Google索引覆盖状态机制:8种GSC未编入索引状态的算法决策路径

本文目录
- GSC索引状态不是8个技术标签是8条算法决策路径
- 页面被索引前要走的7个算法决策节点
- 状态名翻译误区:未索引不等于没收录
- 状态一:Discovered - currently not indexed(抓取调度被压低优先级)
- 算法为什么会把URL压在Discovered不抓?
- 典型场景:新站深层博客或电商分类页
- 修复方向:从抓取调度角度下手不是从内容角度
- 状态二:Crawled - currently not indexed(质量评估未通过)
- 算法判定不值得索引的5类常见原因
- HCU之后这个状态的爆发
- 修复方向:先治站再治页
- Duplicate Canonical家族(去重与代表URL选择)
- Duplicate, Google chose different canonical than user
- Duplicate without user-selected canonical
- Alternate page with proper canonical tag
- Soft 404:语义判定失败的特殊"404"
- 算法判定Soft 404的4类典型信号
- 修复方向二选一:要么补内容要么真返404
- Soft 404也分类型:完全空vs部分有内容vs语义不匹配
- Blocked系列:抓取被显式拦截的几种方式
- Blocked by robots.txt:常被滥用的拦截工具
- Excluded by 'noindex' tag:按设计意图被排除
- Page with redirect与Not found 404
- 8状态的算法决策路径全图
- 状态间转换的4类典型路径
- 正向转换:Discovered → Crawled → Indexed
- 反向转换:Indexed → Crawled - currently not indexed
- 水平转换:Duplicate内部状态变化
- 临时转换:Blocked due to 4xx与服务器错误
- 不同规模站点的状态分布画像
- 小站(<500页):索引率应该90%+
- 中型站(1k-10k页):索引率70-85% 算正常
- 大站(10k-100k页):索引率50-70% 都正常
- 电商或聚合超大站(100k+ 页):30-50% 不奇怪
- B2B SaaS 9个月索引率从42% 拉到91% 复盘
- 起点诊断:状态分布严重畸形
- 三阶段策略:先治站再治结构再治单页
- 9个月数据演变
- 三个被低估的踩坑细节
- 几个会让诊断误判的场景与上线前必验清单
- 误判场景一:把Discovered当Crawled处理
- 误判场景二:把Alternate当问题处理
- 误判场景三:盲目追求100% 索引率
- 误判场景四:用robots.txt处理noindex场景
- 误判场景五:忽视反向转换的算法信号
- 上线前必验清单
- 常见问题解答
- Discovered和Crawled currently not indexed有什么本质区别?
- 为什么我提交sitemap几周了页面还是Discovered状态?
- Duplicate, Google chose different canonical和我设的canonical不一样怎么办?
- Soft 404状态怎么判定,明明页面打开是正常200啊?
- Alternate page with proper canonical tag算正常还是异常?
- Blocked by robots.txt状态会影响排名信号吗?
- 索引率到底多少算正常?
- 权威参考资料
摘要:新接客户经常给保哥看一张图——GSC页面索引报告里写着"未编入索引8400条",下面拉一排英文状态码。大半SEO同行只能看出"哦没索引",看不出每个状态对应的算法决策路径,修复方向自然乱。这篇把8种典型未索引状态当成Google算法在抓取-渲染-去重-入库管线上的决策节点拆透,配状态转换图、跨规模站点画像、9个月B2B SaaS真实复盘。看完不会再把Discovered和Crawled当一回事处理。
GSC索引状态不是8个技术标签是8条算法决策路径
GSC页面索引报告里那些英文状态名(Discovered - currently not indexed / Crawled - currently not indexed / Duplicate, Google chose different canonical / Soft 404 / Blocked by robots.txt / Page with redirect / Alternate page with proper canonical tag / Not found 404 / Excluded by 'noindex' tag等等),每一个不是孤立的技术标签,是Google算法在一条管线上某个具体决策节点的判定结果。
这条管线从URL发现开始,经过抓取调度、内容获取、HTML渲染、内容去重、质量评估、Canonical选择,最后才到入库展示。8种状态分布在这条管线的不同位置,每个状态对应一个特定的算法决策。看懂状态机的关键不是背状态名翻译,是搞清楚每个状态意味着算法卡在哪一步、为什么卡在那一步、怎么让它通过。
页面被索引前要走的7个算法决策节点
一个新发布的URL要进Google索引展示在SERP上,要走完7个算法决策节点。第一个节点是URL发现——Google通过Sitemap提交、内链发现、外链发现、用户提交等渠道知道这个URL存在。第二个节点是抓取调度——Google判断要不要派Googlebot去抓这个URL、什么时候抓、用什么频率抓。
第三个节点是抓取执行——Googlebot实际访问URL拿到HTTP响应。第四个节点是HTML渲染(如果需要JS渲染)——把客户端JS跑完得到最终DOM。第五个节点是内容去重——判断这个内容是否与已有索引内容重复。第六个节点是Canonical选择——如果不是重复,选哪个URL作为代表入库。第七个节点是质量评估——综合内容质量、权威信号、用户行为预测判断要不要真的入库。
8种典型未索引状态对应到这7个节点的失败点。Discovered卡在节点二、Crawled卡在节点七(质量评估)、Duplicate系列卡在节点五和六(去重与Canonical选择)、Soft 404卡在节点七的语义判定子环节、Blocked系列卡在节点三的访问环节、Page with redirect卡在节点六的URL选择。看懂这套对应关系,每个状态的修复方向就清晰了。
状态名翻译误区:未索引不等于没收录
中文GSC把not indexed翻译成"未编入索引",很多SEO同行就理解成"没收录"。这个理解不准。Google严格区分两个概念——已知(known,URL在Google数据库里)和已索引(indexed,可在SERP上展示)。
Discovered状态的URL是已知但未抓取;Crawled - currently not indexed是已抓取但未入库;Alternate page with proper canonical tag是已知且按设计意图被合并到canonical页面。三个状态都叫"未索引"但意义完全不同。把"未索引"统一理解为"没收录"会让诊断方向完全跑偏。
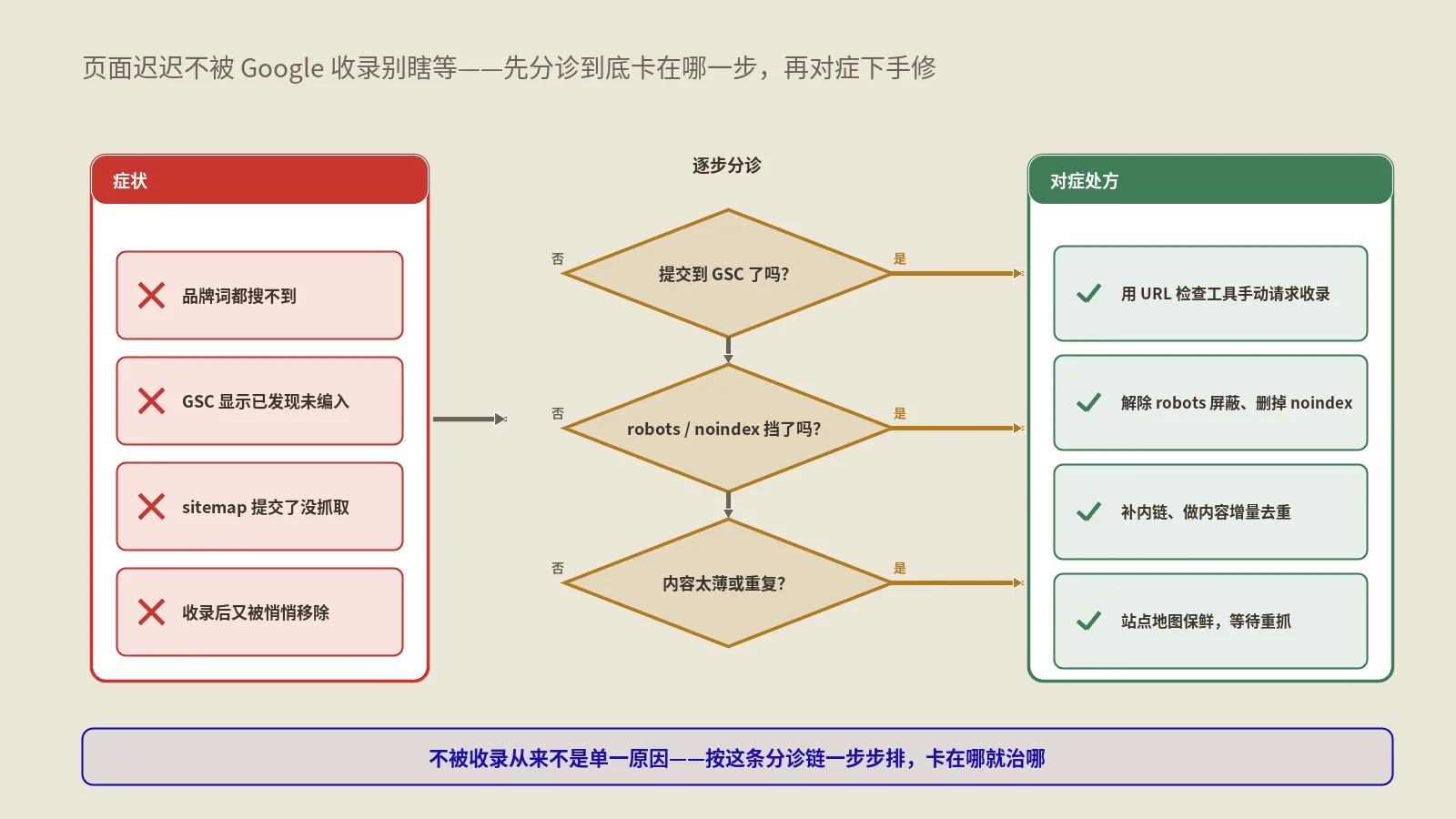
状态一:Discovered - currently not indexed(抓取调度被压低优先级)
Discovered状态表示Google已经发现这个URL(通过Sitemap或内链或外链),但还没派Googlebot来抓取。这是抓取管线最早的卡点,对应算法决策节点二——抓取调度。
算法为什么会把URL压在Discovered不抓?
核心原因是抓取预算分配。Google给每个站点分配的抓取预算是有限的,需要按优先级分配到该站点的所有URL上。新发现的URL排队进抓取队列,队列里靠前的优先抓、靠后的可能排几周甚至几个月。决定队列顺序的信号包括URL在内链架构中的位置(首页直链优先于深层埋点)、上级页面的抓取频率、URL来源的权威性(高DR站外链发现的优先)、历史上Googlebot对该站点同类URL的抓取与质量经验。
这套优先级机制的实际效果是——发布在站点深层、内链入口少、外链支持弱的URL,可能长期卡在Discovered。新站尤其严重,因为Google对新站的整体抓取预算就低,分配到深层页面的更少。
典型场景:新站深层博客或电商分类页
常见的Discovered集中爆发场景有三个。新站发布大量内容但内链架构不合理,70% 以上博客文章只能通过Archive列表页或Sitemap入口发现。电商站新增SKU分类页,但分类页隐藏在筛选器里没有直接HTML链接。聚合站点抓取式生成大量页面,但没有从首页或权威hub页给入口。
这三类场景的共同特征是URL在内链架构中的发现路径过长(>3级跳)或权威页面没有直接指向。结果是Google知道这些URL存在但优先级很低,长期卡在Discovered。
修复方向:从抓取调度角度下手不是从内容角度
Discovered的修复方向是改善抓取调度信号,不是改内容。常用动作有:把目标URL加到从首页可达的hub页内链里、提升hub页本身的PageRank(外链或高权威内链)、用Sitemap priority字段标注高优先级(作用有限但有)、通过Indexing API主动推送(仅特定行业生效)、检查是否有robots.txt或robots meta误拦。配合服务器日志的抓取预算与Bot验证看到Googlebot实际访问轨迹,能判断哪些URL优先级被压、哪些被反复抓。
判断修复有效的信号是Googlebot在服务器日志里开始访问目标URL。如果改了内链架构4到8周还没看到Googlebot访问,说明修复力度不够,要加强信号。
状态二:Crawled - currently not indexed(质量评估未通过)
Crawled - currently not indexed状态表示Googlebot已经抓取了这个URL的内容,但Google判断不值得放进索引。这是抓取管线最深也最难解的卡点,对应算法决策节点七——质量评估。
算法判定不值得索引的5类常见原因
质量评估是综合判定,但实战里常见的判定原因有5类。一是内容过于稀薄——正文文字量极少(< 300字)、缺少实质信息、模板痕迹过重。二是与站内或站外已有内容高度重复——爬虫抓回来一看大部分内容已经被索引过了,没必要再收一份。三是质量信号不足——E-E-A-T信号薄、作者信息缺失、出处与权威背书缺失。四是用户行为预测差——Google基于历史数据预测这个页面即使收录也不会有点击或停留。五是页面所属站点的整体权威度低——Google对新站或低权威站的页面有更严的入库门槛。
HCU之后这个状态的爆发
2022年8月HCU(Helpful Content System)上线后,Crawled - currently not indexed状态的页面数量在很多站点出现爆发式增长。HCU把内容有用性作为站级信号叠加到质量评估上,对于被判定为"为搜索引擎而不是为人写"的站点,整站索引门槛会提高。结果就是大量原本能进索引的页面被卡在Crawled状态。
2024年3月Core Update把HCU并入核心算法后,这种站级质量门槛影响进一步常态化。今天看到Crawled - currently not indexed大量出现的站点,首先要怀疑的不是单页质量问题,是站级HCU信号问题。
修复方向:先治站再治页
Crawled - currently not indexed的修复路径是先治站再治页。站级动作包括——审视全站内容是否有大量"为SEO而写、不为读者而写"的页面(如果有,先做内容剪枝),强化站点E-E-A-T信号(作者署名、原创数据、专业资质背书),优化用户行为信号(页面停留、跳出率、内部跳转)。
页级动作包括——补充实质信息(不是字数堆砌而是真正回答用户需求)、补充原创视角(保哥团队的实战观察、客户案例、行业一手数据)、加强Schema结构化(Article/Author/Organization)。站级动作通常需要3到6个月才看到效果,页级动作2到8周可见。
Duplicate Canonical家族(去重与代表URL选择)
Duplicate相关的状态有三种,都对应到去重与Canonical选择两个决策节点。这三种状态经常被混淆,但实际意义差很大。
Duplicate, Google chose different canonical than user
这个状态表示URL A通过canonical标签指向URL B,但Google不认你设的canonical,自己选了URL C作为代表。这是典型的"用户意图与算法判定冲突"。
算法不接受你设的canonical通常有三类原因。一是内容相似度极高但URL C在内链或外链信号上明显更强(Google觉得C才是真正的权威版本)。二是用户行为偏向C——SERP上点击C的多、停留长、跳出低。三是C的canonical与A不一致(A指向B,C指向D,Google综合判断觉得D才是真正的代表)。
修复方法是要么真正做内容差异化(让A与C不再高度相似)、要么主动统一信号(把A用301跳到C,承认Google的选择)。强行坚持指向B通常没用,因为算法不会按你的canonical走。这部分跟Google Canonical URL选择9大决策逻辑讲的算法决策维度是一脉相承的,决定权不在canonical标签本身。
Duplicate without user-selected canonical
这个状态表示你完全没设canonical标签,但Google抓回来发现你站内有多个URL内容高度相似。Google自己选了一个作为代表,其他都标记为Duplicate。
这种状态对应的典型场景是电商带筛选参数的URL(example.com/category vs example.com/category?color=red vs example.com/category?sort=price三个都被抓但内容近似)、博客的分页URL(page 1/2/3内容相近)、内容管理系统自动生成的多个访问路径(example.com/post vs example.com/2024/post vs example.com/category/post)。
修复方法是显式设canonical标签告诉Google哪个URL是代表,或者用robots.txt / robots meta拦掉不应被抓的参数版本,或者用URL参数处理工具(已逐步弃用)。从工程上推荐显式canonical,因为robots拦的方式有副作用。
Alternate page with proper canonical tag
这个状态是完全正常的设计意图。URL A通过canonical标签指向URL B,Google接受了你的设定,把A标记为B的备用页(alternate),索引的是B而不是A。这是SEO的预期行为,不需要修复。
需要关注的只是canonical指向是否真的是你想要的。比如本应指向英文版的国际版canonical写错指到了西班牙版,会导致英文版不被索引而西班牙版被索引(虽然西班牙版的内容质量可能更低)。定期审计canonical指向是否正确,是大型多语言站的必做动作。
Soft 404:语义判定失败的特殊"404"
Soft 404状态是最容易让SEO同行困惑的状态。页面打开明明是HTTP 200状态码,没任何技术意义上的404,但Google偏说这是Soft 404不收录。这是Google的语义判定。
算法判定Soft 404的4类典型信号
Google判定Soft 404不看HTTP状态码,看的是语义信号。典型信号有4类。一是页面正文极少(通常 < 100字),无法构成完整页面。二是出现"not found"、"页面不存在"、"该商品已下架"、"已售罄"等明示性文本。三是页面主要内容是错误提示或重定向跳转,没有实质信息。四是URL主题与正文内容严重不匹配(如URL是某产品SKU但正文是空白模板)。
满足上述任一信号且页面体积小于5KB的页面,被判Soft 404的概率极高。电商的缺货占位页、博客的空分类聚合页、内容已删后的占位页、动态生成失败后的回退页都是高发场景。
修复方向二选一:要么补内容要么真返404
Soft 404的修复方向有两条互斥路径。一是补充实质内容——电商缺货页加上推荐替代品、品牌故事、用户评价,让页面有实质阅读价值;博客分类页加上分类介绍、热门内容推荐,不只是文章列表骨架。二是直接返回HTTP 404或410状态——承认这个URL不应存在,让Google干脆把它从索引中清掉。
选哪一条取决于URL的商业价值。有商业价值(如品牌词、长尾词流量入口)的页面补内容;没商业价值的页面直接404让它从索引消失。最忌讳的是放任Soft 404大量积累——会拖低站级质量信号,影响其他健康页面的抓取与索引。
Soft 404也分类型:完全空vs部分有内容vs语义不匹配
实战里Soft 404不是一种统一现象。完全空白的页面(如错误页)算硬性Soft 404,处置最简单。部分有内容但内容稀薄的页面算轻度Soft 404,需要补内容。语义不匹配的页面(如URL像产品页但正文是错误提示)算最复杂的一类,常常需要前端工程师协同修代码层逻辑而不是补内容。
诊断时按这三类分桶,分别采取对应动作,比一刀切按Soft 404处理效率高得多。
Blocked系列:抓取被显式拦截的几种方式
Blocked系列状态表示页面在抓取阶段就被拦截了,Google根本没拿到内容。这一类问题诊断相对简单但容易误用工具。
Blocked by robots.txt:常被滥用的拦截工具
robots.txt拦截是大家最熟悉的方式。在robots.txt里写Disallow: /private/ 等规则,Googlebot就不会抓取该路径下的URL。但robots.txt拦截的后果常被误解——被拦的URL仍然可能被Google知道(通过外链发现),并以URL加一句robots.txt描述的形式出现在SERP上。这种展示对品牌词搜索体验是负面的。
如果真的不想让URL出现在搜索结果里,正确做法是用noindex meta标签而不是robots.txt拦。两者的语义完全不同——robots.txt是"不让爬虫看",noindex是"看过但不索引"。后者的效果更彻底。这部分组合策略XML Sitemap与多引擎差异完整指南里有更系统的归纳,sitemap与robots.txt应该配合而不是替代。
Excluded by 'noindex' tag:按设计意图被排除
这个状态表示页面HTML里有noindex meta标签或HTTP响应里有X-Robots-Tag: noindex,Google抓取后按设计意图把它排除出索引。这是预期行为不是问题。
需要关注的只是noindex是否设对了页面。常见错误是CMS升级或主题更新时全站误加noindex导致整站从索引消失,或者后台测试页的noindex漏掉了导致内部页面被索引。建议每月用Screaming Frog全站扫一次noindex标签确认覆盖正确。
Page with redirect与Not found 404
Page with redirect表示URL返回3xx跳转,Google跟随跳转去索引目标URL,原URL标记为redirect。Not found 404表示URL返回4xx,Google把它从索引中标记移除。这两个都是清晰的预期行为。
需要关注的是这两类的数量是否合理。Page with redirect数量过大说明站内有大量历史URL还在通过跳转维持,可能需要考虑直接404减少跳转链长度。Not found 404数量突增可能说明站点出了批量删除事故或URL结构调整漏了重定向。
8状态的算法决策路径全图
把前面拆的8种状态放到Google算法管线上,能画出一张完整的决策路径图。下表是按管线节点排列的状态映射,建议每次诊断时按这张表逆推。
| 算法节点 | 对应失败状态 | 典型原因 | 修复方向 |
|---|---|---|---|
| 1. URL发现 | (不在GSC索引报告里完全未知) | 无Sitemap、无内链、无外链 | 补发现路径(Sitemap/内链/外链) |
| 2. 抓取调度 | Discovered - currently not indexed | 优先级低、入口深、信号弱 | 改善内链架构、提权威 |
| 3. 抓取访问 | Blocked by robots.txt / Blocked due to 4xx | 显式拦截或服务器返回错误 | 调robots.txt或修服务器 |
| 4. 渲染(如需) | Crawled - 渲染失败子情况 | JS阻塞、超时、资源缺失 | 优化SSR/CSR与关键资源 |
| 5. 去重判定 | Duplicate系列 | 内容相似、参数URL、副本 | 显式canonical或差异化 |
| 6. Canonical选择 | Duplicate, Google chose different / Alternate | 用户与算法选择冲突或一致 | 对齐算法选择或加强差异 |
| 7. 质量评估 | Crawled - currently not indexed / Soft 404 | 内容稀薄、HCU站级低、语义不匹 | 站级E-E-A-T+页级实质内容 |
| 明确排除 | Excluded by 'noindex' / Page with redirect / Not found 404 | 按设计意图或正常URL生命周期 | 确认设置正确即可 |
这张表是诊断SOP的基础。每次拿到一个站点的GSC索引报告,先按这张表分类,再针对性给修复方向,效率比凭经验拍方案高得多。
状态间转换的4类典型路径
8种状态不是静态标签,是动态的状态机。一个URL可以从一个状态转换到另一个状态,转换路径有几条典型形态值得记。
正向转换:Discovered → Crawled → Indexed
最希望看到的正向转换是Discovered(已发现未抓)→ Crawled - currently not indexed(已抓未索引)→ Indexed(已索引)。这条路径的每一步都对应算法决策节点的通过。Discovered转Crawled需要抓取调度通过;Crawled转Indexed需要质量评估通过。
实战里看到URL从Discovered转到Crawled之后,到底会不会进一步转到Indexed,取决于内容质量。如果质量过关,2到8周内会进Indexed;如果质量不过关,会一直停留在Crawled状态。看到Crawled长期不动,说明质量这一关没过。
反向转换:Indexed → Crawled - currently not indexed
已经在索引里的URL也可能反向转出来。最常见的反向转换是Indexed转Crawled - currently not indexed——原本被收录的页面突然被算法判定不值得继续保留在索引里。HCU上线、算法更新、站级质量评估下调都可能触发这种反向转换。
反向转换是非常重要的信号。如果一个站短期内大量URL从Indexed反向转Crawled,几乎可以确定遭遇了某种算法处罚或质量评估下调。需要立刻按HCU与质量信号的恢复路径做诊断。另一类常被忽视的反向转换触发是移动优先索引切换后桌面版掉量的修复——MFI之后Google抓的是移动版,如果移动版的内容、Schema、内链密度与桌面版有差异,原本以桌面版进索引的页面可能反向转出。
水平转换:Duplicate内部状态变化
Duplicate系列内部也有水平转换。Alternate page with proper canonical tag可能转成Duplicate, Google chose different canonical(你设的canonical算法不再接受),反过来也可能。这种水平转换通常对应内容更新、内链信号变化、用户行为变化。
水平转换的修复方向是检查内容差异化是否够、canonical信号是否一致。如果内容真的高度相似,Google选哪个作canonical都有可能,需要主动决定哪一个是代表并加强信号。
临时转换:Blocked due to 4xx与服务器错误
服务器临时故障(5xx、超时、限流)可能让原本健康的URL临时转到Blocked due to 4xx状态(虽然名叫4xx但5xx也归这里)。这类转换通常是短期的,服务器恢复后会自动转回正常状态。
但如果服务器持续故障超过2到4周,Google会判定URL长期不可访问,可能把它从索引中移除并转为Not found 404状态。监测重点是5xx不能长期化,发现批量5xx要立即修。
不同规模站点的状态分布画像
不同规模站点的索引状态分布是不一样的。看懂正常分布是判断异常的基础。下面按四档规模给出经验性的状态分布画像。
小站(<500页):索引率应该90%+
小站的URL数量少,Google的抓取预算分配相对充裕,每个URL都能被关注到。正常的小站索引率应该90% 以上。Discovered状态应该几乎为零(除非新发布等抓取队列),Crawled - currently not indexed应该不超过5%,Soft 404应该不超过2%。
如果小站索引率低于80%,几乎确定是站级问题——HCU信号差、整站权威度低、或者批量低质量页面拉低站级评估。要做的不是单页修复,是站级清理。
中型站(1k-10k页):索引率70-85% 算正常
中型站的抓取预算开始紧张,深层页面可能被压在Discovered。正常的中型站索引率70到85% 算健康。Discovered状态可能占5到10%(队列里的正常排队),Crawled - currently not indexed占10到15%(质量边缘的页面),Duplicate系列占5到10%(参数URL与近似内容)。
中型站的诊断重点是内链架构与质量分级——把高商业价值页面用强内链推到队列前端,把低价值页面做剪枝或合并。
大站(10k-100k页):索引率50-70% 都正常
大站的抓取预算紧张到必须做战略分配,索引率自然降低。50到70% 都算正常范围。Discovered状态可能占10到20%(大量页面排在队列里)、Crawled - currently not indexed占15到25%(质量评估筛掉的)、Duplicate系列占10到20%(参数URL与多版本)。
大站的诊断重点是URL战略——哪些URL应该被索引、哪些应该被合并、哪些应该被noindex。盲目追求高索引率把所有URL都推进索引反而拉低整站质量信号。
电商或聚合超大站(100k+ 页):30-50% 不奇怪
电商和聚合站的URL爆炸(每个SKU多个变体URL、每个分类多个筛选URL、每个搜索词一个SERP拷贝URL),索引率30到50% 都不奇怪。这种规模的站点Google已经主动放弃索引大量低价值URL,这是健康状态不是问题。
电商大站的诊断重点是核心商业价值页面的索引率——产品详情页、热门分类页、品类hub页应该95%+ 索引率,其他长尾URL索引率低不重要。按价值分层看索引率比看总盘索引率有意义得多。
B2B SaaS 9个月索引率从42% 拉到91% 复盘
下面这段是2024年保哥带的一家B2B SaaS客户的真实复盘。起点客户全站4200页,GSC索引率只有42%(约1760页被索引),核心商业页(解决方案/客户案例/价格页)的索引率甚至只有58%。9个月后索引率拉到91%,核心商业页100% 索引。
起点诊断:状态分布严重畸形
第一周做了完整的GSC状态分布诊断。4200页里——Indexed 1760页(42%)、Discovered 580页(14%)、Crawled - currently not indexed 920页(22%)、Duplicate系列410页(10%)、Soft 404 280页(7%)、Blocked/noindex系列250页(5%)。
这个分布是典型的"中型站走偏"状态——Crawled - currently not indexed占比高达22%(中型站健康范围是10-15%)、Soft 404占比7%(健康范围是2-3%)、Discovered占比14%(健康范围是5-10%)。三个不健康状态加起来43%,几乎是被索引页面的同等数量。
三阶段策略:先治站再治结构再治单页
策略分三阶段。第一阶段(第1-3月)治站——把Soft 404的280页全部清掉(180页直接404、100页补实质内容)、Crawled - currently not indexed里明显低质量的320页做内容合并或删除、整站做E-E-A-T信号加强(每页加作者署名、原创数据点、客户案例引用)。这一阶段目标是把站级质量信号拉上去。
第二阶段(第4-6月)治结构——重做内链架构,把Discovered状态的580页通过hub页内链推到队列前端、Duplicate系列做canonical显式声明、所有核心商业页加Schema结构化数据。这一阶段目标是让算法决策路径上每一步都顺畅。
第三阶段(第7-9月)治单页——剩余Crawled - currently not indexed状态的600页逐页诊断,按价值分级——高价值的补内容升级、中价值的合并到同主题强页、低价值的接受noindex或删除。这一阶段是把已经过得去的状态再往上推一档。
9个月数据演变
9个月分阶段数据如下:
| 时点 | Indexed | Crawled NI | Discovered | 核心页索引率 |
|---|---|---|---|---|
| 第0月 | 42% | 22% | 14% | 58% |
| 第3月 | 58% | 16% | 11% | 74% |
| 第6月 | 76% | 10% | 6% | 92% |
| 第9月 | 91% | 4% | 2% | 100% |
9个月把整站索引率拉到91%,核心商业页100%。带来的自然搜索流量从月1.4万UV涨到月7.8万UV,5.6倍增长。这个增长不是单纯靠多发内容,是把已有内容里被算法卡住的部分激活了。
三个被低估的踩坑细节
第一个踩坑是Soft 404清理时直接404了60页SEO流量不大但客户高频访问的内部支持页。客户客服团队抱怨这些页面消失了。教训是SEO决策必须与产品/客服/销售对齐,404之前先核URL的非SEO用途,确认无人依赖再动。
第二个踩坑是第2个月加Schema时模板写错,导致全站1200页Schema验证失败但前端正常显示。GSC一直在报错但被运营忽略,第4个月才被发现修复。教训是Schema上线后必须配GSC报警监测,schema.org Validator加Rich Results Test都要纳入发布流程。
第三个踩坑是第7个月内链架构调整后Discovered状态确实降了,但同时Crawled - currently not indexed反而上升了8个百分点。原因是抓取队列里大量低质量页排到前面被抓了但质量不够进不了索引。教训是改内链架构前必须先做内容质量基线,否则只是把问题从一个状态推到另一个状态。
几个会让诊断误判的场景与上线前必验清单
把这套方法落地之前,提醒几类常见误判场景,避免做了错事自己还不知道。
误判场景一:把Discovered当Crawled处理
这是最常见的误判。看到大量URL未索引就盲目去改内容质量,但其实URL还没被抓取。改内容质量的动作对Discovered状态完全无效。修复方向先看状态再下手。
误判场景二:把Alternate当问题处理
Alternate page with proper canonical tag是预期行为,不是问题。但部分SEO同行看到GSC报告里大量Alternate状态就紧张,开始改canonical把Alternate推到索引。这种动作不必要还可能造成新的重复问题。
误判场景三:盲目追求100% 索引率
不是所有URL都应该被索引。低价值长尾URL、参数URL、过期内容URL本来就不该进索引。盲目追求100% 索引率会把低质量URL推进索引,反而拉低站级质量评估,得不偿失。
误判场景四:用robots.txt处理noindex场景
robots.txt拦截会让URL在SERP上以URL加描述的形式出现,对品牌词体验有负面影响。真不希望被收录的页面应该用noindex meta,不要用robots.txt替代。
误判场景五:忽视反向转换的算法信号
Indexed反向转Crawled - currently not indexed是非常重要的算法信号。看到这种反向转换批量出现要立即怀疑站级问题,不要等几周再看。
上线前必验清单
每次站点SEO改造或新页面上线前过一遍这份清单:
- 核心商业页(产品/解决方案/价格/案例)索引率是否95%+,未索引页是什么状态。
- Discovered状态URL的内链入口与发现路径是否健康(≤3级跳)。
- Crawled - currently not indexed状态URL的内容质量与E-E-A-T信号是否达标。
- Duplicate系列URL是否都有显式canonical声明,canonical指向是否正确。
- Soft 404状态URL是否补内容或返404,没有放任积累。
- robots.txt与noindex的边界是否清晰,没有混用。
- Schema结构化数据是否在schema.org Validator与Rich Results Test都通过。
常见问题解答
Discovered和Crawled currently not indexed有什么本质区别?
Discovered表示Google已发现这个URL但还没派Googlebot去抓取,问题出在抓取调度环节;Crawled表示Google已经抓回内容但判定不值得入库,问题出在质量评估环节。两者对应完全不同的修复动作——前者要解决抓取预算分配与发现路径,后者要解决内容质量与权威信号。混淆这两个会让修复方向完全错乱。
为什么我提交sitemap几周了页面还是Discovered状态?
Sitemap提交只是告知Google URL存在,并不直接触发抓取。Google是否抓取这个URL取决于站点整体的抓取预算分配、URL在内链架构中的位置、上级页面的抓取优先级。Sitemap是发现信号但不是优先级信号,要让Discovered转Crawled必须从内链架构与发现路径下手。
Duplicate, Google chose different canonical和我设的canonical不一样怎么办?
这是Google判定你设的canonical不可信,按它自己的去重算法选了另一个URL作为代表。原因通常是内容相似度极高、用户行为偏向Google选定的版本、或者内链与外链信号指向Google选定的版本。修复方法是要么内容差异化(让两个页面真的不同),要么主动统一到Google选的那个URL用301跳过去。
Soft 404状态怎么判定,明明页面打开是正常200啊?
Soft 404是Google用语义识别判定的,不看HTTP状态码。判定信号包括页面正文极少、出现not found类文本、跳转到错误页、内容与URL主题严重不符等。空电商分类页、缺货产品页、内容已删的占位页都常被判Soft 404。修复方法是补充实质内容或直接返回404状态码。
Alternate page with proper canonical tag算正常还是异常?
完全正常,是设计意图。当一个URL通过canonical指向另一个URL,Google把这个URL标记为Alternate而不索引它,索引的是canonical指向的那个。这是SEO的正确预期。需要关注的只是canonical指向是否正确——如果错了,就要修canonical指向。
Blocked by robots.txt状态会影响排名信号吗?
会。被robots.txt拦的页面Google不抓取,但仍可能基于外链信号收录URL不收录内容,在SERP上展示一行URL加一句robots.txt拦截说明。这会让品牌词搜索体验变差。如果是真的不希望被收录,应该用noindex meta标签而不是robots.txt拦。两者的语义完全不同。
索引率到底多少算正常?
看站点类型与规模。小站点100-500页索引率应该90%+,1k-10k中型站70-85% 算正常,10k以上大型站50-70% 都正常,电商或聚合大站30-50% 不奇怪。索引率本身不是KPI,索引率乘以平均页面质量分才是真实SEO资产。盲目追求高索引率把低质量页面塞进去反而拉低整站权威。
到这里8种状态的算法决策路径、状态间转换路径、跨规模站点画像、典型踩坑都拆清楚了。下次再打开GSC页面索引报告,应该能从每个状态名直接读出算法卡在哪一步、对应该做什么动作。这是给客户做索引诊断时最值钱的能力——不是看GSC报告,是读懂GSC报告背后的算法决策路径。剩下的就是按SOP执行的工程问题。
权威参考资料
本文标题:《Google索引覆盖状态机制:8种GSC未编入索引状态的算法决策路径》
本文链接:https://zhangwenbao.com/gsc-index-coverage-states-discovered-crawled-canonical-mechanism.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0