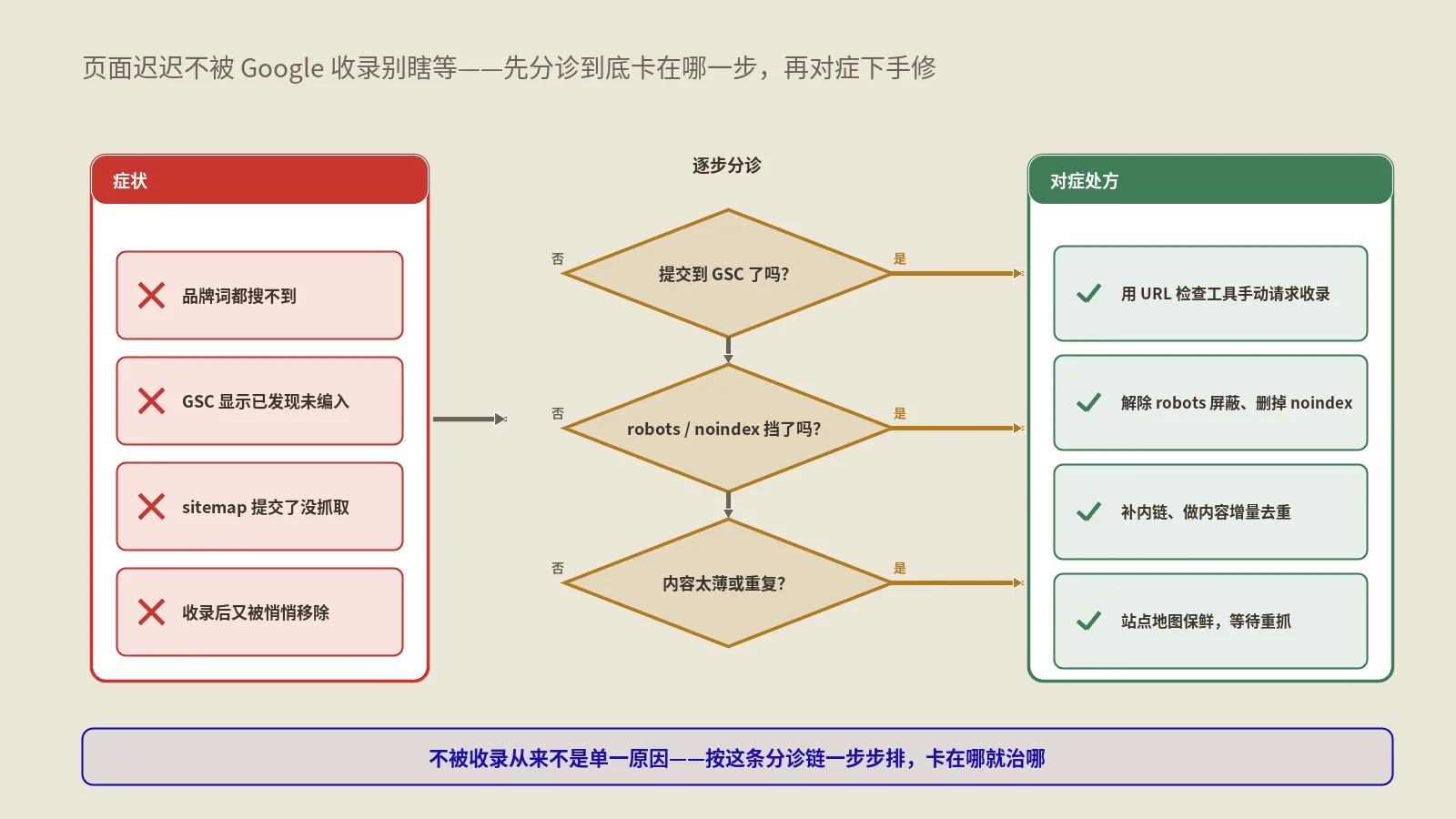
AI爬虫到底抓你什么?代码逆向出爬虫真实偏好8步实操
本文目录
- 为什么“AI爬虫优化”大多是在凭感觉做?
- 你以为的“一个AI爬虫”,其实是一支机队
- 文档为什么不能照着信
- AI爬虫到底想要什么?先把“抓取偏好”说清楚
- 训练抓取、检索抓取、即时代取——三套完全不同的经济学
- 字节预算与截断——AI根本不会把你整页读完
- 动手:做一个能复现AI爬虫指纹的请求模拟器
- 用curl复刻几个真实客户端
- 关键不是发请求,是建对照组
- 访问日志才是唯一真相——怎么从里面把真实行为挖出来?
- 一段可复用的日志解析思路
- 从日志里能读出六种“病”
- 逆向完之后,robots、llms.txt、渲染到底怎么配才有用?
- robots的分客户端策略,和它真实的边界
- llms.txt:先回答“谁会读它”,再决定写不写、写什么
- 渲染与字节策略——让AI花最少预算拿到主内容
- 这套逆向该多久做一次?怎么固化成长期能力?
- 一张可以直接抄的季度自检清单
- 团队定位与给业务方的口径
- 常见问题解答
- 权威参考资料
摘要:先把最容易被省掉的一句话摆在前面:所谓“给AI爬虫做优化”,绝大多数人其实是在对着一份既滞后又含糊的官方文档猜,再抄一段网上的llms.txt模板交差。真相只有一个地方能给你,就是你自己服务器的访问日志。这篇不教你抄配置,教你把这件事当工程做:先用一个能复现请求指纹的模拟器搞清楚每个AI客户端“能怎样”,再用访问日志反查它“实际怎样”,然后才谈robots、llms.txt、渲染该怎么配,最后把整套逆向固化成每季度能自动复跑的能力,而不是折腾一次三个月后全部过期。读完你会知道三件事:AI爬虫不是一种爬虫,是一支行为差异极大的机队;llms.txt写了不等于有人读;UA这东西,第一眼就不该信。
这两年找上门做AI可见性诊断的客户,开口几乎都是同一句:我robots放开了、llms.txt也按模板铺了,怎么在ChatGPT、Perplexity里还是搜不到我。我让他们先别急着改任何东西,把过去三十天的服务器访问日志导出来。十有八九,问题在日志里一眼就能看见,而且跟他们想改的地方根本不是一回事。保哥做这行二十多年,最深的一个体会是:搜索也好、AI也好,文档会骗你,日志不会。
这篇文章的主线就一条:把“对AI爬虫做优化”从凭感觉,变成可复现、可验证、可长期维护的逆向工程。它不是一篇llms.txt怎么写的教程,也不是泛泛的服务器日志分析入门,而是讲一套方法——怎么把每个真实AI客户端的行为指纹复刻出来、怎么从日志里把它的真实偏好挖出来、怎么据此做分客户端的决策、再怎么把它固化下来。先说清楚为什么大多数人这一步就走偏了。
为什么“AI爬虫优化”大多是在凭感觉做?
根子上是三件事凑一块儿了:官方文档滞后又含糊,UA可以随便伪造,而且不同客户端对robots的遵守程度天差地别。你照着一篇半年前的博客改配置,改的是一个早就变了的目标,还以为自己在做优化。
你以为的“一个AI爬虫”,其实是一支机队
最常见的认知误区,是把“AI爬虫”当成一个东西。实际上光OpenAI一家就分了好几个客户端,各管各的:GPTBot抓离线训练语料,OAI-SearchBot给它的搜索功能建检索索引,ChatGPT-User是用户在对话里点了链接、或触发了实时检索时,代用户去取那一篇。这三个的触发条件、回访频率、对新鲜度的敏感度完全不同,你把它们一起拦掉的后果也完全不同。Anthropic同样分ClaudeBot、Claude-User、Claude-SearchBot,Perplexity分PerplexityBot和Perplexity-User。把这一堆混成一类去配置,等于拿一把钥匙去开十几把锁,开不开全靠运气。
| 客户端 | 用途 | 是否执行JS | 是否读robots | 被你拦掉的后果 |
|---|---|---|---|---|
| GPTBot | 训练语料抓取 | 否 | 声明遵守 | 缺席训练语料,模型“天生不认识你” |
| OAI-SearchBot | 检索索引构建 | 否 | 声明遵守 | ChatGPT实时检索结果里没有你 |
| ChatGPT-User | 用户即时代取 | 有限 | 较弱 | 用户当场点你,取不到内容 |
| ClaudeBot | 训练抓取 | 否 | 声明遵守 | 同GPTBot |
| Claude-User / SearchBot | 用户即时取 / 检索 | 有限 | 较弱 | Claude回答里引不到你 |
| PerplexityBot | 检索索引 | 有限 | 实测时有不遵守 | Perplexity答案缺你 |
| Google-Extended | Gemini训练授权开关 | 不适用 | 是开关非独立UA | 关掉≠不被Googlebot抓 |
| Applebot-Extended | Apple智能训练授权 | 否 | 遵守 | 退出Apple生态语料 |
| Bytespider / Amazonbot / Meta-ExternalAgent | 各家训练/抓取 | 多数否 | 参差,部分激进 | 多为成本与过载问题 |
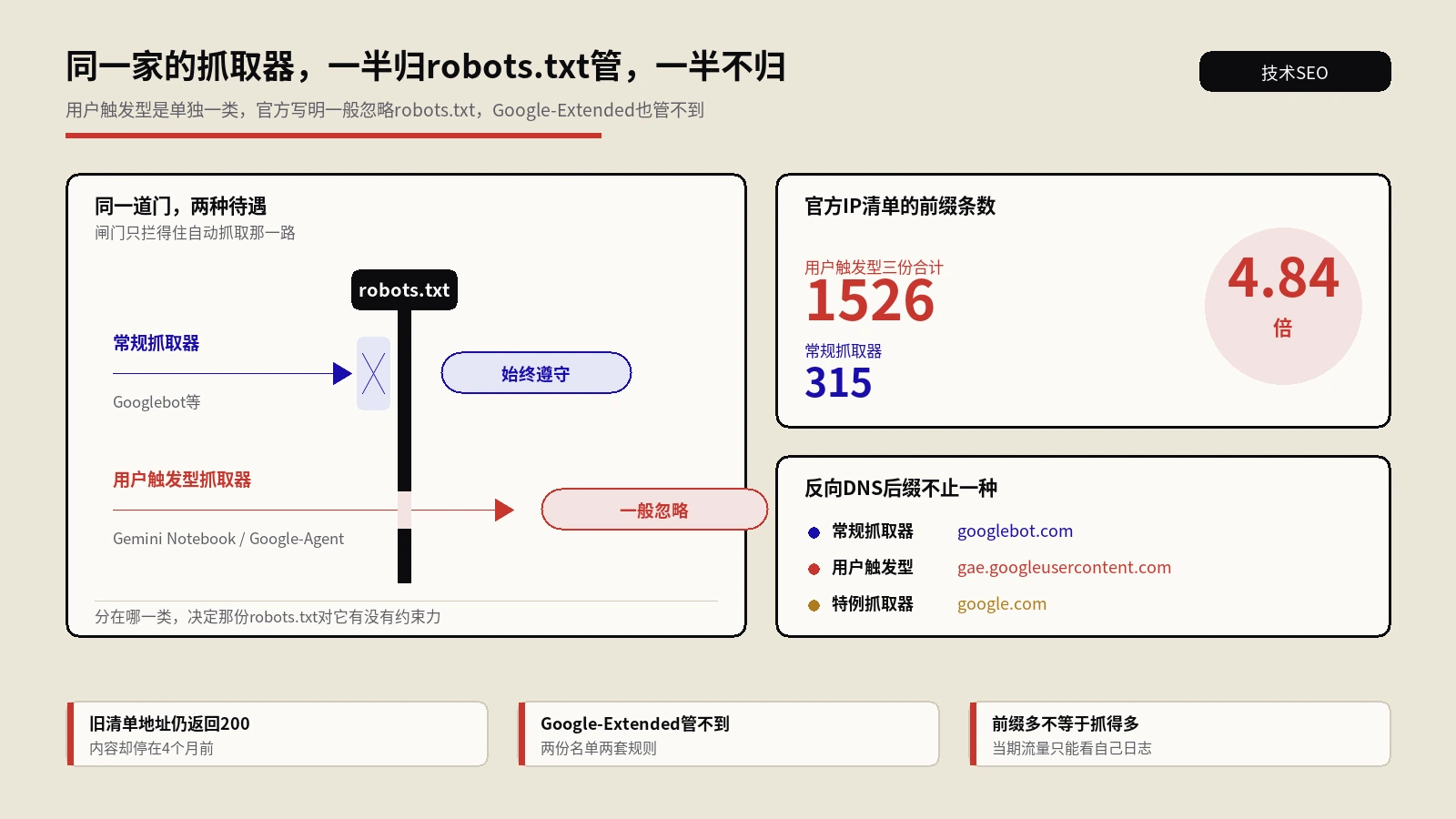
这张表里最值得记的不是某一行,是“是否读robots”那一列里那几个“较弱”和“实测时有不遵守”。它直接决定了你后面该用robots这种君子协定去管它,还是只能动服务器和WAF。这事不能信文档,得自己测,后面会讲怎么测。还有一个最容易被忽略的细节:Google-Extended不是一个独立爬虫,它是一个授权开关,关掉它只是不让你的内容进Gemini训练,Googlebot该怎么抓你做搜索还是怎么抓——很多人误以为关了Google-Extended就“屏蔽了谷歌的AI”,结果既没挡住该挡的,又没搞懂自己到底在关什么。
文档为什么不能照着信
官方文档有两个天然问题。一是滞后:UA名称、IP段、是否开始执行JS、是否开始读某个文件,这些变更往往先上线、文档后补,甚至不补。二是它只说“我们打算怎样”,不说“我们实际怎样”。一个出海做3C配件的独立站客户,严格照OpenAI文档把robots写得漂漂亮亮,结果日志拉出来:PerplexityBot压根没请求过robots.txt就直接开抓,还有大量自称是普通Chrome的请求,UA、访问节奏、只啃文章正文页这三个特征叠在一起,基本可以判定是伪装过UA的抓取。文档里写的那套,对它们一行都没生效。
更隐蔽的一种滞后是“关系变更”。比如某段时间Google的AI Overviews复用的是Googlebot的抓取结果,而不是单独派一个AI爬虫,这意味着你想“对AI放、对搜索收”根本做不到,因为它们是同一次抓取。这种关系不会写在显眼的地方,只有你在日志里发现AI引用页的抓取来源全是Googlebot时才反应过来。所以这一节的结论很简单,也是整篇的地基:先有数据,再有策略。任何在没看自己日志之前就开始改的robots、llms.txt、渲染方案,都是在赌博,赌注是你的AI可见性。
AI爬虫到底想要什么?先把“抓取偏好”说清楚
“抓取偏好”这个词被用得很虚。把它拆成四个能观测的维度,它就立刻变得可操作了:怎么发现你(发现)、用什么方式取你(取用)、隔多久回来(节奏)、更认哪种内容(内容)。逆向工程逆的就是这四样,缺一个,你的结论都是片面的。
训练抓取、检索抓取、即时代取——三套完全不同的经济学
这是整篇最该先建立的分类。同样是“AI来抓我”,背后是三套经济模型,优化方向几乎相反。
| 维度 | 训练抓取 | 检索抓取 | 用户即时代取 |
|---|---|---|---|
| 触发 | 离线批量、周期性大扫 | 索引更新、事件驱动 | 用户当场提问/点击 |
| 频率 | 低频但覆盖广 | 中高频、回访重点页 | 极零散、无缓存 |
| 对新鲜度敏感 | 低 | 高 | 最高,要的就是此刻 |
| 是否执行JS | 基本不 | 多数不 | 部分客户端有限执行 |
| 被拦的后果 | 长期缺席语料 | AI答案里直接消失 | 用户点了你却空手 |
| 该优先保谁 | 能放就放,喂干净结构 | 必须保,且要快 | 必须保,首屏即正文 |
很多人把三者混着谈,于是出现“我要不要拦AI训练”这种没法回答的问题。讲一个真实的反面例子:一个做户外装备的出海独立站,运维觉得AI爬虫白嫖内容还吃带宽,一刀把所有OpenAI相关UA全Disallow了。短期看带宽确实降了一点,三个月后市场部发现一个怪现象——客户在ChatGPT里问这类产品,竞品被点名,自己一次都没出现过。问题就在那一刀:他们以为只拦了“训练白嫖”,实际上把OAI-SearchBot也一起拦了,等于主动从ChatGPT的实时检索里把自己删掉。拦训练抓取也许只是少进一批语料,但顺手拦掉检索抓取,是在AI答案里把自己抹掉,这两件事的代价根本不在一个量级。分不清这三类,后面所有决策都是错的。
字节预算与截断——AI根本不会把你整页读完
另一个反直觉点:检索类管线在把你的页面塞进模型之前,对单文档有明确的字节或token上限,超了就截断,而且通常是从后往前截。也就是说,你导航、cookie横幅、同意弹层、相关推荐、骨架屏占掉的每一段,都是在用预算换噪音,真正的正文可能还没轮到就被切掉了。这跟“怎么让页面被高效抽取”是同一件事的两面:让机器花最少的字节拿到主内容,和把站点做轻、做低碳,本质上是同一套字节动作,只是出发点不同。理解这点,你看页面的眼光会变——不再问“这段内容好不好”,而是问“在被截断之前,机器能不能读到这段”。
有个做B2B SaaS的客户,产品文档站,主内容藏在一个要点击才展开的tab里,初始HTML里只有标题和一句导语,剩下全靠前端异步拉。他们一直纳闷为什么AI从来引用不到具体功能说明,明明文档写得很细。答案不复杂:GPTBot这类不执行JS,它取到的就是那个空壳,里面那句导语反复出现在每个页面,于是模型“认识”这个站的方式就是一堆雷同的空导语。这不是内容质量问题,是取用方式问题——内容写得再好,机器那一刻根本看不见它。把那段说明改成服务端直出之后,同一批页面在AI回答里被引用的概率,肉眼可见地起来了。
条件请求与回访——被很多人漏掉的第四维
除了发现、取用、内容,还有一维很少有人测:客户端怎么处理If-Modified-Since和ETag。检索型客户端如果支持条件请求,它会带上次的时间戳来问“变了没”,没变你返回304,省双方的资源、也让它更愿意高频回访;如果你的站对所有请求一律返回200全量(很多动态站、很多CDN默认就是这样),相当于每次回访都让它重读一遍,它要么降低你的回访频率,要么干脆少抓你。逆向的时候一定要单独看这一项:日志里某个客户端的304占比,是它愿不愿意常来的直接信号。
动手:做一个能复现AI爬虫指纹的请求模拟器
逆向的第一步,是你能按每个真实客户端的“请求指纹”去敲你自己的站,看它怎么回应。指纹绝不只是UA,它至少包括下面这些,缺一项你就复刻不准。
| 指纹要素 | 为什么重要 | 怎么观测 |
|---|---|---|
| UA串 | 第一道筛,但可伪造 | 模拟器里逐个设 |
| Accept / Accept-Encoding | 决定你返回HTML还是别的、压不压缩 | 对比不同Accept的响应 |
| HTTP版本 | 部分客户端只走HTTP/1.1,影响性能与连接复用 | 抓包或服务端日志记录协议 |
| 是否执行JS | 决定它看到首屏还是完整DOM | 纯请求vs渲染对照 |
| 是否读robots | 决定你能不能用robots管它 | 看它有没有先请求robots.txt |
| 来源IP是否在官方网段 | 判真假的唯一硬证据 | 反向DNS + 官方CIDR校验 |
| 条件请求行为 | 决定它愿不愿意高频回访 | 带If-Modified-Since看是否304 |
用curl复刻几个真实客户端
最低成本的模拟器就是几行脚本,按不同客户端的真实头去取同一个页面,再对比返回的状态码、字节数和正文。重点是观察“纯HTML取到的”和“浏览器渲染后的”差多少——差得越多,说明你越依赖JS,越容易在不渲染的客户端那里变成空壳。下面这段刻意写得朴素,能跑、能改就行:
#!/usr/bin/env bash
URL="https://example.com/your-key-page.html"
# 各客户端真实UA,按官方公布抄全,这里省略号处要补完整
UA_GPTBOT='Mozilla/5.0 (compatible; GPTBot/1.1; +https://openai.com/gptbot)'
UA_OAISEARCH='Mozilla/5.0 (compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot)'
UA_PERP='Mozilla/5.0 (compatible; PerplexityBot/1.0; +https://perplexity.ai/bot)'
UA_CLAUDE='Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)'
for name in GPTBOT OAISEARCH PERP CLAUDE; do
eval ua=\$UA_$name
curl -s -A "$ua" -H 'Accept: text/html' \
-o "/tmp/ai_$name.html" \
-w "$name http=%{http_code} bytes=%{size_download} proto=%{http_version}\n" \
"$URL"
done
# 渲染对照组:用无头浏览器把执行JS后的DOM落盘
node render.js "$URL" > /tmp/ai_rendered.html
# 主内容是否依赖JS:纯请求版vs渲染版的可见文本长度差
python3 - <<'PY'
import re,sys
def vis(p):
t=open(p,encoding='utf-8',errors='ignore').read()
t=re.sub(r'<script.*?</script>','',t,flags=re.S)
t=re.sub(r'<[^>]+>',' ',t)
return len(re.sub(r'\s+','',t))
raw=vis('/tmp/ai_GPTBOT.html'); ren=vis('/tmp/ai_rendered.html')
print('raw=%d rendered=%d gap=%.0f%%'%(raw,ren,(ren-raw)*100.0/max(ren,1)))
PY这段脚本本身不是重点,重点是它逼你建立对照组。没有对照,单看一个返回,你判断不了问题出在哪一层。那个gap百分比就是最关键的一个数:它接近0,说明你主内容基本在首屏HTML里,安全;它越大,说明越多内容只有渲染后才出现,对不渲染的AI客户端就是越多的盲区。
关键不是发请求,是建对照组
三个对照一摆,问题层立刻定位:
| 对照源 | 代表什么 | 它和别人不一样,说明问题在 |
|---|---|---|
| 真实Googlebot(GSC的网址检查/实时测试) | 主流搜索看到的渲染后版本 | 对照基准,最接近“理想态” |
| 无头浏览器渲染后DOM | 执行JS后的完整内容 | 它有、纯HTML没有 → 取用层(依赖JS) |
| 纯curl拿到的原始HTML | 不渲染客户端真正看到的 | 它就缺主内容 → 内容没进首屏HTML |
如果三者都拿不到这个页面,那问题根本不在取用层,而在发现层——没人把这个URL告诉过任何爬虫。这种情况改渲染、改llms.txt全是白费,得回去补sitemap、补内外链、补外部提及。这也是为什么对照组不能省:少了它,你会把一个发现层的问题,当成内容层的问题去改,改三个月没动静,还以为是AI不识货。
UA可以伪造,反查IP才算数
必须强调一遍:UA是纯文本,谁都能写。Bytespider伪装成普通浏览器、有人冒充GPTBot来薅你内容,都很常见,后者甚至常常是竞品或采集器借AI爬虫的名头压你带宽。判定一个请求是不是真的某客户端,靠的是反向DNS加官方公布的IP网段双向校验:先对来源IP做反向解析看域名对不对,再正向解析回去看IP对不对,两边都对,再核对它是否落在厂商公布的CIDR列表里(OpenAI、Anthropic等都以JSON形式公布并会更新)。把这条写进你的日志分桶逻辑,不然你统计出来的“GPTBot抓取量”可能一半是李鬼,你还据此做了一堆错误决策。
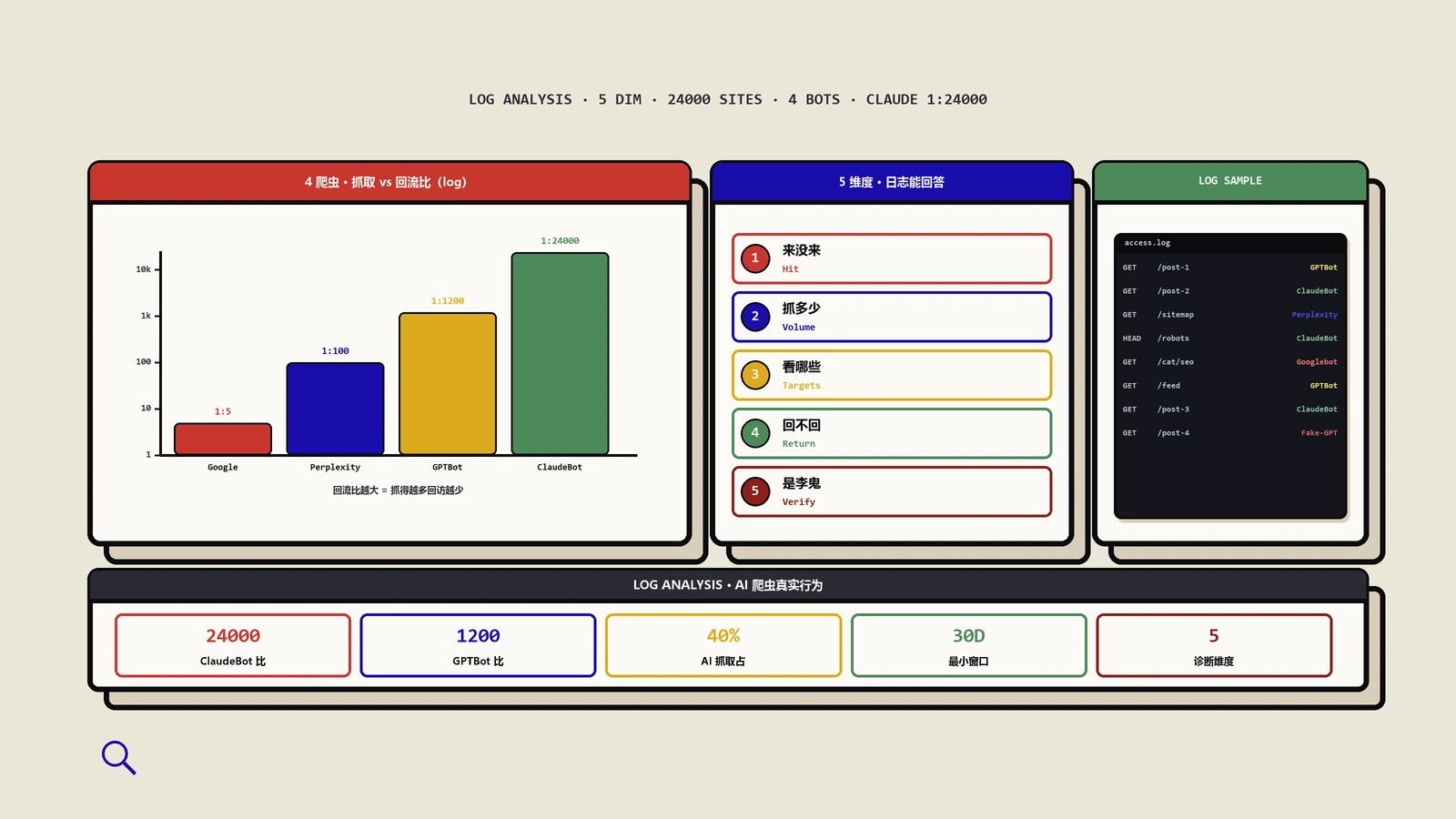
访问日志才是唯一真相——怎么从里面把真实行为挖出来?
模拟器证明“它能怎样”,日志证明“它实际怎样”,两者缺一不可。逆向的核心战场在这里:把Nginx或CDN日志按客户端分桶,统计请求量占比、命中路径分布、状态码构成、抓取时段、有没有踩robots禁区、单位时间峰值、还有上一节说的304占比。这套东西不该是临时跑一次的脚本,而该像对待把它做成CI而不是裸cron那样去工程化,否则三个月后又得从头来一遍。
一段可复用的日志解析思路
不贴整套脚本,讲清楚口径比给代码更有用。核心就三步:按UA正则把请求归到客户端,对路径做前缀聚类看它在啃什么,再单独检测有没有命中你robots里Disallow的路径。下面是核心逻辑,字段号按你的日志格式调:
# Nginx access.log,UA在双引号分隔的第6段,按需改字段号
awk -F'"' '
$6 ~ /GPTBot/ {b["GPTBot"]++}
$6 ~ /OAI-SearchBot/ {b["OAI-Search"]++}
$6 ~ /ClaudeBot/ {b["ClaudeBot"]++}
$6 ~ /PerplexityBot/ {b["Perplexity"]++}
$6 ~ /Googlebot/ {b["Googlebot"]++}
END{ for (k in b) printf "%-12s %d\n", k, b[k] }
' access.log | sort -k2 -nr
# 谁踩了robots禁区:把你Disallow的前缀填进这个正则
grep -E 'GPTBot|PerplexityBot|ClaudeBot' access.log \
| grep -E ' /(cart|account|search|filter)\?' \
| awk -F'"' '{print $6}' | sort | uniq -c | sort -nr
# 某客户端的304占比:愿不愿意常来的直接信号
grep 'GPTBot' access.log \
| awk '{c[$9]++} END{ for (k in c) print k, c[k] }'把它做成定时任务、把UA清单抽成一份可维护的配置、给关键指标加阈值告警,这套逆向才算长出了生命,而不是你哪天心血来潮才跑一次。口径上有个坑要提醒:很多站前面挂了CDN,源站日志看到的“客户端”可能全是CDN的回源IP,UA倒是透传的。这时候判真假要靠CDN那一层的日志,或者让CDN把真实客户端IP透传进头里,否则你在源站做IP校验,校验的是CDN自己。
从日志里能读出六种“病”
看多了你会发现,AI爬虫的问题翻来覆去就那么几种,每一种在日志里都有很明确的指纹:
| 病 | 日志特征 | 根因层 | 该往哪修 |
|---|---|---|---|
| AI爬虫零到访 | 分桶里某类客户端计数为0 | 发现层 | 补sitemap、内外链、外部提及 |
| 高频回访全404 | 同前缀大量404/410 | URL结构 | 查迁移残留、规范化、做对跳转 |
| 只取到模板空壳 | 请求成功但抓取字节数异常小且雷同 | 取用/渲染层 | 主内容进首屏HTML |
| 伪UA吃爆带宽 | 自称浏览器但行为像批量抓取 | 成本/过载 | IP校验后限速或WAF拦 |
| 踩robots禁区仍抓 | 持续命中Disallow路径 | 策略失效 | 换工具:服务器/WAF,不再靠robots |
| 回访全量无304 | 同一页反复200全量、回访频率走低 | 缓存/条件请求 | 支持ETag/If-Modified-Since |
举两个真实的。一个做出海宠物用品的独立站,日志里ClaudeBot在一个带筛选参数的URL空间里疯狂打转,同一前缀几万条请求,状态码还都是200。这不是内容问题,是URL空间没收口,爬虫把每个筛选组合都当成了新页面,既浪费它的预算也浪费你的带宽,正经文章页反而没被好好抓。修法不在内容侧,在把这类参数URL用规范化和robots收掉。另一个是前面那个B2B SaaS文档站,ClaudeBot把变更日志页当高价值页天天高频回访,但因为站点对任何请求都不返回304,它每次都全量重读,几周后回访频率明显下降——这恰恰是“回访全量无304”这条病的活样本。能在日志里一眼分出这是“URL空间病”、那是“缓存病”,而不是笼统归成“AI不抓我”,正是逆向的价值所在。
逆向完之后,robots、llms.txt、渲染到底怎么配才有用?
到这一步才轮到配置,而且配置的依据是你前面实测出来的东西,不是模板。原则就一句:对每一类客户端,问四个问题——它读不读robots、读不读llms.txt、执不执行JS、它来抓对我是收益还是纯成本,然后给一个明确动作。
| 实测结论 | 对它该用的工具 | 典型动作 |
|---|---|---|
| 遵守robots、是检索型(收益) | robots放行 + 内容侧优化 | 放行关键目录,喂干净结构与首屏正文 |
| 遵守robots、纯训练且你不想进语料 | robots | 精准Disallow,无需上服务器层 |
| 不遵守robots、有价值 | 限速 + 监控 | 按IP限速保住服务,不一刀切 |
| 不遵守robots、纯成本/伪装 | WAF + IP/UA双校验 | 校验后拦截,robots对它无意义 |
robots的分客户端策略,和它真实的边界
robots是一份君子协定,它的全部效力建立在对方愿意遵守的前提上。对声明并实测遵守的客户端(多数训练型),用robots做粗粒度的放行与禁区划分,是有效且低成本的。但对实测不遵守的,写再多Disallow都是写给自己看的安慰剂,只能靠服务器层、WAF、UA加IP双校验去硬挡。还有个常被忽略的点:robots的Disallow是“别抓”,不是“别收录也别用”,它管的是抓取入口,管不了一个已经被别处提及的URL被当作实体收进知识里。想把这套协议的机制、优先级、各引擎差异彻底搞清楚,可以专门补一下 robots.txt协议机制,这里只强调一点:robots能不能管住一个客户端,是实测结论,不是文档承诺。
llms.txt:先回答“谁会读它”,再决定写不写、写什么
必须把话说透:llms.txt目前是一个社区提案,不是被广泛执行的标准,主流大模型引擎当前多数并不会主动来读你的llms.txt。所以正确顺序是——先从日志里确认到底有没有、有谁来请求过这个文件,再决定值不值得认真维护它。它真正不那么虚的价值有两块:一是给少数确实会读的客户端、以及你自己内部的检索增强或agent一个干净的内容地图;二是当你自建RAG、做站内AI问答时,它就是一份现成的“最权威页面清单”,省得每次重新爬自己。
写它有讲究:只列规范URL加一句话说明,和sitemap、规范页保持一致,别堆关键词、别塞营销话术、别和正文打架。前面提到的那个跨境美妆Shopify站,当初就是把llms.txt当成了关键词页,堆了一大段卖点词。保哥给的纠正只有一句:它是地图文件,不是排名文件。你在地图上画满广告,照着导航的人只会更找不到路。把它改回只列规范URL加简述、和站点结构对齐之后,至少它不再是噪音了——但指望它单独带来排名,本来就是对它的误解。
渲染与字节策略——让AI花最少预算拿到主内容
这一节其实和前面字节预算那段闭环了。可落地的动作就几条:主内容必须在服务端首次返回的HTML里;最关键的事实、结论、定义往前放,别让它排在一堆模板和相关推荐后面;模板性的、装饰性的东西能延迟加载就延迟。一个具体的排序原则是:把“一个人问这个页面,最想要的那句答案”放在正文第一屏、第一段,因为检索管线截断是从后往前截,越靠前越安全。你会发现,这些动作既让不渲染的AI客户端拿得到内容,又顺便改善了真实用户的首屏体验和站点性能,没有一处是只为机器做的。
别为AI爬虫单独做一套内容
有人会动“给爬虫看一套、给用户看另一套”的念头。这是cloaking,风险高、收益低,一旦被判定后果严重,而且现在判定它的手段比十年前强太多。更要命的是它根本没必要——上面那些动作本来就是人机同利的,单独伺候机器纯属自找麻烦,还得额外维护一套逻辑,多一处出错的地方。
这套逆向该多久做一次?怎么固化成长期能力?
最现实的一句忠告:AI客户端的清单和行为,基本每个季度都在变。新的UA会冒出来,某个开关和主爬虫的关系会调整,某个原来不读robots的开始读了,某个原来不读llms.txt的开始读了。你这次辛辛苦苦逆向出来的结论,三个月后有相当一部分会过期。所以一次性地大干一场、然后就不管了,性价比其实很低,过期的结论比没有结论更危险,因为你以为自己知道。
一张可以直接抄的季度自检清单
把逆向固化,本质是把“每季度要重新回答的问题”列死,让模拟器和日志分桶按周期自动复跑,只在结果偏离阈值时才需要人介入:
| 每季度重答 | 数据来源 | 偏离阈值的动作 |
|---|---|---|
| UA清单有没有新增/改名 | 官方公告 + 日志里的未知UA | 更新分桶配置,补测指纹 |
| 各客户端到访量同比怎么变 | 日志分桶 | 突降查发现层,突增查成本 |
| robots遵守度有没有变 | 禁区命中检测 | 由“信协定”改“上WAF” |
| llms.txt有没有被真读 | 该文件的请求日志 | 有人读了才值得加码维护 |
| 关键页字节预算有没有回归 | 模拟器对照组的gap值 | 主内容退回JS才出现就报警 |
| 304占比有没有掉 | 状态码分桶 | 掉了查缓存头与CDN配置 |
团队定位与给业务方的口径
最后一件事,关于预期管理,也最容易被做这块的人自己搞混。AI爬虫来抓你,不等于AI引用了你,更不等于带来了流量。这是三件递进的事,中间各有一道坎:抓到了不一定被选进答案,被选进答案不一定带点击,带了点击不一定转化。逆向工程解决的是最底层那一环——确保机器能发现你、取得到你、读得懂你的主内容;它是必要条件,不是充分条件。对内汇报时把这个口径说清楚,别把“被抓到了”包装成“被推荐了”,否则下个季度数据不涨,团队的信任就崩了,下次再要资源就难了。想把抓取、索引、排名这条链彻底理顺,回头补一篇搜索引擎抓取与索引的底层流程会很值。逆向给你的是地基,不是屋顶;但没有这个地基,上面盖什么都是空中楼阁。
常见问题解答
AI爬虫和Googlebot是一回事吗?
不是。Googlebot是搜索抓取,AI客户端还分训练、检索、用户即时取三类,行为差异极大;多数不执行JS,对robots遵守度也参差,必须分开看分开配。
写了llms.txt,AI就会来读吗?
多数主流引擎当前并不会主动读llms.txt,它是社区提案不是标准。先用日志确认有谁真的请求过它,再决定要不要认真维护;把它当地图文件,不是排名文件。
User-Agent能不能直接信?
不能。UA是纯文本可随意伪造,Bytespider、假GPTBot很常见。要靠反向DNS加官方公布IP网段双向校验,UA只能当第一道粗筛,不能当判定依据。
AI爬虫被robots挡住会怎样?
看类型。训练抓取被挡大致是少进语料;检索抓取被挡,等于在AI答案里直接消失。而且实测不遵守robots的客户端,只能靠服务器或WAF加IP校验来挡。
这套逆向多久该做一次?
建议按季度。AI客户端清单和行为基本每季度都在变,一次性逆向三个月就过期,最好把模拟器和日志分桶做成定时任务,加阈值告警,只在偏离时人工介入。
该不该专门给AI爬虫单独做一套内容?
不建议。给爬虫和用户看不同内容属于cloaking,风险高收益低。正确做法是主内容进首屏HTML、事实前置、噪音后置,人和机器同时受益,不存在取舍。
权威参考资料
本文标题:《AI爬虫到底抓你什么?代码逆向出爬虫真实偏好8步实操》
本文链接:https://zhangwenbao.com/ai-crawler-reverse-engineering-fetch-behavior-llms-strategy.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0