后台日志分析SEO怎么做:5000站爬虫伪造抓取预算实战拆解
本文目录
- GSC告诉你的,和日志告诉你的,到底有什么不一样?
- GSC是Google视角,日志是网站视角
- 日志特有的诊断维度
- 大站做SEO为什么必须做日志分析?
- 抓取预算分配的真实诊断
- 真伪爬虫鉴别避免CDN账单虚高
- 状态码异常的早期发现
- 内容池抓取覆盖率监控
- 真假Googlebot到底怎么鉴别?
- UA头不可信
- 反向DNS+正向DNS双向验证
- Google官方IP段JSON
- 假爬虫的几大类
- 怎么屏蔽假爬虫不伤真爬虫
- 日志能算出抓取预算的真实分配吗?
- 按URL pattern聚合的方法
- 抓取预算浪费的典型场景
- 抓取预算释放路径
- 诊断报告里要看的几个比例
- 独立URL覆盖率vs请求总数的差异
- 状态码按时段分布怎么看出问题端倪?
- 404突增 = 改版后链接断裂
- 5xx时段集中 = 服务端事故
- 304占比反映抓取效率
- 301链路深度问题
- 软404反推
- 哪些是孤岛页?哪些被冷落?
- 用日志做三集合差集
- 大站覆盖率60-70%是常态
- 把覆盖率拉到90%+的实战路径
- 抓取频率突增和突降代表什么?
- 突增的几类原因
- 突降的几类原因
- 告警阈值设置
- 实战案例:凌晨突增300%是SEO工具刷站
- 突降案例:robots.txt 一行配错致索引覆盖率跌40%
- 季节性流量波动vs真正异常的区分
- 日志分析工具该怎么选?
- 主流工具梯度对比
- 工具选型决策
- 日志数据保留多久才够?
- 不同时长能做什么
- 原始日志压缩+聚合长留
- 隐私合规处理
- 日志分析能解决什么GSC永远解决不了的问题?
- 实时性
- 单URL的完整抓取历史
- 假爬虫识别
- 抓取预算的真实分配
- 状态码的时段分布
- 日志分析怎么和其他SEO工具联动?
- 日志+GSC=完整Google视角
- 日志+Crawler=想抓vs真抓
- 日志+内链工具=权重vs抓取关系
- 日志+Analytics=流量与抓取的关系
- 日志分析容易踩的几个坑
- 把日志分析嵌入SEO工作流
- 常见问题解答
- 问:中小站需要做日志分析吗?
- 问:假Googlebot占比多高算异常?
- 问:日志能不能直接看出某个URL在掉排名?
- 问:云服务的日志怎么拉到本地分析?
- 问:Nginx日志默认格式够用吗?
- 问:日志分析多久做一次合适?
- 问:如何判断日志里的Googlebot是真的?
- 问:日志数据量太大怎么管理存储?
- 权威参考资料
摘要:服务器日志是网站对Googlebot抓取行为最真实的账本,能告诉你GSC永远说不清的几件事:哪些Googlebot UA是假的、抓取预算实际花在了哪几个目录、404和5xx在哪个时段集中爆发、哪些页面是孤儿、哪些被Google抓但每次都换成304。本文按真假爬虫鉴别、抓取预算诊断、状态码时段分布、孤岛页发现、突增告警五条主线,配电商DTC、媒体站、B2B SaaS三类客户日志诊断的真实片段,把日志分析从“大站才用得着”重新定位成中大型站点做SEO的标配能力。
GSC告诉你的,和日志告诉你的,到底有什么不一样?
保哥这些年带客户做技术SEO诊断时,最常被问的一个问题是:GSC的索引报告都看了、Google Analytics也接好了,为什么还看不到问题?答案几乎每次都一样:你看的是Google和用户两端,中间那一段Googlebot到底怎么访问你这个站的,两边都没告诉你。
很多团队做SEO主要看两个东西:GSC和Google Analytics。这两个工具各有各的局限——GSC是Google站在外面看你的视角,GA4是用户落地后的视角。中间那一段,也就是“Googlebot到底是怎么访问我这个站的”,两个工具都不直接告诉你。
这一段恰好是技术SEO诊断里最关键的一段。Googlebot每天什么时间来、抓了哪些URL、每个URL拿到了什么状态码、字节数是多少、响应时间多久、来自哪个IP段、UA字符串是什么——这些都只能从服务器日志里读。这就是日志分析作为SEO诊断工具的独特价值。
GSC是Google视角,日志是网站视角
GSC的核心数据维度是Google整理后给你看的:曝光、点击、排名、索引覆盖率、特定状态码分类的URL列表。这些数据有两个固有特征:经过Google的判断滤镜处理过、有2-3天的延迟。这意味着GSC告诉你的是“Google认为发生了什么”,不是“实际发生了什么”。
日志正相反,它告诉你的是网站这一端收到的实际请求与发出的实际响应,没有判断滤镜、没有延迟。两个视角对照着看,才能找到真问题。比如GSC说一批URL是“已抓取未编入”,日志能告诉你Googlebot最后一次抓这批URL是几天前、那时候返回的是什么状态码、字节数是不是太小(暗示是空页面)、响应时间是不是过长(暗示服务端有问题)。
日志特有的诊断维度
相比GSC,日志能给你这些独有的维度:
- 完整的UA字符串(不只是Googlebot的简化标签)
- 源IP地址(鉴别真伪爬虫的关键)
- 精确到秒的时间戳(看抓取节奏)
- referer字段(看Googlebot怎么找到这个URL)
- 响应字节数(识别空内容与软404)
- 响应时间(慢响应是不是导致抓取频次降低)
- 请求方法(GET vs HEAD,不同行为)
- 每个URL的完整抓取历史(GSC只给摘要)
大站做SEO为什么必须做日志分析?
这个问题保哥每接一个新客户都会被问一次。答案不在某一个具体功能,而在于规模到了一定量级后,没有日志分析做SEO就是盲人摸象。
抓取预算分配的真实诊断
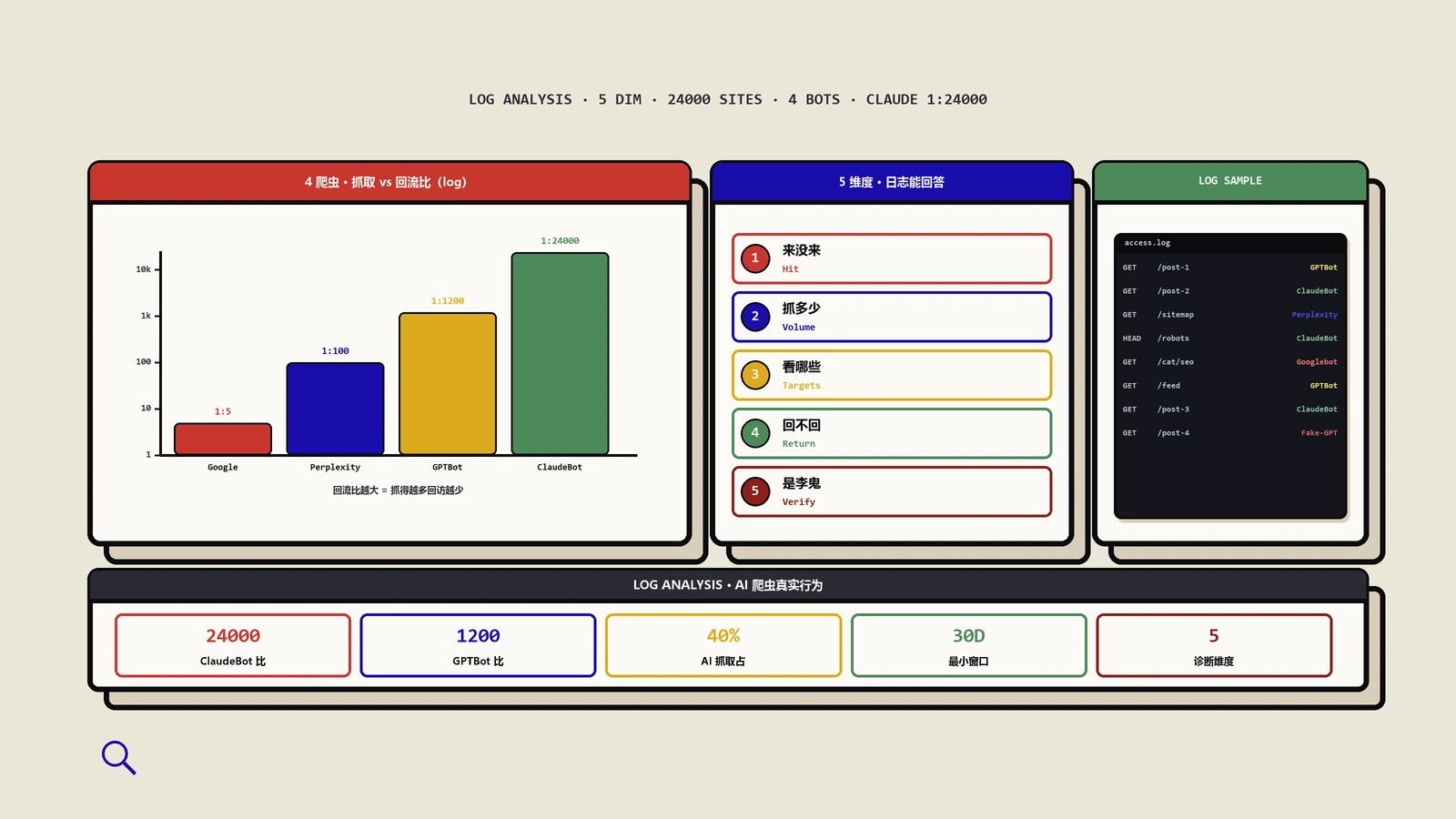
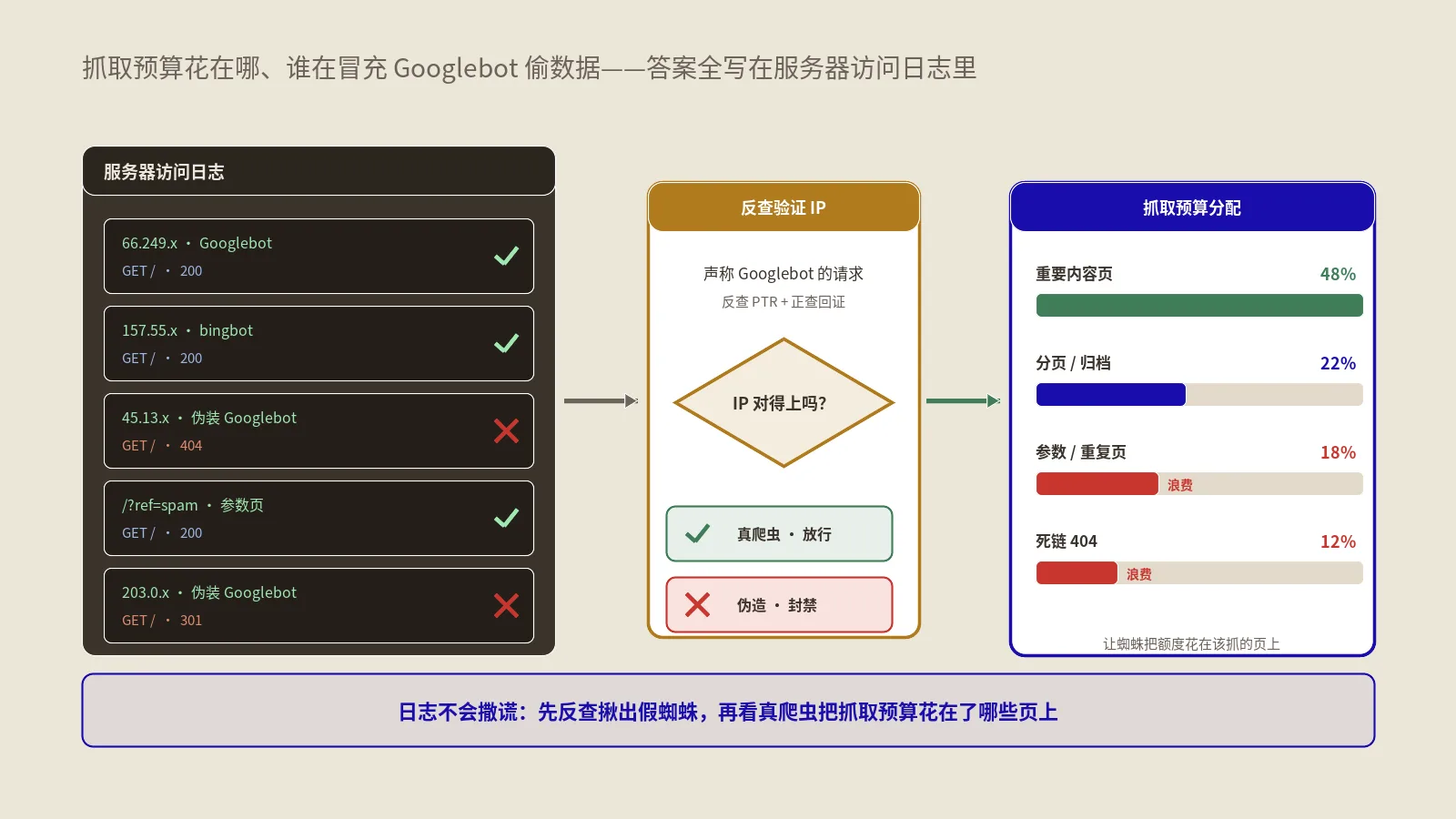
Googlebot不会无限抓你的站,每天能抓的URL数有一个动态预算。这个预算实际落到了哪些目录、哪些URL pattern、哪些参数组合上,GSC不告诉你。但日志能精确算出来:把Googlebot请求按URL pattern聚合后,每个pattern占预算的百分比一目了然。
有个客户是百万级商品的跨境家居站,做日志诊断之前他们以为Googlebot主要在抓产品页和分类页。日志一拉发现实际47%的预算花在了带排序、筛选、追踪参数的URL变体上——这些URL几乎全部是canonical到主URL的近重复,本该不被抓但因为内链结构没收敛全被Googlebot发现了。把这47%压下来释放出的预算,让新产品的发现速度从平均8天降到48小时内。
真伪爬虫鉴别避免CDN账单虚高
UA头里写着Googlebot不代表真的是Google来抓。市场上有大量SEO工具、竞品监控、内容采集爬虫会伪装成Googlebot UA来避开常规屏蔽。这些假Googlebot会消耗服务器算力、CDN流量、抓取频次配额,但不会带来任何SEO价值。
保哥诊断过一个出海B2B工业设备站,他们CDN月账单从800美金涨到3200美金。客户以为是流量自然增长,开心了一阵。日志拉出来才发现,所谓“流量增长”里有2100美金的成本是某个韩国IP段冒充Googlebot批量爬产品规格,目的是给他们的同行做产品对比表。屏蔽这个IP段后CDN账单立刻回到正常水位。
状态码异常的早期发现
GSC的索引报告告诉你的状态码分布是聚合数据,看不出时段。日志可以按小时切片看Googlebot抓到404、5xx的时段分布,能在问题刚发生时就发现,不用等GSC两三天后才提醒。
内容池抓取覆盖率监控
有了日志,可以算出过去30天内Googlebot访问过的URL集合,再和sitemap、内链发现集合做对比,差集就是孤岛页或准孤岛页。这个监控GSC虽然部分提供但不够细,日志能精确到URL级。
真假Googlebot到底怎么鉴别?
这是日志分析里最实用的一个具体技能。绝大部分技术SEO初学者不知道,结果就是把假爬虫数据当真信号在解读,分析全错。
UA头不可信
任何脚本都可以在HTTP请求里把User-Agent设成 Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) 这样的字符串。这是公开字符串,没有任何防伪能力。光看UA判断爬虫身份,等于光看名字判断身份证。
反向DNS+正向DNS双向验证
Google官方给出的鉴别真Googlebot的方法是两步DNS验证:
- 拿日志里这个IP做反向DNS查询(PTR记录),结果应该是以
.googlebot.com或.google.com结尾的主机名 - 对这个主机名再做一次正向DNS查询(A记录),看返回的IP是不是和日志里的原IP一致
两步都通过才算真Googlebot。任何一步失败都是假冒。这个方法对Bingbot、Yandexbot等其他主流搜索引擎也适用,每家都有自己对应的官方域名后缀。
Google官方IP段JSON
2021年之后Google开始公开Googlebot的IP范围JSON清单(developers.google.com/search/apis/ipranges/googlebot.json),每周更新。可以把这个JSON拉下来做白名单校验,比纯DNS反查更快。但JSON更新有延迟,最稳的方式还是DNS反查加IP白名单结合。
假爬虫的几大类
实战日志里假Googlebot主要有这几类来源:
- SEO工具爬虫(Ahrefs、Semrush、Moz、Majestic等的内容爬虫)
- 竞品监控(专门盯一两个对手的定向爬虫)
- 内容采集(把别人内容批量爬走做内容站的)
- 价格监控(电商行业特别多)
- 恶意爬取(探测漏洞、批量注册、刷接口)
- 搜索引擎API聚合(小搜索引擎复用大爬虫数据)
怎么屏蔽假爬虫不伤真爬虫
识别出假爬虫之后,处置有几种梯度:
- 软处置:用robots.txt明示禁止特定UA(但只对自觉的爬虫有效)
- 中处置:CDN层按IP段或UA字符串限速
- 硬处置:CDN层按IP段或UA字符串直接403
- 极端处置:把可疑爬虫导向假数据页面(蜜罐策略)
关键是不要影响真Googlebot。处置前必须用反向DNS+正向DNS验证过该IP确实不是真爬虫,否则误屏蔽真Googlebot会导致索引覆盖率下跌。AI爬虫到底在抓你什么?拿代码逆向出它的真实偏好里有AI爬虫家族的UA白名单和分类策略,可以联合做。
日志能算出抓取预算的真实分配吗?
能,而且这是日志分析最高价值的应用场景。GSC的抓取统计报告只告诉你Googlebot每天抓多少个URL、下载多少字节、平均响应时间。但每个URL pattern占多少比例、哪些目录在浪费预算、哪些目录被冷落,GSC不告诉你。
按URL pattern聚合的方法
真正的抓取预算诊断起点是把所有Googlebot请求按URL pattern聚合。pattern不是单个URL,是参数化后的目录结构。比如:
/product/{id}单品详情页/category/{slug}分类页/category/{slug}?sort=*&filter=*分类带排序筛选/tag/{tag}标签页/search?q=*站内搜索结果页/blog/{year}/{month}/{slug}博客文章
每个pattern算两个数:请求总数(占抓取预算的%)、独立URL数(pattern下被抓的URL变体数量)。两个数对比能立刻看出问题。
抓取预算浪费的典型场景
日志诊断里最常见的预算浪费有这几类:
- 分面/筛选/排序URL变体抓爆(参数组合爆炸)
- 站内搜索结果页被抓(用户搜索词触发的URL也被Googlebot爬)
- 追踪参数(UTM等)让同URL多变体被独立抓取
- 软404页(200状态码但实际找不到内容)反复被抓
- 重定向链多跳被全链抓一遍
- 分页深度过深,深层分页页被反复抓
- JS/CSS/图片在不应该抓的时候被抓(这些不是核心SEO资源时浪费)
抓取预算释放路径
找出浪费场景后,释放预算的处法:
- 分面爆炸 → 源头不可爬(链接里加 rel=nofollow 或PRG)+ canonical收编已索引的
- 站内搜索 → robots.txt禁
/search+ noindex - 追踪参数 → GSC参数处理工具(已废弃)+ canonical指向无参版本
- 软404 → 改返410或noindex
- 重定向链 → 拉平到1跳
- 分页深度 → 加canonical到第一页或专题页
诊断报告里要看的几个比例
抓取预算诊断报告里要常态化关注的几个比例数:
- Googlebot请求中状态码200的占比(核心抓取的健康度)
- 304占比(条件请求支持是否到位)
- 3xx占比(重定向链的隐性消耗)
- 4xx占比(无效URL的预算浪费)
- 5xx占比(服务端稳定性)
- 独立URL覆盖比例(30天内抓到的独立URL数÷sitemap总URL数)
- HTML vs 静态资源比例(图片CSS JS被抓的相对量)
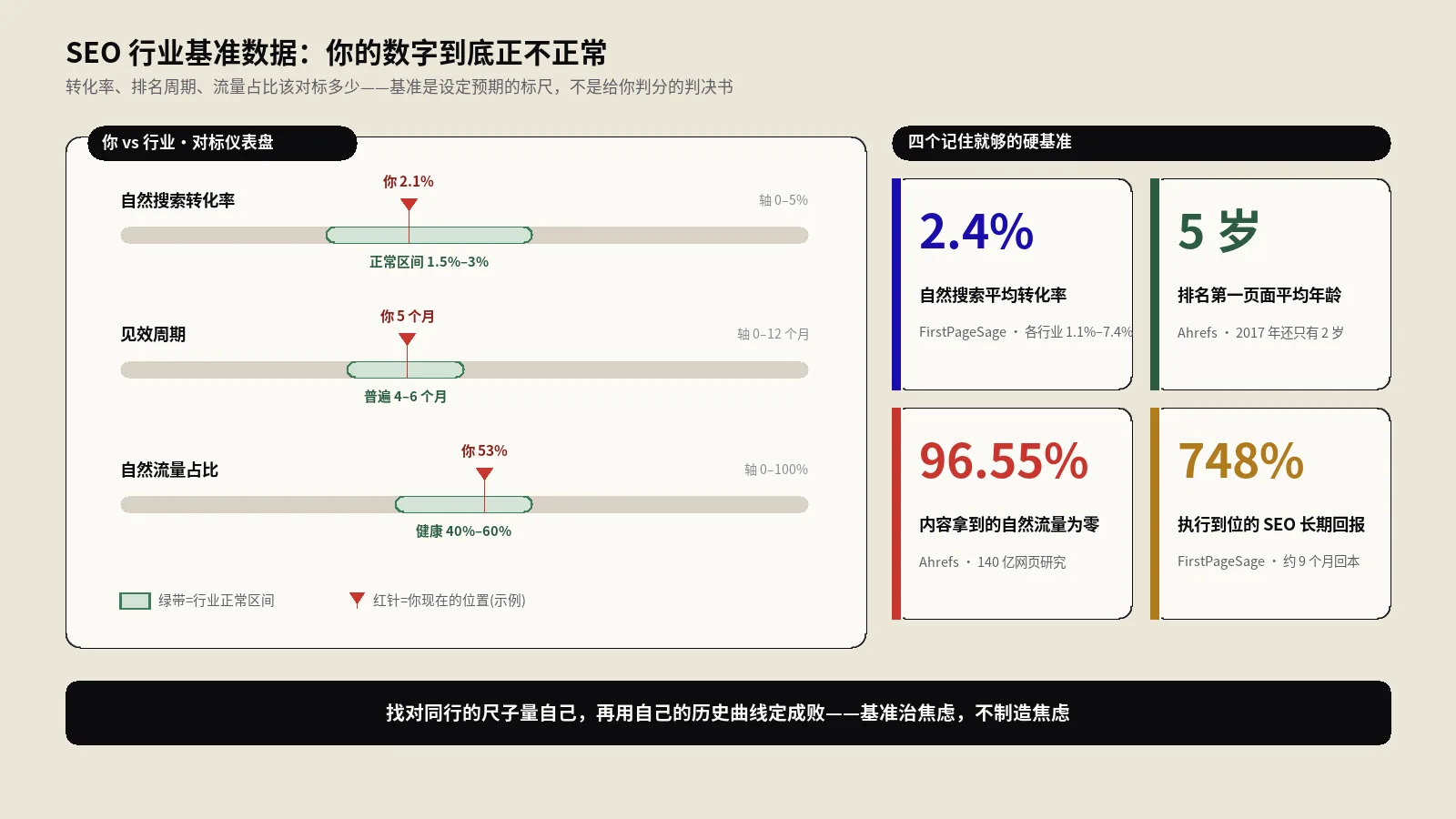
每个数都有自己的健康区间。200占比应该在70%-85%(剩余给304等正常状态码留位置);304在40%-60%;3xx尽量低于5%;4xx低于3%;5xx低于1%。任一数偏离健康区间都是诊断信号。
独立URL覆盖率vs请求总数的差异
抓取预算里有个常被忽视的细节:请求总数和独立URL数是两个不同的指标。一个URL pattern一周内可能被Googlebot抓100万次,但只覆盖了5000个独立URL(每个URL平均被抓200次)。这种“高频低覆盖”模式说明Googlebot在反复抓同一批热URL,对长尾URL的发现不足。
反过来,“低频高覆盖”模式(一周200万次请求覆盖180万独立URL,平均每个URL只抓1.1次)则说明Googlebot在大规模扫站、但每个URL的抓取频次都不够,新内容更新可能不及时被索引。两种模式对应的优化策略完全不同。
状态码层面的具体处置策略,可参考HTTP状态码SEO图谱:301、302、410怎么用别踩雷里的状态码全图谱与决策矩阵,配合日志诊断使用最有效。
状态码按时段分布怎么看出问题端倪?
状态码不能只看聚合分布,还要看时段分布。同样是5%的404占比,如果是均匀分布那是稳态问题;如果是某天突增到20%那是事故。时段维度是日志独有的优势。
404突增 = 改版后链接断裂
404突然飙升的最常见原因是改版没做完整的301映射,旧URL大量404。这种情况在日志里会有明显的时间起点(改版上线的那一刻),按目录聚合能看出来是哪一批URL断了。
5xx时段集中 = 服务端事故
5xx一般不会均匀分布,往往集中在某几个时段——服务器负载高峰、定时任务窗口、数据库慢查询时段。日志按小时切片看5xx占比,能精确定位事故时间,配合监控日志能找到根因。
有个出海3C配件DTC站,他们的5xx长期稳定在2%。一段时间后突然涨到8%,但运维监控没报警。日志按小时一切片,发现5xx集中在凌晨3-5点,对应着他们新部署的全量库存同步任务,数据库被锁导致网页请求超时。任务移到凌晨2点之前完成后,5xx回到2%。
304占比反映抓取效率
304响应表示页面没变化,Googlebot跳过下载字节,是抓取预算优化里最值钱的状态码。健康的大站304占Googlebot请求的40%-60%是正常水位。低于20%意味着条件请求支持有问题,可能是Last-Modified和ETag没正确实现。
301链路深度问题
日志能看出来Googlebot跟随重定向的实际行为。如果一个URL的最终目标是B,但日志显示Googlebot先访问A,A返301到X,X返301到Y,Y返301到B,那就是4跳重定向链,浪费预算。把整个链路拉平到1跳是该做的工程。
软404反推
日志里的字节数字段能用来反推软404。如果一类URL的Googlebot响应字节数明显小于同类正常页(比如平均10KB但这类只有1.5KB),高概率是软404——返回了200但body几乎为空。
哪些是孤岛页?哪些被冷落?
孤岛页是只在sitemap或外链里存在但站内没有任何内链指向的页面。准孤岛页是有内链指向但极少,导致Googlebot发现频率很低。这两类页面是大站常见的SEO损耗源,但只能用日志诊断。
用日志做三集合差集
这是诊断孤岛页的标准方法:
- 集合A:sitemap.xml里列出的所有URL
- 集合B:站内爬虫(如Screaming Frog)从主页爬到的URL(即内链可达)
- 集合C:过去30天日志里Googlebot真实抓过的URL
三个集合做交叉对比:
- A有B没有:孤岛页(在sitemap里但没内链)
- B有A没有:sitemap漏录
- A有C没有:Googlebot没抓的URL(可能因为低优先级或孤儿)
- C有A、B都没有:意外被Googlebot抓到的URL(可能是历史外链或参数变体)
大站覆盖率60-70%是常态
百万URL量级的站,Googlebot 30天内能覆盖60-70%的URL是常态。低于50%说明内链结构有大问题;高于85%说明站点结构非常健康。
把覆盖率拉到90%+的实战路径
提升抓取覆盖率的常见路径:
- 修内链结构:增加孤岛页的入站内链
- 分类页加分页:让深层URL有更短的发现路径
- sitemap分片:按时间或类型拆sitemap,标lastmod新鲜度
- 优先级标注:sitemap里的priority字段配合数据
- 低优先页砍掉:那些一直没人搜也不重要的页,直接410
抓取频率突增和突降代表什么?
抓取频率的时间序列变化是非常敏感的领先指标。突变往往对应着某个具体事件,但需要诊断者识别。
突增的几类原因
Googlebot抓取频率突然上涨,可能的原因:
- 大量新内容发布触发Googlebot加速发现
- Google算法更新后对部分站点重新评估
- 站点结构变更(改版)让Googlebot重新爬一遍
- 外链增加让Googlebot发现新入口
- 假爬虫攻击伪装成Googlebot(这是最常见的假突增)
突降的几类原因
抓取频率突然下跌的可能原因:
- robots.txt配置错误把Googlebot挡了
- 服务器响应变慢(Googlebot自动降抓取频率)
- 5xx过多(Googlebot认为站点不稳定)
- 大量404让Googlebot失去信任
- 算法降权前兆(Google提前减少投入)
- HCU或核心更新后的站点重评
告警阈值设置
怎么算“突增”和“突降”?常用方法是基线+标准差:
- 取过去14天的日均抓取量算平均值μ和标准差σ
- 今天的抓取量 > μ + 2σ = 黄色告警
- 今天的抓取量 > μ + 3σ = 橙色告警
- 今天的抓取量 < μ - 2σ = 黄色告警
- 今天的抓取量 < μ - 3σ = 红色告警,立刻人工介入
不要用绝对值阈值(比如“抓取量低于1万次就告警”),因为不同站点的基线天差地远。统计基线告警泛化能力强得多。
实战案例:凌晨突增300%是SEO工具刷站
某客户的告警系统报“凌晨2点Googlebot请求突增300%”。运维和开发都没头绪。日志拉出来按IP段聚合,发现90%的突增请求来自一个韩国IP段,UA是Googlebot但反向DNS不通。屏蔽这个IP段后告警消失,且发现这家客户每周三凌晨都会被这个IP段刷一次。后来定位是某SEO工具的定时爬虫。
突降案例:robots.txt 一行配错致索引覆盖率跌40%
另一类高频事故是robots.txt误配。有个媒体站做内容平台升级,新加了一行 Disallow: /article/ 想屏蔽某个废弃测试目录,但所有正式文章URL路径就是/article/{id}。这一行上线后两小时内Googlebot抓取频次断崖下跌,但运维没发现,因为站点自身访问一切正常。
3天后GSC才报警,再过一周整站索引覆盖率从92%跌到53%。日志按小时切片倒查,发现Googlebot抓取量在配置上线那一刻精确归零,凡是/article/路径下的请求全被robots.txt拦截。修复robots.txt + 主动提交sitemap,索引覆盖率花了6周才回到原位。这一类事故只能靠日志按小时实时告警发现,等GSC报警就晚了。
季节性流量波动vs真正异常的区分
不是所有抓取频率变化都是异常。电商站在大促前后、媒体站在突发新闻时、B2B站在采购季都会有自然的Googlebot抓取波动。基线告警必须按周/季度分别建立基线,避免把正常季节性波动误判为异常。
常用的做法是建分层基线:日内基线(同一周几同一时段对比)、周基线(过去4周同一周几)、季基线(过去13周同期)。三层都偏离才算真异常。这套机制比单层标准差告警更稳,能挡住大多数误报。
日志分析工具该怎么选?
市场上的日志分析工具梯度很全,从免费的命令行到企业级SaaS都有。选错工具往往导致投入与产出严重失衡。
主流工具梯度对比
| 工具 | 适合场景 | 成本 | 团队技能要求 | 缺点 |
|---|---|---|---|---|
| awk/grep/Python脚本 | 临时诊断、定制分析 | 免费 | 命令行+脚本 | 可视化弱、长期维护重 |
| Screaming Frog Log File Analyser | 中小站、单机分析 | 低(≈£239/年) | SEO团队即可 | 日志量上限、单机性能 |
| 自建ELK Stack | 大站、定制需求强 | 中(基础设施) | 需要DevOps支持 | 维护重、查询语言陡 |
| OnCrawl | 中大站、爬虫数据联动 | 中高 | SEO团队即可 | 定制弱、贵 |
| Botify | 大站、企业级 | 极高(万美金级/年) | SEO+数据团队 | 价格门槛 |
| Splunk | 已有Splunk企业的SEO模块 | 极高 | 需要Splunk经验 | 价格门槛、SEO视角不专 |
| AWS Athena/BigQuery | 云原生、SQL查询 | 按查询计费 | SQL熟练 | 需自建报表层 |
工具选型决策
简单决策:
- 10万URL以下,团队没专人 → Screaming Frog Log File Analyser
- 10-100万URL,有DevOps支持 → ELK或Athena
- 100万URL以上 → OnCrawl或Botify
- 有现成大数据栈 → 复用Splunk或Athena
- 临时诊断 → awk/Python脚本足够
日志数据保留多久才够?
日志存储是成本话题,但保留策略直接影响能做哪些分析。
不同时长能做什么
- 滚动30天:基本诊断、状态码分布、抓取频率基线
- 90天:季度趋势、改版后效果对比、季节性发现
- 365天:年度同比、长周期诊断、算法更新影响
- 2年以上:长期资产价值评估、外链/内链长期效果
原始日志压缩+聚合长留
实战里的存储策略:
- 原始日志:保留7-30天,gzip压缩,便于细查
- 每日聚合:按URL pattern+status_code+小时聚合count和总bytes,留12个月以上
- 每周快照:核心指标的周报,长期保留
- 异常事件存档:突增突降、事故时段的原始日志单独存档
隐私合规处理
日志含IP地址等可识别信息,按GDPR、CCPA要做哈希或脱敏。常见做法是入库前对IP做单向哈希,保留分析能力(仍能聚合同一IP的请求)但不再可还原。SEO分析里很少需要原始IP,哈希后完全够用。
日志分析能解决什么GSC永远解决不了的问题?
这是评估日志分析投入产出比的核心问题。如果GSC能解决,确实不需要花时间做日志。但实际有几类问题GSC天然解决不了。
实时性
GSC数据有2-3天延迟。日志是实时的。事故诊断、改版后立即验证、AB测试期间监控,都需要实时性,GSC做不到。
单URL的完整抓取历史
GSC只告诉你URL的当前状态。日志能告诉你过去N个月每次Googlebot访问这个URL的精确时间、状态码、字节数、响应时间。这对诊断单URL的SEO问题极其关键。
假爬虫识别
GSC不告诉你你的站被哪些假爬虫访问。日志能精确识别。这关乎服务器成本和CDN账单。
抓取预算的真实分配
GSC的抓取统计是聚合数据,看不出每个URL pattern的具体占比。日志能精确到目录、参数组合级。这对大站抓取预算优化是必需的。
状态码的时段分布
GSC的状态码是快照分布,看不出时段。日志能按小时切片,对事故诊断和发版后监控不可替代。
日志分析怎么和其他SEO工具联动?
日志分析的价值在和其他工具联动时被放大。单独看日志只看到一面,多源联动才能拼出完整画像。
日志+GSC=完整Google视角
日志告诉你Googlebot实际抓了什么,GSC告诉你Google最终决定收录展示什么。两边对照能看出“抓了但没收”的URL、“GSC说找不到但日志里Googlebot确实抓过”的矛盾、“GSC报告状态码”vs“日志真实状态码”的差异。这些差异往往就是诊断起点。
日志+Crawler=想抓vs真抓
SF或Botify的爬虫能告诉你“你的内链结构允许哪些URL被抓”。日志告诉你“Googlebot真实抓了哪些URL”。两者差异:内链可达但日志里没有的URL=Googlebot没去抓(可能是低优先级);日志里有但内链不可达的URL=外链或参数变体进入。
日志+内链工具=权重vs抓取关系
内链分析工具(比如自建的PageRank模拟器)告诉你每个URL的内链权重。日志告诉你Googlebot的实际抓取频次。两者相关性高=内链权重正常传导;相关性低=内链结构有问题,权重没引导到该被抓的页面上。
日志+Analytics=流量与抓取的关系
Analytics告诉你哪些页面有真实用户流量。日志告诉你哪些页面被Googlebot频繁抓取。两者乘积矩阵能找到四种页面类型:高抓高流(健康)、高抓低流(抓了但没排名)、低抓高流(结构问题但用户在找)、低抓低流(候选删除)。指标层口径与SEO数据治理的细节可参考SEO数据老是对不上?建一套可信指标层和单一口径,把日志数据接进指标层会让多源联动更稳。
日志分析容易踩的几个坑
实战里日志分析新手最常踩的几个坑:
- 把所有Googlebot UA都当真Googlebot(不做DNS验证)
- 按聚合状态码分析(不切时段)
- 忽略响应字节数字段(错失软404识别机会)
- 不按URL pattern聚合(看不出预算分配)
- 用相对值阈值告警(基线不稳)
- 不存原始日志(事后没法细查)
- 日志和GSC数据不对照(单源分析容易跑偏)
- 把Bingbot、Yandexbot当无关数据扔掉(多引擎诊断价值丢了)
避坑的最小动作:建立标准的Googlebot反向DNS验证脚本、每周自动跑URL pattern聚合报表、原始日志压缩存7-30天、聚合数据存12个月以上、按周建告警基线、关键事件单独存档。这些动作做对一次之后,长期维护成本不高,但能让日志分析真正持续产生SEO价值。
把日志分析嵌入SEO工作流
日志分析做完一次只是开始,真正的价值在嵌入日常SEO工作流。每周自动跑报表后,把异常摘要发到团队群里、把状态码异常单独邮件给运维、把孤岛页列表发给内容编辑。让日志数据成为团队多角色的共享语言,而不是技术SEO一个人的独门绝技。
robots.txt层面的协同也是关键。日志诊断出预算浪费场景后,处置往往要靠robots.txt落地,robots.txt误封整站消失?协议机制完全指南里有协议机制全图,配合日志分析才能精准下手而不误伤。日志、robots、状态码、内链结构是技术SEO的四件套,缺哪一件诊断都不完整。
常见问题解答
问:中小站需要做日志分析吗?
几万URL以下的站,GSC配合每月一次轻量日志抽样就够用,不必投入Botify这类大站工具。但真假爬虫鉴别即便小站也建议做一次,免得CDN带宽和服务器算力被假爬虫吃掉。
问:假Googlebot占比多高算异常?
正常情况假Googlebot占总Googlebot UA请求的15%-25%是常态,主要来源是SEO工具和竞品监控。超过40%说明你的站被特定爬虫盯上,需要主动屏蔽。
问:日志能不能直接看出某个URL在掉排名?
不能直接看排名,但能看到掉排名前的征兆:抓取频次突降、304比例升高(内容被判定不需要更新)、状态码异常。日志是排名变动的领先指标,不是排名本身。
问:云服务的日志怎么拉到本地分析?
AWS的S3日志和ALB日志可以通过Athena直接SQL查询,阿里云日志服务可以用LogQL类似语法。建议设置每日定时把过滤后的Googlebot请求导出到独立存储,原始全量日志压缩归档。
问:Nginx日志默认格式够用吗?
默认combined格式只有基础字段,建议加上request_time、upstream_response_time、bytes_sent等响应性能字段,便于诊断慢响应是否影响抓取。注意要按GDPR对IP做哈希处理。
问:日志分析多久做一次合适?
大站每周自动跑一次报表+月度深度诊断;中型站每月一次深度诊断;事故/改版/算法更新后立即做。不要等GSC报警才看,GSC有2-3天延迟。
问:如何判断日志里的Googlebot是真的?
做反向DNS查询拿到主机名(应该以.googlebot.com或.google.com结尾),再对该主机名做正向DNS查询确认回到原IP。两步都通过才算真Googlebot,单看UA字段不可信。
问:日志数据量太大怎么管理存储?
原始日志压缩存7-30天滚动,按日聚合数据(每URL pattern每天每status_code的count和总bytes)长期存12个月。这样既能保留诊断细节又控制存储成本。
权威参考资料
本文标题:《后台日志分析SEO怎么做:5000站爬虫伪造抓取预算实战拆解》
本文链接:https://zhangwenbao.com/server-log-file-analysis-seo-crawl-budget-bot-verification.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0