Google Search Console三大数据黑洞怎么破?1000行+URL分组+阈值过滤补全工程
本文目录
- GSC数据三大黑洞到底吞了多少?
- 三大黑洞各自吞掉了什么?
- 为什么Google要做这三道折损?
- 三大黑洞叠加效应:可见数据vs真实数据的差距
- 1000行表格限制是什么机制?怎么绕过这一关?
- 多维拆分采样法
- 四轴拆分实操路径
- 常见误区与坑
- API配额、速率限制与重试策略
- 阈值过滤(anonymized queries)怎么折损我的数据?
- anonymized的具体边界
- 逆向估算anonymized占比的方法
- anonymized高占比的应对策略
- anonymized比例突变背后的常见原因
- URL分组(“其他”桶)藏了哪些页面?
- URL bucketing触发场景
- “其他”桶的逆向分布估算
- 多维拆分到底能补回多少真实数据?
- 扩容倍数与什么相关?
- 多维拆分的工程成本
- GSC API + BigQuery Export工程化抽取怎么搭?
- 轻量档:Search Analytics API直拉
- 中量档:BigQuery Export配dbt或自建ETL
- BigQuery Export启用与使用的几个坑
- 重量档:完整SEO数据仓库
- CrUX、URL Inspection API、Crawl Stats API三件套补什么洞?
- CrUX(Chrome User Experience Report)
- URL Inspection API
- Crawl Stats API
- 三件套的协同使用顺序
- 把GSC + GA4 + 服务器日志三源对账起来要看哪些差异?
- 三源数据的关注重点对照
- 三种最常见的对账差异
- 在线教育长尾词案例
- 自动化对账周报的最小可行模板
- 常见问题解答
- GSC报表里那1000行是按什么排序选出来的?
- anonymized queries是什么?为什么我数据里有那么多?
- BigQuery Export能解决所有GSC数据折损吗?
- GSC和GA4的点击数对不上是正常的吗?
- URL Inspection API一天能查几个URL?
- 三源对账(GSC、GA4、服务器日志)真的有必要吗?
- GSC数据折损会越来越严重吗?
- 权威参考资料
摘要:Google Search Console报表里你看到的不是全部真实数据,是被三道折损闸过滤后的可见切片。1000行表格上限把长尾词砍掉、URL bucketing把零散页面塞进“其他”桶、阈值过滤把低展现量查询全藏起来变成anonymized。三者合起来吞掉的数据可能比你看到的还多一倍。这篇按机制原理 → 多维拆分突破 → API + BigQuery工程化抽取 → 四件套补洞 → GSC×GA4×日志三源对账,把“该看见但没看见”的那部分数据想办法补回来;用SEO指标层与单一事实源做承接的口径治理,再往后接Ahrefs/Semrush/GSC多工具对账形成完整数据栈。本篇切的是GSC单源数据完整性的工程化解法,与上面两篇互不重叠。
保哥见过太多甲方把GSC当作“Google给的官方数据,肯定是最准的”,然后基于上面的报表做内容决策、关键词选型、页面修复优先级。可真相是:GSC是Google给的采样数据,里面被砍掉的部分往往比留下的还多。理解GSC的三大数据折损黑洞、再用工程化方法把丢掉的数据想办法补回来,是任何严肃做SEO数据分析的底层基本功——可这件事行业里讲的人少得离谱。
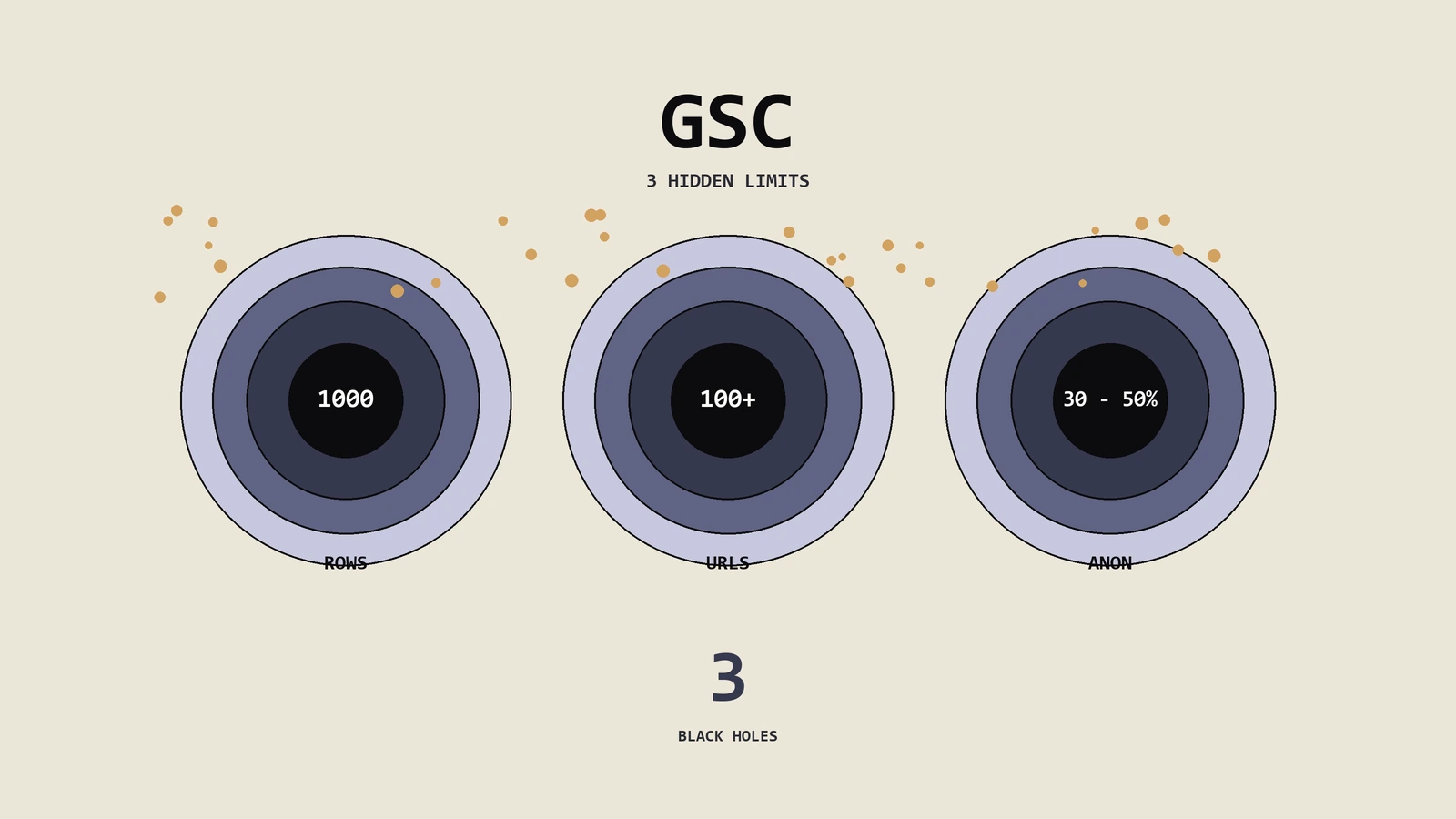
GSC数据三大黑洞到底吞了多少?
先看一组实测数据。保哥服务过一家跨境3C独立站,月均GSC展现量2400万,可见查询数4.8万条。同期通过BigQuery Export拉到的原始数据是:查询条目27.3万条,比GSC表格上限多了5倍多;其中点击数0的查询占84%、展现量低于阈值被隐藏的anonymized部分把“已知URL”的总展现量还原后比表格多了38%;“其他”桶里的零散页面合计展现量占整站22%。这家客户原本认为自己只覆盖了4.8万词,实际上覆盖了27万词;以为78% 的展现量集中在前1000个URL,实际上是56%。决策方向完全不同。
三大黑洞各自吞掉了什么?
用一个不严谨但形象的比喻来理解:GSC主报表就像一家大型菜市场每日只给客人开放前两排摊位的“门面菜单”,剩下的几十排摊位卖什么、谁在卖、价格多少、卖给了谁,你只能看到当天的总营业额数字。要知道真实情况只能换个角度——绕到后门看物流单、问摊主拿手账、对账供应商发票,把这些零碎线索拼合起来才接近真相。GSC数据补全的本质就是把这种“绕道还原”工程化、自动化、可重复,让原本散落在API、BigQuery、第三方工具、服务器日志各处的线索按一致口径汇聚成可决策的数据,而不是凭一张被砍掉一半的报表瞎拍板。
| 黑洞名 | 触发机制 | 吞掉的典型数据 | 对决策的影响 |
|---|---|---|---|
| 1000行表格上限 | UI与API单次查询返回的行数硬限制 | 长尾词、零点击词、低展现词 | 看到的全是头部,做长尾策略时缺基础数据 |
| URL bucketing“其他”桶 | 单一查询命中的URL太多时,零散尾部页面汇总成“其他”桶 | 分散流量的内容站尾部页面、SEO工程页面 | 看不到哪些页面在贡献长尾价值 |
| 阈值过滤anonymized queries | 展现量低于隐私阈值的查询隐藏,只保留总和不显示词 | 低展现长尾词、个性化触发的词、新词 | 新词与小众词发现盲区 |
为什么Google要做这三道折损?
不是因为Google想为难站长。三道折损各有原因:
- 1000行是工程性能限制——UI渲染表格 + API返回JSON的数据量上限,长期保留是为了响应速度与服务成本平衡
- URL bucketing是数据呈现可读性——一次查询命中几万个零散URL,全列出来反而失去意义,bucketing是无奈的折衷
- anonymized过滤是隐私合规——欧盟GDPR之后,低频查询可能携带可识别个体信息(病情、姓名、特殊地点搜索),不公开是法律义务
知道折损原因有什么用?知道了才能判断哪些数据“能补”哪些“不能补”——比如anonymized queries永远不会让你看到具体词(合规边界),但1000行限制可以通过多维拆分大幅突破。
三大黑洞叠加效应:可见数据vs真实数据的差距
三道闸不是独立工作,是叠加在一起。一条查询可能既因为展现量低被anonymized过滤掉、对应的URL又被bucketing归入“其他”桶、即使有展现也因为不在前1000行而看不见——这种三重叠加的情况下,单看GSC主报表你完全察觉不到这部分流量的存在。
判断叠加效应严重程度有个简单经验法则:把GSC站点级总展现量除以可见查询数 + 可见URL数的乘积,得到的“平均每个可见组合贡献的展现”如果远小于GSC给的“平均位置”对应的预期展现,说明大量流量被三道闸合力吃掉了。这种情况下不补全就做决策风险很高——你看到的“头部”可能只占真实流量的一半。
1000行表格限制是什么机制?怎么绕过这一关?
1000行限制是GSC数据折损里影响最大、也是最容易突破的一道闸。机制原理上它有两个层次:UI渲染时GSC后台一次最多渲染1000行;API调用searchanalytics.query时单次response也限定在25000行内(按维度组合不同有差异)。但二者都有变通空间。
多维拆分采样法
GSC的“1000行”是按当前筛选条件下计算的,而不是全局总数。换句话说,如果你换一个筛选维度,1000行的“前1000”就变成不同集合。把多个维度的“前1000”合并去重,理论上能拿到远超1000行的实际数据。下面这张表列了多维拆分的常用切法:
| 切法 | 维度组合 | 能补充的数据类型 | 典型扩容倍数 |
|---|---|---|---|
| 按日切 | 每天单独拉1000行 | 当天峰值出现的零散词 | 30-90天数据合并后5-15倍 |
| 按国家切 | 每个主要市场国家单独拉 | 本地化查询、小市场长尾 | 主要5-10个国家合并后3-8倍 |
| 按设备切 | 移动/桌面/平板各拉 | 设备特有查询模式 | 合并后2-3倍 |
| 按搜索类型切 | Web/Image/Video/News各拉 | 跨垂直搜索覆盖 | 合并后2-4倍 |
| 按页面切 | 每个核心页面单独拉 | 页面级的精细查询分布 | 需要先有URL清单 |
| 按查询前缀切 | 用contains过滤分段 | 主题集群内的长尾词 | 视集群密度而定 |
四轴拆分实操路径
对中型站的常规拆分路径是“日 × 国家 × 设备 × 类型”四轴:按60-90天每天拆 × 主要8个市场国家拆 × 桌面+移动两端拆 × Web+Image两种类型拆。理论组合90×8×2×2 = 2880个查询组合,去重后实际能拿到原始GSC表格30-80倍的查询条目。这套拆分对中型站(月展现100-1000万)效果最好;超大站(月展现亿级)建议直接走BigQuery Export,多维拆分的工作量超过收益。
常见误区与坑
- 不要按“查询关键词包含”做拆分——这种过滤本身依赖你已经知道的关键词,没法发现新词
- 按日拆分时anonymized仍然存在但每天阈值独立计算,所以累积起来覆盖更多原本被屏蔽的低展现长尾
- 按国家拆分时主要市场国家覆盖到80% 展现量就够了——尾部国家拆分性价比急剧下降
- 移动/桌面拆分对面向C端的站效果显著、对面向B端的站差异较小
- 多维拆分的输出要做“反向去重”——同一条查询可能在多个维度切片里都出现,合并时要按query+landing_page做唯一键
API配额、速率限制与重试策略
Search Analytics API的官方配额是每个项目每天1200个查询、每分钟1200个,但实际可用配额按你的OAuth项目状态调整。对中型站做3维拆分(90天 × 8国 × 2设备 = 1440次调用)已经接近日配额上限,需要做几件事来稳:
- 申请配额扩容(Google Cloud Console提工单),普通账号可申请到5000/日
- 实现指数退避重试——HTTP 429时按2的幂次等待时间后重试,最大重试5次
- 用ETag与条件请求节流——返回304 Not Modified的请求不计入配额
- 缓存中间结果——同一天同一国家同一设备的数据增量更新而非全量重拉
- 分时段调度——主要拉数据放在凌晨低谷期,避免与其他工程任务抢配额
阈值过滤(anonymized queries)怎么折损我的数据?
这是三大黑洞里最难处理的一道。Google出于用户隐私把展现量低于某个内部阈值的查询全部隐藏,在报表里标成anonymized;这部分查询的具体内容你永远看不到,只能看到它们的汇总点击与展现数。问题是这部分的占比通常很大——长尾型内容站anonymized占比30-50% 是常态,越是覆盖广泛、越多新词的站越严重。
anonymized的具体边界
| 维度 | 是否显示 | 说明 |
|---|---|---|
| 具体查询词 | 不显示 | 合规硬边界,任何方法都补不回来 |
| 这部分的总点击数 | 显示 | 在站点级或URL级汇总数里包含 |
| 这部分的总展现量 | 显示 | 同上 |
| 对应落地URL | 显示 | 知道是哪些页面收到的,但不知道关键词 |
| 对应国家、设备 | 显示 | 地理与设备分布可见 |
| 历史数据 | 不显示 | 过了发布日窗口完全消失 |
逆向估算anonymized占比的方法
虽然具体词补不回来,但anonymized部分的总量是可以倒推出来的。简单的方法是:
- 把整站某段时间内的“可见查询总点击/总展现”汇总,记为V
- 把同一时间段的“站点级总点击/总展现”汇总,记为T
- anonymized占比 ≈ (T - V) / T
这个差值就是被隐私阈值过滤掉的部分。保哥的经验是:
- 品牌站(70% 流量是品牌词)anonymized占比通常15-25%
- 电商类目站anonymized占比25-40%
- 纯内容站(博客、媒体、教育)anonymized占比40-55%
- 新发布站(< 6 个月)anonymized 占比可能 60% 以上,因为大量新词还在阈值之下
anonymized高占比的应对策略
具体词查不到,但能用站点层补救:
- 按落地URL反推主题——anonymized落到哪些URL上,主题方向就是已知的
- 用第三方关键词工具(Ahrefs、Semrush、Sistrix)的关键词数据库做交叉填补——它们的爬虫数据虽不完整但能看具体词
- 看GA4的Landing Page报表——展现到点击的转化路径间接揭示关键词类别
- 追踪长期趋势的anonymized占比变化——如果某月突然从30% 跳到50%,说明大量新词在阈值附近活动,是潜在增长信号
anonymized比例突变背后的常见原因
anonymized占比是个被低估的信号——长期看占比变化往往比展现量绝对值更能反映站点状态:
- 占比突然下降10个百分点——可能是Google调整了隐私阈值,或者你新发的几篇头部内容把大量原来藏着的词拉到了阈值之上
- 占比突然上升10个百分点——可能是某个核心头部页面流量崩了导致可见词总量缩水,或者大量新词刚开始爬坡都在阈值之下
- 占比稳定在高位——内容结构偏长尾型,正常状态,重点关注anonymized总展现量同比而非具体词
- 占比稳定在低位但绝对展现量低——头部集中度过高,可能错过大量长尾机会,可以反向用anonymized总量来评估站点的“未开发潜力”
URL分组(“其他”桶)藏了哪些页面?
URL bucketing是GSC里相对小但同样影响大的折损。当某个查询命中的URL数量超过一定阈值,GSC会把零散的尾部页面合并成一个“其他”桶展示。你能看到这个桶的总点击与总展现,但不知道里面具体是哪些页面。
URL bucketing触发场景
- 大型聚合站(论坛、问答、UGC、电商)某些品类页面分散——同一查询下100+ 个URL都有展现,尾部80+ 被归入“其他”
- 同一信息密集型站点的标签页、归档页、分页——长尾分布严重
- 多语言版本的同主题页面——通过hreflang关联但GSC把它们当独立URL处理
- UTM参数化的入口页面——同一基础URL加不同参数被当成不同URL
“其他”桶的逆向分布估算
跟anonymized类似,“其他”桶的具体URL看不到,但分布可以估算:
- 把同一查询下的“已知URL”按点击量分布做帕累托分析
- “其他”桶的总点击除以未知URL的预估数量,可估算尾部页面平均贡献
- 跨多个查询观察“其他”桶的总量变化趋势——长期上升说明长尾页面价值在累积
更实用的方法是:把核心查询的“已知URL”列表合起来,跟站点sitemap做差集,剩下没出现在任何查询“已知URL”里的页面,大概率就是“其他”桶的常住居民——这部分页面要么内容质量不达SERP标准(应该剪枝),要么是新页面还没起飞(应该扶持),靠侧面方法识别出来。
多维拆分到底能补回多少真实数据?
讲完三大黑洞机制,下面把团队跑过的多维拆分实测数据展开看。三家典型客户的对比:
| 客户类型 | GSC原始可见词 | 四轴拆分后唯一词 | 扩容倍数 | anonymized估算占比 | “其他”桶估算占比 |
|---|---|---|---|---|---|
| 出海B2B法务SaaS | 1.2万 | 5.4万 | 4.5倍 | 32% | 11% |
| 跨境3C独立站 | 4.8万 | 27.3万 | 5.7倍 | 38% | 22% |
| 出海消费电子内容媒体 | 2.3万 | 18.9万 | 8.2倍 | 47% | 18% |
扩容倍数与什么相关?
实测下来三个最相关因素:
- 市场覆盖广度——覆盖国家数越多,按国家拆分能补的越多。仅做美国市场的站扩容3-4倍是上限,覆盖8-10个国家的全球站能到6-10倍
- 内容长尾度——内容站长尾分布最严重,扩容倍数最高;电商品牌站头部集中,扩容相对小
- 站点年龄——老站积累了更多历史尾部词,多维拆分挖出来的“被遗忘的词”更多;新站本身就没太多尾部
多维拆分的工程成本
不能盲目堆维度——每多一维边际成本指数上升而边际收益递减:
- 2维(日+国家):覆盖GSC总展现的75-85%,API调用量适中,单站每天100-500次调用
- 3维(日+国家+设备):覆盖到88-93%,API调用量翻倍,单站每天200-1000次调用
- 4维(日+国家+设备+类型):覆盖到92-96%,API调用量再翻倍但收益已经很薄
- 5维及以上:覆盖率不会显著上升,但API配额会成为瓶颈
一般推荐3维就够了,4维只在做年度大盘审计时跑一次。
GSC API + BigQuery Export工程化抽取怎么搭?
多维拆分手工跑当然不现实,必须工程化。下面是这套数据栈的标准搭建路径,按从轻到重三档:
轻量档:Search Analytics API直拉
适合数据量适中(月展现100万-1亿)的站。技术栈:
- 语言:Python配Google API Client、或Node.js配googleapis包
- 认证:OAuth 2.0服务账号,授权Webmasters API
- 调度:cron或GitHub Actions每天定时跑
- 存储:直接落CSV、或入SQLite/Postgres简单库
- 可视化:Looker Studio直连API、或拉本地后画图
中量档:BigQuery Export配dbt或自建ETL
2023年Google正式GA了GSC的BigQuery数据导出功能,免费每天导出原始数据到你的BigQuery项目。这是数据完整性的最大跃迁——突破1000行限制、保留更长历史、原始字段更多。技术栈:
- BigQuery项目设置(基础免费、查询付费但量小成本低)
- GSC后台勾选启用导出、关联到BigQuery项目
- 表结构:searchdata_site_impression + searchdata_url_impression两张主表,每天滚动
- dbt做数据模型化分层(raw → staging → mart)
- Looker Studio或Metabase接入BigQuery做可视化(详见Looker Studio搭SEO仪表盘的工程实践)
BigQuery Export启用与使用的几个坑
启用看似简单但有不少容易踩的坑:
- 启用之后不会回填历史数据——只有启用之后的新增数据会导出,过去16个月的数据仍然只能通过API拉取,启用越早越好
- 每天的数据延迟2-3天才会出现在BigQuery表里——做实时监控不能完全依赖这一档
- BigQuery项目所在地区要选对——欧盟客户的数据如果落在美国地区可能违反GDPR,建议选multi-region EU或europe-west单区
- 查询付费上限要设——一不留神跑全表扫描很烧钱,最低也要给单查询设1GB上限
- 表分区与聚簇要做——按日期分区 + 按query聚簇,常用查询能减少80%+ 扫描量
- 跟其他数据源JOIN时小心query字段的NULL值——anonymized queries在BigQuery里query字段为NULL而不是被剔除,简单GROUP BY query会漏算这部分
重量档:完整SEO数据仓库
大站或多站点矩阵管理才用得上:
- BigQuery / Snowflake / Redshift之一作为数据湖
- GSC + GA4 + 第三方爬虫数据(Ahrefs/Semrush API)+ 服务器日志 + 内部业务数据多源汇总
- Airflow / Dagster做调度
- 专属SEO Analytics团队维护
注意:anonymized queries在BigQuery Export里仍然不显示具体词(合规边界统一)。BigQuery Export解决的是1000行限制和历史保留,不解决anonymized与URL bucketing两道闸——这点千万不要误判。
CrUX、URL Inspection API、Crawl Stats API三件套补什么洞?
GSC主报表是数据骨架,但站内SEO工程还需要几套补充API才能拼出全图。三件套各补一道关键洞:
CrUX(Chrome User Experience Report)
CrUX是Google公开的Core Web Vitals真实用户数据集,按月发布。它补的是GSC不显示的真实用户性能体感:
- LCP、INP、CLS三大核心指标的真实分布(不是PageSpeed Insights模拟数据)
- 按页面URL或域名级粒度
- 桌面/移动分别可看
- 历史数据可追溯到2017年
- 数据集免费、放在BigQuery公开数据集里直接查
URL Inspection API
这个API补的是单URL的索引状态细节,GSC主报表看不到的部分:
- 索引覆盖详细状态(Submitted/Indexed/Crawled/Discovered/Error)
- Google选定的canonical URL
- 最后抓取时间与抓取结果
- 渲染过的HTML(看到的是Google真实抓取版本)
- 移动端可用性详情
限额是每个站点每天2000个URL,配额按分钟限速。这意味着大站不能全量审计,必须按优先级排队:核心商业页面 + 最近发布的页面 + 流量异常的页面 = 重点监控池。
Crawl Stats API
Crawl Stats看的是Googlebot抓取你站点的详细日志:
- 每日抓取请求数
- 抓取响应字节数与平均响应时间
- 抓取响应状态码分布(200/3xx/4xx/5xx)
- 按Googlebot类型分(Googlebot、Googlebot-Image、AdsBot等)
- 抓取目的(Discovery / Refresh)
这套数据对技术SEO排查不可替代——抓取频次突降、5xx响应突增、AI爬虫流量异常都靠这里识别。
三件套的协同使用顺序
三件套不是平行随便用,有最高性价比的协同顺序。常规运营场景:先看CrUX看真实用户体感的趋势线,确认页面性能没有结构性问题;再用URL Inspection API抽样核心页面看索引状态详情;最后用Crawl Stats API看Googlebot抓取健康度。这个顺序对应“用户感受 → 索引正确性 → 抓取可达性”由表及里的诊断链路。遇到流量异常时反向走——先Crawl Stats看是不是抓取层出问题、再URL Inspection看具体URL的索引状态、最后CrUX看是不是性能突变赶走了用户。
大站每天的常规自动化脚本组合是:CrUX月度趋势看板(每月1号刷新)+ URL Inspection每日核心200个页面巡检(流量Top 100 + 最近7天发布的100个)+ Crawl Stats每周一次跟历史基线对比。这套组合能把80% 以上的技术SEO异常在影响显著扩大前发现。
把GSC + GA4 + 服务器日志三源对账起来要看哪些差异?
三源数据对账是SEO数据工程的“压舱石”——任何一源出问题,另外两源能交叉验证。常见的对账差异有几类,每一类背后都对应可识别的根因。
三源数据的关注重点对照
| 数据源 | 关注重点 | 看到的 | 看不到的 |
|---|---|---|---|
| GSC | SERP上的展现与点击 | 未到落地页的点击、查询关键词、设备国家 | 站内行为、转化、bot流量细节 |
| GA4 | 用户到达落地页之后的行为 | 会话、跳出率、转化、归因路径 | SERP上没点击进来的展现、详细查询词 |
| 服务器日志 | 所有到达服务器的请求 | 所有bot、所有HTTP状态、原始请求路径 | 用户搜索意图、转化数据 |
三种最常见的对账差异
差异1:GSC点击数 > GA4 organic会话数。差异10-30% 是常态(adblock、JavaScript屏蔽、跟踪cookie拒绝、用户快速关闭页面没触发page_view)。差异超过50% 要查跟踪代码:是不是GA4在某些页面没部署、是不是referrer信息丢失导致归因到direct/none、是不是有运营商劫持把referrer替换。
差异2:服务器日志Googlebot抓取数 > Crawl Stats API报告数。这种差异往往是UA伪造导致——别人冒充Googlebot抓你的站。靠反向DNS验证IP可以剔除假Googlebot,差异收窄之后还有5-15% 残留属于正常的统计粒度差。
差异3:GA4 organic会话数 > GSC点击数。这种反向差异比较少见但出现时几乎都是归因配置问题——常见原因是把utm_source=google的付费流量被归到了organic池,或者把社交平台带来的“自然搜索”误归到organic。
在线教育长尾词案例
保哥服务过一家在线教育平台,2025年初某月GSC报表显示某课程页面排名第4、展现量稳定,但GA4显示该页面organic会话同比下降28%。三源对账后发现:GSC展现量正常但点击率从8.2% 掉到5.1%;GA4 organic会话同步下降但落地页跳出率没变化;服务器日志显示该页面访问数下降幅度跟GA4一致,证明不是跟踪代码问题。最后定位到根因——SERP第1-3位被AI Overview的答案盒接管,蓝链点击大量被吸走。这种“展现没变但点击没了”的现象,单看GSC看不到全貌,必须三源对账才能给出有说服力的诊断结论,而不是被甲方质问“为什么GSC显示我们排名没掉但流量没了”答不上来。
自动化对账周报的最小可行模板
不需要花俏的BI工具,一张5行表就能跑起来:
| 指标 | GSC周值 | GA4周值 | 日志周值 | 差异比例 | 告警阈值 |
|---|---|---|---|---|---|
| 组织自然点击/会话 | GSC点击数 | GA4 organic会话数 | 日志referrer=google数 | (GSC-GA4)/GSC | 差异 >40% 告警 |
| Googlebot抓取请求 | Crawl Stats API | — | 日志UA=Googlebot | (日志-API)/日志 | 差异 >25% 告警 |
| 核心页面索引数 | URL Inspection API | — | — | 本周-上周变化 | 下降 >5% 告警 |
| 展现量同比 | GSC | — | — | 本周-去年同周 | 下降 >15% 告警 |
| 点击率同比 | GSC | — | — | 本周-去年同周 | 下降 >20% 告警 |
这张表配合GSC自定义报表与诊断指南里的“周度健康度报表”框架使用最顺手,把GSC单源诊断升级成三源诊断不增加太多人力。每周一上午半小时跑一遍,告警阈值任何一项被触发就进入深度排查,没触发就只看趋势线。
常见问题解答
GSC报表里那1000行是按什么排序选出来的?
按当前筛选条件下点击量从高到低取前1000行。所以长尾词、零点击词、impression很低的词大概率被截掉。换不同筛选维度(日/国家/设备/类型)拿到的前1000行内容不重叠,正是多维拆分能补出更多数据的根本原因。
anonymized queries是什么?为什么我数据里有那么多?
GSC出于用户隐私把展现量低于某个阈值的查询隐藏,标成anonymized。占比可能高达总查询的30-50%,越长尾的页面这部分越严重。它们的总点击/展现汇总数还显示在站点级,但具体词不可见。
BigQuery Export能解决所有GSC数据折损吗?
不能。BigQuery Export突破1000行限制和保留更长历史,但anonymized queries仍然不出现、URL bucketing仍然存在。它是必要工程基础,不是数据完整性的终点。
GSC和GA4的点击数对不上是正常的吗?
正常。GSC看的是SERP上的点击事件(含bot与未到落地页的),GA4看的是真到落地页且发送了page_view的会话。两者差10-30% 是常态,差50% 以上要查跟踪代码与广告劫持。
URL Inspection API一天能查几个URL?
Google给的官方限额是每个站点每天2000个URL,按分钟限速到60个/分钟左右。够监控核心几百到几千个页面,但不够给大站全量审计用,需要按优先级排队。
三源对账(GSC、GA4、服务器日志)真的有必要吗?
有必要但要按场景排优先级。常态运营靠GSC + GA4双源已经够用;技术SEO排查(抓取浪费、bot伪造、收录异常)必须有日志;电商高客单转化归因争议时三源都不能少。
GSC数据折损会越来越严重吗?
趋势上是。隐私阈值近年只升不降、AI Overview接管段不算SERP点击、Discover与新闻tab的数据相对独立。靠GSC单一信源做决策的难度只会上升,多源校准已经是必选项。
权威参考资料
本文标题:《Google Search Console三大数据黑洞怎么破?1000行+URL分组+阈值过滤补全工程》
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0