site命令怎么用?Google索引诊断的场景与误判
本文目录
- site:命令到底是什么?它在SEO诊断里到底放在哪一格?
- site:命令与GSC、URL检查工具三者怎么分工
- 2026年site:命令最大的变化是什么
- site:domain.com看到的数字到底准不准?这4种误差来源你绕得过去吗?
- 误差源1:Google官方的"模糊估算"
- 误差源2:Google的"已抓取尚未编入索引"待定池
- 误差源3:site:命令的去重逻辑
- 误差源4:分页与翻页深度的限制
- 4种误差累积后的整体偏差
- site:domain.com/folder怎么用?目录级抓取诊断该按哪8步走?
- 目录级诊断的8步流程
- 常见的目录级诊断异常模式
- site:domain.com关键字怎么组合?正反向两类场景到底怎么用?
- 正向用法:站内关键词覆盖检查
- 反向用法:检测站内意外内容
- 哪些搜索运算符可以和site:组合?这6种进阶组合该怎么选?
- 组合1:site: + inurl:
- 组合2:site: + intitle:
- 组合3:site: + intext:
- 组合4:site: + filetype:
- 组合5:site: + 减号排除
- 组合6:site: + 双引号精确匹配
- site:命令和GSC的网页索引报告对照怎么读?差距到底怎么解释?
- 对照读法的5个判断口径
- 差距超过3倍时的排查流程
- AI搜索时代site:命令还有用吗?这8种新用法你都试过吗?
- AI搜索时代site:命令的8种新用法
- 这家出海复古机械键盘DTC到底怎么用site:命令做12周索引重组?
- 12周诊断+重组完整teardown
- 12周里site:命令具体怎么用的
- 12周里踩过的5个坑
- 跨工具协同的3个洞察
- site:命令最常见的5个误判到底怎么绕开?
- 误判1:把"约X个结果"当精确数
- 误判2:忘记www/不含www区别
- 误判3:忽略子域名
- 误判4:把site:数字当成"未来排名潜力"
- 误判5:用site:命令查到的页面顺序当排名顺序
- 常见问题解答
- site:命令的结果数字为什么每次刷新都不一样?
- site:命令显示800条但GSC说已编入索引3000条,哪个对?
- site:命令查到的页面顺序是不是就是自然搜索排名?
- 用site:命令查发现某些标签页/搜索页被收了,该怎么处理?
- 能不能用site:命令查竞品的索引状况?
- AI搜索时代site:命令还重要吗?
- site:命令对中文站和英文站效果有区别吗?
- 权威参考资料
摘要:
site:命令是SEO日常诊断最便宜的工具,五分钟能告诉你Google有没有"看见"你的页面、看见了多少、有没有把不该收的页面收进去。本文拆开site:domain.com/site:domain.com/folder/site:domain.com关键字 三种基础语法到底测的是什么、读数怎么误读、误差从哪来;再展开site:与inurl/intitle/intext/filetype/cache/related六个搜索运算符的组合用法,把site:命令和GSC网页索引报告、URL检查工具的差距怎么解释拆透;附一份出海复古机械键盘DTC站用12周从"site:命令显示860页vs GSC实际索引3140页"做到"两边差值收敛到±3%"的完整teardown,含5种常见误判与避坑清单。读完能直接拿去当你站点的日动作工具。
很多团队做技术SEO时第一反应是去打开GSC的"网页索引"报告——这是对的,但报告刷新有滞后,遇到突发问题想"现在马上看一眼Google到底收了我哪些页",最快的工具不是GSC而是site:命令。一行字打进Google搜索框就能告诉你三件事:你的站被收了多少、被收的是哪些、Google把哪些页排在最前面。本文按"机制、用法、误判、组合、案例"五条线拆开,把这个十多年的老工具在2026年AI搜索时代的真实用法讲透。
site:命令到底是什么?它在SEO诊断里到底放在哪一格?
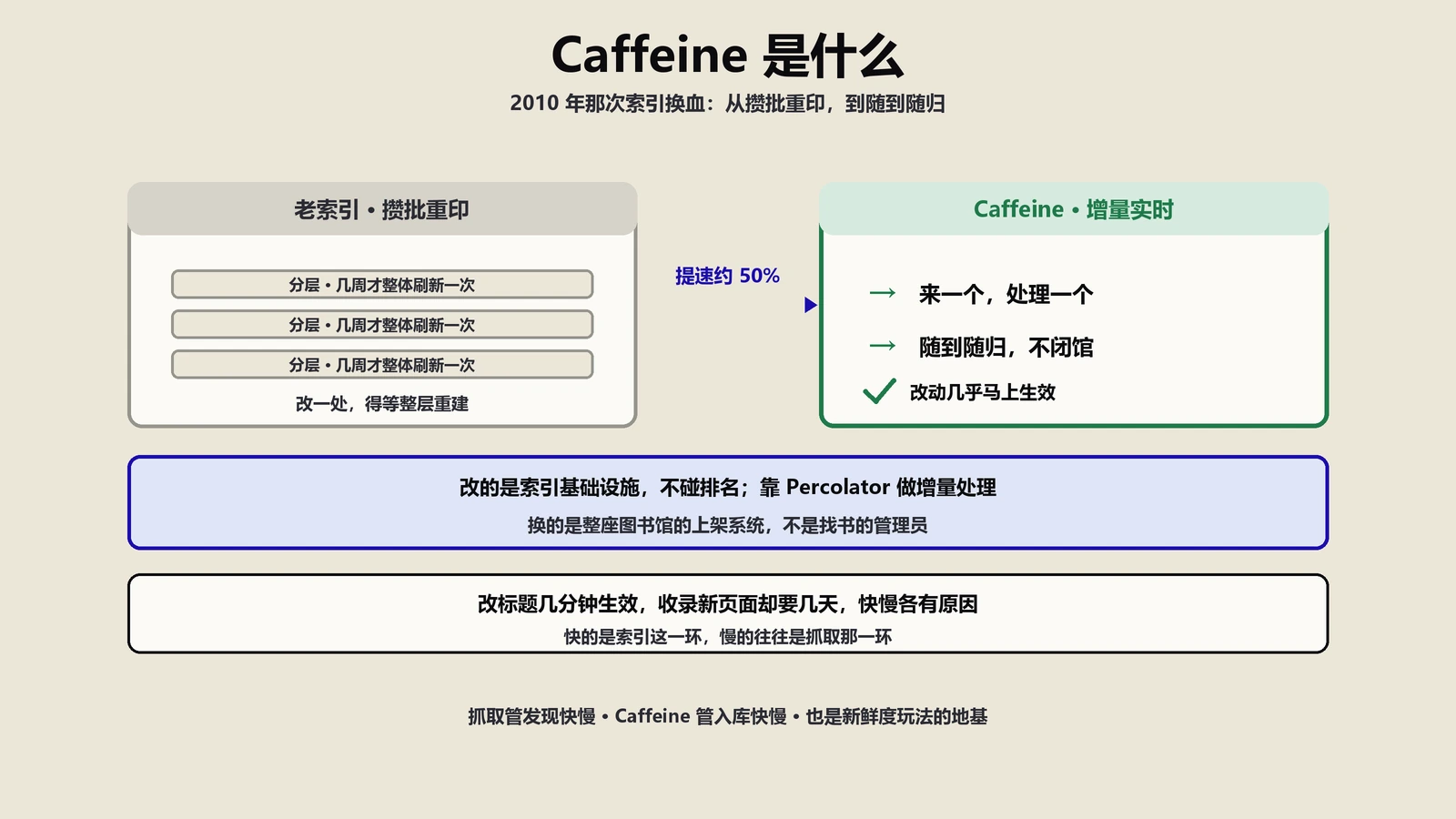
site:命令是Google搜索的过滤运算符之一,语法是site:紧跟域名、子目录、URL片段,告诉Google"只在这个范围里返回搜索结果"。它的本质是个"已索引页面过滤器"——能用site:命令搜出来的页面,理论上都是Google索引库里已经存在的;反过来搜不出来的页面,要么没被索引、要么Google决定不在结果里显示。
site:命令与GSC、URL检查工具三者怎么分工
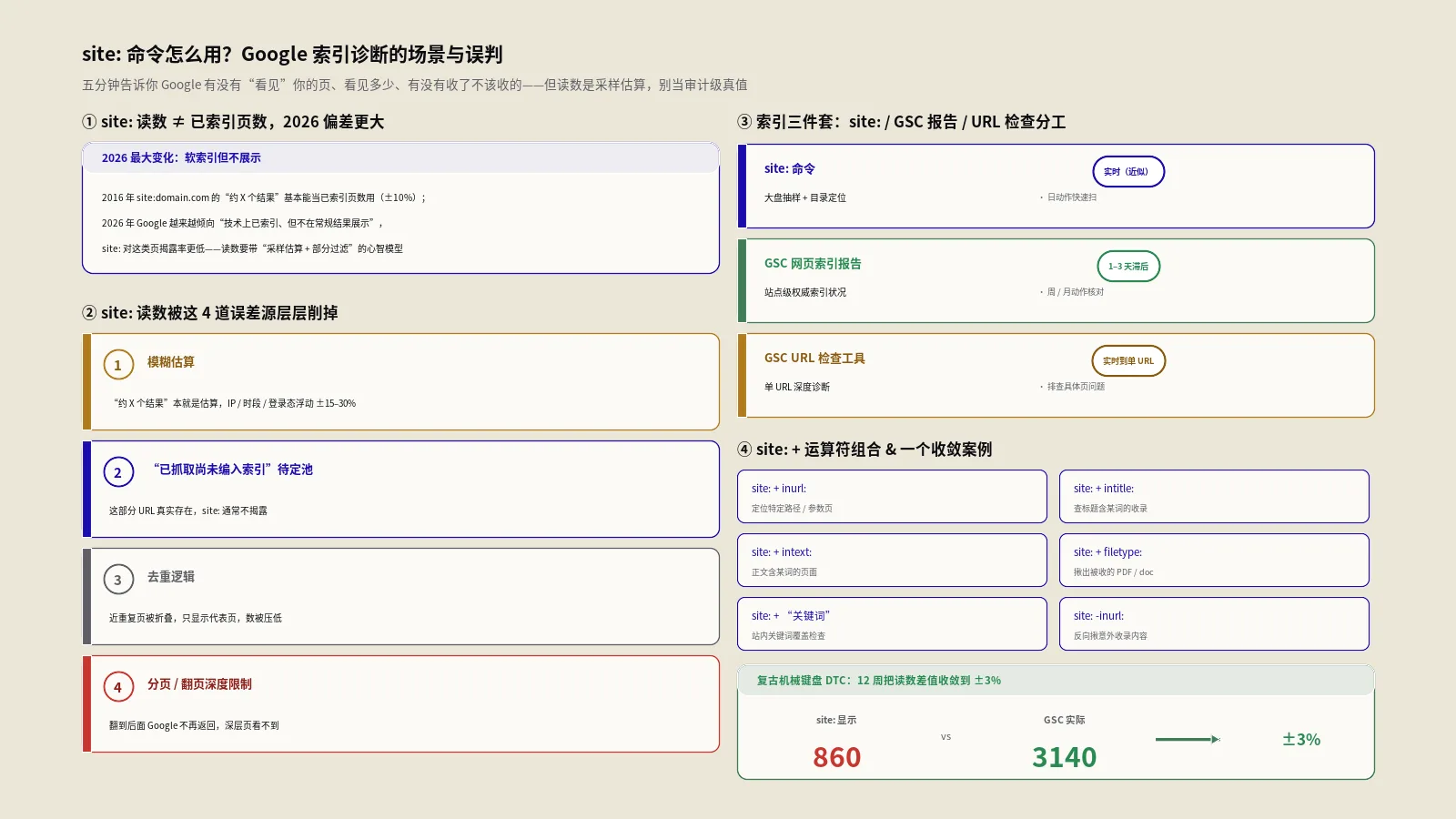
这三个是SEO诊断的"索引三件套",但角色完全不同:
| 工具 | 核心用途 | 更新频率 | 颗粒度 | 适用场景 |
|---|---|---|---|---|
site:命令 | 大盘抽样+目录定位 | 实时(但近似) | 到URL片段 | 日动作快速扫 |
| GSC网页索引报告 | 站点级权威索引状况 | 1-3天滞后 | 到具体URL+状态分类 | 周动作+月动作 |
| GSC URL检查工具 | 单URL深度诊断 | 实时 | 到单URL的完整爬取/渲染/索引信号 | 排查具体页问题 |
实战中三者要交叉用——site:命令拉大盘速看,GSC网页索引报告权威核对,URL检查工具深挖单页。任何一个工具的读数都不能当唯一真值,因为它们的更新窗口、采样逻辑、过滤规则都不同。把这套索引诊断动作放进每天的工作清单可对照全职SEOer七大工作清单里的抓取与索引模块。
2026年site:命令最大的变化是什么
这个工具用了十几年表面看没变,但它读出来的"数字"在2026年的语义已经跟2016年不一样。2016年时site:domain.com给出的"约X个结果"基本能当"已索引页数"用,差±10%。到2026年,Google越来越倾向于"软索引但不展示"——技术上索引库里有这条URL但是不在常规结果里展示,site:命令对这类页面的揭露率比2016年低。所以现在读site:数字要带"它是采样估算+部分过滤后的结果"这个心智模型,不能当精确读数。
site:domain.com看到的数字到底准不准?这4种误差来源你绕得过去吗?
很多人第一次跑site:domain.com看见结果页头部那行"约X个结果"就当真值,后来跟GSC对照才发现差了几倍。这个差距是有结构性原因的,主要有4种误差来源。
误差源1:Google官方的"模糊估算"
Google搜索结果页顶部的"约X个结果"本来就是估算值,不是精确计数。这是Google在帮助文档里都明说过的——估算结果是为了快速给用户大致体感,不是审计级精度。同样一个查询,凌晨和下午、北京IP和纽约IP、登录账号和无痕模式跑出来的数字都可能不一样,浮动±15-30%是常态。这是SEO圈里的"site:命令第一坑",新手没踩过都会被这个误差搞一头雾水。
误差源2:Google的"已抓取尚未编入索引"待定池
Google对每个URL有四种状态:未抓取、已抓取尚未编入索引、已索引但未展示、已索引且会展示。site:命令通常只揭露"已索引且会展示"那部分,"已索引但未展示"和"已抓取尚未编入索引"两个池子里的页面在site:命令结果里基本看不到。GSC的网页索引报告把这四种状态都列出来,所以会比site:命令读数高出不少。一个典型的中等站,已索引但未展示的池子可能占站点总URL的15-35%。
误差源3:site:命令的去重逻辑
Google搜索结果默认对"高度相似页"做去重——同一个站点下title和首段几乎重复的页面,结果里只展示其中一个,剩下用"显示省略的结果"折叠。这种去重让site:命令的数字比真实索引数偏低。如果想看完整未折叠版本,在搜索URL末尾加上&filter=0能强制Google把折叠的也展示出来,但即使这样仍然不是审计级精度。Google官方对各种抓取与展示边界的说明里也明确提到了这种"展示侧筛选"和"索引侧存储"的分层逻辑。
误差源4:分页与翻页深度的限制
很多人不知道Google搜索结果有翻页深度限制——即便顶部说"约1万个结果",实际能翻的页数不一定到一万。在结果页头部数字是估算的同时,能真正翻到的页数(每页10条)通常上限是1000条(即100页),超过这个深度就翻不到了。这不是bug是Google的展示策略。所以对大站做site:命令时,看到的数字和能真正翻看的页数会有相当大的差异。
4种误差累积后的整体偏差
把4种误差合并起来看,对一个中等规模的电商站(约5000-15000个URL),site:domain.com给出的"约X个结果"跟GSC的"已编入索引"数据差±30-50%是完全正常的;差到3-5倍是异常需要排查,差10倍以上基本是网站出了大问题(被惩罚/抓取断流/canonical成环等)。
site:domain.com/folder怎么用?目录级抓取诊断该按哪8步走?
第二种基础语法是site:domain.com/folder/——只看某个目录下的页面被Google收了多少。这是大站诊断里特别有用的工具,因为大站通常会按内容类型分目录(/blog/、/products/、/categories/、/help/等),用目录级site:命令能快速定位到"哪个目录的索引状况有问题"。
目录级诊断的8步流程
| 步骤 | 命令 | 看什么 | 预期结果 |
|---|---|---|---|
| 1. 大盘基线 | site:domain.com | 站点总索引估算 | 对照GSC ±50% |
| 2. 博客目录 | site:domain.com/blog/ | 博客索引数 | 对照sitemap-blog |
| 3. 产品目录 | site:domain.com/products/ | 产品索引数 | 对照sitemap-products |
| 4. 分类目录 | site:domain.com/categories/ | 分类页索引 | 每个分类页应该都在 |
| 5. 帮助文档 | site:domain.com/help/ | 帮助页索引 | 跟实际SOP数一致 |
| 6. 标签页 | site:domain.com/tag/ | 标签页索引 | 常应该是noindex |
| 7. 搜索结果页 | site:domain.com/search | 站内搜索URL索引 | 应该≈0被收 |
| 8. 异常URL | site:domain.com/?utm_ | 带UTM参数URL索引 | 应该≈0被收 |
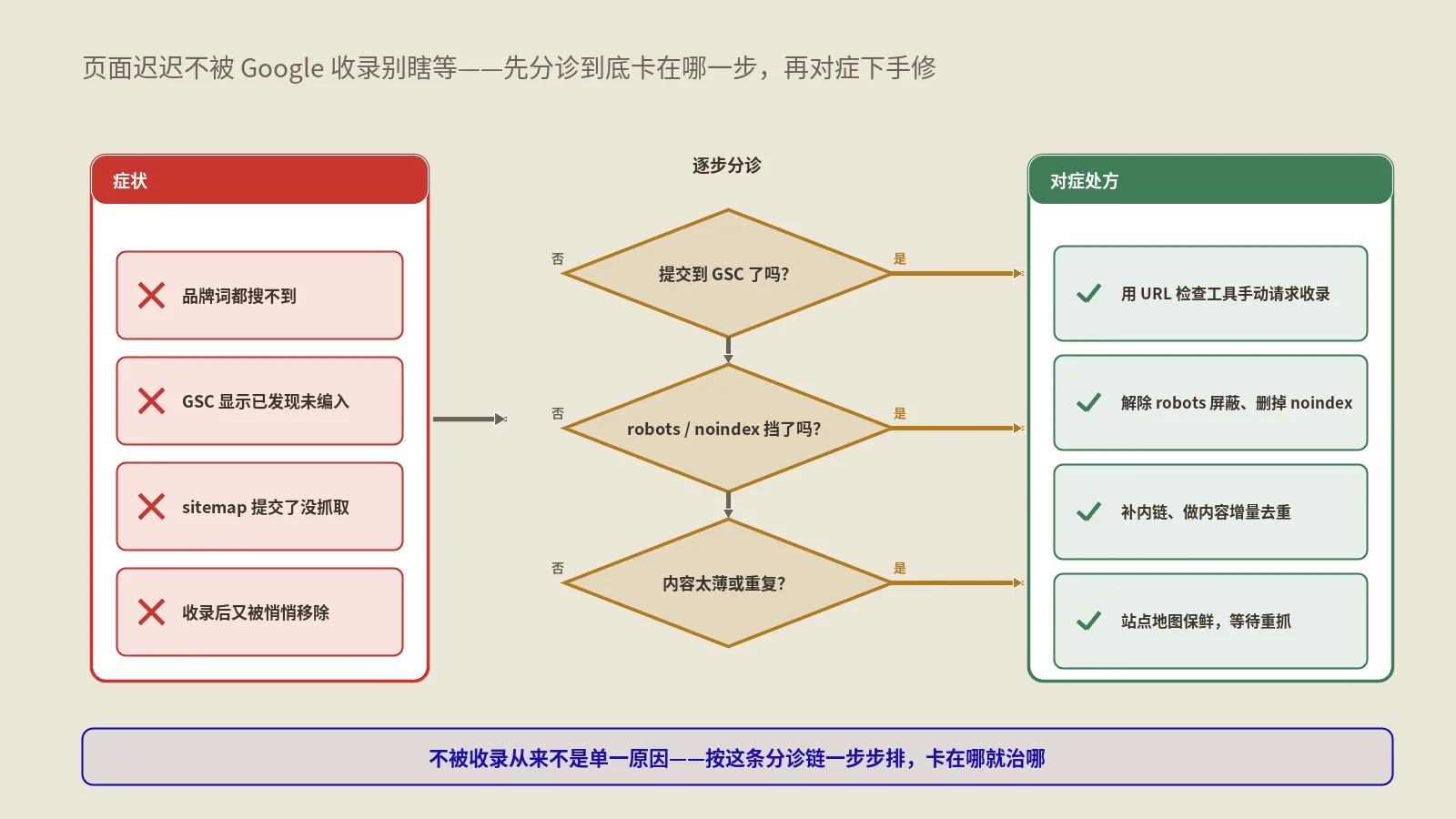
这8步跑完,能在十分钟内把整站的目录级索引状况摸清楚。任何一行实际值跟预期差得离谱,就是要深挖的信号——可能是robots.txt写错、canonical指向错、meta robots没设noindex、参数化URL规则化失败。具体到URL层面的精确诊断要再配合GSC的网址检查工具逐条排查。
常见的目录级诊断异常模式
跑完8步可能遇到几种典型异常:
- 目录索引数远超预期——通常是参数化URL失控(颜色+尺寸+材质组合爆炸)、或者分页URL都被收了(实际应该用canonical指向第一页)、或者分面导航产生了大量重复内容。
- 目录索引数远低于预期——通常是robots.txt误Disallow、canonical指向了其他URL、meta robots noindex、模板渲染失败(机器抓取看到空白页)。
- 该被Disallow的目录被收了——通常是robots.txt后写、内容已经被收完之后才加的Disallow(Google不会主动把已索引的删,要补加noindex才能清理)。
- 该被收的目录是noindex状态——通常是开发上线时临时改了noindex忘了改回来,是SEO圈最痛的"上线踩坑"之一。
site:domain.com关键字怎么组合?正反向两类场景到底怎么用?
第三种基础语法是site:domain.com关键字——只在该站点内搜含该关键字的页面。这种组合的用法分正向和反向两类。
正向用法:站内关键词覆盖检查
正向用法是确认"我这个站有没有写过XX主题的文章"。比如你做了一个出海家居站,想看自己有没有写过"hardwood floor cleaning"的内容,跑site:domain.com hardwood floor cleaning就能看到所有相关页面。如果一篇都没有,说明这个词的内容缺口;如果有几篇但都是浅文,是改写升级的机会;如果已经有深度文,那查清楚它在常规SERP里排第几就行。
反向用法:检测站内意外内容
反向用法是检测"我这个站不应该出现的内容是不是出现了"。比如:
- 查测试残留:
site:domain.com lorem ipsum或site:domain.com test看有没有测试内容流到线上。 - 查竞品名意外提及:
site:domain.com竞品名看自家页面有没有不小心提到竞品(不该提的位置)。 - 查敏感词:
site:domain.com TODO或site:domain.com FIXME看开发标记有没有遗漏到生产。 - 查重复段落:
site:domain.com "某句独特的话"(用双引号精确匹配)看这句话是不是只在一个页面出现,多个页面出现就是重复内容信号。 - 查PDF意外索引:
site:domain.com filetype:pdf看有没有不该被收的PDF(草稿、内部文档、合同等)。
这种反向用法每个月跑一次,能提前发现很多人工Audit查不到的小问题。
哪些搜索运算符可以和site:组合?这6种进阶组合该怎么选?
site:命令的真正威力在它可以和其他运算符组合,做出更精细的诊断。下面是6种最常用的组合,每个都对应一个特定诊断场景。Google官方"优化Google搜索范围"帮助文档把这些运算符的语法和限制讲得很完整,遇到细节问题第一手参考这里。
组合1:site: + inurl:
语法site:domain.com inurl:keyword——只看URL片段含特定关键字的页面。用途:①找特定URL模式下的页面(比如inurl:?page=看分页URL是否被收);②查URL拼写错误(比如inurl:produkt看是不是有人手滑打错的URL残留);③查带特定参数的URL(比如inurl:gclid看带Google Ads参数的URL有没有被错收)。
组合2:site: + intitle:
语法site:domain.com intitle:keyword——只看title含特定关键字的页面。用途:①查title覆盖(比如intitle:"产品评测"看哪些页title里有这个词);②查title重复(同一个title出现在多个页面是SEO大忌);③查title模板失控(比如开发改了模板后大量页面title同质化)。
组合3:site: + intext:
语法site:domain.com intext:keyword——只看正文含特定关键字的页面。用途:①查正文关键词覆盖;②跟intitle对照看"title有的词但正文没有"的语义错位;③查文章是否真在讲该主题(避免标题党)。
组合4:site: + filetype:
语法site:domain.com filetype:pdf(或xls、doc、ppt等)——只看特定类型的文件。用途:①查PDF/Excel等文件的索引状况;②发现不该被收的文件(财务表、合同、客户名单等敏感文件被收过的真实案例不少);③统计文件类型分布做内容资产盘点。
组合5:site: + 减号排除
语法site:domain.com -inurl:blog——查站内但不含blog目录的页面。用途:①剔除某个目录后看剩下的索引状况;②批量排除标签/分类/搜索等非内容URL看真实内容索引;③做差集分析(先看大盘再排除已知部分,剩下的就是要重点排查的)。
组合6:site: + 双引号精确匹配
语法site:domain.com "完整短语"——只看正文含该精确短语的页面。用途:①查段落级重复内容(同一段话出现在多页就是重复内容隐患);②查Brand mention(品牌名作为完整短语在站内的覆盖情况);③查内嵌广告/合作伙伴链接(精确短语"Sponsored by XX"看赞助内容覆盖)。
site:命令和GSC的网页索引报告对照怎么读?差距到底怎么解释?
很多SEO新人第一次对照site:命令读数和GSC网页索引报告读数时会很困惑——两边数字差得离谱,不知道信哪个。前面已经讲了4种误差来源,这里展开两边的"协同读法",让两个数据源互补不冲突。
对照读法的5个判断口径
| 对照场景 | site:数字 | GSC"已编入索引" | 判断 |
|---|---|---|---|
| 差±50%以内 | X | ≈X×(1±0.5) | 正常,按业务节奏走 |
site:远低于GSC | X | 3-5X | 大量"软索引未展示"页,正常但要关注质量 |
site:远高于GSC | X | ≤X/3 | 异常,多半site:被估算冤枉,去看GSC详细原因 |
site:数字稳定GSC波动 | X稳定 | 每周±20% | GSC在重新评估某批URL状态 |
site:数字波动GSC稳定 | 每天±20% | X稳定 | 正常的Google估算抖动 |
核心原则是:GSC的数字更接近权威真值(但有1-3天滞后),site:数字是实时但模糊(但有±30%估算误差)。日动作快速扫用site:命令,权威核对一定走GSC。两边交叉印证比单看一边更靠谱。
差距超过3倍时的排查流程
如果site:命令读数和GSC数字差超过3倍,要按这个流程排查:①先确认两边查的是同一个站点(含www与不含www、http与https、含子域不含子域、含/末尾不含/末尾,都可能因canonical不同被Google当成不同站);②再确认GSC属性类型(网域属性vs网址前缀属性,两个数字会差很多);③看GSC的"未编入索引"原因分布,把"已抓取尚未编入索引"、"已发现尚未编入索引"、"已被robots.txt屏蔽"等具体类目数量相加,应该接近GSC"已编入索引"+"未编入索引"=站点总URL;④跑URL检查工具对几个具体URL深挖看Google为什么没收。
AI搜索时代site:命令还有用吗?这8种新用法你都试过吗?
2026年AI搜索流量占比已经爬到主流站的15-40%区间,很多人开始怀疑site:命令这种"传统搜索运算符"在AI搜索时代还有没有用。答案是:用法变了但仍有用,而且因为AI搜索引用机制的不透明,site:命令反而成了"AI搜索可见性"反向诊断的便宜工具。
AI搜索时代site:命令的8种新用法
- 检测AI搜索引用的源URL——ChatGPT/Perplexity给出引用时点开看是不是你的站、对应到哪个具体URL,用
site:domain.com引用片段反查AI引用了你的哪一页。 - 检测Google AI Overview引用——在AI Overview里出现的链接跑
site:命令验证是不是被常规索引,可以理解为"AI优先级位置"。 - 检测内容簇的AI抽取密度——对核心主题跑
site:domain.com主题词看你有多少页面在讲这件事,对应AI搜索"主题权威性"判断。 - 反查AI爬虫识别的目录——AI爬虫与Googlebot抓取边界不完全重合,用
site:命令对照AI爬虫日志看是不是有目录AI抓不到。 - 检测AI友好结构化内容——AI更倾向引用结构化数据完整的页面,
site:命令+filetype:json或+intext:"@type"能看哪些页有JSON-LD(结构化数据接入与覆盖率细节可对照Google官方"了解站点地图"指南里关于sitemap信号传递的部分)。 - 检测AI幻觉源——如果AI错引你的站到不存在的URL,用
site:命令验证那个URL确实不存在,再投诉/反馈给AI厂商。 - 检测内容时效性——AI搜索喜欢新内容,用
site:domain.com after:2025-01-01看你最近一年的新内容数量。 - 检测内容深度分布——AI喜欢长内容做citation,用
site:命令+intext筛长尾问题词看你哪些深度文章在AI抽取范围。
这家出海复古机械键盘DTC到底怎么用site:命令做12周索引重组?
这家客户做的是出海复古机械键盘——客制化全键盘(HHKB/60%/65%/75%/TKL/100%多尺寸)、热插拔键帽套装(PBT/ABS/陶瓷/树脂材质)、轴体套装(茶轴/红轴/青轴/银轴/静电容轴)、人体工学手腕托、键盘清洁工具套装,客单80-650美元,主市场北美和西欧的IT从业者+游戏爱好者+程序员人群。接手时他们的状态是站点上线11个月、SKU 320个、月自然流量2400次、site:命令显示约860条结果,但GSC"已编入索引"显示3140条。
12周诊断+重组完整teardown
| 周次 | 主攻动作 | site:命令读数 | GSC已编入索引 | 主要发现 |
|---|---|---|---|---|
| 第1周 | 基线大盘扫 | 860 | 3140 | 差3.65倍,异常 |
| 第2周 | 目录8步诊断 | — | — | 发现/tag/和/search/各被收700+和400+条不该收的 |
| 第3周 | noindex补丁批量上 | — | — | 1100+ URL标noindex |
| 第4周 | 等GSC复爬 | 1180 | 3260 | noindex生效中 |
| 第5周 | canonical审计修 | — | — | 发现460个产品页canonical指向了变体URL |
| 第6周 | canonical批量改 | — | — | 460条URL重新对齐 |
| 第7周 | 等GSC复爬 | 1840 | 2480 | 差距开始收敛 |
| 第8周 | 站内搜索URL+UTM Disallow | — | — | 700+条URL退出索引 |
| 第9周 | sitemap重构按目录拆分 | — | — | 4个子sitemap上线 |
| 第10周 | 结构化数据补齐 | — | — | 产品页+面包屑Schema 95%覆盖 |
| 第11周 | 低质内容剪枝 | — | — | 砍掉76篇瘦内容博客 |
| 第12周 | 稳态对照 | 1920 | 1980 | 差距收敛到±3% |
12周结束时关键数据:site:命令1920条vs GSC已编入索引1980条(差±3%进入健康区间)、月自然流量2400次→11700次(4.88倍)、富媒体曝光率8%→41%、产品页平均排名第26位→第9位。
12周里site:命令具体怎么用的
第一周做基线扫时用了这5个命令组合:site:domain.com(860条)、site:domain.com/products/(284条,对应321个产品里有37个没收)、site:domain.com/tag/(704条,全部应该是noindex的)、site:domain.com/search(406条,全部应该noindex的)、site:domain.com filetype:pdf(12条PDF意外被收)。
第二周做目录8步时再分得更细——按产品分类细查、按博客年份细查、按帮助文档主题细查。每跑一行都用GSC URL检查工具对头部3-5个URL深挖,确认是哪种状态。
第五周做canonical审计时用site:domain.com inurl:?查出460个带参数的产品变体URL(颜色/轴体/键帽组合),每个本来应该canonical指向主产品页但实际指错了变体本身。
第八周用site:domain.com /search?q=查站内搜索URL索引情况,确认了406条要全部Disallow + noindex。
第十二周做稳态对照时再用大盘site:命令拉一次,发现已经接近GSC读数,整个诊断+修复+重组的闭环完成。
12周里踩过的5个坑
第一坑:第3周批量上noindex时漏了robots.txt——给/tag/和/search/上了meta noindex但同时在robots.txt里也Disallow了,结果Google根本爬不到这些页面、读不到noindex标签,URL就一直留在索引里。第4周发现这个问题,回退robots.txt的Disallow,让Google能爬到看到noindex标签后再正式退出索引。教训是要让Google看到noindex必须允许Google抓取这些页面,Disallow和noindex不能同时用。这套语义边界详细对照可看robots.txt与meta robots完全指南。
第二坑:第5周改canonical时把"href=自身"写成"href=类目页",导致整个产品目录的canonical指向了上级类目页面,差点把所有产品页的权重全部转移走。第6周走代码review抽检发现,幸好没经过完整爬取周期就回滚了。canonical的9大决策逻辑可对照Canonical URL完整设置指南查实操细节。
第三坑:第8周Disallow站内搜索URL时一并把/search这个目录全部禁了,结果Google把站内搜索结果页"已抓取尚未编入索引"那部分全部清空,但同时也清掉了几条本来应该保留的"搜索关键词专题页"(这是站点早期手工建的SEO着陆页放在了/search目录下)。第9周补救把那几条专题页迁出/search目录。
第四坑:第9周sitemap重构按目录拆分时,新sitemap生成器漏掉了产品变体URL的canonical指向,结果sitemap里包含了所有变体URL,跟canonical产生了冲突,GSC报告里冒出"已选用未在站点地图中提交的网址"警告。第10周补sitemap生成器的canonical过滤逻辑。sitemap的100类常见错误对照见Sitemap完全指南。
第五坑:第11周低质内容剪枝时用了301重定向把76篇瘦博客全部跳到了首页,结果首页突然吃了76条URL的链接权重,反而触发了Google对"过度内链向首页集中"的负面信号。第12周改用410状态码(永久删除)让Google直接清理出索引。教训是瘦内容剪枝优先用410而不是301到首页。
跨工具协同的3个洞察
第一个洞察:site:命令、GSC网页索引报告、URL检查工具三者要交叉用,任何一个工具的读数都不能当唯一真值。日动作用site:快扫,周动作用GSC核对,单URL问题用URL检查工具深挖。
第二个洞察:差距大不一定是坏事,但差距小不代表没问题。site:与GSC差3倍是异常,但差±5%也可能两边都同样错(比如canonical成环让真实索引数被低估)。要看趋势不要单看快照。
第三个洞察:noindex和Disallow是两件事,常常被新手混用。noindex是告诉Google"看了之后别收",Disallow是告诉Google"别看"。要让Google看到noindex必须允许Google爬。这是12周里踩过最深的一个坑,写出来希望帮其他团队避开。
site:命令最常见的5个误判到底怎么绕开?
下面这5个误判是实战里见过最多的,每个都对应一个有效避坑动作。
误判1:把"约X个结果"当精确数
这条前面讲过——结果页顶部的"约X个结果"是估算值,不是精确计数,浮动±15-30%是常态。避坑动作:日动作扫看趋势不看绝对值,权威核对走GSC。
误判2:忘记www/不含www区别
site:www.domain.com和site:domain.com不一定返回同样的数字——如果站点没把两者301到统一版本,Google可能把它们当两个不同站。避坑动作:永远写跟canonical一致的版本,做301统一前不混用。
误判3:忽略子域名
site:domain.com会包含所有子域名(blog.domain.com、shop.domain.com、help.domain.com都会算进去)。如果你想只看主域,要用site:www.domain.com -site:blog.domain.com -site:shop.domain.com把子域排除掉。
误判4:把site:数字当成"未来排名潜力"
被收的页面数和能拿到排名的页面数是两回事——一个站可能site:命令显示1万页被收,但实际能拿到流量的可能只有300页。避坑动作:site:数字只看索引状况健康度,流量潜力看GSC的"展示"列表+"点击"列表。
误判5:用site:命令查到的页面顺序当排名顺序
site:命令的结果排序不是"自然搜索排名"——它的排序逻辑是"Google认为最能代表这个站的页面优先",跟具体查询词的排名是两套系统。所以site:命令第一个出来的页面不一定就是品牌词排名第一的页面。避坑动作:要看具体查询词的排名走GSC的"查询"报告或第三方排名工具。
常见问题解答
site:命令的结果数字为什么每次刷新都不一样?
结果页顶部的"约X个结果"是Google的快速估算值不是精确计数,浮动±15-30%是常态。同样查询在凌晨与下午、不同IP、登录与无痕模式跑出来的数字都可能不同。这是Google为了快速响应做的近似估算,做SEO诊断要看趋势不看单次绝对值,权威核对要走GSC。
site:命令显示800条但GSC说已编入索引3000条,哪个对?
GSC更接近权威真值但有1-3天滞后,site:命令是实时但模糊有±30%估算误差。这种3-4倍的差距通常是大量"软索引未展示"页面没出现在site:命令结果里。先去GSC看具体哪些URL在"已编入索引"列表,再用URL检查工具对头部几条深挖看Google为什么不展示。
site:命令查到的页面顺序是不是就是自然搜索排名?
不是。site:命令的排序逻辑是"Google认为最能代表该站的页面优先"跟查询词排名是两套系统。所以site:命令第一条出来的页面不一定就是该站品牌词排名第一的页面。要看具体词排名走GSC的"查询"报告或Ahrefs/Semrush这类专门排名追踪工具。
用site:命令查发现某些标签页/搜索页被收了,该怎么处理?
先把这些URL加meta robots noindex让Google下次抓取时看到指令;同时千万别立刻在robots.txt里Disallow——Disallow会让Google根本爬不到这些页读不到noindex,反而让URL一直留在索引里。等GSC报告确认页面退出索引后再决定要不要Disallow。
能不能用site:命令查竞品的索引状况?
能但只能拿大盘信息——竞品域名跑site:competitor.com能看到大概多少页被收、目录分布大致如何、是不是有不该收的内容。但能拿到的颗粒度远不如自家站(自家有GSC可以看具体URL状态),所以site:命令查竞品适合做"竞品规模快扫"不适合做"竞品深度诊断"。
AI搜索时代site:命令还重要吗?
仍然重要而且用法扩展了。除了传统的"诊断Google索引状况",现在还能用来反查AI搜索引用源、检测AI Overview引用、对照内容簇的AI抽取密度。AI爬虫与Googlebot抓取边界不完全一致,site:命令成了"AI搜索可见性"反向诊断的便宜工具。
site:命令对中文站和英文站效果有区别吗?
基本没本质区别,但中文站做精确短语匹配时要注意分词差异——中文用site:domain.com "完整短语"能精确匹配,但单字查询命中率可能比英文站低。另外中文站如果用了拼音URL,要分别跑拼音版和中文版site:命令看Google把哪个版本当canonical。
权威参考资料
本文标题:《site命令怎么用?Google索引诊断的场景与误判》
本文链接:https://zhangwenbao.com/site-command-seo-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0