桌面版在`www.example.com/page`、移动版在`m.example.com/page`,两套URL、两套HTML、两套canonical互相指引。绝大多数大型门户、新闻站、十几年前做出来的电商站仍然走这条路。维护成本极高、SEO风险极大。
动态适配(dynamic serving):同一个URL,但服务器根据请求的User-Agent判断是桌面还是移动,返回不同的HTML。这要求服务器必须正确识别UA、必须在响应头里设置Vary,告诉缓存层这是按UA变体的同一URL;否则CDN会把桌面版缓存了塞给移动用户、或反之。
三种里,从2018年至今,响应式吃下了绝大多数新站;独立m.站从那年起就开始退场,到2023年mobile-only之后基本只剩历史包袱;动态适配从一开始就是少数派,经手过的客户里十年来不超过个位数。
| 适配型 | 桌面与移动URL | HTML差异 | Googlebot视角 | SEO维护成本 |
|---|---|---|---|---|
| 响应式 | 同一URL | 无差异 | 统一一套HTML | 低 |
| 独立m.站 | 分两套URL | 差异大 | 抓移动版,桌面版当辅助 | 极高 |
| 动态适配 | 同一URL | 按UA返回不同 | 需Vary头+UA白名单 | 高 |
差异内容、产品评价、表格被折叠
独立m.站和动态适配最常见的掉量画像,是移动版为了节省屏幕空间,把桌面版里的一些大段内容折叠掉、删掉、或者换成简略版。常见的几类:
- 产品页的详细规格表,桌面版完整展开、移动版折叠成“查看更多”按钮触发才显示。Googlebot不点击,等于这段规格Google看不到。
- 用户评价区,桌面版直接渲染前二十条评价、移动版只渲染首条+“加载更多”。少了的十九条评价对Google来说就是不存在。
- 底部相关文章、相关产品、面包屑导航,移动版为了简洁直接隐藏。导致内链网络在Googlebot眼里少了一大片。
- 客服信息、店铺简介、退货政策这种E-E-A-T关键信号,移动版只链不显示。Google判断这站可信度的依据就少了。
保哥手里有个2022年来咨询的北美户外DTC案例,他们用的是2016年做的独立m.站,桌面端SEO一直做得不错、长尾词排名扎实。2023年8月开始出现连续两次掉量,每次掉百分之十几,业主以为是核心更新影响。我们做完移动版抓取对比之后,结论非常清晰:移动版的产品页直接砍掉了桌面版那一大块“使用场景与材质详解”,只留了规格表和购买按钮。在mobile-only切换那一刻,那些原本靠那段文案吃下来的长尾词,等于内容凭空蒸发。后来花了三个多月把移动版做平内容、加上响应式重构,到2024年Q1才把流量拉回来七成。
结构化数据、meta robots、canonical的对齐陷阱
另一类掉量更隐蔽,发生在元信息层面。Google官方文档里反复强调:移动版必须和桌面版有同样的结构化数据、同样的meta robots指令、同样的canonical指向。但现实是这三项经常被技术团队“顺手优化”掉。
典型踩雷:移动版canonical指回桌面版URL(试图告诉Google桌面是正本),结果Google一边把移动版当抓取对象、一边收到“正本是桌面版”的信号,整页直接索引混乱;移动版meta robots写了noindex(开发觉得移动版不重要、不想被索引),结果mobile-only切换后整页直接从索引里消失;移动版的产品结构化数据少了Offer、少了AggregateRating,富媒体摘要一夜消失。
这类问题诊断起来要比内容差异复杂,因为它们不在DOM对比里直接可见,必须用结构化数据测试工具或GSC的URL检查工具,对比两个版本的解析结果。但解决方式一致:响应式重构、彻底退役m.站,是2024年之后最干净的答案。
桌面型掉量的诊断流程是什么?
讲到这里读者大概有概念了:桌面≠移动型掉量的诊断,关键不是“为什么这页排名跌了”,而是“Google眼里的这页和我眼里的这页差在哪”。这一节给一套实战中用过的诊断顺序。
GSC的URL检查是地基
所有诊断的起点是Google Search Console里的URL检查工具。把出问题的页面贴进去,点“测试已发布的网址”,Google会用Googlebot smartphone去重新抓取并渲染,然后展示:抓到的HTTP状态码、抓到的HTML源代码、渲染后的截图、解析到的结构化数据、检测到的索引指令。
这一步要看两个东西:第一,渲染截图里有没有你期望出现的关键内容(产品规格、价格、评价、CTA按钮等)。第二,源代码里有没有那段关键内容(搜索一下关键词字符串)。这两个交叉,能立刻判断是“移动版根本没渲染出来”还是“移动版渲染了但内容确实少”。
有一个细节读者经常忽略:URL检查给出的“已发布的网址”视图和“已编入索引的网址”视图可能不一样。前者是当下重新抓的,后者是Google上次入库的版本。如果你刚改了移动版、Google还没来得及重新抓,索引里还是老版本。这时候要看“已发布”那一栏作为现状。
渲染后DOM对比
GSC的URL检查给的是Google视角的截图,但有时候你需要更细的DOM对比——具体哪段HTML有、哪段没有、哪个属性差了。这时候要用浏览器模拟Googlebot smartphone的UA去拿渲染后DOM,再和Chrome正常打开拿到的DOM做diff。
具体动作有两个路径。第一种是Chrome DevTools里把User-Agent切换成Googlebot smartphone的字符串,禁用cache,硬刷新一次,然后把DOM导出。第二种是用Lighthouse或Web.dev提供的工具跑一次,它会以Googlebot smartphone的视角加载并报告问题。第三种是用Mobile-Friendly Test或Rich Results Test,这两个工具背后用的就是Googlebot的渲染管线。
对比结果要重点看:缺少的内容是不是关键内容、缺失的原因是不是JS没执行完、是不是被display:none掉了、是不是因为脚本超时。这三类原因对应三种不同的修补路径。
分流测试与双视角抓取记录
大型站做整改前,要做分流测试和长期抓取记录。分流测试的意思是把一部分流量先切到新的响应式版本、保留对照组在老的m.站,观察一段时间的指标变化再决定全切。这件事在2024年之后越来越关键,因为mobile-only切换后任何整改都直接影响全站可见度,没有桌面端兜底了。
双视角抓取记录是说同时维护两套日志:一套是Googlebot smartphone抓取记录(看Google视角的实际情况),一套是真实用户在移动端的抓取日志(看用户视角的实际情况)。两套之间的diff随时间观察,能提前发现潜在掉量风险——比如某次发布后Googlebot开始拿不到某段HTML,但真实用户还能看到,这通常意味着客户端渲染出了问题。
真实复盘:跨境美妆DTC的桌面型掉量教训
保哥2024年带过一家做出海北美的中国美妆DTC,年营收七位数美金、八成流量来自Google自然搜索。他们的站是2020年用Shopify Hydrogen做的SPA架构,桌面端排名一直不错,移动端排名一直差两到三位但没人当回事。
2024年5月那次核心更新里,他们的移动端流量掉了三成、桌面端掉了一成。业主第一反应是去查内容质量、查外链。一周后我们一起做诊断,结论是更老的问题在mobile-only切换后的累积效应:Hydrogen的SPA首屏渲染依赖客户端水合,Googlebot smartphone拿到的渲染结果里,产品页有大约一半的关键内容是空的——因为水合过程在Googlebot的超时阈值内没跑完。
桌面端为什么之前没掉?因为他们在2022年做过一次桌面端的SSR优化,桌面版独有一套服务端渲染逻辑,移动版没做。那个优化在mobile-first时代还能借桌面版兜底兜回来一部分排名分数,到2023年10月mobile-only正式切换后,兜底没了。但因为切换是无声的,加上他们的桌面端SSR做得好、桌面排名仍然不错,他们直到2024年5月才在核心更新放大了这个差异、才被迫面对真相。
解法是把移动端也加上完整SSR,把首屏关键内容(产品标题、价格、规格摘要、Add to cart按钮)从客户端水合改为服务端预渲染,缩短Googlebot的渲染依赖。从开工到全量上线两个月,再过三个月移动端流量回升到原来的九成。这个案例的教训不只在技术修复,更在于:桌面端做得好掩盖问题的能力,在mobile-only时代会消失。
移动优先索引时代的落地策略是什么?
把诊断流程讲完,第四段也是最后一段,给一套2024年之后做新站、改老站的落地决策。这一段更偏取舍,不再纯讲机制。
响应式优先是默认答案
新站从0做,选响应式是不需要犹豫的。同一URL、同一份HTML、CSS媒体查询切换样式,所有SEO信号天然一致,没有canonical冲突、没有结构化数据同步成本、没有URL映射维护,Googlebot视角下整套机制最简单。
这个建议里唯一的弹性来自一种特殊场景:某些重度交互应用(在线协作工具、复杂B2B SaaS控制台、专业工程绘图)的桌面版和移动版用户行为模式差得太远,强行响应式不仅做不出好的移动体验、桌面端也会被妥协。这种场景,工具型功能页可以走两套,但内容型页面(首页、营销页、产品介绍页、文档、博客)必须响应式,因为这些是被Google索引的页面,差异化会直接换算成可见度损失。
独立m.站的退役路径
2024年之后还在用独立m.站的,基本只剩三种情况:老门户、老电商、被业主以“反正一直用得好”为由拒绝重做的网站。退役的路径不是一刀切,而是按SEO收益高低分批走。
第一批退的是流量最大的几个页面类型——产品页、分类页、热门文章。把这些先在桌面版URL上做响应式重构,移动版URL改成301跳转到对应的桌面URL,整体迁移。第二批退的是中长尾页面,套同样的模板批量迁。第三批是历史死页、不再有流量但有外链的页面,做URL映射保留外链权重。整个过程通常六到十二个月,不要急着一次切完,因为大规模301会触发短期可见度波动,分批可控。
退役前最关键一步是URL映射表。桌面版和移动版URL在十几年的演化里不一定一一对应,有些移动版URL对应多个桌面版、有些桌面版没有对应移动版。这张映射表做不好,301跳转就跳错,跳错的代价直接是死链和外链权重蒸发。
动态适配的少数派生存指南
动态适配在2024年之后保留下来的,基本只有一类站:某些超大型电商、某些受合规约束必须按UA分发的网站。如果你的站不在这两类里、还在用动态适配,认真考虑迁到响应式。
必须留下的,那就老老实实做好三件事:服务器响应头里设置`Vary: User-Agent`告诉缓存层和Googlebot这是按UA变体的同一URL(这一条漏掉,CDN缓存会让桌面版被塞给移动用户);维护可信UA白名单,按域名+IP反查的方式识别真假Googlebot smartphone(市面上有大量伪造UA的爬虫,识别不出来会导致桌面版被塞给Google);保证移动版和桌面版的关键内容、结构化数据、内链网络对齐,差异化只发生在排版和交互层面。
渐进增强而非桌面优先
设计思路上,2024年之后的新前端项目应该是渐进增强(progressive enhancement),不是优雅降级(graceful degradation)。渐进增强是先把基础HTML和CSS做到能在手机端基础浏览器跑、能让Googlebot smartphone拿到完整内容,再往上加桌面端独有的交互和样式。优雅降级是反过来,先做一个桌面端华丽版本、再裁剪给移动端。这两种思路在2018年之前可以互换、之后已经分出胜负——优雅降级在mobile-only时代是给Google看一个有损版本,赌不起。
具体到工程实践,这意味着关键内容走SSR、关键交互走原生HTML按钮和链接而不是依赖JS的click handler、关键数据用语义化HTML标签呈现而不是用纯样式堆出来。这些做法对移动端体验也是好的,对Googlebot视角更友好,是一笔双赢的工程债务还清。
性能、Core Web Vitals与移动优先的边界
最后一个常被混淆的问题:移动优先索引和Page Experience信号里的Core Web Vitals是什么关系?答案是“相邻但不同”。
移动优先索引决定的是“拿谁当正本”,是抓取和索引层的事。Core Web Vitals是用这个正本来评估页面体验的,本身是一个排名信号——按Google目前公开的说法权重不算大,但作为tie-breaker存在。两件事的共同点是它们都默认从移动端取数:移动优先决定拿移动版当正本,CWV评估默认看移动端的LCP、INP、CLS。
桌面端有独立的桌面CWV评估,但权重比移动端小、影响面也小。所以日常优化的优先级是非常明确的:手机视角的页面体验是主战场,桌面视角是后置补强。这两条放一起,把2024年之后SEO的技术优先级讲完了:移动正本要全、移动渲染要稳、移动体验要快。剩下的桌面端,做好基本盘即可,不要再倒过来当主线。
常见问题解答
移动优先索引和移动友好是同一件事吗?
不是。移动友好是2015年那次“对移动端体验好”加分的排名信号,仍然以桌面页面做正本;移动优先索引是2018年起把“用谁当正本”换成了手机版的Googlebot抓到的版本。一个是体验加分,一个是底层“页面”定义被换掉。
桌面端独有的内容是不是会被Google直接忽略?
不是被忽略,而是Google能看到的版本里没有这段。Googlebot smartphone抓的是移动版URL或响应式后的同一URL,如果移动版里这段被display:none、被折叠在懒加载里、或被脚本注入失败,移动端“看不见”它就等于Google看不见它。
现在还需要单独做m.开头的独立移动站吗?
绝大多数场景不需要。2023年10月之后Google已经把桌面爬虫退役,独立移动站要维护两套URL、两套canonical、两套结构化数据,反而是负担。除了极少数离线、弱网、老机型场景,响应式优先是不需要再讨论的默认答案。
为什么GSC里URL检查的渲染结果和Chrome里看到的不一样?
GSC用的是Googlebot smartphone的UA,加载顺序、JS执行上限、超时阈值都比浏览器严格;它不会等无限滚动、不会停留触发懒加载、不会执行需要用户交互的脚本。Chrome能看到不代表Google能看到,渲染结果的差异本身就是诊断信号。
Core Web Vitals是不是只看移动端?
Page Experience信号里CWV的评估默认就是移动端取数,这和移动优先索引是一致的;桌面端有单独的桌面排名实验但权重不一样。换句话说,性能体检的主战场永远是手机视角,桌面端做好是加分项不是底线。
动态适配现在还能不能用?
技术上可以但要付出额外代价:必须正确设置Vary头告诉缓存层和Googlebot这是按UA变体的同一URL;必须维护UA白名单识别真假Googlebot;必须保证桌面版和移动版关键内容、结构化数据、内链对齐。除非有不可调和的两端体验需求,否则不建议新站走这条路。
移动优先索引这件事的核心其实就一句话:Google看到的“你的页面”和你看到的不一样的时候,排名的赢家不会是你。把这道差缩到最小,是2024年之后SEO技术工作的主线。更多关于搜索引擎抓取索引排名三步、JS渲染SEO的调试、网站迁移不掉量的机制,以及响应式设计的SEO取舍,可以顺着这几条延伸看。
权威参考资料
本文标题:《移动优先索引:Googlebot渲染机制与桌面掉量自救》
本文链接:https://zhangwenbao.com/mobile-first-indexing-mechanism-googlebot-rendering-evolution-survival.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0