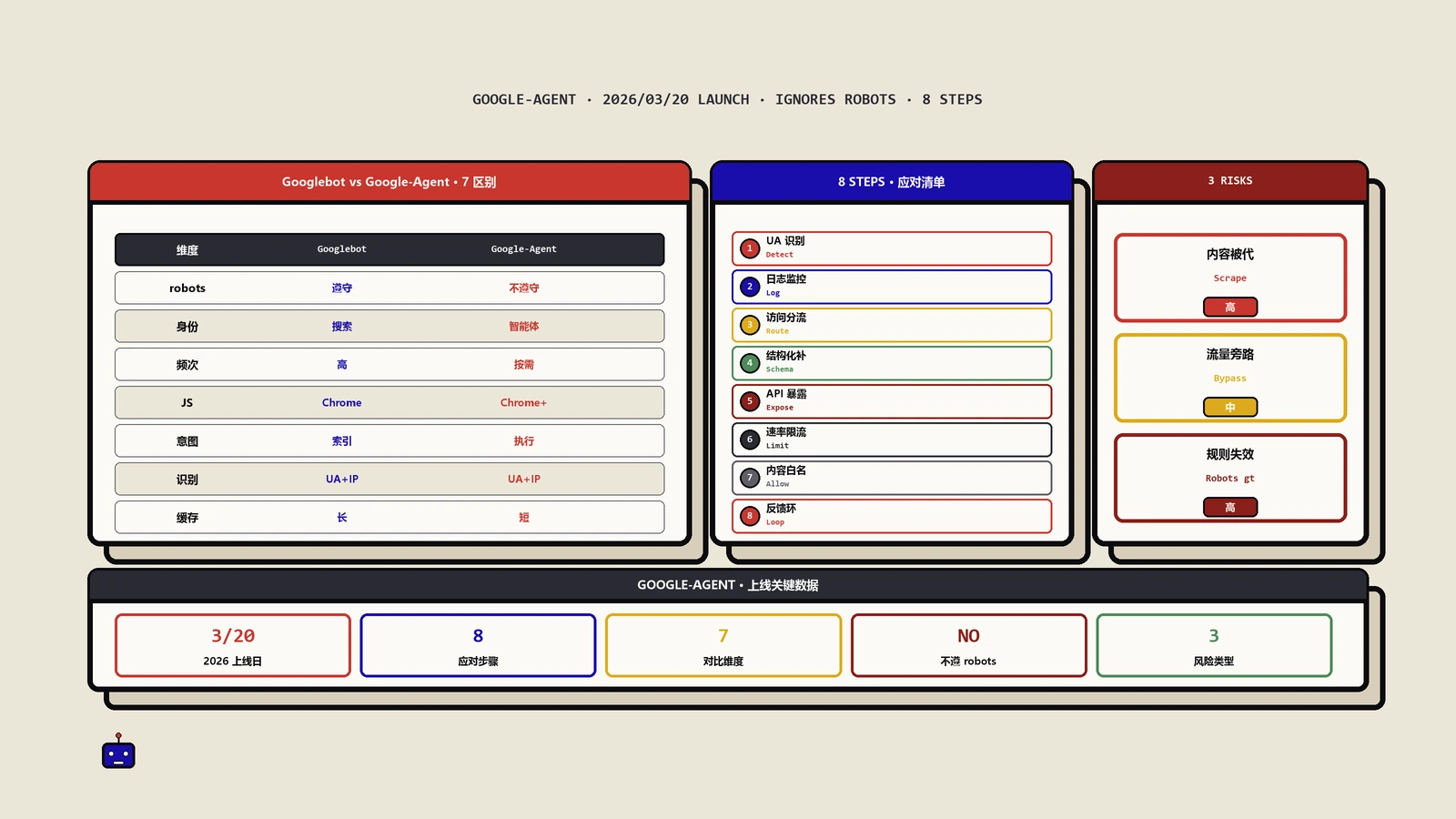
Google-Agent是什么?AI智能体爬虫怎么识别和应对
本文目录
- Google-Agent到底是什么
- 官方定义
- Google-Agent的User-Agent字符串
- IP地址范围
- Google提到的关联产品:Project Mariner
- Google-Agent与Googlebot的核心区别
- 为什么Google-Agent的出现意义重大
- 从"搜索索引"到"代理交互"的范式转变
- 代理商务(Agentic Commerce)的基础设施
- web-bot-auth协议的实验信号
- 实操指南:如何识别和监控Google-Agent
- 服务器日志过滤方法
- 验证请求真实性
- Google Analytics和数据统计的影响
- 网站主的应对策略
- 不要急着屏蔽Google-Agent
- 检查CDN和WAF的封锁规则
- 确保网站的AI可读性
- 为Agentic SEO做前瞻布局
- robots.txt中对Google-Agent的配置建议
- Google-Agent的时间线与未来展望
- 已知的时间线
- 保哥的预测
- 实操检查清单:Google-Agent 时代的网站准备
- 常见问题解答
- Google-Agent和Googlebot是同一个东西吗?
- Google-Agent会遵守我的robots.txt规则吗?
- 我需要在robots.txt中屏蔽Google-Agent吗?
- Google-Agent现在的流量大吗?
- Google-Agent会影响我的网站SEO排名吗?
- 如何验证一个自称是Google-Agent的请求是否真的来自Google?
- Google-Agent会对我的网站执行什么操作?
- 权威参考资料
摘要:Google新发布的Google-Agent用户代理,是AI智能体时代的新爬虫。本文讲它的工作原理、和Googlebot的核心区别、为什么它的出现意义重大,给从服务器日志识别监控、robots.txt配置策略到网站主的应对,再附一份Google-Agent时代的网站准备检查清单,帮你为AI Agent时代做好准备。
2026年3月20日,Google悄悄在其官方爬虫文档中新增了一个名为"Google-Agent"的用户代理(User Agent)。这不是一次普通的文档更新——它标志着Google正式把AI智能体(AI Agent)的网页访问行为从"实验室阶段"推向了"生产环境"。
保哥第一时间注意到了这个变化。说实话,虽然AI Agent的概念已经炒了好几年,但当Google真正把它写进爬虫文档、分配独立的User Agent字符串、公布IP地址范围的那一刻,事情就从"趋势讨论"变成了"落地现实"。
今天这篇文章,保哥要把Google-Agent这件事从底层原理到实操应对全部讲透,帮你在AI Agent大规模到来之前,把准备工作做到位。
Google-Agent到底是什么
官方定义
根据Google开发者文档的说明,Google-Agent是一种用户触发的抓取工具(User-Triggered Fetcher),由托管在Google基础设施上的AI智能体使用,用于根据用户请求浏览网页并执行操作。
这里有两个关键词需要注意:
"用户触发"——这意味着Google-Agent不像Googlebot那样自动后台运行。每一次Google-Agent的访问,背后都对应着一个真实用户的操作指令。比如一个用户对AI说"帮我找三家性价比高的深圳SEO服务商并比较报价",AI智能体就会代替用户去访问相关网站、抓取信息、分析内容。
"执行操作"——这比单纯的"浏览页面"更进一步。Google-Agent不仅会读取你的页面内容,未来还可能会填写表单、完成注册、发起询盘,甚至代替用户下单。
Google-Agent的User-Agent字符串
Google-Agent有两种版本的UA字符串:
桌面版:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Agent; +https://developers.google.com/crawling/docs/crawlers-fetchers/google-agent) Chrome/W.X.Y.Z Safari/537.36移动版:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-Agent; +https://developers.google.com/crawling/docs/crawlers-fetchers/google-agent)其中 W.X.Y.Z 是Chrome版本号占位符,会随着实际使用的Chrome版本动态变化。
IP地址范围
Google为Google-Agent专门发布了独立的IP范围文件:user-triggered-agents.json。注意这个文件和Googlebot的IP范围文件是分开的,后面讲防火墙白名单配置时正是靠它来区分两类爬虫。
Google提到的关联产品:Project Mariner
Google在文档中明确提到了 Project Mariner 作为Google-Agent的使用案例。这是一个DeepMind开发的AI智能体研究原型,可以在Chrome浏览器中代替用户完成各类操作,比如浏览网页、比较产品、填写表单等。
目前Project Mariner还处于受限的测试阶段,但Google把它写进正式文档,说明商业化和规模化已经提上了日程。
Google-Agent与Googlebot的核心区别
很多人看到"又多了一个Google爬虫"可能觉得无所谓,但Google-Agent和我们熟悉的Googlebot有本质性的区别。保哥这里做一个详细对比:
| 对比维度 | Googlebot | Google-Agent |
|---|---|---|
| 触发方式 | 自动后台运行,持续抓取 | 用户主动触发,按需访问 |
| 主要目的 | 索引网页内容,用于搜索排名 | 代替用户浏览、评估、执行操作 |
| 遵守robots.txt | 严格遵守 | 通常忽略robots.txt |
| IP范围文件 | googlebot.json | user-triggered-agents.json |
| 交互深度 | 主要读取页面内容 | 可能执行表单提交、点击等交互 |
| 流量性质 | 机器人流量 | 介于机器人和真实用户之间 |
| 当前流量规模 | 非常大 | 极少(刚开始部署) |
最关键的区别是:Google-Agent作为用户触发的抓取工具,通常不遵守robots.txt规则。 这和Googlebot完全不同。Google的逻辑很简单——既然是用户主动让AI去访问你的网站,那就类似于用户自己访问,不应该被robots.txt阻止。
这一点对站长的影响非常大,后面会详细讲应对策略。
为什么Google-Agent的出现意义重大
从"搜索索引"到"代理交互"的范式转变
过去20年,网站和搜索引擎之间的关系很简单:搜索引擎爬虫来抓取你的内容,建立索引,用户搜索时展示给他们,用户点击链接后来到你的网站。
Google-Agent的出现打破了这个模式。未来的用户旅程可能是这样的:用户对AI说"帮我找一家靠谱的跨境电商代运营公司"→ AI智能体自主浏览多个网站 → 评估服务内容、价格、口碑 → 直接返回推荐结果甚至帮用户填写咨询表单 → 用户全程可能都没有直接访问你的网站。
这意味着你的网站不仅要对"人"友好,还要对"AI智能体"友好。如果你对 GEO(生成式搜索优化)策略 有所了解,你会发现Google-Agent的出现让GEO的重要性又上了一个台阶。
代理商务(Agentic Commerce)的基础设施
Google-Agent本质上是代理商务(Agentic Commerce)的技术基座。想象一下这些场景:
- AI智能体代替用户比较多家供应商的报价
- AI智能体自动完成酒店预订和机票购买
- AI智能体帮用户追踪商品价格并在最佳时机下单
- AI智能体审核供应商的资质证书和企业信息
每一个场景背后,都是Google-Agent在代替用户访问网站、抓取信息、执行操作。当这些场景规模化之后,不被Google-Agent"理解"和"信任"的网站,将直接丧失一大块潜在商业机会。
web-bot-auth协议的实验信号
还有个容易被忽略的细节:Google在文档里提到,自己正在尝试使用 web-bot-auth 协议,并用 https://agent.bot.goog 作为身份标识。
这个 web-bot-auth 是IETF正在起草的一个新网络协议,旨在为AI智能体的网页访问建立标准化的身份认证和授权机制。简单来说,未来网站可能可以通过这个协议来:
- 验证访问你网站的AI智能体是否真的来自Google
- 对不同的AI智能体设置不同的访问权限
- 授权AI智能体执行特定的操作(比如允许查看价格但不允许自动下单)
这说明Google已经在为AI Agent的大规模部署构建基础设施了。
实操指南:如何识别和监控Google-Agent
服务器日志过滤方法
监控Google-Agent最直接的方法就是分析服务器日志。如果你使用的是Nginx或Apache服务器,可以用以下命令快速过滤:
Nginx/Apache(通用Linux命令):
# 过滤出所有Google-Agent的访问记录
grep "Google-Agent" /var/log/nginx/access.log
# 统计Google-Agent的访问次数
grep -c "Google-Agent" /var/log/nginx/access.log
# 查看Google-Agent访问的具体页面
grep "Google-Agent" /var/log/nginx/access.log | awk '{print $7}' | sort | uniq -c | sort -rn
# 查看Google-Agent的来源IP
grep "Google-Agent" /var/log/nginx/access.log | awk '{print $1}' | sort | uniq -c | sort -rn如果你的网站使用了CDN(如Cloudflare、AWS CloudFront),注意要检查CDN的原始日志,而不仅仅是源站日志,因为部分请求可能在CDN层就被处理了。
想要更系统地分析爬虫行为,保哥建议使用专业的 服务器日志分析工具 来可视化呈现爬虫的抓取频率、状态码分布和访问路径,这样能更高效地发现异常。
验证请求真实性
和所有User-Agent一样,Google-Agent的UA字符串也可能被伪造。验证方法和验证Googlebot一样,通过反向DNS查找:
# 第一步:对访问IP做反向DNS查找
host 66.249.xx.xx
# 预期结果应该匹配以下模式之一:
# xxx-xxx-xxx-xxx.gae.googleusercontent.com
# google-proxy-xxx-xxx-xxx-xxx.google.com
# 第二步:正向DNS验证
host xxx-xxx-xxx-xxx.gae.googleusercontent.com
# 确认解析回的IP和原始IP一致另外,你也可以直接对比Google公布的 user-triggered-agents.json 中的IP范围,确认访问IP是否在白名单内。
Google Analytics和数据统计的影响
这是一个容易被忽略的技术细节:Google-Agent的访问是否会出现在你的Google Analytics(GA4)数据中?
答案是不确定。传统的搜索引擎爬虫(如Googlebot)通常不会触发GA4的JavaScript追踪代码,因此不会出现在分析数据中。但Google-Agent是在Chrome浏览器内核中运行的,理论上可能会触发JavaScript执行。
保哥建议你现在就在GA4中设置一个自定义段(Segment),过滤User-Agent包含"Google-Agent"的会话,这样一旦有流量进来就能立即识别。
网站主的应对策略
不要急着屏蔽Google-Agent
保哥看到有些技术博主第一反应是"赶紧在robots.txt里屏蔽Google-Agent"。这是一个非常短视的做法,理由有三:
第一,Google-Agent本身就不遵守robots.txt,你屏蔽了也没用。
第二,Google-Agent代表的是真实用户的操作意图。屏蔽它等于拒绝了潜在客户。
第三,随着AI Agent的普及,能被AI智能体"理解"和"推荐"的网站将获得巨大的流量和商业优势。
正确的做法是:确保Google-Agent能顺利访问你的网站,同时优化你的网站以适应AI智能体的评估方式。
检查CDN和WAF的封锁规则
这一条是最紧急的实操行动。很多网站使用了Cloudflare、Akamai、AWS WAF等安全服务,这些服务的默认规则可能会将Google-Agent的请求识别为异常流量而自动封锁。
具体检查步骤:
- 登录你的CDN/WAF管理后台
- 检查防火墙规则中是否有针对未知User-Agent的封锁策略
- 将Google-Agent的IP范围(来自user-triggered-agents.json)添加到白名单
- 检查速率限制(Rate Limiting)规则,确保不会对Google-Agent触发限流
- 如果你使用了Bot管理方案(如Cloudflare Bot Management),确认Google-Agent被分类为"已验证的好爬虫"
保哥推荐使用 爬虫User-Agent识别工具 来快速识别和分类访问你网站的各类爬虫,包括Google-Agent在内的AI爬虫。
确保网站的AI可读性
Google-Agent在评估你的网站时,和传统的Googlebot有不同的"阅读方式"。它更像一个真实用户——会关注页面的视觉呈现、交互体验、信息的结构化程度。
核心优化要点:
- 结构化数据要完整:确保你的页面部署了完整的Schema.org标记,特别是Product、LocalBusiness、FAQPage、HowTo等类型。AI智能体理解结构化数据的效率远高于理解非结构化的纯文本。
- 关键信息不要藏在JavaScript渲染层:虽然Google-Agent运行在Chrome内核中理论上能执行JavaScript,但为了稳妥起见,核心商业信息(价格、联系方式、服务描述)应该在HTML源码中直接可见。
- 表单和交互流程要简洁:如果你的网站有询盘表单、注册流程或下单页面,确保流程简洁、标签语义明确。未来AI智能体可能需要代替用户完成这些操作。
- 页面加载速度要快:AI智能体代替用户访问时,也会受到页面加载速度的影响。如果你的页面加载超过3秒,AI智能体可能直接跳过去评估下一个竞争对手。
为Agentic SEO做前瞻布局
保哥认为,Google-Agent的发布标志着"Agentic SEO"(代理搜索优化)正式成为一个新的SEO分支。和传统SEO主要关注关键词排名不同,Agentic SEO关注的是:
- 你的网站能否被AI智能体准确理解
- 你的品牌信息能否在AI智能体的评估中脱颖而出
- 你的业务流程能否与AI智能体无缝对接
如果你还不了解AI搜索的运作方式,建议先阅读保哥之前写的 Google AI Mode深度体验文章,理解Google在AI搜索方向的整体布局,这样更容易把握Agentic SEO的核心脉络。
具体布局建议:
- 建立话题权威性:在你的核心业务领域持续输出高质量的深度内容,让AI智能体在评估供应商时将你识别为行业专家。
- 强化品牌实体信号:确保你的品牌在Google知识图谱、维基百科、行业目录等权威来源中有明确的实体标记。
- 优化E-E-A-T信号:经验、专业度、权威性、可信度——这四个维度在AI智能体的评估体系中权重极高。
- 关注WebMCP等新兴协议:WebMCP是一种让网站与AI智能体进行结构化通信的新标准,虽然目前还在早期阶段,但值得持续关注。
robots.txt中对Google-Agent的配置建议
虽然Google-Agent不遵守robots.txt,但保哥建议你在robots.txt中明确添加Google-Agent的规则,这样做有两个好处:一是表明你的网站主动欢迎AI智能体访问;二是为未来可能的授权机制做准备。
使用 robots.txt生成与验证工具 可以帮你快速生成符合规范的配置。以下是推荐的配置示例:
# 允许Google-Agent访问所有页面
User-agent: Google-Agent
Allow: /
# 但限制对敏感目录的访问
Disallow: /admin/
Disallow: /checkout/
Disallow: /account/Google-Agent的时间线与未来展望
已知的时间线
- 2026年3月20日:Google在官方文档中新增Google-Agent条目
- 2026年3月25日:文档更新日志确认Google-Agent将在接下来几周内逐步部署
- 当前状态:早期部署阶段,流量极低
保哥的预测
基于目前Google在AI Agent方面的布局速度,保哥做几个预测:
短期(2026年Q2-Q3):Google-Agent的流量仍然很低,主要出现在Google AI Mode和Project Mariner的测试用户群中。但这是建立监控基线的黄金窗口期。
中期(2026年Q4-2027年):随着Google AI Mode的全面铺开和Agent功能的成熟,Google-Agent的流量将出现显著增长。特别是在电商、旅游、B2B等交易属性强的行业,AI代理下单和询盘将成为常态。
长期(2027年以后):AI智能体将成为互联网的"第二类用户"。网站优化将从"SEO+GEO"双轨制演变为"SEO+GEO+ASO(Agentic Search Optimization)"三轨并行的格局。
实操检查清单:Google-Agent 时代的网站准备
把上面的策略落到具体执行时,建议按以下清单逐项推进,确保不会错过任何关键环节:
- 日志监控:是否已经在 Nginx/Apache 日志中建立了对 Google-Agent UA 字符串的过滤规则?是否设置了周报机制汇总访问数据?
- DNS 验证:是否在 fail2ban 或 WAF 中加入了 Google-Agent 反向 DNS 验证脚本,防止伪造 UA 被混入白名单?
- CDN/WAF:Cloudflare、Akamai、AWS WAF 等服务的默认规则是否会把 Google-Agent 误判为异常流量?是否已经加入白名单和速率限制豁免?
- GA4 自定义段:是否在 GA4 中创建了过滤 User-Agent 含 Google-Agent 的自定义段,方便流量增长时立刻分析?
- Schema 部署:核心商业页面(产品、服务、价格、联系方式)是否都部署了对应的 Schema.org 标记?
- 关键信息可见性:核心商业信息是否都在 HTML 源码中直接可见,而非依赖 JavaScript 渲染后才出现?
- 表单友好度:询盘、注册、下单表单的字段是否使用了语义化标签(label、aria-label、autocomplete)便于 AI 代填?
- 页面性能:核心页面的 LCP 是否在 2.5 秒以内?整体 Core Web Vitals 是否达标?
- 品牌实体:Google 知识图谱、维基百科、行业目录中的品牌信息是否完整、一致、可被交叉验证?
- robots.txt 配置:是否在 robots.txt 中显式声明欢迎 Google-Agent,同时限制敏感目录的访问?
- web-bot-auth 关注:是否订阅了 IETF web-bot-auth 协议的更新动态,为未来的授权机制做准备?
- 季度复盘:是否制定了季度复盘机制,跟踪 Google-Agent 流量增长趋势和访问行为变化?
常见问题解答
Google-Agent和Googlebot是同一个东西吗?
不是。Googlebot是Google用于自动抓取和索引网页的搜索爬虫,属于后台自动运行的常规爬虫。而Google-Agent是用户触发的AI智能体,只有在真实用户发出指令后才会访问你的网站。两者的User-Agent字符串、IP范围文件、遵循的规则都不同。
Google-Agent会遵守我的robots.txt规则吗?
通常不会。Google官方将Google-Agent归类为"用户触发的抓取工具",这类工具的特点就是通常忽略robots.txt规则。Google的逻辑是:既然是用户主动要求AI去访问某个网站,就相当于用户自己在访问。
我需要在robots.txt中屏蔽Google-Agent吗?
保哥强烈不建议这样做。首先,屏蔽了也不一定有效;其次,Google-Agent代表的是潜在的商业机会——真实用户正在通过AI智能体评估你的网站和服务。屏蔽它等于把客户拒之门外。
Google-Agent现在的流量大吗?
非常小。Google-Agent从2026年3月20日才开始部署,目前还在早期阶段。你的服务器日志中很可能还看不到任何Google-Agent的记录。但保哥建议现在就设置好监控,这样能在流量增长时第一时间掌握数据。
Google-Agent会影响我的网站SEO排名吗?
目前不会直接影响排名。Google-Agent的访问目的不是建立搜索索引,而是代替用户浏览和评估内容。但从长远来看,如果你的网站不能被AI智能体良好理解,你将在"AI推荐"这个新的流量渠道中处于劣势。
如何验证一个自称是Google-Agent的请求是否真的来自Google?
使用反向DNS查找验证。对请求IP执行 host 命令,确认域名是否匹配 *.gae.googleusercontent.com 或 google-proxy-*.google.com 模式,然后再做正向DNS验证确保IP一致。也可以直接比对Google公布的user-triggered-agents.json中的IP范围。
Google-Agent会对我的网站执行什么操作?
目前主要是浏览和评估,也就是读取页面内容、分析信息。但Google的文档明确提到了"执行操作"(perform actions),这意味着未来Google-Agent可能会代替用户提交表单、完成注册、发起交易等。具体能执行哪些操作取决于Google的产品迭代。
权威参考资料
本文标题:《Google-Agent是什么?AI智能体爬虫怎么识别和应对》
本文链接:https://zhangwenbao.com/google-agent-ai-crawler.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0