图片SEO新机制是什么?Vision AI读图与Lens排名
本文目录
- Vision AI是怎么读图的?
- Vision AI在每张图上跑哪些任务?
- Vision AI识别准不准?
- 识别结果如何进入排名?
- 图像嵌入向量空间是怎么工作的?
- 传统五信号今天还剩多少分量?
- alt属性:从描述到消歧
- 文件名:被严重低估的早期信号
- title属性:今天已基本无用
- 周围文字:仍然是最强单点信号
- EXIF信息:场景化决策
- Vision AI与传统信号怎么职责切分?
- 两套信号的职责对照表
- 落地清单:一张图的完整SEO化
- Image Pack为什么不出?
- Image Pack的触发条件
- 站点级图片信任门槛
- 独家原创vs素材库重复
- Image Pack vs Discover图片流
- Google Lens排名靠什么?
- Lens的反向匹配机制
- 实物拍照角度的现实
- Lens流量的转化特点
- 把Lens引流当作产品洞察反向利用
- 多平台视觉搜索的差异是什么?
- 六平台视觉搜索对照矩阵
- 多平台视觉搜索关联
- 图片sitemap和image schema怎么用?
- 图片sitemap的字段与规模
- ImageObject Schema怎么挂
- licensable图片的合规价值
- 图片性能和Core Web Vitals怎么协同?
- LCP图片的选择标准
- srcset+sizes的常见错配
- 性能和Image Pack的双向影响
- AI爬虫抓图与图片版权风险
- AI训练vs AI检索的差异
- robots.txt对AI爬虫的细粒度控制
- AI检索抽取你的图怎么追踪?
- 图片侵权与防御
- 北美厨具DTC品牌图片SEO改造的完整复盘
- 常见问题解答
- alt文字写得多详细Google就给我排名?
- Vision AI能读图,传统五信号还要不要做?
- 为什么我图片很多但Image Pack就是不出?
- Google Lens和谷歌以图搜图是同一回事吗?
- 图片用WebP还是AVIF?JPEG还能不能用?
- AI爬虫抓我图片去训练会损害我吗?
- EXIF信息要不要保留?要不要去?
- 权威参考资料
摘要:Image Pack出不出来、Lens拍照搜不搜得到你,跟你alt写多好、WebP有没有上几乎不挂钩。Google现在用Vision AI模型直接看图,传统五信号只剩补充识别盲区的填空作用;真正决定排名的是Vision AI识别+上下文意图+独家原创+站点信任的合力。这篇拆开新机制:Vision AI在每张图上跑的八项任务、传统五信号今天的权重重排、Image Pack的查询触发与站点信任门槛、Google Lens实物拍照怎么打中、六大平台视觉搜索差异矩阵、AI爬虫训练vs检索的分别处置。北美厨具DTC品牌做完Vision AI对齐+实物场景图补全,Image Pack曝光半年提升约67%、Lens月引流从100爬到3200——杠杆从来不在alt那一句话。
保哥前两个月接了一个北美户外装备DTC品牌的咨询,客户问题听起来很简单:站上有1万多张产品图,alt写得很认真,文件名也都规范,WebP和懒加载早就上线了,但Google Image Pack(图片包)在大词上几乎不出,Google Lens用产品实物拍照搜过来的流量更是零。我把站点架构和近6个月的图片在搜索表现一起拉出来看,结论让客户有点意外:图片SEO在Vision AI时代,做alt和WebP只是入门门票,真正决定能不能拿到Image Pack和Lens流量的是另外几组信号,这几组信号大多数指南里根本没提。
这一篇是把今天的图片SEO机制完整说清楚。如果你只看过那篇alt+WebP+懒加载实战入门,那只是图片SEO最基础的一层;过去三年Google视觉理解能力的飞跃,加上Lens、Pinterest Lens、Amazon Style Search、TikTok视觉搜索等多平台视觉搜索产品爆发,把图片SEO的回报路径整个改写了。今天这一篇负责讲机制,那篇负责讲基础实操,两篇配套看可以构成完整知识地基。
Vision AI是怎么读图的?
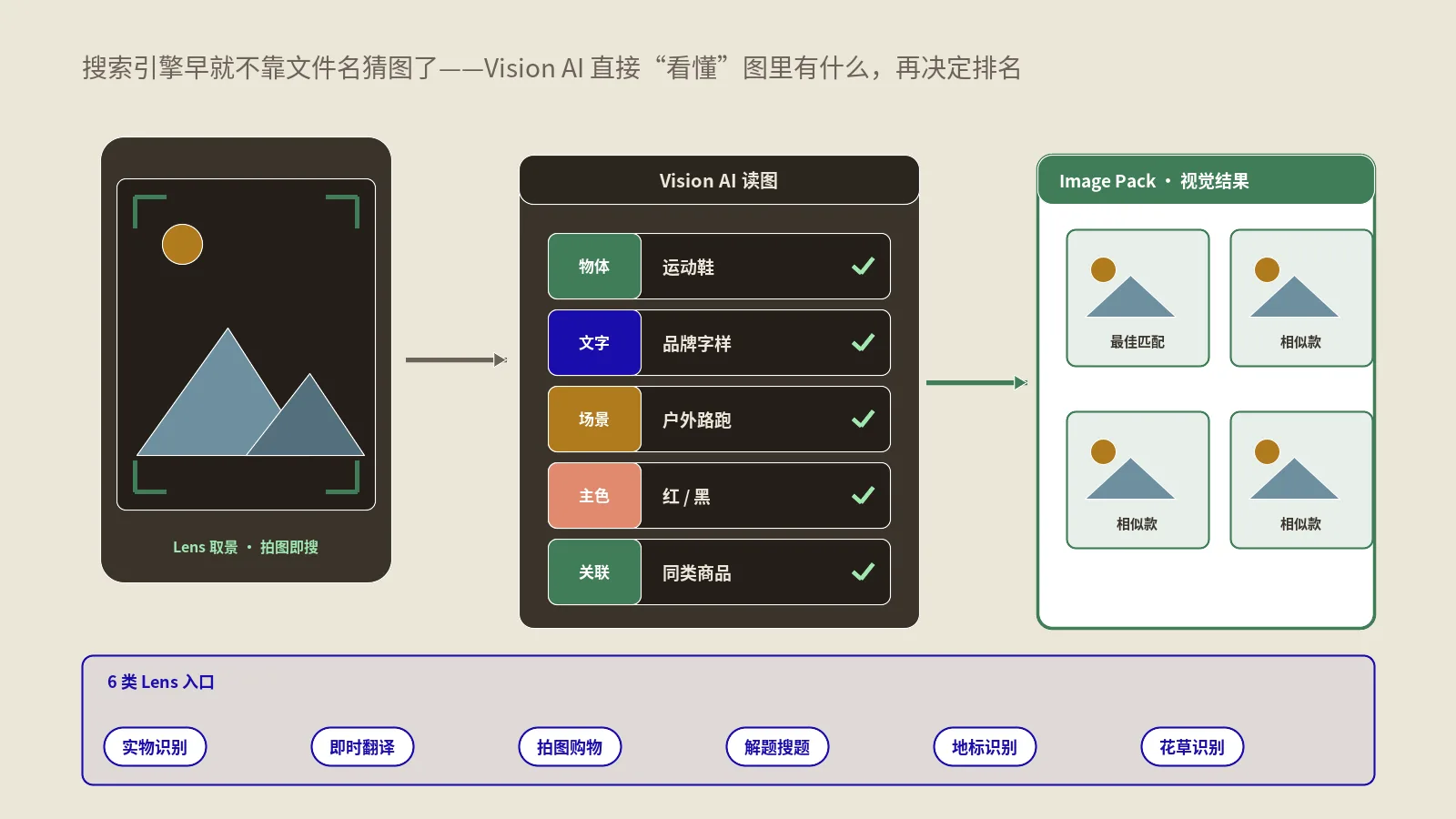
理解今天的图片SEO,必须先理解Google的Vision AI到底在你的图片上做了什么。这不是一两个识别模型,是一组并行运行的视觉理解任务,每一项都会产生独立的语义信号进入Google的图像索引。
Vision AI在每张图上跑哪些任务?
根据Google公开的Vision AI文档和我做过的反向测试,Google对你站点的每一张被抓取图片至少跑这几项任务:物体识别(识别图中所有可见物体并打标签)、场景理解(判断是室内/室外/办公/餐厅等场景)、文字OCR(提取图中所有文字,对截图、商品标签、海报特别重要)、人脸识别(不识别身份只识别人脸属性,性别、年龄段、表情)、品牌识别(识别图中可见的品牌Logo、产品包装、商标)、地标识别(自然或人文地标)、安全分类(NSFW、暴力、医疗等内容分级)、视觉相似度索引(把图片嵌入向量空间,让相似图能被反向检索)。
关键一点:Vision AI抽取的语义信号不会显式告诉你,但会进入Google的图像索引。你能从Lens的反向搜索结果倒推一部分——把自己的产品图传Lens搜,看Google把它归类到什么物体标签、识别出哪些可见品牌、关联到哪些相似图。这是诊断你图片被Google如何理解的最直接工具。这背后到底搜索引擎是怎么把抓回来的图存进索引、再在排名时调用出来的,机制层在搜索引擎抓取索引排名三步全拆解里讲得比较通用,可以配合看。
Vision AI识别准不准?
保哥做过一组反向测试,挑了20张样本图(5张服装电商、5张餐饮菜品、5张工具设备、5张室内场景),用Lens反查Google对每张图的识别结果。结果:服装类识别准确率高,但分不清材质和款式细节;餐饮类对菜系判断准但具体菜名错误率约30%;工具类基本只识别到大类(“电钻”、“扳手”);室内场景能识别物体但难判断品牌和价位段。结论:Vision AI对通用物体和场景准确率已经很高,对细分品类、垂直品牌、专业术语仍有显著盲区。这些盲区就是传统五信号今天的核心价值——填补Vision AI识别不到的语义。
识别结果如何进入排名?
Vision AI抽取的标签会和你页面上的传统信号(alt、文件名、title、周围文字、EXIF、Schema)合并形成一个图片实体,然后这个图片实体进入Google的图像索引。当用户搜索某个查询时,Google会优先匹配那些Vision AI识别+传统信号双重确认的图片。换句话说:Vision AI识别说“这是一张户外帐篷的图”,传统信号说“这张图在讲4季帐篷选购”,两边对得上才有竞争力;只有一边Vision AI识别成功传统信号缺失,或者只有传统信号声明Vision AI识别不出,都会被降权。这里有个隐性后果——传统SEO一直强调的“alt堆词”今天反而是反向信号,因为Vision AI识别和alt堆词冲突时Google会判定页面在欺骗。
图像嵌入向量空间是怎么工作的?
Vision AI识别物体、场景这一层是显式标签输出,但还有一层更底层的信号:每张图被压成一个高维向量(典型是512维或1024维),落进图像嵌入空间。同主题、同风格、同色调的图在向量空间里距离近,差异大的距离远。这套机制的实际影响有三点:
- 视觉相似图自动聚类,Google Lens拍照搜索时按向量距离从近到远召回候选。
- 重复或近重复图被自动识别——同一张图在多个站点出现,权重归到最早或最权威的发布站。
- 风格一致性变成站点级信号——一家品牌如果产品图、文章图、Hero图视觉风格高度一致,向量空间里聚成一簇,Google判断品牌实体识别度更高。
这一层最少被讨论但越来越重要。早期的图片SEO只关心单图,今天每张图都被放进整站的视觉风格簇里一起评估。同一品牌站内所有原创图维持统一的视觉规范(光线、色调、构图、留白),向量空间里聚得紧,品牌识别就强。我服务过的一个北美护肤品DTC,做完全站300多张原创图的视觉规范统一(统一了背景色板和打光参数),三个月后Google Knowledge Panel里的品牌图片栏从空着到完整加载,Image Pack展示的图也明显偏向自家而非UGC素材。这是个长达半年才看到的回报,前两个月数据几乎不动,第三个月开始拐弯——视觉聚类的信号是慢工,但一旦建立非常稳定。
这里有个新的语义衔接:搜索引擎从关键词匹配进化到语义理解的演变路径上,视觉理解和语义理解共用很多底层模型架构,蜂鸟到BERT再到MUM的演变史那条线索能帮你理解为什么Vision AI能在图像理解上飞跃——同样的Transformer架构、同样的多模态预训练、同样的实体关系建模思路,从文本扩展到了视觉。
传统五信号今天还剩多少分量?
alt、文件名、title属性、周围文字、EXIF——这五组信号是过去十几年图片SEO的核心。Vision AI崛起后它们的权重发生了重新分配。这一节给具体拆解。
alt属性:从描述到消歧
alt过去是“Google看不到图,所以你得描述图给它看”。现在Google看得到图,但仍然读alt——alt的作用从主要描述转变为消歧和补充。当Vision AI识别有多种合理解释时,alt是决策依据;当Vision AI识别准确时,alt是上下文意图的传达者(这张图在你这页讲什么)。所以alt写法的原则也变了:
- 简洁准确,不堆关键词,自然描述图像内容+所属上下文。
- 不要重复Vision AI已经能识别到的明显物体(“一张图”、“产品图”这种泛词),多说Vision AI识别不到的细节(材质、用途、品牌、型号)。
- 装饰图片用alt=“”明确告诉屏幕阅读器与爬虫跳过,不要写“图标”或“装饰”。
- 背景图、CSS background-image不传alt,Google基本不索引这类图片。
- 表单图标用aria-label而非alt,更符合无障碍规范。
文件名:被严重低估的早期信号
文件名在抓取阶段是Google对图片的第一信号源——Vision AI还没跑,文件名先看到。所以文件名是Google对你图片的第一印象。带连字符、英文小写、描述图像内容、合理长度(30-60字符),是最稳妥的格式。
常见踩坑:DSC0234.jpg、IMG_5678.jpg、screenshot-2024-11-22.png这类相机/系统默认文件名,Google抓到只能等Vision AI识别,少了第一信号源的辅助。CMS自动生成的文件名(uploads/2024/11/post-id-123-thumb.png)也属于这一类。所有上传到站点的图片,文件名都应该用语义化命名重写。我服务过的一个北美厨具DTC品牌,把站点1万8千张老图按“产品大类-款式-颜色-款号”重命名上传,三个月内Image Pack曝光提升约35%——文件名一个信号源补回去,效果就这么明显。
title属性:今天已基本无用
title属性(图片hover时显示的提示文字)今天对SEO几乎没作用。Google早就不把title作为排名信号,浏览器对它的展示也不一致。不要再为SEO写title属性,留着只造成模板冗余。需要无障碍辅助时用aria-label或figcaption。
周围文字:仍然是最强单点信号
图片周围文字(caption、figure内的figcaption、紧邻段落、所在section的H标题)今天是图片SEO最强单点信号之一,权重高于alt。Google用图片周围文字判断这张图在页面里的语义角色:是产品展示?方法步骤?数据可视化?用户案例?这一判断直接决定图片在哪类查询下被Image Pack展示。做法:图片所在section的H2/H3要包含图片想要排名的核心词;figure用figcaption写一行自然语言描述+主关键词;紧邻图片的段落第一句话要呼应图片内容。
EXIF信息:场景化决策
EXIF是图片元数据,包括拍摄时间、相机型号、GPS、版权、镜头参数。Google官方说不直接用EXIF做排名,但实践中EXIF对原创性识别、Local SEO、新闻图片有正向间接信号。决策原则按场景:
| 场景 | EXIF处理 | 原因 |
|---|---|---|
| 本地业务图片 | 保留GPS+时间 | 对Local SEO有正向信号 |
| 新闻媒体原创图 | 保留全部 | 原创性识别和版权追溯 |
| 原创摄影作品 | 保留时间+设备+版权 | 原创性证据 |
| 电商产品图 | 清掉EXIF | 避免暴露厂家路径、降低文件体积 |
| 隐私敏感场景 | 必须清掉GPS | 用户拍照可能含家庭地址 |
| 素材库下载图 | 清掉原版权字段 | 避免授权链不清 |
Vision AI与传统信号怎么职责切分?
理解了Vision AI和传统五信号各自的作用,接下来就是怎么把两套信号在每张图上协同好。这一节给具体的职责切分对照与落地清单。
两套信号的职责对照表
| 信号类 | Vision AI | 传统信号 | 结合方式 |
|---|---|---|---|
| 物体识别 | 主 | alt补充消歧 | Vision识别后alt补品牌型号 |
| 场景识别 | 主 | 周围文字定义意图 | 周围文字告诉Google为什么用这张图 |
| 文字OCR | 主 | alt不重复OCR内容 | alt写OCR外的语义,文字OCR交给Vision |
| 品牌识别 | 有限 | 文件名+alt补全 | 对小品牌Vision识别不到,文件名带品牌 |
| 地理位置 | 地标识别有限 | EXIF GPS+周围文字 | Local场景用EXIF+正文地址双重定位 |
| 主题意图 | 无 | H标题+正文上下文 | 必须靠传统信号传达页面级主题 |
| 商业意图 | 有限 | Schema Product+Offer | 商品图必须配Product Schema |
落地清单:一张图的完整SEO化
下面这套清单是过去两年咨询服务里固化下来的图片SEO作业流程,每张关键图(产品图、文章首图、数据图、案例图)都按这套跑一遍:
- 文件名:用语义化英文命名,产品图用品类-型号-款号,文章图用主题-序号格式。
- 压缩与格式:原图AVIF或WebP,浏览器fallback到JPEG,确保单图<200KB(首屏图<100KB)。
- 尺寸与srcset:至少3档尺寸(移动/平板/桌面),srcset+sizes正确声明。
- alt:30-100字符,自然描述图像内容+上下文意图,不堆词。
- figure/figcaption:内容图用figure包裹,figcaption写一句话辅助说明。
- 周围文字:紧邻段落首句呼应图像内容,所在H2/H3包含目标核心词。
- Schema:商品图必须配Product+Image,文章图配ImageObject嵌进Article Schema。
- EXIF:按场景决策(保留或清除)。
- loading属性:首屏图eager,其他图loading=“lazy”。
- fetchpriority:LCP关键图设fetchpriority=“high”,加快渲染。
- image sitemap:所有有SEO价值的图片提交进image sitemap,配title和caption字段。
Image Pack为什么不出?
Image Pack是SERP里那个图片轮播展示位,正常占SERP前两屏10-30%的视觉面积,是图片SEO最高价值的展示位之一。但客户里大量站点反映Image Pack出不来,这一节专门拆机理。
Image Pack的触发条件
Image Pack按查询触发,不是所有搜索都会展示。Google判断当前查询有视觉意图时才出,比如“how to fold a t-shirt”、“living room decor ideas”、“sourdough bread step by step”、“BMW M3 interior”。纯文本意图查询(“什么是HCU”、“SEO是什么意思”)几乎不出Image Pack。所以图片SEO要做的第一件事,是判断你想拿排名的查询是不是视觉意图。这个判断很简单:直接搜一下,看SERP上有没有Image Pack或图片大块展示,没有就别在这查询上指望图片流量。
站点级图片信任门槛
Image Pack对站点信任有门槛。新站、HCU受影响站、站内大量素材库重复图的站,Image Pack展示概率明显低于高信任站点。这门槛是Google的反垃圾防护——避免Image Pack被低质素材站霸屏。站点信任不足时,单纯优化图片SEO上限很低,要先把整站质量信号拉起来。
独家原创vs素材库重复
Google对图片有近重复检测——同一张图被多个站点使用时,权重给“首发或最权威”的那个,其他站基本拿不到Image Pack。所以电商和内容站千万不要用Shutterstock、Unsplash这类素材库图当主图;产品图最好实拍,配图最好原创制作。这一条做不到,Image Pack 90%的版位都和你无关。
Image Pack vs Discover图片流
注意两个相似但机制不同的展示位:Image Pack在SERP里、按查询触发;Discover图片流在Google App首页、按用户兴趣推送。两者图片要求不同——Discover要大图(至少1200像素宽)、清晰、有吸引力;Image Pack更看相关性和点击预测。同一组图片要兼容两个展示位,要求按更严的Discover走(大图、高清、原创)。
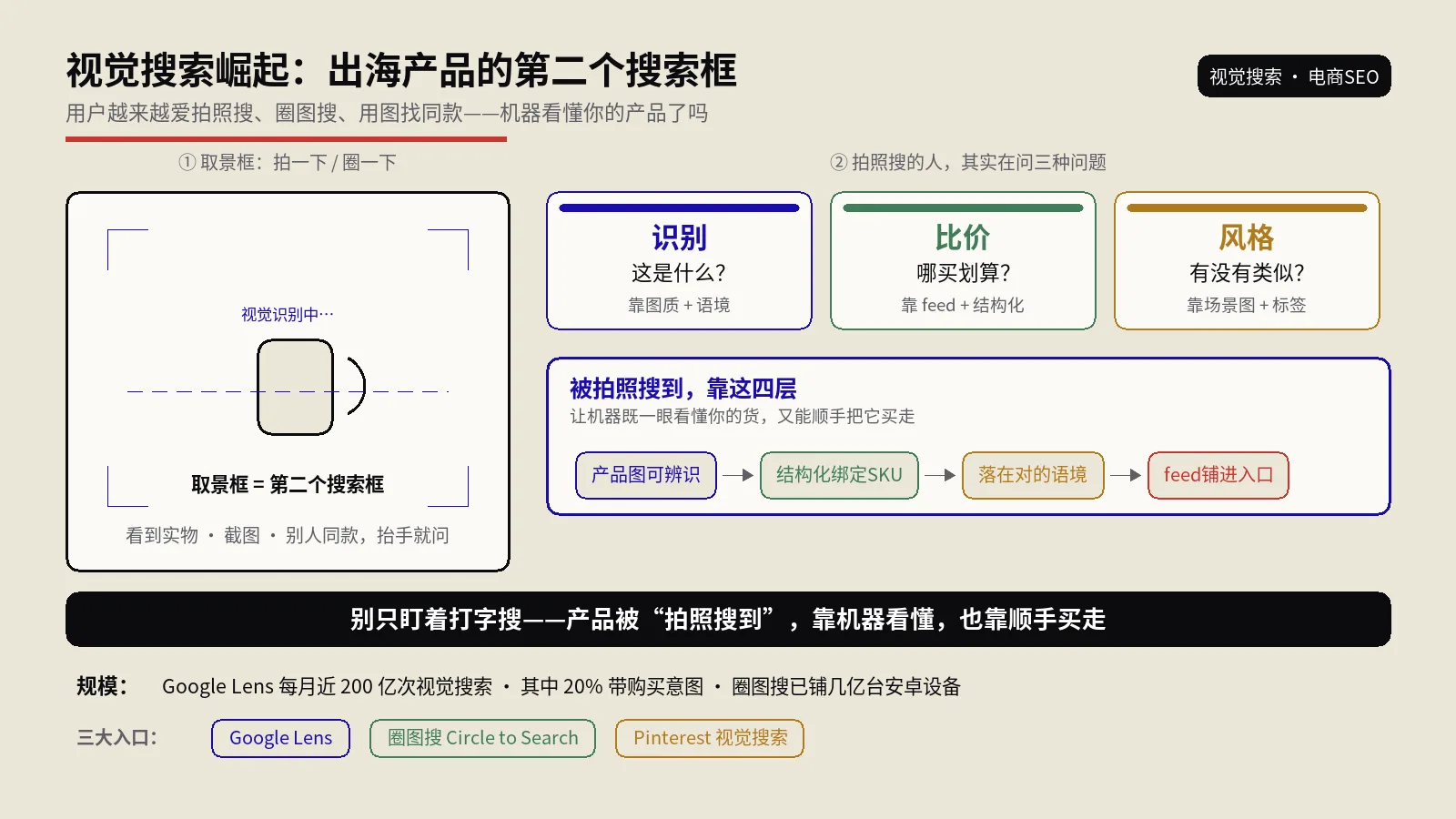
Google Lens排名靠什么?
Google Lens是用图片做搜索查询——用户拍一张实物,Google返回相似商品、识别对象、文本翻译、相似图。Lens流量被严重低估,到站质量极高(用户拍照搜索的转化意愿几乎最高),但绝大多数站点完全没在Lens上做SEO。这一节讲怎么让你的图被Lens排上。
Lens的反向匹配机制
Lens的核心是图像嵌入向量空间匹配——把用户拍的图嵌成向量,在Google的图像索引里找最相似的图。能上Lens排名的前提,是你的图被Google索引并能被Vision AI识别成对应类目。要做的事情:所有产品图都要被Google抓取(Image Sitemap+robots.txt允许Googlebot-Image+Image Schema),且产品分类清晰(用Product Schema声明category)。
实物拍照角度的现实
用户用Lens拍的是实物,所以你的产品图也要有实物拍照视角的版本。纯白底、纯标准角度的电商主图很难被Lens实物拍照命中——用户拍的角度、光线、背景和电商主图差太远。解决办法:每个核心SKU配3-5张实物使用场景图(在家里用、户外用、近景、远景、不同光线),上传到产品页或博客文章。这些图被Vision AI识别+Lens索引后,实物拍照命中概率成倍提升。
Lens流量的转化特点
北美厨房小家电品牌做完Lens实物拍照图优化(每个核心SKU补5张实物场景图),三个月后Lens引流过来的用户转化率比普通自然搜索高2.4倍,平均订单价值高37%。原因不复杂:用户拍图搜索时已经看到实物决定要买类似的,决策门槛低、转化意愿高。Lens流量量级不大但质量极高。
把Lens引流当作产品洞察反向利用
Lens的另一个被忽视的价值是反向情报。GA4里的referral来源带?lens或来自Lens的查询,可以拆出“用户拍了什么实物来找你”。我帮一个出海宠物用品品牌跑这一步的时候,发现来自Lens的实物拍照里有18%是宠物玩具的故障状态(咬碎、磨损、缝线裂开)——用户是拍了坏掉的旧玩具想找替代品。这条洞察直接重写了他们的产品页:增加“耐用度对比”、“咬力测试”等内容板块。这种从图像找回的用户意图,传统关键词数据完全看不到。
具体操作:GA4里设事件参数捕获Lens来源、按“图片到达页”维度看哪些产品页接得最多Lens流量、对这些产品做更密集的实物场景图覆盖+评论展示+对比内容补强,形成正反馈循环。Lens流量小但每一单都是高情报价值,把它当广告流量做转化优化就低估了,它更像是免费的客户访谈。
还有个更要紧的变化:Lens早就不只是“拍张静态图去搜”了。Google在Lens视频搜索的官方更新里把它推进到了视频加语音的实时多模态搜索——在Google App里按住快门录一段视频、同时把问题问出来(比如“这两条鱼为什么总一起游”),系统会把画面和你的问题一起理解,直接产出AI Overview;后来这套能力又长成了Search Live那样的实时视觉对话。这对图片SEO的含义很直接:被检索的不再只是一张张孤立的静态图,而是能被连续追问的场景。产品怎么用、和什么搭、在真实环境里长什么样——这些过去靠图文详情页交代的东西,现在更值得用能被Vision AI逐帧读懂的视频和结构化标注补上;否则用户对着摄像头问出来的那类问题,你的页面根本接不住。
多平台视觉搜索的差异是什么?
视觉搜索不只Google Lens。这一节给六大平台视觉搜索的机制对照,做电商和出海的尤其要看清。
六平台视觉搜索对照矩阵
| 平台 | 视觉搜索产品 | 核心算法 | 主要场景 | SEO优化要点 |
|---|---|---|---|---|
| Lens, Image Pack | Vision AI+图像嵌入 | 实物识别、商品搜索、文本翻译 | 实物场景图+Product Schema+Image Sitemap | |
| Pinterest Lens, Visual Search | Pinterest独家视觉模型 | 风格灵感、家居装饰、时尚搭配 | 高质量场景图+Rich Pins+主题板 | |
| Amazon | Amazon StyleSnap, Lens | 商品视觉相似度 | 商品反向搜索、相似商品 | 多角度主图+ASIN视觉打通 |
| TikTok | 视觉搜索(封面) | 视频帧+封面OCR | 商品发现、UGC视觉 | 封面文字OCR可读+首帧识别 |
| 小红书 | 视觉相似笔记 | 笔记封面+图片嵌入 | 种草内容、生活方式 | 封面识别度+OCR文字+人物属性 |
| Bing | Bing Visual Search | Microsoft Vision | 商品搜索、文本识别 | 类似Google但更看图像清晰度 |
差异的核心:Google Lens偏物体识别+商品定位,Pinterest偏风格灵感+审美,Amazon偏纯商品反向,TikTok和小红书把视频/笔记封面当视觉搜索入口。做平台SEO时,每个平台的图像准备要求是不一样的——Google要清晰的物体特写,Pinterest要有审美的风格场景,TikTok要让封面文字能被OCR清晰读取。一套图通用所有平台是不可能的。
多平台视觉搜索关联
抖音、TikTok的视觉搜索机制和Google有显著差异,可以参考TikTok SEO机制完全指南里讲的机器理解优先级(口播>屏幕OCR>音频>caption/标签)来类比理解,平台SEO机制差异比一般人以为的大得多。小红书的视觉搜索把笔记封面的OCR权重打得比内容文字还高,所以同一张封面图在小红书和Google的优化方向几乎是相反的——一边要图上文字醒目可读,一边要图本身视觉信息密度大。
图片sitemap和image schema怎么用?
这两个是图片SEO的工程化底盘,决定Google能否高效发现和理解你的图片。
图片sitemap的字段与规模
image sitemap是XML sitemap里专门标记图片的扩展。每个URL节点下可以包含多个image:image子节点,每个声明一张图。关键字段:loc(图片绝对URL)、title(图片标题)、caption(说明文字)、license(版权声明URL)。image sitemap最大的价值不是排名直接信号,而是让Google知道哪些图是你认为有SEO价值的——同一页上未声明的图Google抓取优先级会低很多。
规模站常踩的坑:image sitemap生成时把所有图都塞进去(包括装饰图、模板图、广告图、用户上传图),导致Google抓取预算被烧在低价值图上。image sitemap只包含原创、独家、有SEO价值的图,装饰图和模板图一律不进。这一条对大型电商和UGC站点尤其关键。
ImageObject Schema怎么挂
每张关键图(产品主图、文章首图、Hero图)都应该挂ImageObject Schema,作为Product或Article或BlogPosting的image字段值。完整ImageObject节点包含url、width、height、caption、license、creator、creditText等。Schema的image字段也是Google判断图片是否为页面主图的核心信号,挂了ImageObject Schema的图被选为SERP缩略图的概率明显高于没挂的。
licensable图片的合规价值
Schema里license字段填正确,Google会在Image Pack展示时附带“可授权”标记,对原创摄影、媒体、设计资源站是流量加分项。这要求你站点有清晰的图片授权页面,license字段指向该页URL。媒体和原创内容站强烈建议做这一步,对外授权能力也变成SEO信号。
图片性能和Core Web Vitals怎么协同?
图片是LCP的最大单一因素。这一节讲图片性能和CWV、Image Pack排名的协同关系。
LCP图片的选择标准
LCP(Largest Contentful Paint)的元素绝大多数情况下是页面首屏的一张大图。优化LCP图片是CWV优化里最高ROI的一步。要做的事情:LCP图设fetchpriority=“high”、preload链接预加载、用AVIF/WebP现代格式、合理压缩到100KB以内(移动端)、避免srcset里塞过多档位(3档够用)、避免延迟加载(loading=“lazy”对LCP图反而是负面)。
srcset+sizes的常见错配
srcset和sizes是响应式图片的核心,但错配率惊人。常见错误:srcset里档位过多(5-8档),浏览器选不准;sizes声明的宽度和实际容器不符,浏览器下载了不必要的大图;移动端没用占位符或fallback;srcset里的图URL写错404。修复办法:3档(小/中/大)够用、sizes要精确(一般“100vw”或“50vw”对应布局)、用Lighthouse audit检查实际下载图与显示尺寸的匹配度。
性能和Image Pack的双向影响
CWV是Google Image Pack的间接信号——CWV差的站点,Image Pack展示概率被降权。这是Google过去三年明显的趋势。所以图片性能不只为用户体验,也直接影响图片SEO本身。我服务过的一个北美时尚DTC品牌,做完LCP图片优化(AVIF+fetchpriority+preload)后,移动端LCP从4.2秒降到1.8秒,Image Pack曝光在三个月内提升约48%,没改一个alt一个文件名。
AI爬虫抓图与图片版权风险
2024年以来AI爬虫(GPTBot、CCBot、Google-Extended、Anthropic ClaudeBot、PerplexityBot)大量抓图用于训练和检索增强。这给图片SEO带来全新议题,绕不开。
AI训练vs AI检索的差异
必须分清两件事:AI训练(抓你的图训练大模型的视觉理解能力)和AI检索(AI产品回答用户问题时引用你的图作为来源附带链接)。两件事影响完全不同——训练对你无直接回流但有潜在版权风险,检索给你回链曝光是正向。robots.txt里阻不阻AI爬虫,要按这两件事分别决策。
robots.txt对AI爬虫的细粒度控制
| UA | 用途 | 建议 |
|---|---|---|
| Googlebot-Image | Google图片搜索+Image Pack | 必须允许 |
| Google-Extended | Bard/Gemini训练 | 按你对训练态度决策 |
| Googlebot | Google AI Overviews检索 | 必须允许(影响SERP) |
| GPTBot | OpenAI模型训练 | 按你对训练态度决策 |
| OAI-SearchBot | ChatGPT Search检索 | 建议允许(影响AI回链) |
| CCBot | Common Crawl训练库 | 影响所有AI厂商,谨慎决策 |
| PerplexityBot | Perplexity检索 | 建议允许(影响AI回链) |
| ClaudeBot | Anthropic训练 | 按训练态度决策 |
核心原则:阻训练爬虫,放检索爬虫。具体做法是robots.txt里Disallow GPTBot/Google-Extended/CCBot/ClaudeBot等训练相关UA,Allow OAI-SearchBot/PerplexityBot/Googlebot等检索相关UA。但要权衡:阻训练等于关掉模型未来对你品牌的认知能力,五年后AI检索时代你的品牌可能被边缘化。
AI检索抽取你的图怎么追踪?
AI检索(AI Overviews、ChatGPT Search、Perplexity)抽取图片作为答案素材的频率越来越高,但官方都不会发“被引用报告”。三种容易被AI选中的图共同点很清楚:白底或近白底的产品主图(视觉噪音低、AI压缩成视觉token更稳)、有明确数据标注或文字层的信息图(AI可读取并复用其中事实)、独家拍摄的实物场景图(向量空间内独占性高)。反过来,纯文字截图、低分辨率图、和其他站重复的素材库图,AI抽取概率极低。怎么知道你的图被抽到了哪些AI答案里?三个粗暴但有效的办法:
- 定期把核心产品/教程关键词在AI Overviews、Perplexity、ChatGPT Search上跑一遍,截图记录答案里有没有你的图、点击源链接是否回到你的页面。
- GA4或Plausible里看referral来源带perplexity.ai、chat.openai.com、bing.com/chat等域名的流量,按到达页分组识别哪些图被引用。
- image sitemap里的图URL单独打UTM参数(utm_source=ai_overviews等),方便服务端日志或GA直接看到AI引用回流。
追踪本身不是目的,目的是知道哪些图最容易被AI选作答案素材,反向加强这类图的供给。过去三个季度AI检索回流占整体自然流量的比例在保哥服务的客户里普遍从1%-2%涨到5%-12%,2026年会继续往上走,图片在AI答案里的展示位置很可能成为下一个Image Pack级的流量入口。
图片侵权与防御
原创图被AI生成内容复刻、被竞品盗用、被素材站重新打包卖是真实风险。防御办法:所有原创图加可见水印(不影响视觉的角落logo)+ EXIF版权字段保留 + Schema license字段声明 + 站点底部声明知识产权 + 定期用Google Lens反向搜索自己的图查盗用站。这是个长期工程,没有一次性解决方案。
北美厨具DTC品牌图片SEO改造的完整复盘
保哥结束讲机制,给一个完整案例落地参考。北美厨具DTC品牌,月营收六位数美元,独立站架在Shopify上,主要品类是厨房小家电+刀具+烹饪工具,目标市场北美+西欧。改造前状态:站内1万8千张图,alt全部规范、文件名规范、WebP已上线,Google Image Pack曝光近一年增长几乎为零,Lens引流几乎零。
第一阶段诊断:用Google Lens反查站点核心SKU的产品图,发现Vision AI对大部分产品的识别只到通用大类(“厨房电器”、“刀具”),具体品类(“立式搅拌机”、“切肉刀”)识别率不到40%。这说明Vision AI在他们的细分品类上识别能力不够,传统信号的补充极其重要,但他们的alt和文件名都偏短、缺品类核心词。
第二阶段动作:所有产品图重命名为“品类-品牌-型号-款号”格式(1万8千张图全量),alt重写为“品类描述+品牌型号+主要用途”30-60字符版本,每个核心SKU补5张实物使用场景图(在家庭厨房用、在户外用、近景、远景、不同光线),所有产品图配Product Schema+ImageObject Schema完整字段,image sitemap只包含产品图与文章原创图(不进装饰图与模板图),EXIF全清。这一阶段用了大约8周完成。
第三阶段优化:LCP图(产品页首图)改AVIF格式+fetchpriority=“high”+preload,移动端LCP从3.6秒降到1.7秒;robots.txt调整阻GPTBot/CCBot/Google-Extended,放Googlebot-Image/OAI-SearchBot/PerplexityBot。
第四阶段结果(改造后第6个月):Image Pack曝光提升约67%,Google Lens引流从月不到100到月3200,Lens引流的转化率2.4倍于普通自然搜索,月均订单总额贡献约8%来自Image相关流量。更重要的是这个量级一旦建立基本不会塌,图片SEO的复利效应非常稳定。
这个案例最值得说的不是数字,是改造逻辑:从“调alt和压缩格式”转到“补Vision AI识别盲区+加实物场景图+完整工程化”。今天做图片SEO的真正杠杆在这后半段,不在alt那一句话。
常见问题解答
alt文字写得多详细Google就给我排名?
不是。Google用Vision AI直接读图,alt主要给三类场景:屏幕阅读器、加载失败兜底、Vision AI识别不出时辅助消歧。alt过长或堆关键词反而触发反堆砌,自然准确描述即可。
Vision AI能读图,传统五信号还要不要做?
要。Vision AI读出来的是图像物理内容,传统信号传达页面上下文与意图。两套并行:Vision AI判断这张图是什么,传统信号告诉Google这张图在你这页里讲什么主题。缺哪边Image Pack都拿不到。
为什么我图片很多但Image Pack就是不出?
Image Pack按查询触发,还有图像质量、独占性、文字相关性、站点信任四道门槛。多和漂亮不够,必须独家原创、与正文主题强相关、站点在该主题有权威,三条都过才有机会。
Google Lens和谷歌以图搜图是同一回事吗?
技术同源但产品定位不同。以图搜图是反向找图源;Lens是用图片做即时搜索查询,结果是商品、识别对象、文本翻译、相似图等多形态。Lens的SEO意义在于让你的产品图能被实物拍照触发,到站量较高。
图片用WebP还是AVIF?JPEG还能不能用?
AVIF压缩率最高但兼容性还有边缘缺口,主图用AVIF配WebP fallback、再老的浏览器fallback到JPEG最稳。纯JPEG也不会被Google惩罚,但LCP在移动端容易拖到3秒以上,影响CWV和Image Pack排名。
AI爬虫抓我图片去训练会损害我吗?
影响主要在版权和商业模式:你的图被训练后AI生成的图可能复刻你风格;用作AI Overviews素材时附带回链。robots.txt可阻Google-Extended、GPTBot、CCBot等训练UA,但等于关掉AI检索曝光,要权衡。
EXIF信息要不要保留?要不要去?
看场景。本地业务、新闻媒体、原创摄影类强烈建议保留GPS和拍摄时间,对Local SEO和原创性识别有正向信号;电商产品图建议清掉EXIF,避免暴露厂家路径或被爬虫指纹识别。隐私敏感场景一律去EXIF。
权威参考资料
本文标题:《图片SEO新机制是什么?Vision AI读图与Lens排名》
本文链接:https://zhangwenbao.com/image-seo-vision-ai-multimodal-search-google-lens-mechanism.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0