Opus 4.8基准刷新后,AI SEO自动化能把哪些活交给Agent自己跑?
本文目录
- Opus 4.8这张基准表,到底在替SEO人回答什么问题?
- 为什么说agentic coding冲到69.2%,是技术SEO的一道分水岭?
- 电脑操作83.4%,意味着哪些SEO重复劳动能真正甩给机器?
- 终端编码74.6%,能帮SEO自动化扛下哪些脏活累活?
- 知识工作1890分和财务分析53.9%,这两个数字该怎么读?
- 基准分数高,为什么不等于你的SEO任务能直接外包给AI?
- 一套能落地的AI SEO自动化分层委托清单,怎么搭?
- 跑agentic SEO自动化,团队踩过哪些真实的坑?
- 这波agentic模型,会怎么重塑SEO团队的活法?
- 常见问题解答
- Opus 4.8的基准分数这么高,是不是意味着SEO工作很快就不用人了?
- SWE-Bench Pro的69.2% 和OSWorld的83.4%,哪个对SEO自动化更重要?
- 为什么财务分析只有53.9%,这对SEO算账类工作意味着什么?
- 哪些SEO任务现在可以放心交给AI Agent自动跑?
- 用Agent做SEO自动化,最容易踩的坑是什么?
- 权威参考资料
摘要:基准跑分再漂亮,也不等于你能闭眼把SEO任务丢给Agent。Opus 4.8在编码、电脑操作、知识工作这几条线上确实集体登顶,但真正决定一项活能不能自动化的,是它可不可验证、以及你这个站有多特殊,而不是那串漂亮的百分比。这篇文章帮你做三件事:读懂这张基准表在替SEO人回答什么、按“可委托度”把手里的活分级、再给每一层配上不翻车的护栏。
这阵子做SEO的圈子里被一张表刷了屏。Opus 4.8在2026年5月底放出来,距离上一版Opus 4.7才41天,节奏快得像在赶火车。但真正让做SEO的人坐直身子的,不是“又快了一档”这种话术,而是它在几个跟我们日常活计高度相关的基准上,把分数顶到了一个新位置。
编码、终端操作、电脑界面操作、跨学科推理、知识工作、财务分析——这六项里,有四项是SEO自动化每天都在碰的东西。一个能写代码、能点鼠标、能读懂复杂文档、还能跑数据分析的模型,意味着我们过去那些“只能人肉硬扛”的活,第一次有了被量化评估“到底能不能交出去”的可能。
所以这篇不打算复述发布会话术,也不想给谁站台。要干的事很简单:把这张表当成一份能力体检报告,逐项翻译成SEO从业者听得懂的话——哪些任务现在真的能甩给Agent自己跑,哪些甩出去会出事,中间那条线到底画在哪。这是一个早就该有人认真画一画的边界。
Opus 4.8这张基准表,到底在替SEO人回答什么问题?
先把六个数字摆出来,顺手翻译成人话。这样后面聊自动化才有共同语言,不然容易各说各的。
| 基准能力 | 测的是什么 | Opus 4.8成绩 | 对SEO自动化意味着 |
|---|---|---|---|
| Agentic coding(SWE-Bench Pro) | 从真实代码仓库里自主修Bug、写补丁 | 69.2%(同组最高) | 改schema、写重定向规则、调性能代码这类“技术SEO编码活”能不能交 |
| Agentic terminal coding(Terminal-Bench 2.1) | 在命令行里自主完成多步任务 | 74.6%(GPT-5.5以78.2% 居首) | 日志分析、批量脚本、爬虫、sitemap生成这类“脏活”能扛多少 |
| Multidisciplinary reasoning(Humanity's Last Exam) | 跨学科难题推理 | 无工具49.8%/带工具57.9%(均最高) | 策略判断、复杂诊断这类需要“想清楚”的活,靠谱程度几何 |
| Agentic computer use(OSWorld-Verified) | 像人一样操作真实操作系统界面 | 83.4%(同组最高) | 登后台改TDK、GSC取数、截图取证这类“点鼠标重复劳动”能不能托管 |
| Knowledge work(GDPval-AA) | 真实经济价值的知识工作产出质量 | 1890(同组最高) | 写报告、做诊断文档、整理竞品分析这类“脑力产出”的水准 |
| Agentic financial analysis(Finance Agent v2) | 自主完成财务分析任务 | 53.9%(同组最高,但绝对值偏低) | SEO投入产出、预算分配这类“算账”能信几分 |
看出门道了吗?这六项不是孤立的跑分,它们刚好对应SEO工作流里四种不同性质的劳动:写代码(技术改造)、点界面(后台操作)、读数据(取数算账)、想问题(策略推理)。一个Agent想端到端替你跑SEO,这四样得样样过关,缺一样都会在某个环节卡壳。
而这张表第一次让我们能分开看:哪一样已经熟透了,哪一样还半生不熟。比如电脑操作83.4% 已经相当能打,而财务分析虽然同组第一,绝对值才53.9%——一半多一点的题做对,这种水平你敢让它单独给老板汇报SEO预算吗?换成谁都得捏把汗。这个差距,正是这篇文章要反复掰扯的核心。具体的分数细节,Anthropic把更完整的能力评估放进了它的Claude Opus 4.8官方公告与系统卡,有兴趣可以对着原始口径核一遍,别只信二手解读。
为什么说agentic coding冲到69.2%,是技术SEO的一道分水岭?
SWE-Bench Pro这个基准,测的不是“会不会写for循环”,而是把模型扔进一个真实的代码仓库,给它一个像“修复这个登录Bug”这样的任务,看它能不能自己读懂代码、定位问题、写出能通过测试的补丁。它和入门级编程题最大的区别,就是SWE-bench官方排行榜里收录的全是来自真实开源项目的工单,上下文又长又乱。这跟SEO有什么关系?关系大了。
技术SEO里有一大块活,本质就是“在别人写好的代码里做精准小手术”:给产品页补Product schema、把分页参数的canonical写对、给多语言站配hreflang、改robots规则把抓取预算从垃圾页挪到赚钱页、压缩首屏阻塞渲染的脚本拉Core Web Vitals。这些活的共同点是——改动不大,但错一个字符就翻车,而且需要读懂上下文才能动手。
69.2% 这个分数(领先Opus 4.7的64.3%、GPT-5.5的58.6%、Gemini 3.1 Pro的54.2%)说明什么?说明在“读懂一段陌生代码再做正确改动”这件事上,模型已经能稳定接住接近七成的真实任务。换算到技术SEO,意味着下面这些活,现在交给Agent跑、人来审,是真的能省时间的:
- 结构化数据批量补全:给几百个产品页生成符合规范的JSON-LD,过去外包要排期一周,现在一个下午能出初稿。
- 重定向规则梳理:网站改版时,让Agent读旧URL清单和新结构,自动生成301映射表,再人工抽查链路有没有断链或循环。
- 主题模板里的SEO标签注入:在Typecho、Shopify、Headless这类不同技术栈上改meta、改OG、改面包屑结构,模型能跨栈搬运,省去“每套系统都得请一个懂行的”的成本。
- 性能优化的代码改动:找出阻塞渲染的资源、加lazy-load、改图片格式,这种有明确度量(PSI分数)的活,机器跑起来比人有耐心。
这道“分水岭”的意思是:技术SEO里那些有标准答案、改完能立刻验证对错的编码活,已经过了“值不值得交给Agent”的临界点。实战里有个真实例子:给一个3C出海独立站做schema重构,先让Agent把200多个SKU页的结构化数据草稿全跑出来,人只做规范校验和抽查,整体工时砍掉六成。这种“可验证的代码活”,正是AI SEO自动化最先成熟的地带。想看更系统的用法清单,可以翻这篇AI做SEO的20个实战用法,那里把内容、技术、数据三块都拆开过。
但要泼一盆冷水:69.2% 也意味着三成会错。schema写错语法Google顶多忽略,但重定向链写错能让一批页面集体掉出索引。所以分水岭的另一面是——交得出去不等于不用看,越是影响面大的改动,人工那一关越不能省,这条原则后面会反复出现。
电脑操作83.4%,意味着哪些SEO重复劳动能真正甩给机器?
如果说编码能力解决的是“改代码”,那OSWorld这个基准测的就是另一件更接地气的事:模型能不能像人一样操作电脑界面——打开浏览器、点按钮、填表单、在不同软件之间搬数据。它衡量的是“鼠标键盘活”,而SEO工作里这种活多得吓人。
83.4% 是个相当高的分数。要知道,OSWorld这套基准刚出来时,最强的模型成功率才12% 出头,而人类大概能完成七成多。OSWorld基准的官方说明里写得很清楚,它收录的是几百个真实操作系统里的开放式任务,难度不低。短短一年多能从12% 冲到83.4%,说明“界面操作”这条线已经从“勉强能动”跨到了“多数能成”。
翻译成SEO日常,下面这些“点到手抽筋”的重复劳动,现在具备了托管给Agent的基础:
- GSC与GA4取数:登录Search Console,筛日期、导出查询词、抓覆盖率报告,再贴进表格——这种纯搬运,机器比人快且不烦。
- 批量改后台TDK:在WordPress、Shopify后台逐页改标题描述,过去实习生干一天,现在Agent按清单跑。
- 排名与收录截图取证:给客户做月报要的那些SERP截图、收录状态截图,按模板批量出,不用一张张手动截。
- 跨工具数据拼接:从Ahrefs拉外链、从GSC拉点击、从后台拉转化,拼成一张诊断表,机器在几个标签页之间来回切的耐心远超人类。
这一类活有个共同特征:流程固定、判断成分低、做错了代价小且容易回滚。改错一个TDK,发现了再改回来就是,不会让网站塌掉。正因为容错高,它们是AI SEO自动化里“最该第一批交出去”的活——把人从这些机械操作里捞出来,去做机器还做不了的判断,才是这83.4% 的真正价值所在。
实战里最直接的体感是,这一档自动化省下的不是“工时”,是“心力”。一个SEO要是一天把三个小时耗在登录各种后台导数据上,剩下的脑子也想不出什么好策略了。把这块交出去,团队的注意力质量肉眼可见地回来。当然,托管不等于放养——后面讲护栏时会说,界面操作类最大的坑是“它点错了你还不知道”,这是个比想象中更隐蔽的雷。
终端编码74.6%,能帮SEO自动化扛下哪些脏活累活?
Terminal-Bench测的是模型在命令行环境里自主完成多步任务的能力。这块Opus 4.8拿了74.6%,是六项里唯一没拿同组第一的——GPT-5.5以78.2% 领先。这个细节本身就值得SEO人记住:没有哪个模型在所有维度都最强,选工具得看你的活落在哪条线上,迷信单一“最强模型”反而容易吃亏。
终端能力对SEO意味着什么?意味着那些“黑乎乎的命令行脏活”有了帮手。SEO做到一定规模,绕不开跟服务器、日志、批量数据打交道,而这些恰恰是非技术背景的运营最怵的部分:
- 服务器日志分析:从几百兆的访问日志里,把Googlebot、Bingbot、各家AI爬虫的抓取行为扒出来,看它们到底在抓什么、有没有在垃圾页上浪费抓取预算。
- 批量化处理脚本:几千个URL要批量查状态码、查canonical、查hreflang一致性,写个脚本跑一遍,比人工抽查靠谱得多,也不会查到一半走神。
- 定制化爬虫:竞品改版了想监控它的标题结构变化,或者要定期抓自己站的内链分布,让Agent写个轻量爬虫定时跑。
- sitemap与llms.txt生成维护:站点大了之后,sitemap分卷、内容索引文件这些都得脚本化维护,手动早就跟不上更新节奏。
74.6% 的水平,配上“人给目标、机器写脚本、人审脚本逻辑再跑”的协作方式,能让一个不太懂命令行的SEO也吃到自动化红利。一个常用的招数是:要分析一个站的爬虫抓取偏好,过去得找开发排期,现在把日志样本和需求描述清楚,让Agent先出一版分析脚本,人读懂逻辑、确认没问题再放到真实数据上跑。这套“逆向爬虫行为”的玩法,在AI爬虫到底抓你什么那篇里拆得更细。
但终端活有个比改代码更需要警惕的地方:命令行的破坏力更大。一条写错的批量命令,可能不是改错一个标签,而是删错一批文件,甚至动到生产数据。所以这一档自动化的护栏不是“事后审结果”,而是“事前审脚本 + 在隔离环境先跑”——这条铁律后面会专门讲,它能挡掉绝大多数灾难性事故。
知识工作1890分和财务分析53.9%,这两个数字该怎么读?
前面四项都偏“执行”,这两项偏“产出”和“判断”,得分开读,因为它们暴露了AI SEO自动化里一条很关键的裂缝。
先看知识工作。GDPval-AA这个基准衡量的是模型在真实经济价值任务上的产出质量,Opus 4.8拿了1890,领先GPT-5.5的1769、Opus 4.7的1753,更把Gemini 3.1 Pro的1314甩开一大截。这是个Elo式的分数,121分的领先大致对应六成多的捉对胜率。翻译成SEO场景,它说明模型在“写一份像样的诊断报告、整理一份结构清楚的竞品分析、产出一篇有信息量的内容初稿”这类脑力产出上,已经达到能用的水准。
这正是内容生产自动化的底气来源。从选题、提纲、初稿到SEO加工,整条内容流水线的“产出”环节,机器现在能扛下大头。成熟团队的内容工作流,早就是“机器出初稿、人做事实核查和注入真实经验”的人机分工,相关的分工节点在AI内容生产工作流的6个阶段里画过完整的图。
但财务分析那53.9% 就是另一回事了。它虽然也是同组第一,可绝对值只有五成多——一半多一点的题做对,将近一半做错。SEO投入产出测算、预算分配、渠道ROI对比这类“算账”活,正好落在这个区间。这意味着什么?
能让Agent帮你把数据拉齐、把计算框架搭好、把初步结论列出来,但绝不能直接拿它的数字去跟老板汇报、去定预算。这一档,机器是助手,不是决策者。
这两个数字摆在一起,AI SEO自动化的一条核心规律就浮出来了:越是有标准产出格式、越能被验证的脑力活,自动化越成熟;越是牵涉钱、牵涉判断、错了代价高的活,机器越只能当副手。把1890和53.9% 放一块看,比单看任何一个都更有指导意义——一个告诉你产出环节能放手,一个告诉你决策环节得攥紧,委托的天花板就画在这两条线之间。
基准分数高,为什么不等于你的SEO任务能直接外包给AI?
讲到这儿得来一次重要的转弯。前面一直在说“能交”,但实战里见过太多团队栽在“以为分数高就能闭眼托管”上。基准和你的真实活之间,隔着至少四道坎。
第一道坎:基准是受控环境,你的站是野生环境。SWE-Bench也好、OSWorld也好,任务都是被精心定义、有明确成功标准的。可你的真实SEO活往往是“这个站为什么流量掉了”这种边界模糊、原因纠缠的问题,没有标准答案,也没有自动判分。受控环境里83% 的成功率,搬到你那套乱糟糟的后台和历史遗留结构上,会打多少折,没人能拍胸脯保证。
第二道坎:站点特异性。每个站都有自己的脾气——一个用了五年的WordPress站,插件冲突、历史重定向、奇怪的URL参数,这些“只有你懂”的上下文,Agent不可能凭空知道。它在通用任务上的高分,遇到你站的特殊历史包袱,很容易自信地做出错误判断,而且错得理直气壮。
第三道坎:幻觉与“一本正经地胡说”。模型不会的时候不会举手,它会编。让它分析一个它其实没读全的日志,它可能给你一个看起来很专业、实则站不住脚的结论。SEO里最怕这种——你照着一个幻觉出来的“诊断”去大改网站,越改越糟。AI做SEO/GEO审计为什么必须有前提,AI做SEO/GEO审计的3个前提里专门讲过数据、方法、人工复核这三关,少一关都可能被幻觉带沟里。
第四道坎:E-E-A-T和真实性这道红线。这是SEO最特殊的地方。Google越来越看重内容背后的真实经验、真实作者、真实信任信号。机器能写出语法完美的内容,但写不出“去年给某个宠物DTC客户踩过的那个坑”这种带着体温的细节。一旦内容流水线失控、批量产出没有真实经验支撑的“正确废话”,轻则没排名,重则被反垃圾系统判降权。这种翻车实在见过太多,那篇AI内容流水线为什么6站4降权就是一份血淋淋的复盘。
所以基准分数该怎么用?保哥的态度是:把它当成“能力上限的参考”,而不是“可以放手的许可”。分数告诉你这条线大概能走多远,但你站上能走多远,得自己拿低风险任务一点点试出来,没有捷径。
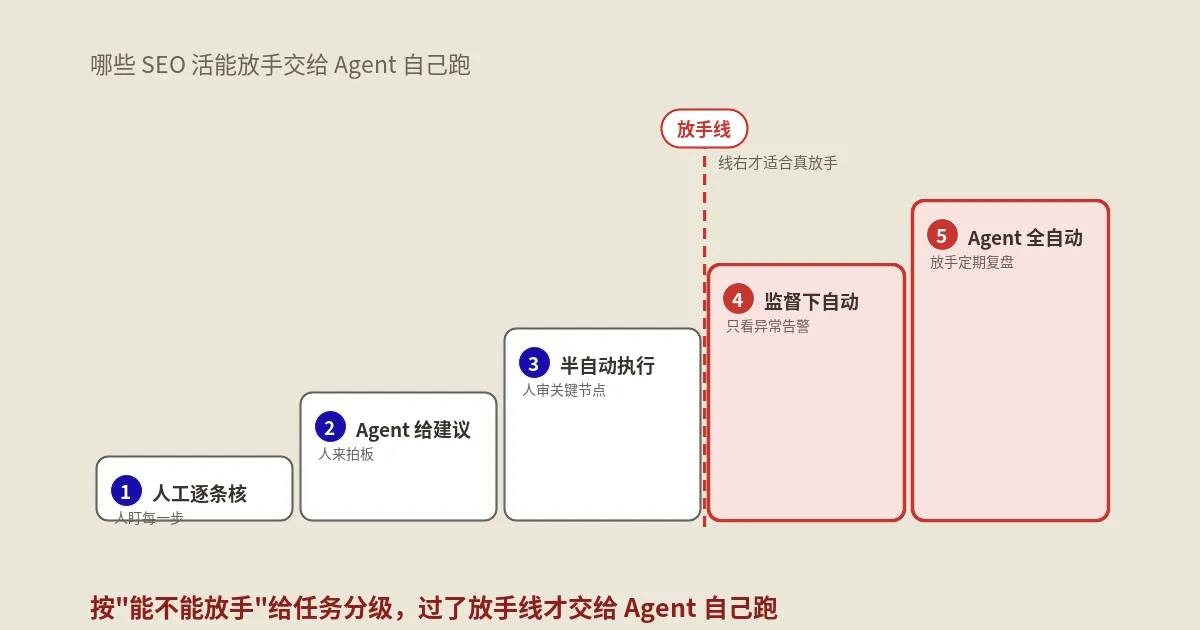
一套能落地的AI SEO自动化分层委托清单,怎么搭?
光说“有的能交有的不能交”太虚。把这一年攒下来的经验整理成一个按“可委托度”分四层的框架,你可以照着把自己手里的活对号入座。
| 层级 | 任务特征 | SEO活举例 | 人的角色 |
|---|---|---|---|
| L1放心托管 | 流程固定、判断少、错了易回滚 | GSC取数、批量截图、TDK按模板填充、结构化数据草稿 | 事后抽查 |
| L2跑了要审 | 有标准答案、但影响面较大 | schema批量生成、重定向映射、性能优化代码、内容初稿 | 逐项过审再上线 |
| L3当副手用 | 需判断、牵涉策略或钱 | 流量诊断、预算分配、竞品策略分析、选题判断 | 机器出框架,人做决策 |
| L4别交给它 | 需真实经验、信任信号、最终担责 | 注入真实案例、E-E-A-T信号、对客户或老板的正式结论 | 人主导,机器最多打辅助 |
这套分层有几个用法上的要点,实操下来觉得比框架本身更重要:
- 新任务一律从高一层往低一层试。哪怕你觉得某个活该是L1,第一次也按L2来审,跑顺了、信得过了,再降级放手。降级容易,出了事再收权很伤元气。
- 护栏跟着层级走,不搞一刀切。L1的护栏是“留操作日志方便回溯”;L2是“上线前人工逐项过”;L3是“机器只能产出建议不能直接执行”;L4干脆就是“机器不碰最终输出”。每一层配的护栏不一样,混用要么束手束脚,要么留隐患。
- 命令行类任务自动降一级。前面说过,终端活破坏力大,哪怕看着像L1,也按L2对待——先在隔离环境跑,确认无误再上真实数据。
- 定期复盘升降级。模型在升级、你的信任在积累,每隔一两个月回看一次哪些活可以往下放一层,哪些出过事得往上收一层。这个框架是活的,不是刻在石头上的。
这个清单的好处是,它把“要不要用AI做SEO”这个早就过时的问题,换成了“这个具体任务该放在哪一层”。一旦团队习惯用层级说话,自动化推进就不再是赌运气,而是有章可循。Claude这类Agent现在还能挂技能、串工作流,把多步任务编排起来,Claude Skills全解析里拆过怎么把这些能力接进SEO自动化管线,配合分层框架用效果更好。
跑agentic SEO自动化,团队踩过哪些真实的坑?
框架是干净的,现实是脏的。挑几个真实踩过的坑说说,比讲一百遍“要小心”管用。
坑一:界面操作“点错了你还不知道”。有次让Agent批量改一个服装出海站的产品页标题,它在某个分类下把模板套错了,把“连衣裙”系列的标题全填成了“T恤”的关键词。问题是这种错不会报错,页面照样能打开,等两周后发现这批页排名集体异常,才回溯到是那次自动化埋的雷。教训:界面操作类一定要让Agent留下逐步操作记录,并且改完后做一次自动化抽检(比如随机抽5% 页面比对标题是否符合预期),不能只看“任务完成”这四个字就放心。
坑二:诊断报告里的“自信幻觉”。让Agent分析一个母婴DTC站的流量下滑,它给出一份条理清晰的报告,说是“算法更新导致”。保哥当时差点信了,幸好让团队复核GSC原始数据,发现真实原因是一批页面被误加了noindex——一个纯技术失误,跟算法毫无关系。模型在数据不全时,倾向于套用最“常见”的解释来填补空白。教训:L3的诊断结论,必须能回溯到原始数据每一步,凡是“拍脑袋归因”一律打回。这件事在AI内容质检工作流的人机分工里也强调过,事实核查这一关人永远不能缺席。
坑三:内容流水线“正确但没人想看”。早期试过让内容生产线全自动跑,结果产出的文章语法挑不出毛病,信息也没硬伤,但读起来像说明书,没有任何真实经验和观点。这种内容上线后停留时间惨不忍睹,也拿不到AI搜索的引用。教训:内容的“产出”可以自动化,但“注入真实经验、观点和踩坑”这一步,是L4,必须人来。机器负责把骨架搭好,血肉得真人填——这也是保哥一直不肯把内容最后一公里交出去的原因。
坑四:全站级配置的“自作主张”。有回让Agent帮一个B2B工业品站优化抓取预算,它读完日志后自动给一批带参数的页面加了Disallow,逻辑上没毛病——那些确实多是低价值页。可它不知道,其中一类筛选参数页正在悄悄吃下一批精准长尾流量,被一刀切掉后,那部分询盘肉眼可见地少了,过了小半个月才查出根因。教训:robots、canonical、noindex这类“全站级”指令,影响面跟命令行一个量级,哪怕Agent给的理由再充分,也必须人工核一遍“被牺牲的页面里有没有正在赚钱的”,宁可慢一步也别一刀切。
这几个坑有个共同的根:自动化最危险的不是它做错,而是它“看起来做对了”。真正成熟的AI SEO自动化,一半功夫花在让Agent干活,另一半花在搭一套能识别“假性成功”的验证机制上。后者才是分水岭这边和那边的真正区别,也是新手和老手拉开差距的地方。
这波agentic模型,会怎么重塑SEO团队的活法?
把镜头拉远一点。当编码、电脑操作、知识产出这些活能大面积托管出去,SEO团队的能力结构其实在悄悄重排。这不是“AI取代SEO”的老调子,而是更具体的位移。
过去衡量一个SEO值不值钱,常看他“能干多少活”——会不会写脚本、会不会调schema、能不能熬夜导数据做月报。这些恰恰是Agent现在最擅长接的部分。当这些变成机器的活,人的价值就被逼着往上走:会判断、懂业务、能担责、有真实经验,这些机器还摸不到的地方,成了新的护城河。
有三个正在发生的变化值得盯紧。其一,“执行型SEO”和“判断型SEO”开始分层,会熟练驾驭Agent把执行活批量跑完、再用省下的时间做策略的人,产出会和别人拉开差距。其二,“验证能力”变成稀缺技能——能快速识别一份AI诊断哪里靠谱哪里在胡说,这种本事比会用工具更值钱。其三,真实经验和E-E-A-T的溢价在涨,越是机器能批量产出“正确废话”的时代,那些有真实战绩、真实踩坑、真实判断的人和内容,反而越稀缺、越值钱。
所以保哥给同行的建议很朴素:别跟Agent比谁活干得快,那场比赛人注定输。要做的是把执行层尽量交出去,把自己腾到判断层和经验层,再把验证机制练成肌肉记忆。Opus 4.8这张基准表的真正信号不是“机器要来抢饭碗”,而是“该重新想想,你这碗饭里哪部分只有人能端”。工具越强,人越要往工具够不到的地方站——这话听着像鸡汤,却是这波agentic浪潮里最实在的生存逻辑。
常见问题解答
Opus 4.8的基准分数这么高,是不是意味着SEO工作很快就不用人了?
不是。基准测的是受控环境里的能力上限,跟你真实站点上的表现是两回事。分数高说明“执行类”的活越来越能托管,但牵涉判断、策略、真实经验和最终担责的活——也就是SEO里最值钱的部分——机器还远远接不住。更现实的判断是:人会从“干活的人”变成“指挥和验证Agent干活的人”,岗位不会消失,但能力要求会变。
SWE-Bench Pro的69.2% 和OSWorld的83.4%,哪个对SEO自动化更重要?
看你团队的瓶颈在哪。如果你卡在技术改造上(schema、重定向、性能代码),编码能力(SWE-Bench Pro)更关键;如果你卡在重复的后台操作和取数上,电脑操作能力(OSWorld)更解渴。对多数中小团队来说,OSWorld那83.4% 代表的“界面操作自动化”见效最快,因为它直接砍掉每天耗在登录后台、导数据上的时间,而且这类活容错高、好回滚,最适合第一批交出去。
为什么财务分析只有53.9%,这对SEO算账类工作意味着什么?
意味着算账类的活只能让Agent当副手。53.9% 是同组最高,但绝对值才一半多一点,将近一半会出错。SEO的投入产出测算、预算分配、渠道ROI这些直接牵涉钱和决策的事,可以让Agent帮你拉数据、搭计算框架、列初步结论,但最终数字必须人来核、人来拍板,绝不能直接拿机器的输出去定预算或向上汇报。
哪些SEO任务现在可以放心交给AI Agent自动跑?
按可委托度看,最该第一批交出去的是L1类:流程固定、判断少、错了好回滚的活——比如GSC/GA4取数、批量截图取证、按模板填TDK、生成结构化数据草稿。再往上一层L2(schema批量生成、重定向映射、性能代码、内容初稿)可以让Agent跑,但上线前要逐项人工过审。涉及策略判断和算账的L3只能当副手,需要真实经验和最终担责的L4别交给它。
用Agent做SEO自动化,最容易踩的坑是什么?
最危险的不是它做错,而是它“看起来做对了”。界面操作可能套错模板却照样显示任务完成,诊断报告可能给出条理清晰却站不住脚的归因,内容流水线可能产出语法完美却没人想看的“正确废话”。对策是给每一层配验证机制:界面操作留操作日志加自动化抽检,诊断结论必须能回溯到原始数据,内容的真实经验注入必须由真人完成。把功夫一半花在让Agent干活、一半花在识别“假性成功”上,才是成熟的自动化。
权威参考资料
本文标题:《Opus 4.8基准刷新后,AI SEO自动化能把哪些活交给Agent自己跑?》
本文链接:https://zhangwenbao.com/opus-4-8-agentic-benchmarks-ai-seo-automation.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0