EntityMap是什么?一个给AI的实体声明文件要不要现在配

本文目录
- EntityMap到底是什么?一句话先讲明白
- 它想治的是一个什么样的老毛病?
- 它和sitemap、schema、llms.txt、agents.md差在哪?
- entitymap.json长什么样?
- 怎么把它放到网站上,AI才找得到?
- AI读到它之后会怎么用?
- 谁在背后推这个标准,靠不靠谱?
- 配了entitymap.json,AI就会优先引用我吗?
- 它会不会又是一个llms.txt?
- Google、OpenAI这些厂商到底认不认?
- 归因信息真能在AI那头活下来吗?
- 哪类网站现在值得配,哪类先放着?
- 它和你已经在做的“实体优化”是什么关系?
- 自己手写还是等工具成熟?
- 配好之后,怎么知道AI真的读了?
- 关于EntityMap的三个常见误区
- EntityMap能根治AI幻觉吗?
- 出海做多引擎AI可见度,它排得上号吗?
- 站在GEO的角度,该怎么看它?
- 想试水的话,5步落地清单
- 常见问题解答
- 权威参考资料
摘要:EntityMap是2026年6月刚进公示期的一个开放标准:让你在网站根目录放一个entitymap.json,告诉AI你覆盖哪些实体、它们怎么关联、证据在哪。它要治的是AI张冠李戴——编造你没有的产品、安一个不存在的高管、错引你的能力。但我把规范读完,又把它和已经凉掉的llms.txt摆一起比,结论是:文件结构设计得很用心,真正的悬念全在采纳——主流AI厂商目前没有一家公开说会读它。这篇讲清它长什么样、怎么发布、谁在推、和你在做的实体优化是什么关系,最后给一张哪类站值得配的决策表。
最近后台陆续有人转给我同一条消息:“又出了个新标准叫EntityMap,说是能让AI看懂你的网站,连schema.org的创始人都背书了,是不是得赶紧配上?”——附带的潜台词通常是“别人配了我没配会不会吃亏”。
先把结论放前头,省得你纠结一整天:值得了解,但绝大多数站现在不用急着上手。下面把这套东西从规范到现实一层层拆开,既讲清它设计得好的地方,也讲明白它最大的不确定性卡在哪儿,你看完自己就能判断要不要动手。
EntityMap到底是什么?一句话先讲明白
用一句话概括:EntityMap是一个让你用单个文件向AI声明“本站知识全貌”的开放标准。你在域名根目录放一个entitymap.json,里面写明三件事:你覆盖哪些实体(产品、服务、人物、概念、地点等),这些实体之间是什么关系,以及每一条说法的证据出自你网站的哪个页面。
最好理解的类比是拿它跟sitemap比。sitemap.xml告诉搜索引擎“本站有哪些页面”,是一张URL清单;entitymap.json告诉AI系统“本站懂哪些东西、它们怎么连在一起”,是一张意义和证据的地图。一个回答“你有什么页”,一个回答“你是谁、你知道什么”。这就是它名字里那个“Entity(实体)”的由来——它不是按页组织的,是按你这门生意里的关键事物组织的。
它的官方定位是“给AI系统、检索管线和大模型应用读的、实体优先的网站知识索引”。换句话说,它瞄准的读者根本不是人,也不完全是传统爬虫,而是那些要把你的内容拆碎、塞进向量库、再重新组织成一段答案的AI。
它想治的是一个什么样的老毛病?
你大概遇到过这种场景:去问AI你自己的品牌,它一本正经地报出一个你从没出过的产品型号,或者给你公司安了个查无此人的“CEO”,再或者把你某项服务的能力说得离谱。这不是AI故意黑你,而是它在用一堆从各处抓来的碎片重新拼答案,拼的时候没有一个权威源头校准,就容易拼歪。
问题的根子在于,现在AI理解一个网站的方式是“抓页面、切段落、猜关系”。它把你几十上百个页面抓下来,切成一段一段,再靠概率去猜“这个产品”和“那个功能”是不是一回事、这个人是不是负责那条线。猜错的概率,随着你站点实体越复杂越高。这背后其实是个实体消歧的问题,我之前专门拆过实体消歧机制怎么影响SEO以及该管控哪些信号,EntityMap想做的,相当于把消歧这件事从“让AI去猜”改成“由你直接声明”。
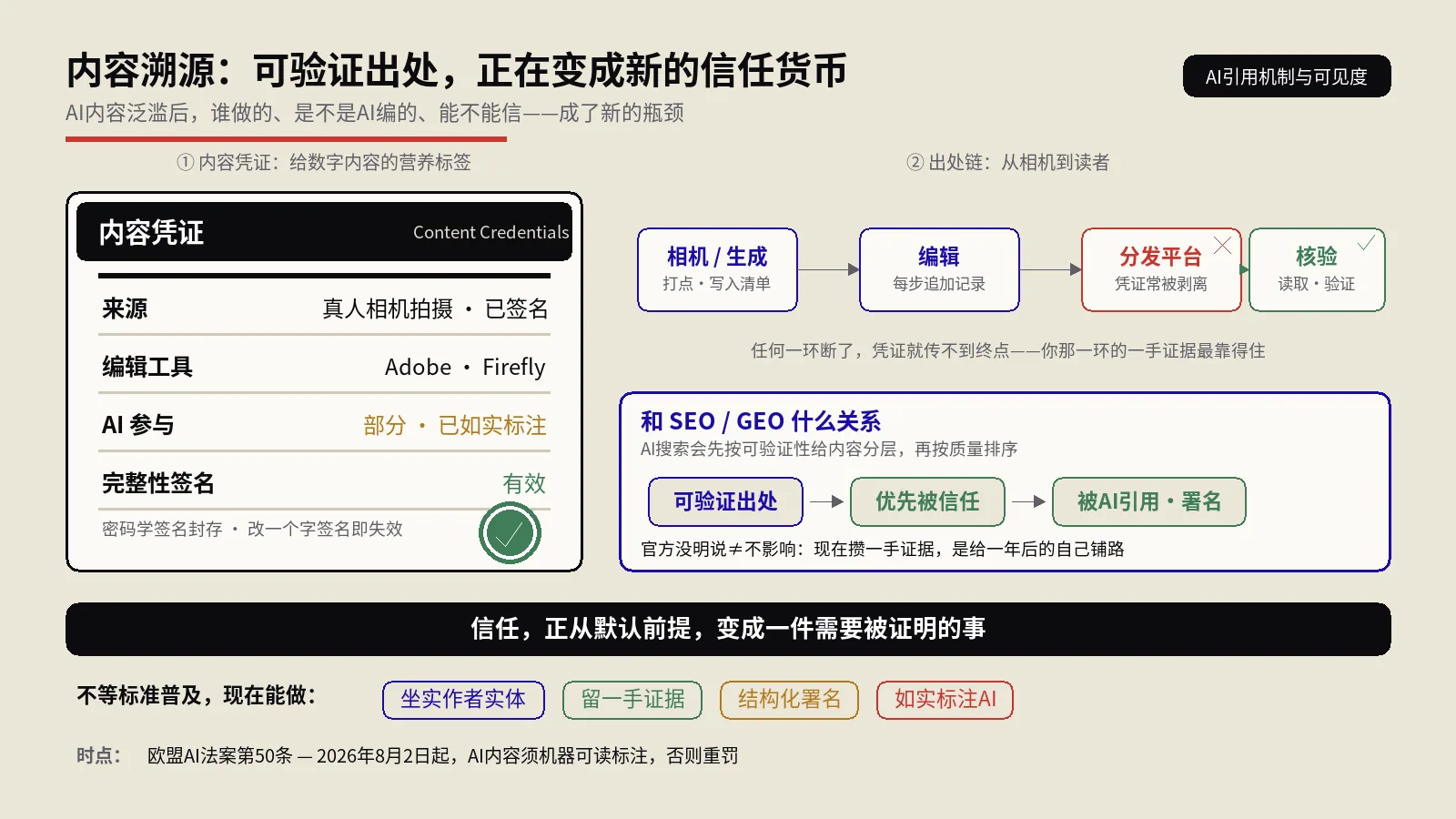
顺带还解决一个归因问题。你的内容被AI拆碎、聚合、存进数据库之后,“这句话原本出自谁”这个信息往往就丢了。EntityMap给每一条证据都拴上来源URL和发布者名字,理论上让归因信息能跟着内容一路活下去。这一点对靠内容立身的站点格外要紧——被引用却不留名,等于白干。
它和sitemap、schema、llms.txt、agents.md差在哪?
这几样东西最容易被搅成一锅粥,因为它们都是“放在网站上给机器读的文件”。但各管各的,分工其实很清楚。下面这张表帮你一眼分开:
| 文件 | 回答的问题 | 读者 | 组织方式 |
|---|---|---|---|
| sitemap.xml | 本站有哪些页面 | 搜索引擎爬虫 | 按URL |
| schema.org结构化数据 | 这一页讲的是什么 | 搜索引擎 | 按单页 |
| llms.txt | AI该优先读哪些内容 | 大模型 | 按内容索引 |
| agents.md | AI代理来本站怎么行动 | AI代理 | 按操作说明 |
| entitymap.json | 本站懂哪些实体、怎么关联、证据在哪 | AI检索系统 | 按实体 |
看清楚就会发现,EntityMap和它们不是替代关系,是补位。schema.org描述的是单页内容,sitemap列的是页面清单,而EntityMap想填的是“整站层面的知识结构”这块空白——你这门生意由哪些实体构成、它们如何串成一张网。它跟同属“AI可读文件”家族的agents.md也不冲突,我之前拆过Shopify默认上线agents.md到底是不是AI流量神器,那个管的是“代理来了怎么动作”,这个管的是“你到底是谁”,一个偏行为一个偏身份。
entitymap.json长什么样?
空谈结构不如看一眼真东西。按v1.0规范,一个最小可用的entitymap.json大致长这样:
{
"version": "1.0",
"schema": "https://entitymap.org/spec/v1.0",
"publisher": { "name": "户外电源旗舰店", "url": "https://example.com" },
"generated": "2026-06-03T00:00:00Z",
"entities": [
{
"entityId": "e_001",
"@type": "Product",
"name": "便携储能电源P2000",
"description": "面向露营场景的2000瓦时便携储能电源。",
"hasChunks": [
{
"chunkId": "c_001",
"text": "P2000支持2000瓦时容量,常温循环寿命3000次以上。",
"sourceUrl": "https://example.com/p2000",
"pageTitle": "P2000产品页",
"publisher": "户外电源旗舰店"
}
]
}
]
}结构上是三层套娃。最外层是根对象,必填version、schema、publisher、generated和entities。每个实体(entity)必填entityId、类型、名称、描述,外加至少一个证据块(hasChunks)。每个证据块(chunk)必填chunkId、原文、来源URL、页面标题和发布者。三类对象加起来,大约12个必填字段,剩下都是可选的增强项。
这里有个容易翻车的硬约束:每个证据块里的publisher字段,必须和根对象里的publisher.name一字不差,连大小写和空格都要对上。这种刻板看着烦,其实是为了让归因链可被机器严格校验——发布者一对不上,整条证据的可信度就打折。
除了实体和证据,规范还支持relations(关系)对象,用predicate和targetName描述“这个产品改善那个结果”“这个人负责那条线”这类连接,给低置信度的推断关系还要额外标confidence。站点实体超过200个时,规范建议分片,用一个清单文件加若干分片文件来组织,免得一个文件大到没法处理。
怎么把它放到网站上,AI才找得到?
发布这一步不复杂。规范要求把两个文件放在域名根目录、且不带任何登录验证:一个是机器读的entitymap.json,一个是给人看的entitymap.html。两份内容对应,一份给AI,一份方便你自己核对。
光放上去还不够,得让AI知道它在哪。规范给了三条发现路径,建议都做上:第一,在robots.txt里加一行声明指向你的entitymap.json;第二,在网页head里加一个link标签,rel写成entitymap;第三,在全站页脚放一个指向entitymap.html的链接。规范还顺带建议把entitymap.html列进sitemap.xml,给个偏高的优先级和每周更新的频率,等于多铺一条被发现的路。
这套发现机制其实很眼熟——和当年sitemap、robots、llms.txt推广时的玩法一模一样:放文件、加声明、等机器来读。眼熟也意味着,它能不能起作用,最终不取决于你放得多规范,而取决于另一头愿不愿意来读。这是后面要重点泼冷水的地方。
AI读到它之后会怎么用?
规范把“消费方”分成了三个由浅入深的一致性级别,这部分是很多新闻报道没讲透、但恰恰最能说明它野心的地方。
第一级是证据块消费方:AI在把你的内容做成向量嵌入时,顺手把publisher这类归因信息一起保留下来,让“这段话是谁说的”跟着数据一路活到向量库里。第二级是实体消费方:AI会用你提供的别名、规范名去做实体消歧,遇到你声明的专有术语,直接当权威定义采信,而不是自己瞎猜。第三级是图谱消费方:AI会顺着你声明的关系网去做多跳推理,同时对你标了“推断”的低置信关系打折处理,还会去核验认证类声明。
举个落到实处的例子:你在文件里声明“P2000”的别名包括“便携储能P2000”和“P2000电源”,做到第二级的AI遇到这三种叫法就知道指的是同一个产品,不会拆成三件;做不到这一级的AI,照样可能把它们当成三个不同的东西去理解。同样一份声明,在不同成熟度的AI那里,效果天差地别——这就是三个级别的差异最终落到你身上的实际后果。
层级越高,对AI的要求也越高——它得真把你这套声明当回事,一级级用上去。这里就埋着EntityMap的命门:文件标准写得再周密,也只是规定了“如果AI愿意读,它该怎么读”。愿不愿意读,规范说了不算。
谁在背后推这个标准,靠不靠谱?
这一层得讲实话,因为它直接关系到你该投入多少信任。据发起方InLinks的官方介绍,EntityMap由Fred Laurent发起、由Dixon Jones支持推动。Dixon Jones是搜索和实体优化领域的老兵,也是Waikay的联合创始人,他那句“网络是围着页面、链接和散文建起来的,AI检索需要一层更清晰的意义和证据”确实点中了问题。更给它撑场面的是,schema.org的联合创始人R.V. Guha审阅并背书了这个项目——这在结构化数据这个圈子里是相当有分量的信用背书。
但有两个细节你得心里有数。其一,参考实现是Waikay自家的EntityMap生成器,也就是说,推标准的人手里正好有一款卖你“一键生成这种文件”的工具。这不一定是坏事,schema.org当年也是巨头联合推的,但“提出标准的人正好卖配套工具”这个利益关系,值得你在评估时打个问号。
其二,所谓“公示期”其实是2026年6月1日到30日,7月1日正式发布,可规范本身在3月底就已经迭代到v1.0稳定版了。换句话说,公示更像是请大家来验证一份基本定稿的方案,而不是从零共建。这不影响它的技术质量,但能帮你校准期待:这是一个由厂商主导、邀请社区背书的提案,不是一个跑了多年、被巨头实战验证过的成熟标准。
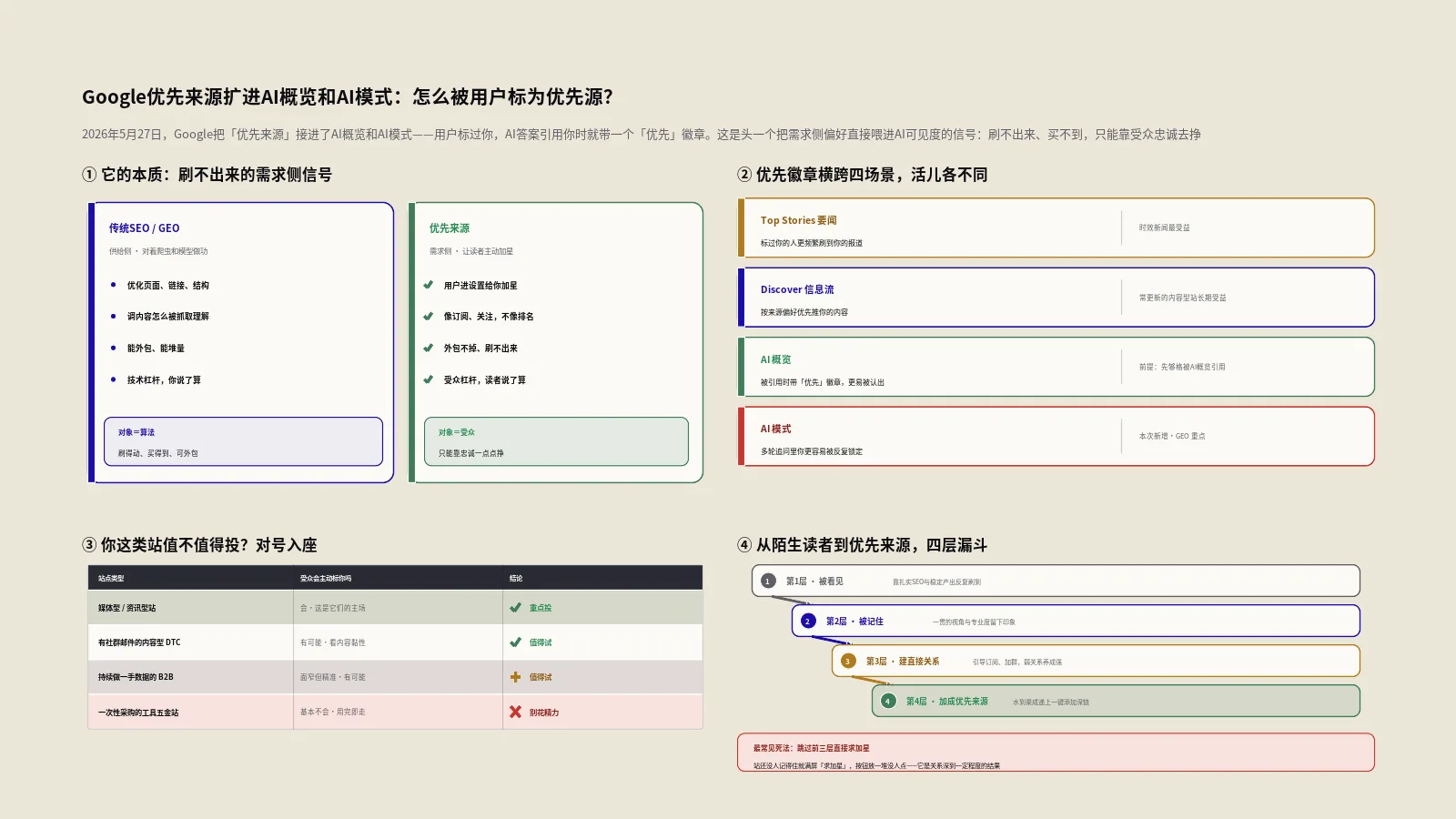
配了entitymap.json,AI就会优先引用我吗?
不会,至少现在不会。这是整件事最需要清醒的一点。EntityMap是一个纯发布侧的自愿文件,你把它放上去,本质上是在“备着”——等有AI厂商愿意来读,它才产生价值。截至目前,OpenAI、Google、Anthropic这些主流玩家,没有一家公开宣布会读取entitymap.json。
更直接的反证来自Google官方。Google在AI功能文档里明说,AI概览和AI模式沿用的就是常规SEO那一套,不需要任何特殊文件、不需要专门的markup。这意味着,至少在Google这边,你配不配entitymap.json,对你出现在AI答案里的概率,目前没有任何已知的直接影响。把这句话刻在心里,能帮你避开“配了就以为稳了”的错觉。
它会不会又是一个llms.txt?
这是我脑子里第一个冒出来的问题,因为剧本太像了。llms.txt当年也是这个套路:一个让你放在网站上、告诉AI该读什么的自愿文件,社区一度炒得很热。结果呢?保哥带人做过10个站90天的llms.txt实测,结论是主流AI压根不稳定地读它,投入产出比低到尴尬,后来Google更是直接表态搜索不需要它。
EntityMap和llms.txt面临的是同一道坎:发布侧自愿标准的价值,100%取决于消费侧愿不愿意配合。区别在于,EntityMap有Guha背书、结构设计更严谨、瞄准的痛点(实体归因)也更具体,理论上比llms.txt更有机会被认真对待。但“更有机会”不等于“已经被采纳”。在没有任何一家AI厂商松口之前,把它当成“可能成、也可能凉”的早期实验,是更稳妥的姿态。
Google、OpenAI这些厂商到底认不认?
把采纳这件事说透:一个标准能不能成,从来不是文件写得好不好决定的,而是用它的人多不多决定的。schema.org是最好的例子——它也有Guha这样的人物,但它真正普及,靠的是Google、微软、雅虎当年联手把它纳进各自的产品,并且用了好几年才让站长们普遍接受。标准的命运握在消费方手里,不在提案方手里。
对EntityMap来说,Guha的背书是一张很好的入场券,能让人愿意多看两眼,但它换不来采纳本身。真正的信号,是某一天某个AI厂商在官方文档里写下“我们会读取entitymap.json”。在那之前,你看到的所有“它很重要”的论调,本质上都还是提案方和早期布道者的一厢情愿。盯紧厂商动向,比盯紧标准本身更有用。
归因信息真能在AI那头活下来吗?
EntityMap一个很打动人的卖点是“保住归因”——给每条证据拴上来源和发布者,让你的内容被拆碎、聚合、塞进向量库之后,还能记得是你说的。这个设计意图是好的,但能不能落地,又得看消费方。
按规范,只有做到第一级(证据块消费方)的AI,才会在生成嵌入时把publisher这类元数据一起留下。如果对接它的AI压根没实现这一级,你写得再工整的归因字段,进了对方的处理管线照样被丢掉。说白了,归因能不能在AI那头活下来,不是你单方面声明就能保证的,是你和读取方双方都得配合才成立。这又一次回到那个核心:标准定义了理想行为,现实取决于谁真的照做。
哪类网站现在值得配,哪类先放着?
抛开热闹,落到你自己身上:现在该不该动手,取决于你站点的实体有多复杂、以及你愿意为一个早期标准押多少注。下面这张决策表给你个判断框架。
| 你的情况 | 建议 | 为什么 |
|---|---|---|
| 多SKU、多产品线,实体关系交织 | 可以小成本试水 | 实体越复杂,AI越容易拼错,声明的边际收益越大 |
| 专业服务、B2B,有人物+概念+方法论 | 值得关注,先把内容做扎实 | 这类站本就吃实体权威,但权威靠内容不靠声明文件 |
| 单品类、几个产品的小站 | 先不急 | 实体简单,AI本来就不太会搞错,回报有限 |
| 资源紧、连基础schema都没配齐 | 放一放 | 先做投入产出比明确的基础项,别本末倒置 |
举两个保哥手上的真实对照。一个做户外储能的DTC客户,产品线铺得很开——按容量分档、按场景分系列、还套着一堆配件,AI去理解它的产品矩阵时经常张冠李戴,把不同档位的参数串错。这种站,把实体关系显式声明一遍,哪怕只是为了自己理清,也不亏,等标准万一成了就是顺水推舟。另一个做精密注塑件的B2B客户,全站核心就一类产品加创始人多年的工艺判断,实体简单得很,AI很难搞错,与其折腾entitymap.json,不如把创始人那套判断写成更扎实的内容,性价比高得多。
它和你已经在做的“实体优化”是什么关系?
很多人会把EntityMap和实体优化划等号,这是个误会。EntityMap是声明层——它帮你把已有的实体关系明明白白说出来;但它造不出权威。如果你在Google知识图谱、维基数据、各路权威站里本来就没什么实体根基,声明得再漂亮,AI也没有旁证去采信你。声明是地图,地图画得好,前提是地上真有路。
所以它和实体权威建设是上下游关系,不是替代关系。你得先有实体根基,我之前讲过实体主页Entity Home怎么给品牌身份搭地基,那是“让外部世界认得你这个实体”的功夫;EntityMap则是在你已经有了根基之后,“把家底整理成一张清单递给AI”。次序不能倒——没盖好楼就先挂门牌,门牌指向的是一片空地,反而暴露你的单薄。
自己手写还是等工具成熟?
真要试,有两条路。一条是用现成工具,发起方Waikay提供了参考实现的生成器,能帮你把站点扒一遍自动生成文件,省去手写的麻烦;entitymap.org也提供了校验器,配好后能验一遍格式合不合规。另一条是自己照规范手写或脚本生成,灵活但容易踩坑——前面说的publisher字段大小写必须一字不差、证据块至少一个、分片清单怎么组织,这些细节手写时极易出错,配完务必过一遍校验器。
保哥的建议是:现阶段别投入太重。如果只是想试水、看看自家实体长什么样,用生成器跑一版、过下校验、放上去就行,别花大力气手工精雕。毕竟标准还没被任何厂商采纳,重投入的时机没到。等哪天有AI厂商官宣支持,再回头精修也不迟。
配好之后,怎么知道AI真的读了?
这是个尴尬但绕不开的问题:EntityMap没有官方的“读取报告”告诉你AI有没有来读、读了多少。所以你只能靠替身指标侧面观察,主要看三类信号。
第一类是引用准确度:定期拿你的核心实体去问几家主流AI,看它报出来的产品名、人物、能力描述对不对、有没有比配置前更准。第二类是品牌词与直接访问:实体被AI正确理解、正确推荐,往往会反映成更多人直接搜你的品牌词、直接访问你的站。第三类是实体识别状态:观察Google知识面板、各AI对你这个实体的认知有没有变清晰。需要强调的是,这几类信号都受很多因素影响,很难干净地归因到entitymap.json头上——这也是早期标准的通病,没有干净的因果,只能看趋势。
关于EntityMap的三个常见误区
最后把容易让人栽跟头的三个误区点一下,省得你被带偏。
第一个误区:配了就能涨可见度。前面反复说了,没有厂商采纳,配它现在换不来直接的可见度提升,它是“备着”不是“开关”。第二个误区:它能替代schema.org。不能,两者管的是不同层面,schema描述单页、EntityMap声明整站知识结构,是互补不是二选一,更不该为了上EntityMap把schema停了。第三个误区:配一次就一劳永逸。你的产品、人物、内容会变,entitymap.json得跟着更新,规范建议每周维护,放上去就不管,过段时间它声明的就是一份过期的家底,反而误导。
EntityMap能根治AI幻觉吗?
别抱这个期待。EntityMap最多算给AI递了一份权威参考,但它管不住AI不去别处乱抓。AI生成一段关于你的答案时,会综合无数来源——你的站、第三方报道、论坛讨论、它训练时记住的旧数据,你的entitymap.json只是其中一个输入,而且还是个需要对方主动来读、主动采信的输入,它没有强制力。
换个角度说,如果网上关于你的错误信息铺天盖地,光靠声明一份正确的entitymap.json,扭不过那股大流。治幻觉的根本,还是得让正确信息在全网范围内足够多、足够一致、足够权威,让AI无论从哪儿抓都抓到对的。EntityMap能做的,是在你把这些功课做到位之后,多给AI一个干净、明确的官方口径,降低它拼错的概率——是锦上添花,不是雪中送炭。
所以把它的作用摆正:它是降低误读概率的一个辅助手段,不是一键纠错的开关。指望配上它,AI就再不会说错你,注定要失望。真正决定AI怎么描述你的,永远是你在全网留下的信息总和,entitymap.json只是这堆信息里你能完全掌控的那一小块。
出海做多引擎AI可见度,它排得上号吗?
出海的朋友看这类标准,得多问一层:它对我面对的那些AI引擎,覆盖得到吗?这里有个常被忽略的现实——出海场景里,能给你带来AI流量的远不止Google一家,ChatGPT、Perplexity、Copilot各有各的取料管线,而这些引擎认不认entitymap.json,目前同样是个未知数,没有谁公开表过态。指望一个文件通吃所有引擎,不现实。
更棘手的是多语言。出海站常常一套实体要在好几种语言下呈现,AI跨语言理解你的实体时,张冠李戴的概率比单语言站高得多——同一个产品在英文站和德文站被当成两个东西,是常有的事。EntityMap用entityId和别名字段把“这几个名字其实是同一个实体”显式声明出来,理论上正好能压一压这种跨语言歧义,这是它对出海站相对更有意义的一个点。
但优先级还是要拎清。对出海站来说,比配entitymap.json更紧要的,是先把多语言内容质量、hreflang、各主要市场的实体根基这些基本盘做扎实。这些是确定有回报的功课,EntityMap是个加分项,加在扎实的基本盘之上才有意义,反过来——基本盘还漏风就先去配声明文件——是把力气使错了地方。
站在GEO的角度,该怎么看它?
把EntityMap放进GEO这盘大棋里看,它的位置其实很清楚:它是声明层的一块拼图,是地基不是楼。它能帮你把已有的东西整理清楚、递给AI,但它替代不了真正决定你被不被AI引用的东西——内容本身的质量、实体本身的权威、信息本身的稀缺。一个内容空洞的站,配再完美的entitymap.json,也只是把空洞声明得更工整而已。
这跟保哥一贯的判断一致:所有这些“给AI看的文件”,无论是llms.txt、agents.md还是EntityMap,都是放大器,不是发动机。它们能让好内容更容易被AI看懂、看全,但放大的前提是你手里得有值得放大的东西。把功夫先下在内容和实体根基上,这些声明文件该配的时候顺手配,次序对了,才不会本末倒置。
想试水的话,5步落地清单
如果看完你还是想现在就上手感受一下,按这个顺序来,成本最低:
- 先盘实体:把你站点最核心的十几个实体列出来——主打产品、关键人物、核心概念,心里先有张图,这一步本身就有用。
- 用生成器跑一版:拿Waikay的参考实现自动生成entitymap.json,别一上来就手写,先看机器生成的版本长什么样。
- 过校验器:用entitymap.org的校验工具验一遍格式,重点盯publisher字段一致、每个实体至少一个证据块这类硬约束。
- 配齐发现机制:robots.txt加一行、head加link标签、页脚放链接,三条路都铺上,再把entitymap.html列进sitemap。
- 记下基线、定期观察:把当前AI对你核心实体的描述准确度记一份基线,之后每月对比一次,看趋势而不是看绝对值。
整套走下来花不了多少力气,关键是带着“试水”的心态做,别当成救命稻草。它现在的价值,更多是逼你把自家实体梳理一遍,以及在标准万一跑通时占个先手——仅此而已,别加戏。
常见问题解答
EntityMap现在是正式标准了吗?
还没正式发布。它在2026年6月1日到30日走公示期,7月1日才正式发布v1.0。要注意的是,规范本身早在3月底就迭代到了v1.0稳定版,所谓公示更像是请社区来验证一份基本定稿的方案,而不是从零共建。所以它是个由厂商主导、邀请背书的提案,离“被巨头实战验证过的成熟标准”还有距离。
配了entitymap.json,AI就会优先引用我吗?
不会。它是发布侧的自愿文件,主流AI厂商目前没有一家公开宣布会读取它。配它的意义是把信息整理好备着、等采纳,而不是立刻换来可见度。Google官方更是明说AI功能不需要任何特殊文件,所以别指望配上就稳了。
EntityMap和llms.txt有什么区别?
侧重不同。llms.txt偏内容索引,告诉AI该优先读哪些页;EntityMap偏知识声明,告诉AI你有哪些实体、怎么关联、证据在哪。但两者面临同一个根本问题:AI厂商认不认。llms.txt实测下来主流AI并不稳定读取,EntityMap会不会重蹈覆辙,现在下结论还太早。
小站有必要配EntityMap吗?
看实体复杂度。单品类、就几个产品的小站不急,AI本来也不太会把简单实体搞错,先把网页质量和基础结构化数据做扎实更划算。实体复杂的站——多SKU、多产品线、人物和概念交织——才更能从这种显式声明里获益,哪怕只是为了自己理清关系。
配EntityMap会影响我在Google上的排名吗?
不会。Google官方明确说AI概览和AI模式沿用常规SEO,不需要任何特殊文件。EntityMap影响的是经由支持它的检索系统取料的那部分AI,和Google的自然排名是两条互不干扰的线,配了不会涨排名,不配也不会掉。
权威参考资料
本文标题:《EntityMap是什么?一个给AI的实体声明文件要不要现在配》
本文链接:https://zhangwenbao.com/entitymap-ai-readable-standard-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0