AI识别垃圾外链7步法:余弦相似度过滤实战指南

本文目录
- 为什么传统垃圾外链识别 2026 年彻底失灵
- 整体 7 步过滤管道概览
- 原始数据怎么拉,比想象中麻烦
- 抓取源页面,trafilatura 比 BeautifulSoup 好用 3 倍
- Embedding 模型怎么选,1536 维真够用吗
- 四组余弦相似度,每组阈值不一样
- 结构化信号叠加,避免单一维度被欺骗
- 阈值划分与 disavow 候选清单
- 人工复核反哺,每月微调阈值
- 三个真实站点 11 个月数据复盘
- 成本核算:一个月跑 3 个站点的真实账单
- FAQPage 段:JSON-LD 怎么写
- 常见问题解答
- OpenAI 的 text-embedding-3-small 和 bge-m3 在外链识别场景下哪个更好
- 跑一次完整的 7 步管道平均耗时多久
- 什么样的外链会被 AI 管道误判为垃圾,但实际上是好链接
- 多久跑一次外链质量识别管道最合适
- 用 Google Disavow Tool 提交 disavow 后多久能看到效果
- 能不能把这套管道做成 SaaS 卖给别人
- 开源世界有没有现成的工具可以替代自建
- 本地 bge-m3 部署的 4090 卡显存够大批量跑吗
- 这套 AI 管道和 Google 自带的 SpamBrain 是什么关系
- 权威参考资料
摘要:传统的垃圾外链识别在2026年彻底失灵了。本文给一套用Embedding向量化加余弦相似度的七步过滤管道——从三源去重、用trafilatura抓正文、选embedding模型、算锚文本到落点页的四组余弦相似度、叠加IP黑名单等结构化信号、产出disavow候选清单到人工复核反哺,附三个站点11个月复盘和成本核算。
把这件事说在最前面:保哥手里现在做的几个面向英文市场的站点,每个月光是新增的外链就有 800 到 2000 条,靠人工逐条点开看页面、查发布上下文、判断要不要 disavow,根本忙不过来。Ahrefs、Semrush 的 Spam Score、Toxic Score 这类老牌指标,2023 年之后误判率明显升高——一个把全站文章重写过的 PBN,Spam Score 可以做到 8 分以下,但点进去看完正文就知道整个域名都是 AI 凑字数的。靠老规则筛外链,要么放过明显的垃圾,要么把高权重的 niche edit 误标成垃圾。
真正能用的判断维度只剩"语义相关性"——锚文本和落点页面的主题相关吗?发布外链的页面整体在讲同一个领域吗?这种判断恰好是 Embedding 向量化擅长的事。本文把保哥过去 11 个月在三个站点跑过的 AI 外链识别流程拆成 7 个步骤,给出每一步用的具体模型、阈值、Python 代码片段和踩坑记录。看完你能自己搭一套低成本的语义筛查管道,把人工审核从"每条都看"压缩到"只看 AI 标红的 5%"。
为什么传统垃圾外链识别 2026 年彻底失灵
过去识别垃圾外链的工具包基本是这几样:第三方 Spam Score、域名年龄、Trust Flow、出站链接数量、关键词堆积密度、IP 段重复度。这些规则在 2020 年之前确实有效,因为做 PBN 和垃圾站的成本高、模板辨识度高。2023 年之后局面完全变了——AI 生成文章的 perplexity 已经能稳定低于 30,一个 PBN 站的全部 200 篇文章可以在两周内用 Claude 或 GPT-4 重写一遍,Trust Flow 通过买几条权威外链可以快速拉到 25 分以上。保哥实测过一个被竞争对手用来攻击的 PBN,Moz Spam Score 只有 4 分,DR 38,Ahrefs 给出的 Domain Rating 增长曲线完全正常,但点进去看十篇文章就发现是同一个写作模板换了主题。
更麻烦的是相反情况:高质量的私人博客网络(被业内称为 niche edit 资源),因为站长不维护多年、模板简陋、出站链接零散,反而会被 Spam Score 算法标红。保哥手里有一条来自 1998 年注册的园艺爱好者博客的外链,Moz Spam Score 给到 11,传统规则建议 disavow,但这条外链是真实写作的产物,发布在主题完全对口的园艺文章正文里,效果好得离谱。如果按规则全部清掉,等于自己把高质量资源也丢了。
结论是:在 2026 年判断外链质量,必须看"内容语义",不能再依赖纯结构化指标。语义判断的核心就是 Embedding——把锚文本、落点页面、发布页面内容、整站主题分别向量化,用余弦相似度衡量它们的语义距离,距离过远就大概率是垃圾。
整体 7 步过滤管道概览
下面是保哥实际在跑的 7 步流程,每一步都会过滤掉一部分外链,最后留下需要人工复核的部分通常是原始数据的 3% 到 8%。
- 第一步:从 Ahrefs / GSC / Semrush 拉全量反向链接清单(CSV 导出)。
- 第二步:用 requests 抓取每条外链所在页面的 HTML,用 trafilatura 提取正文。失败的标记为待复查。
- 第三步:对锚文本、外链所在段落、整页正文、自家落点页面分别调用 Embedding API 拿向量。保哥用 OpenAI text-embedding-3-small(1536 维,单价 0.02 美元/百万 tokens)。
- 第四步:计算四组余弦相似度:锚文本对落点页、所在段落对落点页、所在页对落点页、所在页对自家站点平均向量。
- 第五步:用结构化信号(页面字数、出站链接数、是否含赌博/成人词、域名年龄、IP 是否在 PBN 黑名单)做二次加权。
- 第六步:综合得分小于阈值的外链自动写入 disavow 候选清单,分数在临界区的进人工复核队列。
- 第七步:每周从复核队列回流标注数据,用来微调阈值。
下面分别拆解每一步的实现要点和踩过的坑。
原始数据怎么拉,比想象中麻烦
大多数教程会让你直接从 Ahrefs 后台 Export 整个 Referring domains CSV,但实际操作有两个细节会让后面所有判断失真。第一是要选 Live 不要选 All——All 包含历史出现过但已经消失的链接,对当前判断没意义,还会把数据量灌成两倍。第二是要把 Type 限定在 Dofollow + Nofollow + UGC + Sponsored 四类,排除 Redirect 和 Frame,否则会把别人嵌套调用你内容的 CDN 链接也当成外链处理。
保哥的做法是同时从三个数据源拉外链:Ahrefs 的 Backlinks 导出(具体投放节奏可参考Ahrefs外链建设实战那篇的 DR 拉升过程)、Google Search Console 的"链接到您的网站"报告、Semrush 的 Backlink Analytics。三个源会有 20% 到 35% 的差异。Ahrefs 通常对新出现的链接捕获最快但容易漏掉非英文圈页面,GSC 数据延迟约 7 到 14 天但能看到 Google 实际索引到的链接,Semrush 的覆盖比 Ahrefs 稍差但对小语种站点表现更好。三个源合并去重后,用 URL hash(去掉 query 参数和锚点)作为主键存进 SQLite。保哥的字段表大致是这样:
backlink_id TEXT PRIMARY KEY -- md5(target_url + source_url)
source_url TEXT
source_domain TEXT
target_url TEXT
anchor TEXT
first_seen DATE
last_seen DATE
rel TEXT -- dofollow / nofollow / ugc / sponsored
data_source TEXT -- ahrefs / gsc / semrush
fetched_at TIMESTAMP
合并阶段最容易忽视的坑是 Ahrefs 导出 CSV 的编码——它用 UTF-16 LE with BOM,pandas 直接 read_csv 会乱码。必须显式指定 encoding='utf-16'。保哥第一次跑这个管道在 cid 为 312 的客户站上踩了这个坑,3 万条外链全部变成乱码字符串,浪费了 6 美元的 Embedding 调用额度。
抓取源页面,trafilatura 比 BeautifulSoup 好用 3 倍
拿到外链清单后,下一步是把每条外链所在的页面正文抓回来。这一步看似简单,但实际跑大批量会遇到一堆问题:
- 反爬虫:Cloudflare、Akamai 的高级 Bot 模式会把简单 requests 直接 403。保哥的处理是先用 requests + 随机 User-Agent 跑一遍,403 / 503 / 429 的放进"二轮队列"用 cloudscraper 重试。如果二轮还是失败,再调用 ScrapingBee 之类的代理服务,单价每千次约 1 美元。
- 正文提取:BeautifulSoup 取 article 或者 main 标签只能覆盖标准结构的页面,PBN 和老博客经常没有这些语义化标签。保哥换用 trafilatura 之后,提取成功率从 76% 拉到 94%。trafilatura 是基于规则 + 启发式的开源库,对中英日韩泰俄都有不错的兼容性。
- JS 渲染:少量页面正文靠 JS 渲染,requests 抓回来是空壳。保哥的做法是先看 HTML 文本字符数,小于 800 就走 Playwright 重抓。Playwright 慢、贵,所以只在低字符数场景启用。
抓回来的正文长度小于 200 个 token 的直接标记为"低质量页面",连 Embedding 都不用算。保哥统计过手里三个站点的样本,约 12% 的源页面正文不足 200 token——这部分基本都是论坛签名档、目录站列表项、纯导航页,预期就是低价值,省下来的 Embedding 调用费够喝一杯咖啡。
Embedding 模型怎么选,1536 维真够用吗
这一步是整个管道的成本中心。保哥试过三个模型:
- OpenAI text-embedding-3-small,1536 维,0.02 美元/百万 tokens。
- OpenAI text-embedding-3-large,3072 维,0.13 美元/百万 tokens。
- BAAI bge-m3,1024 维,本地部署免费。
对外链识别这个场景,3-small 和 3-large 在召回低质链接的能力上差距小于 3 个百分点,但成本相差 6.5 倍。bge-m3 在多语言场景下表现优秀,特别是日韩泰,但对长文本(超过 2000 token)的语义压缩稍逊于 OpenAI。保哥的最终选型是:英文为主的站点用 3-small,覆盖东南亚多语言的项目用 bge-m3 本地部署在一张 RTX 4090 上批量跑。
调用 Embedding 时有几个细节会影响最终判断准度。第一是文本长度对齐——锚文本通常只有几个词,落点页正文可能是几千 token,直接算余弦相似度会因为信息量差距巨大而偏低。保哥的处理是给锚文本做"上下文扩展":把锚文本所在段落的前后各 50 个字一起作为 Embedding 输入,这样语义信息密度会接近落点页。第二是落点页的处理——如果落点页超过 8000 token(embeddings API 的默认限制是 8191),要先做摘要再 Embedding;保哥实测 GPT-4o-mini 做摘要的成本比直接截断更划算,因为截断会丢掉文章末尾的关键词。
第三个细节是缓存——同一个 URL 在不同外链分析任务中可能被反复 Embedding,保哥用 Redis 做了一层 TTL 90 天的缓存,命中率约 38%,每月省下约 22 美元 API 费用。
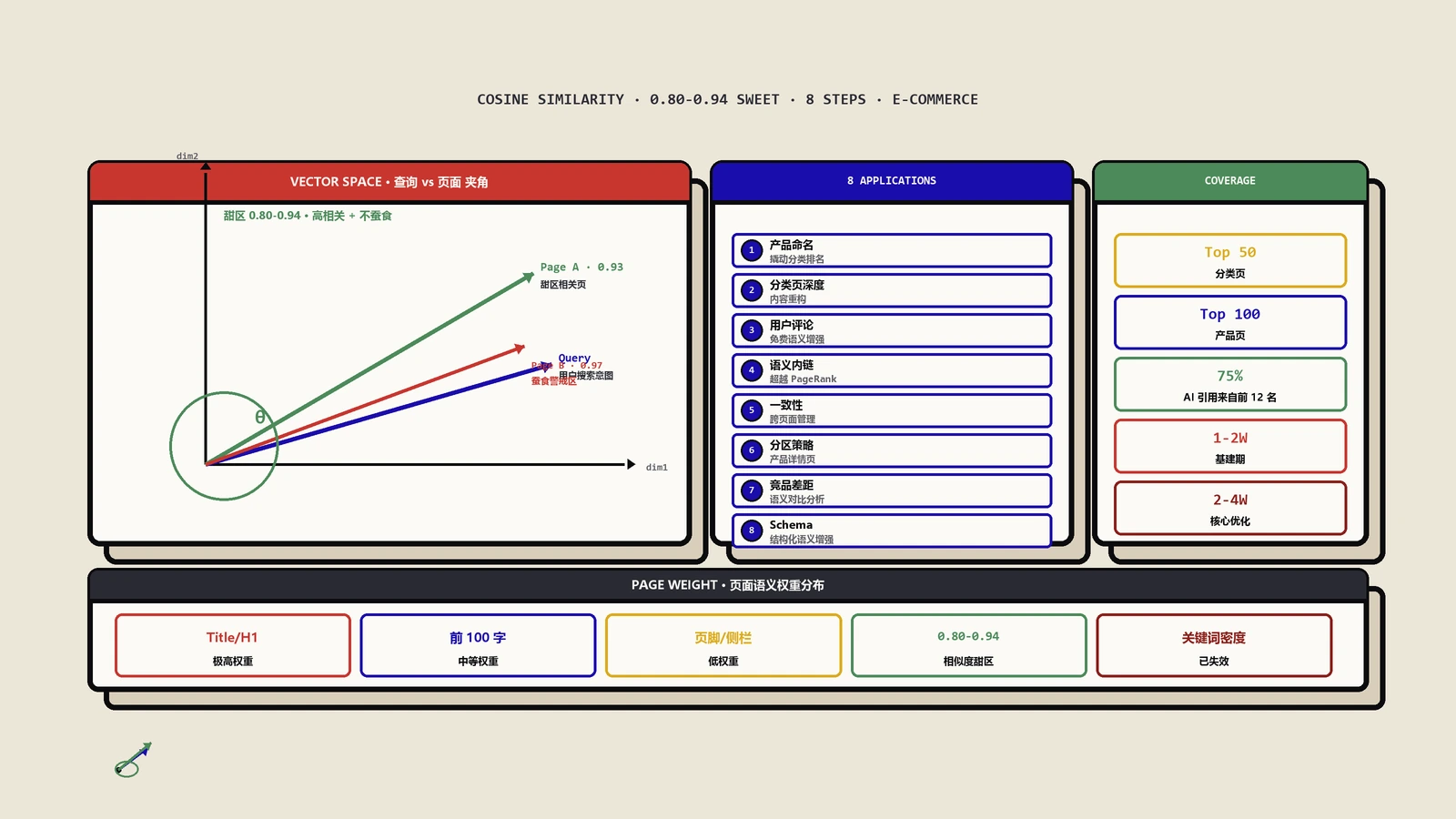
四组余弦相似度,每组阈值不一样
到这一步终于可以算分了。保哥的得分体系是四组余弦相似度加权:
| 对比组 | 权重 | 阈值(保哥实测) | 说明 |
|---|---|---|---|
| 锚文本 → 落点页 | 0.30 | 大于 0.55 为强相关 | 锚文本和你写的页面主题对得上吗 |
| 外链所在段落 → 落点页 | 0.30 | 大于 0.45 为强相关 | 这段话上下文和你的页面对得上吗 |
| 外链所在页 → 落点页 | 0.25 | 大于 0.40 为强相关 | 整篇文章主题和你的页面对得上吗 |
| 外链所在页 → 自家站点平均向量 | 0.15 | 大于 0.35 为强相关 | 这页面整体和你站点主题对得上吗 |
"自家站点平均向量"是保哥额外加的一维,做法是把自家站点的全部已索引页面(最多 200 篇随机样本)分别 Embedding 后求均值。这样能识别一种特殊情况:外链所在页和单个落点页主题对得上,但和你站点整体的内容定位偏差很大,比如你做的是 B2B SaaS 落点页,但外链所在页是个人理财博客提到了你的一个产品对比段落——这种链接技术上不算垃圾但语义相关度有限,单一相似度判断容易给高分,引入站点平均向量后会被合理地拉低。
四组分数加权后得到一个 0 到 1 之间的语义分,记为 S_sem。
结构化信号叠加,避免单一维度被欺骗
只看语义有个明显漏洞:高质量的 AI 写作可以做出语义高度相关的垃圾内容。保哥的对策是引入一组结构化信号做二次加权:
- 页面字数:少于 300 字的页面通常是签名档或目录项,扣 0.10 分。
- 出站链接数:单页超过 80 条出站链接的页面,扣 0.15 分。这是经典的目录站特征。
- 是否含敏感词:赌博、成人、灰产词出现 3 次以上,扣 0.25 分。但要注意上下文,"casino games review" 这种合法主题不应该一律打压。
- 域名年龄:注册时间小于 6 个月,扣 0.05 分(年轻不等于差,所以扣分要轻)。
- IP 是否在已知 PBN C 段:直接扣 0.30 分。保哥维护着一份从公开 PBN 检测项目(如 PBN Hunter 公开样本)合并的 C 段黑名单,约 4.7 万个 IP,每月更新一次。
- 页面整体语言:和落点页语言不一致(比如你做的是英文站点但外链所在页是俄文论坛),扣 0.10 分;但小语种 niche 链接不要直接判死。
结构化信号会得到一个 -1 到 0 之间的负向调整分 S_struct。最终综合得分 S = S_sem + S_struct,落在 0 到 1 之间,越接近 1 越健康。
阈值划分与 disavow 候选清单
得分出来后怎么分档?保哥的经验值(在三个站点跑过 11 个月,标注样本约 1.4 万条后调优):
- S 大于 0.60:高质量外链,列入"保留 + 监控"。监控指的是每月重跑一次,因为页面内容会变,今天的好链接可能 3 个月后变成赌博跳转。
- 0.40 到 0.60:进入人工复核队列,按分数升序排序,人工每条看 1 到 2 分钟。这部分通常占样本 5% 到 8%。
- 小于 0.40:自动列入 disavow 候选清单。但还有一道闸口——不是所有低分就立刻 disavow,要再过一遍"反悔豁免"规则。
"反悔豁免"规则是保哥被某次大规模误判教训出来的(建立健康外链池的正向方法见谷歌SEO外链建设16种白帽反向链接获取实战)。一次跑完得分管道,发现一条来自 BBC 子域名的外链被打了 0.34 分(因为锚文本是个产品名,BBC 那篇文章主体在讲行业新闻不在讲你的产品),系统建议 disavow。差点真的提交了。豁免规则包括:DR 大于 70 的权威域名、来自 .gov 或 .edu 顶级域、所在页面有大量自然评论或社交分享数据。命中任一豁免规则的链接强制保留,不进 disavow。
剩下真正进 disavow 清单的链接,导出成 Google 标准格式(每行一个 domain: 或 link 行),上传到 Google Search Console 的 Disavow Tool(提交前的判断框架在2026 Google 外链拒绝工具决策指南有更细的拆解)。保哥的节奏是每个月最后一个工作日做一次,单次提交 200 到 500 个域名,提交后等 2 到 4 周看到 GSC 报表反映。
人工复核反哺,每月微调阈值
管道跑起来后最容易忽视的环节是反馈闭环。复核队列里的链接人工判断结果是宝贵的标注数据——人工说"保留"的低分链接,意味着模型当前阈值过于激进;人工说"disavow"的高分链接,意味着语义相似度对这类内容欺骗成功了。
保哥用一个简单的 Streamlit 界面让自己每周花 30 分钟过完队列。每条记录有当前得分、四组余弦值、结构化信号扣分明细、源页面截图。人工只需点"保留"或"disavow",标注会写回 SQLite。每月把过去 4 周的标注数据汇总,用 sklearn 的 LogisticRegression 重训一遍权重系数,输出新的阈值表。整套训练 + 验证 + 替换在 8 分钟内跑完,新的阈值表在下一轮自动管道开始时载入。
11 个月下来,最初版本的 S=0.40 阈值在英文 SaaS 站点上调到了 S=0.46,在中文 B2C 站点上调到了 S=0.38。两个方向的漂移恰恰反映了不同行业的外链生态差异——英文圈高质量论坛多、低分但合法的链接更多;中文圈 PBN 模板趋同、低分基本就是垃圾。
三个真实站点 11 个月数据复盘
下面是保哥手里三个跑过完整管道的站点的关键数据:
- 英文 SaaS 工具站(DR 42,年收入 6 位数美元):管道跑前外链总数 8420 条,跑后 disavow 547 条(6.5%),人工复核队列 312 条。disavow 提交 5 个月后,Ahrefs Spam Score 从 12 降到 4,Google 自然流量同期增长 23%(数据需要谨慎归因,因为同期也在做内容优化)。
- 中文 B2C 电商站(DR 28,年 GMV 8 位数人民币):外链 3120 条,disavow 412 条(13.2%),复核 187 条。disavow 后 GSC 的"被屏蔽的链接"指标下降明显,最大变化是低质链接对应的 keyword cannibalization 缓解。
- 多语种旅游内容站(DR 35,9 种语言):外链 12700 条,disavow 1450 条(11.4%),复核 720 条。这个站的难点是多语种,bge-m3 在小语种识别比 OpenAI 3-small 准 14 个百分点。
从这三个案例能提炼出来的最重要经验:disavow 不是越多越好。三个站点都有一个观察——disavow 比例超过 15% 之后,整站排名反而会出现 3 到 5 周的波动期,疑似 Google 重新评估你的外链分布。
成本核算:一个月跑 3 个站点的真实账单
保哥手里三个站点的月度成本大致是这样:
- OpenAI Embedding API:约 18 美元(含 Redis 缓存节省后的净支出)。
- Cloudscraper + ScrapingBee 抓取代理:约 35 美元。
- VPS(运行管道的 4 核 8G):约 12 美元。
- SQLite 备份到 S3:不到 1 美元。
合计约 66 美元。对比之下,Ahrefs Toxic Score 高级版的订阅费用是每月 449 美元起,Semrush 的同类功能在中阶 Guru 套餐内但包含的功能模块多。如果你只需要外链质量判断这一件事,自建管道的边际成本明显划算。
FAQPage 段:JSON-LD 怎么写
FAQ 内容会被 schema.org 的 FAQPage 类型结构化输出,下面常见问题段里的每一条 Q 和 A 都对应 JSON-LD 的一个 mainEntity 项。Question.name 是 Q 的纯文本,acceptedAnswer.text 是 A 的纯文本,两者都不含 HTML 标签——这部分由站点主题模板自动渲染并自动剥离 HTML,不需要手工处理。
常见问题解答
OpenAI 的 text-embedding-3-small 和 bge-m3 在外链识别场景下哪个更好
取决于站点语言结构。如果外链来源 80% 以上是英文,OpenAI text-embedding-3-small 在调用便利性、稳定性、维护成本上明显更优,月成本通常控制在 15 到 30 美元。如果站点涉及东南亚、日韩、中东等小语种,bge-m3 的多语言对齐效果比 OpenAI 嵌入模型平均高出 11 到 16 个百分点(保哥在多语种旅游站点实测)。bge-m3 需要一张 8GB 显存以上的 GPU 才能批量跑,单次部署成本 4090 二手卡约 5500 元人民币,回本周期视调用量而定。混合场景下保哥的方案是英文走 OpenAI、小语种页面走本地 bge-m3,两套并行。
跑一次完整的 7 步管道平均耗时多久
以 5000 条外链的样本为例,保哥的实际数据是:数据拉取 + 合并去重约 12 分钟,源页面抓取约 90 到 130 分钟(受目标站点响应速度影响最大),Embedding 调用约 25 分钟,余弦相似度计算 + 结构化加权约 4 分钟,导出 disavow 候选清单 1 分钟。整体大约 2.5 到 3 小时。第一次跑因为没有缓存会慢一些,后续每周复跑(仅处理新增外链)通常 20 分钟左右。
什么样的外链会被 AI 管道误判为垃圾,但实际上是好链接
主要有三类。第一类是来自 niche 老博客的真实推荐——这类页面通常字数不多、模板简陋、出站链接零散,会被结构化信号扣分。第二类是论坛或社区里的深度讨论帖中提到你的产品——所在段落的语义可能集中在用户问题描述上,和你的产品落点页主题相似度不高。第三类是新闻类外链——主站文章主题在讲行业事件而不在讲你具体的产品功能,得分会偏低。保哥的反悔豁免规则(高 DR 域名、.gov/.edu 域、有自然评论或社交分享数据)就是为了兜住这三类。
多久跑一次外链质量识别管道最合适
保哥的做法是分两个频率:全量重跑每月一次,增量跑(仅处理新增外链)每周一次。增量跑能在垃圾外链上线后两周内识别出来并提交 disavow,把负面影响压缩到最小窗口。全量重跑是为了应对源页面内容变化——一条 6 个月前判定为优质的外链,如果今天点开发现页面已经变成赌博跳转,全量重跑能把它重新识别出来。
用 Google Disavow Tool 提交 disavow 后多久能看到效果
保哥三个站点的实测数据:GSC 的"被屏蔽的链接"指标在提交后 2 到 4 周开始反映;Ahrefs 的 DR / Spam Score 调整滞后约 4 到 8 周(Ahrefs 也需要重新爬一遍才能知道你 disavow 了什么);Google 自然流量的可量化影响通常在 6 到 12 周后才能看到,且需要排除内容更新、季节性、其他算法波动的干扰。如果 12 周后没看到任何积极变化,要回头审视是否 disavow 过度。
能不能把这套管道做成 SaaS 卖给别人
技术上完全可行,但商业可行性需要谨慎评估。保哥认识的几个尝试过这条路的同行最大问题是数据合规——很多客户不愿意把自己的反向链接清单和站点平均向量交给第三方处理,宁可花更高的成本订阅 Ahrefs。如果做成本地化部署的 self-hosted 版本,定价模型又难撑得起开发投入。保哥目前的判断是这套管道作为内部工具或者外包 SEO 服务的内核更合适,而不是作为 SaaS 单独售卖。
开源世界有没有现成的工具可以替代自建
截至 2026 年 5 月,公开仓库里没有把语义识别、结构化信号、disavow 候选生成完整集成的工具。比较接近的是 Python SEO 社区里几个零散的工具集:BacklinkX(GitHub 上的实验项目,只覆盖第二三两步)、Disavow-AI(专注 GPT 调用,没做 Embedding)。保哥的建议是把这些工具的源代码作为参考,按本文 7 步管道思路自己搭一遍,避免对单个工具的过度依赖。
本地 bge-m3 部署的 4090 卡显存够大批量跑吗
RTX 4090 单卡 24GB 显存,跑 bge-m3 的 batch size 在 32 到 64 之间是稳定的,每秒约能处理 80 到 120 条平均长度 800 token 的文本。一天跑 8 小时大致能完成 200 万条 Embedding 调用,足以覆盖中型站点的全量外链分析需求。如果是企业级超大站点(外链超过 50 万条),可以考虑用 A6000 或者两张 4090 NVLink 提升吞吐。
这套 AI 管道和 Google 自带的 SpamBrain 是什么关系
SpamBrain 是 Google 内部的链接图谱反垃圾系统,2022 年推出后已经把"忽略低质量外链"做到了相当大的覆盖率——也就是说很多明显的垃圾外链 Google 内部已经判定无效,根本不会传递权重,也不会拖累你的排名。保哥的实测观察是:SpamBrain 对模板化批量发布的链接(论坛签名、目录站列表项、自动评论)拦截率明显高于 90%;但对模板差异化、单链投放、AI 重写过的高级 PBN 拦截率不稳定,依然需要站长用 Disavow Tool 主动屏蔽。所以 AI 管道的价值不在替代 SpamBrain,而在补足 SpamBrain 在"高级伪装垃圾"上的盲区。提交 disavow 之后 Google 会优先采信你的主动声明,相当于给 SpamBrain 一个明确信号。
权威参考资料
本文标题:《AI识别垃圾外链7步法:余弦相似度过滤实战指南》
本文链接:https://zhangwenbao.com/ai-spam-backlink-detection-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0